
Ferramentas de dados quantitativos para designers de UX
Publicados: 2022-03-10Muitos designers de UX têm um pouco de medo de dados, acreditando que isso requer profundo conhecimento de estatística e matemática. Embora isso possa ser verdade para a ciência de dados avançada, não é verdade para a análise de dados de pesquisa básica exigida pela maioria dos designers de UX. Como vivemos em um mundo cada vez mais orientado por dados, a alfabetização básica de dados é útil para quase qualquer profissional – não apenas para designers de UX.
Aaron Gitlin, designer de interação do Google, argumenta que muitos designers ainda não são orientados por dados:
“Enquanto muitas empresas se promovem como sendo orientadas por dados, a maioria dos designers é impulsionada por instinto, colaboração e métodos de pesquisa qualitativa.”
— Aaron Gitlin, “Tornar-se um designer consciente de dados”
Com este artigo, gostaria de dar aos designers de UX o conhecimento e as ferramentas para incorporar dados em suas rotinas diárias.
Mas primeiro, alguns conceitos de dados
Neste artigo falarei sobre dados estruturados, ou seja, dados que podem ser representados em uma tabela, com linhas e colunas. Dados não estruturados, sendo um assunto em si, são mais difíceis de analisar, como Devin Pickell (especialista em marketing de conteúdo da G2 Crowd, escrevendo sobre dados e análises) apontou em seu artigo “Structured vs Unstructured Data – Qual é a diferença?”. Se os dados estruturados podem ser representados em forma de tabela, os principais conceitos são:
Conjunto de dados
Todo o conjunto de dados que pretendemos analisar. Pode ser, por exemplo, uma tabela do Excel. Outro formato popular para armazenar conjuntos de dados é o arquivo de valores separados por vírgula (CSV). Os arquivos CSV são arquivos de texto simples usados para armazenar informações semelhantes a tabelas. Cada linha CSV corresponde a uma linha na tabela, e cada linha CSV possui valores separados (naturalmente) por vírgulas, que correspondem às células da tabela.
Ponto de dados
Uma única linha de uma tabela de conjunto de dados é um ponto de dados. Dessa forma, um conjunto de dados é uma coleção de pontos de dados.
Variável de dados
Um único valor de uma linha de ponto de dados representa uma variável de dados — simplificando, uma célula de tabela. Podemos ter dois tipos de variáveis de dados: variáveis qualitativas e variáveis quantitativas. As variáveis qualitativas (também conhecidas como variáveis categóricas) têm um conjunto discreto de valores, como color = red/green/blue . As variáveis quantitativas possuem valores numéricos, como height = 167 . Uma variável quantitativa, diferentemente de uma qualitativa, pode assumir qualquer valor.
Criando nosso projeto de dados
Agora que sabemos o básico, é hora de colocar a mão na massa e criar nosso primeiro projeto de dados. O escopo do projeto é analisar um conjunto de dados passando por todo o fluxo de dados de importação, processamento e plotagem de dados. Primeiro, escolheremos nosso conjunto de dados, depois baixaremos e instalaremos as ferramentas para analisar os dados.
Conjunto de dados de carros
Para o propósito deste artigo, escolhi um conjunto de dados de carros porque é simples e intuitivo. A análise de dados simplesmente confirmará o que já sabemos sobre os carros – o que é bom, já que nosso foco está no fluxo de dados e nas ferramentas.
Podemos baixar um conjunto de dados de carros usados do Kaggle, uma das maiores fontes de conjuntos de dados gratuitos. Você precisará se registrar primeiro.
Depois de baixar o arquivo, abra-o e dê uma olhada. É um arquivo CSV muito grande, mas você deve entender a essência. Uma linha neste arquivo ficará assim:
19500,2015,2965,Miami,FL,WBA3B1G54FNT02351,BMW,3Como você pode ver, este ponto de dados possui várias variáveis separadas por vírgulas. Já que agora temos o conjunto de dados, vamos falar um pouco sobre ferramentas.
Ferramentas do comércio
Usaremos a linguagem R e o RStudio para analisar o conjunto de dados. R é uma linguagem muito popular e fácil de aprender, usada não apenas por cientistas de dados, mas também por pessoas do mercado financeiro, medicina e muitas outras áreas. O RStudio é o ambiente onde os projetos em R são desenvolvidos, e existe uma versão gratuita, que é mais que suficiente para nossas necessidades como UX designers.
É provável que alguns designers de UX usem o Excel para seu fluxo de trabalho de dados. Se isso significa você, experimente o R - há uma boa chance de você gostar, pois é fácil de aprender e mais flexível e poderoso que o Excel. Adicionar R ao seu kit de ferramentas fará a diferença.
Instalando as ferramentas
Primeiro, precisamos baixar e instalar o R e o RStudio. Você deve instalar o R primeiro, depois o RStudio. Os processos de instalação para R e RStudio são simples e diretos.
Configuração do projeto
Quando a instalação estiver concluída, crie uma pasta de projeto — eu a chamei de used-cars-prj . Nessa pasta, crie uma subpasta chamada data e copie o arquivo do conjunto de dados (baixado do Kaggle) para essa pasta e renomeie-o para used-cars.csv . Agora volte para a pasta do nosso projeto ( used-cars-prj ) e crie um arquivo de texto simples chamado used-cars.r . Você deve terminar com a mesma estrutura da captura de tela abaixo.
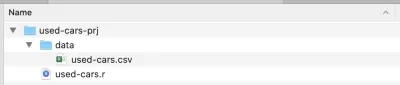
Agora que temos a estrutura de pastas no lugar, podemos abrir o RStudio e criar um novo projeto R. Escolha New Project… no menu File e selecione a segunda opção, Existing Directory . Em seguida, selecione o diretório do projeto ( used-cars-prj ). Por fim, pressione o botão Create Project e pronto. Depois que o projeto for criado, abra used-cars.r no RStudio — este é o arquivo onde adicionaremos todo o nosso código R.
Importando dados
Adicionaremos nossa primeira linha em used-cars.r , para ler os dados do arquivo used-cars.csv . Lembre-se de que os arquivos CSV são apenas arquivos de texto simples usados para armazenar dados. Nossa primeira linha de código R ficará assim:
cars <- read.csv("./data/used-cars.csv", stringsAsFactors = FALSE, sep=",") Pode parecer um pouco intimidante, mas na verdade não é – a propósito, esta é a linha mais complexa de todo o artigo. O que temos aqui é a função read.csv , que recebe três parâmetros.
O primeiro parâmetro é o arquivo a ser lido, no nosso caso used-cars.csv , que está localizado na pasta de dados . O segundo parâmetro, stringsAsFactors=FALSE é definido para garantir que strings como "BMW" ou "Audi" não sejam convertidas em fatores (o jargão R para dados categóricos) - como você se lembra, variáveis qualitativas ou categóricas podem ter apenas valores discretos como red/green/blue . Finalmente, o terceiro parâmetro, sep="," especifica o tipo de separador usado para separar valores no arquivo CSV: uma vírgula.
Depois de ler o arquivo CSV, os dados são armazenados no objeto do quadro de dados do cars . Um quadro de dados é uma estrutura de dados bidimensional (como uma tabela do Excel), que é muito útil em R para manipular dados. Depois de introduzir a linha e executá-la, um quadro de dados de cars será criado para você. Se você olhar no quadrante superior direito do RStudio, notará o quadro de dados dos cars , na seção Dados , na guia Ambiente . Se você clicar duas vezes em carros , uma nova guia será aberta no quadrante superior esquerdo do RStudio e apresentará o quadro de dados de cars . Como você pode esperar, parece uma tabela do Excel.
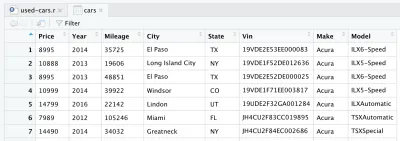
Na verdade, esses são os dados brutos que baixamos do Kaggle. Mas como queremos realizar a análise de dados, precisamos processar nosso conjunto de dados primeiro.
Processamento de dados
Por processamento, queremos dizer remover, transformar ou adicionar informações ao nosso conjunto de dados, a fim de nos preparar para o tipo de análise que queremos realizar. Temos os dados em um objeto de quadro de dados, então agora precisamos instalar a biblioteca dplyr , uma biblioteca poderosa para manipulação de dados. Para instalar a biblioteca em nosso ambiente R, precisamos escrever a seguinte linha na parte superior do nosso arquivo R.
install.packages("dplyr")Então, para adicionar a biblioteca ao nosso projeto atual, usaremos a próxima linha:
library(dplyr) Assim que a biblioteca dplyr for adicionada ao nosso projeto, podemos começar a processar os dados. Temos um conjunto de dados muito grande e precisamos apenas dos dados que representam o mesmo fabricante e modelo de carro para correlacionar isso com o preço. Usaremos o seguinte código R para manter apenas os dados relativos ao BMW Série 3 e remover o resto. Claro, você pode escolher qualquer outro fabricante e modelo do conjunto de dados e esperar ter as mesmas características de dados.
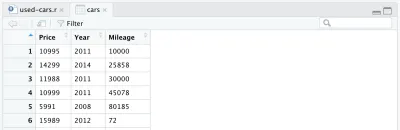
cars <- cars %>% filter(Make == "BMW", Model == "3")Agora temos um conjunto de dados mais gerenciável, embora ainda contendo mais de 11.000 pontos de dados, que se encaixam no nosso objetivo: analisar as distribuições de preço, idade e quilometragem dos carros, e também as correlações entre eles. Para isso, precisamos manter apenas as colunas “Preço”, “Ano” e “Milhagem” e remover o restante — isso é feito com a linha a seguir.
cars <- cars %>% select(Price, Year, Mileage)Depois de remover outras colunas, nosso quadro de dados ficará assim:

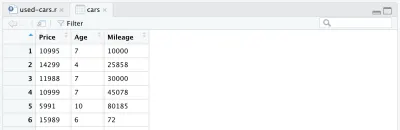
Há mais uma mudança que queremos fazer em nosso conjunto de dados: substituir o ano de fabricação pela idade do carro. Podemos adicionar as duas linhas a seguir, a primeira para calcular a idade, a segunda para alterar o nome da coluna.
cars <- cars %>% mutate(Year = max(Year) - Year) cars <- cars %>% rename(Age = Year)Por fim, nosso quadro de dados processado completo fica assim:
Neste ponto, nosso código R terá a seguinte aparência, e isso é tudo para o processamento de dados. Agora podemos ver o quão fácil e poderosa é a linguagem R. Processamos o conjunto de dados inicial de forma bastante dramática com apenas algumas linhas de código.
install.packages("dplyr") library(dplyr) cars = read.csv("./data/cars.csv", stringsAsFactors = FALSE, sep=",") cars <- cars %>% filter(Make == "BMW", Model == "3") cars <- cars %>% select(Price, Year, Mileage) cars <- cars %>% mutate(Year = max(Year) - Year) cars <- cars %>% rename(Age = Year)Análise de dados
Nossos dados estão agora na forma correta, então podemos fazer alguns gráficos. Como já mencionado, focaremos em dois aspectos: a distribuição das variáveis individuais e as correlações entre elas. A distribuição variável nos ajuda a entender o que é considerado um preço médio ou alto para um carro usado – ou a porcentagem de carros acima de um preço específico. O mesmo se aplica para a idade e quilometragem dos carros. As correlações, por outro lado, são úteis para entender como variáveis como idade e quilometragem estão relacionadas entre si.
Dito isso, usaremos dois tipos de visualização de dados: histogramas para distribuição de variáveis e gráficos de dispersão para correlações.
Distribuição de preços
Traçar o histograma do preço do carro na linguagem R é tão fácil quanto isto:
hist(cars$Price)Uma pequena dica: se você estiver no RStudio você pode executar o código linha por linha; por exemplo, no nosso caso, você precisa executar apenas a linha acima para exibir o histograma. Não é necessário executar todo o código novamente, pois você já o executou uma vez. O histograma deve ficar assim:
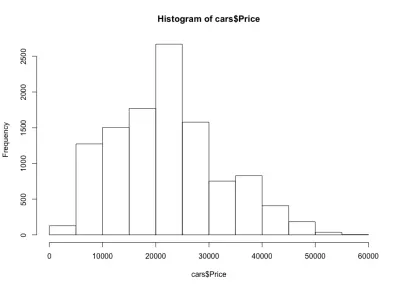
Se olharmos para o histograma, notamos uma distribuição semelhante a um sino dos preços dos carros, que era o que esperávamos. A maioria dos carros fica na faixa intermediária, e temos cada vez menos à medida que nos movemos para cada lado. Quase 80% dos carros custam entre US$ 10.000 e US$ 30.000, e temos um máximo de mais de 2.500 carros entre US$ 20.000 e US$ 25.000. No lado esquerdo, provavelmente temos cerca de 150 carros abaixo de US $ 5.000, e no lado direito ainda menos. Podemos ver facilmente como esses gráficos são úteis para obter insights sobre os dados.
Distribuição de idade
Assim como para os preços dos carros, usaremos uma linha semelhante para traçar o histograma de idade dos carros.
hist(cars$Age)E aqui está o histograma:
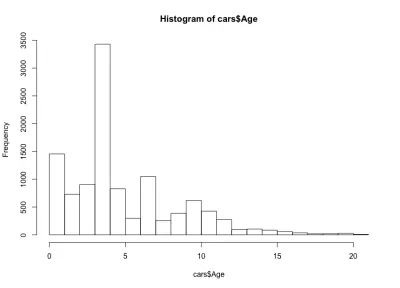
Desta vez, o histograma parece contra-intuitivo - em vez de uma forma simples de sino, temos aqui quatro sinos. Basicamente, a distribuição tem três máximos locais e um global, o que é inesperado. Seria interessante ver se essa estranha distribuição das idades dos carros permanece verdadeira para outra montadora e modelo. Para os fins deste artigo, ficaremos com o conjunto de dados do BMW Série 3, mas você pode se aprofundar nos dados se estiver curioso. Em relação à nossa distribuição etária dos carros, notamos que mais de 90% dos carros têm menos de 10 anos e mais de 80% menos de 7 anos. Além disso, notamos que a maioria dos carros tem menos de 5 anos.
Distribuição de milhas
Agora, o que podemos dizer sobre a quilometragem? Claro, esperamos ter a mesma forma de sino que tínhamos pelo preço. Aqui está o código R e o histograma:
hist(cars$Mileage) 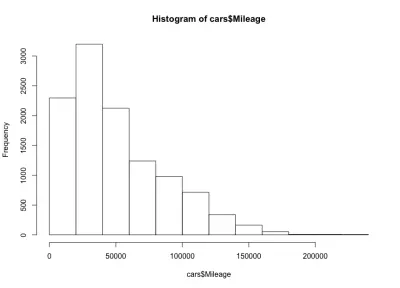
Aqui temos uma forma de sino inclinada para a esquerda, o que significa que há mais carros com menos quilometragem no mercado. Também notamos que a maioria dos carros tem menos de 60.000 milhas, e temos um máximo em torno de 20.000 a 40.000 milhas.
Correlação idade-preço
Em relação às correlações, vamos dar uma olhada mais de perto na correlação idade-preço dos carros. Podemos esperar que o preço esteja negativamente correlacionado com a idade – à medida que a idade de um carro aumenta, seu preço diminui. Usaremos a função de plot R para exibir a correlação preço-idade da seguinte forma:
plot(cars$Age, cars$Price)E o enredo fica assim:
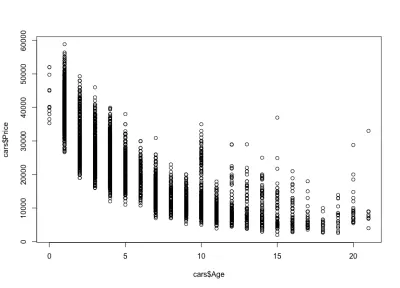
Percebemos como os preços dos carros caem com a idade: há carros novos caros e carros antigos mais baratos. Também podemos ver o intervalo de variação de preço para qualquer idade específica, uma variação que diminui com a idade do carro. Esta variação é em grande parte impulsionada pela quilometragem, configuração e estado geral do carro. Por exemplo, no caso de um carro de 4 anos, o preço varia entre US$ 10.000 e US$ 40.000.
Correlação de quilometragem-idade
Considerando a correlação quilometragem-idade, esperaríamos que a quilometragem aumentasse com a idade, significando uma correlação positiva. Aqui está o código:
plot(cars$Mileage, cars$Age)E aqui está o enredo:
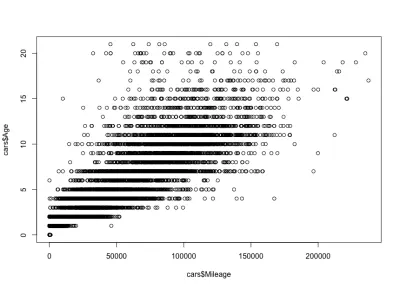
Como você pode ver, a idade e a quilometragem de um carro estão positivamente correlacionadas, ao contrário do preço e da idade de um carro, que estão negativamente correlacionados. Também temos uma variação de milhagem esperada para uma idade específica; isto é, carros da mesma idade têm quilometragem variada. Por exemplo, a maioria dos carros de 4 anos tem a quilometragem entre 10.000 e 80.000 milhas. Mas também há outliers, com maior quilometragem.
Correlação de quilometragem-preço
Como esperado, haverá uma correlação negativa entre a quilometragem dos carros e o preço, o que significa que aumentar a quilometragem reduz o preço.
plot(cars$Mileage, cars$Price)E aqui está o enredo:
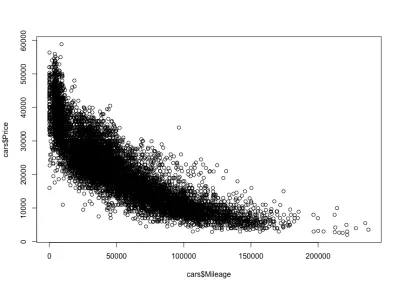
Como esperávamos, uma correlação negativa. Também podemos notar o intervalo de preço bruto entre $ 3.000 e $ 50.000 USD e a quilometragem entre 0 e 150.000. Se olharmos mais de perto a forma de distribuição, veremos que o preço cai muito mais rápido para carros com menos quilometragem do que para carros com mais quilometragem. Existem carros com quase zero quilometragem, onde o preço cai drasticamente. Além disso, acima de 200.000 milhas - porque a quilometragem é muito alta - o preço permanece constante.
De números a visualizações de dados
Neste artigo, usamos dois tipos de visualização: histogramas para distribuições de dados e gráficos de dispersão para correlações de dados. Histogramas são representações visuais que pegam os valores de uma variável de dados ( números reais) e mostram como eles são distribuídos em um intervalo. Usamos a função R hist() para traçar um histograma.
Os gráficos de dispersão, por outro lado, pegam pares de números e os representam em dois eixos. Os gráficos de dispersão usam a função plot() e fornecem dois parâmetros: a primeira e a segunda variáveis de dados da correlação que queremos investigar. Assim, as duas funções R, hist() e plot() nos ajudam a traduzir conjuntos de números em representações visuais significativas.
Conclusão
Tendo sujado as mãos ao passar por todo o fluxo de dados de importação, processamento e plotagem de dados, as coisas parecem muito mais claras agora. Você pode aplicar o mesmo fluxo de dados a qualquer novo conjunto de dados brilhante que encontrar. Na pesquisa do usuário, por exemplo, você pode representar graficamente o tempo em tarefas ou distribuições de erros, e também pode plotar um tempo em tarefas versus correlação de erros.
Para saber mais sobre a linguagem R, o Quick-R é um bom lugar para começar, mas você também pode considerar o R Bloggers. Para documentação sobre pacotes R, como dplyr , você pode visitar RDocumentation. Brincar com dados pode ser divertido, mas também é extremamente útil para qualquer designer de UX em um mundo orientado a dados. À medida que mais dados são coletados e usados para informar as decisões de negócios, há uma chance maior de os designers trabalharem na visualização de dados ou em produtos de dados, onde a compreensão da natureza dos dados é essencial.