
Un ghid pentru regresia liniară folosind Scikit [cu exemple]
Publicat: 2021-06-18Algoritmii de învățare supravegheată sunt în general de două tipuri: regresie și clasificare cu predicția rezultatelor continue și discrete.
Următorul articol va discuta regresia liniară și implementarea acesteia folosind una dintre cele mai populare biblioteci de învățare automată ale python, biblioteca Scikit-learn. Instrumente pentru învățare automată și modele statistice sunt disponibile în biblioteca Python pentru clasificare, regresie, grupare și reducerea dimensionalității. Scrisă în limbajul de programare python, biblioteca este construită pe bibliotecile python NumPy, SciPy și Matplotlib.
Cuprins
Regresie liniara
Regresia liniară îndeplinește sarcina de regresie conform metodei de învățare supravegheată. Pe baza variabilelor independente, este prezisă o valoare țintă. Metoda este utilizată în principal pentru prognoza și identificarea unei relații între variabile.
În algebră, termenul de liniaritate înseamnă o relație liniară între variabile. Între variabilele dintr-un spațiu bidimensional se deduce o linie dreaptă.
Dacă o linie este un grafic între variabilele independente de pe axa X și variabilele dependente de pe axa Y, se realizează o linie dreaptă prin regresie liniară care se potrivește cel mai bine punctelor de date.
Ecuația unei drepte este sub forma

Y = mx + b
Unde, b= intercept
m= panta dreptei
Prin urmare, prin regresie liniară,
- Cele mai optime valori pentru interceptarea și panta sunt determinate în două dimensiuni.
- Nu există nicio schimbare în variabilele x și y, deoarece acestea sunt caracteristicile datelor și, prin urmare, rămân aceleași.
- Doar interceptarea și valorile pantei pot fi controlate.
- Pot exista mai multe linii drepte bazate pe valorile pantei și intersecției, cu toate acestea, prin algoritmul de regresie liniară sunt montate mai multe linii pe punctele de date și linia cu cea mai mică eroare este returnată.
Regresia liniară cu Python
Pentru implementarea regresiei liniare în python, pachetele adecvate trebuie aplicate împreună cu funcțiile și clasele sale. Pachetul NumPy în Python este open source și permite mai multe operațiuni peste matrice, atât matrice unice, cât și multidimensionale.
O altă bibliotecă utilizată pe scară largă în python este Scikit-learn, care este folosită pentru problemele de învățare automată.
Scikit-learN
Biblioteca Scikit-learn oferă dezvoltatorilor algoritmi bazați atât pe învățarea supravegheată, cât și pe cea nesupravegheată. Biblioteca open-source a lui Python este concepută pentru sarcini de învățare automată.
Oamenii de știință de date pot importa datele, le pot preprocesa, le pot reprezenta un grafic și pot prezice date prin utilizarea scikit-learn.
David Cournapeau a dezvoltat pentru prima dată scikit-learn în 2007, iar biblioteca a cunoscut o creștere de decenii.
Instrumentele oferite de scikit-learn sunt:
- Regresia: Include regresia logistică și regresia liniară
- Clasificare: Include metoda K-Nearest Neighbours
- Alegerea unui model
- Clustering: include atât K-Means++ cât și K-Means
- Preprocesare
Avantajele bibliotecii sunt:
- Învățarea și implementarea bibliotecii sunt ușoare.
- Este o bibliotecă open-source și, prin urmare, gratuită.
- Aspectele învățării automate pot fi acoperite, inclusiv învățarea profundă.
- Este un pachet puternic și versatil.
- Biblioteca are documentație detaliată.
- Unul dintre cele mai utilizate seturi de instrumente pentru învățarea automată.
Importul scikit-learn
Scikit-learn trebuie instalat mai întâi prin pip sau prin conda.
- Cerințe: versiunea python 3 pe 64 de biți cu bibliotecile instalate NumPy și Scipy. De asemenea, pentru vizualizarea diagramelor de date, este necesar matplotlib.
Comanda de instalare: pip install -U scikit-learn
Apoi verificați dacă instalarea este completă
Instalarea Numpy, Scipy și matplotlib
Instalarea poate fi confirmată prin:
Sursă
Regresia liniară prin Scikit-learn
Implementarea regresiei liniare prin pachetul scikit-learn implică următorii pași.
- Pachetele și clasele necesare urmează să fie importate.
- Datele sunt necesare pentru a lucra cu și, de asemenea, pentru a continua transformările corespunzătoare.
- Un model de regresie urmează să fie creat și completat cu datele existente.
- Datele de potrivire a modelului trebuie verificate pentru a analiza dacă modelul creat este satisfăcător.
- Predicțiile trebuie făcute prin aplicarea modelului.
Pachetul NumPy și clasa LinearRegression urmează să fie importate din sklearn.linear_model.

Sursă
Funcționalitățile necesare pentru regresia liniară sklearn sunt toate prezente pentru a implementa în sfârșit regresia liniară. Clasa sklearn.linear_model.LinearRegression este utilizată pentru efectuarea analizei de regresie (atât liniare, cât și polinomiale) și pentru realizarea predicțiilor.
Pentru orice algoritm de învățare automată și regresie liniară scikit Learn , setul de date trebuie importat mai întâi. Trei opțiuni sunt disponibile în Scikit-learn pentru a obține datele:
- Seturi de date precum clasificarea irisului sau setul de regresie pentru prețul locuințelor din Boston.
- Seturile de date din lumea reală pot fi descărcate de pe internet direct prin funcțiile predefinite Scikit-learn.
- Un set de date poate fi generat aleatoriu pentru a se potrivi cu un model specific prin generatorul de date Scikit-learn.
Indiferent de opțiunea selectată, seturile de date ale modulului trebuie importate.

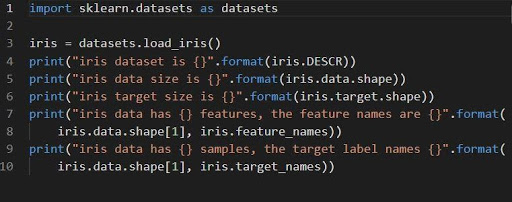
importați sklearn.datasets ca seturi de date
1. Setul de clasificare al irisului
iris = datasets.load_iris()
Irisul setului de date este stocat ca un câmp de date matrice 2D de n_samples * n_features. Importul lui se realizează ca obiect al unui dicționar. Conține toate datele necesare împreună cu metadatele.
Funcțiile DESCR, shape și _names pot fi folosite pentru a obține descrieri și formatare a datelor. Imprimarea rezultatelor funcției va afișa informațiile setului de date care ar putea fi necesare în timp ce lucrați la setul de date iris.
Următorul cod va încărca informațiile setului de date iris.
Sursă
2. Generarea datelor de regresie
Dacă nu există nicio cerință pentru date încorporate, atunci datele pot fi generate printr-o distribuție care poate fi aleasă.
Generarea datelor de regresie cu un set de 1 caracteristică informativă și 1 caracteristică.
X , Y = datasets.make_regression(n_features=1, n_informative=1)
Datele generate sunt salvate într-un set de date 2D cu obiectele x și y. Caracteristicile datelor generate pot fi modificate prin modificarea parametrilor funcției make_regression.
În acest exemplu, parametrii caracteristicilor și caracteristicilor informative sunt modificați de la o valoare implicită de 10 la 1.
Alți parametri luați în considerare sunt eșantioanele și țintele în care sunt controlate numărul de variabile țintă și eșantion urmărite.
- Caracteristicile care oferă informații utile algoritmilor de ML sunt denumite caracteristici informative, în timp ce cele care nu sunt de ajutor sunt denumite caracteristici informative.
3. Trasarea datelor
Datele sunt reprezentate grafic folosind biblioteca matplotlib. În primul rând, matplotlib trebuie să fie importat.
Importă matplotlib.pyplot ca plt
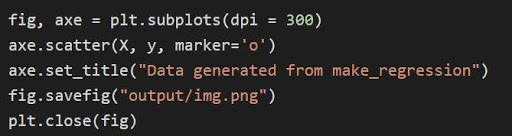
Graficul de mai sus este trasat prin matplotlib prin cod
Sursă
În codul de mai sus:
- Variabilele tuple sunt despachetate și salvate ca variabile separate în linia 1 a codului. Prin urmare, atributele separate pot fi manipulate și salvate.
- Setul de date x, y este folosit pentru a genera un grafic de dispersie prin linia 2. Odată cu disponibilitatea parametrului marker în matplotlib, imaginile sunt îmbunătățite prin marcarea punctelor de date cu un punct (o).
- Titlul diagramei generate este stabilit prin linia 3.
- Figura poate fi salvată ca fișier imagine .png și apoi figura curentă este închisă.
Graficul de regresie generat prin codul de mai sus este
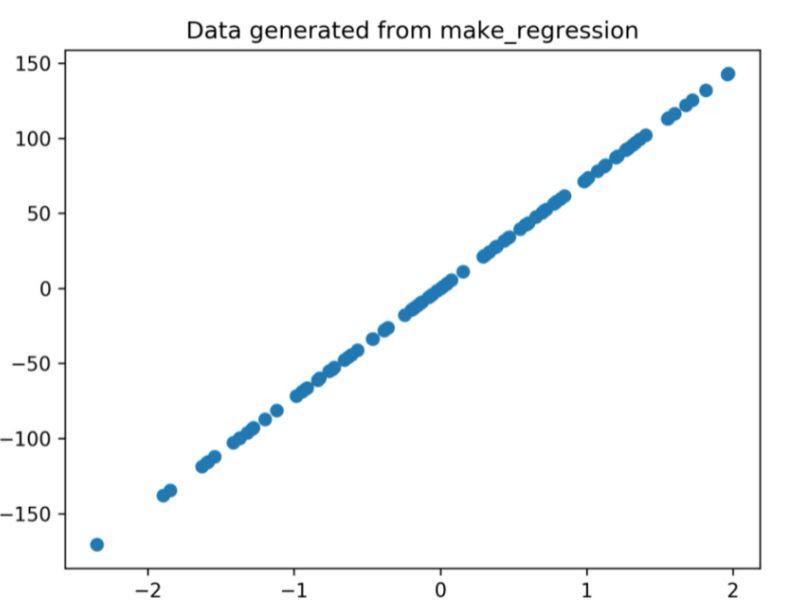
Figura 1: Graficul de regresie generat din codul de mai sus.
4. Implementarea algoritmului de regresie liniară
Folosind eșantionul de date privind prețul locuințelor din Boston, algoritmul de regresie liniară Scikit-learn este implementat în exemplul următor. Ca și alți algoritmi ML, setul de date este importat și apoi antrenat folosind datele anterioare.
Metoda liniară de regresie este folosită de întreprinderi, deoarece este un model predictiv care prezice relația dintre o cantitate numerică și variabilele acesteia cu valoarea de ieșire cu semnificația având o valoare în realitate.
Când este prezent un jurnal de date anterioare, modelul poate fi cel mai bine aplicat, deoarece poate prezice rezultatele viitoare ale a ceea ce se va întâmpla în viitor dacă există o continuare a modelului.
Din punct de vedere matematic, datele pot fi ajustate pentru a minimiza suma tuturor reziduurilor care există între punctele de date și valoarea prezisă.
Următorul fragment arată implementarea regresiei lineare sklearn.
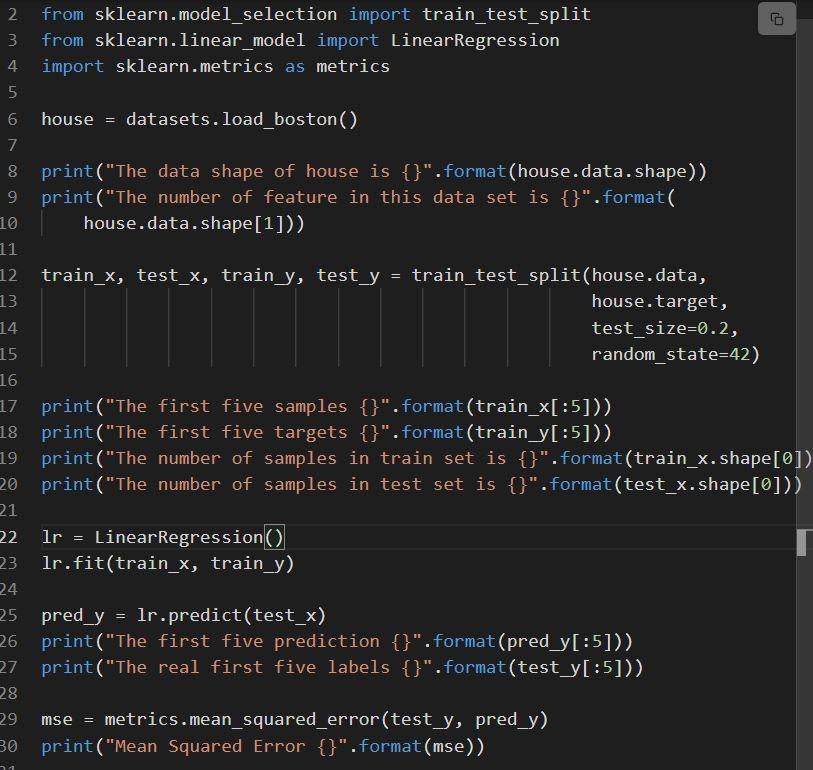
Sursă
Codul este explicat astfel:
- Linia 6 încarcă setul de date numit load_boston.
- Setul de date este împărțit în linia 12, adică setul de antrenament cu 80% date și setul testului cu 20% date.
- Crearea unui model de regresie liniară la linia 23 și apoi antrenat la.
- Performanța modelului este evaluată la lenjerie 29 prin apelarea erorii_pătrate medii.
Graficul de regresie liniară sklearn este prezentat mai jos:
Modelul de regresie liniară al eșantionului de date privind prețurile locuințelor din Boston
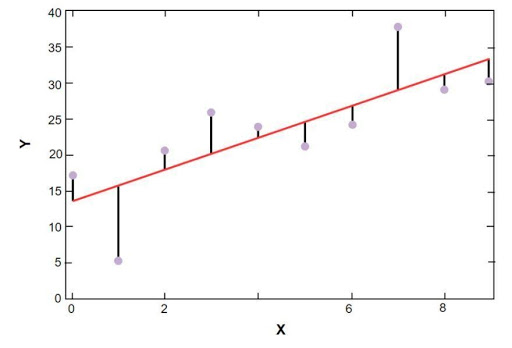
Sursă
În figura de mai sus, linia roșie reprezintă modelul liniar care a fost rezolvat pentru datele eșantionului de preț al locuințelor din Boston. Punctele albastre reprezintă datele originale, iar distanța dintre linia roșie și punctele albastre reprezintă suma reziduurilor. Scopul modelului de regresie liniară scikit-learn este de a reduce suma reziduurilor.
Concluzie
Articolul a discutat despre regresia liniară și implementarea acesteia prin utilizarea unui pachet python open-source numit scikit-learn. Până acum, puteți obține conceptul despre cum să implementați regresia liniară prin acest pachet. Merită să învățați cum să utilizați biblioteca pentru analiza datelor dvs.
Dacă sunteți interesat să explorați subiectul în continuare, cum ar fi implementarea pachetelor Python în învățarea automată și problemele legate de AI, puteți verifica cursul Master of Science în Machine Learning și AI oferit de upGrad . Adresându-se profesioniștilor de la nivel de intrare cu vârsta între 21 și 45 de ani, cursul își propune să instruiască studenții în învățarea automată prin cursuri online de peste 650 de ore, peste 25 de studii de caz și sarcini. Certificat de LJMU , cursul oferă îndrumare perfectă și asistență pentru plasarea unui loc de muncă. Dacă aveți întrebări sau nelămuriri, lăsați-ne un mesaj, vă vom contacta cu plăcere.