
Alegerea unei noi tehnologii de bază de date fără server la o agenție (studiu de caz)
Publicat: 2022-03-10Acest articol a fost susținut cu amabilitate de dragii noștri prieteni de la Fauna, care fac ca lucrul cu date operaționale să fie productiv, scalabil și sigur pentru fiecare echipă de dezvoltare de software. Mulțumesc!

Adoptarea unei noi tehnologii este una dintre cele mai grele decizii pentru un tehnolog într-un rol de conducere. Aceasta este adesea o zonă mare și incomodă de risc, indiferent dacă construiți software pentru o altă organizație sau în cadrul propriei dvs.
În ultimii doisprezece ani, ca inginer software, m-am trezit în situația de a trebui să evaluez o nouă tehnologie cu o frecvență tot mai mare. Acesta poate fi următorul cadru frontend, un nou limbaj sau chiar arhitecturi complet noi, cum ar fi serverless.
Faza de experimentare este adesea distractivă și incitantă. Este locul în care inginerii de software sunt cel mai bine acasă, îmbrățișând noutatea și euforia momentelor „aha” în timp ce creează noi concepte. În calitate de ingineri, ne place să gândim și să schimbăm, dar cu suficientă experiență, fiecare inginer învață că până și cea mai incredibilă tehnologie are imperfecțiunile ei. Doar că nu le-ai găsit încă.
Acum, în calitate de co-fondator al unei agenții de creație, echipa mea și cu mine suntem adesea într-o poziție unică de a folosi noile tehnologii. Vedem multe proiecte greenfield, care devin oportunitatea perfectă de a introduce ceva nou. Aceste proiecte înregistrează, de asemenea, un nivel de izolare tehnică față de organizația mai mare și sunt adesea mai puțin împovărate de deciziile anterioare.
Acestea fiind spuse, unui lider bun de agenție este încredințat să aibă grijă de ideea cea mare a altcuiva și să o livreze lumii. Trebuie să-l tratăm cu și mai multă grijă decât am face-o cu propriile noastre proiecte. Ori de câte ori sunt pe cale să fac apelul final asupra unei noi tehnologii, mă gândesc adesea la această înțelepciune de la co-fondatorul Stack Overflow Joel Spolski:
„Trebuie să transpiri și să sângerezi cu chestia timp de un an sau doi înainte să știi cu adevărat că este suficient de bună sau să realizezi că, indiferent cât de mult ai încerca, nu poți...”
Aceasta este frica, acesta este locul în care niciun lider tehnologic nu vrea să se găsească. Alegerea unei noi tehnologii pentru un proiect în lumea reală este destul de dificilă, dar ca agenție, trebuie să iei aceste decizii cu proiectul altcuiva, cu cineva. visul altcuiva, banii altcuiva. La o agenție, ultimul lucru pe care ți-l dorești este să găsești una dintre acele pete aproape de termenul limită pentru un proiect. Termenele și bugetele strânse fac aproape imposibilă inversarea cursului după depășirea unui anumit prag, așa că descoperirea unei tehnologii nu poate face ceva critic sau nu este de încredere prea târziu într-un proiect poate fi catastrofal.
De-a lungul carierei mele de inginer software, am lucrat la companii SaaS și agenții creative. Când vine vorba de adoptarea unei noi tehnologii pentru un proiect, aceste două medii au criterii foarte diferite. Există o suprapunere în criterii, dar în general, mediul agenției trebuie să lucreze cu bugete rigide și constrângeri riguroase de timp . Deși dorim ca produsele pe care le construim să îmbătrânească bine în timp, este adesea mai dificil să facem investiții în ceva mai puțin dovedit sau să adoptăm tehnologie cu curbe de învățare mai abrupte și margini aspre.
Acestea fiind spuse, agențiile au și unele constrângeri unice pe care o singură organizație poate să nu le aibă. Trebuie să părăsim eficiență și stabilitate. Ora facturabilă este adesea unitatea finală de măsură când un proiect este finalizat. Am fost la companii SaaS unde să petreci o zi sau două pentru configurare sau o conductă de construcție nu este mare lucru.
La o agenție, acest tip de cost de timp pune presiune asupra relațiilor, deoarece echipele financiare văd marjele de profit reduse pentru rezultate puțin vizibile. De asemenea, trebuie să luăm în considerare întreținerea pe termen lung a unui proiect și, invers, ce se întâmplă dacă un proiect trebuie predat înapoi clientului. Prin urmare, trebuie să părăsim eficiență, curba de învățare și stabilitate în tehnologia pe care o alegem.
Când evaluez o nouă tehnologie, mă uit la trei domenii generale:
- Tehnologia
- Experiența dezvoltatorului
- Afacerea
Fiecare dintre aceste zone are un set de criterii pe care mi le place să le îndeplinesc înainte de a începe cu adevărat să mă scufund în cod și să experimentez. În acest articol, vom arunca o privire asupra acestor criterii și vom folosi exemplul de a lua în considerare o nouă bază de date pentru un proiect și o vom revizui la un nivel înalt sub fiecare lentilă. Luarea unei decizii concrete ca aceasta va ajuta la demonstrarea modului în care putem aplica acest cadru în lumea reală.
Tehnologia
Primul lucru la care trebuie să aruncați o privire atunci când evaluați o nouă tehnologie este dacă acea soluție poate rezolva problemele pe care pretinde că le rezolvă. Înainte de a descoperi cum o tehnologie ne poate ajuta procesul și operațiunile de afaceri, este important să stabilim mai întâi că îndeplinește cerințele noastre funcționale . De asemenea, aici îmi place să arunc o privire asupra soluțiilor existente pe care le folosim și a modului în care aceasta nouă se confruntă cu ele.
Îmi voi pune întrebări de genul:
- Rezolvă cel puțin problema soluției mele existente?
- În ce fel este această soluție mai bună?
- În ce fel este mai rău?
- Pentru zonele în care este mai rău, ce va fi nevoie pentru a depăși aceste neajunsuri?
- Va lua locul mai multor instrumente?
- Cât de stabilă este tehnologia?
De ce al nostru?
În acest moment, vreau să trec în revistă de ce căutăm o altă soluție. Un răspuns simplu este că ne confruntăm cu o problemă pe care soluțiile existente nu o rezolvă . Cu toate acestea, acest lucru este adesea cazul. Am rezolvat multe probleme de software de-a lungul anilor cu toată tehnologia pe care o avem astăzi. Ceea ce se întâmplă de obicei este că suntem transformați într-o nouă tehnologie care face ceva ce facem în prezent mai ușor, mai stabil, mai rapid sau mai ieftin.
Să luăm React ca exemplu. De ce am decis să adoptăm React când jQuery sau Vanilla JavaScript făceau treaba? În acest caz, utilizarea cadrului a evidențiat faptul că aceasta a fost o modalitate mult mai bună de a gestiona front-end-urile cu state. A devenit mai rapid pentru noi să construim lucruri precum funcțiile de filtrare și sortare lucrând cu structuri de date în loc de manipularea directă a DOM. Aceasta a fost o economie de timp și o stabilitate sporită a soluțiilor noastre.
Typescript este un alt exemplu în care am decis să-l adoptăm deoarece am constatat creșteri ale stabilității codului nostru și ale menținabilității. Odată cu adoptarea de noi tehnologii, adesea nu există o problemă clară pe care căutăm să o rezolvăm, ci doar căutăm să rămânem la curent și apoi să descoperim soluții mai eficiente și mai stabile decât le folosim în prezent.
În cazul unei baze de date, ne-am gândit în mod special să trecem la o opțiune fără server . Am observat mult succes cu aplicațiile și implementările fără server, reducându-ne cheltuielile generale ca organizație. Un domeniu în care am simțit că acest lucru lipsește a fost stratul nostru de date. Am văzut servicii precum Amazon Aurora, Fauna, Cosmos și Firebase care aplicau principii serverless bazelor de date și am vrut să vedem dacă este timpul să facem noi înșine saltul. În acest caz, am căutat să reducem cheltuielile operaționale și să creștem viteza și eficiența dezvoltării.
Este important la acest nivel să înțelegeți de ce înainte de a începe să vă scufundați în noi oferte. Acest lucru se poate datora faptului că rezolvați o problemă nouă, dar mult mai des căutați să vă îmbunătățiți capacitatea de a rezolva un tip de problemă pe care o rezolvați deja. În acest caz, trebuie să faceți un inventar unde ați fost pentru a vă da seama ce ar oferi o îmbunătățire semnificativă a fluxului dvs. de lucru. Pe baza exemplului nostru de analiză a bazelor de date fără server, va trebui să aruncăm o privire la modul în care rezolvăm problemele în prezent și unde aceste soluții sunt insuficiente.
Unde am fost...
În calitate de agenție, am folosit anterior o gamă largă de baze de date, inclusiv, dar fără a se limita la, MySQL, PostgreSQL, MongoDB, DynamoDB, BigQuery și Firebase Cloud Storage. Marea majoritate a muncii noastre sa concentrat pe trei baze de date de bază: PostgreSQL, MongoDB și Firebase Realtime Database. Fiecare dintre acestea are, de fapt, oferte semi-server, dar unele caracteristici cheie ale ofertelor mai noi ne-au făcut să reevaluăm ipotezele noastre anterioare. Să aruncăm o privire la experiența noastră istorică cu fiecare dintre acestea mai întâi și de ce suntem lăsați să luăm în considerare alternative în primul rând.
Am ales de obicei PostgreSQL pentru proiecte mai mari, pe termen lung, deoarece acesta este standardul de aur testat în luptă pentru aproape orice. Acceptă tranzacții clasice, date normalizate și este compatibil cu ACID. Există o mulțime de instrumente și ORM-uri disponibile în aproape fiecare limbă și poate fi chiar folosită ca bază de date NoSQL ad-hoc cu suport pentru coloana JSON. Se integrează bine cu multe cadre, biblioteci și limbaje de programare existente, făcându-l un adevărat cal de bătaie care merge oriunde. Este, de asemenea, open-source și, prin urmare, nu ne blochează în niciun furnizor. După cum se spune, nimeni nu a fost concediat pentru că a ales Postgres.
Acestea fiind spuse, treptat ne-am trezit să folosim PostgreSQL din ce în ce mai puțin pe măsură ce devenim mai mult un magazin orientat spre Node. Am descoperit că ORM-urile pentru Node sunt lipsite de strălucire și necesită mai multe interogări personalizate (deși acest lucru a devenit mai puțin problematic acum), iar NoSQL s-a părut o potrivire mai naturală atunci când lucrați într-un timp de execuție JavaScript sau TypeScript. Acestea fiind spuse, am avut adesea proiecte care puteau fi realizate destul de repede cu modelarea relațională clasică, cum ar fi fluxurile de lucru de comerț electronic. Cu toate acestea, gestionarea configurației locale a bazei de date, unificarea fluxului de testare între echipe și gestionarea migrărilor locale au fost lucruri pe care nu le-a plăcut și am fost fericiți să le lăsăm în urmă pe măsură ce bazele de date bazate pe cloud NoSQL au devenit mai populare.
MongoDB a fost din ce în ce mai mult baza noastră de date de bază, pe măsură ce am adoptat Node.js ca back-end preferat. Lucrul cu MongoDB Atlas a făcut mai ușor să avem baze de date rapide de dezvoltare și testare pe care echipa noastră le-ar putea folosi. Pentru o vreme, MongoDB nu a fost compatibil cu ACID, nu a acceptat tranzacții și a descurajat prea multe operațiuni interioare asemănătoare aderării, astfel încât pentru aplicațiile de comerț electronic încă folosim Postgres cel mai des. Acestea fiind spuse, există o mulțime de biblioteci care merg cu el, iar limbajul de interogare Mongo și suportul JSON de primă clasă ne-au oferit viteză și eficiență pe care nu le-am experimentat cu bazele de date relaționale. MongoDB a adăugat recent suport pentru tranzacțiile ACID, dar pentru o lungă perioadă de timp, acesta a fost motivul principal pentru care am opta pentru Postgres.
MongoDB ne-a introdus și la un nou nivel de flexibilitate. În mijlocul unui proiect de agenție, cerințele sunt obligate să se schimbe. Indiferent de cât de greu te aperi de el, există întotdeauna o cerință de date de ultimă oră . Cu bazele de date NoSQL, în general, flexibilitatea structurii de date a făcut ca aceste tipuri de modificări să fie mai puțin dure. Nu am ajuns să avem un folder plin de fișiere de migrare pentru a gestiona coloanele adăugate, eliminate și adăugate din nou înainte ca un proiect să se întâmple.
Ca serviciu, Mongo Atlas a fost, de asemenea, destul de aproape de ceea ce ne-am dorit într-un serviciu cloud de baze de date. Îmi place să mă gândesc la Atlas ca la o ofertă semi -server, deoarece mai aveți ceva operațional în gestionarea acesteia. Trebuie să furnizați o anumită dimensiune de bază de date și să selectați o cantitate de memorie în avans. Aceste lucruri nu se vor scala pentru dvs. automat, așa că va trebui să le monitorizați când este timpul să oferiți mai mult spațiu sau memorie. Într-o bază de date cu adevărat fără server, totul s-ar întâmpla automat și la cerere.
De asemenea, am folosit Firebase Realtime Database pentru câteva proiecte. Aceasta a fost într-adevăr o ofertă fără server în care baza de date crește și scade la cerere și, cu prețuri cu plata pe măsură , avea sens pentru aplicațiile în care scara nu era cunoscută de la început și bugetul era limitat. Am folosit acest lucru în loc de MongoDB pentru proiecte de scurtă durată care aveau cerințe simple de date.
Un lucru care nu ne-a plăcut la Firebase a fost că se simțea mai departe de modelul relațional tipic construit în jurul datelor normalizate cu care eram obișnuiți. Menținerea structurilor de date plate a însemnat că am avut adesea mai multe duplicari, care ar putea deveni puțin urâte pe măsură ce un proiect crește. În cele din urmă, trebuie să actualizați aceleași date în mai multe locuri sau să încercați să uniți referințe diferite, rezultând mai multe interogări care pot deveni greu de raționat în cod. Deși ne-a plăcut Firebase, nu ne-am îndrăgostit niciodată de limbajul de interogare și, uneori, am considerat că documentația este slabă.
În general, atât MongoDB, cât și Firebase au avut un accent similar pe datele denormalizate și, fără acces la tranzacții eficiente, am găsit adesea multe dintre fluxurile de lucru care erau ușor de modelat în bazele de date relaționale, ceea ce a condus la un cod mai complex la nivelul aplicației, cu omologii NoSQL. Dacă am putea obține flexibilitatea și ușurința acestor oferte NoSQL cu robustețea și modelarea relațională a unei baze de date SQL tradiționale, am fi găsit într-adevăr o potrivire excelentă. Am simțit că MongoDB are API și capabilități mai bune, dar Firebase avea operațional modelul cu adevărat fără server.
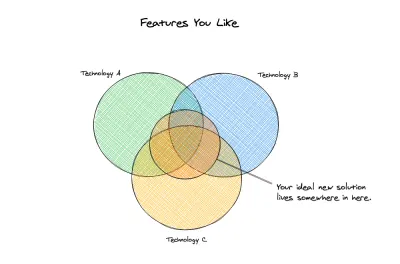
Idealul nostru
În acest moment, putem începe să ne uităm la ce noi opțiuni vom lua în considerare. Am definit clar soluțiile noastre anterioare și am identificat lucrurile care sunt importante pentru noi să le avem la minimum în noua noastră soluție. Nu avem doar o bază sau un set minim de cerințe, dar avem și un set de probleme pe care am dori ca noua soluție să le atenueze pentru noi. Iată cerințele tehnice pe care le avem:
- Operațional fără server cu scară la cerere
- Modelare flexibilă (fără schemă)
- Fără dependență de migrații sau ORM-uri
- Tranzacții conform ACID
- Sprijină relații și date normalizate
- Funcționează atât cu backend-uri fără server, cât și cu backend-uri tradiționale
Deci, acum că avem o listă de elemente obligatorii, putem evalua de fapt unele opțiuni. S-ar putea să nu fie important ca noua soluție să atingă fiecare țintă aici. Este posibil să atingă combinația potrivită de caracteristici în care soluțiile existente nu se suprapun. De exemplu, dacă doreai flexibilitate fără schemă , trebuia să renunți la tranzacțiile ACID. (Acesta a fost cazul mult timp cu bazele de date.)
Un exemplu dintr-un alt domeniu este, dacă doriți să aveți validare dactilografă în redarea șablonului, trebuie să utilizați TSX și React. Dacă alegeți opțiuni precum Svelte sau Vue, puteți avea acest lucru - parțial, dar nu complet - prin randarea șablonului . Așadar, o soluție care v-a oferit amprenta mică și viteza Svelte cu verificarea tipului la nivel de șablon a React și TypeScript ar putea fi suficientă pentru adoptare, chiar dacă îi lipsește o altă caracteristică. Echilibrul dintre dorințele și nevoile se va schimba de la proiect la proiect. Depinde de dvs. să vă dați seama unde va fi valoarea și să decideți cum să bifați cele mai importante puncte din analiza dvs.
Acum putem arunca o privire asupra unei soluții și vedem cum se evaluează aceasta față de soluția dorită. Fauna este o soluție de bază de date fără server care se mândrește cu o scară la cerere cu distribuție globală. Este o bază de date fără schemă, care oferă tranzacții conforme cu ACID și acceptă interogări relaționale și date normalizate ca caracteristică. Fauna poate fi folosit atât în aplicații fără server, cât și în backend-uri mai tradiționale și oferă biblioteci pentru a lucra cu cele mai populare limbi. Fauna oferă, în plus, fluxuri de lucru pentru autentificare, precum și o multi-chirie simplă și eficientă. Acestea sunt ambele caracteristici suplimentare solide de remarcat, deoarece ar putea fi factorii de balansare atunci când două tehnologii sunt nas la nas în evaluarea noastră.
Acum, după ce ne uităm la toate aceste puncte forte, trebuie să evaluăm punctele slabe . Una dintre ele este Fauna, nu este open source. Acest lucru înseamnă că există riscuri de blocare a furnizorilor sau de modificări ale afacerii și ale prețurilor, care sunt în afara controlului dumneavoastră. O sursă deschisă poate fi drăguță, deoarece poți deseori să ridici tehnologia și să duci tehnologia unui alt furnizor, dacă vrei sau dacă poți contribui înapoi la proiect.
În lumea agențiilor, blocarea vânzătorilor este ceva pe care trebuie să-l urmărim îndeaproape, nu atât din cauza prețului, ci este importantă viabilitatea afacerii de bază. A trebui să schimbați bazele de date pentru un proiect aflat în plină dezvoltare sau vechi de câțiva ani sunt ambele dezastruoase pentru o agenție. Adesea, un client va trebui să plătească factura pentru acest lucru, ceea ce nu este o conversație plăcută.
O altă slăbiciune de care ne preocupam este concentrarea pe JAMstack . Deși ne place JAMstack, ne trezim să construim mai des o mare varietate de aplicații web tradiționale. Vrem să fim siguri că Fauna continuă să sprijine aceste cazuri de utilizare. Am avut o experiență proastă în trecut cu un furnizor de găzduire care a intrat all-in pe JAMstack și am ajuns să fim nevoiți să migrăm o serie destul de mare de site-uri din serviciu, așa că vrem să fim încrezători că toate cazurile de utilizare vor continua să fie văzute. suport solid. În acest moment, acesta pare să fie cazul, iar fluxurile de lucru fără server furnizate de Fauna pot completa destul de frumos o aplicație mai tradițională.

În acest moment, ne-am făcut cercetările funcționale și singura modalitate de a ști dacă această soluție este viabilă este să coborâm și să scriem ceva cod. Într-un mediu de agenție, nu putem doar să luăm săptămâni din program pentru ca oamenii să evalueze mai multe soluții. Aceasta este natura lucrului într-o agenție față de un mediu SaaS . În cel din urmă, s-ar putea să construiți câteva prototipuri pentru a încerca să ajungeți la soluția potrivită. Într-o agenție, veți avea câteva zile pentru a experimenta sau poate aveți ocazia de a face un proiect secundar, dar în general trebuie să reducem acest lucru la una sau două tehnologii în acest stadiu și apoi să punem degetele la tastatură.
Experiența dezvoltatorului
Judecarea experienței unei noi tehnologii este poate cea mai dificilă dintre cele trei domenii, deoarece este subiectivă prin natura lor. De asemenea, va avea variabilitate de la o echipă la alta. De exemplu, dacă ați întrebat un programator Ruby, un programator Python și un programator Rust despre opiniile lor despre diferitele caracteristici ale limbajului, veți primi o serie de răspunsuri. Așadar, înainte de a începe să judeci o experiență, trebuie mai întâi să decizi care sunt caracteristicile cele mai importante pentru echipa ta în general.

Pentru agenții, cred că există două blocaje majore care apar în ceea ce privește experiența dezvoltatorului:
- Timp de configurare și configurare
- Capacitatea de învățare
Ambele afectează viabilitatea pe termen lung a unei noi tehnologii în moduri diferite. Menținerea echipelor tranzitorii de dezvoltatori sincronizate la o agenție poate fi o bătaie de cap. Instrumentele care au o mulțime de costuri inițiale de configurare și configurații sunt notoriu dificil de lucrat pentru agenții. Celălalt este capacitatea de învățare și cât de ușor este pentru dezvoltatori să dezvolte noua tehnologie. Vom analiza acestea mai detaliat și de ce sunt baza mea atunci când încep să evaluez experiența dezvoltatorului.
Ora de configurare și configurație
Agențiile tind să aibă puțină răbdare și timp pentru configurare. Pentru mine, iubesc uneltele ascuțite, cu design ergonomic, care îmi permit să mă apuc rapid de treaba la problema de afaceri la îndemână. Cu câțiva ani în urmă, am lucrat pentru o companie SaaS care avea o configurare locală complexă care implica multe configurații și care deseori a eșuat la anumite momente ale procesului de configurare. Odată ce ai fost configurat, înțelepciunea convențională a fost să nu atingi nimic și să speri că nu ai fost la companie suficient de mult pentru a fi nevoit să-l instalezi din nou pe o altă mașină. Am întâlnit dezvoltatori cărora le-a plăcut foarte mult să configureze fiecare parte din configurația lor emacs și nu s-au gândit la nimic să piardă câteva ore într-un mediu local defect.
În general, am constatat că inginerii agenției au un dispreț față de aceste tipuri de lucruri în munca lor de zi cu zi. În timp ce sunt acasă, s-ar putea schimba cu aceste tipuri de unelte, dar la un termen limită nu există nimic ca instrumentele care pur și simplu funcționează. La agenții, de obicei, am prefera să învățăm câteva lucruri noi care funcționează bine, în mod constant, decât să putem configura fiecare piesă de tehnologie după gustul personal al fiecărui individ.
Un lucru bun despre lucrul cu o platformă cloud care nu este open source este că dețin în întregime setarea și configurația. Deși un dezavantaj al acestui lucru este blocarea furnizorului, avantajul este că aceste tipuri de instrumente fac adesea ceea ce sunt configurați pentru a face bine. Nu există nicio modificare a mediilor, nu există setări locale și nicio conducte de implementare. De asemenea, avem mai puține decizii de luat.
Acesta este în mod inerent atractia serverless . Serverless, în general, se bazează mai mult pe serviciile și instrumentele proprietare. Schimbăm flexibilitatea găzduirii și a codului sursă, astfel încât să putem obține o mai mare stabilitate și să ne concentrăm pe problemele domeniului de afaceri pe care încercăm să-l rezolvăm. Voi observa, de asemenea, că atunci când evaluez o tehnologie și am senzația că ar putea fi necesară migrarea de pe o platformă, acesta este adesea un semn rău de la început.
În cazul bazelor de date, configurarea set-it-and-forget-it este ideală atunci când lucrați cu clienți în care nevoile bazei de date pot fi ambigue. Am avut clienți care nu erau siguri cât de popular ar fi un program sau o aplicație. Am avut clienți pe care din punct de vedere tehnic nu am fost contractați să îi susținem în acest fel, dar totuși ne-au sunat în panică când au avut nevoie de noi pentru a-și scala baza de date sau aplicația.
În trecut, ar fi trebuit întotdeauna să luăm în considerare lucruri precum redundanța, replicarea datelor și fragmentarea la scară atunci când am creat SOW-urile noastre. Încercarea de a acoperi fiecare scenariu în timp ce fii pregătit să muți o carte completă de afaceri în cazul în care o bază de date nu a fost scalată este o situație imposibil de pregătit. În cele din urmă, o bază de date fără server facilitează aceste lucruri.
Nu pierdeți niciodată date , nu trebuie să vă faceți griji cu privire la replicarea datelor într-o rețea și nici la furnizarea unei baze de date mai mari și a unei mașini pe care să le ruleze – totul funcționează. Ne concentrăm doar pe problema de business în cauză, arhitectura tehnică și amploarea vor fi întotdeauna gestionate. Pentru echipa noastră de dezvoltare, acesta este un câștig uriaș; avem mai puține exerciții de incendiu, monitorizare și schimbare de context.
Capacitatea de învățare
Există o măsură clasică a experienței utilizatorului, care cred că este aplicabilă experienței dezvoltatorului, care este capacitatea de învățare . Când proiectăm pentru o anumită experiență de utilizator, nu ne uităm doar dacă ceva este evident sau ușor la prima încercare. Tehnologia are mai multă complexitate decât atât de cele mai multe ori. Important este cât de ușor un utilizator nou poate învăța și stăpâni sistemul.
Când vine vorba de instrumente tehnice, în special de cele puternice, ar fi foarte mult să ceri ca curba de învățare să fie zero . De obicei, ceea ce căutăm este să existe o documentație excelentă pentru cele mai obișnuite cazuri de utilizare și ca aceste cunoștințe să fie ușor și rapid construite în timpul unui proiect. Să pierzi puțin timp pentru a învăța la primul proiect cu o tehnologie este în regulă. După aceea, ar trebui să vedem îmbunătățirea eficienței cu fiecare proiect succesiv.
Ceea ce caut în mod special aici este modul în care putem valorifica cunoștințele și modelele pe care le cunoaștem deja pentru a ajuta la scurtarea curbei de învățare. De exemplu, cu bazele de date fără server, va exista practic zero curbă de învățare pentru a le configura în cloud și implementate. Când vine vorba de utilizarea bazei de date, unul dintre lucrurile care îmi plac este când putem încă să valorificăm toți anii de stăpânire a bazelor de date relaționale și să aplicăm aceste învățăminte în noua noastră configurație. În acest caz, învățăm cum să folosim un nou instrument, dar nu ne obligă să ne regândim modelarea datelor de la zero.

Ca exemplu în acest sens, atunci când folosim Firebase, MongoDB și DynamoDB, am constatat că încurajează datele denormalizate, mai degrabă decât să încercăm să unim diferite documente. Acest lucru a creat o mulțime de fricțiuni cognitive atunci când ne modelăm datele, deoarece trebuia să ne gândim mai degrabă în termeni de modele de acces decât de entități de afaceri. Pe de altă parte, Fauna ne-a permis să valorificăm anii noștri de cunoștințe relaționale, precum și preferința noastră pentru date normalizate atunci când a fost vorba de modelarea datelor.
Partea cu care trebuia să ne obișnuim a fost să folosim indecși și un nou limbaj de interogare pentru a aduce acele piese împreună. În general, am descoperit că păstrarea conceptelor care fac parte din paradigmele mai mari de proiectare software facilitează echipa de dezvoltare în ceea ce privește capacitatea de învățare și adoptare.
De unde știm că o echipă adoptă și iubește o nouă tehnologie? Cred că cel mai bun semn este atunci când ne întrebăm dacă acel instrument se integrează cu noua tehnologie menționată? Când o nouă tehnologie ajunge la un nivel de dezirabilitate și plăcere, echipa caută modalități de a o încorpora în mai multe proiecte, acesta este un semn bun că aveți un câștigător.
Afacerea
În această secțiune, trebuie să ne uităm la modul în care o nouă tehnologie satisface nevoile noastre de afaceri . Acestea includ întrebări precum:
- Cât de ușor poate fi prețuit și integrat în planurile noastre de asistență?
- Putem trece cu ușurință la clienți?
- Clienții pot fi încorporați la acest instrument dacă este necesar?
- Cât timp economisește acest instrument, dacă este cazul?
Ascensiunea serverless ca paradigmă se potrivește bine agențiilor. Când vorbim despre baze de date și DevOps, nevoia de specialiști în aceste domenii la agenții este limitată. Adesea predăm un proiect când terminăm cu el sau îl sprijinim într-o capacitate limitată pe termen lung. Avem tendința de a părăsi inginerii full-stack, deoarece aceste nevoi depășesc numărul nevoilor DevOps cu o marjă mare. Dacă am angaja un inginer DevOps, probabil că ar petrece câteva ore implementând un proiect și multe alte ore petrecându-și așteptarea unui incendiu.
În acest sens, avem întotdeauna câțiva contractori DevOps pregătiți, dar nu angajăm pentru aceste posturi cu normă întreagă. Aceasta înseamnă că nu ne putem baza pe un inginer DevOps pentru a fi gata să rezolvăm o problemă neașteptată. Pentru noi, știm că putem obține tarife mai bune la găzduire mergând direct la AWS, dar știm și că, folosind Heroku, ne putem baza pe personalul nostru existent pentru a depana majoritatea problemelor. Cu excepția cazului în care avem un client pe care trebuie să-l sprijinim pe termen lung cu nevoi specifice de backend, ne place să utilizăm implicit platformele gestionate ca serviciu.
Bazele de date nu fac excepție. Ne place să ne bazăm pe servicii precum Mongo Atlas sau Heroku Postgres pentru a face acest proces cât mai ușor posibil. Pe măsură ce am început să vedem din ce în ce mai mult din stack-ul nostru în instrumente fără server precum Vercel, Netlify sau AWS Lambda – nevoile noastre de baze de date au trebuit să evolueze odată cu asta. Bazele de date fără server precum Firebase, DynamoDB și Fauna sunt grozave pentru că se integrează bine cu aplicațiile fără server, dar și eliberează complet afacerea noastră de aprovizionare și scalare.
Aceste soluții funcționează bine și pentru aplicații mai tradiționale, în care nu avem o aplicație fără server, dar putem în continuare să valorificăm eficiența fără server la nivel de bază de date. Ca afacere, este mai productiv pentru noi să învățăm o bază de date unică care se poate aplica ambelor lumi decât la schimbarea contextului. Acest lucru este similar cu decizia noastră de a adopta JavaScript Node și izomorf (și TypeScript).
Unul dintre dezavantajele pe care le-am constatat cu serverless a fost stabilirea de prețuri pentru clienții pentru care gestionăm aceste servicii. Într-o arhitectură mai tradițională, nivelurile cu tarife forfetare facilitează transpunerea acestora într-o rată pentru clienții cu circumstanțe previzibile pentru a suporta creșteri și depășiri. Când vine vorba de serverless, acest lucru poate fi ambiguu. Oamenilor din domeniul financiar nu le place de obicei să audă lucruri precum noi percepem 1/10 de bănuț pentru fiecare citire de peste 1 milion și așa mai departe.
Acest lucru este greu de tradus într-un număr fix chiar și pentru ingineri, deoarece adesea construim aplicații pentru care nu suntem siguri care va fi utilizarea . De multe ori trebuie să creăm noi înșine niveluri, dar numeroasele variabile care intră în calculul costului unui lambda pot fi greu de înțeles. În cele din urmă, pentru un produs SaaS, aceste modele de prețuri cu plata în funcție de utilizare sunt grozave, dar pentru agenții contabililor le plac cifre mai concrete și previzibile.
Când a fost vorba de Fauna, acest lucru a fost cu siguranță mai ambiguu de înțeles decât să spunem o bază de date MySQL standard care avea găzduire forfetară pentru o anumită cantitate de spațiu. Avantajul a fost că Fauna oferă un calculator drăguț pe care l-am putut folosi pentru a elabora propriile noastre scheme de prețuri.
Un alt aspect dificil de serverless poate fi faptul că mulți dintre acești furnizori nu permit defalcarea ușoară a fiecărei aplicații găzduite. De exemplu, platforma Heroku face acest lucru destul de ușor prin crearea de noi conducte și echipe. Putem chiar introduce cardul de credit al unui client pentru ei în cazul în care nu doresc să folosească planurile noastre de găzduire. Toate acestea se pot face și în cadrul aceluiași tablou de bord, așa că nu a fost nevoie să creăm mai multe autentificări.
Când a fost vorba de alte instrumente fără server, acest lucru a fost mult mai dificil. În evaluarea bazelor de date fără server, Firebase acceptă împărțirea plăților în funcție de proiect . În cazul Fauna sau DynamoDB, acest lucru nu este posibil, așa că trebuie să lucrăm pentru a monitoriza utilizarea în tabloul de bord, iar dacă clientul dorește să părăsească serviciul nostru, ar trebui să transferăm baza de date în propriul cont.
În cele din urmă, instrumentele fără server oferă oportunități excelente de afaceri în ceea ce privește economiile de costuri, managementul și eficiența procesului. Cu toate acestea, adesea se dovedesc a fi o provocare pentru agenții atunci când vine vorba de prețuri și gestionarea contului. Acesta este un domeniu în care a trebuit să folosim calculatoarele de cost pentru a ne crea propriile niveluri de preț previzibile sau pentru a configura clienții cu propriile conturi, astfel încât să poată efectua plățile direct.
Concluzie
Poate fi o sarcină dificilă adoptarea unei noi tehnologii ca agenție. Deși suntem într-o poziție unică de a lucra cu proiecte noi, greenfield, care au oportunități pentru noi tehnologii, trebuie să luăm în considerare și investiția pe termen lung a acestora. Cum se vor comporta? Oamenii noștri vor fi productivi și vor face plăcere să le folosească? Can we incorporate them into our business offering?
You need to have a firm grasp of where you have been before you figure out where you want to go technologically. When evaluating a new tool or platform it's important to think of what you have tried in the past and figure out what is most important to you and your team. We took a look at the concept of a serverless database and passed it through our three lenses – the technology, the experience, and the business. We were left with some pros and cons and had to strike the right balance.
After we evaluated serverless databases, we decided to adopt Fauna over the alternatives. We felt the technology was robust and ticked all of our boxes for our technology filter. When it came to the experience, virtually zero configuration and being able to leverage our existing knowledge of relational data modeling made this a winner with the development team. On the business side serverless provides clear wins to efficiency and productivity , however on the pricing side and account management there are still some difficulties. We decided the benefits in the other areas outweighed the pricing difficulties.
Overall, we highly recommend giving Fauna a shot on one of your next projects. It has become one of our favorite tools and our go-to database of choice for smaller serverless projects and even more traditional large backend applications. The community is very helpful, the learning curve is gentle, and we believe you'll find levels of productivity you hadn't realized before with existing databases.
When we first use a new technology on a project, we start with something either internal or on the smaller side. We try to mitigate the risk by wading into the water rather than leaping into the deep end by trying it on a large and complex project. As the team builds understanding of the technology, we start using it for larger projects but only after we feel comfortable that it has handled similar use cases well for us in the past.
In general, it can take up to a year for a technology to become a ubiquitous part of most projects so it is important to be patient. Agencies have a lot of flexibility but also are required to ensure stability in the products they produce, we don't get a second chance. Always be experimenting and pushing your agency to adopt new technologies, but do so carefully and you will reap the benefits.
Lectură suplimentară
- Serverless Database Wishlist - What's Missing Today
- Relational NoSQL: Yes, that is an option
- Concerning toolkits - A great piece about the merits of zero configuration on developer experience