
As 15 principais perguntas e respostas da entrevista do Hadoop em 2022
Publicados: 2021-01-09Com a análise de dados ganhando força, houve um aumento na demanda de pessoas boas em lidar com Big Data. De analistas de dados a cientistas de dados, o Big Data está criando uma variedade de perfis de trabalho hoje. A primeira e mais importante coisa com a qual você deve trabalhar é o Hadoop.
Não importa qual cargo/perfil, você provavelmente trabalhará no Hadoop de uma forma ou de outra. Portanto, você pode invariavelmente esperar que os entrevistadores façam algumas perguntas do Hadoop do seu jeito.
Para isso e muito mais, vejamos as 15 principais perguntas da entrevista do Hadoop que podem ser esperadas em qualquer entrevista para a qual você se candidata.
O que é Hadoop? Quais são os principais componentes do Hadoop?
O Hadoop é uma infraestrutura equipada com ferramentas e serviços relevantes necessários para processar e armazenar Big Data. Para ser preciso, o Hadoop é a 'solução' para todos os desafios do Big Data. Além disso, a estrutura do Hadoop também ajuda as organizações a analisar Big Data e tomar melhores decisões de negócios.
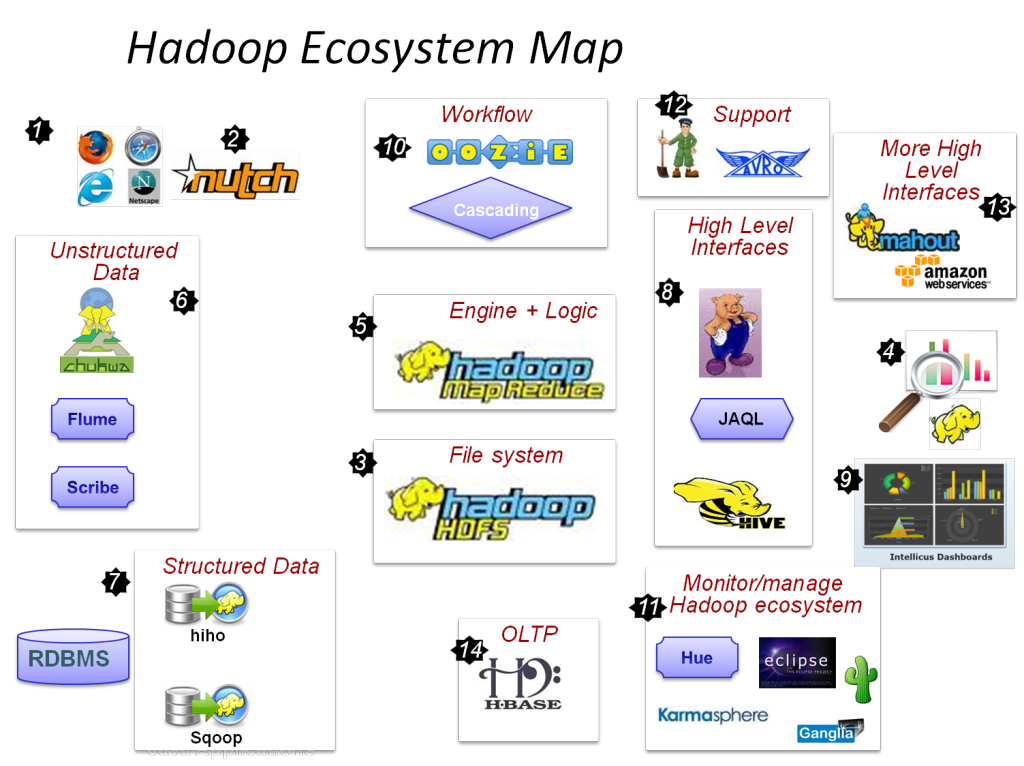
Os principais componentes do Hadoop são:
- HDFS
- Hadoop MapReduce
- Hadoop comum
- FIO
- PIG e HIVE – Os Componentes de Acesso a Dados.
- HBase – Para armazenamento de dados
- Ambari, Oozie e ZooKeeper – Componente de Gerenciamento e Monitoramento de Dados
- Thrift e Avro – componentes de serialização de dados
- Apache Flume, Sqoop, Chukwa – Os componentes de integração de dados
- Apache Mahout e Drill – Componentes de inteligência de dados
Quais são os principais conceitos da estrutura do Hadoop?
O Hadoop é fundamentalmente baseado em dois conceitos principais. Eles estão:
- HDFS: HDFS ou Hadoop Distributed File System é um sistema de arquivos confiável baseado em Java usado para armazenar grandes conjuntos de dados no formato de bloco. A Arquitetura Mestre-Escravo o potencializa.
- MapReduce: MapReduce é uma estrutura de programação que ajuda a processar grandes conjuntos de dados. Essa função é dividida em duas partes – enquanto 'map' segrega os conjuntos de dados em tuplas, 'reduce' usa as tuplas do mapa e cria uma combinação de pedaços menores de tuplas.
Nomeie os formatos de entrada mais comuns no Hadoop?
Existem três formatos de entrada comuns no Hadoop:
- Formato de entrada de texto: Este é o formato de entrada padrão no Hadoop.
- Formato de Entrada de Arquivo de Sequência: Este formato de entrada é usado para ler arquivos em sequência.
- Formato de entrada de valor-chave: Este é usado para ler arquivos de texto simples.
O que é o YARN?
YARN é a abreviação de Yet Another Resource Negotiator. É a estrutura de processamento de dados do Hadoop que gerencia os recursos de dados e cria um ambiente para o processamento bem-sucedido. 
O que é “Consciência de Rack”?
“Rack Awareness” é um algoritmo que NameNode usa para determinar o padrão no qual os blocos de dados e suas réplicas são armazenados no cluster Hadoop. Isso é obtido com a ajuda de definições de rack que reduzem o congestionamento entre os nós de dados contidos no mesmo rack.

O que são NameNodes ativos e passivos?
Um sistema Hadoop de alta disponibilidade geralmente contém dois NameNodes – Active NameNode e Passive NameNode.
O NameNode que executa o cluster Hadoop é chamado de Active NameNode e o NameNode em espera que armazena os dados do Active NameNode é o Passive NameNode.
O objetivo de ter dois NameNodes é que, se o NameNode ativo falhar, o NameNode passivo pode assumir a liderança. Assim, o NameNode está sempre em execução no cluster e o sistema nunca falha.
Quais são os diferentes agendadores na estrutura do Hadoop?
Existem três agendadores diferentes na estrutura do Hadoop:
- COSHH – COSHH ajuda a agendar decisões revisando o cluster e a carga de trabalho combinados com a heterogeneidade.
- FIFO Scheduler – O FIFO alinha os trabalhos em uma fila com base no horário de chegada, sem usar heterogeneidade.
- Fair Sharing – Fair Sharing cria um pool para usuários individuais contendo vários mapas e reduz slots em um recurso que eles podem usar para executar trabalhos específicos.
O que é execução especulativa?
Muitas vezes, na estrutura do Hadoop, alguns nós podem ser executados mais lentamente que os demais. Isso tende a restringir todo o programa. Para superar isso, o Hadoop primeiro detecta ou 'especula' quando uma tarefa está sendo executada mais lentamente do que o normal e, em seguida, inicia um backup equivalente para essa tarefa. Assim, no processo, o nó mestre executa ambas as tarefas simultaneamente e a que for concluída primeiro é aceita enquanto a outra é eliminada. Esse recurso de backup do Hadoop é conhecido como Execução especulativa.

Cite os principais componentes do Apache HBase?
O Apache HBase é composto por três componentes:
- Servidor de região: depois que uma tabela é dividida em várias regiões, os clusters dessas regiões são encaminhados aos clientes por meio do servidor de região.
- HMaster: Esta é uma ferramenta que ajuda a gerenciar e coordenar o servidor da Região.
- ZooKeeper: ZooKeeper é um coordenador dentro do ambiente distribuído HBase. Ele ajuda a manter um estado de servidor dentro do cluster por meio de comunicação em sessões.
O que é “Checkpoint”? Qual é o seu benefício?
Checkpointing refere-se ao procedimento pelo qual um log FsImage e Edit são combinados para formar um novo FsImage. Assim, em vez de reproduzir o log de edição, o NameNode pode carregar diretamente o estado final na memória do FsImage. O NameNode secundário é responsável por esse processo.
O benefício que o Checkpointing oferece é que ele minimiza o tempo de inicialização do NameNode, tornando todo o processo mais eficiente.
Aplicativos de Big Data na cultura pop
Como depurar um código Hadoop?
Para depurar um código Hadoop, primeiro, você precisa verificar a lista de tarefas MapReduce que estão em execução no momento. Em seguida, você precisa verificar se alguma tarefa órfã está sendo executada simultaneamente. Nesse caso, você precisa encontrar o local dos logs do Resource Manager seguindo estas etapas simples:
Execute “ps –ef | grep –I ResourceManager” e no resultado exibido, tente descobrir se há um erro relacionado a um ID de trabalho específico.
Agora, identifique o nó do trabalhador que foi usado para executar a tarefa. Faça login no nó e execute “ps –ef | grep –iNodeManager.”
Por fim, examine o log do Node Manager. A maioria dos erros é gerada a partir de logs de nível de usuário para cada tarefa de redução de mapa.
Qual é o propósito do RecordReader no Hadoop?
O Hadoop divide os dados em formatos de bloco. RecordReader ajuda a integrar esses blocos de dados em um único registro legível. Por exemplo, se os dados de entrada forem divididos em dois blocos –
Linha 1 – Bem-vindo a
Linha 2 - UpGrad
O RecordReader lerá isso como “Bem-vindo ao UpG rad”.
Quais são os modos nos quais o Hadoop pode ser executado?
Os modos nos quais o Hadoop pode ser executado são:
- Modo autônomo – Este é um modo padrão do Hadoop que é usado para fins de depuração. Não suporta HDFS.
- Modo pseudodistribuído – Este modo exigia a configuração dos arquivos mapred-site.xml, core-site.xml e hdfs-site.xml. Tanto o nó mestre quanto o nó escravo são os mesmos aqui.
- Modo totalmente distribuído – O modo totalmente distribuído é o estágio de produção do Hadoop no qual os dados são distribuídos por vários nós em um cluster do Hadoop. Aqui, os nós mestre e escravo são distribuídos separadamente.
Cite algumas aplicações práticas do Hadoop.
Aqui estão alguns exemplos da vida real em que o Hadoop está fazendo a diferença:
- Gerenciando o tráfego nas ruas
- Detecção e prevenção de fraudes
- Analise os dados do cliente em tempo real para melhorar o atendimento ao cliente
- Acessar dados médicos não estruturados de médicos, HCPs, etc., para melhorar os serviços de saúde.
Quais são as ferramentas vitais do Hadoop que podem melhorar o desempenho do Big Data?
As ferramentas do Hadoop que aumentam significativamente o desempenho do Big Data são

• Colmeia
• HDFS
• HBase
• SQL
• NoSQL
• Oozie
• Nuvens
• Avro
• Calha
• Funcionário do zoológico
Engenheiros de Big Data: Mitos vs. Realidades
Conclusão
Essas perguntas da entrevista do Hadoop devem ser de grande ajuda para você em sua próxima entrevista. Embora às vezes seja a tendência dos entrevistadores distorcer algumas perguntas da entrevista do Hadoop, não deve ser um problema para você se você tiver o básico resolvido.
Se você estiver interessado em saber mais sobre Big Data, confira nosso programa PG Diploma in Software Development Specialization in Big Data, projetado para profissionais que trabalham e fornece mais de 7 estudos de caso e projetos, abrange 14 linguagens e ferramentas de programação, práticas práticas workshops, mais de 400 horas de aprendizado rigoroso e assistência para colocação de emprego com as principais empresas.