
Teorema Bayes în învățarea automată: introducere, cum se aplică și exemplu
Publicat: 2021-02-04Cuprins
Introducere: Ce este teorema Bayes?
Teorema Bayes este numită după matematicianul englez Thomas Bayes, care a lucrat intens în teoria deciziei, domeniul matematicii care implică probabilități. Teorema Bayes este, de asemenea, utilizată pe scară largă în învățarea automată, unde este o modalitate simplă și eficientă de a prezice clasele cu precizie și acuratețe. Metoda bayesiană de calcul a probabilităților condiționate este utilizată în aplicațiile de învățare automată care implică sarcini de clasificare.
O versiune simplificată a teoremei Bayes, cunoscută sub numele de Clasificarea Naive Bayes, este utilizată pentru a reduce timpul și costurile de calcul. În acest articol, vă prezentăm aceste concepte și discutăm despre aplicațiile teoremei Bayes în învățarea automată.
Alăturați-vă cursului de învățare automată online de la cele mai bune universități din lume – masterat, programe executive postuniversitare și program de certificat avansat în ML și AI pentru a vă accelera cariera.
De ce să folosiți teorema Bayes în Machine Learning?
Teorema Bayes este o metodă de determinare a probabilităților condiționate – adică probabilitatea ca un eveniment să se producă, având în vedere că un alt eveniment a avut deja loc. Deoarece o probabilitate condiționată include condiții suplimentare - cu alte cuvinte, mai multe date - poate contribui la rezultate mai precise.
Astfel, probabilitățile condiționate sunt o necesitate în determinarea predicțiilor și probabilităților precise în Machine Learning. Având în vedere că domeniul devine din ce în ce mai omniprezent într-o varietate de domenii, este important să înțelegem rolul algoritmilor și metodelor precum teorema Bayes în învățarea automată.
Înainte de a intra în teorema în sine, să înțelegem câțiva termeni printr-un exemplu. Să presupunem că un manager de librărie are informații despre vârsta și veniturile clienților săi. El vrea să știe cum sunt distribuite vânzările de cărți în trei categorii de vârstă de clienți: tineri (18-35), de vârstă mijlocie (35-60) și seniori (60+).

Să numim datele noastre X. În terminologia bayesiană, X se numește dovezi. Avem o ipoteză H, unde avem un X care aparține unei anumite clase C.
Scopul nostru este de a determina probabilitatea condiționată a ipotezei noastre H dat X, adică P(H | X).
În termeni simpli, determinând P(H | X), obținem probabilitatea ca X să aparțină clasei C, dat fiind X. X are atribute de vârstă și venit – să spunem, de exemplu, 26 de ani cu un venit de 2000 USD. H este ipoteza noastră că clientul va cumpăra cartea.
Acordați o atenție deosebită următorilor patru termeni:
- Dovezi – După cum sa discutat mai devreme, P(X) este cunoscută ca dovadă. Este pur și simplu probabilitatea ca clientul, în acest caz, să aibă vârsta de 26 de ani și să câștige 2000 USD.
- Probabilitatea anterioară – P(H), cunoscută sub numele de probabilitate anterioară, este probabilitatea simplă a ipotezei noastre – și anume, că clientul va cumpăra o carte. Această probabilitate nu va fi furnizată cu nicio intrare suplimentară în funcție de vârstă și venit. Deoarece calculul se face cu mai puține informații, rezultatul este mai puțin precis.
- Probabilitatea posterioară – P(H | X) este cunoscută ca probabilitate posterioară. Aici, P(H | X) este probabilitatea ca clientul să cumpere o carte (H) având în vedere X (că are 26 de ani și câștigă 2000 USD).
- Probabilitate – P(X | H) este probabilitatea probabilității. În acest caz, având în vedere că știm că clientul va cumpăra cartea, probabilitatea probabilă este probabilitatea ca clientul să aibă vârsta de 26 de ani și să aibă un venit de 2000 USD.
Având în vedere acestea, teorema Bayes afirmă:
P(H | X) = [ P(X | H) * P(H) ] / P(X)
Observați apariția celor patru termeni de mai sus în teoremă – probabilitate posterioară, probabilitate probabilitate, probabilitate anterioară și dovezi.
Citește: Bayes naiv explicat
Cum se aplică teorema Bayes în învățarea automată
Clasificatorul Naive Bayes, o versiune simplificată a teoremei Bayes, este folosit ca algoritm de clasificare pentru a clasifica datele în diferite clase cu precizie și viteză.
Să vedem cum poate fi aplicat Naive Bayes Clasifier ca algoritm de clasificare.
- Luați în considerare un exemplu general: X este un vector format din 'n' atribute, adică X = {x1, x2, x3, …, xn}.
- Să presupunem că avem clase „m” {C1, C2, …, Cm}. Clasificatorul nostru va trebui să prezică X aparține unei anumite clase. Clasa care oferă cea mai mare probabilitate posterioară va fi aleasă ca cea mai bună clasă. Deci matematic, clasificatorul va prezice pentru clasa Ci dacă P(Ci | X) > P(Cj | X). Aplicarea teoremei Bayes:
P(Ci | X) = [ P(X | Ci) * P(Ci) ] / P(X)
- P(X), fiind independent de condiție, este constantă pentru fiecare clasă. Deci, pentru a maximiza P(Ci | X), trebuie să maximizăm [P(X | Ci) * P(Ci)]. Considerând că fiecare clasă este la fel de probabilă, avem P(C1) = P(C2) = P(C3) … = P(Cn). Deci, în cele din urmă, trebuie să maximizăm doar P(X | Ci).
- Deoarece setul de date tipic mare este probabil să aibă mai multe atribute, este costisitor din punct de vedere computațional să se efectueze operația P(X | Ci) pentru fiecare atribut. Aici intervine independența condiționată de clasă pentru a simplifica problema și a reduce costurile de calcul. Prin independență condiționată de clasă, înțelegem că considerăm că valorile atributului sunt independente unele de altele în mod condiționat. Aceasta este Clasificarea Naive Bayes.
P(Xi | C) = P(x1 | C) * P(x2 | C) *… * P(xn | C)
Acum este ușor să calculați probabilitățile mai mici. Un lucru important de remarcat aici: deoarece xk aparține fiecărui atribut, trebuie să verificăm și dacă atributul cu care avem de-a face este categoric sau continuu .
- Dacă avem un atribut categoric , lucrurile sunt mai simple. Putem doar număra numărul de instanțe ale clasei Ci constând din valoarea xk pentru atributul k și apoi îl împărțim la numărul de instanțe ale clasei Ci.
- Dacă avem un atribut continuu, având în vedere că avem o funcție de distribuție normală, aplicăm următoarea formulă, cu media ? și abaterea standard?:
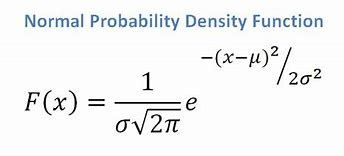

Sursă
În cele din urmă, vom avea P(x | Ci) = F(xk, ?k, ?k).
- Acum, avem toate valorile de care avem nevoie pentru a folosi teorema Bayes pentru fiecare clasă Ci. Clasa noastră prezisă va fi clasa care realizează cea mai mare probabilitate P(X | Ci) * P(Ci).
Exemplu: Clasificarea predictivă a clienților unei librării
Avem următorul set de date de la o librărie:
| Vârstă | Sursa de venit | Student | Credit_Rating | Cumpără_Carte |
| Tineret | Înalt | Nu | Corect | Nu |
| Tineret | Înalt | Nu | Excelent | Nu |
| De vârstă mijlocie | Înalt | Nu | Corect | da |
| Senior | Mediu | Nu | Corect | da |
| Senior | Scăzut | da | Corect | da |
| Senior | Scăzut | da | Excelent | Nu |
| De vârstă mijlocie | Scăzut | da | Excelent | da |
| Tineret | Mediu | Nu | Corect | Nu |
| Tineret | Scăzut | da | Corect | da |
| Senior | Mediu | da | Corect | da |
| Tineret | Mediu | da | Excelent | da |
| De vârstă mijlocie | Mediu | Nu | Excelent | da |
| De vârstă mijlocie | Înalt | da | Corect | da |
| Senior | Mediu | Nu | Excelent | Nu |
Avem atribute precum vârsta, venitul, studentul și ratingul de credit. Clasa noastră, buys_book, are două rezultate: Da sau Nu.
Scopul nostru este de a clasifica pe baza următoarelor atribute:
X = {vârsta = tineret, student = da, venit = mediu, rating_credit = corect}.
După cum am arătat mai devreme, pentru a maximiza P(Ci | X), trebuie să maximizăm [ P(X | Ci) * P(Ci) ] pentru i = 1 și i = 2.
Prin urmare, P(buys_book = yes) = 9/14 = 0,643
P(carte_cumpără = nu) = 5/14 = 0,357
P(vârsta = tineret | buys_book = yes) = 2/9 = 0,222
P(varsta = tineret | buys_book = nu) =3/5 = 0,600
P(venit = mediu | buys_book = yes) = 4/9 = 0,444
P(venit = mediu | buys_book = nu) = 2/5 = 0,400
P(student = da | buys_book = yes) = 6/9 = 0,667
P(student = da | buys_book = nu) = 1/5 = 0,200
P(credit_evaluare = corect | buys_book = yes) = 6/9 = 0,667
P(credit_evaluare = corect | buys_book = nu) = 2/5 = 0,400
Folosind probabilitățile mai sus calculate, avem
P(X | buys_book = yes) = 0,222 x 0,444 x 0,667 x 0,667 = 0,044
În mod similar,
P(X | buys_book = nu) = 0,600 x 0,400 x 0,200 x 0,400 = 0,019
Ce clasă oferă Ci maximul P(X|Ci)*P(Ci)? Calculăm:
P(X | cumpără_book = yes)* P(buys_book = yes) = 0,044 x 0,643 = 0,028
P(X | cartea_cumpără = nu)* P(carte_cumpără = nu) = 0,019 x 0,357 = 0,007
Comparând cele două de mai sus, deoarece 0,028 > 0,007, Naive Bayes Classifier prezice că clientul cu atributele menționate mai sus va cumpăra o carte.
Checkout: Idei și subiecte pentru proiecte de învățare automată
Clasificatorul bayesian este o metodă bună?
Algoritmii bazați pe teorema Bayes în învățarea automată oferă rezultate comparabile cu alți algoritmi, iar clasificatorii bayesieni sunt în general considerați metode simple de înaltă precizie. Cu toate acestea, trebuie avut grijă să ne amintim că clasificatorii bayesieni sunt deosebit de adecvați acolo unde presupunerea independenței condiționate de clasă este validă și nu în toate cazurile. O altă preocupare practică este că obținerea tuturor datelor de probabilitate poate să nu fie întotdeauna fezabilă.
Concluzie
Teorema Bayes are multe aplicații în învățarea automată, în special în problemele bazate pe clasificare. Aplicarea acestei familii de algoritmi în învățarea automată implică familiarizarea cu termeni precum probabilitatea anterioară și probabilitatea posterioară. În acest articol, am discutat elementele de bază ale teoremei Bayes, utilizarea acesteia în problemele de învățare automată și am lucrat printr-un exemplu de clasificare.
Deoarece teorema Bayes formează o parte esențială a algoritmilor bazați pe clasificare în Machine Learning, puteți afla mai multe despre programul de certificat avansat al upGrad în Machine Learning și NLP . Acest curs a fost creat ținând cont de diferitele tipuri de studenți interesați de Machine Learning, oferind mentorat 1-1 și multe altele.
De ce folosim teorema Bayes în Machine Learning?
Teorema Bayes este o metodă de calcul a probabilităților condiționate sau a probabilității ca un eveniment să apară dacă altul a avut loc anterior. O probabilitate condiționată poate duce la rezultate mai precise prin includerea unor condiții suplimentare - cu alte cuvinte, mai multe date. Pentru a obține estimări și probabilități corecte în Machine Learning, sunt necesare probabilități condiționate. Având în vedere prevalența în creștere a domeniului într-o gamă largă de domenii, este esențial să înțelegem importanța algoritmilor și a abordărilor precum teorema Bayes în învățarea automată.
Clasificatorul Bayesian este o alegere bună?
În învățarea automată, algoritmii bazați pe teorema Bayes produc rezultate care sunt comparabile cu cele ale altor metode, iar clasificatorii bayesieni sunt considerați pe scară largă ca abordări simple de înaltă precizie. Cu toate acestea, este important să rețineți că clasificatorii bayesieni sunt utilizați cel mai bine atunci când condiția independenței condiționale de clasă este corectă, nu în toate circumstanțele. O altă considerație este că obținerea tuturor datelor de probabilitate poate să nu fie întotdeauna posibilă.
Cum poate fi aplicată practic teorema Bayes?
Teorema Bayes calculează probabilitatea de apariție pe baza unor noi dovezi care sunt sau ar putea fi legate de aceasta. Metoda poate fi folosită și pentru a vedea modul în care informațiile noi ipotetice afectează probabilitatea unui eveniment, presupunând că noile informații sunt adevărate. Luați, de exemplu, o singură carte selectată dintr-un pachet de 52 de cărți. Probabilitatea ca cardul să devină rege este 4 împărțit la 52, sau 1/13, sau aproximativ 7,69 la sută. Rețineți că pachetul conține patru regi. Să presupunem că s-a dezvăluit că cartea aleasă este o carte cu față. Deoarece există 12 cărți de față într-un pachet, probabilitatea ca cartea aleasă să fie un rege este 4 împărțit la 12, sau aproximativ 33,3 la sută.