
Dincolo de browser: Noțiuni introductive cu Serverless WebAssembly
Publicat: 2022-03-10Acum că WebAssembly este acceptat de toate browserele majore și de peste 85% dintre utilizatorii din întreaga lume, JavaScript nu mai este singura limbă de browser din oraș. Dacă nu ați auzit, WebAssembly este un nou limbaj de nivel scăzut care rulează în browser. Este, de asemenea, o țintă de compilare, ceea ce înseamnă că puteți compila programe existente scrise în limbaje precum C, C++ și Rust în WebAssembly și puteți rula acele programe în browser. Până acum, WebAssembly a fost folosit pentru a porta tot felul de aplicații pe web, inclusiv aplicații desktop, instrumente de linie de comandă, jocuri și instrumente pentru știința datelor.
Notă: Pentru un studiu de caz aprofundat al modului în care WebAssembly poate fi utilizat în browser pentru a accelera aplicațiile web, consultați articolul meu anterior.
WebAssembly în afara Web-ului?
Deși majoritatea aplicațiilor WebAssembly de astăzi sunt centrate pe browser, WebAssembly în sine nu a fost conceput inițial doar pentru web, ci într-adevăr pentru orice mediu sandbox. De fapt, recent a existat mult interes în explorarea modului în care WebAssembly ar putea fi util în afara browserului, ca abordare generală pentru rularea binarelor pe orice sistem de operare sau arhitectură de computer, atâta timp cât există un timp de execuție WebAssembly care acceptă acel sistem. În acest articol, ne vom uita la modul în care WebAssembly poate fi rulat în afara browserului, într-un mod fără server/Function-as-a-Service (FaaS).
WebAssembly pentru aplicații fără server
Pe scurt, funcțiile fără server sunt un model de calcul în care vă predați codul unui furnizor de cloud și îi lăsați să execute și să gestioneze scalarea codului pentru dvs. De exemplu, puteți cere ca funcția dvs. fără server să fie executată oricând apelați un punct final API sau să fie determinată de evenimente, cum ar fi atunci când un fișier este încărcat în compartimentul dvs. cloud. În timp ce termenul „fără server” poate părea o denumire greșită, deoarece serverele sunt în mod clar implicate undeva pe parcurs, este fără server din punctul nostru de vedere, deoarece nu trebuie să ne îngrijorăm cum să gestionăm, să implementăm sau să scalam acele servere.
Deși aceste funcții sunt de obicei scrise în limbaje precum Python și JavaScript (Node.js), există o serie de motive pentru care ați putea alege să utilizați WebAssembly:
- Timpi de inițializare mai rapid
Furnizorii fără server care acceptă WebAssembly (inclusiv Cloudflare și Fastly raportează că pot lansa funcții cu cel puțin un ordin de mărime mai repede decât o pot face majoritatea furnizorilor de cloud cu alte limbi. Ei reușesc acest lucru rulând zeci de mii de module WebAssembly în același proces, care este posibil deoarece natura sandbox a WebAssembly face o modalitate mai eficientă de a obține izolarea pentru care sunt folosite în mod tradițional containerele. - Nu sunt necesare rescrieri
Una dintre principalele atracții ale WebAssembly în browser este capacitatea de a porta codul existent pe web fără a fi nevoie să rescrie totul în JavaScript. Acest beneficiu este încă valabil în cazul de utilizare fără server, deoarece furnizorii de cloud limitează limbile în care vă puteți scrie funcțiile fără server. De obicei, vor accepta Python, Node.js și poate câteva altele, dar cu siguranță nu C, C++ sau Rust . Prin sprijinirea WebAssembly, furnizorii fără server pot suporta indirect mult mai multe limbi. - Mai ușor
Când rulăm WebAssembly în browser, ne bazăm pe computerul utilizatorului final pentru a efectua calculele noastre. Dacă aceste calcule sunt prea intense, utilizatorii noștri nu vor fi mulțumiți când ventilatorul computerului lor începe să zbârnească. Rularea WebAssembly în afara browserului ne oferă avantajele de viteză și portabilitate ale WebAssembly, menținând, de asemenea, aplicația noastră ușoară. În plus, deoarece rulăm codul nostru WebAssembly într-un mediu mai previzibil, putem efectua calcule mai intense.
Un exemplu concret
În articolul meu anterior aici pe Smashing Magazine, am discutat despre modul în care am accelerat o aplicație web prin înlocuirea calculelor JavaScript lente cu cod C compilat în WebAssembly. Aplicația web în cauză a fost fastq.bio, un instrument de previzualizare a calității datelor de secvențiere ADN.
Ca exemplu concret, să rescriem fastq.bio ca o aplicație care folosește WebAssembly fără server în loc să ruleze WebAssembly în browser. Pentru acest articol, vom folosi Cloudflare Workers, un furnizor fără server care acceptă WebAssembly și este construit pe motorul de browser V8. Un alt furnizor de cloud, Fastly, lucrează la o ofertă similară, dar bazată pe timpul de rulare Lucet.
Mai întâi, să scriem un cod Rust pentru a analiza calitatea datelor de secvențiere a ADN-ului. Pentru comoditate, putem folosi biblioteca de bioinformatică Rust-Bio pentru a gestiona analiza datelor de intrare și biblioteca wasm-bindgen pentru a ne ajuta să compilam codul nostru Rust în WebAssembly.

Iată un fragment de cod care citește în datele de secvențiere ADN și scoate un JSON cu un rezumat al valorilor de calitate:
// Import packages extern crate wasm_bindgen; use bio::seq_analysis::gc; use bio::io::fastq; ... // This "wasm_bindgen" tag lets us denote the functions // we want to expose in our WebAssembly module #[wasm_bindgen] pub fn fastq_metrics(seq: String) -> String { ... // Loop through lines in the file let reader = fastq::Reader::new(seq.as_bytes()); for result in reader.records() { let record = result.unwrap(); let sequence = record.seq(); // Calculate simple statistics on each record n_reads += 1.0; let read_length = sequence.len(); let read_gc = gc::gc_content(sequence); // We want to draw histograms of these values // so we store their values for later plotting hist_gc.push(read_gc * 100.0); hist_len.push(read_length); ... } // Return statistics as a JSON blob json!({ "n": n_reads, "hist": { "gc": hist_gc, "len": hist_len }, ... }).to_string() }Apoi am folosit instrumentul de linie de comandă wrangler de la Cloudflare pentru a face sarcini grele de compilare în WebAssembly și implementare în cloud. Odată terminat, ni se oferă un punct final API care preia datele de secvențiere ca intrare și returnează un JSON cu valori de calitate a datelor. Acum putem integra acel API în aplicația noastră.
Iată un GIF al aplicației în acțiune:
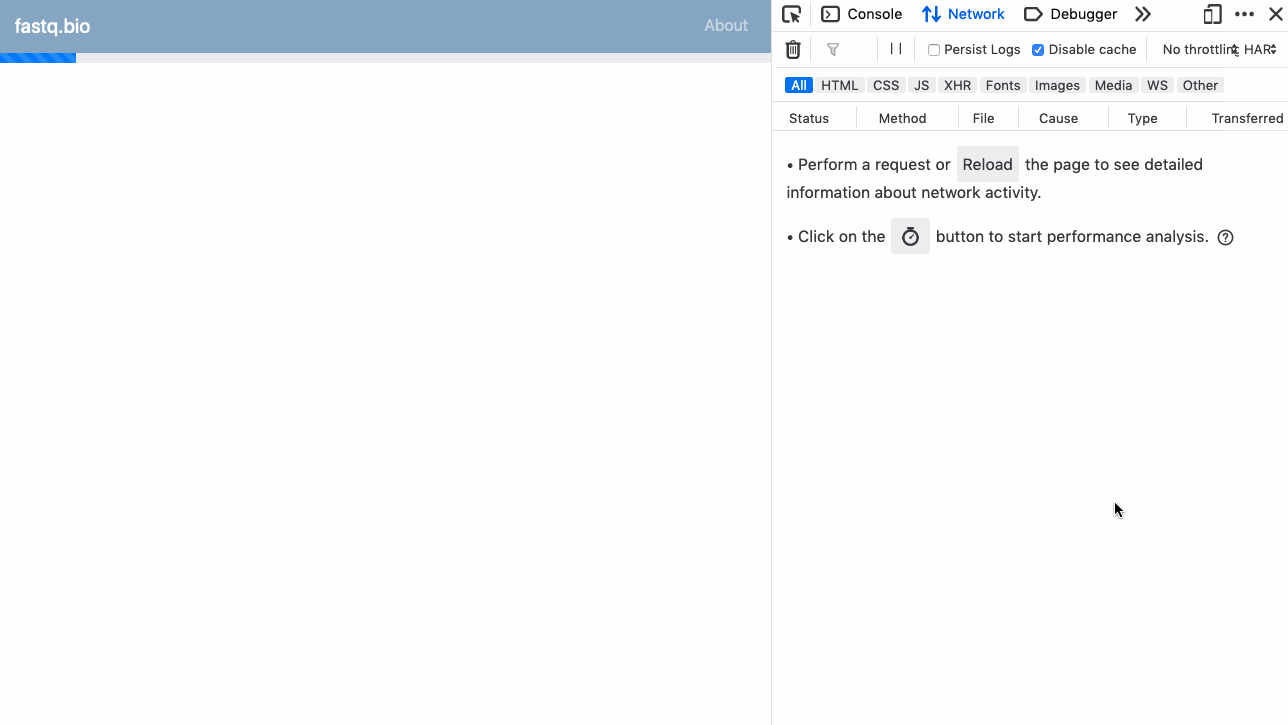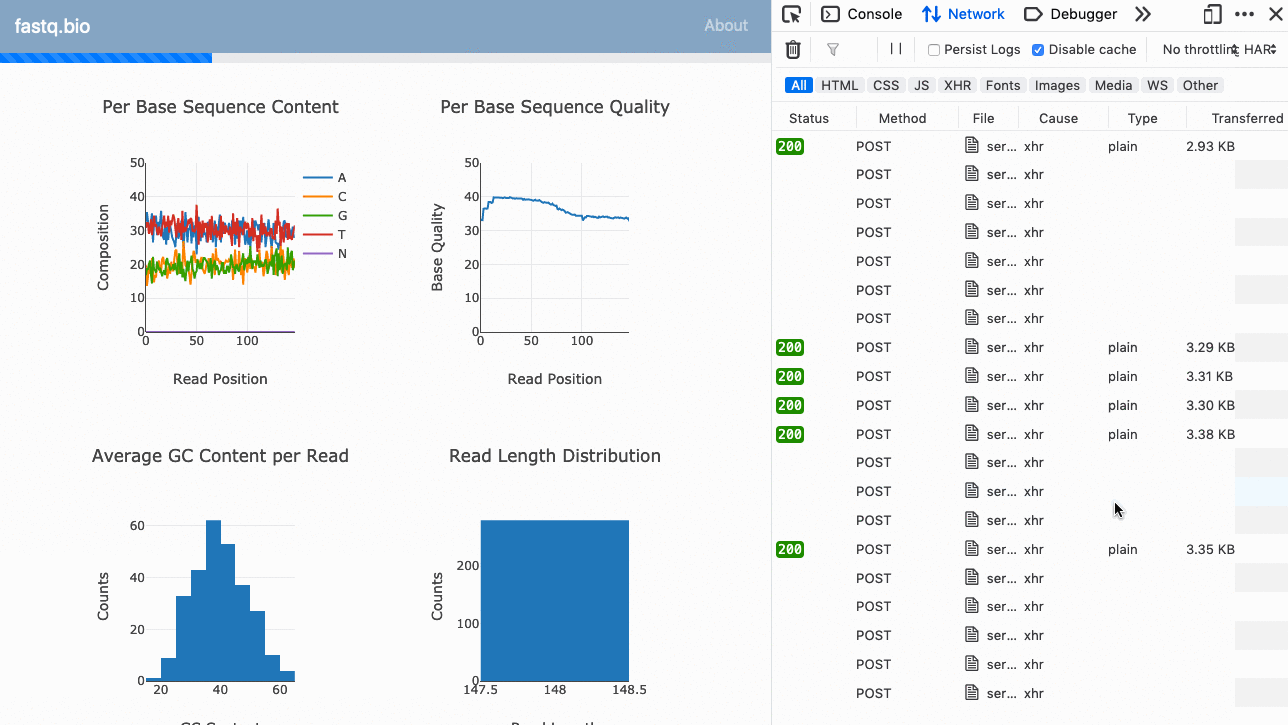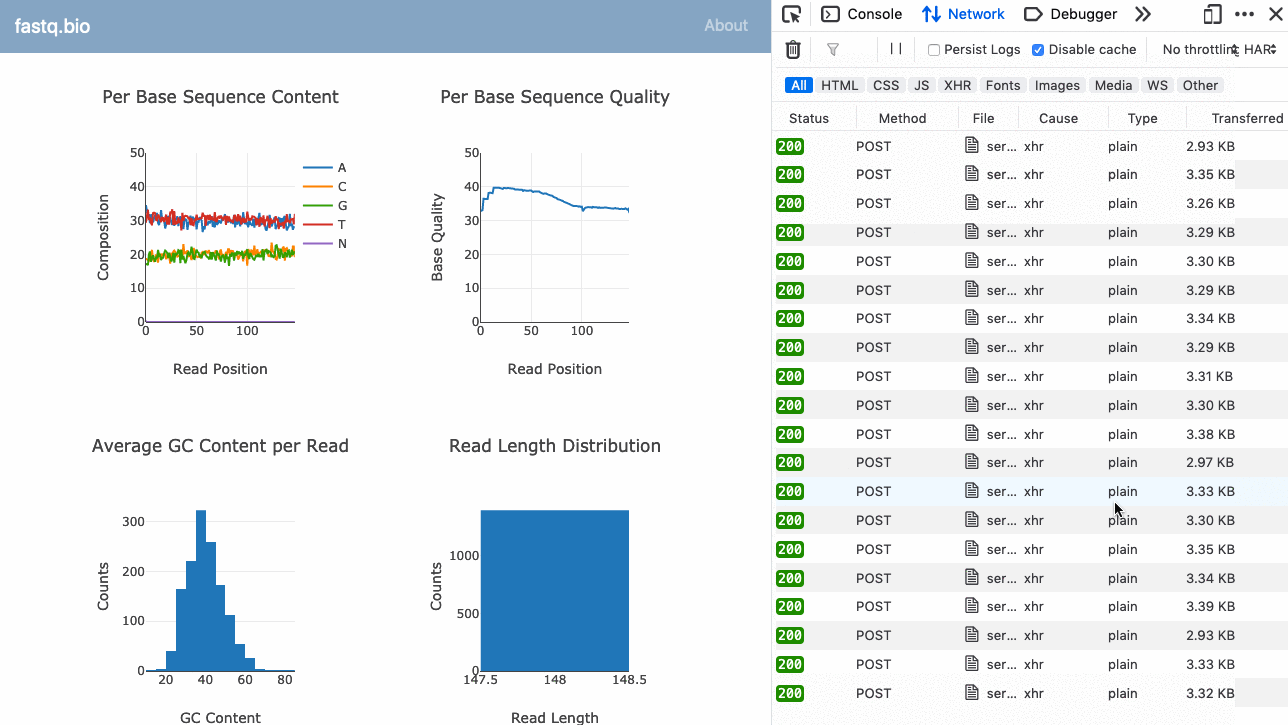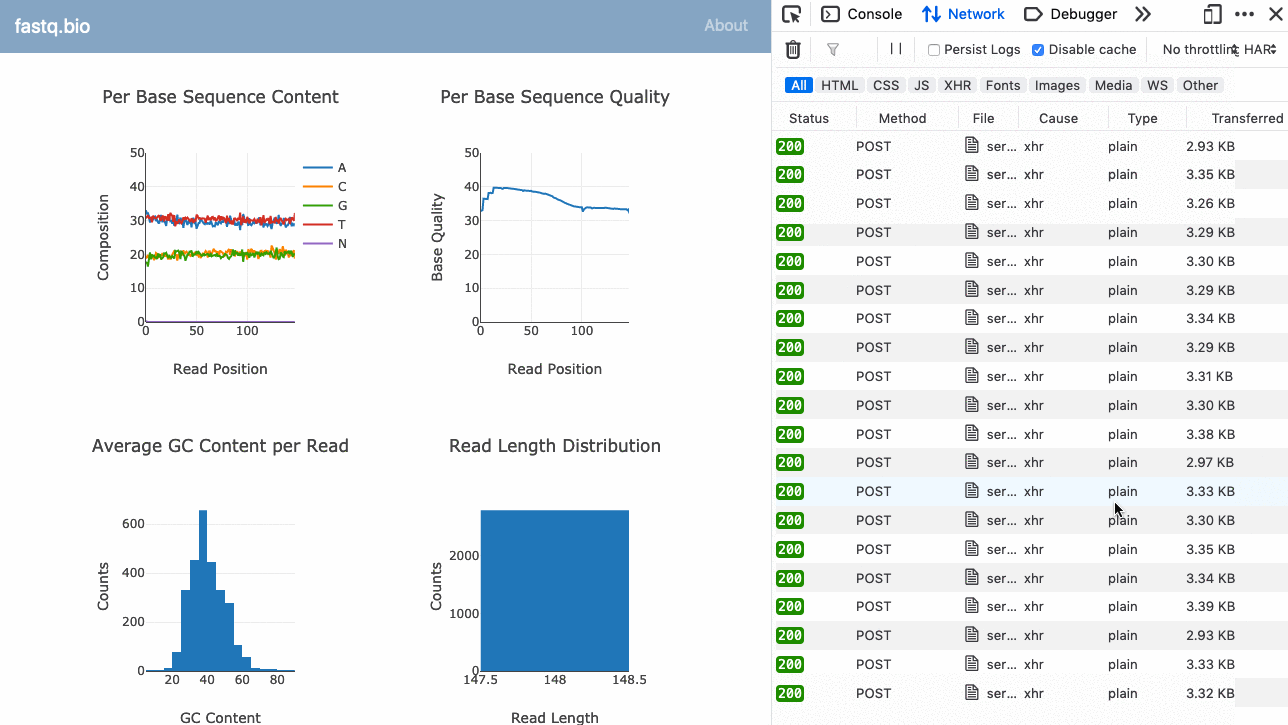
Codul complet este disponibil pe GitHub (open-source).
Punând totul în context
Pentru a pune în context abordarea WebAssembly fără server, să luăm în considerare patru moduri principale în care putem construi aplicații web de procesare a datelor (adică aplicații web în care efectuăm analize pe datele furnizate de utilizator):
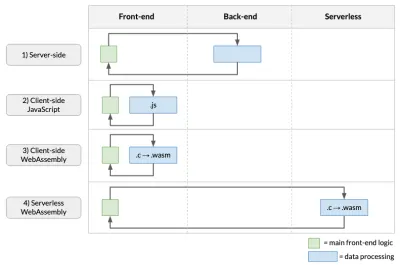
După cum se arată mai sus, prelucrarea datelor se poate face în mai multe locuri:
- Partea de server
Aceasta este abordarea adoptată de majoritatea aplicațiilor web, unde apelurile API efectuate în front-end procesează datele de lansare pe back-end. - JavaScript pe partea clientului
În această abordare, codul de procesare a datelor este scris în JavaScript și rulează în browser. Dezavantajul este că performanța dvs. va fi afectată, iar dacă codul original nu a fost în JavaScript, va trebui să-l rescrieți de la zero! - WebAssembly pe partea clientului
Aceasta implică compilarea codului de analiză a datelor în WebAssembly și rularea acestuia în browser. Dacă codul de analiză a fost scris în limbaje precum C, C++ sau Rust (cum este adesea cazul în domeniul meu de genomică), acest lucru evită nevoia de a rescrie algoritmi complecși în JavaScript. De asemenea, oferă potențialul de a accelera aplicația noastră (de exemplu, așa cum sa discutat într-un articol anterior). - WebAssembly fără server
Aceasta implică rularea WebAssembly-ului compilat pe cloud, folosind un model de tip FaaS (de exemplu, acest articol).
Deci, de ce ați alege abordarea fără server în detrimentul celorlalte? În primul rând, în comparație cu prima abordare, are beneficiile care vin odată cu utilizarea WebAssembly, în special capacitatea de a porta codul existent fără a fi nevoie să-l rescrie în JavaScript. În comparație cu cea de-a treia abordare, WebAssembly fără server înseamnă, de asemenea, că aplicația noastră este mai ușoară, deoarece nu folosim resursele utilizatorului pentru calcularea numerelor. În special, dacă calculele sunt destul de implicate sau dacă datele sunt deja în cloud, această abordare are mai mult sens.
Pe de altă parte, însă, aplicația trebuie acum să realizeze conexiuni la rețea, așa că probabil că aplicația va fi mai lentă. În plus, în funcție de amploarea calculului și dacă acesta poate fi împărțit în bucăți de analiză mai mici, această abordare ar putea să nu fie potrivită din cauza limitărilor impuse de furnizorii de cloud fără server în ceea ce privește utilizarea timpului de execuție, a CPU și a RAM.
Concluzie
După cum am văzut, acum este posibil să rulați codul WebAssembly într-o manieră fără server și să profitați atât de avantajele WebAssembly (portabilitate și viteză), cât și de cele ale arhitecturilor funcționale ca serviciu (scalare automată și prețuri pe utilizare). ). Anumite tipuri de aplicații – cum ar fi analiza datelor și procesarea imaginilor, pentru a numi câteva – pot beneficia foarte mult de o astfel de abordare. Deși timpul de execuție suferă din cauza călătoriilor dus-întors în rețea suplimentare, această abordare ne permite să procesăm mai multe date simultan și să nu punem o scurgere a resurselor utilizatorilor.