
Exemplu de rețea bayesiană [cu reprezentare grafică]
Publicat: 2021-01-29Cuprins
Introducere
În statistică, modelele probabilistice sunt folosite pentru a defini o relație între variabile și pot fi folosite pentru a calcula probabilitățile fiecărei variabile. În multe probleme, există un număr mare de variabile. În astfel de cazuri, modelele complet condiționate necesită o cantitate imensă de date pentru a acoperi fiecare caz de funcții de probabilitate care pot fi imposibil de calculat în timp real. Au existat mai multe încercări de a simplifica calculele probabilității condiționate, cum ar fi Naive Bayes, dar totuși, nu se dovedește a fi eficient, deoarece reduce drastic mai multe variabile.
Singura modalitate este de a dezvolta un model care să poată păstra dependențele condiționate dintre variabilele aleatoare și independența condiționată în alte cazuri. Acest lucru ne conduce la conceptul de rețele bayesiene. Aceste rețele bayesiene ne ajută să vizualizăm eficient modelul probabilistic pentru fiecare domeniu și să studiem relația dintre variabile aleatoare sub forma unui grafic ușor de utilizat.
Învață cursul ML de la cele mai bune universități din lume. Câștigă programe de master, Executive PGP sau Advanced Certificate pentru a-ți accelera cariera.
Ce sunt rețelele bayesiene?
Prin definiție, rețelele bayesiene sunt un tip de model grafic probabilist care utilizează inferențe bayesiene pentru calculele probabilităților. Reprezintă un set de variabile și probabilitățile sale condiționate cu un grafic aciclic direcționat (DAG). Ele sunt potrivite în primul rând pentru a lua în considerare un eveniment care a avut loc și pentru a prezice probabilitatea ca oricare dintre numeroasele cauze cunoscute posibile să fie factorul care contribuie.
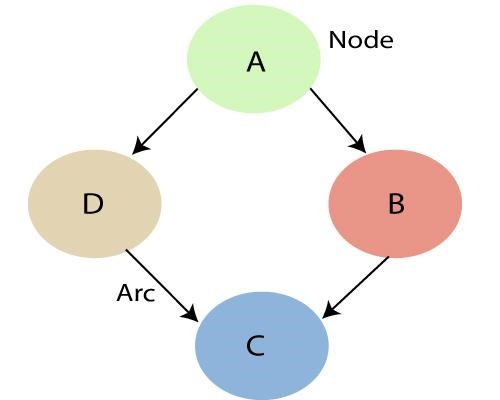
Sursă
După cum am menționat mai sus, utilizând relațiile care sunt specificate de Rețeaua Bayesiană, putem obține Joint Probability Distribution (JPF) cu probabilitățile condiționate. Fiecare nod din grafic reprezintă o variabilă aleatoare, iar arcul (sau săgeata direcționată) reprezintă relația dintre noduri. Ele pot fi fie continue, fie discrete.

În diagrama de mai sus A, B, C și D sunt 4 variabile aleatoare reprezentate prin noduri date în rețeaua graficului. Pentru nodul B, A este nodul părinte și C este nodul copil. Nodul C este independent de Nodul A.
Înainte de a intra în implementarea unei rețele bayesiene, există câteva elemente de bază ale probabilității care trebuie înțelese.
Proprietate locală Markov
Rețelele Bayesiene satisfac proprietatea cunoscută sub numele de Local Markov Property. Afirmă că un nod este independent condiționat de nedescendenții săi, având în vedere părinții săi. În exemplul de mai sus, P(D|A, B) este egal cu P(D|A) deoarece D este independent de nedescendentul său, B. Această proprietate ne ajută să simplificăm distribuția comună. Proprietatea Markov locală ne conduce la conceptul unui câmp aleator Markov care este un câmp aleator în jurul unei variabile despre care se spune că urmează proprietățile Markov.
Probabilitate condițională
În matematică, probabilitatea condiționată a evenimentului A este probabilitatea ca evenimentul A să se producă, având în vedere că un alt eveniment B a avut deja loc. În termeni simpli, p(A | B) este probabilitatea ca evenimentul A să se producă, dat fiind că evenimentul B are loc. Cu toate acestea, există două tipuri de posibilități de evenimente între A și B. Acestea pot fi fie evenimente dependente, fie evenimente independente. În funcție de tipul lor, există două moduri diferite de a calcula probabilitatea condiționată.
- Dat fiind că A și B sunt evenimente dependente, probabilitatea condiționată este calculată ca P (A| B) = P (A și B) / P (B)
- Dacă A și B sunt evenimente independente, atunci expresia probabilității condiționate este dată de, P(A| B) = P (A)
Distribuția comună a probabilității
Înainte de a intra într-un exemplu de rețele bayesiene, să înțelegem conceptul de distribuție a probabilității comune. Se consideră 3 variabile a1, a2 și a3. Prin definiție, probabilitățile tuturor combinațiilor posibile diferite ale a1, a2 și a3 sunt numite distribuția sa comună de probabilitate.
Dacă P[a1,a2, a3,….., an] este JPD-ul următoarelor variabile de la a1 la an, atunci există mai multe moduri de calculare a distribuției comune a probabilității ca o combinație de diferiți termeni, cum ar fi:
P[a1,a2, a3,….., an] = P[a1 | a2, a3,….., an] * P[a2, a3,….., an]
= P[a1 | a2, a3,….., an] * P[a2 | a3,….., an]….P[an-1|an] * P[an]
Generalizând ecuația de mai sus, putem scrie distribuția probabilă comună ca:
P(X i |X i-1 ,………, X n ) = P(X i |Părinți(X i ))
Exemplu de rețele bayesiene
Să înțelegem acum mecanismul rețelelor bayesiene și avantajele acestora cu ajutorul unui exemplu simplu. În acest exemplu, să ne imaginăm că ni se dă sarcina de a modela notele ( m ) ale unui student pentru un examen pe care tocmai l-a dat. Din graficul de rețea bayesian de mai jos, vedem că notele depind de alte două variabile. Sunt,
- Nivelul examenului ( e ) – Această variabilă discretă denotă dificultatea examenului și are două valori (0 pentru ușor și 1 pentru dificil)
- Nivelul IQ ( i ) – Acesta reprezintă nivelul coeficientului de inteligență al elevului și este, de asemenea, de natură discretă, având două valori (0 pentru scăzut și 1 pentru mare)
În plus, nivelul IQ al elevului ne conduce și la o altă variabilă, care este Scorul de aptitudine al elevului ( ele ). Acum, cu notele pe care le-a obținut studentul, el își poate asigura admiterea la o anumită universitate. Distribuția probabilității de admitere ( a ) la o universitate este de asemenea prezentată mai jos.

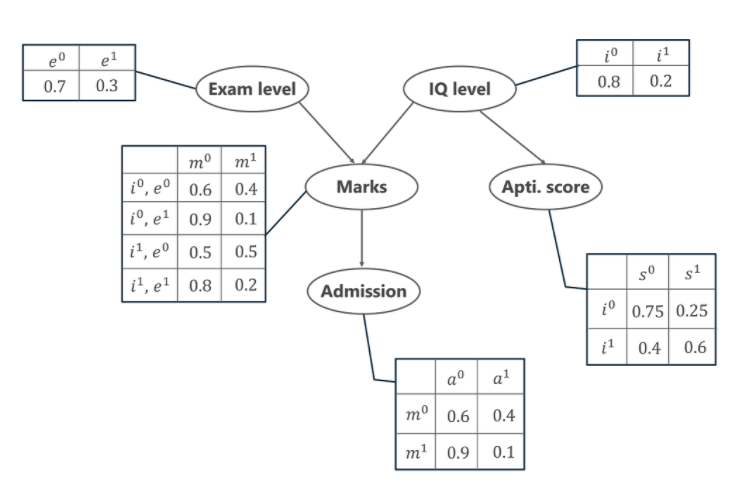
În graficul de mai sus, vedem mai multe tabele reprezentând valorile distribuției de probabilitate ale celor 5 variabile date. Aceste tabele sunt numite Tabelul Probabilităților Condiționale sau CPT. Există câteva proprietăți ale CPT prezentate mai jos -
- Suma valorilor CPT din fiecare rând trebuie să fie egală cu 1 deoarece toate cazurile posibile pentru o anumită variabilă sunt exhaustive (reprezentând toate posibilitățile).
- Dacă o variabilă de natură booleană are k părinți booleeni, atunci în CPT are 2K valori de probabilitate.
Revenind la problema noastră, să enumeram mai întâi toate evenimentele posibile care au loc în tabelul de mai sus.
- Nivelul examenului (e)
- Nivelul IQ (i)
- Scor (e) de aptitudini
- semne (m)
- Admitere (a)
Aceste cinci variabile sunt reprezentate sub forma unui grafic aciclic direcționat (DAG) într-un format de rețea bayesiană cu tabelele lor de probabilitate condiționată. Acum, pentru a calcula distribuția probabilă comună a celor 5 variabile, formula este dată de,
P[a, m, i, e, s]= P(a | m) . P(m | i, e). P(i). P(e). P(s | i)
Din formula de mai sus,
- P(a | m) denotă probabilitatea condiționată ca studentul să obțină admitere pe baza notelor pe care le-a obținut la examen.
- P(m | i, e) reprezintă notele pe care studentul le va nota având în vedere nivelul său de IQ și dificultatea nivelului de examen.
- P(i) și P(e) reprezintă probabilitatea nivelului IQ și a nivelului examenului.
- P(s | i) este probabilitatea condiționată a Scorului de aptitudini al elevului, dat fiind nivelul său de IQ.
Cu următoarele probabilități calculate, putem găsi distribuția probabilă comună a întregii rețele bayesiene.
Calculul distribuției comune de probabilitate
Să calculăm acum JPD pentru două cazuri.
Cazul 1: Calculați probabilitatea ca, deși nivelul examenului este dificil, studentul având un nivel scăzut de IQ și un Scor de aptitudini scăzut, să reușească să promoveze examenul și să se asigure admiterea la universitate.
Din declarația de mai sus a problemei cuvântului, distribuția probabilă comună poate fi scrisă ca mai jos,
P[a=1, m=1, i=0, e=1, s=0]
Din tabelele de probabilitate condiționată de mai sus, valorile pentru condițiile date sunt introduse în formulă și sunt calculate după cum urmează.
P[a=1, m=1, i=0, e=0, s=0] = P(a=1 | m=1). P(m=1 | i=0, e=1) . P(i=0). P(e=1). P(s=0 | i=0)
= 0,1 * 0,1 * 0,8 * 0,3 * 0,75
= 0,0018
Cazul 2: Într-un alt caz, calculați probabilitatea ca studentul să aibă un nivel ridicat de IQ și un punctaj de aptitudini, examenul fiind ușor, dar nu reușește să promoveze și nu asigură admiterea la universitate.
Formula pentru JPD este dată de
P[a=0, m=0, i=1, e=0, s=1]
Prin urmare,
P[a=0, m=0, i=1, e=0, s=1]= P(a=0 | m=0). P(m=0 | i=1, e=0) . P(i=1). P(e=0). P(s=1 | i=1)
= 0,6 * 0,5 * 0,2 * 0,7 * 0,6
= 0,0252
Prin urmare, în acest fel, putem folosi rețele bayesiene și tabele de probabilitate pentru a calcula probabilitatea pentru diferite evenimente posibile care au loc.
Citește și: Idei și subiecte pentru proiecte de învățare automată
Concluzie
Există nenumărate aplicații pentru rețelele bayesiene în filtrarea spamului, căutarea semantică, regăsirea informațiilor și multe altele. De exemplu, cu un anumit simptom putem prezice probabilitatea apariției unei boli cu alți factori care contribuie la apariția bolii. Astfel, conceptul de rețea bayesiană este introdus în acest articol împreună cu implementarea sa cu un exemplu din viața reală.
Dacă sunteți curios să stăpâniți învățarea automată și inteligența artificială, stimulați-vă cariera cu un curs avansat de învățare automată și inteligență artificială cu IIIT-B și Universitatea John Moores din Liverpool.
Cum sunt implementate rețelele bayesiene?
O rețea bayesiană este un model grafic în care fiecare dintre noduri reprezintă variabile aleatorii. Fiecare nod este conectat la alte noduri prin arce direcționate. Fiecare arc reprezintă o distribuție de probabilitate condiționată a părinților în funcție de copii. Marginile direcționate reprezintă influența unui părinte asupra copiilor săi. Nodurile reprezintă de obicei unele obiecte din lumea reală, iar arcurile reprezintă o relație fizică sau logică între ele. Rețelele bayesiene sunt utilizate în multe aplicații precum recunoașterea automată a vorbirii, clasificarea documentelor/imaginilor, diagnosticul medical și robotica.
De ce este importantă rețeaua Bayesiană?
După cum știm, rețeaua Bayesiană este o parte importantă a învățării automate și a statisticilor. Este folosit în extragerea datelor și descoperirea științifică. Rețeaua bayesiană este un graf aciclic direcționat (DAG) cu noduri reprezentând variabile aleatoare și arcuri reprezentând influența directă. Rețeaua bayesiană este utilizată în diverse aplicații, cum ar fi analiza textului, detectarea fraudei, detectarea cancerului, recunoașterea imaginilor etc. În acest articol, vom discuta raționamentul în rețelele bayesiene. Bayesian Network este un instrument important pentru analiza trecutului, prezicerea viitorului și îmbunătățirea calității deciziilor. Rețeaua Bayesiană își are originile în statistici, dar acum este folosită de toți profesioniștii, inclusiv de cercetători, analiști de cercetare operațională, ingineri industriali, profesioniști în marketing, consultanți de afaceri și chiar manageri.
Ce este o rețea Bayesiană Rară?
O rețea Bayesiană Rară (SBN) este un tip special de rețea Bayesiană în care distribuția de probabilitate condiționată este un grafic rar. Ar putea fi adecvat să se utilizeze un SBN atunci când numărul de variabile este mare și/sau numărul de observații este mic. În general, rețelele bayesiene sunt cele mai utile atunci când sunteți interesat să explicați o observație sau un eveniment prin condiționarea unui număr de factori.