
CNN vs RNN: Diferența dintre CNN și RNN
Publicat: 2021-02-25Cuprins
Introducere
În domeniul inteligenței artificiale, rețelele neuronale care sunt inspirate de creierul uman sunt utilizate pe scară largă în extragerea și procesarea informațiilor complexe din diverse date și utilizarea atât a rețelelor neuronale convoluționale (CNN) cât și a rețelelor neuronale recurente (RNN) în astfel de aplicații. se dovedesc a fi utile.
În acest articol, vom înțelege conceptele din spatele rețelelor neuronale convoluționale și ale rețelelor neuronale recurente, vom vedea aplicațiile acestora și vom distinge diferențele dintre ambele tipuri populare de rețele neuronale.
Învață Training Machine Learning de la cele mai bune universități din lume. Câștigă programe de master, Executive PGP sau Advanced Certificate pentru a-ți accelera cariera.
Rețele neuronale și învățare profundă
Înainte de a intra în conceptele atât ale rețelelor neuronale convoluționale, cât și ale rețelelor neuronale recurente, să înțelegem conceptele din spatele rețelelor neuronale și modul în care acestea sunt legate de învățarea profundă.
În ultima vreme, Deep Learning a fost odată un concept utilizat pe scară largă în multe domenii și, prin urmare, este un subiect fierbinte în zilele noastre. Dar care este motivul pentru care se vorbește atât de mult? Pentru a răspunde la această întrebare, vom afla despre conceptul de rețele neuronale.
Pe scurt, rețelele neuronale sunt coloana vertebrală a învățării profunde. Ele sunt un număr stabilit de straturi constând din elemente extrem de interconectate cunoscute sub numele de neuroni care efectuează o serie de transformări asupra datelor, ceea ce generează propria înțelegere a datelor la care ne referim la termenul, caracteristici.

Ce sunt rețelele neuronale?
Primul concept cu care trebuie să trecem este cel al rețelelor neuronale. Știm că creierul uman este una dintre structurile complexe care au fost studiate vreodată. Datorită complexității sale, a existat o mare dificultate în dezvăluirea funcționării sale interioare, dar în prezent sunt întreprinse mai multe tipuri de cercetări pentru a-i dezvălui secretele. Acest creier uman servește drept inspirație din spatele modelelor rețelei neuronale.
Prin definiție, rețelele neuronale sunt unitățile funcționale ale învățării profunde care utilizează aceste rețele neuronale pentru a imita activitatea creierului și pentru a rezolva probleme complexe. Când datele de intrare sunt transmise rețelei neuronale, acestea sunt procesate prin straturile de perceptron și în cele din urmă dă rezultatul.
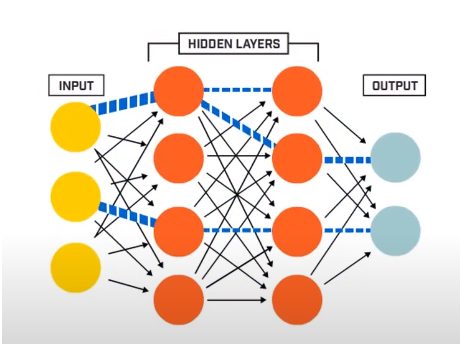
O rețea neuronală constă practic din 3 straturi -
- Strat de intrare
- Straturi ascunse
- Strat de ieșire
Stratul de intrare citește datele de intrare care sunt introduse în sistemul rețelei neuronale pentru preprocesare ulterioară de către straturile ulterioare de neuroni artificiali. Toate straturile care există între stratul de intrare și stratul de ieșire sunt denumite straturi ascunse.
În aceste Straturi Ascunse, neuronii prezenți în ele folosesc intrări și părtiniri ponderate și produc o ieșire utilizând funcțiile de activare. Stratul de ieșire este ultimul strat de neuroni care ne oferă rezultatul pentru programul dat.
Sursă
Cum funcționează rețelele neuronale?
Acum că avem o idee despre structura de bază a rețelelor neuronale, vom merge mai departe și vom înțelege cum funcționează. Pentru a înțelege funcționarea acestuia, trebuie mai întâi să învățăm despre una dintre structurile de bază ale rețelelor neuronale, cunoscută sub numele de Perceptron.
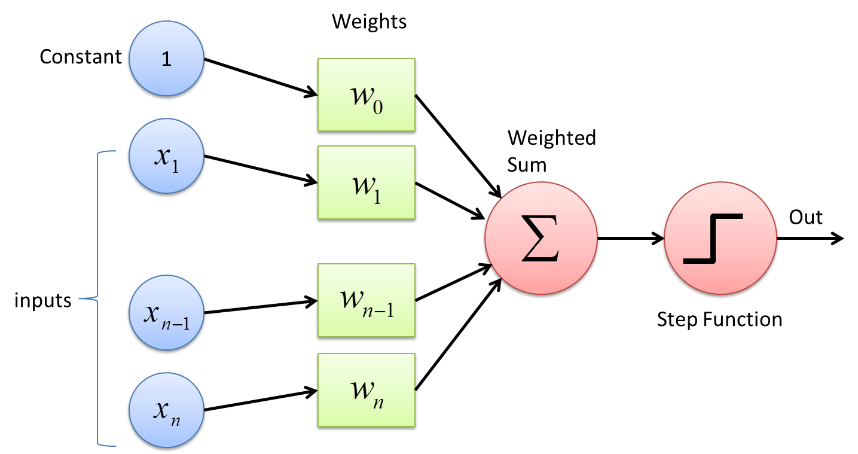
Perceptronul este un tip de rețea neuronală care este cea mai elementară ca formă. Este o simplă rețea neuronală artificială cu un singur strat ascuns. În rețeaua Perceptron, fiecare neuron este conectat la fiecare alt neuron în direcția înainte.
Conexiunile dintre acești neuroni sunt ponderate din cauza faptului că informația care este transferată între cei doi neuroni este întărită sau atenuată de aceste greutăți. În procesul de antrenament al rețelelor neuronale, aceste greutăți sunt ajustate pentru a obține valoarea corectă.
Perceptronul folosește o funcție de clasificare binară în care mapează un vector de variabile care sunt de natură binară la o singură ieșire binară. Acest lucru poate fi folosit și în învățarea supravegheată. Pașii din algoritmul de învățare Perceptron sunt:
- Înmulțiți toate intrările cu ponderile lor w, unde w sunt numere reale care pot fi inițial fixate sau randomizate.
- Adăugați produsul împreună pentru a obține suma ponderată, ∑ wj xj
- Odată ce suma ponderată a intrărilor este obținută, funcția de activare este aplicată pentru a determina dacă suma ponderată este mai mare decât o anumită valoare de prag sau nu, în funcție de funcția de activare aplicată. Ieșirea este atribuită ca 1 sau 0, în funcție de condiția pragului. Aici valoarea „-threshold” se referă și la termenul de părtinire, b.
În acest fel, algoritmul de învățare Perceptron poate fi folosit pentru a activa (valoare =1) neuronii prezenți în rețelele neuronale care sunt proiectate și dezvoltate astăzi. O altă reprezentare a algoritmului de învățare Perceptron este:
f(x) = 1, dacă ∑ wj xj + b ≥ 0
0, dacă ∑ wj xj + b < 0
Deși Perceptronii nu sunt folosiți pe scară largă în zilele noastre, ele rămân încă unul dintre conceptele de bază în rețelele neuronale. În urma cercetărilor ulterioare, s-a înțeles că modificările mici fie ale greutăților, fie ale părtinirii chiar și într-un singur perceptron ar putea schimba considerabil rezultatul de la 1 la 0 sau invers. Acesta a fost un dezavantaj major al Perceptronului. Prin urmare, au fost dezvoltate funcții de activare mai complexe, cum ar fi ReLU, funcțiile sigmoide, care introduce doar modificări moderate în greutatea și părtinirea neuronilor artificiali.
Sursă
Rețele neuronale convoluționale
O rețea neuronală convoluțională este un algoritm de învățare profundă care ia o imagine ca intrare, atribuie diferite ponderi și părtiniri diferitelor părți ale imaginii, astfel încât acestea să fie diferențiate unele de altele. Odată ce acestea devin diferențiabile, folosind diverse funcții de activare, modelul de rețea neuronală convoluțională poate îndeplini mai multe sarcini în domeniul procesării imaginilor, inclusiv recunoașterea imaginilor, clasificarea imaginilor, detectarea obiectelor și feței etc.
Fundamentul unui model de rețea neuronală convoluțională este că primește o imagine de intrare. Imaginea de intrare poate fi fie etichetată (cum ar fi pisică, câine, leu etc.) sau fără etichetă. În funcție de aceasta, algoritmii de învățare profundă sunt clasificați în două tipuri și anume algoritmii supravegheați, unde imaginile sunt etichetate și algoritmii nesupravegheați, unde imaginile nu au o etichetă anume.
Pentru computer, imaginea de intrare este văzută ca o matrice de pixeli, mai adesea sub forma unei matrice. Imaginile sunt în mare parte de forma hxlxd (unde h = înălțime, w = lățime, d = dimensiune). De exemplu, o imagine cu dimensiunea matricei de 16 x 16 x 3 denotă o imagine RGB (3 reprezintă valorile RGB). Pe de altă parte, o imagine de 14 x 14 x 1 matrice matrice reprezintă o imagine în tonuri de gri.
Sursă
Straturi ale rețelei neuronale convoluționale
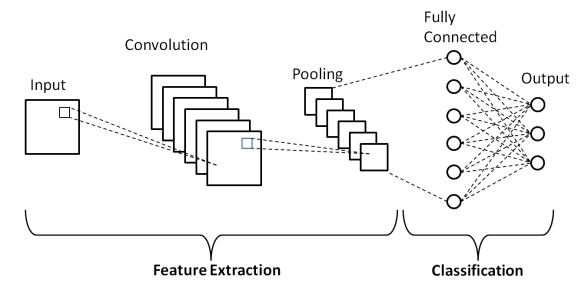
După cum se arată în Arhitectura de bază de mai sus a unei rețele neuronale convoluționale, un model CNN constă din mai multe straturi prin care imaginile de intrare sunt supuse preprocesării pentru a obține rezultatul. Practic, aceste straturi sunt diferențiate în două părți -

- Primele trei straturi, inclusiv stratul de intrare, stratul de convoluție și stratul de pooling, care acționează ca instrument de extragere a caracteristicilor pentru a deriva caracteristicile de la nivel de bază din imaginile introduse în model.
- Stratul final complet conectat și stratul de ieșire utilizează rezultatul straturilor de extracție a caracteristicilor și prezice o clasă pentru imagine în funcție de caracteristicile extrase.
Primul strat este stratul de intrare unde imaginea este introdusă în modelul rețelei neuronale convoluționale sub forma unei matrice de matrice, adică 32 x 32 x 3, unde 3 indică faptul că imaginea este o imagine RGB cu o înălțime și lățime egale. de 32 de pixeli. Apoi, aceste imagini de intrare trec prin Stratul Convoluțional unde este efectuată operația matematică de Convoluție.
Imaginea de intrare este combinată cu o altă matrice pătrată cunoscută sub numele de nucleu sau filtru. Prin glisarea nucleului unul câte unul peste pixelii imaginii de intrare, obținem imaginea de ieșire cunoscută sub numele de harta caracteristică care oferă informații despre caracteristicile la nivel de bază ale imaginii, cum ar fi marginile și liniile.
Stratul convoluțional este urmat de stratul Pooling al cărui scop este reducerea dimensiunii hărții caracteristicilor pentru a reduce costul de calcul. Acest lucru se face prin mai multe tipuri de pooling, cum ar fi Pooling maxim, Pooling mediu și Pooling Sum.
Stratul complet conectat (FC) este penultimul strat al modelului de rețea neuronală convoluțională, unde straturile sunt aplatizate și alimentate la stratul FC. Aici, prin utilizarea funcțiilor de activare, cum ar fi funcțiile Sigmoid, ReLU și tanH, are loc predicția etichetei și este dată în Stratul de ieșire final .
În cazul în care CNN-urile sunt scurte
Cu atât de multe aplicații utile ale rețelei neuronale convoluționale în datele imaginilor vizuale, CNN-urile au un mic dezavantaj prin faptul că nu funcționează bine cu o secvență de imagini (videoclipuri) și nu interpretează informațiile temporale și blocurile de text.
Pentru a trata date temporale sau secvențiale, cum ar fi propozițiile, avem nevoie de algoritmi care învață din datele trecute și, de asemenea, din datele viitoare din secvență. Din fericire, rețelele neuronale recurente fac exact asta.
Rețele neuronale recurente
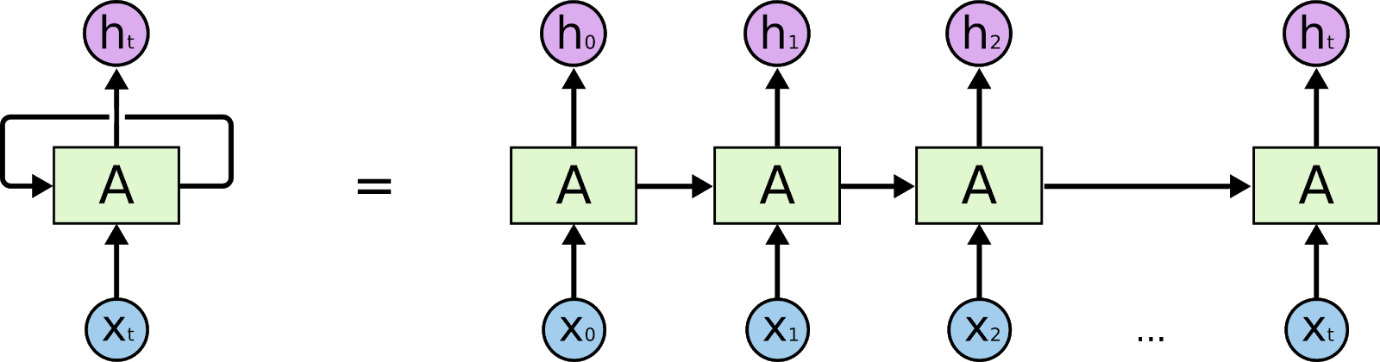
Rețelele neuronale recurente sunt rețele care sunt concepute pentru a interpreta informații temporale sau secvențiale. RNN-urile folosesc alte puncte de date într-o secvență pentru a face predicții mai bune. Ei fac acest lucru prin preluarea intrării și reutilizarea activărilor nodurilor anterioare sau a nodurilor ulterioare în secvență pentru a influența rezultatul.
Sursă
Ca urmare a memoriei lor interne, rețelele neuronale recurente își pot aminti detalii vitale, cum ar fi intrarea pe care le-au primit, ceea ce le face să fie foarte precise în prezicerea a ceea ce urmează. Prin urmare, sunt algoritmul cel mai preferat pentru date secvențiale, cum ar fi seriile de timp, vorbirea, textul, audio, video și multe altele. Rețelele neuronale recurente pot forma o înțelegere mult mai profundă a unei secvențe și a contextului acesteia în comparație cu alți algoritmi.
Cum funcționează rețelele neuronale recurente?
Baza pentru înțelegerea lucrului la rețelele neuronale recurente este aceeași cu cea pentru rețelele neuronale convoluționale, rețelele neuronale simple cu feed-forward, cunoscute și sub numele de Perceptron. În plus, în rețelele neuronale recurente, ieșirea de la pasul anterior este alimentată ca intrare la pasul curent. În majoritatea rețelelor neuronale, ieșirea este de obicei independentă de intrări și invers, aceasta este diferența de bază între RNN și alte rețele neuronale.
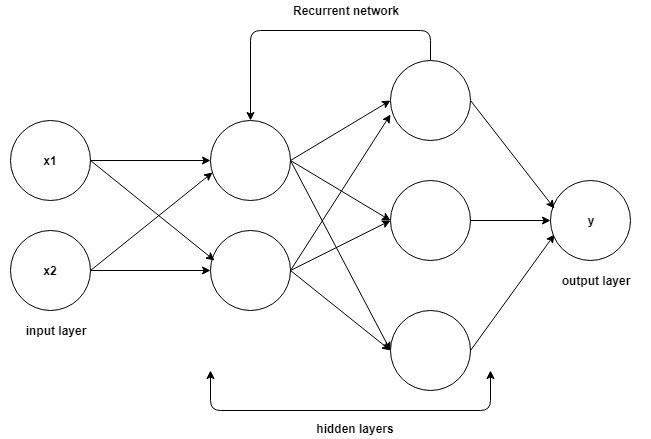
Sursă
Prin urmare, un RNN are două intrări: prezentul și trecutul recent. Acest lucru este important deoarece secvența de date conține informații cruciale despre ceea ce urmează, motiv pentru care un RNN poate face lucruri pe care alți algoritmi nu le pot face. Caracteristica principală și cea mai importantă a rețelelor neuronale recurente este starea Ascunsă, care reține unele informații despre o secvență.
Rețelele neuronale recurente au o memorie care stochează toate informațiile despre ceea ce a fost calculat. Folosind aceiași parametri pentru fiecare intrare și efectuând aceeași sarcină pe toate intrările sau straturile ascunse, complexitatea parametrilor este redusă.
Diferența dintre CNN și RNN
| Rețele neuronale convoluționale | Rețele neuronale recurente |
| În deep learning, o rețea neuronală convoluțională (CNN sau ConvNet) este o clasă de rețele neuronale profunde, cel mai frecvent aplicată la analiza imaginilor vizuale. | O rețea neuronală recurentă (RNN) este o clasă de rețele neuronale artificiale în care conexiunile dintre noduri formează un grafic direcționat de-a lungul unei secvențe temporale. |
| Este potrivit pentru date spațiale precum imagini. | RNN este folosit pentru date temporale, numite și date secvențiale. |
| CNN este un tip de rețea neuronală artificială feed-forward cu variații ale perceptronului multistrat conceput pentru a utiliza cantități minime de preprocesare. | RNN, spre deosebire de rețelele neuronale feed-forward, își pot folosi memoria internă pentru a procesa secvențe arbitrare de intrări. |
| CNN este considerat a fi mai puternic decât RNN. | RNN include mai puțină compatibilitate cu funcțiile în comparație cu CNN. |
| Acest CNN preia intrări de dimensiuni fixe și generează ieșiri de dimensiune fixă. | RNN poate gestiona lungimi arbitrare de intrare/ieșire. |
| CNN-urile sunt ideale pentru procesarea imaginilor și video. | RNN-urile sunt ideale pentru analiza textului și a vorbirii. |
| Aplicațiile includ Recunoașterea imaginilor, Clasificarea imaginilor, Analiza imaginilor medicale, Detectarea feței și Viziunea pe computer. | Aplicațiile includ traducerea textului, procesarea limbajului natural, traducerea limbii, analiza sentimentelor și analiza vorbirii. |
Concluzie
Astfel, în acest articol despre diferențele dintre cele mai populare două tipuri de rețele neuronale, rețelele neuronale convoluționale și rețelele neuronale recurente, am învățat structura de bază a unei rețele neuronale, împreună cu elementele fundamentale atât ale CNN, cât și ale RNN și, în final, am rezumat un scurtă comparație între cei doi cu aplicațiile lor în lumea reală.
Dacă sunteți interesat să aflați mai multe despre învățarea automată, consultați Programul Executive PG de la IIIT-B și upGrad în Învățare automată și IA, care este conceput pentru profesioniști care lucrează și oferă peste 450 de ore de formare riguroasă, peste 30 de studii de caz și sarcini, IIIT -B Statut de absolvenți, peste 5 proiecte practice practice și asistență pentru locuri de muncă cu firme de top.
De ce este CNN mai rapid decât RNN?
CNN-urile sunt mai rapide decât RNN-urile, deoarece sunt concepute pentru a gestiona imagini, în timp ce RNN-urile sunt concepute pentru a gestiona text. Deși RNN-urile pot fi antrenate să gestioneze imaginile, este totuși dificil pentru ei să separe caracteristicile contrastante care sunt mai apropiate. De exemplu, dacă aveți o imagine a unei fețe cu ochi, nas și gură, RNN-ilor le este greu să-și dea seama ce caracteristică să afișeze mai întâi. CNN-urile folosesc o grilă de puncte și, folosind un algoritm, pot fi antrenați să recunoască forme și modele. CNN-urile sunt mai bune decât RNN-urile la sortarea imaginilor; sunt mai rapidi decât RNN-urile pentru că sunt simplu de calculat și sunt mai buni la sortarea imaginilor.
Pentru ce este folosit RNN?
Rețelele neuronale recurente (RNN) sunt o clasă de rețele neuronale artificiale în care conexiunile dintre unități formează un ciclu direcționat. Ieșirea unei unități devine intrarea unei alte unități și așa mai departe, la fel cum ieșirea unui neuron devine intrarea altuia. RNN-urile au fost folosite cu succes pentru a îndeplini sarcini complexe, cum ar fi recunoașterea vorbirii și traducerea automată, care sunt dificil de realizat cu metode standard.
Ce este RNN și prin ce diferă de rețelele neuronale Feedforward?
Rețelele neuronale recurente (RNN) sunt un fel de rețele neuronale care sunt utilizate pentru procesarea datelor secvențiale. O rețea neuronală recurentă constă dintr-un strat de intrare, unul sau mai multe straturi ascunse și un strat de ieșire. Straturile ascunse sunt concepute pentru a învăța reprezentările interne ale datelor de intrare, care sunt apoi prezentate stratului de ieșire ca o reprezentare externă. RNN este antrenat cu ajutorul retropropagarii. RNN-urile sunt adesea comparate cu rețelele neuronale feedforward (FNN). În timp ce atât RNN-urile, cât și FNN-urile pot învăța reprezentări interne ale datelor, RNN-urile sunt capabile să învețe dependențe pe termen lung, de care FNN-urile nu sunt capabile.