
O que é Aprendizado de Máquina com Java? Como Implementá-lo?
Publicados: 2021-03-10Índice
O que é Aprendizado de Máquina?
O aprendizado de máquina é uma divisão da Inteligência Artificial que aprende com dados, exemplos e experiências disponíveis para imitar o comportamento e a inteligência humanos. Um programa criado usando aprendizado de máquina pode criar lógica por conta própria, sem que um humano precise escrever o código manualmente.
Tudo começou com o Teste de Turing no início da década de 1950, quando Alan Turning concluiu que, para um computador ter inteligência real, ele precisaria manipular ou convencer um humano de que também era humano. O aprendizado de máquina é um conceito relativamente antigo, mas é apenas hoje que esse campo emergente está sujeito a realização, pois os computadores agora podem processar algoritmos complexos. Os algoritmos de aprendizado de máquina evoluíram na última década para incluir habilidades computacionais complexas que, por sua vez, levaram a um aprimoramento em suas capacidades de imitação.
Os aplicativos de aprendizado de máquina também aumentaram em um ritmo alarmante. De assistência médica, finanças, análise e educação a manufatura, marketing e operações governamentais, todos os setores tiveram um aumento significativo na qualidade e eficiência após a implementação de tecnologias de aprendizado de máquina. Houve melhorias qualitativas generalizadas em todo o mundo, portanto, impulsionando a demanda por profissionais de aprendizado de máquina.
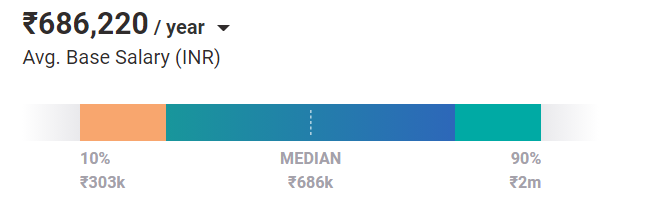
Em média, os engenheiros de aprendizado de máquina valem um salário de ₹ 686.220 / ano hoje. E esse é o caso de uma posição de nível de entrada. Com experiência e habilidades, eles podem ganhar até ₹ 2 milhões por ano na Índia.
Tipos de algoritmos de aprendizado de máquina
Os algoritmos de aprendizado de máquina são de três tipos:
1. Aprendizado Supervisionado : Nesse tipo de aprendizado, os conjuntos de dados de treinamento orientam um algoritmo para fazer previsões precisas ou decisões analíticas. Ele emprega o aprendizado de conjuntos de dados de treinamento anteriores para processar novos dados. Aqui estão alguns exemplos de modelos de aprendizado de máquina de aprendizado supervisionado:

- Regressão linear
- Regressão logística
- Árvore de decisão
2. Aprendizado não supervisionado : nesse tipo de aprendizado, um modelo de aprendizado de máquina aprende com informações não rotuladas. Ele emprega agrupamento de dados agrupando objetos ou entendendo a relação entre eles, ou explorando suas propriedades estatísticas para realizar análises. Exemplos de algoritmos de aprendizado não supervisionado são:
- Agrupamento K-means
- Agrupamento hierárquico
3. Aprendizado por Reforço : Este processo é baseado em acertos e tentativas. É aprender interagindo com o espaço ou um ambiente. Um algoritmo de RL aprende com suas experiências passadas interagindo com o ambiente e determinando o melhor curso de ação.
Como implementar o aprendizado de máquina com Java?
Java está entre as principais linguagens de programação usadas para implementar algoritmos de aprendizado de máquina. A maioria de suas bibliotecas é de código aberto, fornecendo amplo suporte de documentação, fácil manutenção, comercialização e fácil leitura.
Dependendo da popularidade, aqui estão as 10 principais bibliotecas de aprendizado de máquina usadas para implementar o aprendizado de máquina em Java.
1. ADAMS
Advanced-Data Mining And Machine Learning System ou ADAMS está preocupado com a construção de sistemas de fluxo de trabalho novos e flexíveis e para gerenciar processos complexos do mundo real. O ADAMS emprega uma arquitetura semelhante a uma árvore para gerenciar o fluxo de dados em vez de fazer conexões manuais de entrada e saída.
Ele elimina qualquer necessidade de conexões explícitas. Ele é baseado no princípio “menos é mais” e realiza recuperação, visualização e visualizações orientadas por dados. O ADAMS é especialista em processamento de dados, streaming de dados, gerenciamento de bancos de dados, scripts e documentação.
2. JavaML
JavaML oferece uma variedade de algoritmos de ML e mineração de dados que são escritos para Java para dar suporte a engenheiros de software, programadores, cientistas de dados e pesquisadores. Cada algoritmo tem uma interface comum que é fácil de usar e possui amplo suporte de documentação, mesmo que não haja GUI.
É bastante simples e direto de implementar em comparação com outros algoritmos de agrupamento. Seus principais recursos incluem manipulação de dados, documentação, gerenciamento de banco de dados, classificação de dados, agrupamento, seleção de recursos e assim por diante.
Participe do Curso de Aprendizado de Máquina on-line das principais universidades do mundo - Mestrados, Programas de Pós-Graduação Executiva e Programa de Certificado Avançado em ML e IA para acelerar sua carreira.
3. WEKA
Weka também é uma biblioteca de aprendizado de máquina de código aberto escrita para Java que suporta aprendizado profundo. Ele fornece um conjunto de algoritmos de aprendizado de máquina e encontra amplo uso em mineração de dados, preparação de dados, agrupamento de dados, visualização de dados e regressão, entre outras operações de dados.
Exemplo: Vamos demonstrar isso usando um pequeno conjunto de dados de diabetes.
Passo 1 : Carregar os dados usando Weka
| importar weka.core.Instances; importar weka.core.converters.ConverterUtils.DataSource; classe pública Principal { public static void main(String[] args) lança Exception { // Especificando a fonte de dados DataSource dataSource = new DataSource(“data.arff”); // Carregando o conjunto de dados Instâncias dataInstances = dataSource.getDataSet(); // Exibindo o número de instâncias log.info(“O número de instâncias carregadas é: ” + dataInstances.numInstances()); log.info(“dados:” + dataInstances.toString()); } } |
Etapa 2: o conjunto de dados tem 768 instâncias. Precisamos acessar o número de atributos, ou seja, 9.
| log.info(“O número de atributos (features) no conjunto de dados: ” + dataInstances.numAttributes()); |
Etapa 3 : Precisamos determinar a coluna de destino antes de construir um modelo e encontrar o número de classes.
| // Identificando o índice do rótulo dataInstances.setClassIndex(dataInstances.numAttributes() – 1); // Obtendo o número de log.info(“O número de classes: ” + dataInstances.numClasses()); |
Passo 4 : Agora vamos construir o modelo usando um classificador de árvore simples, J48.
| // Criando um classificador de árvore de decisão Classificador de árvore J48 = new J48(); treeClassifier.setOptions(new String[] { “-U” }); treeClassifier.buildClassifier(dataInstances); |
O código acima destaca como criar uma árvore não podada que consiste nas instâncias de dados necessárias para o treinamento do modelo. Uma vez que a estrutura da árvore é impressa após o treinamento do modelo, podemos determinar como as regras foram construídas internamente.
| pla <= 127 | massa <= 26,4 | | preg <= 7: testado_negativo (117,0/1,0) | | preg > 7 | | | massa <= 0: testado_positivo (2,0) | | | massa > 0: testado_negativo (13,0) | massa > 26,4 | | idade <= 28: testado_negativo (180,0/22,0) | | idade > 28 | | | plas <= 99: testado_negativo (55,0/10,0) | | | pla > 99 | | | | pedi <= 0,56: testado_negativo (84,0/34,0) | | | | pedi > 0,56 | | | | | preg <= 6 | | | | | | idade <= 30: testado_positivo (4,0) | | | | | | idade > 30 | | | | | | | idade <= 34: testado_negativo (7,0/1,0) | | | | | | | idade > 34 | | | | | | | | massa <= 33,1: testado_positivo (6,0) | | | | | | | | massa > 33,1: testado_negativo (4,0/1,0) | | | | | preg > 6: testado_positivo (13,0) número > 127 | massa <= 29,9 | | plas <= 145: testado_negativo (41,0/6,0) | | pl > 145 | | | idade <= 25: testado_negativo (4,0) | | | idade > 25 | | | | idade <= 61 | | | | | massa <= 27,1: testado_positivo (12,0/1,0) | | | | | massa > 27,1 | | | | | | pres <= 82 | | | | | | | pedi <= 0,396: testado_positivo (8,0/1,0) | | | | | | | pedi > 0,396: testado_negativo (3,0)  | | | | | | pres > 82: testado_negativo (4,0) | | | | idade > 61: testado_negativo (4,0) | massa > 29,9 | | pla <= 157 | | | pres <= 61: testado_positivo (15,0/1,0) | | | pres > 61 | | | | idade <= 30: testado_negativo (40,0/13,0) | | | | idade > 30: testado_positivo (60,0/17,0) | | plas > 157: testado_positivo (92,0/12,0) Número de folhas: 22 Tamanho da árvore: 43 |
4. Apache Mahaut
Mahaut é uma coleção de algoritmos para ajudar a implementar o aprendizado de máquina usando Java. É uma estrutura de álgebra linear escalável usando a qual os desenvolvedores podem realizar matemática, análises estatísticas. Geralmente é usado por cientistas de dados, engenheiros de pesquisa e profissionais de análise para criar aplicativos prontos para empresas. Sua escalabilidade e flexibilidade permitem que os usuários implementem clusters de dados, sistemas de recomendação e criem aplicativos de aprendizado de máquina de alto desempenho com rapidez e facilidade.
5. Aprendizado profundo4j
Deeplearning4j é uma biblioteca de programação escrita em Java e oferece amplo suporte para aprendizado profundo. É uma estrutura de código aberto que combina redes neurais profundas e aprendizado de reforço profundo para atender às operações de negócios. É compatível com Scala, Kotlin, Apache Spark, Hadoop e outras linguagens JVM e estruturas de computação de big data.
Normalmente é usado para detectar padrões e emoções na voz, fala e texto escrito. Ele serve como uma ferramenta de bricolage que pode descobrir discrepâncias nas transações e lidar com várias tarefas. É uma biblioteca distribuída de nível comercial que possui documentação detalhada da API devido à sua natureza de código aberto.
Aqui está um exemplo de como você pode implementar o aprendizado de máquina usando o Deeplearning4j.
Exemplo : Usando Deeplearning4j, construiremos um modelo de Rede Neural de Convolução (CNN) para classificar os dígitos manuscritos com a ajuda da biblioteca MNIST.
Etapa 1 : Carregue o conjunto de dados para exibir seu tamanho.
| DataSetIterator MNISTTrain = new MnistDataSetIterator(tamanho do lote,true,semente); DataSetIterator MNISTTest = new MnistDataSetIterator(tamanho do lote,falso,semente); |
Etapa 2 : verifique se o conjunto de dados nos fornece dez rótulos exclusivos.
| log.info(“O número total de rótulos encontrados no conjunto de dados de treinamento” + MNISTTrain.totalOutcomes()); log.info(“O número total de rótulos encontrados no conjunto de dados de teste ” + MNISTTest.totalOutcomes()); |
Etapa 3 : Agora, vamos configurar a arquitetura do modelo usando duas camadas de convolução junto com uma camada achatada para exibir a saída.
Existem opções no Deeplearning4j que permitem inicializar o esquema de peso.
| // Construindo o modelo CNN conf MultiLayerConfiguration = new NeuralNetConfiguration.Builder() .seed(seed) // semente aleatória .l2(0,0005) // regularização .weightInit(WeightInit.XAVIER) // inicialização do esquema de peso .updater(new Adam(1e-3)) // Configurando o algoritmo de otimização .Lista() .layer(new ConvolutionLayer.Builder(5, 5) //Definindo o passo, o tamanho do kernel e a função de ativação. .nIn(nCanais) .passo(1,1) .nOut(20) .activation(Activation.IDENTITY) .Construir()) .layer(new SubsamplingLayer.Builder(PoolingType.MAX) // reduzindo a amostra da convolução .kernelSize(2,2) .passo(2,2) .Construir()) .layer(new ConvolutionLayer.Builder(5, 5) // Configurando o passo, o tamanho do kernel e a função de ativação. .passo(1,1) .nOut(50) .activation(Activation.IDENTITY) .Construir()) .layer(new SubsamplingLayer.Builder(PoolingType.MAX) // reduzindo a amostra da convolução .kernelSize(2,2) .passo(2,2) .Construir()) .layer(new DenseLayer.Builder().activation(Activation.RELU) .nOut(500).build()) .layer(new OutputLayer.Builder(LossFunctions.LossFunction.NEGATIVELOGLIKELIHOOD) .nOut(outputNum) .activation(Ativação.SOFTMAX) .Construir()) // a camada de saída final é 28×28 com uma profundidade de 1. .setInputType(InputType.convolutionalFlat(28,28,1)) .Construir(); |
Etapa 4 : Depois de configurar a arquitetura, inicializaremos o modo e o conjunto de dados de treinamento e iniciaremos o treinamento do modelo.
| Modelo MultiLayerNetwork = new MultiLayerNetwork(conf); // inicializa os pesos do modelo. model.init(); log.info(“Passo 2: comece a treinar o modelo”); //Definindo um ouvinte a cada 10 iterações e avaliando no conjunto de teste em cada época model.setListeners(new ScoreIterationListener(10), new EvaluativeListener(MNISTTest, 1, InvocationType.EPOCH_END)); //Treinando o modelo model.fit(MNISTTrain, nEpochs); |
À medida que o treinamento do modelo começa, você terá a matriz de confusão da precisão da classificação.
Aqui está a precisão do modelo após dez épocas de treinamento:
| ========================= Matriz de confusão======================== == 0 1 2 3 4 5 6 7 8 9 —————————————————— 977 0 0 0 0 0 1 1 1 0 | 0 = 0 0 1131 0 1 0 1 2 0 0 0 | 1 = 1 1 2 1019 3 0 0 0 3 4 0 | 2 = 2 0 0 1 1004 0 1 0 1 3 0 | 3 = 3 0 0 0 0 977 0 2 0 1 2 | 4 = 4 1 0 0 9 0 879 1 0 1 1 | 5 = 5 4 2 0 0 1 1 949 0 1 0 | 6 = 6 0 4 2 1 1 0 0 1018 1 1 | 7 = 7 2 0 3 1 0 1 1 2 962 2 | 8 = 8 0 2 0 2 11 2 0 3 2 987 | 9 = 9 |
6. ELKI
Ambiente para Desenvolvimento de Aplicativos KDD Suportado por Index-structure ou ELKI é uma coleção de algoritmos e programas embutidos usados para mineração de dados. Escrito em Java, é uma biblioteca de código aberto que compreende parâmetros altamente configuráveis em algoritmos. Normalmente, é usado por pesquisadores e estudantes para obter informações sobre conjuntos de dados. Como o nome sugere, ele fornece um ambiente para desenvolver programas sofisticados de mineração de dados e bancos de dados usando uma estrutura de índice.
7. JSAT
Java Statistical Analysis Tool ou JSAT é uma biblioteca GPL3 que usa uma estrutura orientada a objetos para ajudar os usuários a implementar o aprendizado de máquina com Java. É normalmente usado para fins de auto-educação por estudantes e desenvolvedores. Em comparação com outras bibliotecas de implementação de IA, o JSAT possui o maior número de algoritmos de ML e é o mais rápido entre todos os frameworks. Com zero dependências externas, é altamente flexível e eficiente e oferece alto desempenho.
8. O Encog Machine Learning Framework
O Encog é escrito em Java e C# e inclui bibliotecas que ajudam a implementar algoritmos de aprendizado de máquina. Ele é usado para construir algoritmos genéticos, redes bayesianas, modelos estatísticos como o Hidden Markov Model e muito mais.
9. Marreta
O Machine Learning for Language Toolkit ou Mallet é usado no Natural Language Processing (NLP). Como a maioria das outras estruturas de implementação de ML, o Mallet também oferece suporte para modelagem de dados, agrupamento de dados, processamento de documentos, classificação de documentos e assim por diante.
10. Spark MLlib
O Spark MLlib é usado pelas empresas para aprimorar a eficiência e a escalabilidade do gerenciamento de fluxo de trabalho. Ele processa grandes quantidades de dados e suporta algoritmos de ML de carga pesada.
Checkout: ideias de projetos de aprendizado de máquina
Conclusão
Isso nos leva ao final do artigo. Para obter mais informações sobre os conceitos de Machine Learning, entre em contato com o corpo docente superior do IIIT Bangalore e da Liverpool John Moores University por meio do programa Master of Science in Machine Learning & AI do upGrad.
Por que devemos usar Java junto com Machine Learning?
Os profissionais de Machine Learning acharão mais fácil interagir com os repositórios de código atuais se escolherem Java como linguagem de programação para seus projetos. É uma linguagem de aprendizado de máquina de preferência devido a recursos como facilidade de uso, serviços de pacote, melhor interação do usuário, depuração rápida e ilustração gráfica de dados. O Java facilita para os desenvolvedores de Machine Learning o dimensionamento de seus sistemas, tornando-o uma excelente opção para criar aplicativos de Machine Learning grandes e sofisticados desde o início. A Java Virtual Machine (JVM) oferece suporte a vários ambientes de desenvolvimento integrados (IDEs) que permitem que os aprendizes de máquina projetem novas ferramentas rapidamente.
Aprender Java é fácil?
Como Java é uma linguagem de alto nível, é simples de entender. Como aprendiz, você não terá que entrar em tantos detalhes, pois é uma linguagem bem estruturada e orientada a objetos que é simples o suficiente para os novatos aprenderem. Como existem vários procedimentos que operam automaticamente, você pode dominá-los rapidamente. Você não precisa entrar em grandes detalhes sobre como as coisas funcionam lá. Java é uma linguagem de programação independente de plataforma. Ele permite que um programador crie um aplicativo móvel que pode ser usado em qualquer dispositivo. É a linguagem preferida da Internet das Coisas, bem como a melhor ferramenta para desenvolver aplicativos de nível empresarial.
O que é o ADAMS e como ele é útil no Machine Learning?
O Advanced Data Mining And Machine Learning System (ADAMS) é um mecanismo de fluxo de trabalho licenciado pela GPLv3 para criação e gerenciamento rápidos de fluxos de trabalho reativos orientados a dados que podem ser prontamente incorporados aos processos de negócios. O mecanismo de fluxo de trabalho, que segue o princípio de menos é mais, está no coração do ADAMS. O ADAMS emprega uma estrutura semelhante a uma árvore em vez de permitir que o usuário organize os operadores (ou atores no jargão do ADAMS) em uma tela e, em seguida, vincule manualmente as entradas e saídas. Nenhuma conexão explícita é necessária porque essa estrutura e os atores de controle determinam como os dados fluem no processo. A representação de objetos internos e o aninhamento de suboperadores dentro de manipuladores de operadores resultam em uma estrutura semelhante a uma árvore. O ADAMS fornece um conjunto diversificado de agentes para recuperação, processamento, mineração e exibição de dados.