
Entendendo os genéricos do TypeScript
Publicados: 2022-03-10Neste artigo, aprenderemos o conceito de genéricos no TypeScript e examinaremos como os genéricos podem ser usados para escrever código modular, desacoplado e reutilizável. Ao longo do caminho, discutiremos brevemente como eles se encaixam em melhores padrões de teste, abordagens para tratamento de erros e separação de domínio/acesso a dados.
Um exemplo do mundo real
Eu quero entrar no mundo dos genéricos não explicando o que eles são, mas fornecendo um exemplo intuitivo de por que eles são úteis. Suponha que você tenha recebido a tarefa de criar uma lista dinâmica rica em recursos. Você pode chamá-lo de array, ArrayList , List , std::vector , ou qualquer outra coisa, dependendo do seu histórico de idioma. Talvez essa estrutura de dados também deva ter sistemas de buffer embutidos ou intercambiáveis (como uma opção de inserção de buffer circular). Será um wrapper em torno do array JavaScript normal para que possamos trabalhar com nossa estrutura em vez de arrays simples.
O problema imediato que você encontrará é o das restrições impostas pelo sistema de tipos. Você não pode, neste ponto, aceitar qualquer tipo que desejar em uma função ou método de uma maneira limpa e agradável (revisitaremos esta declaração mais tarde).
A única solução óbvia é replicar nossa estrutura de dados para todos os tipos diferentes:
const intList = IntegerList.create(); intList.add(4); const stringList = StringList.create(); stringList.add('hello'); const userList = UserList.create(); userList.add(new User('Jamie')); A sintaxe .create() aqui pode parecer arbitrária e, de fato, new SomethingList() seria mais direto, mas você verá por que usamos esse método de fábrica estático mais tarde. Internamente, o método create chama o construtor.
Isso é terrível. Temos muita lógica dentro dessa estrutura de coleção e a estamos duplicando descaradamente para oferecer suporte a diferentes casos de uso, quebrando completamente o Princípio DRY no processo. Quando decidirmos alterar nossa implementação, teremos que propagar/refletir manualmente essas alterações em todas as estruturas e tipos que suportamos, incluindo tipos definidos pelo usuário, como no último exemplo acima. Suponha que a estrutura da coleção em si tivesse 100 linhas — seria um pesadelo manter várias implementações diferentes onde a única diferença entre elas são os tipos.
Uma solução imediata que pode vir à mente, especialmente se você tiver uma mentalidade OOP, é considerar um “supertipo” raiz, se desejar. Em C#, por exemplo, consiste um tipo pelo nome de object e object é um alias para a classe System.Object . No sistema de tipos do C#, todos os tipos, sejam eles predefinidos ou definidos pelo usuário e sejam tipos de referência ou tipos de valor, herdam direta ou indiretamente de System.Object . Isso significa que qualquer valor pode ser atribuído a uma variável do tipo object (sem entrar na semântica de pilha/heap e boxing/unboxing).
Nesse caso, nosso problema parece resolvido. Podemos simplesmente usar um tipo como any e isso nos permitirá armazenar o que quisermos em nossa coleção sem ter que duplicar a estrutura e, de fato, isso é muito verdadeiro:
const intList = AnyList.create(); intList.add(4); const stringList = AnyList.create(); stringList.add('hello'); const userList = AnyList.create(); userList.add(new User('Jamie')); Vejamos a implementação real de nossa lista usando any :
class AnyList { private values: any[] = []; private constructor (values: any[]) { this.values = values; // Some more construction work. } public add(value: any): void { this.values.push(value); } public where(predicate: (value: any) => boolean): AnyList { return AnyList.from(this.values.filter(predicate)); } public select(selector: (value: any) => any): AnyList { return AnyList.from(this.values.map(selector)); } public toArray(): any[] { return this.values; } public static from(values: any[]): AnyList { // Perhaps we perform some logic here. // ... return new AnyList(values); } public static create(values?: any[]): AnyList { return new AnyList(values ?? []); } // Other collection functions. // ... }Todos os métodos são relativamente simples, mas começaremos com o construtor. Sua visibilidade é privada, pois assumiremos que nossa lista é complexa e desejamos proibir construções arbitrárias. Também podemos querer executar a lógica antes da construção, portanto, por esses motivos e para manter o construtor puro, delegamos essas preocupações a métodos estáticos de fábrica/auxiliar, o que é considerado uma boa prática.
Os métodos estáticos from e create são fornecidos. O método from aceita uma matriz de valores, executa a lógica personalizada e, em seguida, usa-os para construir a lista. O método estático create recebe uma matriz opcional de valores para o caso de desejarmos semear nossa lista com dados iniciais. O “operador de coalescência nulo” ( ?? ) é usado para construir a lista com um array vazio caso não seja fornecido. Se o lado esquerdo do operando for null ou undefined , voltaremos para o lado direito, pois neste caso, values é opcional e, portanto, pode ser undefined . Você pode aprender mais sobre a coalescência nula na página de documentação relevante do TypeScript.
Eu também adicionei um select e um método where . Esses métodos apenas envolvem o map e o filter do JavaScript, respectivamente. select nos permite projetar uma matriz de elementos em uma nova forma com base na função seletora fornecida e where nos permite filtrar determinados elementos com base na função de predicado fornecida. O método toArray simplesmente converte a lista em um array retornando a referência de array que mantemos internamente.
Finalmente, suponha que a classe User contenha um método getName que retorna um nome e também aceita um nome como seu primeiro e único argumento construtor.
Nota: Alguns leitores reconhecerãoWhereeSelectdo LINQ do C#, mas lembre-se de que estou tentando manter isso simples, portanto, não estou preocupado com preguiça ou execução adiada. São otimizações que podem e devem ser feitas na vida real.
Além disso, como uma nota interessante, quero discutir o significado de “predicado”. Em Matemática Discreta e Lógica Proposicional, temos o conceito de “proposição”. Uma proposição é alguma afirmação que pode ser considerada verdadeira ou falsa, como “quatro é divisível por dois”. Um “predicado” é uma proposição que contém uma ou mais variáveis, portanto, a veracidade da proposição depende daquela dessas variáveis. Você pode pensar nisso como uma função, comoP(x) = x is divisible by two, pois precisamos saber o valor dexpara determinar se a afirmação é verdadeira ou falsa. Você pode aprender mais sobre lógica de predicados aqui.
Existem alguns problemas que surgirão com o uso de any . O compilador TypeScript não sabe nada sobre os elementos dentro da lista/array interno, portanto, não fornecerá nenhuma ajuda dentro de where ou select ou ao adicionar elementos:
// Providing seed data. const userList = AnyList.create([new User('Jamie')]); // This is fine and expected. userList.add(new User('Tom')); userList.add(new User('Alice')); // This is an acceptable input to the TS Compiler, // but it's not what we want. We'll definitely // be surprised later to find strings in a list // of users. userList.add('Hello, World!'); // Also acceptable. We have a large tuple // at this point rather than a homogeneous array. userList.add(0); // This compiles just fine despite the spelling mistake (extra 's'): // The type of `users` is any. const users = userList.where(user => user.getNames() === 'Jamie'); // Property `ssn` doesn't even exist on a `user`, yet it compiles. users.toArray()[0].ssn = '000000000'; // `usersWithId` is, again, just `any`. const usersWithId = userList.select(user => ({ id: newUuid(), name: user.getName() })); // Oops, it's "id" not "ID", but TS doesn't help us. // We compile just fine. console.log(usersWithId.toArray()[0].ID); Como o TypeScript sabe apenas que o tipo de todos os elementos do array é any , ele não pode nos ajudar em tempo de compilação com as propriedades inexistentes ou a função getNames que nem existe, portanto, esse código resultará em vários erros de tempo de execução inesperados .
Para ser honesto, as coisas estão começando a parecer bastante sombrias. Tentamos implementar nossa estrutura de dados para cada tipo concreto que desejávamos oferecer, mas logo percebemos que isso não era sustentável de forma alguma. Então, pensamos que estávamos chegando a algum lugar usando any , que é análogo a depender de um supertipo raiz em uma cadeia de herança da qual todos os tipos derivam, mas concluímos que perdemos a segurança de tipo com esse método. Qual é a solução, então?
Acontece que, no início do artigo, eu menti (mais ou menos):
“Você não pode, neste momento, aceitar qualquer tipo que você queira em uma função ou método de uma maneira limpa e agradável.”
Você realmente pode, e é aí que os genéricos entram. Observe que eu disse “neste ponto”, pois eu estava assumindo que não sabíamos sobre os genéricos naquele ponto do artigo.
Começarei mostrando a implementação completa de nossa estrutura List com Generics e, em seguida, daremos um passo atrás, discutiremos o que eles realmente são e determinaremos sua sintaxe de maneira mais formal. Eu o chamei de TypedList para diferenciar de nosso AnyList anterior:
class TypedList<T> { private values: T[] = []; private constructor (values: T[]) { this.values = values; } public add(value: T): void { this.values.push(value); } public where(predicate: (value: T) => boolean): TypedList<T> { return TypedList.from<T>(this.values.filter(predicate)); } public select<U>(selector: (value: T) => U): TypedList<U> { return TypedList.from<U>(this.values.map(selector)); } public toArray(): T[] { return this.values; } public static from<U>(values: U[]): TypedList<U> { // Perhaps we perform some logic here. // ... return new TypedList<U>(values); } public static create<U>(values?: U[]): TypedList<U> { return new TypedList<U>(values ?? []); } // Other collection functions. // .. }Vamos tentar cometer os mesmos erros de antes mais uma vez:
// Here's the magic. `TypedList` will operate on objects // of type `User` due to the `<User>` syntax. const userList = TypedList.create<User>([new User('Jamie')]); // The compiler expects this. userList.add(new User('Tom')); userList.add(new User('Alice')); // Argument of type '0' is not assignable to parameter // of type 'User'. ts(2345) userList.add(0); // Property 'getNames' does not exist on type 'User'. // Did you mean 'getName'? ts(2551) // Note: TypeScript infers the type of `users` to be // `TypedList<User>` const users = userList.where(user => user.getNames() === 'Jamie'); // Property 'ssn' does not exist on type 'User'. ts(2339) users.toArray()[0].ssn = '000000000'; // TypeScript infers `usersWithId` to be of type // `TypedList<`{ id: string, name: string }> const usersWithId = userList.select(user => ({ id: newUuid(), name: user.getName() })); // Property 'ID' does not exist on type '{ id: string; name: string; }'. // Did you mean 'id'? ts(2551) console.log(usersWithId.toArray()[0].ID)Como você pode ver, o compilador TypeScript está nos ajudando ativamente com a segurança de tipos. Todos esses comentários são erros que recebo do compilador ao tentar compilar este código. Os genéricos nos permitiram especificar um tipo no qual desejamos permitir que nossa lista opere e, a partir disso, o TypeScript pode dizer os tipos de tudo, até as propriedades de objetos individuais dentro da matriz.
Os tipos que fornecemos podem ser tão simples ou complexos quanto queremos que sejam. Aqui, você pode ver que podemos passar interfaces primitivas e complexas. Também poderíamos passar outros arrays, ou classes, ou qualquer coisa:
const numberList = TypedList.create<number>(); numberList.add(4); const stringList = TypedList.create<string>(); stringList.add('Hello, World'); // Example of a complex type interface IAircraft { apuStatus: ApuStatus; inboardOneRPM: number; altimeter: number; tcasAlert: boolean; pushBackAndStart(): Promise<void>; ilsCaptureGlidescope(): boolean; getFuelStats(): IFuelStats; getTCASHistory(): ITCASHistory; } const aircraftList = TypedList.create<IAircraft>(); aircraftList.add(/* ... */); // Aggregate and generate report: const stats = aircraftList.select(a => ({ ...a.getFuelStats(), ...a.getTCASHistory() })); Os usos peculiares de T e U e <T> e <U> na implementação TypedList<T> são exemplos de Genéricos em ação. Tendo cumprido nossa diretiva de construir uma estrutura de coleção de tipo seguro, deixaremos este exemplo para trás por enquanto e retornaremos a ele quando entendermos o que os Genéricos realmente são, como eles funcionam e sua sintaxe. Quando estou aprendendo um novo conceito, sempre gosto de começar vendo um exemplo complexo do conceito em uso, para que, quando começar a aprender o básico, possa fazer conexões entre os tópicos básicos e o exemplo existente que tenho em meu cabeça.
O que são genéricos?
Uma maneira simples de entender os Genéricos é considerá-los como relativamente análogos a marcadores de posição ou variáveis, mas para tipos. Isso não quer dizer que você pode executar as mesmas operações em um espaço reservado de tipo genérico como em uma variável, mas uma variável de tipo genérico pode ser pensada como algum espaço reservado que representa um tipo concreto que será usado no futuro. Ou seja, usar Genéricos é um método de escrever programas em termos de tipos que devem ser especificados posteriormente. A razão pela qual isso é útil é porque nos permite construir estruturas de dados que são reutilizáveis nos diferentes tipos em que operam (ou independentes de tipo).
Essa não é particularmente a melhor das explicações, então para colocar em termos mais simples, como vimos, é comum em programação que possamos precisar construir uma estrutura de função/classe/dados que irá operar em um determinado tipo, mas é igualmente comum que essa estrutura de dados também precise funcionar em vários tipos diferentes. Se estivéssemos presos em uma posição em que tivéssemos que declarar estaticamente o tipo concreto sobre o qual uma estrutura de dados operaria no momento em que projetamos a estrutura de dados (em tempo de compilação), descobriríamos rapidamente que precisamos reconstruir esses estruturas de maneira quase exatamente da mesma maneira para cada tipo que desejamos suportar, como vimos nos exemplos acima.
Os genéricos nos ajudam a resolver esse problema, permitindo-nos adiar o requisito de um tipo concreto até que ele seja realmente conhecido.
Genéricos em TypeScript
Agora temos uma ideia orgânica de por que os genéricos são úteis e vimos um exemplo um pouco complicado deles na prática. Para a maioria, a implementação de TypedList<T> provavelmente já faz muito sentido, especialmente se você vem de uma linguagem de tipagem estática, mas lembro-me de ter dificuldade em entender o conceito quando estava aprendendo, então quero construa esse exemplo começando com funções simples. Conceitos relacionados à abstração em software podem ser notoriamente difíceis de internalizar, portanto, se a noção de Genéricos ainda não clicou, tudo bem, e esperamos que, ao final deste artigo, a ideia seja pelo menos um pouco intuitiva.
Para ser capaz de entender esse exemplo, vamos trabalhar a partir de funções simples. Começaremos com a “Função Identidade”, que é o que a maioria dos artigos, incluindo a própria documentação do TypeScript, gosta de usar.
Uma “Função Identidade”, em matemática, é uma função que mapeia sua entrada diretamente para sua saída, como f(x) = x . O que você coloca é o que você sai. Podemos representar isso, em JavaScript, como:
function identity(input) { return input; }Ou, mais sucintamente:
const identity = input => input; Tentar portar isso para o TypeScript traz de volta os mesmos problemas de sistema de tipo que vimos antes. As soluções estão digitando com any , o que sabemos que raramente é uma boa ideia, duplicando/sobrecarregando a função para cada tipo (quebra DRY), ou usando Generics.
Com a última opção, podemos representar a função da seguinte forma:
// ES5 Function function identity<T>(input: T): T { return input; } // Arrow Function const identity = <T>(input: T): T => input; console.log(identity<number>(5)); // 5 console.log(identity<string>('hello')); // hello A sintaxe <T> aqui declara esta função como Genérica. Assim como uma função nos permite passar um parâmetro de entrada arbitrário para sua lista de argumentos, com uma função Genérica, também podemos passar um parâmetro de tipo arbitrário.
A parte <T> da assinatura de identity<T>(input: T): T e <T>(input: T): T em ambos os casos declara que a função em questão aceitará um parâmetro de tipo genérico chamado T . Assim como as variáveis podem ter qualquer nome, nossos marcadores genéricos também podem, mas é uma convenção usar uma letra maiúscula “T” (“T” para “Tipo”) e mover o alfabeto conforme necessário. Lembre-se, T é um tipo, então também afirmamos que aceitaremos um argumento de função de input de nome com um tipo de T e que nossa função retornará um tipo de T . Isso é tudo que a assinatura está dizendo. Tente deixar T = string em sua cabeça – substitua todos os T s por string nessas assinaturas. Veja como nada tão mágico está acontecendo? Veja como é semelhante à maneira não genérica de usar funções todos os dias?
Lembre-se do que você já sabe sobre o TypeScript e as assinaturas de função. Tudo o que estamos dizendo é que T é um tipo arbitrário que o usuário fornecerá ao chamar a função, assim como input é um valor arbitrário que o usuário fornecerá ao chamar a função. Nesse caso, input deve ser qualquer que seja o tipo T quando a função for chamada no futuro .
A seguir, no “futuro”, nas duas declarações de log, “passamos” o tipo concreto que desejamos usar, assim como fazemos com uma variável. Observe a troca de palavreado aqui — na forma inicial da <T> signature , ao declarar nossa função, ela é genérica — ou seja, funciona em tipos genéricos, ou tipos a serem especificados posteriormente. Isso porque não sabemos que tipo o chamador desejará usar quando escrevermos a função. Mas, quando o chamador chama a função, ele sabe exatamente com que tipo(s) quer trabalhar, que são string e number neste caso.
Você pode imaginar a ideia de ter uma função de log declarada dessa maneira em uma biblioteca de terceiros — o autor da biblioteca não tem ideia de quais tipos os desenvolvedores que usam a lib vão querer usar, então eles tornam a função genérica, essencialmente adiando a necessidade para tipos concretos até que sejam realmente conhecidos.
Quero enfatizar que você deve pensar nesse processo de maneira semelhante à noção de passar uma variável para uma função com o objetivo de obter uma compreensão mais intuitiva. Tudo o que estamos fazendo agora é passar um tipo também.
No ponto em que chamamos a função com o parâmetro number , a assinatura original, para todos os efeitos, pode ser pensada como identity(input: number): number . E, no ponto em que chamamos a função com o parâmetro string , novamente, a assinatura original poderia muito bem ter sido identity(input: string): string . Você pode imaginar que, ao fazer a chamada, todo T genérico é substituído pelo tipo concreto que você fornece naquele momento.
Explorando a sintaxe genérica
Existem diferentes sintaxes e semânticas para especificar genéricos no contexto de funções ES5, funções de seta, aliases de tipo, interfaces e classes. Vamos explorar essas diferenças nesta seção.
Explorando a sintaxe genérica — Funções
Você já viu alguns exemplos de funções genéricas, mas é importante observar que uma função genérica pode aceitar mais de um parâmetro de tipo genérico, assim como variáveis. Você pode optar por pedir um, ou dois, ou três, ou quantos tipos desejar, todos separados por vírgulas (novamente, assim como os argumentos de entrada).
Esta função aceita três tipos de entrada e retorna aleatoriamente um deles:
function randomValue<T, U, V>( one: T, two: U, three: V ): T | U | V { // This is a tuple if you're not familiar. const options: [T, U, V] = [ one, two, three ]; const rndNum = getRndNumInInclusiveRange(0, 2); return options[rndNum]; } // Calling the function. // `value` has type `string | number | IAircraft` const value = randomValue< string, number, IAircraft >( myString, myNumber, myAircraft );Você também pode ver que a sintaxe é um pouco diferente dependendo se usamos uma função ES5 ou uma função de seta, mas ambas declaram os parâmetros de tipo na assinatura:
const randomValue = <T, U, V>( one: T, two: U, three: V ): T | U | V => { // This is a tuple if you're not familiar. const options: [T, U, V] = [ one, two, three ]; const rndNum = getRndNumInInclusiveRange(0, 2); return options[rndNum]; } Lembre-se de que não há "restrição de exclusividade" imposta aos tipos — você pode passar qualquer combinação que desejar, como duas string e um number , por exemplo. Além disso, assim como os argumentos de entrada estão “no escopo” do corpo da função, os parâmetros de tipo genérico também estão. O exemplo anterior demonstra que temos acesso total a T , U e V de dentro do corpo da função e os usamos para declarar uma 3-tupla local.
Você pode imaginar que esses genéricos operam em um determinado “contexto” ou dentro de um determinado “tempo de vida”, e isso depende de onde eles são declarados. Os genéricos em funções estão no escopo dentro da assinatura e do corpo da função (e encerramentos criados por funções aninhadas), enquanto os genéricos declarados em uma classe ou interface ou alias de tipo estão no escopo de todos os membros da classe ou interface ou alias de tipo.
A noção de genéricos em funções não se limita a “funções livres” ou “funções flutuantes” (funções não anexadas a um objeto ou classe, um termo C++), mas também podem ser usadas em funções anexadas a outras estruturas.
Podemos colocar esse randomValue em uma classe e podemos chamá-lo da mesma forma:
class Utils { public randomValue<T, U, V>( one: T, two: U, three: V ): T | U | V { // ... } // Or, as an arrow function: public randomValue = <T, U, V>( one: T, two: U, three: V ): T | U | V => { // ... } }Também poderíamos colocar uma definição dentro de uma interface:
interface IUtils { randomValue<T, U, V>( one: T, two: U, three: V ): T | U | V; }Ou dentro de um alias de tipo:
type Utils = { randomValue<T, U, V>( one: T, two: U, three: V ): T | U | V; }Assim como antes, esses parâmetros de tipo genérico estão “no escopo” para essa função específica – eles não são de classe, interface ou tipo de alias. Eles vivem apenas dentro da função específica sobre a qual são especificados. Para compartilhar um tipo genérico entre todos os membros de uma estrutura, você deve anotar o próprio nome da estrutura, como veremos a seguir.
Explorando a sintaxe genérica — aliases de tipo
Com Type Aliases, a sintaxe genérica é usada no nome do alias.
Por exemplo, alguma função de “ação” que aceita um valor, possivelmente altera esse valor, mas retorna void pode ser escrita como:
type Action<T> = (val: T) => void;Observação : isso deve ser familiar para desenvolvedores C# que entendem o delegado Action<T>.
Ou, uma função de retorno de chamada que aceita um erro e um valor pode ser declarada como tal:
type CallbackFunction<T> = (err: Error, data: T) => void; const usersApi = { get(uri: string, cb: CallbackFunction<User>) { /// ... } }Com nosso conhecimento de genéricos de função, poderíamos ir além e tornar a função no objeto da API genérica também:
type CallbackFunction<T> = (err: Error, data: T) => void; const api = { // `T` is available for use within this function. get<T>(uri: string, cb: CallbackFunction<T>) { /// ... } } Agora, estamos dizendo que a função get aceita algum parâmetro de tipo genérico e, seja o que for, CallbackFunction o recebe. Nós essencialmente “passamos” o T que entra em get como o T para CallbackFunction . Talvez isso faça mais sentido se mudarmos os nomes:
type CallbackFunction<TData> = (err: Error, data: TData) => void; const api = { get<TResponse>(uri: string, cb: CallbackFunction<TResponse>) { // ... } } Prefixar parâmetros de tipo com T é meramente uma convenção, assim como prefixar interfaces com I ou variáveis de membro com _ . O que você pode ver aqui é que CallbackFunction aceita algum tipo ( TData ) que representa a carga útil de dados disponível para a função, enquanto get aceita um parâmetro de tipo que representa o tipo/forma de dados da Resposta HTTP ( TResponse ). O HTTP Client ( api ), semelhante ao Axios, usa o que quer que seja TResponse como o TData para CallbackFunction . Isso permite que o chamador da API selecione o tipo de dados que receberá de volta da API (suponha que em algum outro lugar no pipeline temos um middleware que analisa o JSON em um DTO).
Se quiséssemos ir um pouco mais longe, poderíamos modificar os parâmetros de tipo genérico em CallbackFunction para aceitar um tipo de erro personalizado também:
type CallbackFunction<TData, TError> = (err: TError, data: TData) => void;E, assim como você pode tornar os argumentos de função opcionais, você também pode com parâmetros de tipo. Caso o usuário não forneça um tipo de erro, vamos defini-lo para o construtor de erro por padrão:
type CallbackFunction<TData, TError = Error> = (err: TError, data: TData) => void;Com isso, agora podemos especificar um tipo de função de retorno de chamada de várias maneiras:
const apiOne = { // `Error` is used by default for `CallbackFunction`. get<TResponse>(uri: string, cb: CallbackFunction<TResponse>) { // ... } }; apiOne.get<string>('uri', (err: Error, data: string) => { // ... }); const apiTwo = { // Override the default and use `HttpError` instead. get<TResponse>(uri: string, cb: CallbackFunction<TResponse, HttpError>) { // ... } }; apiTwo.get<string>('uri', (err: HttpError, data: string) => { // ... });Essa ideia de parâmetros padrão é aceitável em funções, classes, interfaces e assim por diante — não se limita apenas a aliases de tipo. Em todos os exemplos que vimos até agora, poderíamos ter atribuído qualquer parâmetro de tipo que quiséssemos a um valor padrão. Os aliases de tipo, assim como as funções, podem receber quantos parâmetros de tipo genéricos você desejar.
Explorando a sintaxe genérica — Interfaces
Como você viu, um parâmetro de tipo genérico pode ser fornecido a uma função em uma interface:
interface IUselessFunctions { // Not generic printHelloWorld(); // Generic identity<T>(t: T): T; } Neste caso, T vive apenas para a função de identity como seu tipo de entrada e retorno.
Também podemos disponibilizar um parâmetro de tipo para todos os membros de uma interface, assim como com classes e aliases de tipo, especificando que a própria interface aceita um genérico. Falaremos sobre o Repository Pattern um pouco mais tarde quando discutirmos casos de uso mais complexos para genéricos, então tudo bem se você nunca ouviu falar dele. O Repository Pattern nos permite abstrair nosso armazenamento de dados para tornar a lógica de negócios independente de persistência. Se você desejasse criar uma interface de repositório genérica que operasse em tipos de entidade desconhecidos, poderíamos digitá-la da seguinte forma:
interface IRepository<T> { add(entity: T): Promise<void>; findById(id: string): Promise<T>; updateById(id: string, updated: T): Promise<void>; removeById(id: string): Promise<void>; }Nota : Existem muitos pensamentos diferentes sobre Repositórios, desde a definição de Martin Fowler até a definição de DDD Aggregate. Estou apenas tentando mostrar um caso de uso para genéricos, então não estou muito preocupado em estar totalmente correto em termos de implementação. Definitivamente, há algo a ser dito para não usar repositórios genéricos, mas falaremos sobre isso mais tarde.
Como você pode ver aqui, IRepository é uma interface que contém métodos para armazenar e recuperar dados. Ele opera em algum parâmetro de tipo genérico chamado T , e T é usado como entrada para add e updateById , bem como o resultado da resolução da promessa de findById .
Lembre-se de que há uma grande diferença entre aceitar um parâmetro de tipo genérico no nome da interface em vez de permitir que cada função aceite um parâmetro de tipo genérico. O primeiro, como fizemos aqui, garante que cada função dentro da interface opere no mesmo tipo T . Ou seja, para um IRepository<User> , todo método que usa T na interface agora está trabalhando em objetos User . Com o último método, cada função poderia trabalhar com qualquer tipo que desejasse. Seria muito peculiar poder apenas adicionar User ao Repositório, mas poder receber Policies ou Orders de volta, por exemplo, que é a situação potencial em que nos encontraríamos se não pudéssemos impor que o tipo é uniforme em todos os métodos.
Uma determinada interface pode conter não apenas um tipo compartilhado, mas também tipos exclusivos para seus membros. Por exemplo, se quiséssemos imitar um array, poderíamos digitar uma interface como esta:
interface IArray<T> { forEach(func: (elem: T, index: number) => void): this; map<U>(func: (elem: T, index: number) => U): IArray<U>; } Nesse caso, tanto forEach quanto map têm acesso a T a partir do nome da interface. Como dito, você pode imaginar que T está no escopo de todos os membros da interface. Apesar disso, nada impede que funções individuais também aceitem seus próprios parâmetros de tipo. A função map faz, com U . Agora, o map tem acesso a T e U . Tivemos que nomear o parâmetro com uma letra diferente, como U , porque T já foi usado e não queremos uma colisão de nomenclatura. Assim como seu nome, map irá “mapear” elementos do tipo T dentro do array para novos elementos do tipo U . Ele mapeia T s para U s. O valor de retorno dessa função é a própria interface, agora operando no novo tipo U , para que possamos imitar um pouco a sintaxe fluente do JavaScript para arrays.
Veremos um exemplo do poder de Generics e Interfaces em breve quando implementarmos o Repository Pattern e discutirmos a injeção de dependência. Mais uma vez, podemos aceitar tantos parâmetros genéricos quanto selecionar um ou mais parâmetros padrão empilhados no final de uma interface.
Explorando a sintaxe genérica — classes
Da mesma forma que podemos passar um parâmetro de tipo genérico para um alias de tipo, função ou interface, também podemos passar um ou mais para uma classe. Ao fazer isso, esse parâmetro de tipo estará acessível a todos os membros dessa classe, bem como a classes base estendidas ou interfaces implementadas.
Vamos construir outra classe de coleção, mas um pouco mais simples que TypedList acima, para que possamos ver a interoperabilidade entre tipos genéricos, interfaces e membros. Veremos um exemplo de passagem de um tipo para uma classe base e herança de interface um pouco mais tarde.
Nossa coleção irá meramente suportar funções CRUD básicas além de um método map e forEach .
class Collection<T> { private elements: T[] = []; constructor (elements: T[] = []) { this.elements = elements; } add(elem: T): void { this.elements.push(elem); } contains(elem: T): boolean { return this.elements.includes(elem); } remove(elem: T): void { this.elements = this.elements.filter(existing => existing !== elem); } forEach(func: (elem: T, index: number) => void): void { return this.elements.forEach(func); } map<U>(func: (elem: T, index: number) => U): Collection<U> { return new Collection<U>(this.elements.map(func)); } } const stringCollection = new Collection<string>(); stringCollection.add('Hello, World!'); const numberCollection = new Collection<number>(); numberCollection.add(3.14159); const aircraftCollection = new Collection<IAircraft>(); aircraftCollection.add(myAircraft); Vamos discutir o que está acontecendo aqui. A classe Collection aceita um parâmetro de tipo genérico chamado T . Esse tipo se torna acessível a todos os membros da classe. Nós o usamos para definir um array privado do tipo T[] , que também poderíamos ter denotado na forma Array<T> (Veja? Genéricos novamente para tipagem de array TS normal). Além disso, a maioria das funções de membro utiliza esse T de alguma forma, como controlando os tipos que são adicionados e removidos ou verificando se a coleção contém um elemento.
Finalmente, como vimos antes, o método map requer seu próprio parâmetro de tipo genérico. We need to define in the signature of map that some type T is mapped to some type U through a callback function, thus we need a U . That U is unique to that function in particular, which means we could have another function in that class that also accepts some type named U , and that'd be fine, because those types are only “in scope” for their functions and not shared across them, thus there are no naming collisions. What we can't do is have another function that accepts a generic parameter named T , for that'd conflict with the T from the class signature.

You can see that when we call the constructor, we pass in the type we want to work with (that is, what type each element of the internal array will be). In the calling code at the bottom of the example, we work with string s, number s, and IAircraft s.
How could we make this work with an interface? What if we have different collection interfaces that we might want to swap out or inject into calling code? To get that level of reduced coupling (low coupling and high cohesion is what we should always aim for), we'll need to depend on an abstraction. Generally, that abstraction will be an interface, but it could also be an abstract class.
Our collection interface will need to be generic, so let's define it:
interface ICollection<T> { add(t: T): void; contains(t: T): boolean; remove(t: T): void; forEach(func: (elem: T, index: number) => void): void; map<U>(func: (elem: T, index: number) => U): ICollection<U>; }Now, let's suppose we have different kinds of collections. We could have an in-memory collection, one that stores data on disk, one that uses a database, and so on. By having an interface, the dependent code can depend upon the abstraction, permitting us to swap out different implementations without affecting the existing code. Here is the in-memory collection.
class InMemoryCollection<T> implements ICollection<T> { private elements: T[] = []; constructor (elements: T[] = []) { this.elements = elements; } add(elem: T): void { this.elements.push(elem); } contains(elem: T): boolean { return this.elements.includes(elem); } remove(elem: T): void { this.elements = this.elements.filter(existing => existing !== elem); } forEach(func: (elem: T, index: number) => void): void { return this.elements.forEach(func); } map<U>(func: (elem: T, index: number) => U): ICollection<U> { return new InMemoryCollection<U>(this.elements.map(func)); } } The interface describes the public-facing methods and properties that our class is required to implement, expecting you to pass in a concrete type that those methods will operate upon. However, at the time of defining the class, we still don't know what type the API caller will wish to use. Thus, we make the class generic too — that is, InMemoryCollection expects to receive some generic type T , and whatever it is, it's immediately passed to the interface, and the interface methods are implemented using that type.
Calling code can now depend on the interface:
// Using type annotation to be explicit for the purposes of the // tutorial. const userCollection: ICollection<User> = new InMemoryCollection<User>(); function manageUsers(userCollection: ICollection<User>) { userCollection.add(new User()); } With this, any kind of collection can be passed into the manageUsers function as long as it satisfies the interface. This is useful for testing scenarios — rather than dealing with over-the-top mocking libraries, in unit and integration test scenarios, I can replace my SqlServerCollection<T> (for example) with InMemoryCollection<T> instead and perform state-based assertions instead of interaction-based assertions. This setup makes my tests agnostic to implementation details, which means they are, in turn, less likely to break when refactoring the SUT.
At this point, we should have worked up to the point where we can understand that first TypedList<T> example. Here it is again:
class TypedList<T> { private values: T[] = []; private constructor (values: T[]) { this.values = values; } public add(value: T): void { this.values.push(value); } public where(predicate: (value: T) => boolean): TypedList<T> { return TypedList.from<T>(this.values.filter(predicate)); } public select<U>(selector: (value: T) => U): TypedList<U> { return TypedList.from<U>(this.values.map(selector)); } public toArray(): T[] { return this.values; } public static from<U>(values: U[]): TypedList<U> { // Perhaps we perform some logic here. // ... return new TypedList<U>(values); } public static create<U>(values?: U[]): TypedList<U> { return new TypedList<U>(values ?? []); } // Other collection functions. // .. } The class itself accepts a generic type parameter named T , and all members of the class are provided access to it. The instance method select and the two static methods from and create , which are factories, accept their own generic type parameter named U .
The create static method permits the construction of a list with optional seed data. It accepts some type named U to be the type of every element in the list as well as an optional array of U elements, typed as U[] . When it calls the list's constructor with new , it passes that type U as the generic parameter to TypedList . This creates a new list where the type of every element is U . It is exactly the same as how we could call the constructor of our collection class earlier with new Collection<SomeType>() . The only difference is that the generic type is now passing through the create method rather than being provided and used at the top-level.
I want to make sure this is really, really clear. I've stated a few times that we can think about passing around types in a similar way that we do variables. It should already be quite intuitive that we can pass a variable through as many layers of indirection as we please. Forget generics and types for a moment and think about an example of the form:
class MyClass { private constructor (t: number) {} public static create(u: number) { return new MyClass(u); } } const myClass = MyClass.create(2.17); This is very similar to what is happening with the more-involved example, the difference being that we're working on generic type parameters, not variables. Here, 2.17 becomes the u in create , which ultimately becomes the t in the private constructor.
In the case of generics:
class MyClass<T> { private constructor () {} public static create<U>() { return new MyClass<U>(); } } const myClass = MyClass.create<number>(); The U passed to create is ultimately passed in as the T for MyClass<T> . When calling create , we provided number as U , thus now U = number . We put that U (which, again, is just number ) into the T for MyClass<T> , so that MyClass<T> effectively becomes MyClass<number> . The benefit of generics is that we're opened up to be able to work with types in this abstract and high-level fashion, similar to how we can normal variables.
The from method constructs a new list that operates on an array of elements of type U . It uses that type U , just like create , to construct a new instance of the TypedList class, now passing in that type U for T .
The where instance method performs a filtering operation based upon a predicate function. There's no mapping happening, thus the types of all elements remain the same throughout. The filter method available on JavaScript's array returns a new array of values, which we pass into the from method. So, to be clear, after we filter out the values that don't satisfy the predicate function, we get an array back containing the elements that do. All those elements are still of type T , which is the original type that the caller passed to create when the list was first created. Those filtered elements get given to the from method, which in turn creates a new list containing all those values, still using that original type T . The reason why we return a new instance of the TypedList class is to be able to chain new method calls onto the return result. This adds an element of “immutability” to our list.
Hopefully, this all provides you with a more intuitive example of generics in practice, and their reason for existence. Next, we'll look at a few of the more advanced topics.
Generic Type Inference
Throughout this article, in all cases where we've used generics, we've explicitly defined the type we're operating on. It's important to note that in most cases, we do not have to explicitly define the type parameter we pass in, for TypeScript can infer the type based on usage.
If I have some function that returns a random number, and I pass the return result of that function to identity from earlier without specifying the type parameter, it will be inferred automatically as number :
// `value` is inferred as type `number`. const value = identity(getRandomNumber()); Para demonstrar a inferência de tipo, removi todas as anotações de tipo tecnicamente estranhas de nossa estrutura TypedList anteriormente e você pode ver, nas imagens abaixo, que o TSC ainda infere todos os tipos corretamente:
TypedList sem declarações de tipo estranhas:
class TypedList<T> { private values: T[] = []; private constructor (values: T[]) { this.values = values; } public add(value: T) { this.values.push(value); } public where(predicate: (value: T) => boolean) { return TypedList.from(this.values.filter(predicate)); } public select<U>(selector: (value: T) => U) { return TypedList.from(this.values.map(selector)); } public toArray() { return this.values; } public static from<U>(values: U[]) { // Perhaps we perform some logic here. // ... return new TypedList(values); } public static create<U>(values?: U[]) { return new TypedList(values ?? []); } // Other collection functions. // .. } Com base nos valores de retorno da função e nos tipos de entrada passados from e do construtor, o TSC entende todas as informações de tipo. Na imagem abaixo, juntei várias imagens que mostram a extensão de linguagem do Code TypeScript do Visual Studio (e, portanto, o compilador) inferindo todos os tipos:
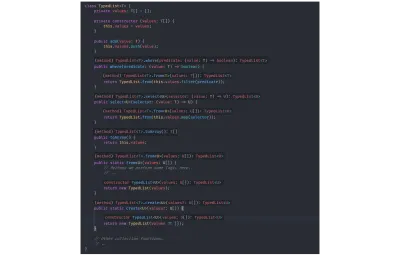
Restrições genéricas
Às vezes, queremos colocar uma restrição em torno de um tipo genérico. Talvez não possamos dar suporte a todos os tipos existentes, mas podemos dar suporte a um subconjunto deles. Digamos que queremos construir uma função que retorne o tamanho de alguma coleção. Como visto acima, poderíamos ter muitos tipos diferentes de arrays/coleções, desde o padrão JavaScript Array até nossos personalizados. Como deixamos nossa função saber que algum tipo genérico tem uma propriedade de length anexada a ele? Da mesma forma, como restringir os tipos concretos que passamos para a função àqueles que contêm os dados de que precisamos? Um exemplo como este, por exemplo, não funcionaria:
function getLength<T>(collection: T): number { // Error. TS does not know that a type T contains a `length` property. return collection.length; }A resposta é utilizar restrições genéricas. Podemos definir uma interface que descreve as propriedades que precisamos:
interface IHasLength { length: number; }Agora, ao definir nossa função genérica, podemos restringir o tipo genérico a ser aquele que estende essa interface:
function getLength<T extends IHasLength>(collection: T): number { // Restricting `collection` to be a type that contains // everything within the `IHasLength` interface. return collection.length; }Exemplos do mundo real
Nas próximas seções, discutiremos alguns exemplos do mundo real de genéricos que criam códigos mais elegantes e fáceis de raciocinar. Vimos muitos exemplos triviais, mas quero discutir algumas abordagens para tratamento de erros, padrões de acesso a dados e estado/props React front-end.
Exemplos do mundo real - Abordagens para tratamento de erros
JavaScript contém um mecanismo de primeira classe para lidar com erros, assim como a maioria das linguagens de programação — try / catch . Apesar disso, não sou muito fã de como fica quando usado. Isso não quer dizer que eu não use o mecanismo, eu uso, mas tento escondê-lo o máximo que posso. Ao abstrair o try / catch , também posso reutilizar a lógica de tratamento de erros em operações com probabilidade de falha.
Suponha que estamos construindo alguma camada de acesso a dados. Esta é uma camada do aplicativo que envolve a lógica de persistência para lidar com o método de armazenamento de dados. Se estivermos executando operações de banco de dados e se esse banco de dados for usado em uma rede, é provável que ocorram erros específicos de banco de dados e exceções transitórias. Parte do motivo de ter uma camada de acesso a dados dedicada é abstrair o banco de dados da lógica de negócios. Devido a isso, não podemos ter esses erros específicos de banco de dados sendo lançados na pilha e fora dessa camada. Precisamos embrulhá-los primeiro.
Vejamos uma implementação típica que usaria try / catch :
async function queryUser(userID: string): Promise<User> { try { const dbUser = await db.raw(` SELECT * FROM users WHERE user_id = ? `, [userID]); return mapper.toDomain(dbUser); } catch (e) { switch (true) { case e instanceof DbErrorOne: return Promise.reject(new WrapperErrorOne()); case e instanceof DbErrorTwo: return Promise.reject(new WrapperErrorTwo()); case e instanceof NetworkError: return Promise.reject(new TransientException()); default: return Promise.reject(new UnknownError()); } } } Alternar true é apenas um método para poder usar as instruções switch case para minha lógica de verificação de erros, em vez de ter que declarar uma cadeia de if/else if — um truque que ouvi pela primeira vez de @Jeffijoe.
Se tivermos várias dessas funções, teremos que replicar essa lógica de encapsulamento de erros, o que é uma prática muito ruim. Parece muito bom para uma função, mas será um pesadelo para muitas. Para abstrair essa lógica, podemos envolvê-la em uma função personalizada de tratamento de erros que passará pelo resultado, mas capturará e encapsulará quaisquer erros que sejam lançados:
async function withErrorHandling<T>( dalOperation: () => Promise<T> ): Promise<T> { try { // This unwraps the promise and returns the type `T`. return await dalOperation(); } catch (e) { switch (true) { case e instanceof DbErrorOne: return Promise.reject(new WrapperErrorOne()); case e instanceof DbErrorTwo: return Promise.reject(new WrapperErrorTwo()); case e instanceof NetworkError: return Promise.reject(new TransientException()); default: return Promise.reject(new UnknownError()); } } } Para garantir que isso faça sentido, temos uma função intitulada withErrorHandling que aceita algum parâmetro de tipo genérico T . Esse T representa o tipo do valor de resolução bem-sucedido da promessa que esperamos retornar da função de retorno de chamada dalOperation . Normalmente, como estamos apenas retornando o resultado de retorno da função assíncrona dalOperation , não precisaríamos await para que isso envolvesse a função em uma segunda promessa estranha e poderíamos deixar a await para o código de chamada. Nesse caso, precisamos capturar quaisquer erros, portanto, await é necessário.
Agora podemos usar esta função para envolver nossas operações DAL anteriores:
async function queryUser(userID: string) { return withErrorHandling<User>(async () => { const dbUser = await db.raw(` SELECT * FROM users WHERE user_id = ? `, [userID]); return mapper.toDomain(dbUser); }); }E lá vamos nós. Temos uma função de consulta de usuário de função segura de tipo e de erro.
Além disso, como você viu anteriormente, se o compilador TypeScript tiver informações suficientes para inferir os tipos implicitamente, você não precisará passá-los explicitamente. Nesse caso, o TSC sabe que o resultado de retorno da função é o tipo genérico. Assim, se mapper.toDomain(user) retornasse um tipo de User , você não precisaria passar o tipo:
async function queryUser(userID: string) { return withErrorHandling(async () => { const dbUser = await db.raw(` SELECT * FROM users WHERE user_id = ? `, [userID]); return mapper.toDomain(user); }); } Outra abordagem de tratamento de erros que eu costumo gostar é a dos Tipos Monádicos. O Both Monad é um tipo de dados algébrico da forma Either<T, U> , em que T pode representar um tipo de erro e U pode representar um tipo de falha. O uso de Tipos Monádicos atende à programação funcional, e um grande benefício é que os erros se tornam seguros para o tipo — uma assinatura de função normal não informa nada ao chamador da API sobre quais erros essa função pode gerar. Suponha que lançamos um erro NotFound de dentro de queryUser . Uma assinatura de queryUser(userID: string): Promise<User> não nos diz nada sobre isso. Mas, uma assinatura como queryUser(userID: string): Promise<Either<NotFound, User>> absolutamente faz. Eu não vou explicar como mônadas como a Both Monad funcionam neste artigo porque elas podem ser bastante complexas, e há uma variedade de métodos que eles devem ter para serem considerados monádicos, como mapeamento/ligação. Se você quiser saber mais sobre eles, eu recomendo duas das palestras NDC de Scott Wlaschin, aqui e aqui, bem como a palestra de Daniel Chamber aqui. Este site, bem como essas postagens de blog, também podem ser úteis.
Exemplos do mundo real — Padrão de repositório
Vamos dar uma olhada em outro caso de uso em que os genéricos podem ser úteis. A maioria dos sistemas de back-end são obrigados a interagir com um banco de dados de alguma maneira - pode ser um banco de dados relacional como o PostgreSQL, um banco de dados de documentos como o MongoDB ou talvez até um banco de dados gráfico, como o Neo4j.
Já que, como desenvolvedores, devemos buscar designs de baixo acoplamento e altamente coesos, seria um argumento justo considerar quais podem ser as ramificações da migração de sistemas de banco de dados. Também seria justo considerar que diferentes necessidades de acesso a dados podem preferir diferentes abordagens de acesso a dados (isso começa a entrar um pouco no CQRS, que é um padrão para separar leituras e gravações. Veja a postagem de Martin Fowler e a listagem do MSDN se desejar Os livros "Implementing Domain Driven Design" de Vaughn Vernon e "Patterns, Principles, and Practices of Domain-Driven Design" de Scott Millet também são boas leituras). Também devemos considerar testes automatizados. A maioria dos tutoriais que explicam a construção de sistemas back-end com Node.js misturam código de acesso a dados com lógica de negócios e roteamento. Ou seja, eles tendem a usar o MongoDB com o Mongoose ODM, adotando uma abordagem Active Record e não tendo uma separação clara de interesses. Tais técnicas são desaprovadas em grandes aplicações; no momento em que você decide que deseja migrar um sistema de banco de dados para outro, ou no momento em que percebe que prefere uma abordagem diferente para o acesso a dados, é necessário remover o antigo código de acesso a dados, substituí-lo por um novo código, e espero que você não tenha introduzido nenhum bug no roteamento e na lógica de negócios ao longo do caminho.
Claro, você pode argumentar que os testes de unidade e integração evitarão regressões, mas se esses testes se encontrarem acoplados e dependentes de detalhes de implementação aos quais devem ser agnósticos, eles também provavelmente quebrarão no processo.
Uma abordagem comum para resolver esse problema é o Repository Pattern. Ele diz que, para chamar o código, devemos permitir que nossa camada de acesso a dados imite uma mera coleção de objetos ou entidades de domínio na memória. Dessa forma, podemos deixar o negócio conduzir o design ao invés do banco de dados (modelo de dados). Para grandes aplicativos, um padrão de arquitetura chamado Domain-Driven Design torna-se útil. Repositórios, no Repository Pattern, são componentes, mais comumente classes, que encapsulam e mantêm interna toda a lógica para acessar fontes de dados. Com isso, podemos centralizar o código de acesso aos dados em uma camada, tornando-o facilmente testável e facilmente reutilizável. Além disso, podemos colocar uma camada de mapeamento no meio, permitindo mapear modelos de domínio agnósticos de banco de dados para uma série de mapeamentos de tabela um para um. Cada função disponível no Repositório pode, opcionalmente, usar um método de acesso a dados diferente, se assim o desejar.
Existem muitas abordagens e semânticas diferentes para Repositórios, Unidades de Trabalho, transações de banco de dados entre tabelas e assim por diante. Como este é um artigo sobre Genéricos, não quero me aprofundar muito, então vou ilustrar um exemplo simples aqui, mas é importante notar que diferentes aplicativos têm necessidades diferentes. Um Repositório para Agregados DDD seria bem diferente do que estamos fazendo aqui, por exemplo. Como eu retrato as implementações do Repositório aqui não é como eu as implemento em projetos reais, pois há muitas funcionalidades ausentes e práticas arquitetônicas menos do que desejadas em uso.
Vamos supor que temos Users e Tasks como modelos de domínio. Estes poderiam ser apenas POTOs — objetos TypeScript simples. Não há noção de um banco de dados embutido neles, portanto, você não chamaria User.save() , por exemplo, como faria usando o Mongoose. Usando o Repository Pattern, podemos persistir um usuário ou excluir uma tarefa de nossa lógica de negócios da seguinte maneira:
// Querying the DB for a User by their ID. const user: User = await userRepository.findById(userID); // Deleting a Task by its ID. await taskRepository.deleteById(taskID); // Deleting a Task by its owner's ID. await taskRepository.deleteByUserId(userID);Claramente, você pode ver como toda a lógica de acesso a dados confuso e transitório está escondida por trás dessa fachada/abstração de repositório, tornando a lógica de negócios agnóstica para preocupações de persistência.
Vamos começar construindo alguns modelos de domínio simples. Esses são os modelos com os quais o código do aplicativo irá interagir. Eles são anêmicos aqui, mas manteriam sua própria lógica para satisfazer invariantes de negócios no mundo real, ou seja, não seriam meros sacos de dados.
interface IHasIdentity { id: string; } class User implements IHasIdentity { public constructor ( private readonly _id: string, private readonly _username: string ) {} public get id() { return this._id; } public get username() { return this._username; } } class Task implements IHasIdentity { public constructor ( private readonly _id: string, private readonly _title: string ) {} public get id() { return this._id; } public get title() { return this._title; } } Você verá em um momento por que extraímos informações de digitação de identidade para uma interface. Esse método de definir modelos de domínio e passar tudo pelo construtor não é como eu faria no mundo real. Além disso, confiar em uma classe de modelo de domínio abstrato teria sido mais preferível do que a interface para obter a implementação do id gratuitamente.
Para o Repositório, já que, neste caso, esperamos que muitos dos mesmos mecanismos de persistência sejam compartilhados em diferentes modelos de domínio, podemos abstrair nossos métodos do Repositório para uma interface genérica:
interface IRepository<T> { add(entity: T): Promise<void>; findById(id: string): Promise<T>; updateById(id: string, updated: T): Promise<void>; deleteById(id: string): Promise<void>; existsById(id: string): Promise<boolean>; }Poderíamos ir além e criar um Repositório Genérico também para reduzir a duplicação. Por brevidade, não farei isso aqui, e devo observar que interfaces de repositórios genéricos como esta e repositórios genéricos, em geral, tendem a ser desaprovadas, pois você pode ter certas entidades que são somente leitura ou escrevem -only, ou que não pode ser excluído, ou similar. Depende da aplicação. Além disso, não temos a noção de uma “unidade de trabalho” para compartilhar uma transação entre tabelas, um recurso que eu implementaria no mundo real, mas, novamente, como esta é uma pequena demonstração, não quer ficar muito técnico.
Vamos começar implementando nosso UserRepository . Vou definir uma interface IUserRepository que contém métodos específicos para usuários, permitindo assim que o código de chamada dependa dessa abstração quando injetamos dependência nas implementações concretas:
interface IUserRepository extends IRepository<User> { existsByUsername(username: string): Promise<boolean>; } class UserRepository implements IUserRepository { // There are 6 methods to implement here all using the // concrete type of `User` - Five from IRepository<User> // and the one above. }O Repositório de Tarefas seria semelhante, mas conteria métodos diferentes conforme o aplicativo achar adequado.
Aqui, estamos definindo uma interface que estende uma genérica, portanto, temos que passar o tipo concreto em que estamos trabalhando. Como você pode ver em ambas as interfaces, temos a noção de que enviamos esses modelos de domínio POTO e os tiramos. O código de chamada não tem ideia de qual é o mecanismo de persistência subjacente, e esse é o ponto.
A próxima consideração a ser feita é que, dependendo do método de acesso a dados que escolhermos, teremos que lidar com erros específicos do banco de dados. Poderíamos colocar o Mongoose ou o Knex Query Builder por trás deste Repositório, por exemplo, e nesse caso, teremos que lidar com esses erros específicos - não queremos que eles borbulhem para a lógica de negócios, pois isso quebraria a separação de preocupações e introduzir um maior grau de acoplamento.
Vamos definir um Repositório Base para os métodos de acesso a dados que desejamos usar que podem lidar com erros para nós:
class BaseKnexRepository { // A constructor. /** * Wraps a likely to fail database operation within a function that handles errors by catching * them and wrapping them in a domain-safe error. * * @param dalOp The operation to perform upon the database. */ public async withErrorHandling<T>(dalOp: () => Promise<T>) { try { return await dalOp(); } catch (e) { // Use a proper logger: console.error(e); // Handle errors properly here. } } }Agora, podemos estender essa Classe Base no Repositório e acessar esse método Genérico:
interface IUserRepository extends IRepository<User> { existsByUsername(username: string): Promise<boolean>; } class UserRepository extends BaseKnexRepository implements IUserRepository { private readonly dbContext: Knex | Knex.Transaction; public constructor (private knexInstance: Knex | Knex.Transaction) { super(); this.dbContext = knexInstance; } // Example `findById` implementation: public async findById(id: string): Promise<User> { return this.withErrorHandling<User>(async () => { const dbUser = await this.dbContext<DbUser>() .select() .where({ user_id: id }) .first(); // Maps type DbUser to User return mapper.toDomain(dbUser); }); } // There are 5 methods to implement here all using the // concrete type of `User`. } Observe que nossa função recupera um DbUser do banco de dados e o mapeia para um modelo de domínio de User antes de retorná-lo. Este é o padrão do Mapeador de Dados e é crucial para manter a separação de interesses. DbUser é um mapeamento um-para-um para a tabela do banco de dados — é o modelo de dados sobre o qual o Repositório opera — e, portanto, é altamente dependente da tecnologia de armazenamento de dados usada. Por esse motivo, DbUser s nunca sairão do Repositório e serão mapeados para um modelo de domínio de User antes de serem retornados. Não mostrei a implementação do DbUser , mas poderia ser apenas uma simples classe ou interface.
Até agora, usando o Repository Pattern, desenvolvido pela Generics, conseguimos abstrair as preocupações de acesso a dados em pequenas unidades, bem como manter a segurança do tipo e a reutilização.
Por fim, para fins de teste de unidade e integração, digamos que manteremos uma implementação de repositório na memória para que, em um ambiente de teste, possamos injetar esse repositório e executar asserções baseadas em estado no disco, em vez de zombar de um quadro de zombaria. Esse método força tudo a depender das interfaces voltadas para o público, em vez de permitir que os testes sejam acoplados aos detalhes da implementação. Como as únicas diferenças entre cada repositório são os métodos que eles escolhem para adicionar na interface ISomethingRepository , podemos construir um repositório genérico na memória e estendê-lo em implementações específicas de tipo:
class InMemoryRepository<T extends IHasIdentity> implements IRepository<T> { protected entities: T[] = []; public findById(id: string): Promise<T> { const entityOrNone = this.entities.find(entity => entity.id === id); return entityOrNone ? Promise.resolve(entityOrNone) : Promise.reject(new NotFound()); } // Implement the rest of the IRepository<T> methods here. } O objetivo dessa classe base é executar toda a lógica para manipular o armazenamento na memória para que não tenhamos que duplicá-lo nos repositórios de teste na memória. Devido a métodos como findById , esse repositório precisa ter um entendimento de que as entidades contêm um campo id , por isso é necessária a restrição genérica na interface IHasIdentity . Já vimos essa interface antes — é o que nossos modelos de domínio implementaram.
Com isso, quando se trata de construir o usuário na memória ou repositório de tarefas, podemos apenas estender essa classe e obter a maioria dos métodos implementados automaticamente:
class InMemoryUserRepository extends InMemoryRepository<User> { public async existsByUsername(username: string): Promise<boolean> { const userOrNone = this.entities.find(entity => entity.username === username); return Boolean(userOrNone); // or, return !!userOrNone; } // And that's it here. InMemoryRepository implements the rest. } Aqui, nosso InMemoryRepository precisa saber que as entidades possuem campos como id e username , assim passamos User como o parâmetro genérico. User já implementa IHasIdentity , então a restrição genérica é satisfeita, e também afirmamos que temos uma propriedade username também.
Agora, quando quisermos usar esses repositórios da Business Logic Layer, é bem simples:
class UserService { public constructor ( private readonly userRepository: IUserRepository, private readonly emailService: IEmailService ) {} public async createUser(dto: ICreateUserDTO) { // Validate the DTO: // ... // Create a User Domain Model from the DTO const user = userFactory(dto); // Persist the Entity await this.userRepository.add(user); // Send a welcome email await this.emailService.sendWelcomeEmail(user); } } (Observe que em um aplicativo real, provavelmente moveríamos a chamada para emailService para uma fila de trabalho para não adicionar latência à solicitação e na esperança de poder realizar novas tentativas idempotentes em falhas (— não que o envio de e-mail seja particularmente idempotente em primeiro lugar). Além disso, passar todo o objeto de usuário para o serviço também é questionável. O outro problema a ser observado é que podemos nos encontrar em uma posição aqui em que o servidor trava depois que o usuário persiste, mas antes que o email seja Existem padrões de mitigação para evitar isso, mas para fins de pragmatismo, a intervenção humana com o registro adequado provavelmente funcionará bem).
E lá vamos nós — usando o Repository Pattern com o poder do Generics, nós dissociamos completamente nossa DAL de nossa BLL e conseguimos fazer a interface com nosso repositório de forma segura. Também desenvolvemos uma maneira de construir rapidamente repositórios em memória igualmente seguros para fins de teste de unidade e integração, permitindo testes de caixa preta e agnósticos de implementação. Nada disso teria sido possível sem os tipos genéricos.
Como aviso, quero mais uma vez observar que esta implementação do Repositório está faltando muito. Eu queria manter o exemplo simples, pois o foco é a utilização de genéricos, razão pela qual não lidei com a duplicação ou me preocupei com transações. Implementações de repositório decentes exigiriam um artigo por si só para explicar completa e corretamente, e os detalhes da implementação mudam dependendo se você está fazendo N-Tier Architecture ou DDD. Isso significa que, se você deseja usar o Repository Pattern, não deve ver minha implementação aqui como uma prática recomendada.
Exemplos do mundo real - React State & Props
O state, ref e o resto dos hooks para React Functional Components também são genéricos. Se eu tiver uma interface contendo propriedades para Task s e quiser manter uma coleção delas em um React Component, eu poderia fazer da seguinte forma:
import React, { useState } from 'react'; export const MyComponent: React.FC = () => { // An empty array of tasks as the initial state: const [tasks, setTasks] = useState<Task[]>([]); // A counter: // Notice, type of `number` is inferred automatically. const [counter, setCounter] = useState(0); return ( <div> <h3>Counter Value: {counter}</h3> <ul> { tasks.map(task => ( <li key={task.id}> <TaskItem {...task} /> </li> )) } </ul> </div> ); }; Além disso, se quisermos passar uma série de props para nossa função, podemos usar o tipo genérico React.FC<T> e obter acesso a props :
import React from 'react'; interface IProps { id: string; title: string; description: string; } export const TaskItem: React.FC<IProps> = (props) => { return ( <div> <h3>{props.title}</h3> <p>{props.description}</p> </div> ); }; O tipo de props é inferido automaticamente como IProps pelo TS Compiler.
Conclusão
Neste artigo, vimos muitos exemplos diferentes de Genéricos e seus casos de uso, desde coleções simples até abordagens de tratamento de erros, isolamento da camada de acesso a dados e assim por diante. Nos termos mais simples, os Genéricos nos permitem construir estruturas de dados sem precisar saber o tempo concreto em que eles irão operar em tempo de compilação. Espero que isso ajude a abrir um pouco mais o assunto, tornar a noção de Genéricos um pouco mais intuitiva e trazer à tona seu verdadeiro poder.