
O que é árvore de decisão em mineração de dados? Tipos, exemplos do mundo real e aplicações
Publicados: 2021-06-15Índice
Introdução à mineração de dados
Os dados geralmente estão presentes como os dados brutos que precisam ser efetivamente processados para convertê-los em informações úteis. A previsão dos resultados geralmente depende do processo de encontrar padrões, anomalias ou correlações nos dados. O processo foi denominado de “descoberta de conhecimento em bancos de dados”.
Foi apenas na década de 1990 que o termo “mineração de dados” foi cunhado. A mineração de dados foi fundada em três disciplinas: estatística, inteligência artificial e aprendizado de máquina. A mineração de dados automatizada mudou o processo de análise de uma abordagem tediosa para uma mais rápida. A mineração de dados permite que o usuário
- Remova todos os dados barulhentos e caóticos
- Compreender os dados relevantes e usá-los para a previsão de informações úteis.
- O processo de previsão de decisões informadas é acelerado .
A mineração de dados também pode ser referida como o processo de identificação de padrões ocultos de informações que requerem categorização. Só então os dados podem ser convertidos em dados úteis. Os dados úteis podem ser alimentados em um data warehouse, algoritmos de mineração de dados, análise de dados para tomada de decisão.
Árvore de decisão em mineração de dados
Um tipo de técnica de mineração de dados, árvore de decisão em mineração de dados constrói um modelo para classificação de dados. Os modelos são construídos na forma de estrutura de árvore e, portanto, pertencem à forma supervisionada de aprendizado. Além dos modelos de classificação, as árvores de decisão são usadas para construir modelos de regressão para prever rótulos de classe ou valores que auxiliam o processo de tomada de decisão. Tanto os dados numéricos quanto os categóricos como sexo, idade, etc. podem ser usados por uma árvore de decisão.
Estrutura de uma árvore de decisão
A estrutura de uma árvore de decisão consiste em um nó raiz, ramos e nós folha. Os nós ramificados são os resultados de uma árvore e os nós internos representam o teste em um atributo. Os nós folha representam um rótulo de classe.
Funcionamento de uma árvore de decisão
1. Uma árvore de decisão funciona sob a abordagem de aprendizado supervisionado para variáveis discretas e contínuas. O conjunto de dados é dividido em subconjuntos com base no atributo mais significativo do conjunto de dados. A identificação do atributo e a divisão são feitas através dos algoritmos.
2. A estrutura da árvore de decisão consiste no nó raiz, que é o nó preditor significativo. O processo de divisão ocorre a partir dos nós de decisão que são os subnós da árvore. Os nós que não se dividem mais são denominados nós folha ou nós terminais.
3. O conjunto de dados é dividido em regiões homogêneas e não sobrepostas seguindo uma abordagem de cima para baixo. A camada superior fornece as observações em um único local que se divide em ramificações. O processo é denominado como “Abordagem Greedy” devido ao seu foco apenas no nó atual e não nos nós futuros.
4. Até e a menos que um critério de parada seja alcançado, a árvore de decisão continuará funcionando.
5. Com a construção de uma árvore de decisão, muito ruído e outliers são gerados. Para remover esses outliers e dados ruidosos, um método de “poda de árvore” é aplicado. Assim, a precisão do modelo aumenta.
6. A precisão de um modelo é verificada em um conjunto de teste que consiste em tuplas de teste e rótulos de classe. Um modelo preciso é definido com base nas porcentagens de tuplas e classes de conjuntos de teste de classificação pelo modelo.
Figura 1 : Um exemplo de uma árvore não podada e podada
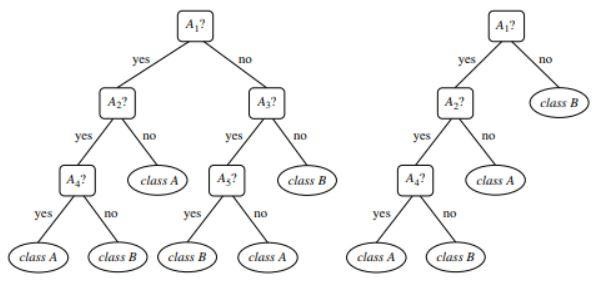
Fonte
Tipos de Árvore de Decisão
As árvores de decisão levam ao desenvolvimento de modelos de classificação e regressão baseados em uma estrutura em forma de árvore. Os dados são divididos em subconjuntos menores. O resultado de uma árvore de decisão é uma árvore com nós de decisão e nós folha. Dois tipos de árvores de decisão são explicados abaixo:
1. Classificação
A classificação inclui a construção de modelos que descrevem rótulos de classes importantes. Eles são aplicados nas áreas de aprendizado de máquina e reconhecimento de padrões. As árvores de decisão no aprendizado de máquina por meio de modelos de classificação levam à detecção de fraude, diagnóstico médico etc. O processo de duas etapas de um modelo de classificação inclui:
- Aprendizagem: Um modelo de classificação baseado nos dados de treinamento é construído.
- Classificação: A precisão do modelo é verificada e, em seguida, usada para classificação dos novos dados. Os rótulos de classe estão na forma de valores discretos como “sim” ou “não”, etc.
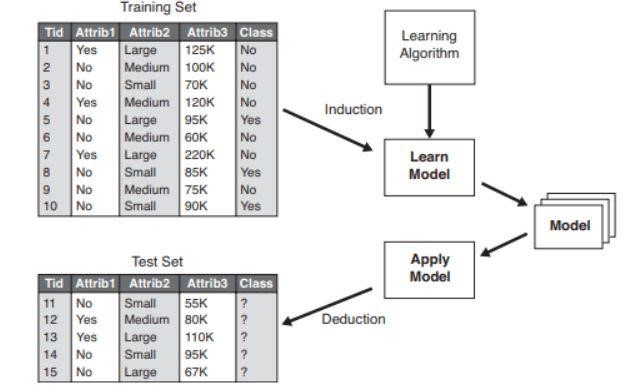
Figura 2 : Exemplo de um modelo de classificação .
Fonte
2. Regressão
Modelos de regressão são utilizados para a análise de regressão dos dados, ou seja, a previsão de atributos numéricos. Estes também são chamados de valores contínuos. Portanto, em vez de prever os rótulos de classe, o modelo de regressão prevê os valores contínuos.
Lista de Algoritmos Usados
Um algoritmo de árvore de decisão conhecido como “ID3” foi desenvolvido em 1980 por um pesquisador de máquinas chamado J. Ross Quinlan. Este algoritmo foi sucedido por outros algoritmos como o C4.5 desenvolvido por ele. Ambos os algoritmos aplicaram a abordagem gulosa. O algoritmo C4.5 não usa retrocesso e as árvores são construídas de forma recursiva de divisão e conquista de cima para baixo. O algoritmo usou um conjunto de dados de treinamento com rótulos de classe que são divididos em subconjuntos menores à medida que a árvore é construída.
- Três parâmetros são selecionados inicialmente - lista de atributos, método de seleção de atributos e partição de dados. Os atributos do conjunto de treinamento são descritos na lista de atributos.
- O método de seleção de atribuição inclui o método de seleção do melhor atributo para discriminação entre as tuplas.
- Uma estrutura em árvore depende do método de seleção de atributos.
- A construção de uma árvore começa com um único nó.
- A divisão das tuplas ocorre quando diferentes rótulos de classe são representados em uma tupla. Isso levará à formação de ramos da árvore.
- O método de divisão determina qual atributo deve ser selecionado para a partição de dados. Com base nesse método, as ramificações são cultivadas a partir de um nó com base no resultado do teste.
- O método de divisão e particionamento é executado recursivamente, resultando em uma árvore de decisão para as tuplas do conjunto de dados de treinamento.
- O processo de formação da árvore continua até e a menos que as tuplas restantes não possam ser mais particionadas.
- A complexidade do algoritmo é denotada por
n * |D| * log |D|
Onde, n é o número de atributos no conjunto de dados de treinamento D e |D| é o número de tuplas.
Fonte
Figura 3: Uma divisão de valor discreta
As listas de algoritmos usados em uma árvore de decisão são:
ID3
Todo o conjunto de dados S é considerado como o nó raiz enquanto forma a árvore de decisão. A iteração é então realizada em cada atributo e a divisão dos dados em fragmentos. O algoritmo verifica e pega os atributos que não foram obtidos antes dos iterados. A divisão de dados no algoritmo ID3 é demorada e não é um algoritmo ideal, pois superajusta os dados.
C4.5
É uma forma avançada de algoritmo, pois os dados são classificados como amostras. Ambos os valores contínuos e discretos podem ser tratados de forma eficiente ao contrário do ID3. Método de poda está presente que remove os ramos indesejados.
CARRINHO
As tarefas de classificação e regressão podem ser executadas pelo algoritmo. Ao contrário de ID3 e C4.5, os pontos de decisão são criados considerando o índice de Gini. Um algoritmo guloso é aplicado para o método de divisão visando reduzir a função custo. Em tarefas de classificação, o índice de Gini é usado como função de custo para indicar a pureza dos nós folha. Em tarefas de regressão, o erro de soma ao quadrado é usado como função de custo para encontrar a melhor previsão.
PRESIDENTE
Como o nome sugere, significa Chi-square Automatic Interaction Detector, um processo que lida com qualquer tipo de variável. Podem ser variáveis nominais, ordinais ou contínuas. As árvores de regressão utilizam o teste F, enquanto o teste Qui-quadrado é utilizado no modelo de classificação.

MARTE
Significa splines de regressão adaptativa multivariada. O algoritmo é implementado especialmente em tarefas de regressão, onde os dados são em sua maioria não lineares.
Divisão binária recursiva gananciosa
Um método de divisão binária ocorre resultando em duas ramificações. A divisão das tuplas é realizada com o cálculo da função de custo de divisão. A divisão de custo mais baixa é selecionada e o processo é executado recursivamente para calcular a função de custo das outras tuplas.
Árvore de decisão com exemplo do mundo real
Preveja o processo de elegibilidade para empréstimos a partir de dados fornecidos.
Passo 1: Carregamento dos dados
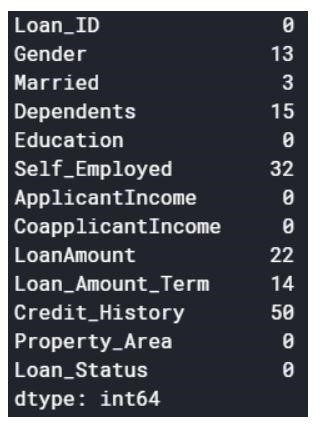
Os valores nulos podem ser descartados ou preenchidos com alguns valores. A forma do conjunto de dados original era (614,13), e o novo conjunto de dados após eliminar os valores nulos é (480,13).
Etapa 2: uma olhada no conjunto de dados.

Passo 3: Dividindo os dados em conjuntos de treinamento e teste.
Etapa 4: construir o modelo e ajustar o conjunto de trens

Antes da visualização, alguns cálculos devem ser feitos.
Cálculo 1: calcule a entropia do conjunto de dados total.

Cálculo 2: Encontre a entropia e o ganho para cada coluna.
- Coluna de gênero
- Condição 1: conjunto de dados com todos os machos e, em seguida,
p = 278, n=116, p+n=489
Entropia(G=Masculino) = 0,87
- Condição 2: conjunto de dados com todas as mulheres nele e, em seguida,
p = 54, n = 32, p+n = 86
Entropia(G=Feminino) = 0,95
- Informações médias na coluna de gênero

- coluna casada
- Condição 1: Casado = Sim(1)
Nesta divisão, todo o conjunto de dados com status de casado sim
p = 227, n = 84, p+n = 311
E(Casado = Sim) = 0,84
- Condição 2: Casado = Não(0)
Nesta divisão, todo o conjunto de dados com status de casado não
p = 105, n = 64, p+n = 169
E(Casado = Não) = 0,957
- A informação média na coluna Casado é
- Coluna educacional
- Condição 1: Educação = Graduado(1)
p = 271, n = 112, p+n = 383
E(Educação = Pós-graduação) = 0,87
- Condição 2: Educação = Não Graduado(0)
p = 61, n = 36, p+n = 97
E(Educação = Não Graduado) = 0,95
- Coluna Informação Média da Educação = 0,886
Ganho = 0,01
4) Coluna Autônomo
- Condição 1: Autônomo = Sim(1)
p = 43, n = 23, p+n = 66
E(Autonomo=Sim) = 0,93
- Condição 2: Autônomo = Não(0)
p = 289, n = 125, p+n = 414
E(Autónomo=Não) = 0,88
- Coluna Média de Informações em Autônomos na Educação = 0,886
Ganho = 0,01
- Coluna Credit Score: a coluna tem valor 0 e 1.
- Condição 1: pontuação de crédito = 1
p = 325, n = 85, p+n = 410
E(Pontuação de crédito = 1) = 0,73
- Condição 2: pontuação de crédito = 0
p = 63 , n = 7 , p + n = 70
E(Pontuação de crédito = 0) = 0,46
- Informações médias na coluna de pontuação de crédito = 0,69
Ganho = 0,2
Compare todos os valores de ganho

A pontuação de crédito tem o maior ganho. Portanto, ele será usado como o nó raiz.
Passo 5: Visualize a Árvore de Decisão

Figura 5: Árvore de decisão com critério Gini
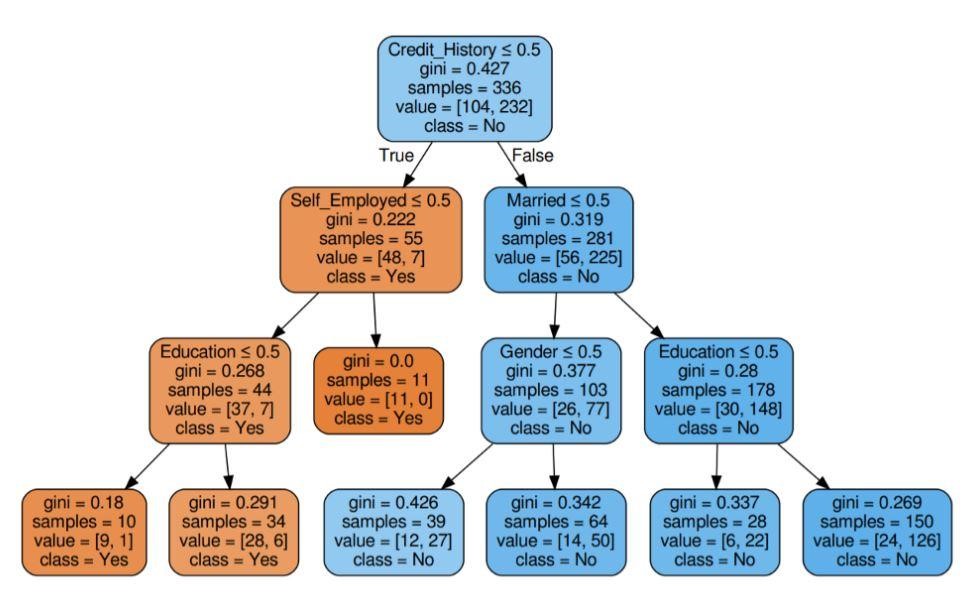 Fonte
Fonte
Figura 6: Árvore de decisão com entropia de critério
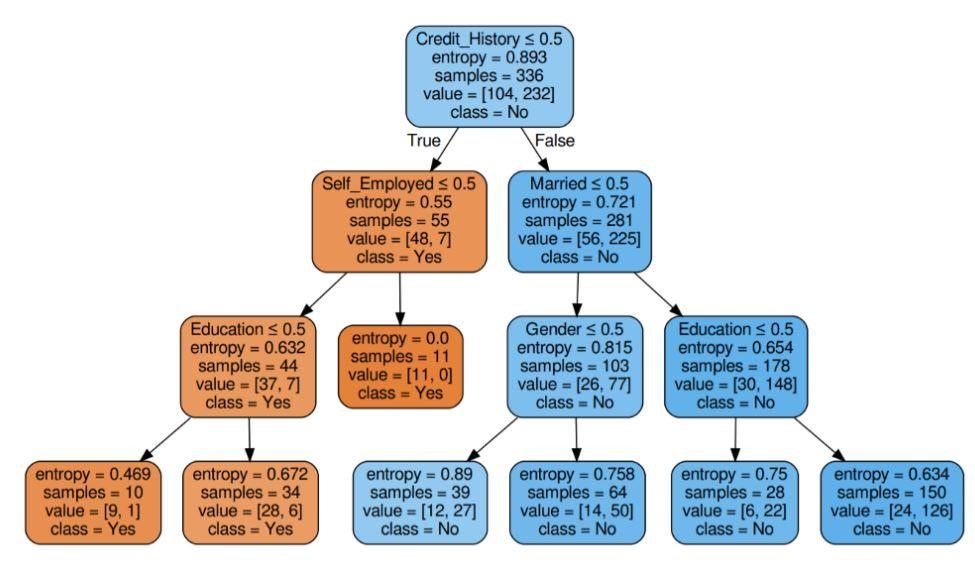
Fonte
Passo 6: Verifique a pontuação do modelo
Quase 80% por cento de precisão pontuada.
Lista de aplicativos
As árvores de decisão são usadas principalmente por especialistas em informação para realizar uma investigação analítica. Eles podem ser usados extensivamente para fins comerciais para analisar ou prever dificuldades. A flexibilidade da árvore de decisão permite que eles sejam usados em uma área diferente:
1. Saúde
As árvores de decisão permitem prever se um paciente está sofrendo de uma determinada doença com condições de idade, peso, sexo, etc. Outras previsões incluem decidir o efeito do medicamento considerando fatores como composição, período de fabricação, etc.
2. Setores bancários
As árvores de decisão ajudam a prever se uma pessoa é elegível para um empréstimo, considerando sua situação financeira, salário, membros da família, etc. Também pode identificar fraudes de cartão de crédito, inadimplência, etc.
3. Setores Educacionais
A pré-seleção de um aluno com base em sua pontuação de mérito, frequência, etc. pode ser decidida com a ajuda de árvores de decisão.
Lista de vantagens
- Os resultados interpretáveis de um modelo de decisão podem ser representados para a alta administração e as partes interessadas.
- Ao construir um modelo de árvore de decisão, o pré-processamento dos dados, ou seja, normalização, dimensionamento, etc. não é necessário.
- Ambos os tipos de dados numéricos e categóricos podem ser tratados por uma árvore de decisão que apresenta sua maior eficiência de uso em relação a outros algoritmos.
- O valor ausente nos dados não afeta o processo de uma árvore de decisão, tornando-o um algoritmo flexível.
Qual o proximo?
Se você estiver interessado em ganhar experiência prática em mineração de dados e ser treinado por especialistas, você pode conferir o Programa PG Executivo em Ciência de Dados do upGrad. O curso é direcionado para qualquer faixa etária entre 21-45 anos de idade com critérios mínimos de elegibilidade de 50% ou notas de aprovação equivalentes na graduação. Todos os profissionais que trabalham podem participar deste programa PG executivo certificado pelo ITT Bangalore.
Árvores de decisão na mineração de dados têm a capacidade de lidar com dados muito complicados. Todas as árvores de decisão têm três nós ou porções vitais. Vamos discutir cada um deles a seguir. Agora que entendemos o funcionamento das árvores de decisão, vamos tentar ver algumas vantagens de usar árvores de decisão na mineração de dadosO que é uma árvore de decisão em mineração de dados?
Uma árvore de decisão é uma maneira de construir modelos em mineração de dados. Pode ser entendido como uma árvore binária invertida. Ele inclui um nó raiz, algumas ramificações e nós folha no final.
Cada um dos nós internos em uma árvore de decisão significa um estudo sobre um atributo. Cada uma das divisões significa a consequência daquele estudo ou exame em particular. E, finalmente, cada nó folha representa uma tag de classe.
O objetivo principal de construir uma árvore de decisão é criar um ideal que possa ser utilizado para prever a classe particular usando procedimentos de julgamento em dados anteriores.
Começamos com o nó raiz, fazemos algumas relações com a variável raiz e fazemos divisões que concordam com esses valores. Com base nas escolhas básicas, saltamos para os nós subsequentes. Quais são alguns dos nós importantes usados nas Árvores de Decisão?
Quando conectamos todos esses nós, obtemos divisões. Podemos formar árvores com uma variedade de dificuldades usando esses nós e divisões por um número infinito de vezes. Quais são as vantagens de usar Árvores de Decisão?
1. Quando os comparamos com outros métodos, as árvores de decisão não requerem tanta computação para o treinamento dos dados durante o pré-processamento.
2. A estabilização da informação não está envolvida nas árvores de decisão.
3. Além disso, eles nem exigem escala de informações.
4. Mesmo que alguns valores sejam omitidos no conjunto de dados, isso não interfere na construção das árvores.
5. Esses modelos são idênticos instintivos. Eles são livres de estresse para descrição também.