
O melhor guia para construir Web Scrapers escaláveis com Scrapy
Publicados: 2022-03-10A raspagem da Web é uma maneira de obter dados de sites sem precisar de acesso a APIs ou ao banco de dados do site. Você só precisa acessar os dados do site — desde que seu navegador possa acessar os dados, você poderá raspá-los.
Realisticamente, na maioria das vezes você poderia simplesmente acessar um site manualmente e pegar os dados 'à mão' usando copiar e colar, mas em muitos casos isso levaria muitas horas de trabalho manual, o que poderia custar-lhe um muito mais do que os dados valem, especialmente se você contratou alguém para fazer a tarefa para você. Por que contratar alguém para trabalhar de 1 a 2 minutos por consulta quando você pode fazer com que um programa execute uma consulta automaticamente a cada poucos segundos?
Por exemplo, digamos que você deseja compilar uma lista dos vencedores do Oscar de melhor filme, juntamente com seu diretor, atores principais, data de lançamento e tempo de execução. Usando o Google, você pode ver que existem vários sites que listarão esses filmes por nome e talvez algumas informações adicionais, mas geralmente você terá que seguir com links para capturar todas as informações que deseja.
Obviamente, seria impraticável e demorado percorrer todos os links de 1927 até hoje e tentar manualmente encontrar as informações em cada página. Com a raspagem da web, precisamos apenas encontrar um site com páginas que tenham todas essas informações e, em seguida, apontar nosso programa na direção certa com as instruções corretas.
Neste tutorial, usaremos a Wikipedia como nosso site, pois contém todas as informações de que precisamos e, em seguida, usaremos o Scrapy on Python como uma ferramenta para extrair nossas informações.
Algumas ressalvas antes de começarmos:
A raspagem de dados envolve o aumento da carga do servidor para o site que você está raspando, o que significa um custo mais alto para as empresas que hospedam o site e uma experiência de qualidade inferior para outros usuários desse site. A qualidade do servidor que está executando o site, a quantidade de dados que você está tentando obter e a taxa na qual você está enviando solicitações ao servidor irão moderar o efeito que você tem no servidor. Tendo isso em mente, precisamos ter certeza de que seguimos algumas regras.
A maioria dos sites também tem um arquivo chamado robots.txt em seu diretório principal. Este arquivo estabelece regras para quais diretórios os sites não querem que os raspadores acessem. A página de Termos e Condições de um site geralmente informa qual é a política de extração de dados. Por exemplo, a página de condições do IMDB tem a seguinte cláusula:
Robôs e Screen Scraping: Você não pode usar mineração de dados, robôs, screen scraping ou ferramentas semelhantes de coleta e extração de dados neste site, exceto com nosso consentimento expresso por escrito, conforme indicado abaixo.
Antes de tentarmos obter os dados de um site, devemos sempre verificar os termos do site e o robots.txt para nos certificarmos de que estamos obtendo dados legais. Ao construir nossos scrapers, também precisamos ter certeza de que não sobrecarregamos um servidor com solicitações que ele não pode lidar.
Felizmente, muitos sites reconhecem a necessidade de os usuários obterem dados e disponibilizam os dados por meio de APIs. Se estiverem disponíveis, geralmente é uma experiência muito mais fácil obter dados por meio da API do que por meio de raspagem.
A Wikipedia permite a raspagem de dados, desde que os bots não estejam 'muito rápido', conforme especificado em seu robots.txt . Eles também fornecem conjuntos de dados para download para que as pessoas possam processar os dados em suas próprias máquinas. Se formos rápidos demais, os servidores bloquearão automaticamente nosso IP, então implementaremos temporizadores para manter suas regras.
Começando, Instalando Bibliotecas Relevantes Usando Pip
Primeiro de tudo, para começar, vamos instalar o Scrapy.
janelas
Instale a versão mais recente do Python em https://www.python.org/downloads/windows/
Nota: Os usuários do Windows também precisarão do Microsoft Visual C++ 14.0, que você pode obter em “Microsoft Visual C++ Build Tools” aqui.
Você também deve certificar-se de ter a versão mais recente do pip.
Em cmd.exe digite:
python -m pip install --upgrade pip pip install pypiwin32 pip install scrapyIsso instalará o Scrapy e todas as dependências automaticamente.
Linux
Primeiro você vai querer instalar todas as dependências:
No Terminal, digite:
sudo apt-get install python3 python3-dev python-pip libxml2-dev libxslt1-dev zlib1g-dev libffi-dev libssl-devDepois de tudo instalado, basta digitar:
pip install --upgrade pipPara garantir que o pip seja atualizado e, em seguida:
pip install scrapyE está tudo feito.
Mac
Primeiro você precisa ter certeza de ter um compilador c em seu sistema. No Terminal, digite:
xcode-select --installDepois disso, instale o homebrew em https://brew.sh/.
Atualize sua variável PATH para que os pacotes homebrew sejam usados antes dos pacotes do sistema:
echo "export PATH=/usr/local/bin:/usr/local/sbin:$PATH" >> ~/.bashrc source ~/.bashrcInstale o Python:
brew install pythonE, em seguida, verifique se tudo está atualizado:
brew update; brew upgrade pythonFeito isso, basta instalar o Scrapy usando pip:
pip install Scrapy > ## Visão geral do Scrapy, como as peças se encaixam, analisadores, aranhas, etc.Você estará escrevendo um script chamado 'Spider' para o Scrapy rodar, mas não se preocupe, as aranhas Scrapy não são nada assustadoras apesar do nome. A única semelhança que as aranhas Scrapy e as aranhas reais têm é que elas gostam de rastejar na web.
Dentro da aranha há uma class que você define que diz ao Scrapy o que fazer. Por exemplo, onde começar o rastreamento, os tipos de solicitações que ele faz, como seguir links nas páginas e como ele analisa os dados. Você também pode adicionar funções personalizadas para processar dados, antes de enviar de volta para um arquivo.
Para iniciar nosso primeiro spider, precisamos primeiro criar um projeto Scrapy. Para fazer isso, digite isso em sua linha de comando:
scrapy startproject oscarsIsso criará uma pasta com seu projeto.
Vamos começar com uma aranha básica. O código a seguir deve ser inserido em um script python. Abra um novo script python em /oscars/spiders e nomeie-o como oscars_spider.py
Importaremos o Scrapy.
import scrapyEm seguida, começamos a definir nossa classe Spider. Primeiro, definimos o nome e, em seguida, os domínios que o spider pode raspar. Finalmente, dizemos à aranha por onde começar a raspar.
class OscarsSpider(scrapy.Spider): name = "oscars" allowed_domains = ["en.wikipedia.org"] start_urls = ['https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture']Em seguida, precisamos de uma função que irá capturar as informações que queremos. Por enquanto, vamos apenas pegar o título da página. Usamos CSS para encontrar a tag que carrega o texto do título e, em seguida, extraímos. Por fim, retornamos as informações ao Scrapy para serem registradas ou gravadas em um arquivo.
def parse(self, response): data = {} data['title'] = response.css('title::text').extract() yield data Agora salve o código em /oscars/spiders/oscars_spider.py
Para executar este spider, basta acessar sua linha de comando e digitar:
scrapy crawl oscarsVocê deve ver uma saída como esta:
2019-05-02 14:39:31 [scrapy.utils.log] INFO: Scrapy 1.6.0 started (bot: oscars) ... 2019-05-02 14:39:32 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None) 2019-05-02 14:39:34 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None) 2019-05-02 14:39:34 [scrapy.core.scraper] DEBUG: Scraped from <200 https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture> {'title': ['Academy Award for Best Picture - Wikipedia']} 2019-05-02 14:39:34 [scrapy.core.engine] INFO: Closing spider (finished) 2019-05-02 14:39:34 [scrapy.statscollectors] INFO: Dumping Scrapy stats: {'downloader/request_bytes': 589, 'downloader/request_count': 2, 'downloader/request_method_count/GET': 2, 'downloader/response_bytes': 74517, 'downloader/response_count': 2, 'downloader/response_status_count/200': 2, 'finish_reason': 'finished', 'finish_time': datetime.datetime(2019, 5, 2, 7, 39, 34, 264319), 'item_scraped_count': 1, 'log_count/DEBUG': 3, 'log_count/INFO': 9, 'response_received_count': 2, 'robotstxt/request_count': 1, 'robotstxt/response_count': 1, 'robotstxt/response_status_count/200': 1, 'scheduler/dequeued': 1, 'scheduler/dequeued/memory': 1, 'scheduler/enqueued': 1, 'scheduler/enqueued/memory': 1, 'start_time': datetime.datetime(2019, 5, 2, 7, 39, 31, 431535)} 2019-05-02 14:39:34 [scrapy.core.engine] INFO: Spider closed (finished)2019-05-02 14:39:31 [scrapy.utils.log] INFO: Scrapy 1.6.0 started (bot: oscars) ... 2019-05-02 14:39:32 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None) 2019-05-02 14:39:34 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None) 2019-05-02 14:39:34 [scrapy.core.scraper] DEBUG: Scraped from <200 https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture> {'title': ['Academy Award for Best Picture - Wikipedia']} 2019-05-02 14:39:34 [scrapy.core.engine] INFO: Closing spider (finished) 2019-05-02 14:39:34 [scrapy.statscollectors] INFO: Dumping Scrapy stats: {'downloader/request_bytes': 589, 'downloader/request_count': 2, 'downloader/request_method_count/GET': 2, 'downloader/response_bytes': 74517, 'downloader/response_count': 2, 'downloader/response_status_count/200': 2, 'finish_reason': 'finished', 'finish_time': datetime.datetime(2019, 5, 2, 7, 39, 34, 264319), 'item_scraped_count': 1, 'log_count/DEBUG': 3, 'log_count/INFO': 9, 'response_received_count': 2, 'robotstxt/request_count': 1, 'robotstxt/response_count': 1, 'robotstxt/response_status_count/200': 1, 'scheduler/dequeued': 1, 'scheduler/dequeued/memory': 1, 'scheduler/enqueued': 1, 'scheduler/enqueued/memory': 1, 'start_time': datetime.datetime(2019, 5, 2, 7, 39, 31, 431535)} 2019-05-02 14:39:34 [scrapy.core.engine] INFO: Spider closed (finished)2019-05-02 14:39:31 [scrapy.utils.log] INFO: Scrapy 1.6.0 started (bot: oscars) ... 2019-05-02 14:39:32 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None) 2019-05-02 14:39:34 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None) 2019-05-02 14:39:34 [scrapy.core.scraper] DEBUG: Scraped from <200 https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture> {'title': ['Academy Award for Best Picture - Wikipedia']} 2019-05-02 14:39:34 [scrapy.core.engine] INFO: Closing spider (finished) 2019-05-02 14:39:34 [scrapy.statscollectors] INFO: Dumping Scrapy stats: {'downloader/request_bytes': 589, 'downloader/request_count': 2, 'downloader/request_method_count/GET': 2, 'downloader/response_bytes': 74517, 'downloader/response_count': 2, 'downloader/response_status_count/200': 2, 'finish_reason': 'finished', 'finish_time': datetime.datetime(2019, 5, 2, 7, 39, 34, 264319), 'item_scraped_count': 1, 'log_count/DEBUG': 3, 'log_count/INFO': 9, 'response_received_count': 2, 'robotstxt/request_count': 1, 'robotstxt/response_count': 1, 'robotstxt/response_status_count/200': 1, 'scheduler/dequeued': 1, 'scheduler/dequeued/memory': 1, 'scheduler/enqueued': 1, 'scheduler/enqueued/memory': 1, 'start_time': datetime.datetime(2019, 5, 2, 7, 39, 31, 431535)} 2019-05-02 14:39:34 [scrapy.core.engine] INFO: Spider closed (finished)
Parabéns, você construiu seu primeiro raspador Scrapy básico!

Código completo:
import scrapy class OscarsSpider(scrapy.Spider): name = "oscars" allowed_domains = ["en.wikipedia.org"] start_urls = ["https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture"] def parse(self, response): data = {} data['title'] = response.css('title::text').extract() yield dataObviamente, queremos que ele faça um pouco mais, então vamos ver como usar o Scrapy para analisar dados.
Primeiro, vamos nos familiarizar com o shell Scrapy. O shell do Scrapy pode ajudá-lo a testar seu código para garantir que o Scrapy esteja capturando os dados desejados.
Para acessar o shell, digite isso em sua linha de comando:
scrapy shell “https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture”Isso basicamente abrirá a página para a qual você o direcionou e permitirá que você execute linhas únicas de código. Por exemplo, você pode visualizar o HTML bruto da página digitando:
print(response.text)Ou abra a página em seu navegador padrão digitando:
view(response)Nosso objetivo aqui é encontrar o código que contém as informações que queremos. Por enquanto, vamos tentar pegar apenas os nomes dos títulos dos filmes.
A maneira mais fácil de encontrar o código que precisamos é abrindo a página em nosso navegador e inspecionando o código. Neste exemplo, estou usando o Chrome DevTools. Basta clicar com o botão direito do mouse em qualquer título de filme e selecionar 'inspecionar':
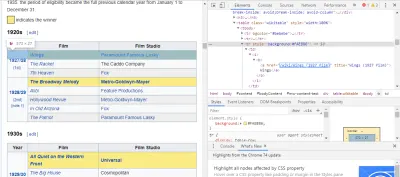
Como você pode ver, os vencedores do Oscar têm um fundo amarelo, enquanto os indicados têm um fundo liso. Há também um link para o artigo sobre o título do filme, e os links para filmes terminam em film) . Agora que sabemos disso, podemos usar um seletor CSS para pegar os dados. No shell do Scrapy, digite:
response.css(r"tr[] a[href*='film)']").extract()Como você pode ver, agora você tem uma lista de todos os vencedores do Oscar de Melhor Filme!
> response.css(r"tr[] a[href*='film']").extract() ['<a href="/wiki/Wings_(1927_film)" title="Wings (1927 film)">Wings</a>', ... '<a href="/wiki/Green_Book_(film)" title="Green Book (film)">Green Book</a>', '<a href="/wiki/Jim_Burke_(film_producer)" title="Jim Burke (film producer)">Jim Burke</a>']Voltando ao nosso objetivo principal, queremos uma lista dos vencedores do Oscar de melhor filme, junto com seu diretor, atores principais, data de lançamento e tempo de execução. Para fazer isso, precisamos do Scrapy para obter dados de cada uma dessas páginas de filmes.
Teremos que reescrever algumas coisas e adicionar uma nova função, mas não se preocupe, é bem simples.
Começaremos iniciando o raspador da mesma maneira que antes.
import scrapy, time class OscarsSpider(scrapy.Spider): name = "oscars" allowed_domains = ["en.wikipedia.org"] start_urls = ["https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture"] Mas desta vez, duas coisas vão mudar. Primeiro, importaremos time junto com scrapy porque queremos criar um cronômetro para restringir a rapidez com que o bot raspa. Além disso, quando analisamos as páginas pela primeira vez, queremos obter apenas uma lista dos links para cada título, para que possamos obter informações dessas páginas.
def parse(self, response): for href in response.css(r"tr[] a[href*='film)']::attr(href)").extract(): url = response.urljoin(href) print(url) req = scrapy.Request(url, callback=self.parse_titles) time.sleep(5) yield req Aqui fazemos um loop para procurar cada link na página que termina em film) com o fundo amarelo nele e então juntamos esses links em uma lista de URLs, que enviaremos para a função parse_titles para passar adiante. Também colocamos um cronômetro para solicitar apenas páginas a cada 5 segundos. Lembre-se, podemos usar o shell Scrapy para testar nossos campos response.css para garantir que estamos obtendo os dados corretos!
def parse_titles(self, response): for sel in response.css('html').extract(): data = {} data['title'] = response.css(r"h1[id='firstHeading'] i::text").extract() data['director'] = response.css(r"tr:contains('Directed by') a[href*='/wiki/']::text").extract() data['starring'] = response.css(r"tr:contains('Starring') a[href*='/wiki/']::text").extract() data['releasedate'] = response.css(r"tr:contains('Release date') li::text").extract() data['runtime'] = response.css(r"tr:contains('Running time') td::text").extract() yield data O trabalho real é feito em nossa função parse_data , onde criamos um dicionário chamado data e então preenchemos cada chave com as informações que queremos. Novamente, todos esses seletores foram encontrados usando o Chrome DevTools, conforme demonstrado antes, e depois testados com o shell Scrapy.
A linha final retorna o dicionário de dados de volta ao Scrapy para armazenar.
Código completo:
import scrapy, time class OscarsSpider(scrapy.Spider): name = "oscars" allowed_domains = ["en.wikipedia.org"] start_urls = ["https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture"] def parse(self, response): for href in response.css(r"tr[] a[href*='film)']::attr(href)").extract(): url = response.urljoin(href) print(url) req = scrapy.Request(url, callback=self.parse_titles) time.sleep(5) yield req def parse_titles(self, response): for sel in response.css('html').extract(): data = {} data['title'] = response.css(r"h1[id='firstHeading'] i::text").extract() data['director'] = response.css(r"tr:contains('Directed by') a[href*='/wiki/']::text").extract() data['starring'] = response.css(r"tr:contains('Starring') a[href*='/wiki/']::text").extract() data['releasedate'] = response.css(r"tr:contains('Release date') li::text").extract() data['runtime'] = response.css(r"tr:contains('Running time') td::text").extract() yield dataÀs vezes, queremos usar proxies, pois os sites tentarão bloquear nossas tentativas de raspagem.
Para fazer isso, só precisamos mudar algumas coisas. Usando nosso exemplo, em nosso def parse() , precisamos alterá-lo para o seguinte:
def parse(self, response): for href in (r"tr[] a[href*='film)']::attr(href)").extract() : url = response.urljoin(href) print(url) req = scrapy.Request(url, callback=self.parse_titles) req.meta['proxy'] = "https://yourproxy.com:80" yield reqIsso encaminhará as solicitações por meio do servidor proxy.
Implantação e registro, mostre como realmente gerenciar uma aranha em produção
Agora é hora de executar nossa aranha. Para fazer com que o Scrapy comece a extrair e, em seguida, produza um arquivo CSV, digite o seguinte em seu prompt de comando:
scrapy crawl oscars -o oscars.csvVocê verá uma saída grande e, após alguns minutos, ela será concluída e você terá um arquivo CSV na pasta do projeto.
Compilando resultados, mostre como usar os resultados compilados nas etapas anteriores
Ao abrir o arquivo CSV, você verá todas as informações que queríamos (classificadas por colunas com títulos). É realmente tão simples.
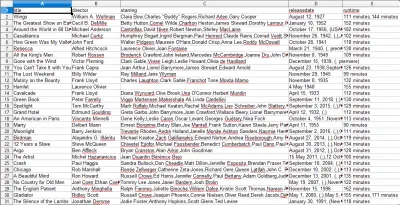
Com a raspagem de dados, podemos obter praticamente qualquer conjunto de dados personalizado que desejarmos, desde que as informações estejam disponíveis publicamente. O que você quer fazer com esses dados é com você. Essa habilidade é extremamente útil para fazer pesquisas de mercado, manter as informações de um site atualizadas e muitas outras coisas.
É bastante fácil configurar seu próprio web scraper para obter conjuntos de dados personalizados por conta própria, no entanto, lembre-se sempre de que pode haver outras maneiras de obter os dados de que você precisa. As empresas investem muito para fornecer os dados que você deseja, por isso é justo que respeitemos seus termos e condições.
Recursos adicionais para aprender mais sobre Scrapy e Web Scraping em geral
- O site oficial do Scrapy
- Página do Scrapy no GitHub
- “As 10 melhores ferramentas de raspagem de dados e ferramentas de raspagem da Web”, API Scraper
- “5 dicas para raspagem da Web sem ser bloqueado ou na lista negra”, API do Scraper
- Parsel, uma biblioteca Python para usar expressões regulares para extrair dados de HTML.