
Creați o aplicație de marcare cu FaunaDB, Netlify și 11ty
Publicat: 2022-03-10Revoluția JAMstack (JavaScript, API-uri și Markup) este în plină desfășurare. Site-urile statice sunt sigure, rapide, de încredere și distractiv de lucrat. În centrul JAMstack-ului se află generatoarele statice de site (SSG) care stochează datele dvs. ca fișiere plate: Markdown, YAML, JSON, HTML și așa mai departe. Uneori, gestionarea datelor în acest fel poate fi prea complicată. Uneori, mai avem nevoie de o bază de date.
Având în vedere acest lucru, Netlify – o gazdă de site static și FaunaDB – o bază de date cloud fără server – au colaborat pentru a ușura combinarea ambelor sisteme.
De ce un site de marcare?
JAMstack este excelent pentru multe utilizări profesionale, dar unul dintre aspectele mele preferate ale acestui set de tehnologie este bariera sa scăzută de acces pentru instrumente și proiecte personale.
Există o mulțime de produse bune pe piață pentru majoritatea aplicațiilor cu care aș putea veni, dar niciuna nu ar fi exact configurată pentru mine. Niciunul nu mi-ar oferi control deplin asupra conținutului meu. Niciuna nu ar veni fără un cost (monetar sau informațional).
Având în vedere acest lucru, putem crea propriile noastre mini-servicii folosind metodele JAMstack. În acest caz, vom crea un site pentru a stoca și a publica orice articole interesante pe care le-am întâlnit în lectura mea zilnică de tehnologie.
Petrec mult timp citind articole care au fost distribuite pe Twitter. Când îmi place unul, apăs pe pictograma „inima”. Apoi, în câteva zile, este aproape imposibil de găsit cu afluxul de noi favorite. Vreau să construiesc ceva cât mai aproape de ușurința „inimii”, dar pe care îl dețin și îl controlez.
Cum vom face asta? Mă bucur că ai întrebat.
Vă interesează să obțineți codul? Îl poți lua de pe Github sau îl poți implementa direct în Netlify din acel depozit! Aruncă o privire la produsul finit aici.
Tehnologiile noastre
Funcții de găzduire și serverless: Netlify
Pentru găzduire și funcții fără server, vom folosi Netlify. Ca un bonus suplimentar, odată cu noua colaborare menționată mai sus, CLI-ul Netlify — „Netlify Dev” — se va conecta automat la FaunaDB și va stoca cheile noastre API ca variabile de mediu.
Baza de date: FaunaDB
FaunaDB este o bază de date NoSQL „fără server”. Îl vom folosi pentru a stoca datele marcajelor noastre.
Generator de site static: 11ty
Sunt un mare credincios în HTML. Din acest motiv, tutorialul nu va folosi JavaScript front-end pentru a reda marcajele noastre. În schimb, vom folosi 11ty ca generator de site static. 11ty are o funcționalitate de date încorporată care face preluarea datelor dintr-un API la fel de ușoară ca și scrierea a câteva funcții JavaScript scurte.
Comenzi rapide iOS
Vom avea nevoie de o modalitate ușoară de a posta date în baza noastră de date. În acest caz, vom folosi aplicația Comenzi rapide pentru iOS. Acesta ar putea fi convertit și într-un bookmarklet JavaScript pentru Android sau desktop.
Configurarea FaunaDB prin Netlify Dev
Indiferent dacă v-ați înscris deja la FaunaDB sau trebuie să creați un cont nou, cel mai simplu mod de a configura o legătură între FaunaDB și Netlify este prin CLI-ul Netlify: Netlify Dev. Puteți găsi instrucțiuni complete de la FaunaDB aici sau urmați mai jos.
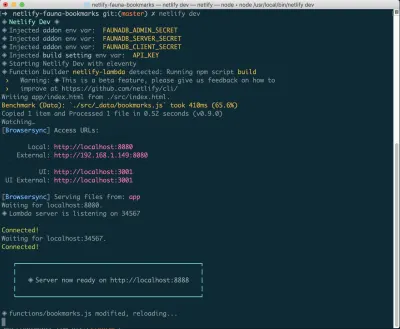
Dacă nu aveți deja instalat, puteți rula următoarea comandă în Terminal:
npm install netlify-cli -gDin directorul proiectului, rulați următoarele comenzi:
netlify init // This will connect your project to a Netlify project netlify addons:create fauna // This will install the FaunaDB "addon" netlify addons:auth fauna // This command will run you through connecting your account or setting up an account Odată ce toate acestea sunt conectate, puteți rula netlify dev în proiectul dvs. Aceasta va rula orice scripturi de compilare pe care le-am configurat, dar, de asemenea, se va conecta la serviciile Netlify și FaunaDB și va prelua orice variabile de mediu necesare. La indemana!
Crearea primelor noastre date
De aici, ne vom conecta la FaunaDB și vom crea primul nostru set de date. Vom începe prin a crea o nouă bază de date numită „marcaje”. În interiorul unei baze de date, avem colecții, documente și indici.
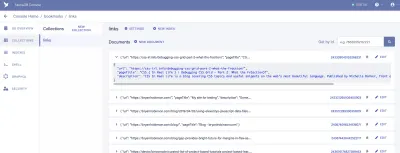
O colecție este un grup de date clasificat. Fiecare parte de date ia forma unui document. Un document este o „înregistrare unică, modificabilă într-o bază de date FaunaDB”, conform documentației Fauna. Vă puteți gândi la Colecții ca la un tabel tradițional de bază de date și la un Document ca la un rând.
Pentru aplicația noastră, avem nevoie de o colecție, pe care o vom numi „linkuri”. Fiecare document din Colecția „link-uri” va fi un simplu obiect JSON cu trei proprietăți. Pentru a începe, vom adăuga un document nou pe care îl vom folosi pentru a construi prima noastră preluare de date.
{ "url": "https://css-irl.info/debugging-css-grid-part-2-what-the-fraction/", "pageTitle": "CSS { In Real Life } | Debugging CSS Grid – Part 2: What the Fr(action)?", "description": "CSS In Real Life is a blog covering CSS topics and useful snippets on the web's most beautiful language. Published by Michelle Barker, front end developer at Ordoo and CSS superfan." }Aceasta creează baza pentru informațiile pe care va trebui să le extragem din marcajele noastre și ne oferă primul nostru set de date pe care să le extragem în șablonul nostru.
Dacă ești ca mine, vrei să vezi imediat roadele muncii tale. Hai să punem ceva pe pagină!
Instalarea 11ty și tragerea datelor într-un șablon
Deoarece dorim ca marcajele să fie redate în HTML și să nu fie preluate de browser, vom avea nevoie de ceva pentru a face randarea. Există multe modalități grozave de a face acest lucru, dar pentru ușurință și putere, îmi place să folosesc generatorul de site static 11ty.
Deoarece 11ty este un generator de site static JavaScript, îl putem instala prin NPM.
npm install --save @11ty/eleventy De la acea instalare, putem rula unsprezece sau eleventy --serve eleventy proiectul nostru pentru a începe și a funcționa.
Netlify Dev va detecta adesea 11ty ca o cerință și va rula comanda pentru noi. Pentru a funcționa și pentru a ne asigura că suntem gata de implementare, putem crea și comenzi „serve” și „build” în package.json .
"scripts": { "build": "npx eleventy", "serve": "npx eleventy --serve" }Fișierele de date ale lui 11ty
Majoritatea generatoarelor de site-uri statice au o idee despre un „fișier de date” încorporat. De obicei, aceste fișiere vor fi fișiere JSON sau YAML care vă permit să adăugați informații suplimentare pe site-ul dvs.
În 11ty, puteți utiliza fișiere de date JSON sau fișiere de date JavaScript. Utilizând un fișier JavaScript, putem de fapt să facem apeluri API și să returnăm datele direct într-un șablon.
În mod implicit, 11ty dorește fișierele de date stocate într-un director _data . Apoi puteți accesa datele utilizând numele fișierului ca variabilă în șabloanele dvs. În cazul nostru, vom crea un fișier la _data/bookmarks.js și îl vom accesa prin numele variabilei {{ bookmarks }} .
Dacă doriți să aprofundați configurația fișierelor de date, puteți citi exemple din documentația 11ty sau puteți consulta acest tutorial despre utilizarea fișierelor de date 11ty cu API-ul Meetup.
Fișierul va fi un modul JavaScript. Deci, pentru a avea ceva de lucru, trebuie să exportăm fie datele noastre, fie o funcție. În cazul nostru, vom exporta o funcție.
module.exports = async function() { const data = mapBookmarks(await getBookmarks()); return data.reverse() } Să descompun asta. Avem două funcții care își fac munca principală aici: mapBookmarks() și getBookmarks() .
Funcția getBookmarks() va prelua datele noastre din baza noastră de date FaunaDB, iar mapBookmarks() va prelua o serie de marcaje și le va restructura pentru a funcționa mai bine pentru șablonul nostru.
Să cercetăm mai profund în getBookmarks() .
getBookmarks()
În primul rând, va trebui să instalăm și să inițializam o instanță a driverului JavaScript FaunaDB.
npm install --save faunadbAcum că l-am instalat, să-l adăugăm în partea de sus a fișierului nostru de date. Acest cod este direct din documentele lui Fauna.
// Requires the Fauna module and sets up the query module, which we can use to create custom queries. const faunadb = require('faunadb'), q = faunadb.query; // Once required, we need a new instance with our secret var adminClient = new faunadb.Client({ secret: process.env.FAUNADB_SERVER_SECRET }); După aceea, ne putem crea funcția. Vom începe prin a construi prima noastră interogare folosind metode încorporate în driver. Acest prim bit de cod va returna referințele la baza de date pe care le putem folosi pentru a obține date complete pentru toate linkurile noastre marcate. Folosim metoda Paginate , ca ajutor pentru a gestiona starea cursorului în cazul în care decidem să paginam datele înainte de a le preda lui 11ty. În cazul nostru, vom returna doar toate referințele.
În acest exemplu, presupun că ați instalat și conectat FaunaDB prin Netlify Dev CLI. Folosind acest proces, obțineți variabilele de mediu locale ale secretelor FaunaDB. Dacă nu l-ați instalat în acest fel sau nu rulați netlify dev în proiectul dvs., veți avea nevoie de un pachet precum dotenv pentru a crea variabilele de mediu. De asemenea, va trebui să adăugați variabilele de mediu la configurația site-ului Netly pentru ca implementările să funcționeze mai târziu.
adminClient.query(q.Paginate( q.Match( // Match the reference below q.Ref("indexes/all_links") // Reference to match, in this case, our all_links index ) )) .then( response => { ... })Acest cod va returna o serie a tuturor linkurilor noastre sub formă de referință. Acum putem construi o listă de interogări pe care să o trimitem în baza noastră de date.
adminClient.query(...) .then((response) => { const linkRefs = response.data; // Get just the references for the links from the response const getAllLinksDataQuery = linkRefs.map((ref) => { return q.Get(ref) // Return a Get query based on the reference passed in }) return adminClient.query(getAllLinksDataQuery).then(ret => { return ret // Return an array of all the links with full data }) }).catch(...) De aici, trebuie doar să curățăm datele returnate. Aici mapBookmarks() !
mapBookmarks()
În această funcție, ne ocupăm de două aspecte ale datelor.
În primul rând, obținem o dată și oră gratuită în FaunaDB. Pentru orice date create, există o proprietate timestamp ( ts ). Nu este formatat într-un mod care să facă fericit filtrul de dată implicit al lui Liquid, așa că haideți să rezolvăm asta.
function mapBookmarks(data) { return data.map(bookmark => { const dateTime = new Date(bookmark.ts / 1000); ... }) } Cu asta în afara drumului, putem construi un nou obiect pentru datele noastre. În acest caz, va avea o proprietate time și vom folosi operatorul Spread pentru a ne destructura obiectul de data pentru a le face pe toate să trăiască la un nivel.
function mapBookmarks(data) { return data.map(bookmark => { const dateTime = new Date(bookmark.ts / 1000); return { time: dateTime, ...bookmark.data } }) }Iată datele noastre înainte de funcția noastră:
{ ref: Ref(Collection("links"), "244778237839802888"), ts: 1569697568650000, data: { url: 'https://sample.com', pageTitle: 'Sample title', description: 'An escaped description goes here' } }Iată datele noastre după funcția noastră:

{ time: 1569697568650, url: 'https://sample.com', pageTitle: 'Sample title' description: 'An escaped description goes here' }Acum, avem date bine formatate care sunt gata pentru șablonul nostru!
Să scriem un șablon simplu. Vom parcurge marcajele noastre și vom valida că fiecare are un pageTitle de pagină și o url , astfel încât să nu părem proști.
<div class="bookmarks"> {% for link in bookmarks %} {% if link.url and link.pageTitle %} // confirms there's both title AND url for safety <div class="bookmark"> <h2><a href="{{ link.url }}">{{ link.pageTitle }}</a></h2> <p>Saved on {{ link.time | date: "%b %d, %Y" }}</p> {% if link.description != "" %} <p>{{ link.description }}</p> {% endif %} </div> {% endif %} {% endfor %} </div>Acum ingerăm și afișăm date de la FaunaDB. Să luăm un moment și să ne gândim cât de frumos este că aceasta redă HTML pur și nu este nevoie să preluăm date din partea clientului!
Dar asta nu este cu adevărat suficient pentru a face din aceasta o aplicație utilă pentru noi. Să găsim o modalitate mai bună decât adăugarea unui marcaj în consola FaunaDB.
Introduceți funcțiile Netlify
Suplimentul Netlify Functions este una dintre modalitățile mai ușoare de a implementa funcții lambda AWS. Deoarece nu există un pas de configurare, este perfect pentru proiectele DIY în care doriți doar să scrieți codul.
Această funcție va apărea la o adresă URL din proiectul dvs. care arată astfel: https://myproject.com/.netlify/functions/bookmarks presupunând că fișierul pe care îl creăm în folderul nostru de funcții este bookmarks.js .
Flux de bază
- Transmiteți o adresă URL ca parametru de interogare la adresa URL a funcției noastre.
- Utilizați funcția pentru a încărca adresa URL și pentru a răzui titlul și descrierea paginii, dacă sunt disponibile.
- Formatați detaliile pentru FaunaDB.
- Împingeți detaliile în colecția noastră FaunaDB.
- Reconstruiți site-ul.
Cerințe
Avem câteva pachete de care vom avea nevoie pe măsură ce construim asta. Vom folosi netlify-lambda CLI pentru a ne construi funcțiile la nivel local. request-promise este pachetul pe care îl vom folosi pentru a face cereri. Cheerio.js este pachetul pe care îl vom folosi pentru a răzui anumite elemente din pagina noastră solicitată (gândiți-vă la jQuery pentru Node). Și, în sfârșit, vom avea nevoie de FaunaDb (care ar trebui să fie deja instalat.
npm install --save netlify-lambda request-promise cheerioOdată ce este instalat, să ne configuram proiectul pentru a construi și a servi funcțiile la nivel local.
Vom modifica scripturile noastre „build” și „serve” din package.json pentru a arăta astfel:
"scripts": { "build": "npx netlify-lambda build lambda --config ./webpack.functions.js && npx eleventy", "serve": "npx netlify-lambda build lambda --config ./webpack.functions.js && npx eleventy --serve" } Avertisment: Există o eroare cu driverul NodeJS al Fauna la compilarea cu Webpack, pe care funcțiile Netlify îl folosesc pentru a construi. Pentru a ocoli acest lucru, trebuie să definim un fișier de configurare pentru Webpack. Puteți salva următorul cod într-un webpack.config.js nou sau existent .
const webpack = require('webpack'); module.exports = { plugins: [ new webpack.DefinePlugin({ "global.GENTLY": false }) ] }; Odată ce acest fișier există, când folosim comanda netlify-lambda , va trebui să îi spunem să ruleze din această configurație. Acesta este motivul pentru care scripturile noastre „serve” și „build folosesc valoarea --config pentru acea comandă.
Funcția Menaj
Pentru a menține fișierul Function principal cât mai curat posibil, vom crea funcțiile noastre într-un director separat de bookmarks și le vom importa în fișierul Function principal.
import { getDetails, saveBookmark } from "./bookmarks/create"; getDetails(url)
Funcția getDetails() va primi o adresă URL, transmisă de la handlerul nostru exportat. De acolo, vom ajunge la site-ul de la acea adresă URL și vom prelua părți relevante ale paginii pentru a le stoca ca date pentru marcajul nostru.
Începem prin a solicita pachetele NPM de care avem nevoie:
const rp = require('request-promise'); const cheerio = require('cheerio'); Apoi, vom folosi modulul request-promise pentru a returna un șir HTML pentru pagina solicitată și îl vom trece în cheerio pentru a ne oferi o interfață foarte jQuery.
const getDetails = async function(url) { const data = rp(url).then(function(htmlString) { const $ = cheerio.load(htmlString); ... }De aici, trebuie să obținem titlul paginii și o meta descriere. Pentru a face asta, vom folosi selectori ca și în jQuery.
Notă: În acest cod, folosim 'head > title' ca selector pentru a obține titlul paginii. Dacă nu specificați acest lucru, este posibil să obțineți etichete <title> în interiorul tuturor SVG-urilor de pe pagină, ceea ce este mai puțin decât ideal.
const getDetails = async function(url) { const data = rp(url).then(function(htmlString) { const $ = cheerio.load(htmlString); const title = $('head > title').text(); // Get the text inside the tag const description = $('meta[name="description"]').attr('content'); // Get the text of the content attribute // Return out the data in the structure we expect return { pageTitle: title, description: description }; }); return data //return to our main function }Cu datele în mână, este timpul să trimitem marcajul nostru către Colecția noastră în FaunaDB!
saveBookmark(details)
Pentru funcția noastră de salvare, vom dori să transmitem detaliile pe care le-am obținut de la getDetails , precum și adresa URL ca obiect singular. Operatorul Spread lovește din nou!
const savedResponse = await saveBookmark({url, ...details}); În fișierul nostru create.js , trebuie să solicităm și să setăm driverul nostru FaunaDB. Acest lucru ar trebui să pară foarte familiar din fișierul nostru de date 110.
const faunadb = require('faunadb'), q = faunadb.query; const adminClient = new faunadb.Client({ secret: process.env.FAUNADB_SERVER_SECRET });Odată ce l-am scos din drum, putem codifica.
În primul rând, trebuie să ne formatăm detaliile într-o structură de date pe care Fauna o așteaptă pentru interogarea noastră. Fauna se așteaptă la un obiect cu o proprietate de date care conține datele pe care dorim să le stocăm.
const saveBookmark = async function(details) { const data = { data: details }; ... }Apoi vom deschide o nouă interogare pentru a o adăuga la colecția noastră. În acest caz, vom folosi ajutorul nostru de interogare și vom folosi metoda Create. Create() ia două argumente. Prima este Colecția în care dorim să ne stocăm datele, iar a doua este datele în sine.
După ce salvăm, returnăm fie succes, fie eșec managerului nostru.
const saveBookmark = async function(details) { const data = { data: details }; return adminClient.query(q.Create(q.Collection("links"), data)) .then((response) => { /* Success! return the response with statusCode 200 */ return { statusCode: 200, body: JSON.stringify(response) } }).catch((error) => { /* Error! return the error with statusCode 400 */ return { statusCode: 400, body: JSON.stringify(error) } }) }Să aruncăm o privire la fișierul Function complet.
import { getDetails, saveBookmark } from "./bookmarks/create"; import { rebuildSite } from "./utilities/rebuild"; // For rebuilding the site (more on that in a minute) exports.handler = async function(event, context) { try { const url = event.queryStringParameters.url; // Grab the URL const details = await getDetails(url); // Get the details of the page const savedResponse = await saveBookmark({url, ...details}); //Save the URL and the details to Fauna if (savedResponse.statusCode === 200) { // If successful, return success and trigger a Netlify build await rebuildSite(); return { statusCode: 200, body: savedResponse.body } } else { return savedResponse //or else return the error } } catch (err) { return { statusCode: 500, body: `Error: ${err}` }; } }; rebuildSite()
Ochiul cu discernământ va observa că avem încă o funcție importată în handlerul nostru: rebuildSite() . Această funcție va folosi funcționalitatea Deploy Hook de la Netlify pentru a reconstrui site-ul nostru din noile date de fiecare dată când trimitem o nouă salvare a marcajului, cu succes.
În setările site-ului dvs. în Netlify, vă puteți accesa setările Build & Deploy și puteți crea un nou „Build Hook”. Cârligele au un nume care apare în secțiunea Deploy și o opțiune pentru implementarea unei ramuri non-master, dacă doriți. În cazul nostru, îl vom numi „new_link” și vom implementa ramura noastră principală.
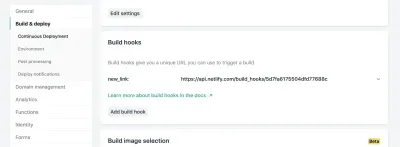
De acolo, trebuie doar să trimitem o solicitare POST la adresa URL furnizată.
Avem nevoie de o modalitate de a face solicitări și, deoarece am instalat deja request-promise , vom continua să folosim acel pachet, solicitându-l în partea de sus a fișierului nostru.
const rp = require('request-promise'); const rebuildSite = async function() { var options = { method: 'POST', uri: 'https://api.netlify.com/build_hooks/5d7fa6175504dfd43377688c', body: {}, json: true }; const returned = await rp(options).then(function(res) { console.log('Successfully hit webhook', res); }).catch(function(err) { console.log('Error:', err); }); return returned } Configurarea unei comenzi rapide iOS
Deci, avem o bază de date, o modalitate de a afișa date și o funcție de a adăuga date, dar încă nu suntem foarte ușor de utilizat.
Netlify oferă adrese URL pentru funcțiile noastre Lambda, dar nu este distractiv de tastat pe un dispozitiv mobil. De asemenea, ar trebui să transmitem o adresă URL ca parametru de interogare în ea. Este MULT efort. Cum putem face acest lucru cât mai puțin posibil?
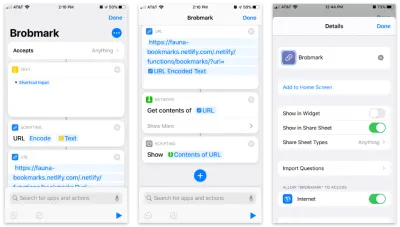
Aplicația Apple Shortcuts permite crearea de elemente personalizate pentru a intra în foaia de partajare. În cadrul acestor comenzi rapide, putem trimite diferite tipuri de solicitări de date colectate în procesul de partajare.
Iată comanda rapidă pas cu pas:
- Acceptați orice articole și stocați acel articol într-un bloc „text”.
- Transmite acel text într-un bloc „Scripting” la codificarea URL (doar pentru orice eventualitate).
- Treceți acel șir într-un bloc URL cu adresa URL a funcției noastre Netlify și un parametru de interogare
url. - Din „Rețea” utilizați un bloc „Obține conținut” pentru a POST în JSON la adresa noastră URL.
- Opțional: Din „Scripting” „Afișează” conținutul ultimului pas (pentru a confirma datele pe care le trimitem).
Pentru a accesa aceasta din meniul de partajare, deschidem setările pentru această comandă rapidă și activăm opțiunea „Afișează în foaia de partajare”.
Începând cu iOS13, aceste „Acțiuni” partajate pot fi preferate și mutate într-o poziție înaltă în dialog.
Acum avem o „aplicație” funcțională pentru partajarea marcajelor pe mai multe platforme!
Mergi la Mila suplimentară!
Dacă sunteți inspirat să încercați singur acest lucru, există o mulțime de alte posibilități de a adăuga funcționalitate. Bucuria rețelei de bricolaj este că puteți face ca astfel de aplicații să funcționeze pentru dvs. Iată câteva idei:
- Utilizați o „cheie API” falsă pentru autentificare rapidă, astfel încât alți utilizatori să nu posteze pe site-ul dvs. (a mea folosește o cheie API, așa că nu încercați să postați pe ea!).
- Adăugați funcționalitatea de etichetă pentru a organiza marcajele.
- Adăugați un flux RSS pentru site-ul dvs., astfel încât alții să se poată abona.
- Trimiteți un e-mail săptămânal de resumare în mod programatic pentru linkurile pe care le-ați adăugat.
Într-adevăr, cerul este limita, așa că începeți să experimentați!