
Cum să construiți un Amazon Product Scraper cu Node.js
Publicat: 2022-03-10Ați fost vreodată într-o poziție în care trebuie să cunoașteți îndeaproape piața pentru un anumit produs? Poate că lansați un software și trebuie să știți cum să stabiliți prețul acestuia. Sau poate că aveți deja propriul produs pe piață și doriți să vedeți ce caracteristici să adăugați pentru un avantaj competitiv. Sau poate vrei doar să cumperi ceva pentru tine și vrei să te asiguri că obții cel mai bun profit pentru banii tăi.
Toate aceste situații au un lucru în comun: aveți nevoie de date exacte pentru a lua decizia corectă . De fapt, există un alt lucru pe care îl împărtășesc. Toate scenariile pot beneficia de utilizarea unui scraper web.
Web scraping este practica de a extrage cantități mari de date web prin utilizarea unui software. Deci, în esență, este o modalitate de a automatiza procesul plictisitor de a apăsa „copiere” și apoi „lipire” de 200 de ori. Desigur, un bot poate face asta în timpul necesar pentru a citi această propoziție, așa că nu numai că este mai puțin plictisitor, ci și mult mai rapid.
Dar întrebarea arzătoare este: de ce ar vrea cineva să răzuiască paginile Amazon?
Ești pe cale să afli! Dar mai întâi de toate, aș dori să clarific ceva chiar acum - în timp ce actul de a răzui datele disponibile public este legal, Amazon are câteva măsuri pentru a preveni acest lucru pe paginile lor. Ca atare, vă îndemn să fiți întotdeauna atenți la site-ul web în timpul răzuirii, să aveți grijă să nu-l deteriorați și să urmați îndrumările etice.
Lectură recomandată : „Ghidul pentru răzuirea etică a site-urilor web dinamice cu Node.js și Puppeteer” de Andreas Altheimer
De ce ar trebui să extrageți datele despre produse Amazon
Fiind cel mai mare retailer online de pe planetă, este sigur să spunem că dacă vrei să cumperi ceva, probabil că îl poți obține pe Amazon. Deci, este de la sine înțeles cât de mare este o comoară de date site-ul web.
Când răzuiți pe web, întrebarea dvs. principală ar trebui să fie ce să faceți cu toate acele date. Deși există multe motive individuale, aceasta se rezumă la două cazuri de utilizare proeminente: optimizarea produselor și găsirea celor mai bune oferte.
„
Să începem cu primul scenariu. Dacă nu ați conceput un produs nou cu adevărat inovator, sunt șanse să găsiți deja ceva cel puțin similar pe Amazon. Scurtarea acestor pagini de produse vă poate aduce date neprețuite, cum ar fi:
- Strategia de prețuri a concurenților
Așadar, să vă puteți ajusta prețurile pentru a fi competitiv și pentru a înțelege modul în care alții gestionează ofertele promoționale; - Opiniile clienților
Pentru a vedea ce interesează cel mai mult viitorul tău client și cum să le îmbunătățești experiența; - Cele mai comune caracteristici
Pentru a vedea ce oferă concurența pentru a ști ce funcționalități sunt cruciale și care pot fi lăsate pentru mai târziu.
În esență, Amazon are tot ce aveți nevoie pentru o analiză profundă a pieței și a produselor. Veți fi mai bine pregătit să proiectați, lansați și extindeți gama de produse cu acele date.
Al doilea scenariu se poate aplica atât afacerilor, cât și oamenilor obișnuiți. Ideea este destul de asemănătoare cu ceea ce am menționat mai devreme. Puteți analiza prețurile, caracteristicile și recenziile tuturor produselor pe care le-ați putea alege și, astfel, îl veți putea alege pe cel care oferă cele mai multe beneficii la cel mai mic preț. La urma urmei, cui nu-i place o afacere bună?
Nu toate produsele merită acest nivel de atenție la detalii, dar poate face o diferență enormă cu achiziții scumpe. Din păcate, deși beneficiile sunt clare, multe dificultăți vin împreună cu răzuirea Amazon.
Provocările răzuirii datelor despre produse Amazon
Nu toate site-urile web sunt la fel. De regulă, cu cât un site web este mai complex și mai răspândit, cu atât este mai greu să-l răzuiești. Îți amintești când am spus că Amazon era cel mai proeminent site de comerț electronic? Ei bine, asta îl face atât extrem de popular, cât și destul de complex.
În primul rând, Amazon știe cum acționează roboții de scraping, așa că site-ul are măsuri de contracarare. Și anume, dacă scraperul urmează un model previzibil, trimițând cereri la intervale fixe, mai rapid decât ar putea un om sau cu parametri aproape identici, Amazon va observa și va bloca IP-ul. Proxy-urile pot rezolva această problemă, dar nu am avut nevoie de ele, deoarece nu vom elimina prea multe pagini în exemplu.
În continuare, Amazon utilizează în mod deliberat diferite structuri de pagină pentru produsele lor. Adică, dacă inspectați paginile pentru diferite produse, există șanse mari să găsiți diferențe semnificative în structura și atributele acestora. Motivul din spatele acestui lucru este destul de simplu. Trebuie să adaptați codul scraper-ului pentru un anumit sistem și, dacă utilizați același script pe un nou tip de pagină, va trebui să rescrieți părți din acesta. Deci, în esență, te fac să lucrezi mai mult pentru date.
În cele din urmă, Amazon este un site vast. Dacă doriți să adunați cantități mari de date, rularea software-ului de răzuire pe computer s-ar putea dovedi a lua prea mult timp pentru nevoile dvs. Această problemă este consolidată și mai mult de faptul că mersul prea repede îți va bloca racleta. Deci, dacă doriți o mulțime de date rapid, veți avea nevoie de un scraper cu adevărat puternic.
Ei bine, este suficient să vorbim despre probleme, să ne concentrăm pe soluții!
Cum să construiți un răzuitor web pentru Amazon
Pentru a menține lucrurile simple, vom adopta o abordare pas cu pas pentru scrierea codului. Simțiți-vă liber să lucrați în paralel cu ghidul.
Căutați datele de care avem nevoie
Deci, iată un scenariu: mă mut în câteva luni într-un loc nou și voi avea nevoie de câteva rafturi noi pentru a găzdui cărți și reviste. Vreau să știu toate opțiunile mele și să obțin o afacere cât mai bună. Deci, să mergem la piața Amazon, să căutăm „rafturi” și să vedem ce obținem.
Adresa URL pentru această căutare și pagina pe care o vom elimina este aici.
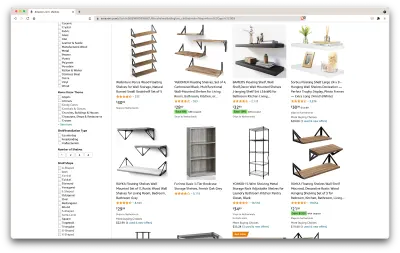
Ok, hai să facem un bilanț al ceea ce avem aici. Doar aruncând o privire pe pagină, putem obține o imagine bună despre:
- cum arată rafturile;
- ce include pachetul;
- cum îi evaluează clienții;
- prețul acestora;
- link-ul către produs;
- o sugestie pentru o alternativă mai ieftină pentru unele dintre articole.
Este mai mult decât am putea cere!
Obțineți instrumentele necesare
Să ne asigurăm că avem toate instrumentele următoare instalate și configurate înainte de a continua cu pasul următor.
- Crom
Îl putem descărca de aici. - VSCode
Urmați instrucțiunile de pe această pagină pentru a o instala pe dispozitivul dvs. - Node.js
Înainte de a începe să folosim Axios sau Cheerio, trebuie să instalăm Node.js și Node Package Manager. Cel mai simplu mod de a instala Node.js și NPM este să obțineți unul dintre programele de instalare din sursa oficială Node.Js și să îl rulați.
Acum, să creăm un nou proiect NPM. Creați un folder nou pentru proiect și rulați următoarea comandă:
npm init -yPentru a crea web scraper, trebuie să instalăm câteva dependențe în proiectul nostru:
- Cheerio
O bibliotecă open-source care ne ajută să extragem informații utile prin analizarea markupurilor și furnizarea unui API pentru manipularea datelor rezultate. Cheerio ne permite să selectăm etichetele unui document HTML utilizând selectori:$("div"). Acest selector specific ne ajută să alegem toate elementele<div>dintr-o pagină. Pentru a instala Cheerio, rulați următoarea comandă în folderul proiectelor:
npm install cheerio- Axios
O bibliotecă JavaScript folosită pentru a face solicitări HTTP de la Node.js.
npm install axiosInspectați sursa paginii
În următorii pași, vom afla mai multe despre cum sunt organizate informațiile pe pagină. Ideea este să înțelegem mai bine ceea ce putem scoate din sursa noastră.
Instrumentele pentru dezvoltatori ne ajută să explorăm în mod interactiv modelul de obiecte document (DOM) al site-ului web. Vom folosi instrumentele pentru dezvoltatori din Chrome, dar puteți folosi orice browser web cu care vă simțiți confortabil.
Să-l deschidem făcând clic dreapta oriunde pe pagină și selectând opțiunea „Inspectați”:
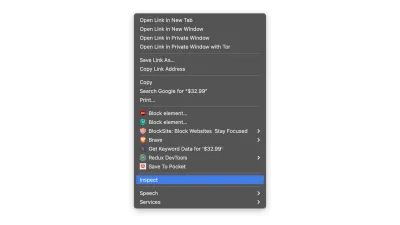
Aceasta va deschide o nouă fereastră care conține codul sursă al paginii. După cum am spus mai devreme, căutăm să curățăm informațiile fiecărui raft.
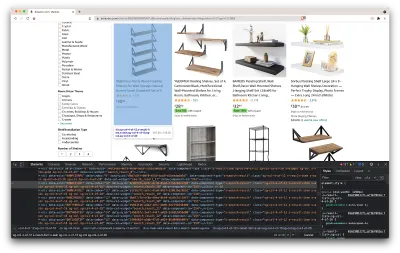
După cum putem vedea din captura de ecran de mai sus, containerele care dețin toate datele au următoarele clase:

sg-col-4-of-12 s-result-item s-asin sg-col-4-of-16 sg-col sg-col-4-of-20În pasul următor, vom folosi Cheerio pentru a selecta toate elementele care conțin datele de care avem nevoie.
Preluați datele
După ce am instalat toate dependențele prezentate mai sus, să creăm un nou fișier index.js și să introducem următoarele linii de cod:
const axios = require("axios"); const cheerio = require("cheerio"); const fetchShelves = async () => { try { const response = await axios.get('https://www.amazon.com/s?crid=36QNR0DBY6M7J&k=shelves&ref=glow_cls&refresh=1&sprefix=s%2Caps%2C309'); const html = response.data; const $ = cheerio.load(html); const shelves = []; $('div.sg-col-4-of-12.s-result-item.s-asin.sg-col-4-of-16.sg-col.sg-col-4-of-20').each((_idx, el) => { const shelf = $(el) const title = shelf.find('span.a-size-base-plus.a-color-base.a-text-normal').text() shelves.push(title) }); return shelves; } catch (error) { throw error; } }; fetchShelves().then((shelves) => console.log(shelves)); După cum putem vedea, importăm dependențele de care avem nevoie pe primele două linii, apoi creăm o fetchShelves() care, folosind Cheerio, obține toate elementele care conțin informațiile produselor noastre din pagină.
Iterează peste fiecare dintre ele și îl împinge într-o matrice goală pentru a obține un rezultat mai bine formatat.
Funcția fetchShelves() va returna doar titlul produsului momentan, așa că haideți să obținem restul informațiilor de care avem nevoie. Vă rugăm să adăugați următoarele rânduri de cod după linia în care am definit title variabilei.
const image = shelf.find('img.s-image').attr('src') const link = shelf.find('aa-link-normal.a-text-normal').attr('href') const reviews = shelf.find('div.a-section.a-spacing-none.a-spacing-top-micro > div.a-row.a-size-small').children('span').last().attr('aria-label') const stars = shelf.find('div.a-section.a-spacing-none.a-spacing-top-micro > div > span').attr('aria-label') const price = shelf.find('span.a-price > span.a-offscreen').text() let element = { title, image, link: `https://amazon.com${link}`, price, } if (reviews) { element.reviews = reviews } if (stars) { element.stars = stars } Și înlocuiți shelves.push(title) cu shelves.push(element) .
Acum selectăm toate informațiile de care avem nevoie și le adăugăm la un nou obiect numit element . Fiecare element este apoi împins în matricea de shelves pentru a obține o listă de obiecte care conține doar datele pe care le căutăm.
Iată cum ar trebui să arate un obiect de shelf înainte de a fi adăugat în lista noastră:
{ title: 'SUPERJARE Wall Mounted Shelves, Set of 2, Display Ledge, Storage Rack for Room/Kitchen/Office - White', image: 'https://m.media-amazon.com/images/I/61fTtaQNPnL._AC_UL320_.jpg', link: 'https://amazon.com/gp/slredirect/picassoRedirect.html/ref=pa_sp_btf_aps_sr_pg1_1?ie=UTF8&adId=A03078372WABZ8V6NFP9L&url=%2FSUPERJARE-Mounted-Floating-Shelves-Display%2Fdp%2FB07H4NRT36%2Fref%3Dsr_1_59_sspa%3Fcrid%3D36QNR0DBY6M7J%26dchild%3D1%26keywords%3Dshelves%26qid%3D1627970918%26refresh%3D1%26sprefix%3Ds%252Caps%252C309%26sr%3D8-59-spons%26psc%3D1&qualifier=1627970918&id=3373422987100422&widgetName=sp_btf', price: '$32.99', reviews: '6,171', stars: '4.7 out of 5 stars' }Formatați datele
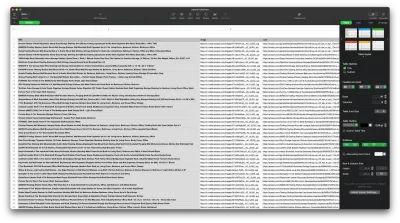
Acum că am reușit să obținem datele de care avem nevoie, este o idee bună să le salvăm ca fișier .CSV pentru a îmbunătăți lizibilitatea. După obținerea tuturor datelor, vom folosi modulul fs furnizat de Node.js și vom salva un nou fișier numit saved-shelves.csv în folderul proiectului. Importați modulul fs din partea de sus a fișierului și copiați sau scrieți de-a lungul următoarelor linii de cod:
let csvContent = shelves.map(element => { return Object.values(element).map(item => `"${item}"`).join(',') }).join("\n") fs.writeFile('saved-shelves.csv', "Title, Image, Link, Price, Reviews, Stars" + '\n' + csvContent, 'utf8', function (err) { if (err) { console.log('Some error occurred - file either not saved or corrupted.') } else{ console.log('File has been saved!') } }) După cum putem vedea, pe primele trei rânduri, formatăm datele pe care le-am adunat anterior unind toate valorile unui obiect de raft folosind o virgulă. Apoi, folosind modulul fs , creăm un fișier numit saved-shelves.csv , adăugăm un nou rând care conține antetele coloanei, adăugăm datele pe care tocmai le-am formatat și creăm o funcție de apel invers care se ocupă de erori.
Rezultatul ar trebui să arate cam așa:
Sfaturi bonus!
Scraping aplicații cu o singură pagină
Conținutul dinamic devine standardul în zilele noastre, deoarece site-urile web sunt mai complexe decât oricând. Pentru a oferi cea mai bună experiență de utilizator posibilă, dezvoltatorii trebuie să adopte diferite mecanisme de încărcare pentru conținutul dinamic , ceea ce face ca munca noastră să fie puțin mai complicată. Dacă nu știți ce înseamnă asta, imaginați-vă un browser lipsit de o interfață grafică de utilizator. Din fericire, există Puppeteer — biblioteca magică Node care oferă un API de nivel înalt pentru a controla o instanță Chrome prin protocolul DevTools. Totuși, oferă aceeași funcționalitate ca un browser, dar trebuie controlat programatic prin tastarea a câteva rânduri de cod. Să vedem cum funcționează.
În proiectul creat anterior, instalați biblioteca Puppeteer rulând npm install puppeteer , creați un nou fișier puppeteer.js și copiați sau scrieți de-a lungul următoarelor linii de cod:
const puppeteer = require('puppeteer') (async () => { try { const chrome = await puppeteer.launch() const page = await chrome.newPage() await page.goto('https://www.reddit.com/r/Kanye/hot/') await page.waitForSelector('.rpBJOHq2PR60pnwJlUyP0', { timeout: 2000 }) const body = await page.evaluate(() => { return document.querySelector('body').innerHTML }) console.log(body) await chrome.close() } catch (error) { console.log(error) } })() În exemplul de mai sus, creăm o instanță Chrome și deschidem o nouă pagină de browser care este necesară pentru a accesa acest link. În rândul următor, îi spunem browserului fără cap să aștepte până când elementul cu clasa rpBJOHq2PR60pnwJlUyP0 apare pe pagină. De asemenea, am specificat cât timp ar trebui să aștepte browserul până se încarcă pagina (2000 milisecunde).
Folosind metoda evaluate pe variabila de page , am instruit Puppeteer să execute fragmentele Javascript în contextul paginii imediat după ce elementul a fost în sfârșit încărcat. Acest lucru ne va permite să accesăm conținutul HTML al paginii și să returnăm corpul paginii ca rezultat. Apoi închidem instanța Chrome apelând metoda close pe variabila chrome . Lucrarea rezultată ar trebui să conțină tot codul HTML generat dinamic. Acesta este modul în care Puppeteer ne poate ajuta să încărcăm conținut HTML dinamic .
Dacă nu vă simțiți confortabil să utilizați Puppeteer, rețineți că există câteva alternative, cum ar fi NightwatchJS, NightmareJS sau CasperJS. Sunt ușor diferite, dar în cele din urmă, procesul este destul de asemănător.
Setarea antetelor user-agent
user-agent este un antet de solicitare care spune despre dvs. site-ul web pe care îl vizitați, și anume browserul și sistemul de operare. Acesta este folosit pentru a optimiza conținutul pentru configurația dvs., dar site-urile îl folosesc și pentru a identifica roboții care trimit o mulțime de solicitări - chiar dacă schimbă IPS.
Iată cum arată un antet user-agent :
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36Pentru a nu fi detectat și blocat, ar trebui să schimbați regulat acest antet. Aveți grijă deosebită să nu trimiteți un antet gol sau învechit, deoarece acest lucru nu ar trebui să se întâmple niciodată pentru un utilizator neobișnuit și veți ieși în evidență.
Limitare de rata
Web scrapers pot aduna conținut extrem de rapid, dar ar trebui să evitați să mergeți cu viteză maximă. Există două motive pentru aceasta:
- Prea multe solicitări în scurt timp pot încetini serverul site-ului sau chiar îl pot opri, cauzând probleme proprietarului și altor vizitatori. În esență, poate deveni un atac DoS.
- Fără rotirea proxy-urilor, este asemănător cu anunțul cu voce tare că utilizați un bot , deoarece niciun om nu ar trimite sute sau mii de solicitări pe secundă.
Soluția este să introduceți o întârziere între cererile dvs., o practică numită „limitare a ratei”. ( De asemenea, este destul de simplu de implementat! )
În exemplul Puppeteer furnizat mai sus, înainte de a crea variabila body , putem folosi metoda waitForTimeout oferită de Puppeteer pentru a aștepta câteva secunde înainte de a face o altă solicitare:
await page.waitForTimeout(3000); Unde ms este numărul de secunde pe care doriți să le așteptați.
De asemenea, dacă dorim să facem același lucru pentru exemplul axios, putem crea o promisiune care apelează metoda setTimeout() , pentru a ne ajuta să așteptăm numărul dorit de milisecunde:
fetchShelves.then(result => new Promise(resolve => setTimeout(() => resolve(result), 3000)))În acest fel, puteți evita să puneți prea multă presiune asupra serverului vizat și, de asemenea, puteți aduce o abordare mai umană a web scraping-ului.
Gânduri de închidere
Și iată-l, un ghid pas cu pas pentru crearea propriului web scraper pentru datele despre produse Amazon! Dar amintiți-vă, aceasta a fost doar o situație. Dacă doriți să analizați un alt site web, va trebui să faceți câteva ajustări pentru a obține rezultate semnificative.
Lectură aferentă
Dacă tot doriți să vedeți mai mult web scraping în acțiune, iată câteva materiale de lectură utile pentru dvs.:
- „Ghidul suprem pentru Web Scraping cu JavaScript și Node.Js”, Robert Sfichi
- „Advanced Node.JS Web Scraping with Puppeteer”, Gabriel Cioci
- „Python Web Scraping: The Ultimate Guide to Building Your Scraper”, Raluca Penciuc