
Apache Kafka: arhitectură, concepte, caracteristici și aplicații
Publicat: 2021-03-09Kafka a fost lansat în 2011, totul datorită LinkedIn. De atunci, a cunoscut o creștere incredibilă până la punctul în care majoritatea companiilor listate în Fortune 500 îl folosesc acum. Este un produs extrem de scalabil, durabil și cu un randament ridicat, care poate gestiona cantități mari de date în flux. Dar acesta este singurul motiv din spatele popularității sale extraordinare? Ei bine, nu. Nici măcar nu am început cu caracteristicile sale, calitatea pe care o produce și ușurința pe care o oferă utilizatorilor.
Ne vom scufunda în asta mai târziu. Să înțelegem mai întâi ce este Kafka și unde este folosit.
Cuprins
Ce este Apache Kafka?
Apache Kafka este un software open-source de procesare a fluxurilor care își propune să ofere un randament ridicat și o latență scăzută, în timp ce gestionează datele în timp real. Scris în Java și Scala, Kafka oferă durabilitate prin microservicii în memorie și are un rol esențial de jucat în menținerea evenimentelor de aprovizionare pentru Serviciile de transmitere a evenimentelor complexe, altfel cunoscute sub numele de CEP sau Sisteme de automatizare.
Este un sistem distribuit excepțional de versatil, fără erori, care permite companiilor precum Uber să gestioneze potrivirea pasagerilor și șoferului. De asemenea, oferă date în timp real și întreținere proactivă pentru produsele pentru casă inteligentă ale British Gas, pe lângă faptul că ajută LinkedIn să urmărească mai multe servicii în timp real.
Folosit adesea în arhitectura de date în flux în timp real pentru a oferi analize în timp real, Kafka este un sistem de mesagerie rapid, robust, scalabil și de publicare-abonare. Apache Kafka poate fi folosit ca înlocuitor pentru MOM tradițional datorită compatibilității sale excelente și arhitecturii flexibile care îi permite să urmărească apelurile de service sau datele senzorului IoT.
Kafka funcționează genial cu Apache Flume/Flafka, Apache Spark Streaming, Apache Storm, HBase, Apache Flink și Apache Spark pentru asimilarea, cercetarea, analiza și procesarea datelor în flux în timp real. Intermediarii Kafka facilitează, de asemenea, rapoarte de urmărire cu latență scăzută în Hadoop sau Spark. Kafka are, de asemenea, un proiect subsidiar numit Kafka Stream, care funcționează ca un instrument eficient pentru analiza în timp real.

Arhitectura și componentele Kafka
Kafka este utilizat pentru transmiterea datelor în timp real către mai multe sisteme destinatare. Kafka funcționează ca un strat central pentru decuplarea conductelor de date în timp real. Nu își găsește prea multă utilizare în calculele directe. Este cel mai compatibil cu sistemele de alimentare pe bandă rapidă, în timp real sau bazate pe date operaționale, pentru a transmite în flux o cantitate semnificativă de date pentru analiza datelor pe lot.
Cadrele Storm, Flink, Spark și CEP sunt câteva sisteme de date cu care Kafka lucrează pentru a realiza analize în timp real, creând copii de rezervă, audituri și multe altele. De asemenea, poate fi integrat cu platforme de date mari sau sisteme de baze de date precum RDBMS și Cassandra, Spark etc., pentru analiza științei datelor, raportare etc.
Diagrama de mai jos ilustrează ecosistemul Kafka:
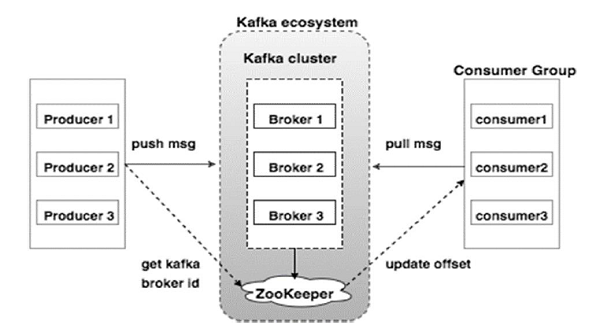
Sursă
Iată diferitele componente ale ecosistemului Kafka, așa cum sunt ilustrate în diagrama arhitecturii Kafka:
1. Broker Kafka
Kafka emulează un cluster care cuprinde mai multe servere, fiecare cunoscut drept „broker”. Orice comunicare între clienți și servere aderă la un protocol TCP de înaltă performanță. Acesta cuprinde mai mult de un broker apatrid pentru a gestiona încărcături grele. Un singur broker Kafka este capabil să gestioneze mai multe lacsuri de citiri și scrieri în fiecare secundă, fără a compromite performanța. Ei folosesc ZooKeeper pentru a menține clustere și pentru a alege liderul brokerului.
2. Kafka ZooKeeper
După cum am menționat mai sus, ZooKeeper este responsabil cu gestionarea brokerilor Kafka. Orice nouă adăugare sau eșec a unui broker în ecosistemul Kafka este adusă la cunoștința producătorului sau consumatorului prin intermediul ZooKeeper.
3. Producători Kafka
Ei sunt responsabili pentru trimiterea datelor către brokerii. Producătorii nu se bazează pe brokeri pentru a confirma primirea unui mesaj. În schimb, ei determină cât de mult poate gestiona un broker și trimite mesaje în consecință.

4. Consumatorii Kafka
Este responsabilitatea consumatorilor Kafka să țină o evidență a numărului de mesaje consumate de compensarea partiției. Confirmarea unui mesaj indică faptul că mesajele trimise înainte de a fi consumate. Pentru a se asigura că brokerul are un buffer de octeți pregătit pentru a fi trimis către consumator, consumatorul inițiază o cerere de extragere asincronă. ZooKeeper are un rol de jucat în menținerea valorii de compensare a omiterii sau înapoi a unui mesaj.
Mecanismul lui Kafka presupune trimiterea de mesaje între aplicații din sistemele distribuite. Kafka folosește un jurnal de comitere, care, atunci când este abonat, publică datele prezente într-o varietate de aplicații de streaming. Expeditorul trimite mesaje către Kafka, în timp ce destinatarul primește mesaje din fluxul distribuit de Kafka.
Mesajele sunt adunate pe subiecte - o deliberare eficientă a lui Kafka. Un anumit subiect reprezintă abur organizat de date bazat pe un anumit tip sau clasificare. Producătorul scrie mesaje pe care să le citească consumatorii, care se bazează pe un subiect.
Fiecare subiect are un nume unic. Orice mesaj dintr-un anumit subiect trimis de un expeditor este primit de toți utilizatorii care se conectează la acel subiect. Odată publicate, datele dintr-un subiect nu pot fi actualizate sau modificate.
Caracteristicile lui Kafka
- Kafka constă într-un jurnal de comitere perpetuă care vă permite să vă abonați la acesta și, ulterior, să publicați date pe mai multe sisteme sau aplicații în timp real.
- Oferă aplicațiilor posibilitatea de a controla acele date pe măsură ce apar. API-ul Streams din Apache Kafka este o bibliotecă puternică, ușoară, care facilitează procesarea rapidă a datelor pe lot.
- Este o aplicație Java care vă permite să vă reglați fluxul de lucru și reduce semnificativ orice cerință de întreținere.
- Kafka funcționează ca o „stocare a adevărului” care distribuie date către mai multe noduri, permițând implementarea datelor prin mai multe sisteme de date.
- Jurnalul de comitere al lui Kafka îl face un sistem de stocare fiabil. Kafka creează replici/backup-uri ale unei partiții care ajută la prevenirea pierderii de date (configurațiile corecte pot duce la zero pierderi de date). Acest lucru previne, de asemenea, defecțiunea serverului și sporește durabilitatea lui Kafka.
- Subiectele din Kafka au mii de partiții, ceea ce îl face capabil să gestioneze o cantitate arbitrară de date și încărcare grea.
- Kafka depinde de nucleul sistemului de operare pentru a muta datele într-un ritm rapid. Aceste grupuri de informații sunt criptate end-to-end, de la producător la sistem de fișiere la consumator final.
- Batching-ul în Kafka face comprimarea datelor eficiență și scade latența I/O.
Aplicații ale lui Kafka
O mulțime de companii care se ocupă zilnic de cantități mari de date folosesc Kafka.

- LinkedIn folosește Kafka pentru a urmări activitatea utilizatorilor și valorile de performanță. Twitter îl combină cu Storm pentru a activa un cadru de procesare a fluxului.
- Square folosește Kafka pentru a facilita deplasarea tuturor evenimentelor de sistem către alte centre de date Square. Acestea includ jurnalele, evenimentele personalizate și valorile.
- Alte companii populare care profită de beneficiile Kafka includ Netflix, Spotify, Uber, Tumblr, CloudFlare și PayPal.
De ce ar trebui să înveți Apache Kafka?
Kafka este o platformă excelentă de streaming de evenimente care poate gestiona, urmări și monitoriza în mod eficient datele în timp real. Arhitectura sa tolerantă la erori și scalabilă permite integrarea datelor cu latență scăzută, rezultând un debit mare al evenimentelor de streaming. Kafka reduce semnificativ „time-to-value” pentru date.
Funcționează ca sistem de bază care produce informații pentru organizații prin eliminarea „jurnalelor” din jurul datelor. Acest lucru le permite oamenilor de știință de date și specialiștilor să acceseze cu ușurință informații în orice moment.
Din aceste motive, este cea mai bună platformă de streaming preferată de multe companii de top și, prin urmare, candidații cu o calificare în Apache Kafka sunt foarte căutați.
Dacă sunteți interesat să aflați mai multe despre Kafka, Big Data, ar trebui să consultați Diploma PG de la upGrad în Specializarea Dezvoltare Software în Big Data , care oferă peste 7 studii de caz și proiecte și mentorat de la experți din industrie și facultăți de talie mondială. Programul de 13 luni acoperă 14 limbaje de programare și predă Procesarea datelor, MapReduce, Data Warehousing, Procesarea în timp real, Procesarea datelor mari pe cloud, printre alte abilități.
Consultați celelalte cursuri ale noastre de inginerie software la upGrad.