
Previsão do mercado de ações usando aprendizado de máquina [Implementação passo a passo]
Publicados: 2021-02-26Índice
Introdução
Previsão e análise do mercado de ações são algumas das tarefas mais complicadas de se fazer. Existem várias razões para isso, como a volatilidade do mercado e tantos outros fatores dependentes e independentes para decidir o valor de uma determinada ação no mercado. Esses fatores tornam muito difícil para qualquer analista do mercado de ações prever a alta e a queda com altos graus de precisão.
No entanto, com o advento do Machine Learning e seus algoritmos robustos, os mais recentes desenvolvimentos de análise de mercado e previsão do mercado de ações começaram a incorporar essas técnicas na compreensão dos dados do mercado de ações.
Em suma, os algoritmos de aprendizado de máquina estão sendo amplamente utilizados por muitas organizações na análise e previsão de valores de ações. Este artigo passará por uma implementação simples de análise e previsão dos valores de estoque de uma loja de varejo online popular mundial usando vários algoritmos de aprendizado de máquina em Python.
Declaração do problema
Antes de entrarmos na implementação do programa para prever os valores do mercado de ações, vamos visualizar os dados sobre os quais estaremos trabalhando. Aqui, estaremos analisando o valor das ações da Microsoft Corporation (MSFT) da National Association of Securities Dealers Automated Quotations (NASDAQ). Os dados do valor do estoque serão apresentados na forma de um arquivo separado por vírgulas (.csv), que pode ser aberto e visualizado usando o Excel ou uma planilha.
A MSFT tem suas ações registradas na NASDAQ e tem seus valores atualizados durante todos os dias úteis do mercado de ações. Observe que o mercado não permite negociações aos sábados e domingos; portanto, há uma lacuna entre as duas datas. Para cada data, o Valor de Abertura da ação, os valores mais alto e mais baixo dessa ação nos mesmos dias são anotados, juntamente com o valor de fechamento no final do dia.
O valor de fechamento ajustado mostra o valor da ação após os dividendos serem lançados (muito técnico!). Além disso, também é dado o volume total das ações no mercado, com esses dados, cabe ao trabalho de um Machine Learning/Data Scientist estudar os dados e implementar diversos algoritmos que possam extrair padrões do histórico de ações da Microsoft Corporation dados.

Memória de curto prazo longa
Para desenvolver um modelo de Machine Learning para prever os preços das ações da Microsoft Corporation, utilizaremos a técnica de Long Short-Term Memory (LSTM). Eles são usados para fazer pequenas modificações nas informações por multiplicações e adições. Por definição, a memória de longo prazo (LSTM) é uma arquitetura de rede neural recorrente artificial (RNN) usada em aprendizado profundo.
Ao contrário das redes neurais feed-forward padrão, o LSTM possui conexões de feedback. Ele pode processar pontos de dados únicos (como imagens) e sequências de dados inteiras (como fala ou vídeo). Para entender o conceito por trás do LSTM, vamos dar um exemplo simples de uma análise de um cliente online de um telefone celular.
Suponha que queremos comprar o celular, geralmente nos referimos às avaliações da rede por usuários certificados. Dependendo do pensamento e das contribuições deles, decidimos se o celular é bom ou ruim e depois o compramos. Conforme vamos lendo os comentários, procuramos por palavras-chave como “incrível”, “boa câmera”, “melhor bateria de reserva” e muitos outros termos relacionados a um telefone celular.
Tendemos a ignorar as palavras comuns em inglês como “it”, “gave”, “this”, etc. Assim, quando decidimos comprar ou não o celular, lembramos apenas dessas palavras-chave definidas acima. Muito provavelmente, esquecemos as outras palavras.
Esta é a mesma maneira pela qual o Algoritmo de Memória de Longo Prazo Curto funciona. Ele apenas lembra as informações relevantes e as usa para fazer previsões ignorando os dados não relevantes. Dessa forma, temos que construir um modelo LSTM que essencialmente reconheça apenas os dados essenciais sobre esse estoque e deixe de fora seus outliers.
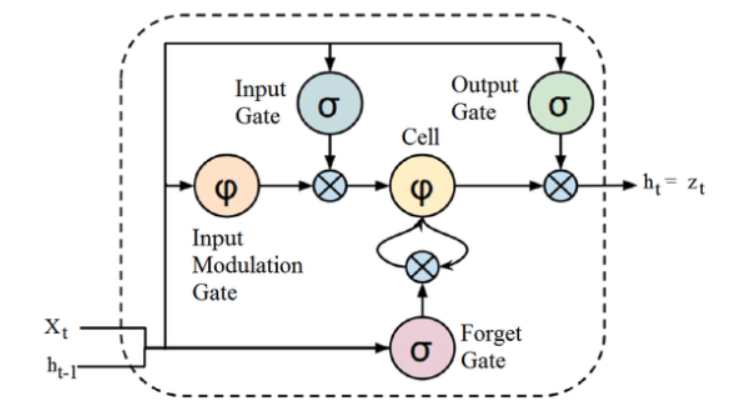
Fonte
Embora a estrutura de uma arquitetura LSTM dada acima possa parecer intrigante no início, é suficiente lembrar que LSTM é uma versão avançada de Redes Neurais Recorrentes que retém memória para processar sequências de dados. Ele pode remover ou adicionar informações ao estado da célula, cuidadosamente regulado por estruturas chamadas portas.
A unidade LSTM compreende uma célula, uma porta de entrada, uma porta de saída e uma porta de esquecimento. A célula memoriza valores em intervalos de tempo arbitrários e as três portas regulam o fluxo de informações para dentro e para fora da célula.
Implementação do Programa
Passaremos para a parte em que colocamos o LSTM em uso para prever o valor das ações usando Machine Learning em Python.
Passo 1 – Importando as Bibliotecas
Como todos sabemos, o primeiro passo é importar as bibliotecas necessárias para pré-processar os dados de estoque da Microsoft Corporation e as demais bibliotecas necessárias para construir e visualizar as saídas do modelo LSTM. Para isso, usaremos a biblioteca Keras no framework TensorFlow. Os módulos necessários são importados da biblioteca Keras individualmente.
#Importando as Bibliotecas
importar pandas como PD
importar NumPy como np
%matplotlib em linha
importe matplotlib. pyplot como plt
importar matplotlib
de sklearn. Importação de pré-processamento MinMaxScaler
de Keras. camadas importam LSTM, Dense, Dropout
de sklearn.model_selection importar TimeSeriesSplit
de sklearn.metrics importam mean_squared_error, r2_score
importe matplotlib. datas como mandatos
de sklearn. Importação de pré-processamento MinMaxScaler
do sklearn import linear_model
de Keras. Importação de modelos Sequencial
de Keras. Importação de camadas Dense
importar Keras. Back-end como K
de Keras. Importação de retornos de chamada EarlyStopping
de Keras. Otimizadores importam Adam
de Keras. Modelos importam load_model
de Keras. Importação de camadas LSTM
de Keras. utils.vis_utils import plot_model
Passo 2 – Obtendo a visualização dos dados
Usando a biblioteca do leitor Pandas Data, devemos carregar os dados de estoque do sistema local como um arquivo de valor separado por vírgula (.csv) e armazená-lo em um DataFrame pandas. Por fim, também veremos os dados.
#Obter o conjunto de dados
df = pd.read_csv(“MicrosoftStockData.csv”,na_values=['null'],index_col='Data',parse_dates=True,infer_datetime_format=True)
df.head()
Obtenha a certificação de IA online das melhores universidades do mundo - mestrados, programas de pós-graduação executiva e programa de certificação avançada em ML e IA para acelerar sua carreira.
Etapa 3 – Imprima a forma do DataFrame e verifique se há valores nulos.
Nesta outra etapa crucial, primeiro imprimimos a forma do conjunto de dados. Para certificar-se de que não há valores nulos no quadro de dados, verificamos por eles. A presença de valores nulos no conjunto de dados tende a causar problemas durante o treinamento, pois atuam como outliers causando uma grande variação no processo de treinamento.
#Imprima a forma do Dataframe e verifique se há valores nulos
print("Forma do quadro de dados: ", df. forma)
print("Valor Nulo Presente: ", df.IsNull().values.any())
>> Forma do Dataframe: (7334, 6)
>>Valor Nulo Presente: Falso
| Encontro: Data | Abrir | Alto | Baixo | Fechar | Ajustar Fechar | Volume |
| 02-01-1990 | 0,605903 | 0,616319 | 0,598090 | 0,616319 | 0,447268 | 53033600 |
| 1990-01-03 | 0,621528 | 0,626736 | 0,614583 | 0,619792 | 0,449788 | 113772800 |
| 1990-01-04 | 0,619792 | 0,638889 | 0,616319 | 0,638021 | 0,463017 | 125740800 |
| 1990-01-05 | 0,635417 | 0,638889 | 0,621528 | 0,622396 | 0,451678 | 69564800 |
| 08-01-1990 | 0,621528 | 0,631944 | 0,614583 | 0,631944 | 0,458607 | 58982400 |
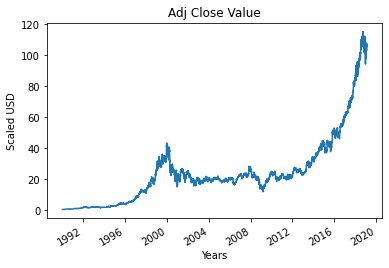
Etapa 4 - Plotando o valor de fechamento ajustado verdadeiro
O valor de saída final que deve ser previsto usando o modelo de aprendizado de máquina é o valor de fechamento ajustado. Este valor representa o valor de fechamento da ação naquele dia específico de negociação no mercado de ações.
#Plot o valor True Adj Close
df['Adj Close'].plot()
Etapa 5 – Definindo a variável de destino e selecionando os recursos
Na próxima etapa, atribuímos a coluna de saída à variável de destino. Nesse caso, é o valor relativo ajustado do Microsoft Stock. Além disso, também selecionamos as características que atuam como variável independente para a variável alvo (variável dependente). Para dar conta do propósito de treinamento, escolhemos quatro características, que são:

- Abrir
- Alto
- Baixo
- Volume
#Definir variável de destino
output_var = PD.DataFrame(df['Adj Close'])
#Selecionando os recursos
features = ['Abrir', 'Alto', 'Baixo', 'Volume']
Passo 6 – Dimensionamento
Para reduzir o custo computacional dos dados na tabela, reduziremos os valores de estoque para valores entre 0 e 1. Desta forma, todos os dados em grandes números são reduzidos, reduzindo assim o uso de memória. Além disso, podemos obter mais precisão reduzindo a escala, pois os dados não são espalhados em valores tremendos. Isso é realizado pela classe MinMaxScaler da biblioteca sci-kit-learn.
#Scaling
escalar = MinMaxScaler()
feature_transform = scaler.fit_transform(df[recursos])
feature_transform= pd.DataFrame(columns=features, data=feature_transform, index=df.index)
feature_transform.head()
| Encontro: Data | Abrir | Alto | Baixo | Volume |
| 02-01-1990 | 0,000129 | 0,000105 | 0,000129 | 0,064837 |
| 1990-01-03 | 0,000265 | 0,000195 | 0,000273 | 0,144673 |
| 1990-01-04 | 0,000249 | 0,000300 | 0,000288 | 0,160404 |
| 1990-01-05 | 0,000386 | 0,000300 | 0,000334 | 0,086566 |
| 08-01-1990 | 0,000265 | 0,000240 | 0,000273 | 0,072656 |
Como mencionado acima, vemos que os valores das variáveis de recurso são reduzidos para valores menores em comparação com os valores reais fornecidos acima.
Passo 7 – Dividindo para um conjunto de treinamento e um conjunto de teste.
Antes de alimentar os dados no modelo de treinamento, precisamos dividir todo o conjunto de dados em treinamento e conjunto de teste. O modelo LSTM de aprendizado de máquina será treinado nos dados presentes no conjunto de treinamento e testado no conjunto de teste para precisão e retropropagação.
Para isso, usaremos a classe TimeSeriesSplit da biblioteca sci-kit-learn. Definimos o número de divisões como 10, o que denota que 10% dos dados serão usados como conjunto de teste e 90% dos dados serão usados para treinar o modelo LSTM. A vantagem de usar essa divisão de séries temporais é que as amostras de dados de séries temporais divididas são observadas em intervalos de tempo fixos.
#Splitting para conjunto de treinamento e conjunto de teste
timesplit= TimeSeriesSplit(n_splits=10)
para train_index, test_index em timesplit.split(feature_transform):
X_train, X_test = feature_transform[:len(train_index)], feature_transform[len(train_index): (len(train_index)+len(test_index))]
y_train, y_test = output_var[:len(train_index)].values.ravel(), output_var[len(train_index): (len(train_index)+len(test_index))].values.ravel()
Etapa 8 – Processando os dados para LSTM
Assim que os conjuntos de treinamento e teste estiverem prontos, podemos alimentar os dados no modelo LSTM assim que ele for construído. Antes disso, precisamos converter os dados do conjunto de treinamento e teste em um tipo de dados que o modelo LSTM aceitará. Primeiro convertemos os dados de treinamento e os dados de teste em matrizes NumPy e, em seguida, os remodelamos para o formato (Número de Amostras, 1, Número de Recursos), pois o LSTM exige que os dados sejam alimentados no formato 3D. Como sabemos, o número de amostras no conjunto de treinamento é 90% de 7334, que é 6667, e o número de recursos é 4, o conjunto de treinamento é reformulado para (6667, 1, 4). Da mesma forma, o conjunto de teste também é reformulado.
#Processar os dados para LSTM
trainX =np.array(X_train)
testeX =np.array(X_test)
X_train = trainX.reshape(X_train.shape[0], 1, X_train.shape[1])
X_test = testX.reshape(X_test.shape[0], 1, X_test.shape[1])
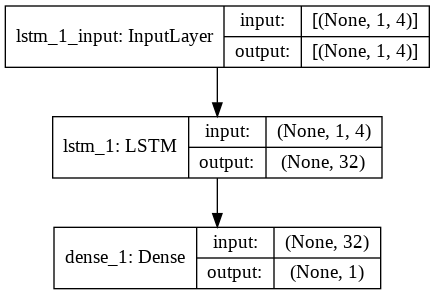
Passo 9 – Construindo o Modelo LSTM
Finalmente, chegamos ao estágio em que construímos o Modelo LSTM. Aqui, criamos um modelo Sequential Keras com uma camada LSTM. A camada LSTM tem 32 unidades e é seguida por uma camada Densa de 1 neurônio.
Usamos o Adam Optimizer e o Mean Squared Error como a função de perda para compilar o modelo. Esses dois são a combinação mais preferida para um modelo LSTM. Além disso, o modelo também é plotado e é exibido abaixo.
#Construindo o modelo LSTM
lstm = Sequencial()
lstm.add(LSTM(32, input_shape=(1, trainX.shape[1]), ativação='relu', return_sequences=False))
lstm.add(Dense(1))
lstm.compile(loss='mean_squared_error', otimizador='adam')
plot_model(lstm, show_shapes=True, show_layer_names=True)
Passo 10 – Treinando o Modelo
Finalmente, treinamos o modelo LSTM projetado acima nos dados de treinamento para 100 épocas com um tamanho de lote de 8 usando a função de ajuste.
#Treinamento de modelos
history = lstm.fit(X_train, y_train, epochs=100, batch_size=8, verbose=1, shuffle=False)
Época 1/100
834/834 [==============================] – 3s 2ms/passo – perda: 67,1211
Época 2/100
834/834 [==============================] – 1s 2ms/passo – perda: 70.4911
Época 3/100
834/834 [==============================] – 1s 2ms/passo – perda: 48.8155
Época 4/100
834/834 [==============================] – 1s 2ms/passo – perda: 21,5447
Época 5/100
834/834 [==============================] – 1s 2ms/passo – perda: 6,1709
Época 6/100
834/834 [==============================] – 1s 2ms/passo – perda: 1,8726
Época 7/100
834/834 [==============================] – 1s 2ms/passo – perda: 0,9380
Época 8/100
834/834 [==============================] – 2s 2ms/passo – perda: 0,6566
Época 9/100
834/834 [==============================] – 1s 2ms/passo – perda: 0,5369
Época 10/100
834/834 [==============================] – 2s 2ms/passo – perda: 0,4761
.
.
.
.
Época 95/100
834/834 [==============================] – 1s 2ms/passo – perda: 0,4542
Época 96/100
834/834 [==============================] – 2s 2ms/passo – perda: 0,4553
Época 97/100
834/834 [==============================] – 1s 2ms/passo – perda: 0,4565
Época 98/100
834/834 [==============================] – 1s 2ms/passo – perda: 0,4576
Época 99/100
834/834 [==============================] – 1s 2ms/passo – perda: 0,4588
Época 100/100
834/834 [==============================] – 1s 2ms/passo – perda: 0,4599
Por fim, vemos que o valor da perda diminuiu exponencialmente ao longo do tempo durante o processo de treinamento de 100 épocas e atingiu um valor de 0,4599
Etapa 11 - Previsão LSTM
Com nosso modelo pronto, é hora de usar o modelo treinado usando a rede LSTM no conjunto de teste e prever o Valor de fechamento adjacente da ação da Microsoft. Isso é realizado usando a função simples de previsão no modelo lstm construído.
#LSTM Previsão
y_pred= lstm.predict(X_test)
Etapa 12 - Valor de fechamento ajustado real vs previsto - LSTM
Finalmente, como previmos os valores do conjunto de teste, podemos traçar o gráfico para comparar os valores verdadeiros de Adj Close e o valor previsto de Adj Close pelo modelo LSTM Machine Learning.
#True vs Predicted Adj Close Value – LSTM
plt.plot(y_test, label='True Value')
plt.plot(y_pred, label='Valor LSTM')
plt.title(“Previsão por LSTM”)
plt.xlabel('Escala de Tempo')
plt.ylabel('Escalado em USD')
plt.legend()
plt.show()
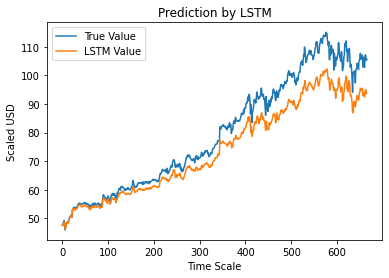
O gráfico acima mostra que algum padrão é detectado pelo modelo de rede LSTM simples muito básico construído acima. Ao ajustar vários parâmetros e adicionar mais camadas LSTM ao modelo, podemos obter uma representação mais precisa do valor das ações de qualquer empresa.
Conclusão
Se você estiver interessado em saber mais sobre exemplos de inteligência artificial, aprendizado de máquina, confira o Programa PG Executivo do IIIT-B & upGrad em Machine Learning e IA , projetado para profissionais que trabalham e oferece mais de 450 horas de treinamento rigoroso, mais de 30 estudos de caso e atribuições, status de ex-alunos do IIIT-B, mais de 5 projetos práticos práticos e assistência de trabalho com as principais empresas.
Você pode prever o mercado de ações usando aprendizado de máquina?
Hoje, temos uma série de indicadores para ajudar a prever as tendências do mercado. No entanto, não precisamos procurar além de um computador de alta potência para encontrar os indicadores mais precisos para o mercado de ações. O mercado de ações é um sistema aberto e pode ser visto como uma rede complexa. A rede é composta pelas relações entre as ações, empresas, investidores e volumes de negócios. Ao usar um algoritmo de mineração de dados como a máquina de vetores de suporte, você pode aplicar uma fórmula matemática para extrair as relações entre essas variáveis. O mercado de ações está agora além da previsão humana.
Qual algoritmo é melhor para previsão do mercado de ações?
Para melhores resultados, você deve usar a Regressão Linear. A Regressão Linear é uma abordagem estatística que é usada para determinar a relação entre duas variáveis diferentes. Neste exemplo, as variáveis são preço e tempo. Na previsão do mercado de ações, o preço é a variável independente e o tempo é a variável dependente. Se uma relação linear entre essas duas variáveis puder ser determinada, é possível prever com precisão o valor da ação em qualquer ponto no futuro.
A previsão do mercado de ações é um problema de classificação ou regressão?
Antes de responder, precisamos entender o que significam as previsões do mercado de ações. É um problema de classificação binária ou um problema de regressão? Suponha que queremos prever o futuro de uma ação, onde futuro significa o próximo dia, semana, mês ou ano. Se o desempenho passado da ação em algum momento é a entrada e o futuro é a saída, então é um problema de regressão. Se o desempenho passado de uma ação e o futuro de uma ação são independentes, então é um problema de classificação.