
Construirea unui detector de cameră pentru dispozitive IoT pe Mac OS
Publicat: 2022-03-10Știind în ce cameră vă aflați, sunt posibile diverse aplicații IoT — de la aprinderea luminii până la schimbarea canalelor TV. Deci, cum putem detecta momentul în care tu și telefonul tău vă aflați în bucătărie, dormitor sau sufragerie? Cu hardware-ul de astăzi, există o multitudine de posibilități:
O soluție este echiparea fiecărei camere cu un dispozitiv bluetooth . Odată ce telefonul dvs. se află în raza de acțiune a unui dispozitiv bluetooth, telefonul dvs. va ști ce cameră este, pe baza dispozitivului bluetooth. Cu toate acestea, menținerea unei game de dispozitive Bluetooth este o suprasolicitare semnificativă - de la înlocuirea bateriilor până la înlocuirea dispozitivelor disfuncționale. În plus, apropierea de dispozitivul Bluetooth nu este întotdeauna răspunsul: dacă ești în sufragerie, lângă peretele comun cu bucătăria, aparatele tale de bucătărie nu ar trebui să înceapă să producă alimente.
O altă soluție, deși nepractică, este utilizarea GPS-ului . Cu toate acestea, rețineți că GPS-ul funcționează prost în interior, în care multitudinea de pereți, alte semnale și alte obstacole fac ravagii în precizia GPS-ului.
Abordarea noastră este, în schimb, să folosim toate rețelele WiFi din raza de acțiune, chiar și cele la care telefonul dvs. nu este conectat. Iată cum: luați în considerare puterea WiFi A în bucătărie; spuneți că este 5. Deoarece există un perete între bucătărie și dormitor, ne putem aștepta în mod rezonabil ca puterea WiFi A în dormitor să difere; spunem că este 2. Putem exploata această diferență pentru a prezice în ce cameră ne aflăm. În plus: rețeaua WiFi B de la vecinul nostru poate fi detectată doar din camera de zi, dar este efectiv invizibilă din bucătărie. Asta face predicția și mai ușoară. În concluzie, lista tuturor WiFi-urilor din raza de acțiune ne oferă informații abundente.
Această metodă are avantajele distincte:
- nu necesită mai mult hardware;
- bazându-se pe semnale mai stabile, cum ar fi WiFi;
- funcționează bine acolo unde alte tehnici precum GPS-ul sunt slabe.
Cu cât sunt mai mulți pereți, cu atât mai bine, cu cât puterile rețelei WiFi sunt mai disparate, cu atât camerele sunt mai ușor de clasificat. Veți construi o aplicație desktop simplă care colectează date, învață din date și prezice în ce cameră vă aflați la un moment dat.
Citiți suplimentare despre SmashingMag:
- Ascensiunea interfeței de utilizare inteligentă conversațională
- Aplicații ale învățării automate pentru designeri
- Cum să prototipați experiențe IoT: construirea hardware-ului
- Proiectare pentru internetul lucrurilor emoționale
Cerințe preliminare
Pentru acest tutorial, veți avea nevoie de un Mac OSX. În timp ce codul se poate aplica oricărei platforme, vom oferi doar instrucțiuni de instalare a dependenței pentru Mac.
- Mac OS X
- Homebrew, un manager de pachete pentru Mac OSX. Pentru a instala, copiați și lipiți comanda de la brew.sh
- Instalarea NodeJS 10.8.0+ și npm
- Instalarea Python 3.6+ și pip. Consultați primele 3 secțiuni din „Cum se instalează virtualenv, Instalarea cu pip și gestionarea pachetelor”
Pasul 0: Configurați mediul de lucru
Aplicația dvs. desktop va fi scrisă în NodeJS. Cu toate acestea, pentru a folosi biblioteci de calcul mai eficiente, cum ar fi numpy , codul de antrenament și predicție va fi scris în Python. Pentru a începe, vă vom configura mediile și vă vom instala dependențe. Creați un director nou pentru a vă găzdui proiectul.
mkdir ~/riotNavigați în director.
cd ~/riotUtilizați pip pentru a instala managerul de mediu virtual implicit al Python.
sudo pip install virtualenv Creați un mediu virtual Python3.6 numit riot .
virtualenv riot --python=python3.6Activați mediul virtual.
source riot/bin/activate Solicitarea dvs. este acum precedată de (riot) . Aceasta indică că am intrat cu succes în mediul virtual. Instalați următoarele pachete folosind pip :
-
numpy: O bibliotecă de algebră liniară eficientă -
scipy: O bibliotecă de calcul științific care implementează modele populare de învățare automată
pip install numpy==1.14.3 scipy ==1.1.0Odată cu configurarea directorului de lucru, vom începe cu o aplicație desktop care înregistrează toate rețelele WiFi din rază. Aceste înregistrări vor constitui date de antrenament pentru modelul dvs. de învățare automată. Odată ce avem date la îndemână, veți scrie un clasificator cu cele mai mici pătrate, antrenat pe semnalele WiFi colectate mai devreme. În cele din urmă, vom folosi modelul celor mai mici pătrate pentru a prezice camera în care vă aflați, pe baza rețelelor WiFi din raza de acțiune.
Pasul 1: Aplicația desktop inițială
În acest pas, vom crea o nouă aplicație desktop folosind Electron JS. Pentru început, vom avea în schimb managerul de pachete Node npm și un utilitar de descărcare wget .
brew install npm wgetPentru început, vom crea un nou proiect Node.
npm init Aceasta vă solicită numele pachetului și apoi numărul versiunii. Apăsați ENTER pentru a accepta numele implicit al riot și versiunea implicită a 1.0.0 .
package name: (riot) version: (1.0.0) Aceasta vă solicită o descriere a proiectului. Adăugați orice descriere care nu este goală pe care doriți. Mai jos, descrierea este room detector
description: room detector Aceasta vă solicită punctul de intrare sau fișierul principal din care rulați proiectul. Introduceți app.js
entry point: (index.js) app.js Acest lucru vă solicită test command și git repository . Apăsați ENTER pentru a sări peste aceste câmpuri pentru moment.
test command: git repository: Aceasta vă solicită keywords și author . Completați toate valorile pe care le doriți. Mai jos, folosim iot , wifi pentru cuvintele cheie și folosim John Doe pentru autor.
keywords: iot,wifi author: John Doe Acest lucru vă solicită să obțineți licența. Apăsați ENTER pentru a accepta valoarea implicită a ISC .
license: (ISC) În acest moment, npm vă va solicita un rezumat al informațiilor de până acum. Ieșirea dvs. ar trebui să fie similară cu următoarea.
{ "name": "riot", "version": "1.0.0", "description": "room detector", "main": "app.js", "scripts": { "test": "echo \"Error: no test specified\" && exit 1" }, "keywords": [ "iot", "wifi" ], "author": "John Doe", "license": "ISC" } Apăsați ENTER pentru a accepta. npm produce apoi un package.json . Listați toate fișierele de verificat.
lsAcesta va scoate singurul fișier din acest director, împreună cu folderul de mediu virtual.
package.json riotInstalați dependențe NodeJS pentru proiectul nostru.
npm install electron --global # makes electron binary accessible globally npm install node-wifi --save Începeți cu main.js de la Electron Quick Start, prin descărcarea fișierului, folosind cele de mai jos. Următorul argument -O redenumește main.js în app.js .
wget https://raw.githubusercontent.com/electron/electron-quick-start/master/main.js -O app.js Deschideți app.js în nano sau editorul de text preferat.
nano app.js Pe linia 12, schimbați index.html în static/index.html , deoarece vom crea un director static care să conțină toate șabloanele HTML.
function createWindow () { // Create the browser window. win = new BrowserWindow({width: 1200, height: 800}) // and load the index.html of the app. win.loadFile('static/index.html') // Open the DevTools. Salvați modificările și ieșiți din editor. Fișierul dvs. ar trebui să se potrivească cu codul sursă al fișierului app.js Acum creați un nou director pentru a găzdui șabloanele noastre HTML.
mkdir staticDescărcați o foaie de stil creată pentru acest proiect.
wget https://raw.githubusercontent.com/alvinwan/riot/master/static/style.css?token=AB-ObfDtD46ANlqrObDanckTQJ2Q1Pyuks5bf79PwA%3D%3D -O static/style.css Deschideți static/index.html în nano sau editorul de text preferat. Începeți cu structura standard HTML.
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title>Riot | Room Detector</title> </head> <body> <main> </main> </body> </html>Imediat după titlu, conectați fontul Montserrat legat de Fonturi Google și foaia de stil.
<title>Riot | Room Detector</title> <!-- start new code --> <link href="https://fonts.googleapis.com/css?family=Montserrat:400,700" rel="stylesheet"> <link href="style.css" rel="stylesheet"> <!-- end new code --> </head> Între etichetele main , adăugați un spațiu pentru numele prevăzut pentru cameră.
<main> <!-- start new code --> <p class="text">I believe you're in the</p> <h1 class="title">(I dunno)</h1> <!-- end new code --> </main>Scriptul dvs. ar trebui acum să se potrivească exact cu următoarele. Ieși din editor.
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title>Riot | Room Detector</title> <link href="https://fonts.googleapis.com/css?family=Montserrat:400,700" rel="stylesheet"> <link href="style.css" rel="stylesheet"> </head> <body> <main> <p class="text">I believe you're in the</p> <h1 class="title">(I dunno)</h1> </main> </body> </html>Acum, modificați fișierul pachetului pentru a conține o comandă de pornire.
nano package.json Imediat după linia 7, adăugați o comandă de start care are alias la electron . . Asigurați-vă că adăugați o virgulă la sfârșitul rândului precedent.
"scripts": { "test": "echo \"Error: no test specified\" && exit 1", "start": "electron ." }, Salvează și ieși. Acum sunteți gata să lansați aplicația desktop în Electron JS. Utilizați npm pentru a vă lansa aplicația.
npm startAplicația dvs. desktop ar trebui să se potrivească cu următoarele.

Acest lucru completează pornirea aplicației desktop. Pentru a ieși, navigați înapoi la terminal și CTRL+C. În pasul următor, vom înregistra rețelele wifi și vom face utilitarul de înregistrare accesibil prin interfața de utilizare a aplicației desktop.
Pasul 2: Înregistrați rețelele WiFi
În acest pas, veți scrie un script NodeJS care înregistrează puterea și frecvența tuturor rețelelor wifi din raza de acțiune. Creați un director pentru scripturile dvs.
mkdir scripts Deschideți scripts/observe.js în nano sau editorul de text preferat.
nano scripts/observe.jsImportați un utilitar wifi NodeJS și obiectul sistemului de fișiere.
var wifi = require('node-wifi'); var fs = require('fs'); Definiți o funcție de record care acceptă un handler de finalizare.
/** * Uses a recursive function for repeated scans, since scans are asynchronous. */ function record(n, completion, hook) { } În noua funcție, inițializați utilitarul wifi. Setați iface la null pentru a se inițializa la o interfață wifi aleatorie, deoarece această valoare este în prezent irelevantă.
function record(n, completion, hook) { wifi.init({ iface : null }); }Definiți o matrice care să conțină mostrele dvs. Eșantioanele sunt date de antrenament pe care le vom folosi pentru modelul nostru. Exemplele din acest tutorial special sunt liste de rețele wifi în raza de acțiune și punctele forte, frecvențele, numele etc. asociate acestora.
function record(n, completion, hook) { ... samples = [] } Definiți o funcție recursivă startScan , care va iniția în mod asincron scanări wifi. După finalizare, scanarea wifi asincronă va invoca recursiv startScan .
function record(n, completion, hook) { ... function startScan(i) { wifi.scan(function(err, networks) { }); } startScan(n); } În wifi.scan , verificați dacă există erori sau liste goale de rețele și reporniți scanarea dacă da.
wifi.scan(function(err, networks) { if (err || networks.length == 0) { startScan(i); return } });Adăugați cazul de bază al funcției recursive, care invocă handlerul de completare.
wifi.scan(function(err, networks) { ... if (i <= 0) { return completion({samples: samples}); } });Produceți o actualizare de progres, adăugați la lista de mostre și efectuați apelul recursiv.
wifi.scan(function(err, networks) { ... hook(n-i+1, networks); samples.push(networks); startScan(i-1); }); La sfârșitul fișierului, invocați funcția de record cu un apel invers care salvează mostre pe un fișier de pe disc.
function record(completion) { ... } function cli() { record(1, function(data) { fs.writeFile('samples.json', JSON.stringify(data), 'utf8', function() {}); }, function(i, networks) { console.log(" * [INFO] Collected sample " + (21-i) + " with " + networks.length + " networks"); }) } cli();Verificați de două ori dacă fișierul dvs. se potrivește cu următoarele:
var wifi = require('node-wifi'); var fs = require('fs'); /** * Uses a recursive function for repeated scans, since scans are asynchronous. */ function record(n, completion, hook) { wifi.init({ iface : null // network interface, choose a random wifi interface if set to null }); samples = [] function startScan(i) { wifi.scan(function(err, networks) { if (err || networks.length == 0) { startScan(i); return } if (i <= 0) { return completion({samples: samples}); } hook(n-i+1, networks); samples.push(networks); startScan(i-1); }); } startScan(n); } function cli() { record(1, function(data) { fs.writeFile('samples.json', JSON.stringify(data), 'utf8', function() {}); }, function(i, networks) { console.log(" * [INFO] Collected sample " + i + " with " + networks.length + " networks"); }) } cli();Salvează și ieși. Rulați scriptul.
node scripts/observe.jsIeșirea dvs. se va potrivi cu următoarele, cu un număr variabil de rețele.
* [INFO] Collected sample 1 with 39 networks Examinați mostrele care tocmai au fost colectate. Pipe la json_pp pentru a imprima destul de JSON și pipe pentru a vedea primele 16 linii.
cat samples.json | json_pp | head -16Mai jos este un exemplu de ieșire pentru o rețea de 2,4 GHz.
{ "samples": [ [ { "mac": "64:0f:28:79:9a:29", "bssid": "64:0f:28:79:9a:29", "ssid": "SMASHINGMAGAZINEROCKS", "channel": 4, "frequency": 2427, "signal_level": "-91", "security": "WPA WPA2", "security_flags": [ "(PSK/AES,TKIP/TKIP)", "(PSK/AES,TKIP/TKIP)" ] },Aceasta încheie scriptul dvs. de scanare wifi NodeJS. Acest lucru ne permite să vedem toate rețelele WiFi din raza de acțiune. În pasul următor, veți face acest script accesibil din aplicația desktop.
Pasul 3: Conectați Scriptul de scanare la aplicația desktop
În acest pas, mai întâi veți adăuga un buton la aplicația desktop pentru a declanșa scriptul. Apoi, veți actualiza interfața de utilizare a aplicației desktop cu progresul scriptului.
Deschideți static/index.html .
nano static/index.htmlIntroduceți butonul „Adăugați”, așa cum se arată mai jos.
<h1 class="title">(I dunno)</h1> <!-- start new code --> <div class="buttons"> <a href="add.html" class="button">Add new room</a> </div> <!-- end new code --> </main> Salvează și ieși. Deschideți static/add.html .
nano static/add.htmlLipiți următorul conținut.
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title>Riot | Add New Room</title> <link href="https://fonts.googleapis.com/css?family=Montserrat:400,700" rel="stylesheet"> <link href="style.css" rel="stylesheet"> </head> <body> <main> <h1 class="title">0</h1> <p class="subtitle">of <span>20</span> samples needed. Feel free to move around the room.</p> <input type="text" class="text-field" placeholder="(room name)"> <div class="buttons"> <a href="#" class="button">Start recording</a> <a href="index.html" class="button light">Cancel</a> </div> <p class="text"></p> </main> <script> require('../scripts/observe.js') </script> </body> </html> Salvează și ieși. Redeschideți scripts/observe.js .
nano scripts/observe.js Sub funcția cli , definiți o nouă funcție ui .
function cli() { ... } // start new code function ui() { } // end new code cli();Actualizați starea aplicației desktop pentru a indica că funcția a început să ruleze.
function ui() { var room_name = document.querySelector('#add-room-name').value; var status = document.querySelector('#add-status'); var number = document.querySelector('#add-title'); status.style.display = "block" status.innerHTML = "Listening for wifi..." }Partiționați datele în seturi de date de instruire și validare.
function ui() { ... function completion(data) { train_data = {samples: data['samples'].slice(0, 15)} test_data = {samples: data['samples'].slice(15)} var train_json = JSON.stringify(train_data); var test_json = JSON.stringify(test_data); } } Încă în perioada de apel invers de completion , scrieți ambele seturi de date pe disc.
function ui() { ... function completion(data) { ... fs.writeFile('data/' + room_name + '_train.json', train_json, 'utf8', function() {}); fs.writeFile('data/' + room_name + '_test.json', test_json, 'utf8', function() {}); console.log(" * [INFO] Done") status.innerHTML = "Done." } } Invocați record cu apelurile corespunzătoare pentru a înregistra 20 de mostre și a salva mostrele pe disc.
function ui() { ... function completion(data) { ... } record(20, completion, function(i, networks) { number.innerHTML = i console.log(" * [INFO] Collected sample " + i + " with " + networks.length + " networks") }) } În cele din urmă, invocați funcțiile cli și ui acolo unde este cazul. Începeți prin a șterge cli(); apelați în partea de jos a fișierului.
function ui() { ... } cli(); // remove me Verificați dacă obiectul document este accesibil la nivel global. Dacă nu, scriptul este rulat din linia de comandă. În acest caz, invocați funcția cli . Dacă este, scriptul este încărcat din aplicația desktop. În acest caz, legați ascultătorul de clic la funcția ui .
if (typeof document == 'undefined') { cli(); } else { document.querySelector('#start-recording').addEventListener('click', ui) }Salvează și ieși. Creați un director pentru a păstra datele noastre.
mkdir dataLansați aplicația desktop.
npm startVeți vedea următoarea pagină de pornire. Faceți clic pe „Adăugați o cameră”.
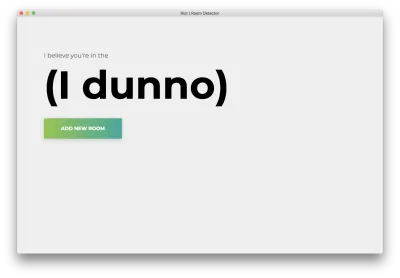
Veți vedea următorul formular. Introduceți un nume pentru cameră. Amintiți-vă acest nume, deoarece îl vom folosi mai târziu. Exemplul nostru va fi bedroom .
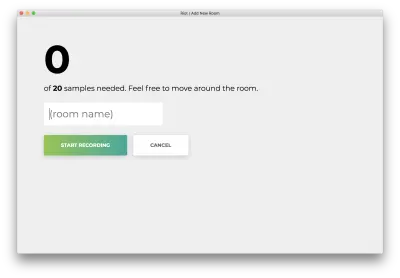
Faceți clic pe „Începe înregistrarea” și veți vedea următoarea stare „Ascult pentru wifi...”.

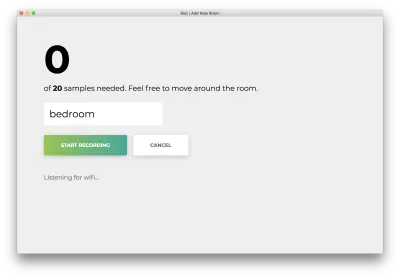
Odată ce toate cele 20 de mostre sunt înregistrate, aplicația dvs. se va potrivi cu următoarele. Starea va indica „Terminat”.
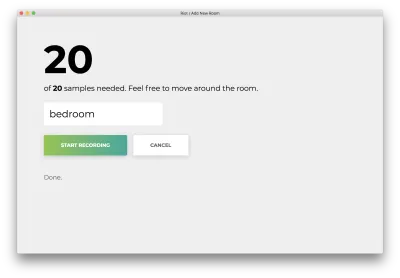
Faceți clic pe „Anulare” denumit greșit pentru a reveni la pagina de pornire, care se potrivește cu următoarele.
Acum putem scana rețelele wifi din interfața de utilizare a desktopului, care va salva toate mostrele înregistrate pe fișiere de pe disc. În continuare, vom antrena un algoritm de învățare automată din cele mai mici pătrate pe datele pe care le-ați colectat.
Pasul 4: Scrieți scriptul de antrenament Python
În acest pas, vom scrie un script de antrenament în Python. Creați un director pentru utilitarele dvs. de antrenament.
mkdir model Deschide model/train.py
nano model/train.py În partea de sus a fișierului, importați biblioteca de calcul numpy și scipy pentru modelul său cu cele mai mici pătrate.
import numpy as np from scipy.linalg import lstsq import json import sysUrmătoarele trei utilitare se vor ocupa de încărcarea și configurarea datelor de pe fișierele de pe disc. Începeți prin adăugarea unei funcții utilitare care aplatizează listele imbricate. Veți folosi acest lucru pentru a aplatiza o listă de eșantioane.
import sys def flatten(list_of_lists): """Flatten a list of lists to make a list. >>> flatten([[1], [2], [3, 4]]) [1, 2, 3, 4] """ return sum(list_of_lists, []) Adăugați un al doilea utilitar care încarcă mostre din fișierele specificate. Această metodă elimină faptul că mostrele sunt răspândite pe mai multe fișiere, returnând doar un singur generator pentru toate probele. Pentru fiecare dintre eșantioane, eticheta este indexul fișierului. De exemplu, dacă apelați get_all_samples('a.json', 'b.json') , toate mostrele din a.json vor avea eticheta 0 și toate mostrele din b.json vor avea eticheta 1.
def get_all_samples(paths): """Load all samples from JSON files.""" for label, path in enumerate(paths): with open(path) as f: for sample in json.load(f)['samples']: signal_levels = [ network['signal_level'].replace('RSSI', '') or 0 for network in sample] yield [network['mac'] for network in sample], signal_levels, labelApoi, adăugați un utilitar care codifică eșantioanele folosind un model tip sac de cuvinte. Iată un exemplu: Să presupunem că colectăm două mostre.
- rețeaua wifi A la puterea 10 și rețeaua wifi B la puterea 15
- rețeaua wifi B la puterea 20 și rețeaua wifi C la puterea 25.
Această funcție va produce o listă de trei numere pentru fiecare dintre eșantioane: prima valoare este puterea rețelei wifi A, a doua pentru rețeaua B și a treia pentru C. De fapt, formatul este [A, B, C ].
- [10, 15, 0]
- [0, 20, 25]
def bag_of_words(all_networks, all_strengths, ordering): """Apply bag-of-words encoding to categorical variables. >>> samples = bag_of_words( ... [['a', 'b'], ['b', 'c'], ['a', 'c']], ... [[1, 2], [2, 3], [1, 3]], ... ['a', 'b', 'c']) >>> next(samples) [1, 2, 0] >>> next(samples) [0, 2, 3] """ for networks, strengths in zip(all_networks, all_strengths): yield [strengths[networks.index(network)] if network in networks else 0 for network in ordering] Folosind toate cele trei utilități de mai sus, sintetizăm o colecție de mostre și etichetele acestora. Adunați toate mostrele și etichetele folosind get_all_samples . Definiți o ordering de format consecventă pentru a codifica toate mostrele one-hot, apoi aplicați codarea one_hot la mostre. În cele din urmă, construiți matricele de date și etichete X și respectiv Y
def create_dataset(classpaths, ordering=None): """Create dataset from a list of paths to JSON files.""" networks, strengths, labels = zip(*get_all_samples(classpaths)) if ordering is None: ordering = list(sorted(set(flatten(networks)))) X = np.array(list(bag_of_words(networks, strengths, ordering))).astype(np.float64) Y = np.array(list(labels)).astype(np.int) return X, Y, orderingAceste funcții completează conducta de date. În continuare, retragem predicția și evaluarea modelului. Începeți prin a defini metoda de predicție. Prima funcție normalizează rezultatele modelului nostru, astfel încât suma tuturor valorilor să fie totală la 1 și că toate valorile sunt nenegative; aceasta asigură că rezultatul este o distribuție de probabilitate validă. Al doilea evaluează modelul.
def softmax(x): """Convert one-hotted outputs into probability distribution""" x = np.exp(x) return x / np.sum(x) def predict(X, w): """Predict using model parameters""" return np.argmax(softmax(X.dot(w)), axis=1)Apoi, evaluați acuratețea modelului. Prima linie rulează predicția folosind modelul. Al doilea numără de câte ori sunt de acord atât valorile prezise, cât și cele adevărate, apoi se normalizează cu numărul total de eșantioane.
def evaluate(X, Y, w): """Evaluate model w on samples X and labels Y.""" Y_pred = predict(X, w) accuracy = (Y == Y_pred).sum() / X.shape[0] return accuracy Aceasta încheie utilitățile noastre de predicție și evaluare. După aceste utilitare, definiți o funcție main care va colecta setul de date, va instrui și va evalua. Începeți prin a citi lista de argumente din linia de comandă sys.argv ; acestea sunt sălile de inclus în antrenament. Apoi creați un set de date mare din toate camerele specificate.
def main(): classes = sys.argv[1:] train_paths = sorted(['data/{}_train.json'.format(name) for name in classes]) test_paths = sorted(['data/{}_test.json'.format(name) for name in classes]) X_train, Y_train, ordering = create_dataset(train_paths) X_test, Y_test, _ = create_dataset(test_paths, ordering=ordering)Aplicați codificare one-hot la etichete. O codificare one-hot este similară cu modelul sac de cuvinte de mai sus; folosim această codificare pentru a gestiona variabilele categoriale. Să presupunem că avem 3 etichete posibile. În loc să etichetăm 1, 2 sau 3, etichetăm datele cu [1, 0, 0], [0, 1, 0] sau [0, 0, 1]. Pentru acest tutorial, vom scuti explicația pentru ce este importantă codificarea one-hot. Antrenați modelul și evaluați atât pe tren, cât și pe seturile de validare.
def main(): ... X_test, Y_test, _ = create_dataset(test_paths, ordering=ordering) Y_train_oh = np.eye(len(classes))[Y_train] w, _, _, _ = lstsq(X_train, Y_train_oh) train_accuracy = evaluate(X_train, Y_train, w) test_accuracy = evaluate(X_test, Y_test, w)Imprimați ambele precizie și salvați modelul pe disc.
def main(): ... print('Train accuracy ({}%), Validation accuracy ({}%)'.format(train_accuracy*100, test_accuracy*100)) np.save('w.npy', w) np.save('ordering.npy', np.array(ordering)) sys.stdout.flush() La sfârșitul fișierului, rulați funcția main .
if __name__ == '__main__': main()Salvează și ieși. Verificați de două ori dacă fișierul dvs. se potrivește cu următoarele:
import numpy as np from scipy.linalg import lstsq import json import sys def flatten(list_of_lists): """Flatten a list of lists to make a list. >>> flatten([[1], [2], [3, 4]]) [1, 2, 3, 4] """ return sum(list_of_lists, []) def get_all_samples(paths): """Load all samples from JSON files.""" for label, path in enumerate(paths): with open(path) as f: for sample in json.load(f)['samples']: signal_levels = [ network['signal_level'].replace('RSSI', '') or 0 for network in sample] yield [network['mac'] for network in sample], signal_levels, label def bag_of_words(all_networks, all_strengths, ordering): """Apply bag-of-words encoding to categorical variables. >>> samples = bag_of_words( ... [['a', 'b'], ['b', 'c'], ['a', 'c']], ... [[1, 2], [2, 3], [1, 3]], ... ['a', 'b', 'c']) >>> next(samples) [1, 2, 0] >>> next(samples) [0, 2, 3] """ for networks, strengths in zip(all_networks, all_strengths): yield [int(strengths[networks.index(network)]) if network in networks else 0 for network in ordering] def create_dataset(classpaths, ordering=None): """Create dataset from a list of paths to JSON files.""" networks, strengths, labels = zip(*get_all_samples(classpaths)) if ordering is None: ordering = list(sorted(set(flatten(networks)))) X = np.array(list(bag_of_words(networks, strengths, ordering))).astype(np.float64) Y = np.array(list(labels)).astype(np.int) return X, Y, ordering def softmax(x): """Convert one-hotted outputs into probability distribution""" x = np.exp(x) return x / np.sum(x) def predict(X, w): """Predict using model parameters""" return np.argmax(softmax(X.dot(w)), axis=1) def evaluate(X, Y, w): """Evaluate model w on samples X and labels Y.""" Y_pred = predict(X, w) accuracy = (Y == Y_pred).sum() / X.shape[0] return accuracy def main(): classes = sys.argv[1:] train_paths = sorted(['data/{}_train.json'.format(name) for name in classes]) test_paths = sorted(['data/{}_test.json'.format(name) for name in classes]) X_train, Y_train, ordering = create_dataset(train_paths) X_test, Y_test, _ = create_dataset(test_paths, ordering=ordering) Y_train_oh = np.eye(len(classes))[Y_train] w, _, _, _ = lstsq(X_train, Y_train_oh) train_accuracy = evaluate(X_train, Y_train, w) validation_accuracy = evaluate(X_test, Y_test, w) print('Train accuracy ({}%), Validation accuracy ({}%)'.format(train_accuracy*100, validation_accuracy*100)) np.save('w.npy', w) np.save('ordering.npy', np.array(ordering)) sys.stdout.flush() if __name__ == '__main__': main() Salvează și ieși. Amintiți-vă numele camerei folosit mai sus atunci când înregistrați cele 20 de mostre. Folosește acest nume în loc de bedroom de mai jos. Exemplul nostru este bedroom . Folosim -W ignore pentru a ignora avertismentele de la o eroare LAPACK.
python -W ignore model/train.py bedroomDeoarece am colectat doar mostre de antrenament pentru o singură cameră, ar trebui să vedeți 100% precizie de instruire și validare.
Train accuracy (100.0%), Validation accuracy (100.0%)În continuare, vom conecta acest script de antrenament la aplicația desktop.
Pasul 5: Link Train Script
În acest pas, vom reinstrui automat modelul ori de câte ori utilizatorul colectează un nou lot de mostre. Deschideți scripts/observe.js .
nano scripts/observe.js Imediat după importul fs , importați generatorul de generare a procesului copil și utilitățile.
var fs = require('fs'); // start new code const spawn = require("child_process").spawn; var utils = require('./utils.js'); În funcția ui , adăugați următorul apel pentru retrain la sfârșitul handler-ului de finalizare.
function ui() { ... function completion() { ... retrain((data) => { var status = document.querySelector('#add-status'); accuracies = data.toString().split('\n')[0]; status.innerHTML = "Retraining succeeded: " + accuracies }); } ... } După funcția ui , adăugați următoarea funcție de retrain . Acest lucru generează un proces copil care va rula scriptul Python. La finalizare, procesul apelează un handler de finalizare. La eșec, va înregistra mesajul de eroare.
function ui() { .. } function retrain(completion) { var filenames = utils.get_filenames() const pythonProcess = spawn('python', ["./model/train.py"].concat(filenames)); pythonProcess.stdout.on('data', completion); pythonProcess.stderr.on('data', (data) => { console.log(" * [ERROR] " + data.toString()) }) } Salvează și ieși. Deschideți scripts/utils.js .
nano scripts/utils.js Adăugați următorul utilitar pentru a prelua toate seturile de date din data/ .
var fs = require('fs'); module.exports = { get_filenames: get_filenames } function get_filenames() { filenames = new Set([]); fs.readdirSync("data/").forEach(function(filename) { filenames.add(filename.replace('_train', '').replace('_test', '').replace('.json', '' )) }); filenames = Array.from(filenames.values()) filenames.sort(); filenames.splice(filenames.indexOf('.DS_Store'), 1) return filenames }Salvează și ieși. Pentru încheierea acestui pas, mutați-vă fizic într-o nouă locație. În mod ideal, ar trebui să existe un zid între locația inițială și noua locație. Cu cât sunt mai multe bariere, cu atât mai bine va funcționa aplicația pentru desktop.
Încă o dată, rulați aplicația desktop.
npm startLa fel ca și înainte, rulați scriptul de antrenament. Faceți clic pe „Adăugați o cameră”.
Introduceți un nume de cameră diferit de cel al primei camere. Vom folosi living room .
Faceți clic pe „Începe înregistrarea” și veți vedea următoarea stare „Ascult pentru wifi...”.
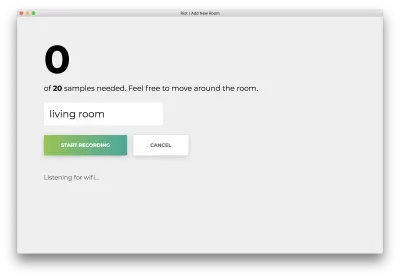
Odată ce toate cele 20 de mostre sunt înregistrate, aplicația dvs. se va potrivi cu următoarele. Starea va fi „Terminat. Model de recalificare…”
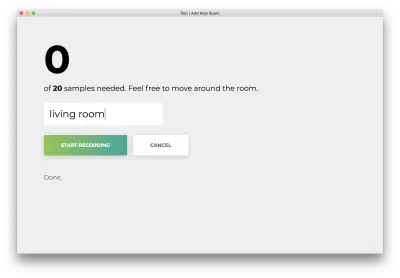
În pasul următor, vom folosi acest model reantrenat pentru a prezice încăperea în care vă aflați, din mers.
Pasul 6: Scrieți Scriptul de evaluare Python
În acest pas, vom încărca parametrii modelului preantrenați, vom căuta rețele wifi și vom prezice camera pe baza scanării.
Deschide model/eval.py .
nano model/eval.pyImportă biblioteci utilizate și definite în ultimul nostru script.
import numpy as np import sys import json import os import json from train import predict from train import softmax from train import create_dataset from train import evaluate Definiți un utilitar pentru a extrage numele tuturor seturilor de date. Această funcție presupune că toate seturile de date sunt stocate în data/ ca <dataset>_train.json și <dataset>_test.json .
from train import evaluate def get_datasets(): """Extract dataset names.""" return sorted(list({path.split('_')[0] for path in os.listdir('./data') if '.DS' not in path})) Definiți funcția main și începeți prin a încărca parametrii salvați din scriptul de antrenament.
def get_datasets(): ... def main(): w = np.load('w.npy') ordering = np.load('ordering.npy')Creați setul de date și preziceți.
def main(): ... classpaths = [sys.argv[1]] X, _, _ = create_dataset(classpaths, ordering) y = np.asscalar(predict(X, w))Calculați un scor de încredere bazat pe diferența dintre primele două probabilități.
def main(): ... sorted_y = sorted(softmax(X.dot(w)).flatten()) confidence = 1 if len(sorted_y) > 1: confidence = round(sorted_y[-1] - sorted_y[-2], 2) În cele din urmă, extrageți categoria și imprimați rezultatul. Pentru a încheia scriptul, invocați funcția main .
def main() ... category = get_datasets()[y] print(json.dumps({"category": category, "confidence": confidence})) if __name__ == '__main__': main()Salvează și ieși. Verificați din nou codul dvs. se potrivește cu următoarele (codul sursă):
import numpy as np import sys import json import os import json from train import predict from train import softmax from train import create_dataset from train import evaluate def get_datasets(): """Extract dataset names.""" return sorted(list({path.split('_')[0] for path in os.listdir('./data') if '.DS' not in path})) def main(): w = np.load('w.npy') ordering = np.load('ordering.npy') classpaths = [sys.argv[1]] X, _, _ = create_dataset(classpaths, ordering) y = np.asscalar(predict(X, w)) sorted_y = sorted(softmax(X.dot(w)).flatten()) confidence = 1 if len(sorted_y) > 1: confidence = round(sorted_y[-1] - sorted_y[-2], 2) category = get_datasets()[y] print(json.dumps({"category": category, "confidence": confidence})) if __name__ == '__main__': main()În continuare, vom conecta acest script de evaluare la aplicația desktop. Aplicația desktop va rula în mod continuu scanări wifi și va actualiza interfața de utilizare cu camera prevăzută.
Pasul 7: Conectați evaluarea la aplicația desktop
În acest pas, vom actualiza interfața de utilizare cu un afișaj de „încredere”. Apoi, scriptul NodeJS asociat va rula continuu scanări și predicții, actualizând interfața de utilizare în consecință.
Deschideți static/index.html .
nano static/index.htmlAdăugați o linie pentru încredere imediat după titlu și înaintea butoanelor.
<h1 class="title">(I dunno)</h1> <!-- start new code --> <p class="subtitle">with <span>0%</span> confidence</p> <!-- end new code --> <div class="buttons"> Imediat după main , dar înainte de sfârșitul body , adăugați un nou script predict.js .
</main> <!-- start new code --> <script> require('../scripts/predict.js') </script> <!-- end new code --> </body> Salvează și ieși. Deschideți scripts/predict.js .
nano scripts/predict.jsImportați utilitarele NodeJS necesare pentru sistemul de fișiere, utilitare și generatorul de procese copil.
var fs = require('fs'); var utils = require('./utils'); const spawn = require("child_process").spawn; Definiți o funcție de predict care invocă un proces de nod separat pentru a detecta rețelele wifi și un proces Python separat pentru a prezice camera.
function predict(completion) { const nodeProcess = spawn('node', ["scripts/observe.js"]); const pythonProcess = spawn('python', ["-W", "ignore", "./model/eval.py", "samples.json"]); }După ce ambele procese au apărut, adăugați apeluri inverse la procesul Python atât pentru succese, cât și pentru erori. Reapelarea de succes înregistrează informații, invocă apelul de finalizare și actualizează interfața de utilizare cu predicție și încredere. Eroarea apel invers înregistrează eroarea.
function predict(completion) { ... pythonProcess.stdout.on('data', (data) => { information = JSON.parse(data.toString()); console.log(" * [INFO] Room '" + information.category + "' with confidence '" + information.confidence + "'") completion() if (typeof document != "undefined") { document.querySelector('#predicted-room-name').innerHTML = information.category document.querySelector('#predicted-confidence').innerHTML = information.confidence } }); pythonProcess.stderr.on('data', (data) => { console.log(data.toString()); }) } Definiți o funcție principală pentru a invoca funcția de predict recursiv, pentru totdeauna.
function main() { f = function() { predict(f) } predict(f) } main();Pentru ultima dată, deschideți aplicația desktop pentru a vedea predicția live.
npm startAproximativ în fiecare secundă, o scanare va fi finalizată, iar interfața va fi actualizată cu cea mai recentă încredere și cameră prevăzută. Felicitări; ați completat un detector de cameră simplu bazat pe toate rețelele WiFi din raza de acțiune.
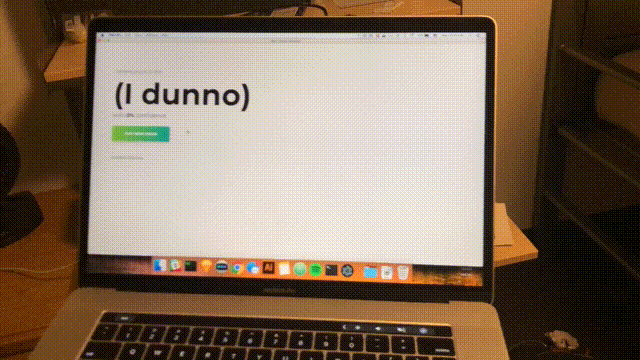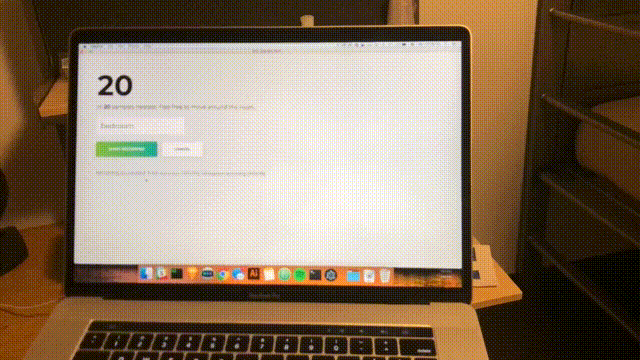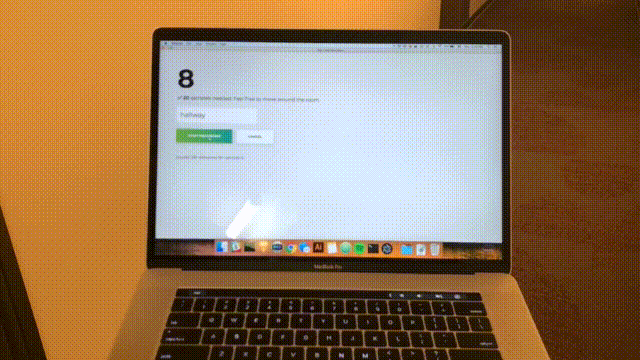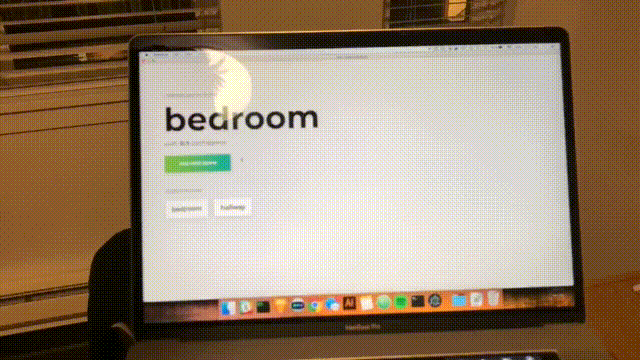
Concluzie
În acest tutorial, am creat o soluție folosind doar desktopul pentru a vă detecta locația într-o clădire. Am creat o aplicație desktop simplă folosind Electron JS și am aplicat o metodă simplă de învățare automată pe toate rețelele WiFi din raza de acțiune. Acest lucru deschide calea pentru aplicațiile Internet-of-things fără a fi nevoie de matrice de dispozitive care sunt costisitoare de întreținut (cost nu în termeni de bani, ci în termeni de timp și dezvoltare).
Notă : Puteți vedea codul sursă în întregime pe Github.
Cu timpul, s-ar putea să descoperi că aceste cele mai mici pătrate nu au performanțe spectaculoase de fapt. Încercați să găsiți două locații într-o singură cameră sau stați în uși. Cele mai mici pătrate vor fi mari, nu vor putea face distincția între cazurile de margine. Putem face mai bine? Se dovedește că putem, iar în lecțiile viitoare, vom folosi alte tehnici și elementele fundamentale ale învățării automate pentru o performanță mai bună. Acest tutorial servește ca un banc de testare rapid pentru experimentele viitoare.