
Como melhoramos o desempenho do SmashingMag
Publicados: 2022-03-10Este artigo é gentilmente apoiado por nossos queridos amigos da Media Temple, que oferecem uma gama completa de soluções de hospedagem na web para designers, desenvolvedores e seus clientes. Obrigado, queridos amigos!

Toda história de desempenho na web é semelhante, não é? Sempre começa com a tão esperada reformulação do site. Um dia em que um projeto, totalmente polido e cuidadosamente otimizado, é lançado, com uma classificação alta e subindo acima das pontuações de desempenho no Lighthouse e no WebPageTest. Há uma celebração e um sentimento sincero de realização prevalecendo no ar – lindamente refletido em retuítes, comentários, boletins informativos e tópicos do Slack.
No entanto, com o passar do tempo, a empolgação desaparece lentamente e ajustes urgentes, recursos muito necessários e novos requisitos de negócios surgem. E de repente, antes que você perceba, a base de código fica um pouco acima do peso e fragmentada os scripts precisam ser carregados um pouco mais cedo, e o novo conteúdo dinâmico e brilhante chega ao DOM através dos backdoors de scripts de terceiros e seus convidados não convidados.
Nós estivemos lá no Smashing também. Poucas pessoas sabem, mas somos uma equipe muito pequena de cerca de 12 pessoas, muitas das quais trabalham meio período e a maioria geralmente usa muitos chapéus diferentes em um determinado dia. Embora o desempenho tenha sido nosso objetivo por quase uma década, nunca tivemos uma equipe de desempenho dedicada.
Após a última reformulação no final de 2017, foi Ilya Pukhalski no lado JavaScript das coisas (meio período), Michael Riethmueller no lado CSS das coisas (algumas horas por semana) e sinceramente, jogando jogos mentais com CSS crítico e tentando fazer malabarismos com algumas coisas demais.
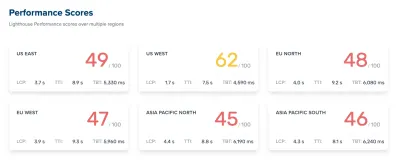
Como aconteceu, perdemos a noção do desempenho na correria do dia-a-dia. Estávamos projetando e construindo coisas, configurando novos produtos, refatorando os componentes e publicando artigos. Então, no final de 2020, as coisas ficaram um pouco fora de controle, com as pontuações do Lighthouse em vermelho-amarelado aparecendo lentamente em todo o quadro. Tivemos que consertar isso.
É Onde Estávamos
Alguns de vocês devem saber que estamos rodando no JAMStack, com todos os artigos e páginas armazenados como arquivos Markdown, arquivos Sass compilados em CSS, JavaScript dividido em partes com Webpack e Hugo construindo páginas estáticas que servimos diretamente de um Edge CDN. Em 2017, construímos o site inteiro com o Preact, mas depois mudamos para o React em 2019 – e o usamos junto com algumas APIs para pesquisa, comentários, autenticação e checkout.
Todo o site foi construído com aprimoramento progressivo em mente, o que significa que você, caro leitor, pode ler todos os artigos do Smashing na íntegra sem a necessidade de inicializar o aplicativo. Também não é muito surpreendente - no final, um artigo publicado não muda muito ao longo dos anos, enquanto peças dinâmicas, como autenticação de associação e check-out, precisam que o aplicativo seja executado.
Toda a compilação para implantar cerca de 2.500 artigos ao vivo leva cerca de 6 minutos no momento. O processo de construção por si só se tornou uma fera ao longo do tempo, com injeções de CSS críticas, divisão de código do Webpack, inserções dinâmicas de publicidade e painéis de recursos, (re)geração de RSS e eventuais testes A/B na borda.
No início de 2020, começamos com a grande refatoração dos componentes de layout CSS. Nós nunca usamos CSS-in-JS ou styled-components, mas sim um bom e velho sistema baseado em componentes de módulos Sass que seriam compilados em CSS. Em 2017, todo o layout foi construído com Flexbox e reconstruído com CSS Grid e CSS Custom Properties em meados de 2019. No entanto, algumas páginas necessitaram de tratamento especial devido a novos spots publicitários e novos painéis de produtos. Então, enquanto o layout estava funcionando, não estava funcionando muito bem, e era muito difícil de manter.
Além disso, o cabeçalho com a navegação principal teve que ser alterado para acomodar mais itens que queríamos exibir dinamicamente. Além disso, queríamos refatorar alguns componentes usados com frequência em todo o site, e o CSS usado lá também precisava de alguma revisão – a caixa do boletim informativo era o culpado mais notável. Começamos refatorando alguns componentes com CSS utilitário, mas nunca chegamos ao ponto em que ele foi usado de forma consistente em todo o site.
O maior problema era o grande pacote JavaScript que – não surpreendentemente – estava bloqueando o thread principal por centenas de milissegundos. Um grande pacote de JavaScript pode parecer deslocado em uma revista que apenas publica artigos, mas, na verdade, há muitos scripts acontecendo nos bastidores.
Temos vários estados de componentes para clientes autenticados e não autenticados. Depois de fazer login, queremos mostrar todos os produtos no preço final e, à medida que você adiciona um livro ao carrinho, queremos manter um carrinho acessível com um toque em um botão - não importa em que página você esteja. A publicidade precisa chegar rapidamente sem causar mudanças de layout disruptivas, e o mesmo vale para os painéis de produtos nativos que destacam nossos produtos. Além de um service worker que armazena em cache todos os ativos estáticos e os serve para visualizações repetidas, juntamente com versões em cache de artigos que um leitor já visitou.
Então, todo esse roteiro tinha que acontecer em algum momento, e estava esgotando a experiência de leitura, mesmo que o roteiro estivesse chegando muito tarde. Francamente, estávamos trabalhando meticulosamente no site e nos novos componentes sem ficar de olho no desempenho (e tínhamos algumas outras coisas em mente para 2020). A virada veio inesperadamente. Harry Roberts realizou seu (excelente) Web Performance Masterclass como um workshop on-line conosco e, durante todo o workshop, ele usou o Smashing como exemplo, destacando problemas que tínhamos e sugerindo soluções para esses problemas juntamente com ferramentas e diretrizes úteis.
Durante todo o workshop, eu estava diligentemente tomando notas e revisitando a base de código. Na época do workshop, nossas pontuações no Lighthouse eram de 60 a 68 na página inicial e em torno de 40 a 60 nas páginas de artigos — e obviamente piores no celular. Terminada a oficina, começamos a trabalhar.
Identificando os Gargalos
Muitas vezes, tendemos a confiar em pontuações específicas para entender o nosso desempenho, mas muitas vezes as pontuações únicas não fornecem uma imagem completa. Como David East observou eloquentemente em seu artigo, o desempenho na web não é um valor único; é uma distribuição. Mesmo que uma experiência na Web seja pesada e completamente um desempenho geral otimizado, ela não pode ser apenas rápida. Pode ser rápido para alguns visitantes, mas no final das contas também será mais lento (ou lento) para outros.
As razões para isso são inúmeras, mas a mais importante é uma enorme diferença nas condições da rede e no hardware do dispositivo em todo o mundo. Na maioria das vezes, não podemos realmente influenciar essas coisas, então temos que garantir que nossa experiência as acomode.
Em essência, nosso trabalho é aumentar a proporção de experiências rápidas e diminuir a proporção de experiências lentas. Mas para isso, precisamos ter uma imagem adequada do que a distribuição realmente é. Agora, ferramentas de análise e ferramentas de monitoramento de desempenho fornecerão esses dados quando necessário, mas analisamos especificamente o CrUX, o Relatório de experiência do usuário do Chrome. O CrUX gera uma visão geral das distribuições de desempenho ao longo do tempo, com o tráfego coletado dos usuários do Chrome. Muitos desses dados relacionados ao Core Web Vitals que o Google anunciou em 2020 e que também contribuem e são expostos no Lighthouse.
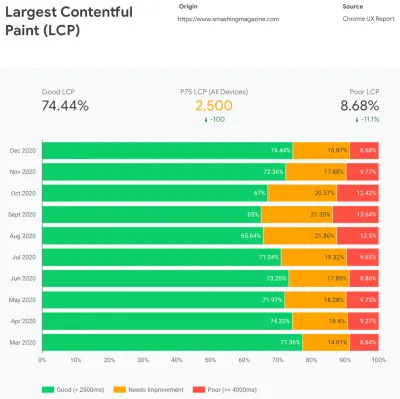
Percebemos que, em geral, nosso desempenho regrediu drasticamente ao longo do ano, com quedas específicas em agosto e setembro. Uma vez que vimos esses gráficos, poderíamos olhar para trás em alguns dos PRs que colocamos ao vivo naquela época para estudar o que realmente aconteceu.
Não demorou muito para descobrir que, por volta dessa época, lançamos uma nova barra de navegação ao vivo. Essa barra de navegação - usada em todas as páginas - dependia do JavaScript para exibir itens de navegação em um menu ao toque ou ao clicar, mas a parte JavaScript dela foi realmente empacotada dentro do pacote app.js. Para melhorar o Time To Interactive, decidimos extrair o script de navegação do pacote e servi-lo em linha.
Na mesma época, mudamos de um arquivo CSS crítico criado manualmente (desatualizado) para um sistema automatizado que gerava CSS crítico para cada modelo - página inicial, artigo, página de produto, evento, quadro de empregos e assim por diante - e CSS crítico embutido durante o tempo de construção. No entanto, não percebemos o quanto o CSS crítico gerado automaticamente era mais pesado. Tivemos que explorá-lo com mais detalhes.
E também na mesma época, estávamos ajustando o carregamento de fontes da web , tentando empurrar as fontes da web de forma mais agressiva com dicas de recursos, como pré-carregamento. No entanto, isso parece estar prejudicando nossos esforços de desempenho, pois as fontes da Web estavam atrasando a renderização do conteúdo, sendo priorizadas ao lado do arquivo CSS completo.
Agora, um dos motivos comuns para a regressão é o alto custo do JavaScript, então também analisamos o Webpack Bundle Analyzer e o mapa de solicitações de Simon Hearne para obter uma imagem visual de nossas dependências de JavaScript. Parecia bastante saudável no início.
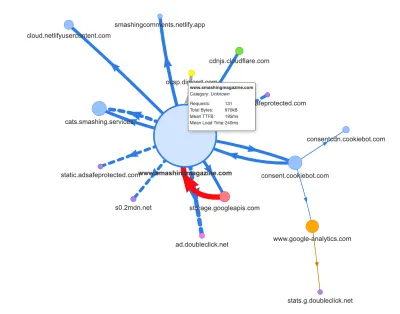
Algumas solicitações estavam chegando ao CDN, um serviço de consentimento de cookies Cookiebot, Google Analytics, além de nossos serviços internos para servir painéis de produtos e publicidade personalizada. Não parecia haver muitos gargalos – até que olhamos um pouco mais de perto.
No trabalho de desempenho, é comum observar o desempenho de algumas páginas críticas — provavelmente a página inicial e provavelmente algumas páginas de artigos/produtos. No entanto, embora haja apenas uma página inicial, pode haver várias páginas de produtos, portanto, precisamos escolher aquelas que representam nosso público.
Na verdade, como estamos publicando alguns artigos pesados de código e design no SmashingMag, ao longo dos anos acumulamos literalmente milhares de artigos que continham GIFs pesados, trechos de código com destaque de sintaxe, incorporações de CodePen, vídeo/áudio incorpora e encadeamentos aninhados de comentários sem fim.
Quando reunidos, muitos deles estavam causando nada menos que uma explosão no tamanho do DOM, juntamente com o trabalho excessivo do thread principal – diminuindo a experiência em milhares de páginas. Sem mencionar que, com a publicidade em vigor, alguns elementos DOM foram injetados no final do ciclo de vida da página, causando uma cascata de recálculos e repinturas de estilo - também tarefas caras que podem produzir tarefas longas.
Tudo isso não estava aparecendo no mapa que geramos para uma página de artigo bastante leve no gráfico acima. Então, escolhemos as páginas mais pesadas que tínhamos – a homepage poderosa, a mais longa, aquela com muitas incorporações de vídeo e aquela com muitas incorporações do CodePen – e decidimos otimizá-las o máximo possível. Afinal, se forem rápidas, as páginas com uma única incorporação do CodePen também devem ser mais rápidas.
Com essas páginas em mente, o mapa parecia um pouco diferente. Observe a enorme linha grossa indo para o player do Vimeo e o CDN do Vimeo, com 78 solicitações provenientes de um artigo do Smashing.
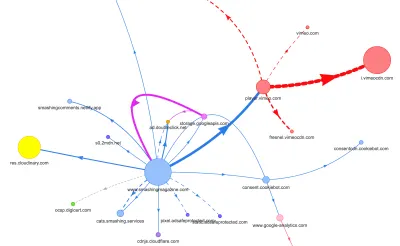
Para estudar o impacto no encadeamento principal, nos aprofundamos no painel Desempenho no DevTools. Mais especificamente, estávamos procurando tarefas que durassem mais de 50ms (destacadas com um retângulo vermelho no canto superior direito) e tarefas que continham estilos de recálculo (barra roxa). O primeiro indicaria execução cara de JavaScript, enquanto o último exporia invalidações de estilo causadas por injeções dinâmicas de conteúdo no DOM e CSS abaixo do ideal. Isso nos deu alguns indicadores acionáveis de por onde começar. Por exemplo, descobrimos rapidamente que nosso carregamento de fonte da web tinha um custo significativo de repintura, enquanto os fragmentos de JavaScript ainda eram pesados o suficiente para bloquear o encadeamento principal.
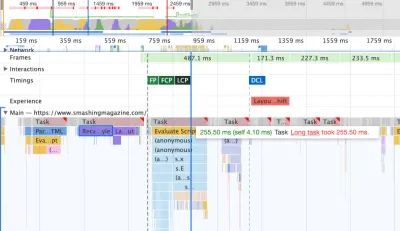
Como linha de base, analisamos atentamente os Core Web Vitals, tentando garantir que estamos pontuando bem em todos eles. Escolhemos focar especificamente em dispositivos móveis lentos — com 3G lento, RTT de 400 ms e velocidade de transferência de 400 kbps, apenas para ficar no lado pessimista das coisas. Não é de surpreender que o Lighthouse também não estivesse muito feliz com nosso site, fornecendo pontuações vermelhas totalmente sólidas para os artigos mais pesados e reclamando incansavelmente sobre JavaScript, CSS, imagens fora da tela e seus tamanhos não utilizados.
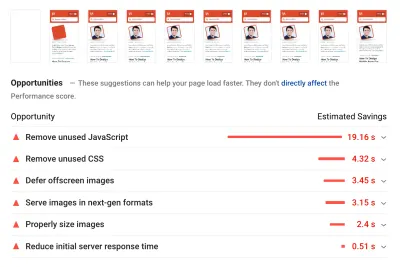
Uma vez que tivéssemos alguns dados à nossa frente, poderíamos nos concentrar em otimizar as três páginas de artigos mais pesadas, com foco em CSS crítico (e não crítico), pacote JavaScript, tarefas longas, carregamento de fonte da web, mudanças de layout e terceiros -incorpora. Mais tarde, também revisaríamos a base de código para remover o código legado e usar os novos recursos modernos do navegador. Parecia que havia muito trabalho pela frente e, de fato, estávamos bastante ocupados nos próximos meses.
Melhorando a ordem dos ativos no <head>
Ironicamente, a primeira coisa que analisamos nem estava intimamente relacionada a todas as tarefas que identificamos acima. No workshop de desempenho, Harry passou um tempo considerável explicando a ordem dos ativos no <head> de cada página, ressaltando que entregar conteúdo crítico rapidamente significa ser muito estratégico e atento sobre como os ativos são ordenados no código-fonte .
Agora não deveria ser uma grande revelação que CSS crítico é benéfico para o desempenho da web. No entanto, foi uma surpresa quanta diferença a ordem de todos os outros ativos – dicas de recursos, pré-carregamento de fontes da Web, scripts síncronos e assíncronos, CSS e metadados completos – tem.
Viramos todo o <head> de cabeça para baixo, colocando CSS crítico antes de todos os scripts assíncronos e todos os recursos pré-carregados, como fontes, imagens etc. Dividimos os recursos aos quais pré-conectaremos ou pré-carregamos por modelo e tipo de arquivo, para que imagens críticas, realce de sintaxe e incorporação de vídeo sejam solicitados antecipadamente apenas para um determinado tipo de artigos e páginas.
Em geral, orquestramos cuidadosamente a ordem no <head> , reduzimos o número de ativos pré-carregados que competiam por largura de banda e focamos em obter o CSS crítico correto. Se você quiser se aprofundar em algumas das considerações críticas com a ordem <head> , Harry as destaca no artigo sobre CSS e desempenho de rede. Essa mudança por si só nos trouxe cerca de 3 a 4 pontos de pontuação do Lighthouse em todos os aspectos.
Movendo-se do CSS crítico automatizado de volta ao CSS crítico manual
Mover as tags <head> foi uma parte simples da história. A mais difícil foi a geração e gerenciamento de arquivos CSS críticos. Em 2017, criamos manualmente CSS crítico para cada modelo, coletando todos os estilos necessários para renderizar os primeiros 1.000 pixels de altura em todas as larguras de tela. Isso, obviamente, foi uma tarefa complicada e pouco inspiradora, sem mencionar os problemas de manutenção para domar uma família inteira de arquivos CSS críticos e um arquivo CSS completo.
Então, analisamos as opções para automatizar esse processo como parte da rotina de compilação. Não havia realmente uma escassez de ferramentas disponíveis, então testamos algumas e decidimos fazer alguns testes. Conseguimos configurá-los e funcionar muito rapidamente. A saída parecia ser boa o suficiente para um processo automatizado, então, após alguns ajustes de configuração, nós a conectamos e a colocamos em produção. Isso aconteceu por volta de julho-agosto do ano passado, o que é bem visualizado no pico e na queda de desempenho nos dados do CrUX acima. Continuamos indo e voltando com a configuração, muitas vezes tendo problemas com coisas simples, como adicionar estilos específicos ou remover outros. Por exemplo, estilos de prompt de consentimento de cookie que não são realmente incluídos em uma página, a menos que o script de cookie tenha inicializado.
Em outubro, introduzimos algumas mudanças importantes no layout do site e, ao analisar o CSS crítico, encontramos exatamente os mesmos problemas novamente - o resultado gerado era bastante detalhado e não era exatamente o que queríamos . Então, como um experimento no final de outubro, todos reunimos nossos pontos fortes para revisitar nossa abordagem crítica de CSS e estudar o quão menor seria um CSS crítico artesanal . Respiramos fundo e passamos dias em torno da ferramenta de cobertura de código nas principais páginas. Agrupamos as regras CSS manualmente e removemos duplicatas e códigos legados em ambos os lugares — o CSS crítico e o CSS principal. Foi uma limpeza muito necessária, já que muitos estilos que foram escritos em 2017-2018 se tornaram obsoletos ao longo dos anos.
Como resultado, acabamos com três arquivos CSS críticos feitos à mão e com mais três arquivos que estão em andamento:
- critical-homepage-manual.css (8,2 KB, Brotlified)
- critical-article-manual.css (8 KB, Brotlified)
- critical-articles-manual.css (6 KB, Brotlified)
- critical-books-manual.css ( trabalho a ser feito )
- critical-events-manual.css ( trabalho a ser feito )
- critical-job-board-manual.css ( trabalho a ser feito )
Os arquivos são embutidos no cabeçalho de cada modelo e, no momento, são duplicados no pacote CSS monolítico que contém tudo o que já foi usado (ou não é mais usado) no site. No momento, estamos tentando dividir o pacote CSS completo em alguns pacotes CSS, para que um leitor da revista não baixe estilos do quadro de empregos ou das páginas do livro, mas ao chegar a essas páginas obterá uma renderização rápida com CSS crítico e obtenha o restante do CSS para essa página de forma assíncrona — somente nessa página.
É certo que os arquivos CSS críticos feitos à mão não eram muito menores em tamanho: reduzimos o tamanho dos arquivos CSS críticos em cerca de 14% . No entanto, eles incluíram tudo o que precisávamos na ordem certa, do início ao fim, sem duplicatas e estilos de substituição. Este parecia ser um passo na direção certa e nos deu um aumento de 3 a 4 pontos no Farol. Estávamos fazendo progressos.
Alterando o carregamento da fonte da Web
Com font-display na ponta dos dedos, o carregamento de fontes parece ser um problema no passado. Infelizmente, não está certo no nosso caso. Vocês, caros leitores, parecem visitar vários artigos na Smashing Magazine. Você também retorna frequentemente ao site para ler outro artigo – talvez algumas horas ou dias depois, ou talvez uma semana depois. Um dos problemas que tivemos com font-display usada em todo o site foi que, para os leitores que alternavam muito entre os artigos, notamos muitos flashes entre a fonte de fallback e a fonte da Web (o que normalmente não deveria acontecer, pois as fontes seriam devidamente em cache).
Isso não parecia uma experiência de usuário decente, então analisamos as opções. No Smashing, estamos usando duas fontes principais - Mija para títulos e Elena para cópia do corpo. Mija vem em dois pesos (Regular e Bold), enquanto Elena vem em três pesos (Regular, Italic, Bold). Deixamos o Bold Italic de Elena anos atrás durante o redesenho apenas porque o usamos em apenas algumas páginas. Subdefinimos as outras fontes removendo caracteres não utilizados e intervalos Unicode.
Nossos artigos são principalmente definidos em texto, por isso descobrimos que na maioria das vezes no site a maior pintura de conteúdo é o primeiro parágrafo do texto em um artigo ou a foto do autor. Isso significa que precisamos ter um cuidado extra para garantir que o primeiro parágrafo apareça rapidamente em uma fonte de fallback, enquanto mudamos para a fonte da Web com o mínimo de refluxos.
Dê uma olhada na experiência de carregamento inicial da primeira página (abrandou três vezes):
Tínhamos quatro objetivos principais ao descobrir uma solução:
- Na primeira visita, renderize o texto imediatamente com uma fonte de reserva;
- Combine as métricas de fontes de fontes alternativas e fontes da Web para minimizar as mudanças de layout;
- Carregue todas as fontes da web de forma assíncrona e aplique-as todas de uma vez (máximo 1 refluxo);
- Nas visitas subsequentes, renderize todo o texto diretamente em fontes da Web (sem flashes ou refluxos).
Inicialmente, tentamos usar font-display: swap on font-face . Esta parecia ser a opção mais simples, no entanto, como mencionado acima, alguns leitores visitarão várias páginas, então acabamos com muita cintilação com as seis fontes que estávamos renderizando ao longo do site. Além disso, apenas com a exibição da fonte , não conseguimos agrupar solicitações ou repinturas.
Outra ideia era renderizar tudo em fonte de fallback na visita inicial , depois solicitar e armazenar em cache todas as fontes de forma assíncrona e somente nas visitas subsequentes entregar fontes da web diretamente do cache. O problema com essa abordagem foi que vários leitores estão vindo de mecanismos de busca, e pelo menos alguns deles verão apenas aquela página – e não queríamos renderizar um artigo apenas em uma fonte do sistema.
Então o que é então?
Desde 2017, usamos a abordagem de renderização em dois estágios para carregamento de fontes da Web, que basicamente descreve dois estágios de renderização: um com um subconjunto mínimo de fontes da Web e o outro com uma família completa de pesos de fonte. Antigamente, criamos subconjuntos mínimos de Mija Bold e Elena Regular, que eram os pesos mais usados no site. Ambos os subconjuntos incluem apenas caracteres latinos, pontuação, números e alguns caracteres especiais. Essas fontes ( ElenaInitial.woff2 e MijaInitial.woff2 ) eram muito pequenas em tamanho - geralmente cerca de 10 a 15 KB de tamanho. Nós os atendemos no primeiro estágio de renderização da fonte, exibindo a página inteira nessas duas fontes.

Fazemos isso com uma API de carregamento de fontes que nos fornece informações sobre quais fontes foram carregadas com sucesso e quais ainda não. Nos bastidores, isso acontece adicionando uma classe .wf-loaded-stage1 ao corpo , com estilos renderizando o conteúdo nessas fontes:
.wf-loaded-stage1 article, .wf-loaded-stage1 promo-box, .wf-loaded-stage1 comments { font-family: ElenaInitial,sans-serif; } .wf-loaded-stage1 h1, .wf-loaded-stage1 h2, .wf-loaded-stage1 .btn { font-family: MijaInitial,sans-serif; }Como os arquivos de fonte são muito pequenos, esperamos que eles passem pela rede rapidamente. Então, como o leitor pode realmente começar a ler um artigo, carregamos os pesos totais das fontes de forma assíncrona e adicionamos .wf-loaded-stage2 ao corpo :
.wf-loaded-stage2 article, .wf-loaded-stage2 promo-box, .wf-loaded-stage2 comments { font-family: Elena,sans-serif; } .wf-loaded-stage2 h1, .wf-loaded-stage2 h2, .wf-loaded-stage2 .btn { font-family: Mija,sans-serif; }Portanto, ao carregar uma página, os leitores obterão um pequeno subconjunto de fontes da Web primeiro e, em seguida, mudaremos para a família de fontes completa. Agora, por padrão, essas alternâncias entre fontes de fallback e fontes da Web acontecem aleatoriamente, com base no que ocorrer primeiro na rede. Isso pode parecer bastante perturbador quando você começou a ler um artigo. Então, em vez de deixar que o navegador decida quando trocar as fontes, agrupamos repaints , reduzindo o impacto de reflow ao mínimo.
/* Loading web fonts with Font Loading API to avoid multiple repaints. With help by Irina Lipovaya. */ /* Credit to initial work by Zach Leatherman: https://noti.st/zachleat/KNaZEg/the-five-whys-of-web-font-loading-performance#sWkN4u4 */ // If the Font Loading API is supported... // (If not, we stick to fallback fonts) if ("fonts" in document) { // Create new FontFace objects, one for each font let ElenaRegular = new FontFace( "Elena", "url(/fonts/ElenaWebRegular/ElenaWebRegular.woff2) format('woff2')" ); let ElenaBold = new FontFace( "Elena", "url(/fonts/ElenaWebBold/ElenaWebBold.woff2) format('woff2')", { weight: "700" } ); let ElenaItalic = new FontFace( "Elena", "url(/fonts/ElenaWebRegularItalic/ElenaWebRegularItalic.woff2) format('woff2')", { style: "italic" } ); let MijaBold = new FontFace( "Mija", "url(/fonts/MijaBold/Mija_Bold-webfont.woff2) format('woff2')", { weight: "700" } ); // Load all the fonts but render them at once // if they have successfully loaded let loadedFonts = Promise.all([ ElenaRegular.load(), ElenaBold.load(), ElenaItalic.load(), MijaBold.load() ]).then(result => { result.forEach(font => document.fonts.add(font)); document.documentElement.classList.add('wf-loaded-stage2'); // Used for repeat views sessionStorage.foutFontsStage2Loaded = true; }).catch(error => { throw new Error(`Error caught: ${error}`); }); }No entanto, e se o primeiro pequeno subconjunto de fontes não estiver passando pela rede rapidamente? Percebemos que isso parece estar acontecendo com mais frequência do que gostaríamos. Nesse caso, depois que um tempo limite de 3s expirar, os navegadores modernos voltam para uma fonte do sistema (em nossa pilha de fontes seria Arial) e, em seguida, alternam para ElenaInitial ou MijaInitial , apenas para serem alternados para Elena ou Mija completos, respectivamente, mais tarde . Isso produziu um pouco de brilho demais em nossa degustação. Estávamos pensando em remover o primeiro estágio de renderização apenas para redes lentas inicialmente (via API de informações de rede), mas depois decidimos removê-lo completamente.
Então, em outubro, removemos completamente os subconjuntos, juntamente com o estágio intermediário. Sempre que todos os pesos das fontes Elena e Mija são baixados com sucesso pelo cliente e prontos para serem aplicados, iniciamos o estágio 2 e repintamos tudo de uma vez. E para tornar os refluxos ainda menos perceptíveis, passamos algum tempo combinando fontes de fallback e fontes da web . Isso significava principalmente aplicar tamanhos de fonte e alturas de linha ligeiramente diferentes para elementos pintados na primeira parte visível da página.
Para isso, usamos font-style-matcher e (ahem, ahem) alguns números mágicos. Essa também é a razão pela qual inicialmente optamos por -apple-system e Arial como fontes de fallback globais; San Francisco (renderizado via -apple-system ) parecia ser um pouco melhor do que o Arial, mas se não estiver disponível, optamos por usar o Arial apenas porque está amplamente difundido na maioria dos sistemas operacionais.
Em CSS, ficaria assim:
.article__summary { font-family: -apple-system,Arial,BlinkMacSystemFont,Roboto Slab,Droid Serif,Segoe UI,Ubuntu,Cantarell,Georgia,sans-serif; font-style: italic; /* Warning: magic numbers ahead! */ /* San Francisco Italic and Arial Italic have larger x-height, compared to Elena */ font-size: 0.9213em; line-height: 1.487em; } .wf-loaded-stage2 .article__summary { font-family: Elena,sans-serif; font-size: 1em; /* Original font-size for Elena Italic */ line-height: 1.55em; /* Original line-height for Elena Italic */ }Isso funcionou bastante bem. Exibimos o texto imediatamente e as fontes da Web aparecem agrupadas na tela, o que idealmente causa exatamente um refluxo na primeira visualização e nenhum refluxo nas visualizações subsequentes.
Após o download das fontes, nós as armazenamos no cache de um service worker. Nas visitas subsequentes, primeiro verificamos se as fontes já estão no cache. Se estiverem, nós os recuperamos do cache do service worker e os aplicamos imediatamente. E se não, começamos tudo de novo com o fallback-web-font-switcheroo .
Essa solução reduziu o número de reflows ao mínimo (um) em conexões relativamente rápidas, ao mesmo tempo em que manteve as fontes de forma persistente e confiável no cache. No futuro, esperamos sinceramente substituir os números mágicos por f-mods. Talvez Zach Leatherman ficasse orgulhoso.
Identificando e quebrando o JS monolítico
Quando estudamos o segmento principal no painel Desempenho do DevTools, sabíamos exatamente o que precisávamos fazer. Havia oito Tarefas Longas que demoravam entre 70ms e 580ms, bloqueando a interface e deixando-a sem resposta. Em geral, esses foram os scripts que mais custaram:
- uc.js , um script de prompt de cookie (70ms)
- recálculos de estilo causados pelo arquivo full.css de entrada (176ms) (o CSS crítico não contém estilos abaixo da altura de 1000px em todas as janelas de visualização)
- scripts de publicidade rodando no evento load para gerenciar painéis, carrinho de compras, etc. + recálculos de estilo (276ms)
- troca de fonte da web, recálculos de estilo (290ms)
- avaliação app.js (580ms)
Nós nos concentramos nos que eram mais prejudiciais primeiro – por assim dizer, as Tarefas Longas mais longas.
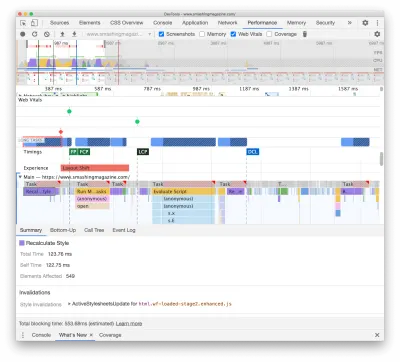
A primeira estava ocorrendo devido a recálculos caros de layout causados pela mudança das fontes (de fonte de fallback para fonte da web), causando mais de 290ms de trabalho extra (em um laptop rápido e uma conexão rápida). Ao remover o estágio um apenas do carregamento da fonte, conseguimos ganhar cerca de 80ms de volta. Mas não foi bom o suficiente porque estava muito além do orçamento de 50ms. Então começamos a cavar mais fundo.
A principal razão pela qual os recálculos aconteceram foi apenas por causa das enormes diferenças entre fontes de fallback e fontes da web. Ao combinar a altura da linha e os tamanhos das fontes substitutas e das fontes da Web , conseguimos evitar muitas situações em que uma linha de texto se quebrava em uma nova linha na fonte substituta, mas ficava um pouco menor e se ajustava à linha anterior, causando grandes mudanças na geometria de toda a página e, consequentemente, grandes mudanças de layout. Também brincamos com letter-spacing e word-spacing , mas não produziu bons resultados.
Com essas alterações, conseguimos cortar outros 50-80ms, mas não conseguimos reduzi-lo abaixo de 120ms sem exibir o conteúdo em uma fonte de fallback e exibir o conteúdo na fonte da Web posteriormente. Obviamente, isso deve afetar massivamente apenas os visitantes de primeira viagem, pois as visualizações de página consequentes seriam renderizadas com as fontes recuperadas diretamente do cache do service worker, sem refluxos dispendiosos devido à troca de fonte.
A propósito, é muito importante notar que, no nosso caso, notamos que a maioria das Tarefas Longas não eram causadas por JavaScript massivo, mas sim por Recálculos de Layout e análise do CSS, o que significava que precisávamos fazer um pouco de CSS cleaning, especially watching out for situations when styles are overwritten. In some way, it was good news because we didn't have to deal with complex JavaScript issues that much. However, it turned out not to be straightforward as we are still cleaning up the CSS this very day. We were able to remove two Long Tasks for good, but we still have a few outstanding ones and quite a way to go. Fortunately, most of the time we aren't way above the magical 50ms threshold.
The much bigger issue was the JavaScript bundle we were serving, occupying the main thread for a whopping 580ms. Most of this time was spent in booting up app.js which contains React, Redux, Lodash, and a Webpack module loader. The only way to improve performance with this massive beast was to break it down into smaller pieces. So we looked into doing just that.
With Webpack, we've split up the monolithic bundle into smaller chunks with code-splitting , about 30Kb per chunk. We did some package.json cleansing and version upgrade for all production dependencies, adjusted the browserlistrc setup to address the two latest browser versions, upgraded to Webpack and Babel to the latest versions, moved to Terser for minification, and used ES2017 (+ browserlistrc) as a target for script compilation.
We also used BabelEsmPlugin to generate modern versions of existing dependencies. Finally, we've added prefetch links to the header for all necessary script chunks and refactored the service worker, migrating to Workbox with Webpack (workbox-webpack-plugin).
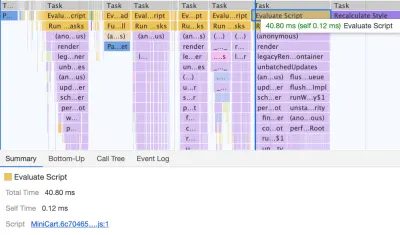
Remember when we switched to the new navigation back in mid-2020, just to see a huge performance penalty as a result? The reason for it was quite simple. While in the past the navigation was just static plain HTML and a bit of CSS, with the new navigation, we needed a bit of JavaScript to act on opening and closing of the menu on mobile and on desktop. That was causing rage clicks when you would click on the navigation menu and nothing would happen, and of course, had a penalty cost in Time-To-Interactive scores in Lighthouse.
We removed the script from the bundle and extracted it as a separate script . Additionally, we did the same thing for other standalone scripts that were used rarely — for syntax highlighting, tables, video embeds and code embeds — and removed them from the main bundle; instead, we granularly load them only when needed.
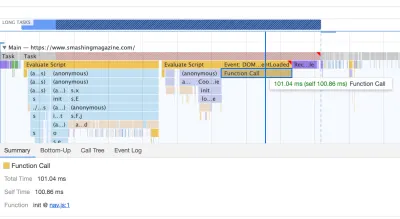
However, what we didn't notice for months was that although we removed the navigation script from the bundle, it was loading after the entire app.js bundle was evaluated, which wasn't really helping Time-To-Interactive (see image above). We fixed it by preloading nav.js and deferring it to execute in the order of appearance in the DOM, and managed to save another 100ms with that operation alone. By the end, with everything in place we were able to bring the task to around 220ms.
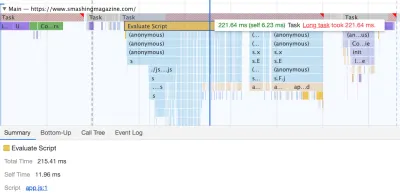
We managed to get some improvement in place, but still have quite a way to go, with further React and Webpack optimizations on our to-do list. At the moment we still have three major Long Tasks — font switch (120ms), app.js execution (220ms) and style recalculations due to the size of full CSS (140ms). For us, it means cleaning up and breaking up the monolithic CSS next.
It's worth mentioning that these results are really the best-scenario- results. On a given article page we might have a large number of code embeds and video embeds, along with other third-party scripts and customer's browser extensions that would require a separate conversation.
Dealing With 3rd-Parties
Fortunately, our third-party scripts footprint (and the impact of their friends' fourth-party-scripts) wasn't huge from the start. But when these third-party scripts accumulated, they would drive performance down significantly. This goes especially for video embedding scripts , but also syntax highlighting, advertising scripts, promo panels scripts and any external iframe embeds.
Obviously, we defer all of these scripts to start loading after the DOMContentLoaded event, but once they finally come on stage, they cause quite a bit of work on the main thread. This shows up especially on article pages, which are obviously the vast majority of content on the site.
The first thing we did was allocating proper space to all assets that are being injected into the DOM after the initial page render. It meant width and height for all advertising images and the styling of code snippets. We found out that because all the scripts were deferred, new styles were invalidating existing styles, causing massive layout shifts for every code snippet that was displayed. We fixed that by adding the necessary styles to the critical CSS on the article pages.
We've re-established a strategy for optimizing images (preferably AVIF or WebP — still work in progress though). All images below the 1000px height threshold are natively lazy-loaded (with <img loading=lazy> ), while the ones on the top are prioritized ( <img loading=eager> ). The same goes for all third-party embeds.
We replaced some dynamic parts with their static counterparts — eg while a note about an article saved for offline reading was appearing dynamically after the article was added to the service worker's cache, now it appears statically as we are, well, a bit optimistic and expect it to be happening in all modern browsers.
As of the moment of writing, we're preparing facades for code embeds and video embeds as well. Plus, all images that are offscreen will get decoding=async attribute, so the browser has a free reign over when and how it loads images offscreen, asynchronously and in parallel.
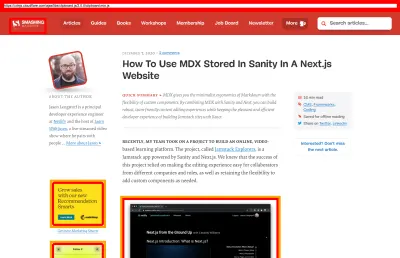
To ensure that our images always include width and height attributes, we've also modified Harry Roberts' snippet and Tim Kadlec's diagnostics CSS to highlight whenever an image isn't served properly. It's used in development and editing but obviously not in production.
One technique that we used frequently to track what exactly is happening as the page is being loaded, was slow-motion loading .
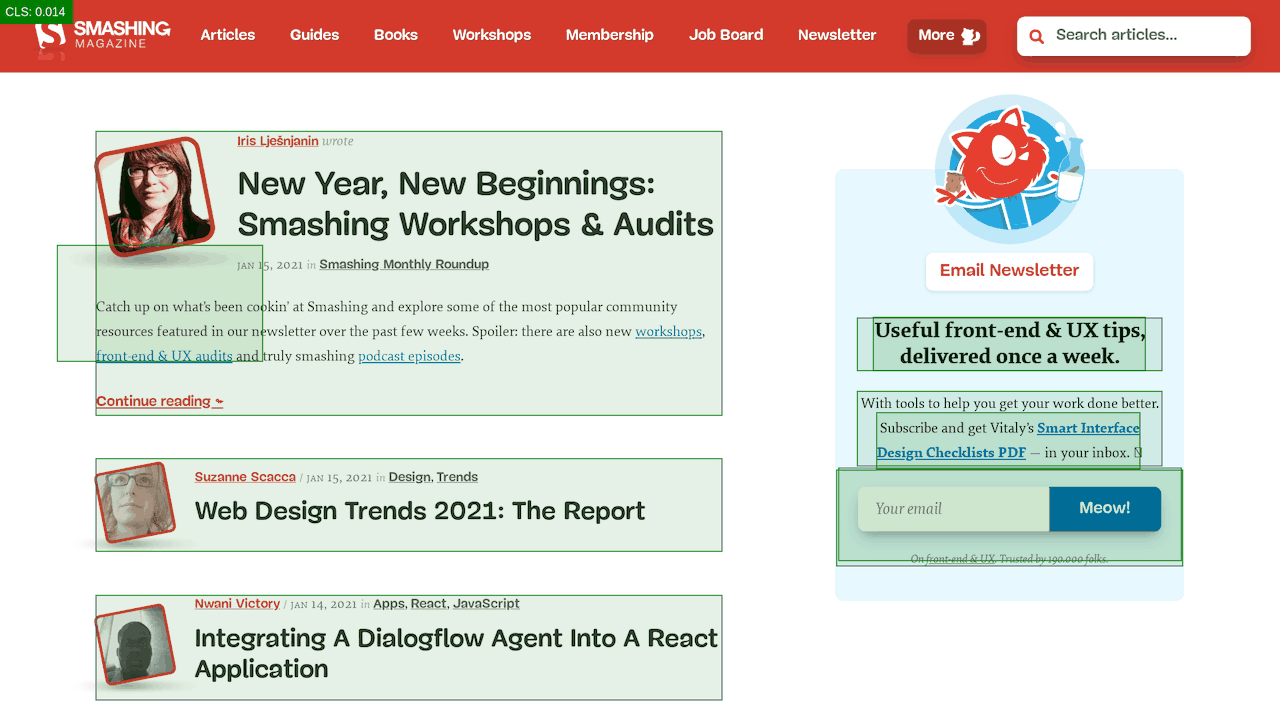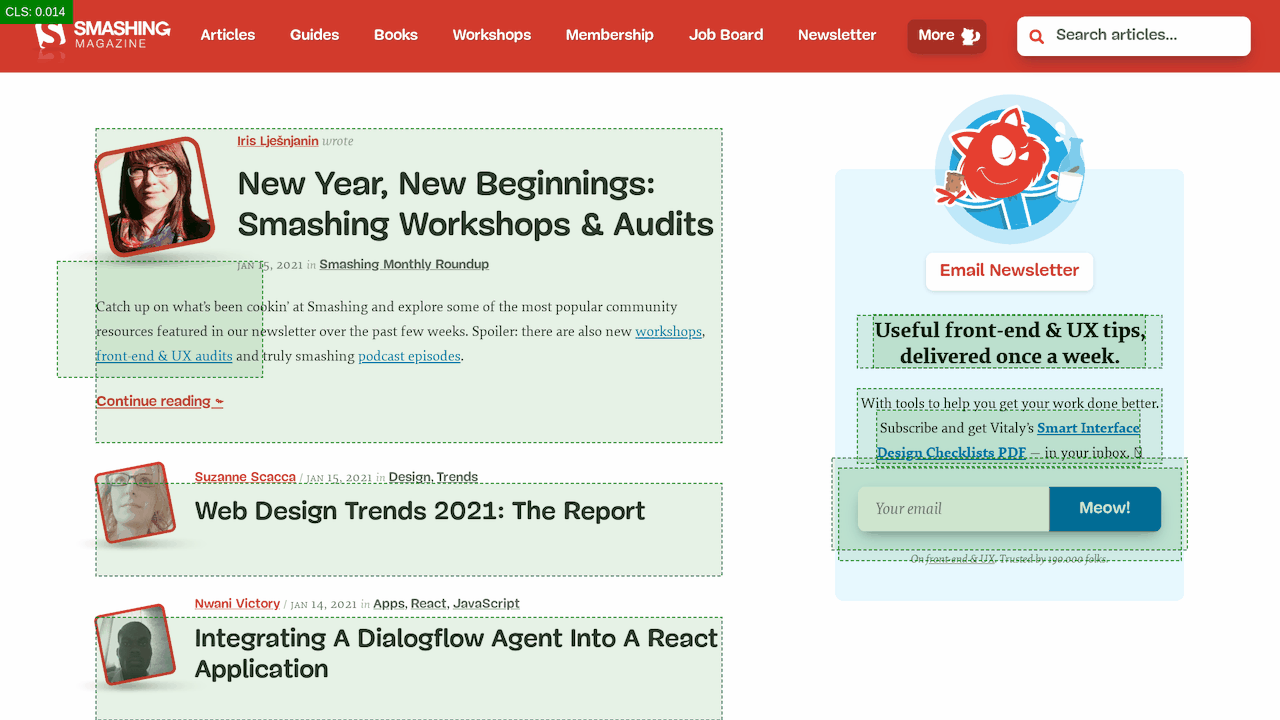
First, we've added a simple line of code to the diagnostics CSS, which provides a noticeable outline for all elements on the page.
* { outline: 3px solid red }* { outline: 3px solid red }
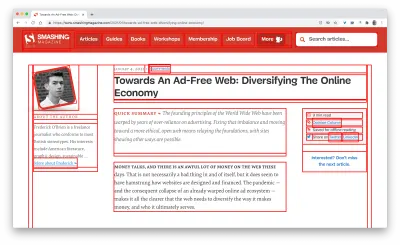
* { outline: 3px red } and observing the boxes as the browser is rendering the page. (Visualização grande)Then we record a video of the page loaded on a slow and fast connection. Then we rewatch the video by slowing down the playback and moving back and forward to identify where massive layout shifts happen.
Here's the recording of a page being loaded on a fast connection:
And here's the recording of a recording being played to study what happens with the layout:
By auditing the layout shifts this way, we were able to quickly notice what's not quite right on the page, and where massive recalculation costs are happening. As you probably have noticed, adjusting the line-height and font-size on headings might go a long way to avoid large shifts.
With these simple changes alone, we were able to boost performance score by a whopping 25 Lighthouse points for the video-heaviest article, and gain a few points for code embeds.
Enhancing The Experience
We've tried to be quite strategic in pretty much everything from loading web fonts to serving critical CSS. However, we've done our best to use some of the new technologies that have become available last year.
We are planning on using AVIF by default to serve images on SmashingMag, but we aren't quite there yet, as many of our images are served from Cloudinary (which already has beta support for AVIF), but many are directly from our CDN yet we don't really have a logic in place just yet to generate AVIFs on the fly. That would need to be a manual process for now.
We're lazy rendering some of the offset components of the page with content-visibility: auto . For example, the footer, the comments section, as well as the panels way below the first 1000px height threshold, are all rendered later after the visible portion of each page has been rendered.
Brincamos um pouco com link rel="prefetch" e até link rel="prerender" (NoPush pré-busca) algumas partes da página que provavelmente serão usadas para navegação adicional — por exemplo, para pré-buscar recursos para o primeiro artigos na primeira página (ainda em discussão).
Também pré-carregamos imagens de autor para reduzir a maior pintura de conteúdo e alguns recursos importantes que são usados em cada página, como imagens de gatos dançantes (para a navegação) e sombra usada para todas as imagens de autor. No entanto, todos eles são pré-carregados apenas se um leitor estiver em uma tela maior (> 800px), embora estejamos procurando usar a API de informações de rede para ser mais preciso.
Também reduzimos o tamanho do CSS completo e de todos os arquivos CSS críticos removendo o código legado, refatorando vários componentes e removendo o truque de sombra de texto que estávamos usando para obter sublinhados perfeitos com uma combinação de text-decoration-skip -ink e text-decoration-thickness (finalmente!).
Trabalho a ser feito
Passamos um tempo bastante significativo trabalhando em todas as pequenas e grandes mudanças no site. Percebemos melhorias bastante significativas no desktop e um aumento bastante perceptível no celular. No momento da redação, nossos artigos estão pontuando em média entre 90 e 100 pontos Lighthouse no computador e cerca de 65-80 no celular .
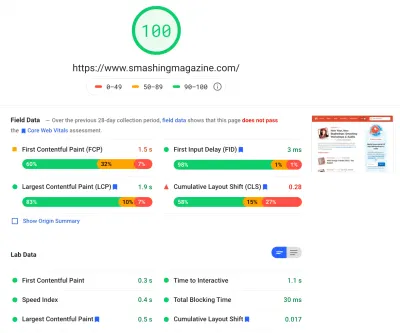
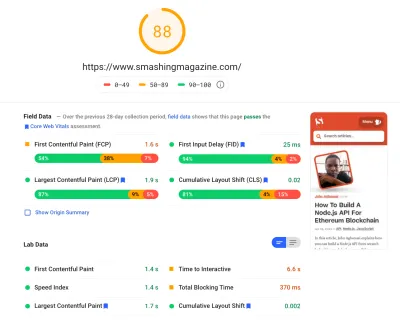
A razão para a pontuação baixa em dispositivos móveis é claramente o baixo tempo de interação e o tempo de bloqueio total ruim devido à inicialização do aplicativo e ao tamanho do arquivo CSS completo. Portanto, ainda há algum trabalho a ser feito lá.
Quanto às próximas etapas, estamos procurando reduzir ainda mais o tamanho do CSS e, especificamente, dividi-lo em módulos, semelhante ao JavaScript, carregando algumas partes do CSS (por exemplo, checkout ou quadro de empregos ou livros/eBooks) somente quando necessário.
Também exploramos opções de experimentação adicional em dispositivos móveis para reduzir o impacto no desempenho do app.js , embora pareça não ser trivial no momento. Por fim, procuraremos alternativas para nossa solução de prompt de cookies, reconstruindo nossos contêineres com CSS clamp() , substituindo a técnica de proporção de preenchimento inferior aspect-ratio e procurando servir o maior número possível de imagens em AVIF.
É isso, pessoal!
Espero que este pequeno estudo de caso seja útil para você, e talvez haja uma ou duas técnicas que você possa aplicar ao seu projeto imediatamente. No final das contas, o desempenho é uma soma de todos os pequenos detalhes que, quando somados, fazem ou quebram a experiência do seu cliente.
Embora estejamos muito empenhados em melhorar o desempenho, também trabalhamos para melhorar a acessibilidade e o conteúdo do site. Portanto, se você encontrar algo que não esteja certo ou algo que possamos fazer para melhorar ainda mais a Smashing Magazine, informe-nos nos comentários deste artigo.
Finalmente, se você quiser se manter atualizado sobre artigos como este, assine nosso boletim informativo por e-mail para dicas amigáveis da web, brindes, ferramentas e artigos, e uma seleção sazonal de gatos Smashing.