
Compartilhamento de dados entre vários servidores por meio do AWS S3
Publicados: 2022-03-10Ao fornecer alguma funcionalidade para processar um arquivo carregado pelo usuário, o arquivo deve estar disponível para o processo durante toda a execução. Uma operação simples de upload e salvamento não apresenta problemas. No entanto, se, além disso, o arquivo precisar ser manipulado antes de ser salvo e o aplicativo estiver sendo executado em vários servidores por trás de um balanceador de carga, precisamos garantir que o arquivo esteja disponível para qualquer servidor que esteja executando o processo a cada vez.
Por exemplo, uma funcionalidade de várias etapas "Faça upload do seu avatar de usuário" pode exigir que o usuário carregue um avatar na etapa 1, corte-o na etapa 2 e, finalmente, salve-o na etapa 3. Após o upload do arquivo para um servidor na etapa 1, o arquivo deve estar disponível para qualquer servidor que lide com a solicitação das etapas 2 e 3, que podem ou não ser a mesma da etapa 1.
Uma abordagem ingênua seria copiar o arquivo carregado na etapa 1 para todos os outros servidores, para que o arquivo ficasse disponível em todos eles. No entanto, essa abordagem não é apenas extremamente complexa, mas também inviável: por exemplo, se o site for executado em centenas de servidores, de várias regiões, não poderá ser realizado.
Uma possível solução é habilitar “sessões fixas” no balanceador de carga, que sempre atribuirá o mesmo servidor para uma determinada sessão. Em seguida, as etapas 1, 2 e 3 serão tratadas pelo mesmo servidor, e o arquivo carregado para este servidor na etapa 1 ainda estará lá para as etapas 2 e 3. No entanto, as sessões fixas não são totalmente confiáveis: se entre as etapas 1 e 2 que o servidor travou, então o balanceador de carga terá que atribuir um servidor diferente, interrompendo a funcionalidade e a experiência do usuário. Da mesma forma, sempre atribuir o mesmo servidor para uma sessão pode, em circunstâncias especiais, levar a tempos de resposta mais lentos de um servidor sobrecarregado.
Uma solução mais adequada é manter uma cópia do arquivo em um repositório acessível a todos os servidores. Então, após o upload do arquivo para o servidor na etapa 1, este servidor irá carregá-lo para o repositório (ou, alternativamente, o arquivo pode ser carregado para o repositório diretamente do cliente, ignorando o servidor); a etapa 2 de manipulação do servidor irá baixar o arquivo do repositório, manipulá-lo e carregá-lo lá novamente; e, finalmente, a etapa 3 de manipulação do servidor irá baixá-lo do repositório e salvá-lo.
Neste artigo, descreverei esta última solução, baseada em um aplicativo WordPress que armazena arquivos no Amazon Web Services (AWS) Simple Storage Service (S3) (uma solução de armazenamento de objetos em nuvem para armazenar e recuperar dados), operando por meio do AWS SDK.
Observação 1: para uma funcionalidade simples, como cortar avatares, outra solução seria ignorar completamente o servidor e implementá-lo diretamente na nuvem por meio de funções do Lambda. Mas como este artigo trata da conexão de um aplicativo em execução no servidor com o AWS S3, não consideramos essa solução.
Nota 2: Para usar o AWS S3 (ou qualquer outro serviço da AWS), precisaremos ter uma conta de usuário. A Amazon oferece um nível gratuito aqui por 1 ano, o que é bom o suficiente para experimentar seus serviços.
Nota 3: Existem plugins de terceiros para fazer upload de arquivos do WordPress para o S3. Um desses plugins é o WP Media Offload (a versão lite está disponível aqui), que oferece um ótimo recurso: ele transfere perfeitamente os arquivos carregados na Biblioteca de mídia para um bucket do S3, o que permite desacoplar o conteúdo do site (como tudo sob /wp-content/uploads) do código do aplicativo. Ao desacoplar conteúdo e código, podemos implantar nosso aplicativo WordPress usando Git (caso contrário, não podemos, pois o conteúdo carregado pelo usuário não está hospedado no repositório Git) e hospedar o aplicativo em vários servidores (caso contrário, cada servidor precisaria manter uma cópia de todo o conteúdo enviado pelo usuário.)
Criando o balde
Ao criar o bucket, precisamos levar em consideração o nome do bucket: cada nome do bucket deve ser globalmente exclusivo na rede da AWS, portanto, mesmo que queiramos chamar nosso bucket de algo simples como “avatars”, esse nome já pode ser usado , então podemos escolher algo mais distinto como "nome-avatares-da-minha-empresa".
Também precisaremos selecionar a região onde o bucket está baseado (a região é o local físico onde o data center está localizado, com locais em todo o mundo).
A região deve ser a mesma onde nosso aplicativo está implantado, para que o acesso ao S3 durante a execução do processo seja rápido. Caso contrário, o usuário pode ter que esperar segundos extras para fazer o upload/download de uma imagem de/para um local distante.
Observação: faz sentido usar o S3 como a solução de armazenamento de objetos em nuvem somente se também usarmos o serviço da Amazon para servidores virtuais na nuvem, EC2, para executar o aplicativo. Se, em vez disso, dependermos de alguma outra empresa para hospedar o aplicativo, como Microsoft Azure ou DigitalOcean, também devemos usar seus serviços de armazenamento de objetos em nuvem. Caso contrário, nosso site sofrerá uma sobrecarga de dados trafegando entre as redes de diferentes empresas.
Nas capturas de tela abaixo veremos como criar o bucket onde carregar os avatares do usuário para recorte. Primeiro, vamos ao painel do S3 e clicamos em “Criar bucket”:
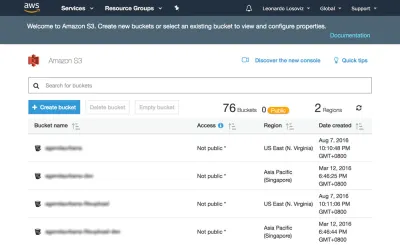
Em seguida, digitamos o nome do bucket (neste caso, “avatars-smashing”) e escolhemos a região (“EU (Frankfurt)”):
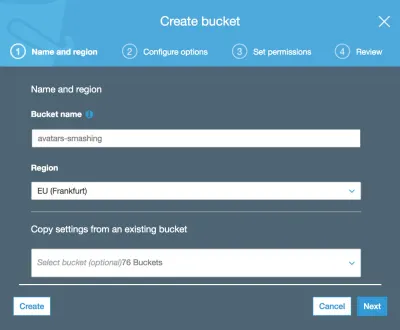
Apenas o nome do bucket e a região são obrigatórios. Para os passos seguintes podemos manter as opções padrão, então clicamos em “Next” até finalmente clicar em “Create bucket”, e com isso, teremos o bucket criado.
Configurando as permissões do usuário
Ao se conectar à AWS por meio do SDK, precisaremos inserir nossas credenciais de usuário (um par de ID de chave de acesso e chave de acesso secreta), para validar que temos acesso aos serviços e objetos solicitados. As permissões do usuário podem ser muito gerais (uma função de “administrador” pode fazer tudo) ou muito granulares, apenas concedendo permissão para as operações específicas necessárias e nada mais.
Como regra geral, quanto mais específicas forem nossas permissões concedidas, melhor, para evitar problemas de segurança . Ao criar o novo usuário, precisaremos criar uma política, que é um documento JSON simples listando as permissões a serem concedidas ao usuário. No nosso caso, nossas permissões de usuário concederão acesso ao S3, para o bucket “avatars-smashing”, para as operações de “Put” (para upload de um objeto), “Get” (para download de um objeto) e “List” ( para listar todos os objetos no bucket), resultando na seguinte política:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "s3:Put*", "s3:Get*", "s3:List*" ], "Resource": [ "arn:aws:s3:::avatars-smashing", "arn:aws:s3:::avatars-smashing/*" ] } ] }Nas capturas de tela abaixo, podemos ver como adicionar permissões de usuário. Devemos ir para o painel Identity and Access Management (IAM):
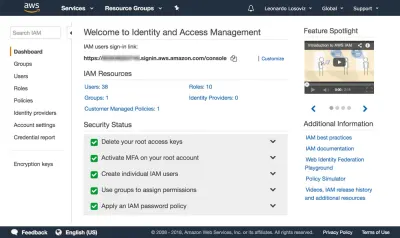
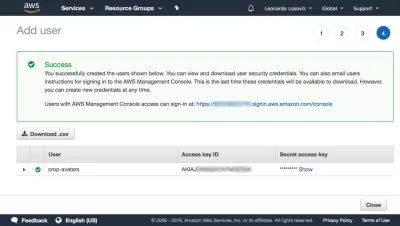
No dashboard, clicamos em “Usuários” e logo em seguida em “Adicionar usuário”. Na página Adicionar usuário, escolhemos um nome de usuário (“crop-avatars”) e marcamos “Acesso programático” como o tipo de acesso, que fornecerá o ID da chave de acesso e a chave de acesso secreta para conexão através do SDK:
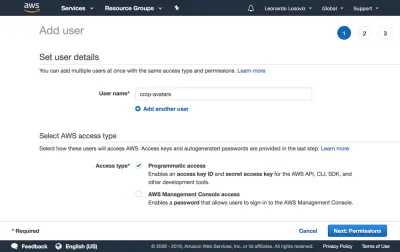
Em seguida, clicamos no botão “Avançar: Permissões”, clicamos em “Anexar políticas existentes diretamente” e clicamos em “Criar política”. Isso abrirá uma nova guia no navegador, com a página Criar política. Clicamos na guia JSON e inserimos o código JSON para a política definida acima:
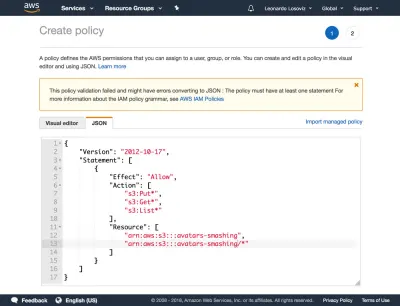
Em seguida, clicamos em Revisar política, damos um nome (“CropAvatars”) e, finalmente, clicamos em Criar política. Com a política criada, voltamos para a guia anterior, selecionamos a política CropAvatars (talvez seja necessário atualizar a lista de políticas para vê-la), clique em Next: Review e, finalmente, em Create user. Feito isso, podemos finalmente baixar o ID da chave de acesso e a chave de acesso secreta (observe que essas credenciais estão disponíveis para este momento único; se não as copiarmos ou baixarmos agora, teremos que criar um novo par ):

Conectando-se à AWS por meio do SDK
O SDK está disponível em vários idiomas. Para um aplicativo WordPress, exigimos o SDK para PHP, que pode ser baixado aqui, e as instruções sobre como instalá-lo estão aqui.
Assim que tivermos o bucket criado, as credenciais do usuário prontas e o SDK instalado, podemos começar a fazer upload de arquivos para o S3.
Upload e download de arquivos
Por conveniência, definimos as credenciais do usuário e a região como constantes no arquivo wp-config.php:
define ('AWS_ACCESS_KEY_ID', '...'); // Your access key id define ('AWS_SECRET_ACCESS_KEY', '...'); // Your secret access key define ('AWS_REGION', 'eu-central-1'); // Region where the bucket is located. This is the region id for "EU (Frankfurt)" No nosso caso, estamos implementando a funcionalidade de recorte de avatar, para a qual os avatares serão armazenados no bucket “avatars-smashing”. No entanto, em nosso aplicativo podemos ter vários outros buckets para outras funcionalidades, sendo necessário executar as mesmas operações de upload, download e listagem de arquivos. Assim, implementamos os métodos comuns em uma classe abstrata AWS_S3 e obtemos as entradas, como o nome do bucket definido por meio da função get_bucket , nas classes filhas de implementação.
// Load the SDK and import the AWS objects require 'vendor/autoload.php'; use Aws\S3\S3Client; use Aws\Exception\AwsException; // Definition of an abstract class abstract class AWS_S3 { protected function get_bucket() { // The bucket name will be implemented by the child class return ''; } } A classe S3Client expõe a API para interagir com o S3. Nós o instanciamos apenas quando necessário (através da inicialização lenta) e salvamos uma referência a ele em $this->s3Client para continuar usando a mesma instância:
abstract class AWS_S3 { // Continued from above... protected $s3Client; protected function get_s3_client() { // Lazy initialization if (!$this->s3Client) { // Create an S3Client. Provide the credentials and region as defined through constants in wp-config.php $this->s3Client = new S3Client([ 'version' => '2006-03-01', 'region' => AWS_REGION, 'credentials' => [ 'key' => AWS_ACCESS_KEY_ID, 'secret' => AWS_SECRET_ACCESS_KEY, ], ]); } return $this->s3Client; } } Quando estamos lidando com $file em nossa aplicação, esta variável contém o caminho absoluto para o arquivo em disco (por exemplo, /var/app/current/wp-content/uploads/users/654/leo.jpg ), mas ao carregar o arquivo arquivo para S3, não devemos armazenar o objeto no mesmo caminho. Em particular, devemos remover o bit inicial referente às informações do sistema ( /var/app/current ) por motivos de segurança, e opcionalmente podemos remover o bit /wp-content (já que todos os arquivos são armazenados nesta pasta, esta é uma informação redundante ), mantendo apenas o caminho relativo para o arquivo ( /uploads/users/654/leo.jpg ). Convenientemente, isso pode ser feito removendo tudo após WP_CONTENT_DIR do caminho absoluto. As funções get_file e get_file_relative_path abaixo alternam entre os caminhos de arquivo absoluto e relativo:
abstract class AWS_S3 { // Continued from above... function get_file_relative_path($file) { return substr($file, strlen(WP_CONTENT_DIR)); } function get_file($file_relative_path) { return WP_CONTENT_DIR.$file_relative_path; } }Ao fazer upload de um objeto para o S3, podemos estabelecer quem tem acesso ao objeto e o tipo de acesso, feito através das permissões da lista de controle de acesso (ACL). As opções mais comuns são manter o arquivo privado (ACL => “private”) e torná-lo acessível para leitura na internet (ACL => “public-read”). Como precisaremos solicitar o arquivo diretamente do S3 para mostrá-lo ao usuário, precisamos de ACL => “public-read”:
abstract class AWS_S3 { // Continued from above... protected function get_acl() { return 'public-read'; } }Por fim, implementamos os métodos para fazer upload de um objeto e fazer download de um objeto do bucket do S3:
abstract class AWS_S3 { // Continued from above... function upload($file) { $s3Client = $this->get_s3_client(); // Upload a file object to S3 $s3Client->putObject([ 'ACL' => $this->get_acl(), 'Bucket' => $this->get_bucket(), 'Key' => $this->get_file_relative_path($file), 'SourceFile' => $file, ]); } function download($file) { $s3Client = $this->get_s3_client(); // Download a file object from S3 $s3Client->getObject([ 'Bucket' => $this->get_bucket(), 'Key' => $this->get_file_relative_path($file), 'SaveAs' => $file, ]); } }Em seguida, na classe filha de implementação, definimos o nome do bucket:
class AvatarCropper_AWS_S3 extends AWS_S3 { protected function get_bucket() { return 'avatars-smashing'; } } Por fim, simplesmente instanciamos a classe para fazer upload dos avatares ou fazer download do S3. Além disso, ao fazer a transição das etapas 1 para 2 e 2 para 3, precisamos comunicar o valor de $file . Podemos fazer isso enviando um campo “file_relative_path” com o valor do caminho relativo de $file através de uma operação POST (não passamos o caminho absoluto por motivos de segurança: não é necessário incluir o “/var/www/current ” informações para pessoas de fora verem):
// Step 1: after the file was uploaded to the server, upload it to S3. Here, $file is known $avatarcropper = new AvatarCropper_AWS_S3(); $avatarcropper->upload($file); // Get the file path, and send it to the next step in the POST $file_relative_path = $avatarcropper->get_file_relative_path($file); // ... // -------------------------------------------------- // Step 2: get the $file from the request and download it, manipulate it, and upload it again $avatarcropper = new AvatarCropper_AWS_S3(); $file_relative_path = $_POST['file_relative_path']; $file = $avatarcropper->get_file($file_relative_path); $avatarcropper->download($file); // Do manipulation of the file // ... // Upload the file again to S3 $avatarcropper->upload($file); // -------------------------------------------------- // Step 3: get the $file from the request and download it, and then save it $avatarcropper = new AvatarCropper_AWS_S3(); $file_relative_path = $_REQUEST['file_relative_path']; $file = $avatarcropper->get_file($file_relative_path); $avatarcropper->download($file); // Save it, whatever that means // ...Exibindo o arquivo diretamente do S3
Se quisermos exibir o estado intermediário do arquivo após a manipulação na etapa 2 (por exemplo, o avatar do usuário após o recorte), devemos referenciar o arquivo diretamente do S3; a URL não pôde apontar para o arquivo no servidor, pois, mais uma vez, não sabemos qual servidor tratará essa solicitação.
Abaixo, adicionamos a função get_file_url($file) que obtém a URL desse arquivo no S3. Se estiver usando esta função, certifique-se de que a ACL dos arquivos carregados seja de “leitura pública”, caso contrário não estará acessível ao usuário.
abstract class AWS_S3 { // Continue from above... protected function get_bucket_url() { $region = $this->get_region(); // North Virginia region is simply "s3", the others require the region explicitly $prefix = $region == 'us-east-1' ? 's3' : 's3-'.$region; // Use the same scheme as the current request $scheme = is_ssl() ? 'https' : 'http'; // Using the bucket name in path scheme return $scheme.'://'.$prefix.'.amazonaws.com/'.$this->get_bucket(); } function get_file_url($file) { return $this->get_bucket_url().$this->get_file_relative_path($file); } }Então, podemos simplesmente pegar a URL do arquivo no S3 e imprimir a imagem:
printf( "<img src='%s'>", $avatarcropper->get_file_url($file) );Listando arquivos
Se em nosso aplicativo quisermos permitir que o usuário visualize todos os avatares carregados anteriormente, podemos fazê-lo. Para isso, introduzimos a função get_file_urls que lista a URL de todos os arquivos armazenados em um determinado caminho (em termos do S3, é chamado de prefixo):
abstract class AWS_S3 { // Continue from above... function get_file_urls($prefix) { $s3Client = $this->get_s3_client(); $result = $s3Client->listObjects(array( 'Bucket' => $this->get_bucket(), 'Prefix' => $prefix )); $file_urls = array(); if(isset($result['Contents']) && count($result['Contents']) > 0 ) { foreach ($result['Contents'] as $obj) { // Check that Key is a full file path and not just a "directory" if ($obj['Key'] != $prefix) { $file_urls[] = $this->get_bucket_url().$obj['Key']; } } } return $file_urls; } }Então, se estivermos armazenando cada avatar no caminho “/users/${user_id}/“, passando este prefixo, obteremos a lista de todos os arquivos:
$user_id = get_current_user_id(); $prefix = "/users/${user_id}/"; foreach ($avatarcropper->get_file_urls($prefix) as $file_url) { printf( "<img src='%s'>", $file_url ); }Conclusão
Neste artigo, exploramos como empregar uma solução de armazenamento de objetos em nuvem para atuar como um repositório comum para armazenar arquivos para um aplicativo implantado em vários servidores. Para a solução, focamos no AWS S3 e passamos a mostrar as etapas necessárias para ser integrada ao aplicativo: criação do bucket, configuração das permissões do usuário e download e instalação do SDK. Por fim, explicamos como evitar armadilhas de segurança no aplicativo e vimos exemplos de código demonstrando como realizar as operações mais básicas no S3: upload, download e listagem de arquivos, que mal exigiam algumas linhas de código cada. A simplicidade da solução mostra que a integração de serviços em nuvem ao aplicativo não é difícil, e também pode ser realizada por desenvolvedores que não têm muita experiência com a nuvem.