
Construirea unui serviciu central de logare în interior
Publicat: 2022-03-10Știm cu toții cât de importantă este depanarea pentru îmbunătățirea performanței și a caracteristicilor aplicațiilor. BrowserStack rulează un milion de sesiuni pe zi pe o stivă de aplicații foarte distribuită! Fiecare implică mai multe părți în mișcare, deoarece o singură sesiune a unui client poate cuprinde mai multe componente în mai multe regiuni geografice.
Fără cadrul și instrumentele potrivite, procesul de depanare poate fi un coșmar. În cazul nostru, aveam nevoie de o modalitate de a colecta evenimente care au loc în diferite etape ale fiecărui proces, pentru a obține o înțelegere aprofundată a tot ceea ce are loc în timpul unei sesiuni. Cu infrastructura noastră, rezolvarea acestei probleme a devenit complicată, deoarece fiecare componentă ar putea avea mai multe evenimente din ciclul de viață al procesării unei cereri.
De aceea, am dezvoltat propriul nostru instrument intern al Serviciului de înregistrare centrală (CLS) pentru a înregistra toate evenimentele importante înregistrate în timpul unei sesiuni. Aceste evenimente îi ajută pe dezvoltatorii noștri să identifice condițiile în care ceva nu merge bine într-o sesiune și îi ajută să țină evidența anumitor valori cheie ale produsului.
Datele de depanare variază de la lucruri simple, cum ar fi latența de răspuns la API, până la monitorizarea sănătății rețelei unui utilizator. În acest articol, împărtășim povestea noastră despre construirea instrumentului nostru CLS care colectează 70G de date cronologice relevante pe zi de la peste 100 de componente în mod fiabil, la scară și cu două instanțe EC2 M3.large.
Decizia de a construi în casă
În primul rând, să luăm în considerare de ce am construit instrumentul nostru CLS intern, mai degrabă decât să folosim o soluție existentă. Fiecare dintre sesiunile noastre trimite în medie 15 evenimente, de la mai multe componente la serviciu - traducându-se în aproximativ 15 milioane de evenimente totale pe zi.
Serviciul nostru avea nevoie de capacitatea de a stoca toate aceste date. Am căutat o soluție completă pentru a sprijini stocarea, trimiterea și interogarea evenimentelor. Deoarece am luat în considerare soluții terțe, cum ar fi Amplitude și Keen, valorile noastre de evaluare au inclus costul, performanța în gestionarea solicitărilor paralele mari și ușurința de adoptare. Din păcate, nu am putut găsi o potrivire care să îndeplinească toate cerințele noastre în limita bugetului - deși beneficiile ar fi inclus economisirea de timp și minimizarea alertelor. Deși ar fi nevoie de efort suplimentar, am decis să dezvoltăm noi înșine o soluție internă.

Detalii tehnice
În ceea ce privește arhitectura pentru componenta noastră, am subliniat următoarele cerințe de bază:
- Performanța clientului
Nu afectează performanța clientului/componentului care trimite evenimentele. - Scară
Capabil să gestioneze un număr mare de solicitări în paralel. - Performanța serviciului
Procesează rapid toate evenimentele care îi sunt trimise. - Perspectivă asupra datelor
Fiecare eveniment înregistrat trebuie să aibă câteva meta informații pentru a putea identifica în mod unic componenta sau utilizatorul, contul sau mesajul și pentru a oferi mai multe informații pentru a ajuta dezvoltatorul să depaneze mai rapid. - Interfață interogabilă
Dezvoltatorii pot interoga toate evenimentele pentru o anumită sesiune, ajutând la depanarea unei anumite sesiuni, la construirea de rapoarte de sănătate a componentelor sau la generarea de statistici semnificative de performanță ale sistemelor noastre. - Adopție mai rapidă și mai ușoară
Integrare ușoară cu o componentă existentă sau nouă, fără a împovăra echipele și a le ocupa resursele. - Întreținere redusă
Suntem o echipă mică de ingineri, așa că am căutat o soluție pentru a minimiza alertele!
Construirea soluției noastre CLS
Decizia 1: Alegerea unei interfețe pentru expunere
În dezvoltarea CLS, evident că nu am vrut să pierdem niciuna dintre datele noastre, dar nu am vrut nici ca performanța componentelor să fie afectată. Ca să nu mai vorbim de factorul suplimentar de a împiedica componentele existente să devină mai complicate, deoarece ar întârzia adoptarea și lansarea generală. La stabilirea interfeței noastre, am luat în considerare următoarele opțiuni:
- Stocarea evenimentelor în Redis local în fiecare componentă, deoarece un procesor de fundal o împinge în CLS. Cu toate acestea, acest lucru necesită o modificare a tuturor componentelor, împreună cu introducerea Redis pentru componentele care nu îl conțineau deja.
- Un model Editor - Abonat, în care Redis este mai aproape de CLS. Pe măsură ce toată lumea publică evenimente, avem din nou factorul componentelor care rulează pe tot globul. În timpul traficului intens, acest lucru ar întârzia componentele. În plus, această scriere ar putea sări intermitent până la cinci secunde (numai datorită internetului).
- Trimiterea de evenimente prin UDP, care oferă un impact mai mic asupra performanței aplicației. În acest caz datele ar fi trimise și uitate, totuși, dezavantajul ar fi pierderea datelor.
Interesant este că pierderea noastră de date prin UDP a fost mai mică de 0,1 la sută, ceea ce a fost o sumă acceptabilă pentru ca noi să luăm în considerare construirea unui astfel de serviciu. Am reușit să convingem toate echipele că această sumă de pierderi a meritat performanța și am continuat să folosim o interfață UDP care a ascultat toate evenimentele trimise.
Deși un rezultat a fost un impact mai mic asupra performanței unei aplicații, ne-am confruntat cu o problemă, deoarece traficul UDP nu a fost permis din toate rețelele, mai ales de la utilizatorii noștri - determinându-ne în unele cazuri să nu primim deloc date. Ca o soluție, am acceptat înregistrarea evenimentelor folosind solicitări HTTP. Toate evenimentele care vin din partea utilizatorului vor fi trimise prin HTTP, în timp ce toate evenimentele înregistrate din componentele noastre ar fi prin UDP.
Decizia 2: Tech Stack (limbă, cadru și stocare)
Suntem un magazin Ruby. Cu toate acestea, nu eram siguri dacă Ruby ar fi o alegere mai bună pentru problema noastră particulară. Serviciul nostru ar trebui să gestioneze o mulțime de solicitări primite, precum și să proceseze o mulțime de scrieri. Cu blocarea Global Interpreter, realizarea multithreadingului sau a concurenței ar fi dificilă în Ruby (vă rugăm să nu vă supărați - iubim Ruby!). Deci aveam nevoie de o soluție care să ne ajute să obținem acest tip de concurență.
Am fost, de asemenea, dornici să evaluăm o nouă limbă în stiva noastră de tehnologie, iar acest proiect părea perfect pentru a experimenta lucruri noi. Atunci am decis să-i dăm o șansă lui Golang, deoarece oferea suport încorporat pentru concurență și fire ușoare și rutine. Fiecare punct de date înregistrat seamănă cu o pereche cheie-valoare în care „cheie” este evenimentul și „valoare” servește ca valoare asociată.
Dar a avea o cheie și o valoare simplă nu este suficient pentru a prelua date legate de o sesiune - există mai multe metadate pentru aceasta. Pentru a rezolva acest lucru, am decis că orice eveniment care trebuie înregistrat ar avea un ID de sesiune împreună cu cheia și valoarea sa. Am adăugat, de asemenea, câmpuri suplimentare, cum ar fi marca temporală, ID-ul utilizatorului și componenta care înregistrează datele, astfel încât să fie mai ușor de preluat și analizat.

Acum că ne-am hotărât asupra structurii încărcăturii noastre utile, a trebuit să ne alegem depozitul de date. Ne-am gândit la Elastic Search, dar am vrut să acceptăm și solicitările de actualizare pentru chei. Acest lucru ar declanșa reindexarea întregului document, ceea ce ar putea afecta performanța scrierilor noastre. MongoDB a avut mai mult sens ca depozit de date, deoarece ar fi mai ușor să interogați toate evenimentele pe baza oricăruia dintre câmpurile de date care ar fi adăugate. A fost ușor!
Decizia 3: Dimensiunea DB este uriașă, iar interogarea și arhivarea este nasolă!
Pentru a reduce întreținerea, serviciul nostru ar trebui să se ocupe de cât mai multe evenimente. Având în vedere rata cu care BrowserStack lansează funcții și produse, eram siguri că numărul evenimentelor noastre va crește cu rate mai mari în timp, ceea ce înseamnă că serviciul nostru ar trebui să continue să funcționeze bine. Pe măsură ce spațiul crește, citirea și scrierea necesită mai mult timp - ceea ce ar putea fi un impact uriaș asupra performanței serviciului.
Prima soluție pe care am explorat-o a fost mutarea jurnalelor dintr-o anumită perioadă departe de baza de date (în cazul nostru, ne-am hotărât pe 15 zile). Pentru a face acest lucru, am creat o bază de date diferită pentru fiecare zi, permițându-ne să găsim jurnalele mai vechi decât o anumită perioadă, fără a fi nevoie să scanăm toate documentele scrise. Acum eliminăm continuu bazele de date mai vechi de 15 zile din Mongo, păstrând, desigur, copii de rezervă pentru orice eventualitate.
Singura piesă rămasă a fost o interfață de dezvoltator pentru a interoga datele legate de sesiune. Sincer, aceasta a fost cea mai ușor de rezolvat. Oferim o interfață HTTP, în care oamenii pot solicita evenimente legate de sesiune în baza de date corespunzătoare din MongoDB, pentru orice date care au un anumit ID de sesiune.
Arhitectură
Să vorbim despre componentele interne ale serviciului, luând în considerare următoarele puncte:
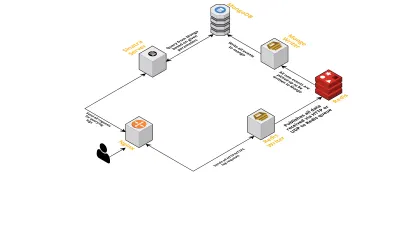
- După cum am discutat anterior, aveam nevoie de două interfețe - una care să asculte prin UDP și alta care să asculte prin HTTP. Așa că am construit două servere, din nou unul pentru fiecare interfață, pentru a asculta evenimente. De îndată ce sosește un eveniment, îl analizăm pentru a verifica dacă are câmpurile necesare - acestea sunt ID-ul sesiunii, cheia și valoarea. Dacă nu, datele sunt eliminate. În caz contrar, datele sunt transmise pe un canal Go către o altă goroutine, a cărei responsabilitate este să scrie în MongoDB.
- O posibilă îngrijorare aici este scrierea către MongoDB. Dacă scrierile în MongoDB sunt mai lente decât datele privind rata sunt primite, acest lucru creează un blocaj. Acest lucru, la rândul său, înfometează alte evenimente primite și înseamnă că datele sunt eliminate. Prin urmare, serverul ar trebui să fie rapid în procesarea jurnalelor de intrare și să fie gata să proceseze pe cele viitoare. Pentru a rezolva problema, am împărțit serverul în două părți: prima primește toate evenimentele și le pune în coadă pentru a doua, care le procesează și le scrie în MongoDB.
- Pentru coadă am ales Redis. Împărțind întreaga componentă în aceste două părți, am redus volumul de lucru al serverului, oferindu-i spațiu pentru a gestiona mai multe jurnaluri.
- Am scris un mic serviciu folosind serverul Sinatra pentru a gestiona toată munca de interogare a MongoDB cu parametrii dați. Returnează un răspuns HTML/JSON dezvoltatorilor atunci când au nevoie de informații despre o anumită sesiune.
Toate aceste procese rulează fericit pe o singură instanță m3.large .
Cereri de caracteristici
Pe măsură ce instrumentul nostru CLS a fost mai utilizat de-a lungul timpului, avea nevoie de mai multe funcții. Mai jos, discutăm despre acestea și despre cum au fost adăugate.
Metadatele lipsesc
Treptat, pe măsură ce numărul de componente din BrowserStack crește, am cerut mai mult de la CLS. De exemplu, aveam nevoie de capacitatea de a înregistra evenimente de la componente fără un ID de sesiune. În caz contrar, obținerea unuia ar împovăra infrastructura noastră, sub forma afectării performanței aplicației și a atragerii de trafic pe serverele noastre principale.
Am rezolvat acest lucru activând înregistrarea evenimentelor folosind alte chei, cum ar fi ID-urile de terminal și de utilizator. Acum, ori de câte ori se creează sau se actualizează o sesiune, CLS este informat cu ID-ul sesiunii, precum și cu ID-urile utilizatorului și terminalului respectiv. Stochează o hartă care poate fi preluată prin procesul de scriere în MongoDB. Ori de câte ori un eveniment care conține fie utilizatorul sau ID-ul terminalului este preluat, ID-ul sesiunii este adăugat.
Gestionați spam-ul (probleme de cod în alte componente)
CLS s-a confruntat și cu dificultățile obișnuite în gestionarea evenimentelor de spam. Am găsit adesea implementări în componente care au generat un volum mare de solicitări trimise către CLS. Alte jurnale ar avea de suferit în acest proces, deoarece serverul a devenit prea ocupat pentru a le procesa și au fost abandonate jurnalele importante.
În cea mai mare parte, majoritatea datelor înregistrate au fost prin solicitări HTTP. Pentru a le controla, activăm limitarea ratei pe nginx (folosind modulul limit_req_zone), care blochează cererile de la orice IP pe care am găsit-o care lovesc solicitări mai mult de un anumit număr într-o perioadă mică de timp. Desigur, folosim rapoartele de sănătate pentru toate IP-urile blocate și informăm echipele responsabile.
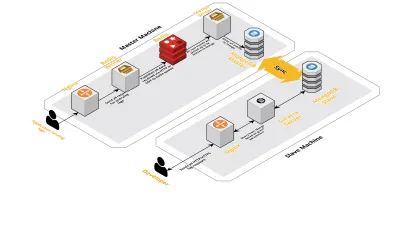
Scară v2
Pe măsură ce sesiunile noastre pe zi au crescut, datele înregistrate în CLS au crescut și ele. Acest lucru a afectat interogările pe care dezvoltatorii noștri rulau zilnic și, în curând, blocajul pe care l-am avut a fost cu mașina în sine. Configurarea noastră a constat din două mașini de bază care rulează toate componentele de mai sus, împreună cu o grămadă de scripturi pentru a interoga Mongo și a ține evidența valorilor cheie pentru fiecare produs. De-a lungul timpului, datele de pe mașină au crescut foarte mult, iar scripturile au început să ia mult timp CPU. Chiar și după ce am încercat să optimizăm interogările Mongo, am revenit mereu la aceleași probleme.
Pentru a rezolva acest lucru, am adăugat o altă mașină pentru rularea scripturilor de rapoarte de sănătate și interfața pentru a interoga aceste sesiuni. Procesul a implicat pornirea unei noi mașini și configurarea unui slave al Mongo care rulează pe mașina principală. Acest lucru a ajutat la reducerea vârfurilor CPU pe care le-am văzut în fiecare zi cauzate de aceste scripturi.
Concluzie
Crearea unui serviciu pentru o sarcină la fel de simplă precum înregistrarea datelor poate deveni complicată, pe măsură ce cantitatea de date crește. Acest articol discută soluțiile pe care le-am explorat, împreună cu provocările cu care se confruntă în rezolvarea acestei probleme. Am experimentat cu Golang pentru a vedea cât de bine s-ar potrivi cu ecosistemul nostru și până acum am fost mulțumiți. Alegerea noastră de a crea un serviciu intern în loc să plătim pentru unul extern a fost extraordinar de eficientă din punct de vedere al costurilor. De asemenea, nu a trebuit să ne extindem configurația la o altă mașină decât mult mai târziu - când volumul sesiunilor noastre a crescut. Desigur, alegerile noastre în dezvoltarea CLS s-au bazat complet pe cerințele și prioritățile noastre.
Astăzi, CLS gestionează până la 15 milioane de evenimente în fiecare zi, constituind până la 70 GB de date. Aceste date sunt folosite pentru a ne ajuta să rezolvăm orice problemă cu care se confruntă clienții noștri în timpul oricărei sesiuni. De asemenea, folosim aceste date în alte scopuri. Având în vedere informațiile oferite de datele fiecărei sesiuni despre diferite produse și componente interne, am început să folosim aceste date pentru a ține evidența fiecărui produs. Acest lucru se realizează prin extragerea valorilor cheie pentru toate componentele importante.
Una peste alta, am observat un mare succes în construirea propriului nostru instrument CLS. Dacă are sens pentru tine, îți recomand să te gândești să faci același lucru!