
6 funcții de schimbare a jocului ale Apache Spark în 2022 [Cum ar trebui să utilizați]
Publicat: 2021-01-07De când Big Data a luat cu asalt lumea tehnologiei și a afacerilor, a existat o creștere enormă a instrumentelor și platformelor Big Data, în special a Apache Hadoop și Apache Spark. Astăzi, ne vom concentra numai pe Apache Spark și ne vom discuta pe larg despre beneficiile și aplicațiile sale de afaceri.
Apache Spark a ajuns în lumina reflectoarelor în 2009 și, de atunci, și-a făcut treptat o nișă în industrie. Potrivit Apache org., Spark este un „motor de analiză unificat fulgerător” conceput pentru procesarea unor cantități colosale de Big Data. Datorită unei comunități active, astăzi, Spark este una dintre cele mai mari platforme open-source Big Data din lume.
Cuprins
Ce este Apache Spark?
Dezvoltat inițial în AMPLab-ul Universității din California (Berkeley), Spark a fost conceput ca un motor robust de procesare pentru datele Hadoop, cu un accent special pe viteză și ușurință în utilizare. Este o alternativă open-source la MapReduce de la Hadoop. În esență, Spark este un cadru paralel de procesare a datelor care poate colabora cu Apache Hadoop pentru a facilita dezvoltarea lină și rapidă a aplicațiilor sofisticate Big Data pe Hadoop.
Spark vine cu o gamă largă de biblioteci pentru algoritmi de învățare automată (ML) și algoritmi grafici. Nu doar atât, acceptă, de asemenea, streaming în timp real și aplicații SQL prin Spark Streaming și, respectiv, Shark. Cea mai bună parte a utilizării Spark este că puteți scrie aplicații Spark în Java, Scala sau chiar Python, iar aceste aplicații vor rula de aproape zece ori mai repede (pe disc) și de 100 de ori mai rapid (în memorie) decât aplicațiile MapReduce.
Apache Spark este destul de versatil, deoarece poate fi implementat în multe moduri și oferă, de asemenea, legături native pentru limbajele de programare Java, Scala, Python și R. Acceptă SQL, procesarea graficelor, fluxul de date și învățarea automată. Acesta este motivul pentru care Spark este utilizat pe scară largă în diverse sectoare ale industriei, inclusiv bănci, companii de telecomunicații, firme de dezvoltare de jocuri, agenții guvernamentale și, desigur, în toate companiile de top din lumea tehnologiei - Apple, Facebook, IBM și Microsoft.
Cele mai bune 6 caracteristici ale Apache Spark
Caracteristicile care fac din Spark una dintre cele mai utilizate platforme Big Data sunt:

1. Iluminare-viteză de procesare rapidă
Procesarea Big Data se referă la procesarea unor volume mari de date complexe. Prin urmare, când vine vorba de procesarea Big Data, organizațiile și întreprinderile își doresc astfel de cadre care pot procesa cantități masive de date la viteză mare. După cum am menționat mai devreme, aplicațiile Spark pot rula până la 100 de ori mai rapid în memorie și de 10 ori mai rapid pe disc în clusterele Hadoop.
Se bazează pe Resilient Distributed Dataset (RDD) care îi permite lui Spark să stocheze în mod transparent datele în memorie și să le citească/să scrie pe disc numai dacă este necesar. Acest lucru ajută la reducerea cea mai mare parte a timpului de citire și scriere a discului în timpul procesării datelor.
2. Ușurință în utilizare
Spark vă permite să scrieți aplicații scalabile în Java, Scala, Python și R. Astfel, dezvoltatorii au posibilitatea de a crea și rula aplicații Spark în limbajele lor de programare preferate. Mai mult, Spark este echipat cu un set încorporat de peste 80 de operatori de nivel înalt. Puteți utiliza Spark în mod interactiv pentru a interoga date din Scala, Python, R și shell-uri SQL.
3. Oferă suport pentru analize sofisticate
Spark nu numai că acceptă operațiuni simple de „hartă” și „reducere”, dar acceptă și interogări SQL, date în flux și analize avansate, inclusiv algoritmi ML și grafic. Vine cu un teanc puternic de biblioteci, cum ar fi SQL & DataFrames și MLlib (pentru ML), GraphX și Spark Streaming. Ceea ce este fascinant este că Spark vă permite să combinați capacitățile tuturor acestor biblioteci într-un singur flux de lucru/aplicație.
4. Procesarea fluxului în timp real
Spark este conceput pentru a gestiona fluxul de date în timp real. În timp ce MapReduce este construit pentru a gestiona și procesa datele care sunt deja stocate în clustere Hadoop, Spark le poate face pe ambele și, de asemenea, poate manipula datele în timp real prin Spark Streaming.
Spre deosebire de alte soluții de streaming, Spark Streaming poate recupera munca pierdută și poate oferi semantica exactă imediată, fără a necesita cod sau configurație suplimentară. În plus, vă permite, de asemenea, să refolosiți același cod pentru procesarea loturilor și a fluxului și chiar pentru a asocia datele în flux cu datele istorice.
5. Este flexibil
Spark poate rula independent în modul cluster și poate rula și pe Hadoop YARN, Apache Mesos, Kubernetes și chiar și în cloud. În plus, poate accesa diverse surse de date. De exemplu, Spark poate rula pe managerul de cluster YARN și poate citi orice date Hadoop existente. Poate citi din orice sursă de date Hadoop, cum ar fi HBase, HDFS, Hive și Cassandra. Acest aspect al Spark îl face un instrument ideal pentru migrarea aplicațiilor pur Hadoop, cu condiția ca cazul de utilizare al aplicațiilor să fie compatibil cu Spark.
6. Comunitate activă și în expansiune
Dezvoltatorii din peste 300 de companii au contribuit la proiectarea și construirea Apache Spark. Încă din 2009, peste 1200 de dezvoltatori au contribuit activ la a face Spark ceea ce este astăzi! Desigur, Spark este susținut de o comunitate activă de dezvoltatori care lucrează pentru a-și îmbunătăți continuu funcțiile și performanța. Pentru a contacta comunitatea Spark, puteți folosi listele de corespondență pentru orice întrebări și puteți participa, de asemenea, la grupuri de întâlniri și conferințe Spark.
Anatomia aplicațiilor Spark
Fiecare aplicație Spark cuprinde două procese de bază – un proces driver primar și o colecție de procese executorii .
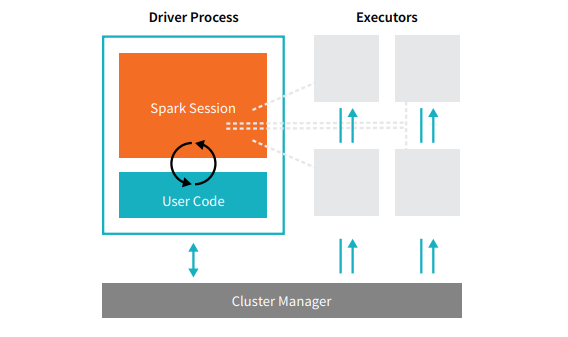
Sursă
Procesul driver care se află pe un nod din cluster este responsabil pentru rularea funcției main(). De asemenea, se ocupă de alte trei sarcini – menținerea informațiilor despre aplicația Spark, răspunsul la codul sau intrarea unui utilizator și analizarea, distribuirea și programarea lucrărilor între executori. Procesul driver formează inima unei aplicații Spark – conține și menține toate informațiile critice care acoperă durata de viață a aplicației Spark.

Executorii sau procesele executorii sunt elemente secundare care trebuie să execute sarcina care le-a fost atribuită de șofer. Practic, fiecare executant îndeplinește două funcții cruciale - rulează codul atribuit de driver și raportează starea calculului (pe acel executor) nodului driver. Utilizatorii pot decide și configura câți executori ar trebui să aibă fiecare nod.
Într-o aplicație Spark, managerul de cluster controlează toate mașinile și alocă resurse aplicației. Aici, managerul de cluster poate fi oricare dintre managerii de cluster de bază ai Spark, inclusiv YARN (managerul de cluster autonom al Spark) sau Mesos. Aceasta înseamnă că un cluster poate rula mai multe aplicații Spark simultan.
Aplicații Apache Spark din lumea reală
Spark este o platformă Big Dara de top și utilizată pe scară largă în industria modernă. Unele dintre cele mai apreciate exemple din lumea reală de aplicații Apache Spark sunt:
Spark pentru Machine Learning
Apache Spark se mândrește cu o bibliotecă scalabilă de învățare automată – MLlib. Această bibliotecă este concepută în mod explicit pentru simplitate, scalabilitate și pentru facilitarea integrării perfecte cu alte instrumente. MLlib nu numai că posedă scalabilitatea, compatibilitatea cu limbajul și viteza Spark, dar poate, de asemenea, să realizeze o serie de sarcini de analiză avansate, cum ar fi clasificarea, gruparea, reducerea dimensionalității. Datorită MLlib, Spark poate fi folosit pentru analiza predictivă, analiza sentimentelor, segmentarea clienților și inteligența predictivă.
O altă caracteristică impresionantă a Apache Spark se află în domeniul securității rețelei. Spark Streaming permite utilizatorilor să monitorizeze pachetele de date în timp real înainte de a le împinge în stocare. În timpul acestui proces, poate identifica cu succes orice activități suspecte sau rău intenționate care apar din surse cunoscute de amenințare. Chiar și după ce pachetele de date sunt trimise la stocare, Spark folosește MLlib pentru a analiza datele în continuare și pentru a identifica riscurile potențiale pentru rețea. Această caracteristică poate fi folosită și pentru detectarea fraudelor și a evenimentelor.
Spark pentru Fog Computing
Apache Spark este un instrument excelent pentru calculul de ceață, în special atunci când se referă la Internet of Things (IoT). IoT se bazează în mare măsură pe conceptul de procesare paralelă la scară largă. Deoarece rețeaua IoT este formată din mii și milioane de dispozitive conectate, datele generate de această rețea în fiecare secundă sunt dincolo de înțelegere.
Desigur, pentru a procesa volume atât de mari de date produse de dispozitivele IoT, aveți nevoie de o platformă scalabilă care să accepte procesarea paralelă. Și ce mai bun decât arhitectura robustă și capacitățile de calcul a ceață ale Spark pentru a gestiona cantități atât de mari de date!
Fog computing descentralizează datele și stocarea și, în loc să utilizeze procesarea în cloud, efectuează funcția de procesare a datelor la marginea rețelei (înglobate în principal în dispozitivele IoT).
Pentru a face acest lucru, calculul de ceață necesită trei capacități, și anume, latență scăzută, procesarea paralelă a ML și algoritmi de analiză a graficelor complecși - fiecare dintre acestea prezentând în Spark. În plus, prezența Spark Streaming, Shark (un instrument de interogare interactiv care poate funcționa în timp real), MLlib și GraphX (un motor de analiză a graficelor) îmbunătățește și mai mult capacitatea de calcul a ceață a Spark.
Spark pentru analiză interactivă
Spre deosebire de MapReduce, sau Hive, sau Pig, care au o viteză de procesare relativ scăzută, Spark se poate lăuda cu analize interactive de mare viteză. Este capabil să gestioneze interogări exploratorii fără a necesita eșantionarea datelor. De asemenea, Spark este compatibil cu aproape toate limbajele de dezvoltare populare, inclusiv R, Python, SQL, Java și Scala.
Cea mai recentă versiune de Spark – Spark 2.0 – oferă o nouă funcționalitate cunoscută sub numele de Structured Streaming. Cu această caracteristică, utilizatorii pot rula interogări structurate și interactive împotriva datelor în flux în timp real.
Utilizatorii Spark
Acum că știți bine caracteristicile și abilitățile Spark, să vorbim despre cei patru utilizatori importanți ai Spark!
1. Yahoo
Yahoo folosește Spark pentru două dintre proiectele sale, unul pentru personalizarea paginilor de știri pentru vizitatori și celălalt pentru efectuarea de analize pentru publicitate. Pentru a personaliza paginile de știri, Yahoo folosește algoritmi ML avansați care rulează pe Spark pentru a înțelege interesele, preferințele și nevoile utilizatorilor individuali și pentru a clasifica poveștile în consecință.
Pentru al doilea caz de utilizare, Yahoo folosește capacitatea interactivă a lui Hive on Spark (pentru a se integra cu orice instrument care se conectează la Hive) pentru a vedea și a interoga datele analitice publicitare ale Yahoo colectate pe Hadoop.
2. Uber
Uber folosește Spark Streaming în combinație cu Kafka și HDFS pentru a ETL (extrage, transforma și încărca) cantități mari de date în timp real ale evenimentelor discrete în date structurate și utilizabile pentru analize ulterioare. Aceste date ajută Uber să elaboreze soluții îmbunătățite pentru clienți.

3. Conviva
În calitate de companie de streaming video, Conviva obține în medie peste 4 milioane de fluxuri video în fiecare lună, ceea ce duce la o creștere masivă a clienților. Această provocare este agravată și mai mult de problema gestionării traficului video live. Pentru a combate aceste provocări în mod eficient, Conviva folosește Spark Streaming pentru a afla condițiile rețelei în timp real și pentru a-și optimiza traficul video în consecință. Acest lucru permite Conviva să ofere utilizatorilor o experiență de vizionare consistentă și de înaltă calitate.
4. Pinterest
Pe Pinterest, utilizatorii își pot fixa subiectele preferate după cum doresc și când navighează pe web și pe rețelele sociale. Pentru a oferi clienților o experiență personalizată și îmbunătățită, Pinterest folosește capacitățile ETL ale Spark pentru a identifica nevoile și interesele unice ale utilizatorilor individuali și pentru a le oferi recomandări relevante pe Pinterest.
Concluzie
În concluzie, Spark este o platformă Big Data extrem de versatilă, cu funcții care sunt create pentru a impresiona. Deoarece este un cadru open-source, se îmbunătățește și evoluează continuu, cu noi caracteristici și funcționalități fiind adăugate la acesta. Pe măsură ce aplicațiile Big Data devin mai diverse și mai expansive, la fel și cazurile de utilizare ale Apache Spark.
Dacă sunteți interesat să aflați mai multe despre Big Data, consultați programul nostru PG Diploma în Dezvoltare Software Specializare în Big Data, care este conceput pentru profesioniști care lucrează și oferă peste 7 studii de caz și proiecte, acoperă 14 limbaje și instrumente de programare, practică practică. ateliere de lucru, peste 400 de ore de învățare riguroasă și asistență pentru plasarea unui loc de muncă cu firme de top.
Consultați celelalte cursuri ale noastre de inginerie software la upGrad.