
Árvores na estrutura de dados: 8 tipos de árvores que todo cientista de dados deveria conhecer
Publicados: 2021-05-26Índice
Introdução
No domínio da computação, as estruturas de dados referem-se ao padrão de organização de dados em um disco, que permite armazenamento e exibição convenientes. Eles pertencem ao campo da ciência de dados, que deve ser uma escolha lucrativa de carreira em 2021. Com base nas previsões para os próximos anos, modelos de aprendizado profundo em larga escala e dispositivos inteligentes de última geração pavimentarão o futuro da este setor.
Assim, obter o conhecimento de estruturas de dados seria essencial para encontrar uma carreira adequada em meio ao avanço tecnológico. De acordo com a previsão do Data Science Industry para 2021, os EUA e a Índia empregariam aproximadamente 50.000 cientistas de dados e 300.000 analistas de dados em suas mais de 2.50.000 empresas. [1]
As estruturas de dados são aplicadas para projetar os caminhos para alocação, gerenciamento e recuperação de informações. As estruturas de dados são particularmente necessárias para redigir e melhorar a eficiência de todos os dados processados. Eles gerenciam os dados agrupando-os e organizando-os para facilitar efetivamente a troca de informações.
Árvores em estruturas de dados
'Árvores' são um tipo de ADTs (Abstract Data Types), que seguem um padrão hierárquico para sua alocação de dados. Essencialmente, uma árvore é uma coleção de vários nós conectados por meio de arestas. Essas 'árvores' formam um design de estrutura de dados que se assemelha a uma árvore, onde o nó 'raiz' leva a nós 'pais', que eventualmente levam a nós 'filhos'. As conexões são feitas com linhas conhecidas como 'bordas'.
Os nós 'Leaf' são terminais sem outros nós filhos originados deles. Árvores em estruturas de dados desempenham um papel vital devido à natureza não linear de seu arranjo. Isso permite um tempo de resposta mais rápido durante uma pesquisa, além de conveniência em todas as etapas do projeto.
Tipos de Árvores na Estrutura de Dados
Os vários tipos de árvores em estruturas de dados são explicados detalhadamente abaixo:
1. Árvore Geral
Uma árvore geral é caracterizada pela falta de qualquer especificação ou restrição sobre o número de filhos que um nó pode ter. Qualquer árvore com uma estrutura hierárquica pode ser classificada como uma árvore geral. Um nó pode ter vários filhos e pode haver qualquer tipo de combinação para a orientação da árvore. Os nós podem ser de qualquer grau, de 0 a n.
A seguir está um exemplo clássico de uma árvore geral na estrutura de dados, com '2' no topo sendo o nó raiz.
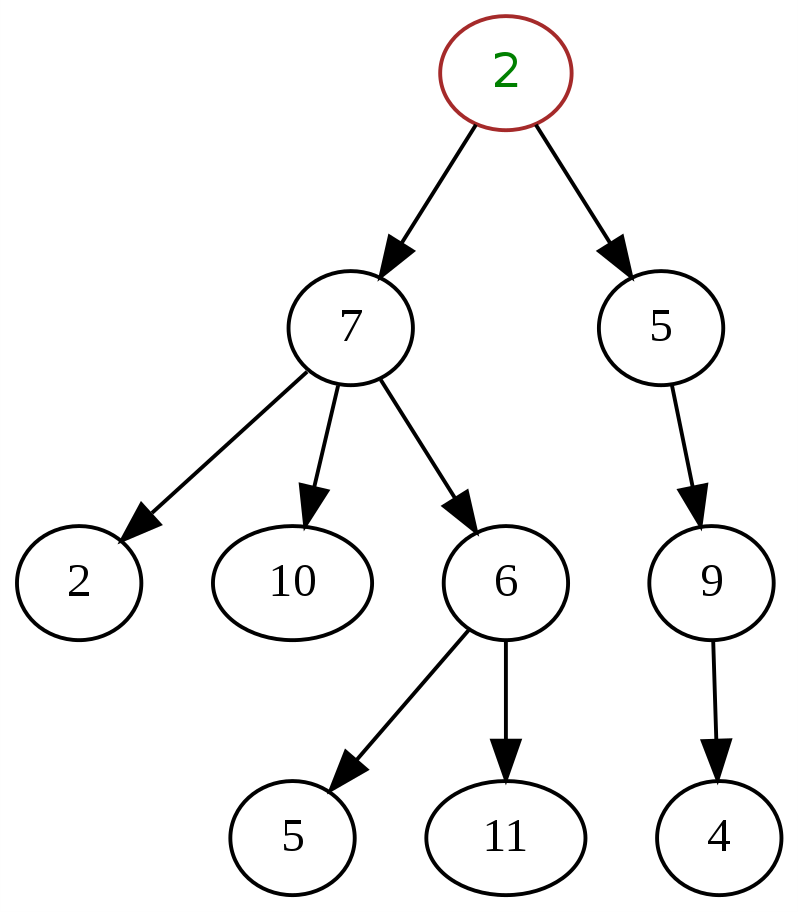
Fonte
2. Árvore Binária
Conforme definido pela palavra 'binário', que significa dois números, uma árvore binária consiste em nós que podem ter 2 nós filhos. Qualquer nó em uma árvore binária pode ter no máximo 0, 1 ou 2 nós. Árvores binárias em estruturas de dados são ADTs altamente funcionais e podem ser subdivididas em vários tipos. Eles são usados principalmente em estruturas de dados para dois propósitos:
- Para acessar nós e rotulá-los, conforme observado em Árvores de pesquisa binária.
- Para a representação de dados através de uma estrutura bifurcada.
O seguinte é um diagrama básico de uma árvore binária em uma estrutura de dados:
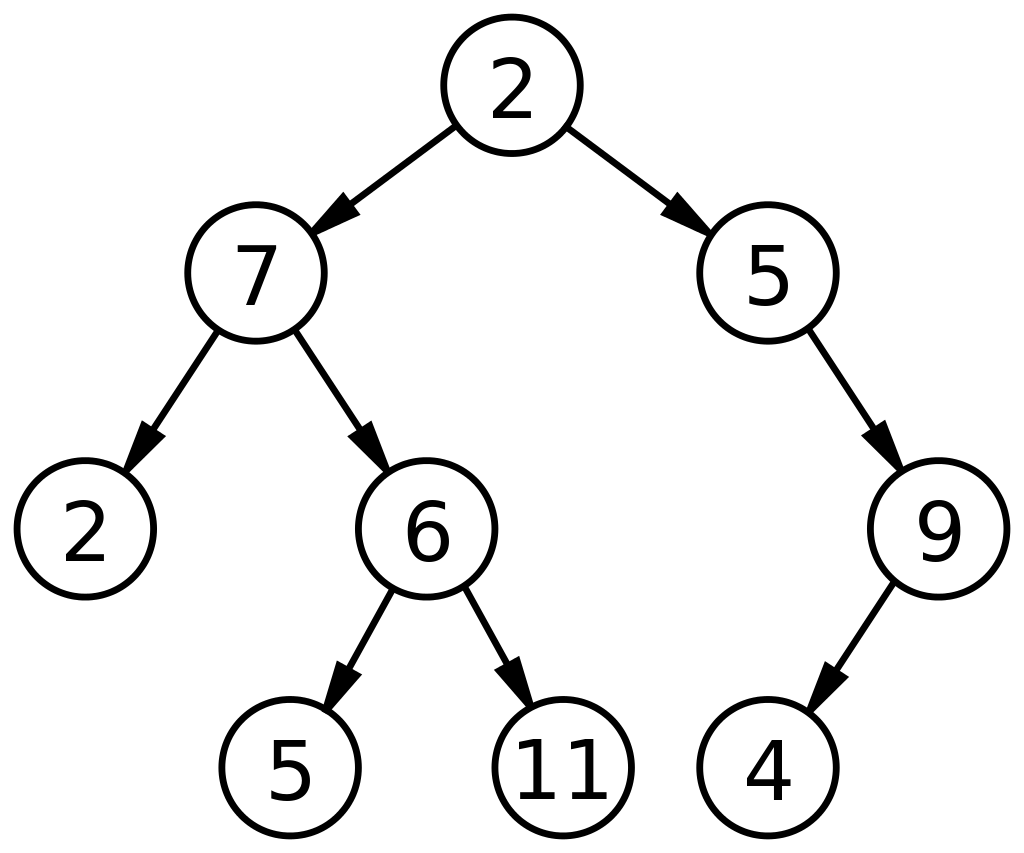
Fonte
3. Árvore de Pesquisa Binária
Uma árvore de pesquisa binária (BST) é um subtipo exclusivo de árvores binárias que são organizadas de forma a facilitar uma pesquisa/pesquisa ou adição/remoção de dados mais rápida. Um BST é definido pela representação dos nós com base em três campos: os dados, seu filho esquerdo e seu filho direito. Os fatores que regem o BST são:
- Cada nó do lado esquerdo (filho esquerdo) deve conter um valor menor que seu nó pai.
- Cada nó do lado direito (filho direito) deve conter um valor maior que seu nó pai.
Tal arranjo reduz os tempos de busca para metade de uma busca linear, conforme encontrado em uma matriz. Assim, árvores de busca binária em estruturas de dados são amplamente aplicáveis para busca e classificação em comparação com outros ADTs.
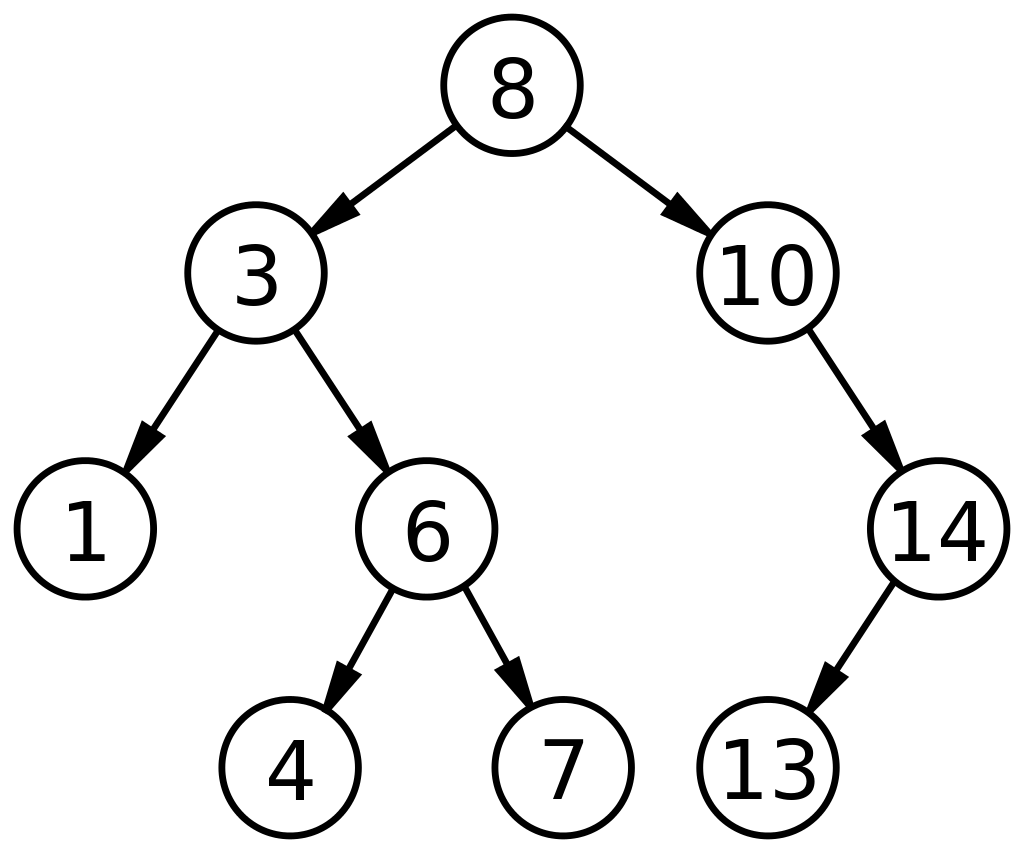
Fonte
Mesmo que BTs e BSTs sejam essencialmente árvores em estruturas de dados , não se confunda com a semelhança em seus nomes. Descubra a diferença entre uma árvore binária e uma árvore de busca binária em detalhes no upGrad.
4. Árvore AVL
A árvore AVL deriva seu nome de seus inventores: Adelson-Velsky e Landis. A árvore AVL é caracterizada por uma natureza auto-equilibrada. As alturas de duas subárvores de seus nós raiz são restritas a menos de dois. Quando a diferença de altura aumenta acima de 1, os nós filhos são rebalanceados.
As árvores AVL são balanceadas em altura, e esse reequilíbrio ocorre por meio de rotações simples ou duplas. O fator de balanceamento é a diferença entre as alturas da subárvore esquerda e da subárvore direita, e os valores são -1, 0 e 1.
5. Árvore preta vermelha
Este tipo se assemelha às árvores AVL, uma vez que as árvores pretas vermelhas também são equilibradas em altura. O que os separa é que não são necessárias mais de duas rotações para equilibrá-los. Eles contêm um bit extra que define a cor vermelha ou preta de um nó, o que garante que as árvores sejam equilibradas durante as exclusões e inserções. O código de cor vermelho preto também é repintado durante as alterações, mas quase sem custo extra de memória.

6. Árvore de Extensão
Outro subtipo da árvore de busca binária, a árvore splay, tem uma propriedade única de realizar operações rotacionais para ajustar o nó recente. O nó acessado recentemente é organizado como o nó raiz executando uma rotação. É uma árvore equilibrada, mas não equilibrada em altura.
O ato de 'splay' é realizado após a busca inicial da árvore binária, pois as rotações da árvore são realizadas de uma maneira específica. Após cada operação, a árvore é girada para se equilibrar e o elemento pesquisado é organizado no topo como um nó raiz.
7. Trep
'Treaps' em estruturas de dados são uma combinação de árvores e heaps. Em BSTs, o valor do filho esquerdo deve ser menor que o nó raiz e o valor do filho direito deve ser maior. Em uma estrutura de dados heap, o nó raiz tem o valor mais baixo e seus nós filho (esquerdo e direito) têm valores maiores.
Assim, uma treap mantém um valor na forma de uma chave (semelhante a BSTs) e uma prioridade (como heaps). Os nós de prioridade mais alta são inseridos primeiro em uma árvore de busca binária de forma que os números de prioridade sejam números aleatórios independentes. Eles mantêm um conjunto dinâmico de chaves ordenadas e permitem pesquisas binárias dentro de suas chaves.
8. Árvore B
Como um tipo de árvore auto-equilibrada em estruturas de dados, o B-Tree classifica os dados para permitir pesquisa, acesso sequencial, exclusões e inserções em tempo logarítmico. Ao contrário de uma árvore binária, uma árvore B permite que seus nós tenham mais de dois filhos. Eles são compatíveis com bancos de dados e sistemas de arquivos que lêem e gravam blocos maiores de dados.
Uma árvore B em estruturas de dados é usada para sistemas de armazenamento maiores, como discos. Todas as folhas não carregam informações e aparecem no mesmo nível. Os nós internos de uma árvore B podem ter um tamanho variável de nós filhos limitados por um intervalo.
Essas são as árvores em estruturas de dados , que são implementadas por programadores que projetam o fluxo de dados. Aprender suas características e aplicativos exclusivos é essencial para sua jornada de se tornar um cientista de dados. Outro método para se aprimorar seria praticar através de vários projetos que exigem o conhecimento de árvores em estruturas de dados e outras formas de ADTs.
Para aplicar seu conhecimento em projetos de DS, os links do blog a seguir têm 13 ideias interessantes de projetos de estrutura de dados e tópicos para iniciantes [2021] .
Conclusão
Aprender sobre conceitos como árvores em uma estrutura de dados pode ser complicado, e os aspirantes a programação precisam de orientação especializada para se educar. Para saber mais sobre árvores em uma estrutura de dados, confira os cursos online do upGrad . Programa PG Executivo em Desenvolvimento de Software – Especialização em DevOps com DevOps pelo IIIT-B & upGrad pode ajudá-lo a construir sua carreira como programador.
Como a proficiência das estruturas de dados é parte integrante do processo de codificação, pode ajudar o aluno a se tornar um programador especialista e desenvolvedor de software. Programadores e cientistas de dados serão requisitados nas próximas décadas .
Temos 500 milhões de usuários de internet na Índia, gerando e consumindo grandes quantidades de dados, o que exige a contratação de milhares de cientistas de dados para atender à demanda. [2] Esses cientistas de dados precisam da educação certa, com conhecimento tecnológico relevante, para buscar emprego nesse setor.
Um Programa Executivo PG em Desenvolvimento de Software – Especialização em Desenvolvimento Full Stack , com curadoria de upGrad & IIIT-Bangalore, pode ajudá-lo a melhorar seu perfil e garantir melhores oportunidades de emprego como programador.
- Uma árvore de pesquisa é uma estrutura de dados usada para localizar certas chaves dentro de um conjunto de dados. A chave de cada nó deve ser maior que qualquer chave nas subárvores à esquerda, mas menor que as chaves nas subárvores à direita para que uma árvore funcione como uma árvore de busca. Dados hierárquicos, como estrutura de pastas, estrutura de organização e dados XML/HTML, devem ser armazenados em árvores. Uma árvore binária perfeita é aquela em que cada nó interior tem dois descendentes e cada folha tem a mesma profundidade ou nível. O gráfico de ascendência (não incestuosa) de uma pessoa em uma determinada profundidade é um exemplo de uma árvore binária perfeita, pois cada pessoa tem precisamente dois pais biológicos (uma mãe e um pai).Que tipo de árvores podem ser usadas para pesquisa?<br />
- Quando a árvore está bastante equilibrada, ou seja, as folhas em cada extremidade têm profundidades equivalentes, as árvores de busca têm uma vantagem em termos de tempo de busca. Há uma variedade de estruturas de dados de árvore de pesquisa, algumas das quais permitem adicionalmente a inserção e exclusão de elementos eficientes, cujas ações devem então preservar o equilíbrio da árvore.
- Um array associativo é frequentemente implementado usando árvores de busca. O algoritmo da árvore de pesquisa localiza um local usando a chave do par chave-valor e, em seguida, o aplicativo armazena o par chave-valor completo nesse local.
- Árvores de pesquisa binárias, árvores B, árvores (a,b) e árvores de pesquisa ternárias são exemplos de árvores de pesquisa. Quais são as principais aplicações da estrutura de dados em árvore?
1. Uma Árvore de Pesquisa Binária é uma árvore que permite pesquisar, inserir e excluir rapidamente dados que foram classificados. Também ajuda a localizar o item mais próximo de você.
2. Heap é uma estrutura de dados em árvore que usa arrays e é usada para construir filas de prioridade.
3. B-Tree e B+ Tree são dois tipos de árvores de indexação usadas em bancos de dados.
4. Os compiladores usam a árvore de sintaxe.
5. Uma árvore de particionamento de espaço usada para organizar pontos no espaço dimensional K é conhecida como Árvore KD.
6. Trie é uma estrutura de dados que é usada para construir dicionários com pesquisa de prefixo.
7. A Árvore de Sufixos é usada para procurar rapidamente padrões em um texto fixo.
8. Em redes de computadores, roteadores e pontes usam árvores geradoras e árvores de caminho mais curto, respectivamente. O que é uma árvore perfeita?