
Apache Kafka Architecture: Ghid cuprinzător pentru începători [2022]
Publicat: 2021-12-23Înainte de a ne aprofunda în detaliile arhitecturii Apache Kafka, este pertinent să aruncăm o lumină asupra motivului pentru care Kafka face titluri în primul rând. Pentru început, Apache Kafka își găsește utilizarea în principal în arhitecturile de date în flux în timp real pentru furnizarea de analize în timp real. Durabil, rapid, scalabil și tolerant la erori, sistemul de mesagerie de publicare-abonare de la Kafka are cazuri de utilizare pentru lucruri precum urmărirea datelor senzorilor IoT sau urmărirea apelurilor de serviciu.
Companii precum LinkedIn, Netflix, Microsoft, Uber, Spotify, Goldman Sachs, Cisco, PayPal și multe altele folosesc Apache Kafka pentru procesarea datelor de streaming în timp real. De exemplu, LinkedIn, de unde provine Kafka, îl folosește pentru a urmări valorile operaționale și datele de activitate. De asemenea, pentru Netflix, Apache Kafka este standardul de facto pentru nevoile sale de mesagerie, evenimente și procesare a fluxurilor.
Învață cursuri online de dezvoltare software de la cele mai bune universități din lume. Câștigă programe Executive PG, programe avansate de certificat sau programe de master pentru a-ți accelera cariera.
Utilitatea Apache Kafka este mai bine apreciată cu o înțelegere a arhitecturii Apache Kafka și a componentelor sale de bază. Deci, haideți să explorăm detaliile arhitecturii lui Kafka.
Cuprins
Concepte fundamentale de arhitectură Kafka
Următoarele concepte sunt de bază pentru înțelegerea arhitecturii Apache Kafka:
1. Subiecte
Subiectele Kafka definesc canalele prin care datele sunt transmise în flux. Astfel, producătorii publică mesaje la subiecte, iar consumatorii citesc mesaje din subiectele pe care le abonează. Nu există o limitare a numărului de subiecte create într-un cluster Kafka și un nume unic identifică fiecare subiect.

2. Brokerii
Brokerii sunt servere dintr-un cluster Kafka care funcționează ca containere și dețin mai multe subiecte cu partiții distincte. Un ID unic întreg identifică brokerii dintr-un cluster Kafka, iar o conexiune cu oricare dintre acești brokeri înseamnă conectarea cu întregul cluster.
3. Despărțitori
Subiectele Kafka sunt împărțite în multe părți cunoscute sub numele de partiții. Partițiile sunt separate în ordine și permit mai multor consumatori să citească date dintr-un anumit subiect în paralel. Partițiile unui subiect sunt distribuite pe mai multe servere din clusterul Kafka și fiecare server gestionează datele și solicitările pentru lotul său de partiții. Mesajele ajung la broker și la o cheie, iar cheia determină partiția la care va merge respectivul mesaj. Prin urmare, mesajele cu aceeași cheie merg la aceeași partiție. În cazul în care cheia este nespecificată, partiția este decisă după o abordare round-robin.
4. Replici
În Kafka, replicile sunt ca copiile de rezervă ale partițiilor pentru a asigura nicio pierdere de date în cazul unei închideri planificate sau a unei eșecuri. Cu alte cuvinte, replicile sunt copii ale partițiilor.
5. Compensații partiții
Deoarece mesajele sau înregistrările din Kafka sunt alocate partițiilor, fiecare înregistrare este prevăzută cu un offset pentru a specifica poziția sa în cadrul partiției. Astfel, valoarea de offset asociată unei înregistrări ajută la identificarea ei ușoară în cadrul partiției. O compensare a partiției are semnificație numai în cadrul acelei partiții particulare și, deoarece înregistrările sunt adăugate la capete de partiție, înregistrările mai vechi vor avea valori mai mici ale decalajului.
6. Producători
Producătorii Kafka publică mesaje la unul sau mai multe subiecte și trimit date către clusterul Kafka. De îndată ce un producător publică un mesaj la un subiect Kafka, brokerul primește mesajul și îl adaugă la o anumită partiție. Apoi, producătorii pot alege partiția în care doresc să își publice mesajul.
7. Consumatori și grupuri de consumatori
Consumatorii citesc mesaje din clusterul Kafka. Când un consumator este gata să primească mesajul, datele sunt extrase de la broker. Consumatorii aparțin unui grup de consumatori și fiecare consumator dintr-un anumit grup este responsabil pentru citirea unui subset al partițiilor fiecărui subiect la care este abonat.
8. Lider și urmaș
Fiecare partiție Kafka are un server care joacă rolul de lider. Liderul efectuează toate sarcinile de citire și scriere pentru partiția respectivă. Pe de altă parte, sarcina adeptului este de a replica datele liderului. Când un lider dintr-o anumită partiție eșuează, unul dintre nodurile urmăritoare își asumă rolul liderului. O partiție poate avea niciunul sau mai mulți adepți.
Următoarea diagramă este o prezentare simplificată a interrelațiilor dintre componentele arhitecturii Apache Kafka discutate mai sus.
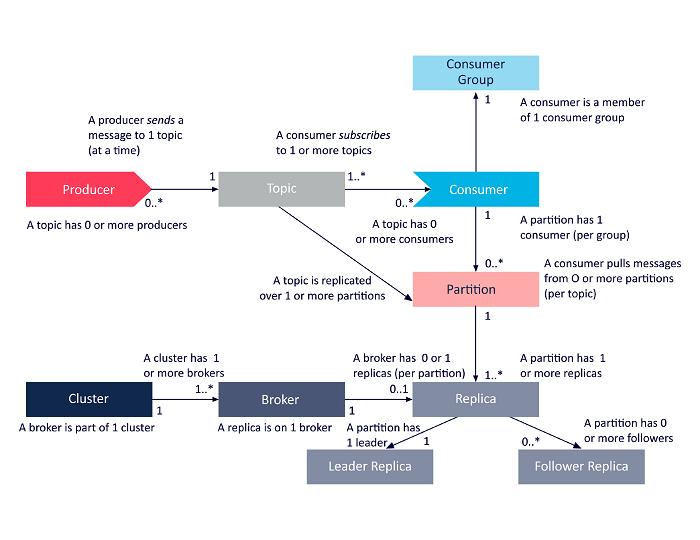
Sursă
Apache Kafka Cluster Architecture
Iată o privire detaliată asupra principalelor componente arhitecturale Kafka:

1. Brokeri Kafka
Clusterele Kafka conțin de obicei mai multe noduri cunoscute sub numele de brokeri. Brokerii mențin echilibrul de sarcină. Fiecare broker Kafka poate gestiona sute și mii de citiri și scrieri în fiecare secundă. Un broker servește ca lider pentru o anumită partiție. Liderul are unul sau mai mulți adepți, cu datele despre lider replicate între adepții acelei partiții particulare.
Adepții trebuie să fie la curent cu datele liderului. Liderul, la rândul său, ține evidența adepților care sunt sincronizați cu acesta. Dacă un urmăritor nu ajunge din urmă cu liderul sau nu mai este în viață, acesta este eliminat din lista de replici în sincronizare asociată cu liderul respectiv. Un nou lider este ales dintre adepți la moartea liderului, iar ZooKeeper supraveghează alegerile. Deoarece brokerii sunt apatrizi, ZooKeeper își menține starea clusterului. Nodurile dintr-un cluster trimit mesaje de ritm cardiac către ZooKeeper pentru a-l informa pe acesta din urmă că sunt în viață.
2. Producători Kafka
Producătorii Kafka trimit direct date brokerilor care joacă rolul de lider pentru o anumită partiție. Brokerii sau nodurile clusterelor Kafka îi ajută pe producători să trimită mesaje directe. Ei fac acest lucru răspunzând la solicitările de metadate pe care serverele sunt vii și la starea live a liderilor de partiție ai unui subiect, permițând producătorului să-și direcționeze cererile în consecință. Producătorul decide ce partiție dorește să publice mesajele. Mesajele din Kafka sunt trimise în loturi, numite loturi de înregistrare. Producătorii colectează mesaje în memorie și le trimit în loturi fie după ce a trecut o perioadă fixă, fie după ce s-a acumulat un anumit număr de mesaje.
3. Consumatorii Kafka
Consumatorii Kafka emit cereri brokerilor indicând partițiile pe care dorește să le consume. Consumatorul specifică offset-ul partiției în cererea sa și primește o bucată de jurnal (începând din poziția offset) de la broker. Un jurnal conține înregistrările pentru o perioadă configurabilă cunoscută sub numele de perioadă de păstrare.
De asemenea, consumatorii pot re-consuma date atâta timp cât jurnalul conține datele. Consumatorii Kafka lucrează la o abordare bazată pe tragere, ceea ce înseamnă că brokerii nu transmit imediat date către consumatori. În schimb, în primul rând, consumatorii trimit cereri brokerilor, semnalând că sunt gata să consume date. Prin urmare, sistemul bazat pe tragere asigură că consumatorii nu sunt copleșiți de mesaje și pot ajunge din urmă dacă rămân în urmă.
Mai jos este o diagramă simplificată a arhitecturii Apache Kafka:
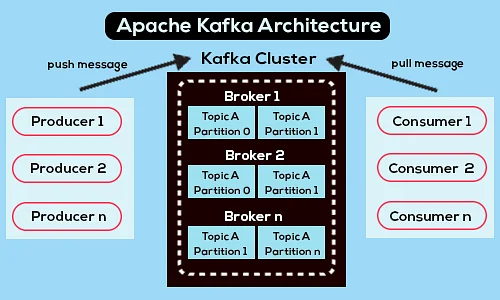
Sursă
Aflați mai multe despre Apache Kafka.
Arhitectura API Apache Kafka
Apache Kafka are patru API-uri cheie - Streams API, Connector API, Producer API și Consumer API. Să vedem ce rol trebuie să joace fiecare în îmbunătățirea capacităților Apache Kafka:
1. Streams API
API-ul Streams de la Kafka permite unei aplicații să prelucreze date folosind un algoritm de procesare a fluxurilor. Folosind Streams API, aplicațiile pot consuma fluxuri de intrare de la unul sau mai multe subiecte, le pot procesa cu operațiuni de flux, pot produce fluxuri de ieșire și, eventual, le pot trimite la unul sau mai multe subiecte. Astfel, Streams API facilitează transformarea fluxurilor de intrare în fluxuri de ieșire.
2. Connector API
API-ul Connector de la Kafka este util pentru construirea, rularea și gestionarea producătorilor și consumatorilor reutilizabili care conectează subiectele Kafka la sistemele sau aplicațiile de date existente. De exemplu, un conector la o bază de date relațională ar putea capta toate actualizările și se poate asigura că modificările sunt disponibile într-un subiect Kafka.

3. Producer API
Producer API-ul Kafka permite aplicațiilor să publice un flux de înregistrări pentru subiectele Kafka.
4. Consumer API
API-ul pentru consumatori Kafka Permite aplicațiilor să se aboneze la subiectele Kafka. De asemenea, permite aplicațiilor să proceseze fluxurile de înregistrare care sunt produse pentru acele subiecte Kafka.
Pas înainte
Arhitectura Apache Kafka este doar o mică parte din vastul repertoriu de instrumente și limbaje cu care se ocupă dezvoltatorii de software. Să presupunem că sunteți un dezvoltator de software în devenire cu o înclinație către Big Data. În acest caz, puteți face primul pas către obiectivele dvs. cu Programul Executive PG de la upGrad în Dezvoltare Software – Specializare în Big Data .
Iată o prezentare generală a programului cu câteva aspecte cheie:
- PGP executiv de la IIIT Bangalore cu certificări în Data Science și Cloud Infrastructure
- Sesiuni online și prelegeri live cu peste 400 de ore de conținut
- 7+ studii de caz și proiecte
- Peste 14 limbaje și instrumente de programare
- Suport în carieră la 360 de grade
- Rețea între egali și industrie
Înscrieți-vă pentru mai multe detalii despre curs!
Pentru ce se folosește Kafka?
Apache Kafka este folosit în principal pentru a construi conducte de date în flux în timp real și aplicații care se adaptează la aceste fluxuri de date. Permite atât stocarea, cât și analiza datelor în timp real și istorice printr-o combinație de mesagerie, stocare și procesare în flux.
Este Kafka un cadru?
Apache Kafka este un software open-source care oferă un cadru pentru stocarea, citirea și analiza datelor în flux. Deoarece este open-source, Kafka poate fi folosit gratuit cu mulți dezvoltatori și utilizatori care contribuie la noi funcții, actualizări și suport pentru noii utilizatori.
De ce avem nevoie de fluxuri Kafka?
Kafka Streams este o bibliotecă client pentru crearea de microservicii și aplicații de streaming în care datele de intrare și datele de ieșire sunt stocate în cluster-ul Apache Kafka. Pe de o parte, oferă beneficiile tehnologiei de cluster pe partea serverului Apache Kafka. Pe de altă parte, simplifică scrierea și implementarea aplicațiilor standard Scala și Java pe partea clientului.