
A Ascensão das Máquinas de Estado
Publicados: 2022-03-10Já estamos em 2018, e inúmeros desenvolvedores front-end ainda estão liderando uma batalha contra a complexidade e a imobilidade. Mês após mês, eles procuraram o Santo Graal: uma arquitetura de aplicativo livre de bugs que os ajudará a entregar rapidamente e com alta qualidade. Eu sou um desses desenvolvedores e encontrei algo interessante que pode ajudar.
Demos um bom passo à frente com ferramentas como React e Redux. No entanto, eles não são suficientes por conta própria em aplicativos de grande escala. Este artigo apresentará a você o conceito de máquinas de estado no contexto do desenvolvimento front-end. Você provavelmente já construiu vários deles sem perceber.
Uma introdução às máquinas de estado
Uma máquina de estado é um modelo matemático de computação. É um conceito abstrato pelo qual a máquina pode ter diferentes estados, mas em um determinado momento cumpre apenas um deles. Existem diferentes tipos de máquinas de estado. A mais famosa, acredito, é a máquina de Turing. É uma máquina de estados infinita, o que significa que pode ter um número incontável de estados. A máquina de Turing não se encaixa bem no desenvolvimento de UI atual porque na maioria dos casos temos um número finito de estados. É por isso que máquinas de estado finito, como Mealy e Moore, fazem mais sentido.
A diferença entre eles é que a máquina de Moore muda seu estado com base apenas em seu estado anterior. Infelizmente, temos muitos fatores externos, como interações do usuário e processos de rede, o que significa que a máquina de Moore também não é boa o suficiente para nós. O que estamos procurando é a máquina Mealy. Ele tem um estado inicial e, em seguida, transita para novos estados com base na entrada e em seu estado atual.
Uma das maneiras mais fáceis de ilustrar como funciona uma máquina de estado é observar uma catraca. Tem um número finito de estados: bloqueado e desbloqueado. Aqui está um gráfico simples que nos mostra esses estados, com suas possíveis entradas e transições.
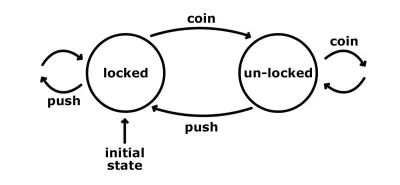
O estado inicial da catraca está bloqueado. Não importa quantas vezes possamos empurrá-lo, ele permanece nesse estado bloqueado. No entanto, se passarmos uma moeda para ele, ele passará para o estado desbloqueado. Outra moeda neste momento não faria nada; ainda estaria no estado desbloqueado. Um empurrão do outro lado funcionaria e seríamos capazes de passar. Essa ação também faz a transição da máquina para o estado bloqueado inicial.
Se quiséssemos implementar uma única função que controla a catraca, provavelmente teríamos dois argumentos: o estado atual e uma ação. E se você usa Redux, isso provavelmente soa familiar para você. É semelhante à conhecida função redutora, onde recebemos o estado atual e, com base na carga útil da ação, decidimos qual será o próximo estado. O redutor é a transição no contexto das máquinas de estado. Na verdade, qualquer aplicativo que tenha um estado que possamos alterar de alguma forma pode ser chamado de máquina de estado. É só que estamos implementando tudo manualmente repetidamente.
Como uma máquina de estado é melhor?
No trabalho, usamos Redux, e estou muito feliz com isso. No entanto, comecei a ver padrões que não gosto. Por “não gosto”, não quero dizer que eles não funcionam. É mais que eles adicionam complexidade e me obrigam a escrever mais código. Eu tive que realizar um projeto paralelo no qual eu tinha espaço para experimentar, e decidi repensar nossas práticas de desenvolvimento React e Redux. Comecei a fazer anotações sobre as coisas que me preocupavam e percebi que uma abstração de máquina de estado realmente resolveria alguns desses problemas. Vamos entrar e ver como implementar uma máquina de estado em JavaScript.
Vamos atacar um problema simples. Queremos buscar dados de uma API de back-end e exibi-los ao usuário. O primeiro passo é aprender a pensar em estados, em vez de transições. Antes de entrarmos nas máquinas de estado, meu fluxo de trabalho para criar esse recurso costumava ser algo assim:
- Exibimos um botão de busca de dados.
- O usuário clica no botão buscar dados.
- Dispare a solicitação para o back-end.
- Recupere os dados e analise-os.
- Mostre para o usuário.
- Ou, se houver um erro, exiba a mensagem de erro e mostre o botão fetch-data para que possamos acionar o processo novamente.
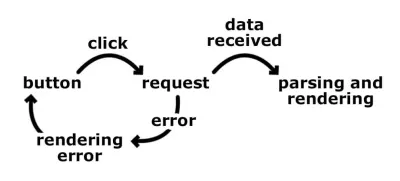
Estamos pensando de forma linear e basicamente tentando cobrir todas as direções possíveis para o resultado final. Um passo leva a outro, e rapidamente começaríamos a ramificar nosso código. E quanto a problemas como o usuário clicar duas vezes no botão, ou o usuário clicar no botão enquanto aguardamos a resposta do back-end, ou a solicitação ser bem-sucedida, mas os dados serem corrompidos. Nesses casos, provavelmente teríamos vários sinalizadores que nos mostrariam o que aconteceu. Ter sinalizadores significa mais cláusulas if e, em aplicativos mais complexos, mais conflitos.
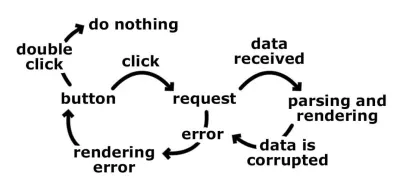
Isso ocorre porque estamos pensando em transições. Estamos nos concentrando em como essas transições acontecem e em que ordem. Concentrar-se nos vários estados do aplicativo seria muito mais simples. Quantos estados temos e quais são suas possíveis entradas? Usando o mesmo exemplo:
- ocioso
Nesse estado, exibimos o botão fetch-data, senta e espera. A ação possível é:- clique
Quando o usuário clica no botão, estamos disparando a solicitação para o back-end e, em seguida, fazemos a transição da máquina para um estado de “busca”.
- clique
- buscando
O pedido está em andamento, e nós sentamos e esperamos. As ações são:- sucesso
Os dados chegam com sucesso e não estão corrompidos. Usamos os dados de alguma forma e fazemos a transição de volta para o estado “inativo”. - falha
Se houver um erro ao fazer a solicitação ou analisar os dados, passamos para um estado de “erro”.
- sucesso
- erro
Mostramos uma mensagem de erro e exibimos o botão fetch-data. Este estado aceita uma ação:- tente novamente
Quando o usuário clica no botão de repetição, disparamos a solicitação novamente e fazemos a transição da máquina para o estado “buscando”.
- tente novamente
Descrevemos aproximadamente os mesmos processos, mas com estados e entradas.
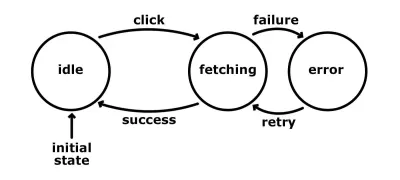
Isso simplifica a lógica e a torna mais previsível. Ele também resolve alguns dos problemas mencionados acima. Observe que, enquanto estamos no estado “buscando”, não estamos aceitando nenhum clique. Portanto, mesmo que o usuário clique no botão, nada acontecerá porque a máquina não está configurada para responder a essa ação enquanto estiver nesse estado. Essa abordagem elimina automaticamente a ramificação imprevisível de nossa lógica de código. Isso significa que teremos menos código para cobrir durante o teste . Além disso, alguns tipos de teste, como teste de integração, podem ser automatizados. Pense em como teríamos uma ideia muito clara do que nosso aplicativo faz e poderíamos criar um script que passasse pelos estados e transições definidos e que gerasse asserções. Essas afirmações podem provar que alcançamos todos os estados possíveis ou percorremos uma jornada específica.
Na verdade, escrever todos os estados possíveis é mais fácil do que escrever todas as transições possíveis porque sabemos quais estados precisamos ou temos. A propósito, na maioria dos casos, os estados descreveriam a lógica de negócios do nosso aplicativo, enquanto as transições são muitas vezes desconhecidas no início. Os bugs em nosso software são resultado de ações despachadas em um estado errado e/ou na hora errada. Eles deixam nosso aplicativo em um estado que não conhecemos, e isso interrompe nosso programa ou faz com que ele se comporte incorretamente. Claro, não queremos estar em tal situação. Máquinas de estado são bons firewalls . Eles nos protegem de alcançar estados desconhecidos porque estabelecemos limites para o que pode acontecer e quando, sem dizer explicitamente como. O conceito de uma máquina de estado combina muito bem com um fluxo de dados unidirecional. Juntos, eles reduzem a complexidade do código e esclarecem o mistério de onde um estado se originou.
Criando uma máquina de estado em JavaScript
Chega de conversa - vamos ver algum código. Usaremos o mesmo exemplo. Com base na lista acima, começaremos com o seguinte:
const machine = { 'idle': { click: function () { ... } }, 'fetching': { success: function () { ... }, failure: function () { ... } }, 'error': { 'retry': function () { ... } } }Temos os estados como objetos e suas possíveis entradas como funções. O estado inicial está ausente, no entanto. Vamos alterar o código acima para este:
const machine = { state: 'idle', transitions: { 'idle': { click: function() { ... } }, 'fetching': { success: function() { ... }, failure: function() { ... } }, 'error': { 'retry': function() { ... } } } }Uma vez que definimos todos os estados que fazem sentido para nós, estamos prontos para enviar a entrada e alterar o estado. Faremos isso usando os dois métodos auxiliares abaixo:
const machine = { dispatch(actionName, ...payload) { const actions = this.transitions[this.state]; const action = this.transitions[this.state][actionName]; if (action) { action.apply(machine, ...payload); } }, changeStateTo(newState) { this.state = newState; }, ... } A função dispatch verifica se existe uma ação com o nome dado nas transições do estado atual. Em caso afirmativo, ele o dispara com a carga útil fornecida. Também estamos chamando o manipulador de action com a machine como contexto, para que possamos despachar outras ações com this.dispatch(<action>) ou alterar o estado com this.changeStateTo(<new state>) .
Seguindo a jornada do usuário do nosso exemplo, a primeira ação que temos para despachar é click . Aqui está a aparência do manipulador dessa ação:
transitions: { 'idle': { click: function () { this.changeStateTo('fetching'); service.getData().then( data => { try { this.dispatch('success', JSON.parse(data)); } catch (error) { this.dispatch('failure', error) } }, error => this.dispatch('failure', error) ); } }, ... } machine.dispatch('click'); Primeiro mudamos o estado da máquina para fetching . Em seguida, acionamos a solicitação para o back-end. Vamos supor que temos um serviço com um método getData que retorna uma promessa. Assim que for resolvido e a análise dos dados estiver OK, despachamos success , se não failure .
Até agora tudo bem. Em seguida, temos que implementar ações e entradas de success e failure no estado de fetching :
transitions: { 'idle': { ... }, 'fetching': { success: function (data) { // render the data this.changeStateTo('idle'); }, failure: function (error) { this.changeStateTo('error'); } }, ... } Observe como liberamos nosso cérebro de ter que pensar sobre o processo anterior. Não nos importamos com os cliques do usuário ou o que está acontecendo com a solicitação HTTP. Sabemos que o aplicativo está em um estado de fetching e esperamos apenas essas duas ações. É um pouco como escrever uma nova lógica isoladamente.
O último bit é o estado de error . Seria bom fornecer essa lógica de repetição para que o aplicativo possa se recuperar de uma falha.
transitions: { 'error': { retry: function () { this.changeStateTo('idle'); this.dispatch('click'); } } } Aqui temos que duplicar a lógica que escrevemos no manipulador de click . Para evitar isso, devemos definir o manipulador como uma função acessível a ambas as ações ou primeiro fazemos a transição para o estado idle e, em seguida, despachamos a ação de click manualmente.
Um exemplo completo da máquina de estado de trabalho pode ser encontrado no meu Codepen.
Gerenciando máquinas de estado com uma biblioteca
O padrão de máquina de estado finito funciona independentemente de usarmos React, Vue ou Angular. Como vimos na seção anterior, podemos implementar facilmente uma máquina de estado sem muitos problemas. No entanto, às vezes uma biblioteca oferece mais flexibilidade. Alguns dos bons são Machina.js e XState. Neste artigo, no entanto, falaremos sobre o Stent, minha biblioteca semelhante ao Redux que se baseia no conceito de máquinas de estado finito.
Stent é uma implementação de um contêiner de máquinas de estado. Ele segue algumas das ideias dos projetos Redux e Redux-Saga, mas fornece, na minha opinião, processos mais simples e livres de clichês. Ele é desenvolvido usando desenvolvimento orientado a readme, e eu literalmente passei semanas apenas no design da API. Como eu estava escrevendo a biblioteca, tive a chance de corrigir os problemas que encontrei ao usar as arquiteturas Redux e Flux.

Criando Máquinas
Na maioria dos casos, nossos aplicativos abrangem vários domínios. Não podemos ir com apenas uma máquina. Assim, o Stent permite a criação de muitas máquinas:
import { Machine } from 'stent'; const machineA = Machine.create('A', { state: ..., transitions: ... }); const machineB = Machine.create('B', { state: ..., transitions: ... }); Mais tarde, podemos obter acesso a essas máquinas usando o método Machine.get :
const machineA = Machine.get('A'); const machineB = Machine.get('B');Conectando as máquinas à lógica de renderização
A renderização no meu caso é feita via React, mas podemos usar qualquer outra biblioteca. Tudo se resume a disparar um retorno de chamada no qual acionamos a renderização. Um dos primeiros recursos em que trabalhei foi a função connect :
import { connect } from 'stent/lib/helpers'; Machine.create('MachineA', ...); Machine.create('MachineB', ...); connect() .with('MachineA', 'MachineB') .map((MachineA, MachineB) => { ... rendering here }); Dizemos quais máquinas são importantes para nós e damos seus nomes. O retorno de chamada que passamos para map é acionado uma vez inicialmente e depois sempre que o estado de algumas das máquinas muda. É aqui que acionamos a renderização. Neste ponto, temos acesso direto às máquinas conectadas, para que possamos recuperar o estado e os métodos atuais. Há também mapOnce , para obter o retorno de chamada acionado apenas uma vez, e mapSilent , para pular essa execução inicial.
Por conveniência, um auxiliar é exportado especificamente para integração com React. É realmente semelhante ao connect(mapStateToProps) do Redux.
import React from 'react'; import { connect } from 'stent/lib/react'; class TodoList extends React.Component { render() { const { isIdle, todos } = this.props; ... } } // MachineA and MachineB are machines defined // using Machine.create function export default connect(TodoList) .with('MachineA', 'MachineB') .map((MachineA, MachineB) => { isIdle: MachineA.isIdle, todos: MachineB.state.todos }); Stent executa nosso callback de mapeamento e espera receber um objeto — um objeto que é enviado como props para nosso componente React.
O que é estado no contexto do stent?
Até agora, nosso estado era strings simples. Infelizmente, no mundo real, temos que manter mais do que uma string em estado. É por isso que o estado do Stent é na verdade um objeto com propriedades dentro. A única propriedade reservada é name . Todo o resto são dados específicos do aplicativo. Por exemplo:
{ name: 'idle' } { name: 'fetching', todos: [] } { name: 'forward', speed: 120, gear: 4 }Minha experiência com Stent até agora me mostra que, se o objeto de estado se tornar maior, provavelmente precisaremos de outra máquina que lide com essas propriedades adicionais. Identificar os vários estados leva algum tempo, mas acredito que este seja um grande passo à frente na escrita de aplicativos mais gerenciáveis. É um pouco como prever o futuro e desenhar quadros das ações possíveis.
Trabalhando com a máquina de estado
Semelhante ao exemplo no início, temos que definir os estados possíveis (finitos) de nossa máquina e descrever as entradas possíveis:
import { Machine } from 'stent'; const machine = Machine.create('sprinter', { state: { name: 'idle' }, // initial state transitions: { 'idle': { 'run please': function () { return { name: 'running' }; } }, 'running': { 'stop now': function () { return { name: 'idle' }; } } } }); Temos nosso estado inicial, idle , que aceita uma ação de run . Uma vez que a máquina está em estado de running , podemos disparar a ação de stop , que nos traz de volta ao estado idle .
Você provavelmente se lembrará dos auxiliares dispatch e changeStateTo de nossa implementação anterior. Essa biblioteca fornece a mesma lógica, mas está oculta internamente e não precisamos pensar nisso. Por conveniência, com base na propriedade de transitions , o Stent gera o seguinte:
- métodos auxiliares para verificar se a máquina está em um estado específico — o estado
idleproduz o métodoisIdle(), enquanto pararunningtemosisRunning(); - métodos auxiliares para despachar ações:
runPlease()estopNow().
Então, no exemplo acima, podemos usar isso:
machine.isIdle(); // boolean machine.isRunning(); // boolean machine.runPlease(); // fires action machine.stopNow(); // fires action Combinando os métodos gerados automaticamente com a função de utilidade de connect , podemos fechar o círculo. Uma interação do usuário aciona a entrada e a ação da máquina, que atualiza o estado. Por causa dessa atualização, a função de mapeamento passada para connect é acionada e somos informados sobre a mudança de estado. Então, nós renderizamos.
Manipuladores de entrada e ação
Provavelmente, a parte mais importante são os manipuladores de ação. Este é o lugar onde escrevemos a maior parte da lógica do aplicativo porque estamos respondendo à entrada e aos estados alterados. Algo que eu realmente gosto no Redux também está integrado aqui: a imutabilidade e simplicidade da função redutora. A essência do manipulador de ação do Stent é a mesma. Ele recebe o estado atual e a carga útil da ação e deve retornar o novo estado. Se o manipulador não retornar nada ( undefined ), o estado da máquina permanecerá o mesmo.
transitions: { 'fetching': { 'success': function (state, payload) { const todos = [ ...state.todos, payload ]; return { name: 'idle', todos }; } } } Vamos supor que precisamos buscar dados de um servidor remoto. Disparamos a solicitação e fazemos a transição da máquina para um estado de fetching . Quando os dados vêm do back-end, acionamos uma ação de success , assim:
machine.success({ label: '...' }); Então, voltamos para um estado idle e mantemos alguns dados na forma do array todos . Há alguns outros valores possíveis para definir como manipuladores de ação. O primeiro e mais simples caso é quando passamos apenas uma string que se torna o novo estado.
transitions: { 'idle': { 'run': 'running' } } Esta é uma transição de { name: 'idle' } para { name: 'running' } usando a ação run() . Essa abordagem é útil quando temos transições de estado síncronas e não temos metadados. Então, se mantivermos outra coisa no estado, esse tipo de transição a eliminará. Da mesma forma, podemos passar um objeto de estado diretamente:
transitions: { 'editing': { 'delete all todos': { name: 'idle', todos: [] } } } Estamos passando da editing para idle usando a ação deleteAllTodos .
Já vimos o manipulador de função, e a última variante do manipulador de ação é uma função geradora. Ele é inspirado no projeto Redux-Saga, e se parece com isso:
import { call } from 'stent/lib/helpers'; Machine.create('app', { 'idle': { 'fetch data': function * (state, payload) { yield { name: 'fetching' } try { const data = yield call(requestToBackend, '/api/todos/', 'POST'); return { name: 'idle', data }; } catch (error) { return { name: 'error', error }; } } } });Se você não tem experiência com geradores, isso pode parecer um pouco enigmático. Mas os geradores em JavaScript são uma ferramenta poderosa. Temos permissão para pausar nosso manipulador de ações, alterar o estado várias vezes e lidar com a lógica assíncrona.
Diversão com geradores
Quando fui apresentado ao Redux-Saga pela primeira vez, pensei que era uma maneira muito complicada de lidar com operações assíncronas. Na verdade, é uma implementação bastante inteligente do padrão de design de comando. O principal benefício desse padrão é que ele separa a invocação da lógica e sua implementação real.
Em outras palavras, dizemos o que queremos, mas não como deve acontecer. A série de blogs de Matt Hink me ajudou a entender como as sagas são implementadas, e eu recomendo fortemente a leitura. Trouxe as mesmas ideias para o Stent e, para o propósito deste artigo, diremos que, ao ceder coisas, estamos dando instruções sobre o que queremos sem realmente fazê-lo. Uma vez que a ação é executada, recebemos o controle de volta.
No momento, algumas coisas podem ser enviadas (rendidas):
- um objeto de estado (ou uma string) para alterar o estado da máquina;
- uma chamada do auxiliar de
call(ele aceita uma função síncrona, que é uma função que retorna uma promessa ou outra função geradora) — estamos basicamente dizendo: “Execute isso para mim e, se for assíncrono, espere. Quando terminar, me dê o resultado.”; - uma chamada do auxiliar de
wait(aceita uma string representando outra ação); se usarmos essa função utilitária, pausamos o manipulador e esperamos que outra ação seja despachada.
Aqui está uma função que ilustra as variantes:
const fireHTTPRequest = function () { return new Promise((resolve, reject) => { // ... }); } ... transitions: { 'idle': { 'fetch data': function * () { yield 'fetching'; // sets the state to { name: 'fetching' } yield { name: 'fetching' }; // same as above // wait for getTheData and checkForErrors actions // to be dispatched const [ data, isError ] = yield wait('get the data', 'check for errors'); // wait for the promise returned by fireHTTPRequest // to be resolved const result = yield call(fireHTTPRequest, '/api/data/users'); return { name: 'finish', users: result }; } } }Como podemos ver, o código parece síncrono, mas na verdade não é. É apenas Stent fazendo a parte chata de esperar pela promessa resolvida ou iterando sobre outro gerador.
Como o Stent está resolvendo minhas preocupações com o Redux
Código de Caldeira em Excesso
A arquitetura Redux (e Flux) depende de ações que circulam em nosso sistema. Quando o aplicativo cresce, geralmente acabamos tendo muitas constantes e criadores de ação. Essas duas coisas geralmente estão em pastas diferentes, e acompanhar a execução do código às vezes leva tempo. Além disso, ao adicionar um novo recurso, sempre temos que lidar com todo um conjunto de ações, o que significa definir mais nomes de ações e criadores de ações.
No Stent, não temos nomes de ação, e a biblioteca cria os criadores de ação automaticamente para nós:
const machine = Machine.create('todo-app', { state: { name: 'idle', todos: [] }, transitions: { 'idle': { 'add todo': function (state, todo) { ... } } } }); machine.addTodo({ title: 'Fix that bug' }); Temos o criador da ação machine.addTodo definido diretamente como um método da máquina. Essa abordagem também resolveu outro problema que enfrentei: encontrar o redutor que responde a uma determinada ação. Normalmente, em componentes React, vemos nomes de criadores de ações como addTodo ; porém, nos redutores, trabalhamos com um tipo de ação que é constante. Às vezes eu tenho que pular para o código do criador de ação apenas para que eu possa ver o tipo exato. Aqui, não temos nenhum tipo.
Mudanças de estado imprevisíveis
Em geral, o Redux faz um bom trabalho gerenciando o estado de maneira imutável. O problema não está no Redux em si, mas no fato de que o desenvolvedor pode despachar qualquer ação a qualquer momento. Se dissermos que temos uma ação que acende as luzes, tudo bem disparar essa ação duas vezes seguidas? Se não, então como devemos resolver esse problema com o Redux? Bem, provavelmente colocaríamos algum código no redutor que protegesse a lógica e que verificasse se as luzes já estão acesas - talvez uma cláusula if que verifique o estado atual. Agora a questão é, isso não está além do escopo do redutor? O redutor deve saber sobre esses casos extremos?
O que está faltando no Redux é uma maneira de parar o envio de uma ação com base no estado atual do aplicativo sem poluir o redutor com lógica condicional. E também não quero tomar essa decisão para a camada de visualização, onde o criador da ação é acionado. Com o Stent, isso acontece automaticamente porque a máquina não responde a ações que não são declaradas no estado atual. Por exemplo:
const machine = Machine.create('app', { state: { name: 'idle' }, transitions: { 'idle': { 'run': 'running', 'jump': 'jumping' }, 'running': { 'stop': 'idle' } } }); // this is fine machine.run(); // This will do nothing because at this point // the machine is in a 'running' state and there is // only 'stop' action there. machine.jump();O fato de a máquina aceitar apenas entradas específicas em um determinado momento nos protege de bugs estranhos e torna nossas aplicações mais previsíveis.
Estados, não transições
Redux, como Flux, nos faz pensar em termos de transições. O modelo mental de desenvolvimento com Redux é basicamente orientado por ações e como essas ações transformam o estado em nossos redutores. Isso não é ruim, mas descobri que faz mais sentido pensar em termos de estados - em quais estados o aplicativo pode estar e como esses estados representam os requisitos de negócios.
Conclusão
O conceito de máquinas de estado na programação, especialmente no desenvolvimento de interface do usuário, foi revelador para mim. Comecei a ver máquinas de estado em todos os lugares e tenho algum desejo de sempre mudar para esse paradigma. Definitivamente, vejo os benefícios de ter estados e transições mais estritamente definidos entre eles. Estou sempre procurando maneiras de tornar meus aplicativos simples e legíveis. Acredito que as máquinas de estado são um passo nessa direção. O conceito é simples e ao mesmo tempo poderoso. Ele tem o potencial de eliminar muitos bugs.