
Usando SSE em vez de WebSockets para fluxo de dados unidirecional sobre HTTP/2
Publicados: 2022-03-10Ao construir um aplicativo da web, deve-se considerar que tipo de mecanismo de entrega eles usarão. Digamos que temos um aplicativo multiplataforma que funciona com dados em tempo real; um aplicativo do mercado de ações que oferece a capacidade de comprar ou vender ações em tempo real. Este aplicativo é composto por widgets que trazem valor diferenciado para os diferentes usuários.
Quando se trata de entrega de dados do servidor para o cliente, estamos limitados a duas abordagens gerais: pull do cliente ou push do servidor . Como um exemplo simples com qualquer aplicativo da web, o cliente é o navegador da web. Quando o site em seu navegador está solicitando dados ao servidor, isso é chamado de cliente pull . O inverso, quando o servidor está enviando atualizações proativamente para o seu site, é chamado de push do servidor .
Atualmente, existem algumas maneiras de implementá-los:
- Sondagem longa/curta (pull do cliente)
- WebSockets (push do servidor)
- Eventos enviados pelo servidor (push do servidor).
Analisaremos detalhadamente as três alternativas depois de definirmos os requisitos para nosso caso de negócios.
O Caso de Negócios
Para poder entregar rapidamente novos widgets para nosso aplicativo de mercado de ações e plug'n'play sem reimplantação de toda a plataforma, precisamos que eles sejam autocontidos e gerenciem suas próprias E/S de dados. Os widgets não são acoplados entre si de forma alguma. No caso ideal, todos eles vão se inscrever em algum endpoint de API e começar a obter dados dele. Além de um tempo de lançamento de novos recursos mais rápido, essa abordagem nos dá a capacidade de exportar conteúdo para sites de terceiros, enquanto nossos widgets trazem tudo o que precisam por conta própria.
A principal armadilha aqui é que o número de conexões crescerá linearmente com o número de widgets que temos e atingiremos o limite dos navegadores para o número de solicitações HTTP tratadas de uma só vez.
Os dados que nossos widgets vão receber são compostos principalmente de números e atualizações de seus números: A resposta inicial contém dez ações com alguns valores de mercado para elas. Isso inclui atualizações de adição/remoção de estoques e atualizações dos valores de mercado dos atualmente apresentados. Transferimos pequenas quantidades de strings JSON para cada atualização o mais rápido possível.
O HTTP/2 fornece multiplexação das solicitações provenientes do mesmo domínio, o que significa que podemos obter apenas uma conexão para várias respostas. Parece que isso pode resolver nosso problema. Começamos explorando as diferentes opções para obter os dados e ver o que podemos obter deles.
- Usaremos o NGINX para balanceamento de carga e proxy para ocultar todos os nossos endpoints no mesmo domínio. Isso nos permitirá usar a multiplexação HTTP/2 pronta para uso.
- Queremos usar a rede e a bateria dos dispositivos móveis com eficiência.
As alternativas
Sondagem longa

A atração do cliente é o equivalente de implementação de software da criança irritante sentada no banco de trás do seu carro perguntando constantemente: “Já chegamos?” Em suma, o cliente solicita dados ao servidor. O servidor não possui dados e aguarda algum tempo antes de enviar a resposta:
- Se algo aparecer durante a espera, o servidor envia e fecha a solicitação;
- Se não houver nada para enviar e o tempo máximo de espera for atingido, o servidor envia uma resposta informando que não há dados;
- Em ambos os casos, o cliente abre a próxima solicitação de dados;
- Ensaboe, enxágue, repita.
As chamadas AJAX funcionam no protocolo HTTP, o que significa que as solicitações para o mesmo domínio devem ser multiplexadas por padrão. No entanto, encontramos vários problemas ao tentar fazer isso funcionar conforme necessário. Algumas das armadilhas que identificamos com nossa abordagem de widgets:
Sobrecarga de cabeçalhos
Cada solicitação e resposta de pesquisa é uma mensagem HTTP completa e contém um conjunto completo de cabeçalhos HTTP no enquadramento da mensagem. No nosso caso onde temos pequenas mensagens frequentes, os cabeçalhos representam na verdade a maior porcentagem dos dados transmitidos. A carga útil real é muito menor que o total de bytes transmitidos (por exemplo, 15 KB de cabeçalhos para 5 KB de dados).Latência máxima
Depois que o servidor responde, ele não pode mais enviar dados ao cliente até que o cliente envie a próxima solicitação. Enquanto a latência média para sondagem longa é próxima a um trânsito de rede, a latência máxima é superior a três trânsitos de rede: resposta, solicitação, resposta. No entanto, devido à perda e retransmissão de pacotes, a latência máxima para qualquer protocolo TCP/IP será de mais de três trânsitos de rede (evitáveis com o pipelining HTTP). Embora na conexão LAN direta isso não seja um grande problema, torna-se um enquanto a pessoa está em movimento e alternando as células da rede. Até certo ponto, isso é observado com SSE e WebSockets, mas o efeito é maior com o polling.Estabelecimento de conexão
Embora isso possa ser evitado usando uma conexão HTTP persistente reutilizável para muitas solicitações de pesquisa, é complicado cronometrar adequadamente todos os seus componentes para pesquisar em durações curtas para manter a conexão ativa. Eventualmente, dependendo das respostas do servidor, suas pesquisas serão dessincronizadas.Degradação de desempenho
Um cliente (ou servidor) de sondagem longo que está sob carga tem uma tendência natural de diminuir o desempenho ao custo da latência da mensagem. Quando isso acontecer, os eventos que são enviados para o cliente serão enfileirados. Isso realmente depende da implementação; no nosso caso, precisamos agregar todos os dados enquanto estamos enviando eventos add/remove/update para nossos widgets.Tempos limite
Solicitações de sondagem longas precisam permanecer pendentes até que o servidor tenha algo para enviar ao cliente. Isso pode fazer com que a conexão seja fechada pelo servidor proxy se permanecer inativa por muito tempo.Multiplexação
Isso pode acontecer se as respostas ocorrerem ao mesmo tempo em uma conexão HTTP/2 persistente. Isso pode ser complicado de fazer, pois as respostas das pesquisas não podem estar realmente sincronizadas.
Mais sobre questões do mundo real que podem ser encontradas com pesquisas longas podem ser encontradas aqui .
WebSockets

Como um primeiro exemplo do método push do servidor , veremos os WebSockets.
Por MDN:
WebSockets é uma tecnologia avançada que possibilita a abertura de uma sessão de comunicação interativa entre o navegador do usuário e um servidor. Com essa API, você pode enviar mensagens para um servidor e receber respostas orientadas a eventos sem precisar pesquisar uma resposta no servidor.
Este é um protocolo de comunicação que fornece canais de comunicação full-duplex em uma única conexão TCP.
Tanto o HTTP quanto o WebSockets estão localizados na camada de aplicação do modelo OSI e, como tal, dependem do TCP na camada 4.
- Inscrição
- Apresentação
- Sessão
- Transporte
- Rede
- Link de dados
- Físico
A RFC 6455 afirma que o WebSocket "foi projetado para funcionar nas portas HTTP 80 e 443, bem como para suportar proxies e intermediários HTTP", tornando-o compatível com o protocolo HTTP. Para obter compatibilidade, o handshake WebSocket usa o cabeçalho HTTP Upgrade para mudar do protocolo HTTP para o protocolo WebSocket.
Há também um artigo muito bom que explica tudo o que você precisa saber sobre WebSockets na Wikipedia. Eu o encorajo a ler isso.
Depois de estabelecer que os soquetes poderiam realmente funcionar para nós, começamos a explorar seus recursos em nosso caso de negócios e atingimos parede após parede.
Servidores proxy : Em geral, existem alguns problemas diferentes com WebSockets e proxies:
- A primeira está relacionada aos provedores de serviços de Internet e à forma como eles lidam com suas redes. Problemas com portas bloqueadas por proxies de raio e assim por diante.
- O segundo tipo de problemas está relacionado à maneira como o proxy é configurado para lidar com o tráfego HTTP não seguro e as conexões de longa duração (o impacto é reduzido com HTTPS).
- O terceiro problema “com WebSockets, você é forçado a executar proxies TCP em vez de proxies HTTP. Os proxies TCP não podem injetar cabeçalhos, reescrever URLs ou desempenhar muitas das funções que tradicionalmente deixamos nossos proxies HTTP cuidarem.”
Um número de conexões : O famoso limite de conexão para solicitações HTTP que gira em torno do número 6, não se aplica a WebSockets. 50 soquetes = 50 conexões. Dez abas do navegador por 50 soquetes = 500 conexões e assim por diante. Como o WebSocket é um protocolo diferente para entrega de dados, ele não é multiplexado automaticamente em conexões HTTP/2 (ele realmente não é executado em cima do HTTP). A implementação de multiplexação personalizada no servidor e no cliente é muito complicada para tornar os soquetes úteis no caso de negócios especificado. Além disso, isso acopla nossos widgets à nossa plataforma, pois eles precisarão de algum tipo de API no cliente para se inscrever e não podemos distribuí-los sem ela.
Balanceamento de carga (sem multiplexação) : Se cada usuário abrir um número
nde soquetes, o balanceamento de carga adequado é muito complicado. Quando seus servidores ficam sobrecarregados e você precisa criar novas instâncias e encerrar as antigas, dependendo da implementação do seu software, as ações que são tomadas na “reconexão” podem desencadear uma enorme cadeia de atualizações e novas solicitações de dados que sobrecarregarão seu sistema . Os WebSockets precisam ser mantidos no servidor e no cliente. Não é possível mover conexões de soquete para um servidor diferente se o atual apresentar alta carga. Eles devem ser fechados e reabertos.DoS : Isso geralmente é tratado por proxies HTTP front-end que não podem ser tratados por proxies TCP que são necessários para os WebSockets. Pode-se conectar ao soquete e começar a inundar seus servidores com dados. Os WebSockets deixam você vulnerável a esse tipo de ataque.
Reinventando a roda : Com WebSockets, é preciso lidar com muitos problemas que são resolvidos no HTTP por conta própria.
Mais sobre problemas do mundo real com WebSockets podem ser lidos aqui.
Alguns bons casos de uso para WebSockets são bate-papos e jogos para vários jogadores nos quais os benefícios superam os problemas de implementação. Com seu principal benefício sendo a comunicação duplex, e nós realmente não precisando disso, precisamos seguir em frente.
Impacto
Obtemos maior sobrecarga operacional em termos de desenvolvimento, teste e dimensionamento; o software e sua infraestrutura de TI com ambos: polling e WebSockets.
Temos o mesmo problema em dispositivos móveis e redes com ambos. O design de hardware desses dispositivos mantém uma conexão aberta, mantendo a antena e a conexão com a rede celular ativa. Isso leva à redução da vida útil da bateria, calor e, em alguns casos, cobranças extras pelos dados.
Mas por que ainda temos problemas com dispositivos móveis?
Vamos considerar como o dispositivo móvel padrão se conecta à Internet:
Uma explicação direta de como a rede móvel funciona: Normalmente, os dispositivos móveis têm uma antena de baixa potência que pode receber dados de uma célula. Dessa forma, uma vez que o dispositivo recebe os dados de uma chamada recebida, ele inicializa a antena full-duplex para estabelecer a chamada. A mesma antena é usada sempre que você deseja fazer uma chamada ou acessar a Internet (se não houver WiFi disponível). A antena full-duplex precisa estabelecer uma conexão com a rede celular e fazer alguma autenticação. Uma vez que a conexão é estabelecida, há alguma comunicação entre seu dispositivo e o celular para fazer nossa solicitação de rede. Somos redirecionados para o proxy interno do provedor de serviços móveis que trata das solicitações da Internet. A partir daí, o procedimento já é conhecido: ele pergunta a um DNS onde realmente está www.domainname.ext , recebendo o URI para o recurso e, eventualmente, sendo redirecionado para ele.
Esse processo, como você pode imaginar, consome bastante bateria. Esta é a razão pela qual os fornecedores de telefones celulares oferecem um tempo de espera de alguns dias e tempo de conversação em apenas algumas horas.
Sem WiFi, tanto o WebSockets quanto o polling exigem que a antena full-duplex funcione quase constantemente. Assim, enfrentamos um maior consumo de dados e maior consumo de energia – e dependendo do dispositivo – calor também.

Quando as coisas parecerem sombrias, parece que teremos que reconsiderar os requisitos de negócios para nosso aplicativo. Estamos perdendo alguma coisa?
SSE
Por MDN:
“A interface EventSource é usada para receber eventos enviados pelo servidor. Ele se conecta a um servidor via HTTP e recebe eventos em formato de fluxo de texto/evento sem fechar a conexão.”
A principal diferença para a pesquisa é que obtemos apenas uma conexão e mantemos um fluxo de eventos passando por ela. Long polling cria uma nova conexão para cada pull - ergo a sobrecarga de cabeçalhos e outros problemas que enfrentamos lá.
Via html5doctor.com:
Eventos enviados pelo servidor são eventos em tempo real emitidos pelo servidor e recebidos pelo navegador. Eles são semelhantes aos WebSockets, pois acontecem em tempo real, mas são um método de comunicação unidirecional do servidor.
Parece meio estranho, mas após consideração - nosso principal fluxo de dados é do servidor para o cliente e em muito menos ocasiões do cliente para o servidor.
Parece que podemos usar isso para nosso principal caso de negócios de entrega de dados. Podemos resolver as compras do cliente enviando uma nova solicitação, pois o protocolo é unidirecional e o cliente não pode enviar mensagens para o servidor através dele. Isso eventualmente terá o atraso de tempo da antena full-duplex para inicializar em dispositivos móveis. No entanto, podemos viver com isso acontecendo de tempos em tempos – afinal, esse atraso é medido em milissegundos.
Características únicas
- O fluxo de conexão vem do servidor e é somente leitura.
- Eles usam solicitações HTTP regulares para a conexão persistente, não um protocolo especial. Obtendo multiplexação sobre HTTP/2 fora da caixa.
- Se a conexão cair, o EventSource acionará um evento de erro e tentará se reconectar automaticamente. O servidor também pode controlar o tempo limite antes que o cliente tente se reconectar (explicado com mais detalhes posteriormente).
- Os clientes podem enviar um ID exclusivo com mensagens. Quando um cliente tenta se reconectar após uma queda de conexão, ele enviará o último ID conhecido. Em seguida, o servidor pode ver que o cliente perdeu
nnúmero de mensagens e enviar a lista de pendências de mensagens perdidas na reconexão.
Exemplo de implementação do cliente
Esses eventos são semelhantes aos eventos JavaScript comuns que ocorrem no navegador — como eventos de clique — exceto que podemos controlar o nome do evento e os dados associados a ele.
Vamos ver a visualização de código simples para o lado do cliente:
// subscribe for messages var source = new EventSource('URL'); // handle messages source.onmessage = function(event) { // Do something with the data: event.data; };O que vemos no exemplo é que o lado do cliente é bastante simples. Ele se conecta à nossa fonte e espera receber mensagens.
Para permitir que os servidores enviem dados para páginas da Web por HTTP ou usando protocolos de envio de servidor dedicados, a especificação introduz a interface `EventSource` no cliente. O uso desta API consiste em criar um objeto `EventSource` e registrar um ouvinte de eventos.
A implementação do cliente para WebSockets é muito semelhante a isso. A complexidade com sockets está na infraestrutura de TI e na implementação do servidor.
Origem do evento
Cada objeto EventSource tem os seguintes membros:
- URL: definido durante a construção.
- Pedido: inicialmente é nulo.
- Tempo de reconexão: valor em ms (valor definido pelo agente do usuário).
- ID do último evento: inicialmente uma string vazia.
- Estado pronto: estado da conexão.
- CONECTANDO (0)
- ABERTO (1)
- FECHADO (2)
Além do URL, todos são tratados como privados e não podem ser acessados de fora.
Eventos integrados:
- Abrir
- Mensagem
- Erro
Lidando com quedas de conexão
A conexão é restabelecida automaticamente pelo navegador se cair. O servidor pode enviar tempo limite para tentar novamente ou fechar a conexão permanentemente. Nesse caso, o navegador cumprirá a tentativa de reconectar após o tempo limite ou não tentar se a conexão receber uma mensagem de encerramento. Parece bastante simples – e realmente é.
Exemplo de implementação de servidor
Bem, se o cliente é tão simples, talvez a implementação do servidor seja complexa?
Bem, o manipulador do servidor para SSE pode ser assim:
function handler(response) { // setup headers for the response in order to get the persistent HTTP connection response.writeHead(200, { 'Content-Type': 'text/event-stream', 'Cache-Control': 'no-cache', 'Connection': 'keep-alive' }); // compose the message response.write('id: UniqueID\n'); response.write("data: " + data + '\n\n'); // whenever you send two new line characters the message is sent automatically }Definimos uma função que vai lidar com a resposta:
- Cabeçalhos de configuração
- Criar mensagem
- Mandar
Observe que você não vê uma chamada de método send() ou push() . Isso porque o padrão define que a mensagem será enviada assim que receber dois caracteres \n\n como no exemplo: response.write("data: " + data + '\n\n'); . Isso enviará imediatamente a mensagem para o cliente. Observe que os data devem ser uma string com escape e não ter novos caracteres de linha no final.
Construção da mensagem
Conforme mencionado anteriormente, a mensagem pode conter algumas propriedades:
- identificação
Se o valor do campo não contiver U+0000 NULL, defina o último buffer de ID do evento para o valor do campo. Caso contrário, ignore o campo. - Dados
Anexe o valor do campo ao buffer de dados e, em seguida, anexe um único caractere U+000A LINE FEED (LF) ao buffer de dados. - Evento
Defina o buffer do tipo de evento para o valor do campo. Isso faz com queevent.typeobtenha seu nome de evento personalizado. - Repetir
Se o valor do campo consistir apenas em dígitos ASCII, interprete o valor do campo como um inteiro na base dez e defina o tempo de reconexão do fluxo de eventos para esse inteiro. Caso contrário, ignore o campo.
Qualquer outra coisa será ignorada. Não podemos introduzir nossos próprios campos.
Exemplo com event adicionado:
response.write('id: UniqueID\n'); response.write('event: add\n'); response.write('retry: 10000\n'); response.write("data: " + data + '\n\n'); Em seguida, no cliente, isso é tratado com addEventListener como tal:
source.addEventListener("add", function(event) { // do stuff with data event.data; });Você pode enviar várias mensagens separadas por uma nova linha, desde que forneça IDs diferentes.
... id: 54 event: add data: "[{SOME JSON DATA}]" id: 55 event: remove data: JSON.stringify(some_data) id: 56 event: remove data: { data: "msg" : "JSON data"\n data: "field": "value"\n data: "field2": "value2"\n data: }\n\n ...Isso simplifica muito o que podemos fazer com nossos dados.
Requisitos Específicos do Servidor
Durante nosso POC para o back-end, identificamos algumas especificidades que precisam ser abordadas para ter uma implementação funcional do SSE. Na melhor das hipóteses, você usará um servidor baseado em loop de eventos, como NodeJS, Kestrel ou Twisted. A ideia é que com a solução baseada em thread você terá um thread por conexão → 1000 conexões = 1000 threads. Com a solução de loop de eventos, você terá um thread para 1.000 conexões.
- Você só pode aceitar solicitações EventSource se a solicitação HTTP disser que pode aceitar o tipo MIME de fluxo de eventos;
- Você precisa manter uma lista de todos os usuários conectados para poder emitir novos eventos;
- Você deve escutar conexões perdidas e removê-las da lista de usuários conectados;
- Opcionalmente, você deve manter um histórico de mensagens para que os clientes reconectados possam acompanhar as mensagens perdidas.
Funciona como esperado e parece mágica no início. Conseguimos tudo o que queremos para que nosso aplicativo funcione de maneira eficiente. Tal como acontece com todas as coisas que parecem boas demais para ser verdade, às vezes enfrentamos alguns problemas que precisam ser resolvidos. No entanto, eles não são complicados de implementar ou contornar:
Servidores proxy legados são conhecidos por, em certos casos, descartar conexões HTTP após um curto tempo limite. Para proteger contra esses servidores proxy, os autores podem incluir uma linha de comentário (uma começando com um caractere ':') a cada 15 segundos ou mais.
Os autores que desejam relacionar conexões de origem de eventos entre si ou com documentos específicos fornecidos anteriormente podem descobrir que confiar em endereços IP não funciona, pois clientes individuais podem ter vários endereços IP (devido a vários servidores proxy) e endereços IP individuais podem ter vários clientes (devido ao compartilhamento de um servidor proxy). É melhor incluir um identificador exclusivo no documento quando ele for servido e, em seguida, passar esse identificador como parte da URL quando a conexão for estabelecida.
Os autores também são advertidos de que o agrupamento HTTP pode ter efeitos negativos inesperados na confiabilidade desse protocolo, em particular, se o agrupamento for feito por uma camada diferente que desconheça os requisitos de tempo. Se isso for um problema, o agrupamento pode ser desabilitado para veicular fluxos de eventos.
Os clientes que suportam a limitação de conexão por servidor do HTTP podem ter problemas ao abrir várias páginas de um site se cada página tiver um EventSource para o mesmo domínio. Os autores podem evitar isso usando o mecanismo relativamente complexo de usar nomes de domínio exclusivos por conexão ou permitindo que o usuário habilite ou desabilite a funcionalidade EventSource por página ou compartilhando um único objeto EventSource usando um trabalhador compartilhado.
Suporte ao navegador e Polyfills: o Edge está atrasado em relação a essa implementação, mas está disponível um polyfill que pode salvá-lo. No entanto, o caso mais importante para SSE é feito para dispositivos móveis onde o IE/Edge não tem participação de mercado viável.
Alguns dos polyfills disponíveis:
- Yaffle
- amvtek
- remy
Push sem conexão e outros recursos
Agentes de usuário executados em ambientes controlados, por exemplo, navegadores em telefones celulares vinculados a operadoras específicas, podem descarregar o gerenciamento da conexão para um proxy na rede. Em tal situação, o agente do usuário para fins de conformidade é considerado como incluindo o software do aparelho e o proxy de rede.
Por exemplo, um navegador em um dispositivo móvel, depois de estabelecer uma conexão, pode detectar que está em uma rede de suporte e solicitar que um servidor proxy na rede assuma o gerenciamento da conexão. O cronograma para tal situação pode ser o seguinte:
- O navegador se conecta a um servidor HTTP remoto e solicita o recurso especificado pelo autor no construtor EventSource.
- O servidor envia mensagens ocasionais.
- Entre duas mensagens, o navegador detecta que está ocioso, exceto pela atividade de rede envolvida em manter a conexão TCP ativa, e decide alternar para o modo de suspensão para economizar energia.
- O navegador se desconecta do servidor.
- O navegador entra em contato com um serviço na rede e solicita que o serviço, um “push proxy”, mantenha a conexão.
- O serviço “push proxy” contata o servidor HTTP remoto e solicita o recurso especificado pelo autor no construtor EventSource (possivelmente incluindo um cabeçalho HTTP
Last-Event-ID, etc.). - O navegador permite que o dispositivo móvel entre no modo de suspensão.
- O servidor envia outra mensagem.
- O serviço “push proxy” usa uma tecnologia como o push OMA para transmitir o evento para o dispositivo móvel, que acorda apenas o suficiente para processar o evento e depois volta a dormir.
Isso pode reduzir o uso total de dados e, portanto, resultar em economias de energia consideráveis.
Além de implementar a API existente e o formato de fio de fluxo de texto/evento conforme definido pela especificação e de maneiras mais distribuídas (conforme descrito acima), os formatos de estrutura de eventos definidos por outras especificações aplicáveis podem ser suportados.
Resumo
Após POCs longos e exaustivos, incluindo implementações de servidor e cliente, parece que o SSE é a resposta para nossos problemas com a entrega de dados. Existem algumas armadilhas com isso também, mas elas provaram ser triviais de corrigir.
É assim que nossa configuração de produção se parece no final:
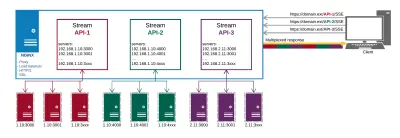
Obtemos o seguinte do NGINX:
- Proxy para endpoints de API em diferentes locais;
- HTTP/2 e todos os seus benefícios como multiplexação para as conexões;
- Balanceamento de carga;
- SSL.
Dessa forma, gerenciamos nossa entrega de dados e certificados em um só lugar, em vez de fazê-lo em cada endpoint separadamente.
Os principais benefícios que obtemos com essa abordagem são:
- Dados eficientes;
- Implementação mais simples;
- Ele é multiplexado automaticamente em HTTP/2;
- Limita o número de conexões para dados no cliente a um;
- Fornece um mecanismo para economizar a bateria descarregando a conexão para um proxy.
O SSE não é apenas uma alternativa viável aos outros métodos para fornecer atualizações rápidas; parece que está em uma liga própria quando se trata de otimizações para dispositivos móveis. Não há sobrecarga em sua implementação em comparação com as alternativas. Em termos de implementação do lado do servidor, não é muito diferente do polling. No cliente, é muito mais simples do que pesquisar, pois requer uma assinatura inicial e atribuição de manipuladores de eventos - muito semelhante à forma como os WebSockets são gerenciados.
Verifique a demonstração do código se quiser obter uma implementação cliente-servidor simples.
Recursos
- “Problemas conhecidos e práticas recomendadas para o uso de sondagens longas e streaming em HTTP bidirecional”, IETF (PDF)
- Recomendação W3C, W3C
- “O WebSocket sobreviverá ao HTTP/2?”, Allan Denis, InfoQ
- “Stream Updates with Server-Sent Events”, Eric Bidelman, HTML5 Rocks
- “Aplicativos de envio de dados com HTML5 SSE”, Darren Cook, O'Reilly Media