
Pipeline de teste 101 para teste de front-end
Publicados: 2022-03-10Imagine esta situação: você está se aproximando de um prazo rapidamente e está usando cada minuto livre para atingir seu objetivo de terminar essa refatoração complexa, com muitas alterações em seus arquivos CSS. Você está até trabalhando nos últimos passos durante a viagem de ônibus. No entanto, seus testes locais parecem falhar todas as vezes e você não consegue fazê-los funcionar. Seu nível de estresse está aumentando .
De fato, há uma cena semelhante em uma série conhecida: é da terceira temporada da série de TV da Netflix, “How to Sell Drugs Online (Fast)”:
Cypress + Vue é apresentado *EM UM SHOW DE TV NETFLIX*
— jess (@_jessicasachs) 7 de agosto de 2021
É uma comédia chamada "Como vender drogas (rápido)" e tem algumas das representações mais realistas do webdev.
Temporada 3, Episódio 1 @ 20:20 e uma ou duas vezes antes disso. pic.twitter.com/ICSAwMxyFB
Bem, ele está usando testes pelo menos, você pode pensar. Por que ele ainda está em perigo, você pode se perguntar? Ainda há muito espaço para melhorias e para evitar tal situação, mesmo se você escrever testes. Como você pensa em monitorar sua base de código e todas as suas alterações desde o início? Como resultado, você não terá surpresas tão desagradáveis, certo? Não é muito difícil incluir essas rotinas de teste automatizadas: vamos criar esse pipeline de teste juntos do início ao fim.
Vamos lá!
Primeiras coisas primeiro: termos básicos
Uma rotina de construção pode ajudá-lo a ficar confiante em refatorações mais complexas, mesmo em seus pequenos projetos paralelos. No entanto, isso não significa que você precisa ser um engenheiro de DevOps. É essencial aprender alguns termos e estratégias, e é para isso que você está aqui, certo? Felizmente, você está no lugar certo! Vamos começar com os termos fundamentais que você encontrará em breve ao lidar com um pipeline de teste para seu projeto de front-end.
Se você pesquisar no Google o mundo dos testes em geral, pode acontecer de você já se deparar com os termos “CI/CD” como um dos primeiros termos. É a abreviação de “Integração Contínua, Entrega Contínua” e “Implantação Contínua” e descreve exatamente isso: Como você provavelmente já ouviu, é um método de distribuição de software usado por equipes de desenvolvimento para implantar alterações de código com mais frequência e confiabilidade. CI/CD envolve duas abordagens complementares, que dependem muito da automação.
- Integração contínua
É um termo para medidas de automação para implementar pequenas alterações de código regulares e mesclá-las em um repositório compartilhado. A integração contínua inclui as etapas de construção e teste do seu código.
CD é o acrônimo para “Entrega Contínua” e “Implantação Contínua”, que são conceitos semelhantes entre si, mas às vezes usados em contextos diferentes. A diferença entre ambos está no escopo da automação:
- Entrega Contínua
Refere-se ao processo do seu código que já estava sendo testado antes, de onde a equipe de operações agora pode implantá-los em um ambiente de produção ao vivo. Este último passo pode ser manual. - Implantação Contínua
Ele se concentra no aspecto de “implantação”, como o nome indica. É um termo para o processo de liberação totalmente automatizado de alterações do desenvolvedor desde o repositório até a produção, onde o cliente pode usá-las diretamente.
Esses processos visam permitir que desenvolvedores e equipes tenham um produto, que você pode lançar a qualquer momento, se desejarem: Ter a confiança de um aplicativo continuamente monitorado, testado e implantado.
Para alcançar uma estratégia de CI/CD bem projetada, a maioria das pessoas e organizações usa processos chamados de “pipelines”. “Pipeline” é uma palavra que já usamos neste guia sem explicá-la. Se você pensar nesses oleodutos, não é exagero pensar em tubos servindo como linhas de longa distância para transportar coisas como gás. Um pipeline na área de DevOps funciona de maneira bastante semelhante: eles estão “transportando” software para implantação.
Espere, isso soa como muitas coisas para aprender e lembrar, certo? Não falamos sobre testes? Você está certo sobre isso: cobrir o conceito completo de um pipeline de CI/CD fornecerá conteúdo suficiente para vários artigos, e queremos cuidar de um pipeline de testes para pequenos projetos de front-end. Ou você está apenas perdendo o aspecto de teste de seus pipelines, concentrando-se apenas nos processos de integração contínua. Então, em particular, vamos nos concentrar na parte “Teste” de pipelines. Portanto, criaremos um pipeline de teste “pequeno” neste guia.
Tudo bem, então a “parte de teste” é nosso foco principal. Nesse contexto, quais testes você já conhece e vêm à sua mente à primeira vista? Se eu pensar em testar dessa maneira, estes são os tipos de teste em que penso espontaneamente:
- O teste de unidade é um tipo de teste no qual pequenas partes ou unidades testáveis de um aplicativo, chamadas de unidades, são testadas individual e independentemente para operação adequada.
- O Teste de Integração tem foco na interação entre componentes ou sistemas. Esse tipo de teste significa que estamos verificando a interação das unidades e como elas estão trabalhando juntas.
- Teste de ponta a ponta , ou teste E2E, significa que as interações reais do usuário são simuladas pelo computador; ao fazer isso, o teste E2E deve incluir o maior número possível de áreas funcionais e partes da pilha de tecnologia usada no aplicativo.
- O teste visual é o processo de verificar a saída visível de um aplicativo e compará-lo com os resultados esperados. Dito de outra forma, ajuda a encontrar “bugs visuais” na aparência de uma página ou tela diferente de bugs puramente funcionais.
- A análise estática não é um teste preciso, mas acho essencial mencioná-la aqui. Você pode imaginá-lo funcionando como uma correção ortográfica: ele depura seu código sem executar o programa e detecta problemas de estilo de código. Esta medida simples pode evitar muitos bugs.
Para ter certeza de mesclar uma refatoração massiva em nosso projeto exclusivo, devemos considerar o uso de todos esses tipos de teste em nosso pipeline de testes. Mas o início leva à frustração rapidamente: você pode se sentir perdido avaliando esses tipos de teste. Por onde devo começar? Quantos testes de quais tipos são razoáveis?
Estratégia: Pirâmides e troféus
Precisamos trabalhar em uma estratégia de teste antes de mergulhar na construção de nosso pipeline. Procurando respostas para todas essas perguntas antes, você pode encontrar uma possível solução em algumas metáforas: Na web e em comunidades de teste especificamente, as pessoas tendem a usar analogias para dar uma ideia de quantos testes você deve usar de qual tipo.
A primeira metáfora que você provavelmente encontrará é a pirâmide de automação de teste. Mike Cohn surgiu com este conceito em seu livro “Succeeding with Agile”, desenvolvido posteriormente como “Practical Test Pyramid” por Martin Fowler. Se parece com isso:
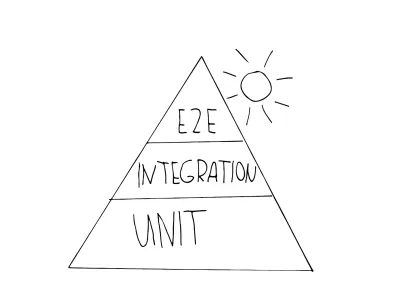
Como você vê, consiste em três níveis, que correspondem aos três níveis de teste apresentados. A pirâmide destina-se a esclarecer a combinação certa de testes diferentes, para orientá-lo durante o desenvolvimento de uma estratégia de teste:
- Unidade
Você encontra esses testes na camada base da pirâmide porque eles são de execução rápida e simples de manter. Isso se deve ao seu isolamento e ao fato de terem como alvo as unidades menores. Veja este para um exemplo de um teste de unidade típico testando um produto muito pequeno. - Integração
Eles estão no meio da pirâmide, pois ainda são aceitáveis quando se trata de velocidade na execução, mas ainda trazem a confiança de estar mais próximo do usuário do que os testes de unidade podem estar. Um exemplo de teste do tipo integração é um teste de API, também testes de componentes podem ser considerados desse tipo. - Testes E2E (também chamados de testes de interface do usuário )
Como vimos, esses testes simulam um usuário genuíno e sua interação. Esses testes precisam de mais tempo para serem executados e, portanto, são mais caros — sendo colocados no topo da pirâmide. Se você quiser inspecionar um exemplo típico para um teste E2E, vá até este.
No entanto, nos últimos anos, essa metáfora parecia fora de tempo. Uma de suas falhas, em particular, é crucial para mim: as análises estáticas são contornadas nessa estratégia. O uso de code-style fixers ou outras soluções de linting não são considerados nesta metáfora, sendo uma grande falha, na minha opinião. Lint e outras ferramentas de análise estática são parte integrante do pipeline em uso e não devem ser ignoradas.
Então, vamos resumir: devemos usar uma estratégia mais atualizada. Mas a falta de ferramentas de linting não é a única falha - há ainda um ponto mais significativo a ser considerado. Em vez disso, podemos mudar um pouco nosso foco: a citação a seguir resume muito bem:
“Escreva testes. Não muito. Principalmente integração.”
— Guilherme Rauch
Vamos quebrar esta citação para aprender sobre isso:
- Escrever testes
Bastante auto-explicativo - você deve sempre escrever testes. Os testes são cruciais para incutir confiança em seu aplicativo — tanto para usuários quanto para desenvolvedores. Até para você mesmo! - Não muito
Escrever testes aleatoriamente não o levará a lugar nenhum; a pirâmide de testes ainda é válida em sua declaração para manter os testes priorizados. - Principalmente integração
Um trunfo dos testes mais “caros” que a pirâmide ignora é que a confiança nos testes aumenta à medida que você sobe na pirâmide. Esse aumento significa que tanto o usuário quanto você como desenvolvedor provavelmente confiarão nesses testes.
Isso significa que devemos optar por testes mais próximos do usuário, por design. Como resultado, você pode pagar mais, mas recebe muito valor de volta. Você pode se perguntar por que não escolher o teste E2E? Como eles estão imitando usuários, eles não são os mais próximos do usuário, para começar? Isso é verdade, mas eles ainda são muito mais lentos para executar e exigem a pilha de aplicativos completa. Portanto, esse retorno do investimento é alcançado mais tarde do que com os testes de integração: Consequentemente, os testes de integração oferecem um equilíbrio justo entre confiança, por um lado, e velocidade e esforço, por outro.
Se você segue Kent C.Dodds, esses argumentos podem soar familiares para você, especialmente se você ler este artigo dele em particular. Esses argumentos não são coincidência: ele criou uma nova estratégia em seu trabalho. Concordo fortemente com seus pontos e vinculo o mais importante aqui e outros na seção de recursos. Sua abordagem sugerida deriva da pirâmide de testes, mas a eleva a outro nível, alterando sua forma para refletir a prioridade mais alta nos testes de integração. É chamado de “Troféu de Teste”.
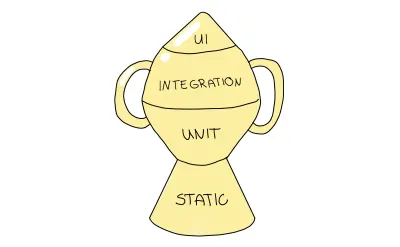
O troféu de teste é uma metáfora que descreve a granularidade dos testes de uma maneira ligeiramente diferente; você deve distribuir seus testes nos seguintes tipos de teste:
- A análise estática desempenha um papel vital nessa metáfora. Dessa forma, você detectará erros de digitação, erros de tipo e outros bugs simplesmente executando as etapas de depuração mencionadas.
- Os Testes Unitários devem garantir que sua menor unidade seja testada adequadamente, mas o troféu de teste não os enfatizará na mesma extensão que a pirâmide de testes.
- A integração é o foco principal, pois equilibra o custo e a maior confiança da melhor maneira.
- Os testes de interface do usuário, incluindo E2E e testes visuais, estão no topo do troféu de testes, semelhante ao seu papel na pirâmide de testes.
Eu optei por essa estratégia de troféu de teste na maioria dos meus projetos e continuarei a fazê-lo neste guia. No entanto, preciso dar um pequeno aviso aqui: Claro, minha escolha é baseada nos projetos em que estou trabalhando no meu dia-a-dia. Assim, os benefícios e a seleção de uma estratégia de teste compatível sempre dependem do projeto em que você está trabalhando. Portanto, não se sinta mal se não atender às suas necessidades, adicionarei recursos a outras estratégias no parágrafo correspondente.
Alerta de spoiler menor: De certa forma, precisarei me desviar um pouco desse conceito também, como você verá em breve. No entanto, acho que está tudo bem, mas chegaremos a isso em breve. Meu ponto é pensar na priorização e distribuição de tipos de teste antes de planejar e implementar seus pipelines.
Como construir esses pipelines online (rápido)
O protagonista da terceira temporada da série de TV da Netflix “How To Sell Drugs Online (Fast)” é mostrado usando Cypress para testes E2E perto de um prazo, no entanto, era realmente apenas testes locais. Nenhum CI/CD foi visto, o que lhe causou estresse desnecessário. Devemos evitar a pressão do protagonista dado nos episódios correspondentes com a teoria que aprendemos. No entanto, como podemos aplicar esses aprendizados à realidade?
Em primeiro lugar, precisamos de uma base de código como base de teste para começar. Idealmente, deve ser um projeto que muitos de nós, desenvolvedores front-end, encontraremos. Seu caso de uso deve ser frequente, sendo adequado para uma abordagem prática e nos permitindo implementar um pipeline de testes do zero. O que poderia ser um projeto desses?
Minha sugestão de um pipeline primário
A primeira coisa que me veio à mente foi evidente: meu site, ou seja, minha página de portfólio, é adequado para ser considerado um exemplo de base de código a ser testado por nosso aspirante a pipeline. É publicado de código aberto no Github, para que você possa visualizá-lo e usá-lo livremente. Algumas palavras sobre a pilha de tecnologia do site: Basicamente, eu construí este site no Vue.js (infelizmente ainda na versão 2 quando escrevi este artigo) como um framework JavaScript com Nuxt.js como um framework web adicional. Você pode encontrar o exemplo de implementação completo em seu repositório GitHub.
Com nossa base de código de exemplo selecionada, devemos começar a aplicar nossos aprendizados. Dado o fato de que queremos usar o troféu de teste como ponto de partida para nossa estratégia de teste, criei o seguinte conceito:
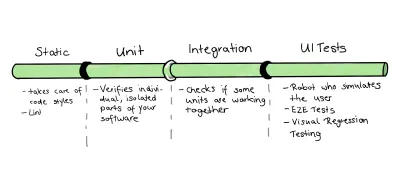
Como estamos lidando com uma base de código relativamente pequena, vou mesclar as partes dos testes de Unidade e Integração. No entanto, essa é apenas uma pequena razão para fazer isso. Outros motivos mais importantes são os seguintes:
- A definição de uma unidade é muitas vezes “para ser discutida”: Se você pedir a um grupo de desenvolvedores para definir uma unidade, você obterá respostas diversas e diferentes. Como alguns se referem a uma função, classe ou serviço – unidades menores – outro desenvolvedor contará no componente completo.
- Além dessas dificuldades de definição, traçar uma linha entre unidade e integração pode ser complicado, pois é muito embaçado. Essa luta é real, especialmente para o Frontend, pois muitas vezes precisamos do DOM para validar a base de teste com sucesso.
- Geralmente é possível usar as mesmas ferramentas e bibliotecas para escrever os dois testes de integração. Assim, podemos economizar recursos mesclando-os.
Ferramenta de escolha: GitHub Actions
Como sabemos o que queremos retratar dentro de um pipeline, o próximo passo é a escolha da plataforma de integração e entrega contínuas (CI/CD). Ao escolher essa plataforma para o nosso projeto, penso naquelas com as quais já ganhei experiência:
- GitLab, pela rotina diária do meu local de trabalho,
- GitHub Actions na maioria dos meus projetos paralelos.
No entanto, existem muitas outras plataformas para escolher. Sugiro sempre basear sua escolha em seus projetos e seus requisitos específicos, considerando as tecnologias e frameworks utilizados — para que não ocorram problemas de compatibilidade. Lembre-se, usamos um projeto Vue 2 que já foi lançado no GitHub, coincidentemente com minha experiência anterior. Além disso, as GitHub Actions mencionadas precisam apenas do repositório GitHub do seu projeto como ponto de partida; para criar e executar um fluxo de trabalho do GitHub Actions especificamente para ele. Como consequência, usarei GitHub Actions para este guia.
Portanto, essas ações do GitHub fornecem uma plataforma para executar fluxos de trabalho definidos especificamente se alguns eventos estiverem acontecendo. Esses eventos são atividades específicas em nosso repositório que acionam o fluxo de trabalho, por exemplo, enviar alterações para uma ramificação. Neste guia, esses eventos estão vinculados ao CI/CD, mas esses fluxos de trabalho também podem automatizar outros fluxos de trabalho, como adicionar rótulos a solicitações pull. O GitHub pode executá-los em máquinas virtuais Windows, Linux e macOS.
Para visualizar esse fluxo de trabalho, ficaria assim:
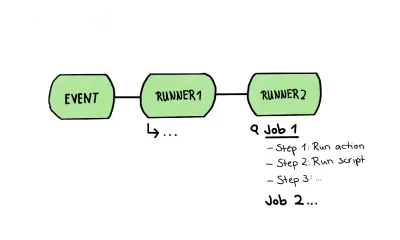
Neste artigo, usarei um fluxo de trabalho para visualizar um pipeline; isso significa que um fluxo de trabalho conterá todas as nossas etapas de teste, desde análise estática até testes de interface do usuário de todos os tipos. Esse pipeline, ou chamado de “fluxo de trabalho” nos parágrafos a seguir, consistirá em um ou mais jobs, que são um conjunto de etapas executadas no mesmo executor.

Este fluxo de trabalho é exatamente a estrutura que eu queria esboçar no desenho acima. Nele, examinamos mais de perto um tal corredor contendo vários trabalhos; As etapas de um trabalho em si são feitas de diferentes etapas. Essas etapas podem ser de dois tipos:
- Uma etapa pode executar um script simples.
- Uma etapa pode ser capaz de executar uma ação. Essa ação é uma extensão reutilizável e geralmente é um aplicativo completo e personalizado.
Tendo isso em mente, um fluxo de trabalho real de uma ação do GitHub se parece com isso:
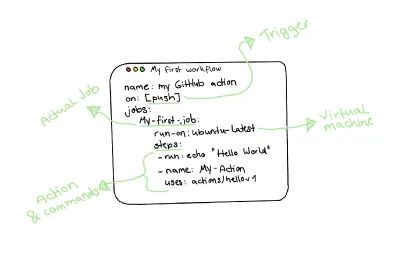
Escrevendo nossa primeira ação no GitHub
Finalmente, podemos escrever nossa primeira ação no Github e escrever algum código! Começaremos com nosso fluxo de trabalho básico e nosso primeiro esboço dos trabalhos que queremos descrever. Lembrando nosso troféu de teste, cada trabalho será semelhante a uma camada no troféu de teste. As etapas serão as coisas que precisamos fazer para automatizar essas camadas.
Portanto, crio o .github/workflows/ para armazenar nossos fluxos de trabalho primeiro. Criaremos um novo arquivo chamado tests.yml para conter nosso fluxo de trabalho de teste dentro deste diretório. Juntamente com a sintaxe de fluxo de trabalho padrão vista no desenho acima, procederei da seguinte forma:
- Vou nomear nosso fluxo de trabalho de
Tests CI. - Como quero executar meu fluxo de trabalho em cada push para minhas ramificações remotas e fornecer uma opção manual para iniciar meu pipeline, configurarei meu fluxo de trabalho para ser executado em
pusheworkflow_dispatch. - Por último, mas não menos importante, conforme indicado no parágrafo “Minha sugestão de pipeline básico”, meu fluxo de trabalho conterá três trabalhos:
-
static-eslintpara análise estática; -
unit-integration-jestpara teste de unidade e integração mesclado em um trabalho; -
ui-cypresscomo estágio de interface do usuário, incluindo teste E2E básico e teste de regressão visual.
-
- Uma máquina virtual baseada em Linux deve executar todos os trabalhos, então vou com
ubuntu-latest.
Coloque a sintaxe correta de um arquivo YAML , o primeiro esboço do nosso fluxo de trabalho pode se parecer com este:
name: Tests CI on: [push, workflow_dispatch] # On push and manual jobs: static-eslint: runs-on: ubuntu-latest steps: # 1 steps unit-integration-jest: runs-on: ubuntu-latest steps: # 1 step ui-cypress: runs-on: ubuntu-latest steps: # 2 steps: e2e and visualSe você quiser se aprofundar em detalhes sobre fluxos de trabalho na ação do GitHub, fique à vontade para acessar sua documentação a qualquer momento. De qualquer forma, você está, sem dúvida, ciente de que as etapas ainda estão faltando. Não se preocupe - eu também estou ciente. Portanto, para dar vida a esse esboço de fluxo de trabalho, precisamos definir essas etapas e decidir quais ferramentas e estruturas de teste usar para nosso pequeno projeto de portfólio. Todos os próximos parágrafos descreverão os respectivos trabalhos e conterão várias etapas para tornar possível a automação dos referidos testes.
Análise estática
Como sugere o troféu de teste, começaremos com linters e outros fixers de estilo de código em nosso fluxo de trabalho. Nesse contexto, você pode escolher entre muitas ferramentas, e alguns exemplos incluem:
- Eslint como um fixador de estilo de código Javascript.
- Stylelint para correção de código CSS.
- Podemos considerar ir ainda mais longe, por exemplo, para analisar a complexidade do código, você pode olhar para ferramentas como o scrutinizer.
Essas ferramentas têm em comum o fato de apontarem erros de padrões e convenções. No entanto, esteja ciente de que algumas dessas regras são uma questão de gosto. Cabe a você decidir o quão rigoroso você deseja aplicá-los. Para citar um exemplo, se você vai tolerar um recuo de duas ou quatro guias. É muito mais importante se concentrar em exigir um estilo de código consistente e capturar causas mais críticas de erros, como usar “==” versus “===”.
Para nosso projeto de portfólio e este guia, quero começar a instalar o Eslint, pois estamos usando muito Javascript. Vou instalá-lo com o seguinte comando:
npm install eslint --save-dev Claro, também posso usar um comando alternativo com o gerenciador de pacotes do Yarn se preferir não usar o NPM. Após a instalação, preciso criar um arquivo de configuração chamado .eslintrc.json . Vamos usar uma configuração básica por enquanto, pois este artigo não vai te ensinar como configurar o Eslint em primeiro lugar:
{ "extends": [ "eslint:recommended", ] } Se você quiser saber mais sobre a configuração do Eslint em detalhes, acesse este guia. Em seguida, queremos dar os primeiros passos para automatizar a execução do Eslint. Para começar, quero definir o comando para executar o Eslint como um script NPM. Eu consigo isso usando este comando em nosso arquivo package.json na seção de script :
"scripts": { "lint": "eslint --ext .js .", }, Posso então executar esse script recém-criado em nosso fluxo de trabalho do GitHub. No entanto, precisamos ter certeza de que nosso projeto está disponível antes de fazer isso. Portanto, usamos o GitHub Action actions/checkout@v2 pré-configurado que faz exatamente isso: Verificando nosso projeto, para que o fluxo de trabalho da sua ação do GitHub possa acessá-lo. A próxima etapa seria instalar todas as dependências do NPM necessárias para o meu projeto de portfólio. Depois disso, estamos finalmente prontos para executar nosso script eslint! Nosso trabalho final para usar linting se parece com isso agora:
static-eslint: runs-on: ubuntu-latest steps: # Action to check out my codebase - uses: actions/checkout@v2 # install NPM dependencies - run: npm install # Run lint script - run: npm run lint Você pode se perguntar agora: esse pipeline “falha” automaticamente quando nosso npm run lint em um teste com falha? Sim, isso funciona fora da caixa. Assim que terminarmos de escrever nosso fluxo de trabalho, veremos as capturas de tela no Github.
Unidade e Integração
Em seguida, quero criar nosso trabalho contendo as etapas de unidade e integração. Em relação ao framework usado neste artigo, gostaria de apresentar o framework Jest para testes de front-end. Claro, você não precisa usar o Jest se não quiser - existem muitas alternativas para escolher:
- Cypress também fornece testes de componentes adequados para testes de integração.
- Jasmine é outro framework para dar uma olhada também.
- E há muito mais; Eu só queria citar alguns.
Jest é fornecido como código aberto pelo Facebook. A estrutura credita seu foco na simplicidade ao mesmo tempo em que é compatível com muitas estruturas e projetos JavaScript, incluindo Vue.js, React ou Angular. Também sou capaz de usar jest em conjunto com o TypeScript. Isso torna o framework muito interessante, especialmente para meu pequeno projeto de portfólio, pois é compatível e adequado.
Podemos iniciar diretamente a instalação do Jest a partir desta pasta raiz do meu projeto de portfólio, digitando o seguinte comando:
npm install --save-dev jest Após a instalação, já consigo começar a escrever testes. No entanto, este artigo se concentra em automatizar esses testes usando ações do Github. Portanto, para aprender a escrever uma unidade ou teste de integração, consulte o guia a seguir. Ao configurar o trabalho em nosso fluxo de trabalho, podemos proceder de maneira semelhante ao trabalho static-eslint . Então, o primeiro passo é criar novamente um pequeno script NPM para usar em nosso trabalho mais tarde:
"scripts": { "test": "jest", }, Depois, definiremos o job chamado unit-integration-jest forma semelhante ao que já fizemos para nossos linters antes. Assim, o fluxo de trabalho verificará nosso projeto. Além disso, usaremos duas pequenas diferenças em nosso primeiro trabalho static-eslint :
- Usaremos uma ação como uma etapa para instalar o Node.
- Depois disso, usaremos nosso script npm recém-criado para executar nosso teste Jest.
Desta forma, nosso trabalho unit-integration-jest ficará assim::
unit-integration-jest: runs-on: ubuntu-latest steps: - uses: actions/checkout@v2 # Set up node - name: Run jest uses: actions/setup-node@v1 with: node-version: '12' - run: npm install # Run jest script - run: npm testTestes de interface do usuário: E2E e testes visuais
Por último, mas não menos importante, escreveremos nosso trabalho ui-cypress , que conterá testes E2E e testes visuais. É inteligente combinar esses dois em um trabalho, pois usarei a estrutura Cypress para ambos. Claro, você pode considerar outros frameworks como os abaixo, NightwatchJS e CodeceptJS.
Novamente, abordaremos apenas o básico para configurá-lo em nosso fluxo de trabalho do GitHub. Se você quiser aprender a escrever testes Cypress em detalhes, eu o cobri com outro dos meus guias abordando exatamente isso. Este artigo irá guiá-lo através de tudo o que precisamos para definir nossas etapas de teste E2E. Tudo bem, primeiro vamos instalar o Cypress, da mesma forma que fizemos com os outros frameworks, usando o seguinte comando em nossa pasta raiz:
npm install --save-dev cypress Desta vez, não precisamos definir um script NPM. Cypress já nos fornece sua própria ação do GitHub para usar, cypress-io/github-action@v2 . Lá, só precisamos configurar algumas coisas para que ele funcione:
- Precisamos garantir que nosso aplicativo esteja totalmente configurado e funcionando, pois um teste E2E precisa da pilha completa de aplicativos disponível.
- Precisamos nomear o navegador no qual estamos executando nosso teste E2E.
- Precisamos esperar que o servidor web esteja funcionando plenamente, para que o computador possa se comportar como um usuário real.
Felizmente, nossa ação Cypress nos ajuda a armazenar todas essas configurações com a área with . Dessa forma, nosso trabalho atual do GitHub fica assim:
steps: - name: Checkout uses: actions/checkout@v2 # Install NPM dependencies, cache them correctly # and run all Cypress tests - name: Cypress Run uses: cypress-io/github-action@v2 with: browser: chrome headless: true # Setup: Nuxt-specific things build: npm run generate start: npm run start wait-on: 'http://localhost:3000'Testes visuais: dê alguns olhos ao seu teste
Lembre-se de nossa primeira intenção de escrever este guia: tenho minha refatoração significativa com muitas alterações nos arquivos SCSS — quero adicionar testes como parte da rotina de compilação para garantir que isso não atrapalhe mais nada. Tendo análise estática, unidade, integração e testes E2E, devemos estar bastante confiantes, certo? É verdade, mas ainda há algo que posso fazer para tornar meu pipeline ainda mais à prova de balas e perfeito. Você poderia dizer que está se tornando o creme. Especialmente ao lidar com refatoração de CSS, um teste E2E só pode ser de ajuda limitada, pois ele só faz o que você disse para fazer escrevendo-o em seu teste.
Felizmente, há outra maneira de detectar bugs além dos comandos escritos e, portanto, além do conceito. É chamado de teste visual: você pode imaginar esse tipo de teste como um quebra-cabeças para identificar a diferença. Tecnicamente falando, o teste visual é uma comparação de capturas de tela que captura capturas de tela do seu aplicativo e as compara com o status quo, por exemplo, da ramificação principal do seu projeto. Dessa forma, nenhum problema de estilo acidental passará despercebido - pelo menos nas áreas em que você usa testes visuais. Isso pode transformar os testes visuais em um salva-vidas para grandes refatorações de CSS, pelo menos na minha experiência.
Existem muitas ferramentas de teste visual para escolher e vale a pena dar uma olhada:
- Percy.io, uma ferramenta do Browserstack que estou usando para este guia;
- Visual Regression Tracker se você preferir não usar uma solução SaaS e se tornar totalmente open source ao mesmo tempo;
- Applitools com suporte a IA. Há um guia interessante para ver na revista Smashing sobre essa ferramenta;
- Cromático por Storybook.
Para este guia e basicamente para o meu projeto de portfólio, foi vital reutilizar meus testes Cypress existentes para testes visuais. Como mencionado anteriormente, usarei Percy para este exemplo devido à sua simplicidade de integração. Embora seja uma solução SaaS, ainda há muitas partes fornecidas de código aberto, e há um plano gratuito que deve ser suficiente para muitos projetos de código aberto ou outros projetos paralelos. No entanto, se você se sentir mais confortável em ficar totalmente auto-hospedado enquanto usa uma ferramenta de código aberto, você pode experimentar o Visual Regression Tracker.
Este guia fornecerá apenas uma breve visão geral de Percy, que de outra forma forneceria conteúdo para um artigo totalmente novo. No entanto, vou dar-lhe as informações para você começar. Se você quiser se aprofundar nos detalhes agora, recomendo dar uma olhada na documentação de Percy. Então, como podemos dar olhos aos nossos testes, por assim dizer? Vamos supor que já escrevemos um ou dois testes Cypress agora. Imagine-os assim:
it('should load home page (visual)', () => { cy.get('[data-cy=Polaroid]').should('be.visible'); cy.get('[data-cy=FeaturedPosts]').should('be.visible'); });Claro, se quisermos instalar o Percy como nossa solução de teste visual, podemos fazer isso com um plugin cypress. Então, como fizemos algumas vezes hoje, estamos instalando-o em nossa pasta raiz usando o NPM:
npm install --save-dev @percy/cli @percy/cypress Depois, você só precisa importar o pacote percy/cypress para o arquivo de índice cypress/support/index.js :
import '@percy/cypress';Essa importação permitirá que você use o comando snapshot do Percy, que tirará um snapshot do seu aplicativo. Nesse contexto, um instantâneo significa uma coleção de capturas de tela tiradas de diferentes janelas de visualização ou navegadores que você pode configurar.
it('should load home page (visual)', () => { cy.get('[data-cy=Polaroid]').should('be.visible'); cy.get('[data-cy=FeaturedPosts]').should('be.visible'); // Take a snapshot cy.percySnapshot('Home page'); }); Voltando ao nosso arquivo de fluxo de trabalho, quero definir o teste de Percy como a segunda etapa do trabalho. Nele, executaremos o script npx percy exec -- cypress run para executar nosso teste junto com Percy. Para conectar nossos testes e resultados ao nosso projeto Percy, precisaremos passar nosso token Percy, oculto por um segredo do GitHub.
steps: # Before: Checkout, NPM, and E2E steps - name: Percy Test run: npx percy exec -- cypress run env: PERCY_TOKEN: ${{ secrets.PERCY_TOKEN }}Por que preciso de um token Percy? É porque Percy é uma solução SaaS para manter nossas capturas de tela. Ele manterá as capturas de tela e o status quo para comparação e nos fornecerá um fluxo de trabalho de aprovação de captura de tela. Lá, você pode aprovar ou rejeitar qualquer alteração futura:
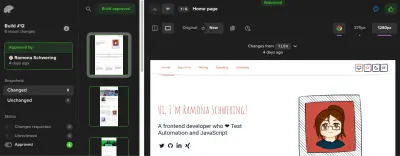
Visualizando nossos trabalhos: integração com o GitHub
Parabéns! Estávamos construindo com sucesso nosso primeiro fluxo de trabalho de ação do GitHub. Vamos dar uma olhada final em nosso arquivo de fluxo de trabalho completo no repositório da minha página de portfólio. Você não se pergunta como fica no uso prático? Você pode encontrar suas ações do GitHub em funcionamento na guia “Ações” do seu repositório:
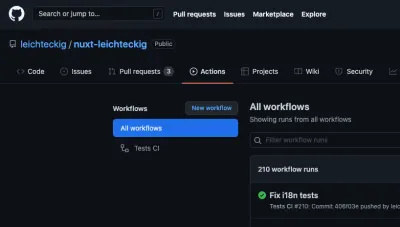
Lá, você pode encontrar todos os fluxos de trabalho, que são equivalentes aos seus arquivos de fluxo de trabalho. Se você der uma olhada em um fluxo de trabalho, por exemplo, meu fluxo de trabalho “Testes CI”, você pode inspecionar todos os trabalhos dele:
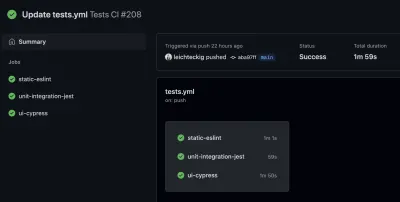
Se quiser dar uma olhada em um de seus trabalhos, você também pode selecioná-lo na barra lateral. Lá, você pode inspecionar o log de seus trabalhos:
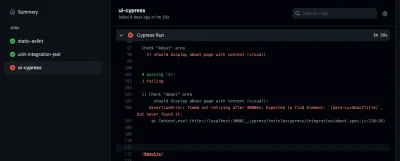
Veja, você é capaz de detectar erros se eles acontecerem dentro do seu pipeline. A propósito, a aba “action” não é o único lugar onde você pode checar os resultados de suas ações do GitHub. Você também pode inspecioná-los em suas pull requests:
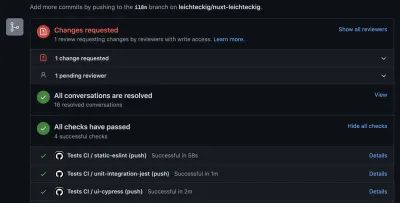
I like to configure those GitHub actions the way they need to be executed successfully: Otherwise, it's not possible to merge any pull requests into my repository.
Conclusão
CI/CD helps us perform even major refactorings — and dramatically minimizes the risk of running into nasty surprises. The testing part of CI/CD is taking care of our codebase being continuously tested and monitored. Consequently, we will notice errors very early, ideally before anyone merges them into your main branch. Plus, we will not get into the predicament of correcting our local tests on the way to work — or even worse — actual errors in our application. I think that's a great perspective, right?
To include this testing build routine, you don't need to be a full DevOps engineer: With the help of some testing frameworks and GitHub actions, you're able to implement these for your side projects as well. I hope I could give you a short kick-off and got you on the right track.
I'm looking forward to seeing more testing pipelines and GitHub action workflows out there! ️
Recursos
- An excellent guide on CI/CD by GitHub
- “The practical test pyramid”, Ham Vocke
- Articles on the testing trophy worth reading, by Kent C.Dodds:
- “Write tests. Not too many. Mostly integration”
- “The Testing Trophy and Testing Classifications”
- “Static vs Unit vs Integration vs E2E Testing for Frontend Apps”
- I referred to some examples of the Cypress real world app
- Documentation of used tools and frameworks:
- GitHub actions
- Eslint docs
- Documentação Jest
- Documentação do cipreste
- Percy documentation