
Como criar um serviço Pub/Sub interno usando Node.js e Redis
Publicados: 2022-03-10O mundo de hoje opera em tempo real. Seja negociando ações ou pedindo comida, os consumidores de hoje esperam resultados imediatos. Da mesma forma, todos nós esperamos saber das coisas imediatamente – seja em notícias ou esportes. Zero, em outras palavras, é o novo herói.
Isso também se aplica aos desenvolvedores de software – sem dúvida algumas das pessoas mais impacientes! Antes de mergulhar na história do BrowserStack, seria negligente da minha parte não fornecer algumas informações sobre o Pub/Sub. Para aqueles que estão familiarizados com o básico, sinta-se à vontade para pular os próximos dois parágrafos.
Muitos aplicativos hoje dependem da transferência de dados em tempo real. Vejamos mais de perto um exemplo: as redes sociais. Os gostos do Facebook e do Twitter geram feeds relevantes , e você (através do aplicativo deles) o consome e espia seus amigos. Eles fazem isso com um recurso de mensagens, em que, se um usuário gerar dados, eles serão postados para que outros consumam em nada menos que um piscar de olhos. Quaisquer atrasos significativos e os usuários reclamarão, o uso cairá e, se persistir, sairá. As apostas são altas, assim como as expectativas dos usuários. Então, como serviços como WhatsApp, Facebook, TD Ameritrade, Wall Street Journal e GrubHub suportam grandes volumes de transferências de dados em tempo real?
Todos eles usam uma arquitetura de software semelhante em alto nível chamada de modelo “Publish-Subscribe”, comumente referido como Pub/Sub.
“Na arquitetura de software, publicar-assinar é um padrão de mensagens em que os remetentes de mensagens, chamados editores, não programam as mensagens para serem enviadas diretamente a receptores específicos, chamados assinantes, mas categorizam as mensagens publicadas em classes sem conhecimento de quais assinantes, se qualquer, pode haver. Da mesma forma, os assinantes manifestam interesse em uma ou mais classes e recebem apenas mensagens de interesse, sem conhecimento de quais editores, se houver, existem.”
— Wikipédia
Entediado com a definição? De volta à nossa história.
No BrowserStack, todos os nossos produtos suportam (de uma forma ou de outra) software com um componente substancial de dependência em tempo real - sejam seus logs de testes automatizados, capturas de tela do navegador recém-criadas ou streaming móvel de 15 fps.
Nesses casos, se uma única mensagem cair, um cliente pode perder informações vitais para evitar um bug . Portanto, precisávamos dimensionar para requisitos de tamanho de dados variados. Por exemplo, com serviços de logger de dispositivo em um determinado momento, pode haver 50 MB de dados gerados em uma única mensagem. Tamanhos como esse podem travar o navegador. Sem mencionar que o sistema do BrowserStack precisaria ser dimensionado para produtos adicionais no futuro.
Como o tamanho dos dados para cada mensagem varia de alguns bytes a até 100 MB, precisávamos de uma solução escalável que pudesse suportar vários cenários. Em outras palavras, buscamos uma espada que pudesse cortar todos os bolos. Neste artigo, discutirei o porquê, como e os resultados da criação interna do nosso serviço Pub/Sub.
Através das lentes do problema do mundo real do BrowserStack, você obterá uma compreensão mais profunda dos requisitos e do processo de criação de seu próprio Pub/Sub .
Nossa necessidade de um serviço Pub/Sub
O BrowserStack tem cerca de 100 milhões de mensagens, cada uma com aproximadamente 2 bytes e mais de 100 MB. Estes são transmitidos ao redor do mundo a qualquer momento, todos em diferentes velocidades de Internet.
Os maiores geradores dessas mensagens, por tamanho de mensagem, são nossos produtos BrowserStack Automate. Ambos possuem painéis em tempo real exibindo todas as solicitações e respostas para cada comando de um teste de usuário. Portanto, se alguém executa um teste com 100 solicitações em que o tamanho médio de solicitação-resposta é de 10 bytes, isso transmite 1 × 100 × 10 = 1.000 bytes.
Agora vamos considerar o quadro maior, pois – é claro – não executamos apenas um teste por dia. Mais de aproximadamente 850.000 testes do BrowserStack Automate e App Automate são executados com o BrowserStack todos os dias. E sim, temos uma média de cerca de 235 solicitações-respostas por teste. Como os usuários podem fazer capturas de tela ou solicitar fontes de página no Selenium, nosso tamanho médio de solicitação-resposta é de aproximadamente 220 bytes.
Então, voltando à nossa calculadora:
850.000 × 235 × 220 = 43.945.000.000 bytes (aprox.) ou apenas 43,945 GB por dia
Agora vamos falar sobre o BrowserStack Live e o App Live. Certamente temos Automate como nosso vencedor em forma de tamanho de dados. No entanto, os produtos Live assumem a liderança quando se trata do número de mensagens transmitidas. Para cada teste ao vivo, cerca de 20 mensagens são passadas a cada minuto. Executamos cerca de 100.000 testes ao vivo, cada teste com uma média de cerca de 12 minutos, o que significa:
100.000 × 12 × 20 = 24.000.000 mensagens por dia
Agora para a parte incrível e notável: nós construímos, executamos e mantemos o aplicativo para este chamado pusher com 6 instâncias t1.micro de ec2. O custo de execução do serviço? Cerca de US $ 70 por mês .
Escolhendo construir versus comprar
Primeiras coisas primeiro: Como uma startup, como a maioria das outras, sempre ficamos empolgados em construir coisas internamente. Mas ainda avaliamos alguns serviços por aí. Os principais requisitos que tínhamos eram:
- Confiabilidade e estabilidade,
- Alto desempenho e
- Custo-benefício.
Vamos deixar de fora os critérios de custo-benefício, pois não consigo pensar em nenhum serviço externo que custe menos de US $ 70 por mês (tweet me se você conhece um que custa!). Portanto, nossa resposta é óbvia.
Em termos de confiabilidade e estabilidade, encontramos empresas que forneciam o Pub/Sub como serviço com SLA de mais de 99,9% de tempo de atividade, mas havia muitos T&Cs anexados. O problema não é tão simples quanto você pensa, especialmente quando você considera as vastas terras da Internet aberta que ficam entre o sistema e o cliente. Qualquer pessoa familiarizada com a infraestrutura da Internet sabe que a conectividade estável é o maior desafio. Além disso, a quantidade de dados enviados depende do tráfego. Por exemplo, um canal de dados que está em zero por um minuto pode estourar durante o próximo. Os serviços que fornecem confiabilidade adequada durante esses momentos de explosão são raros (Google e Amazon).
Desempenho para nosso projeto significa obter e enviar dados para todos os nós de escuta com latência próxima de zero . Na BrowserStack, utilizamos serviços de nuvem (AWS) juntamente com hospedagem de co-localização. No entanto, nossos editores e/ou assinantes podem ser colocados em qualquer lugar. Por exemplo, pode envolver um servidor de aplicativos da AWS gerando dados de log muito necessários ou terminais (máquinas onde os usuários podem se conectar com segurança para testes). Voltando à questão da Internet aberta novamente, se quiséssemos reduzir nosso risco, teríamos que garantir que nosso Pub/Sub aproveitasse os melhores serviços de host e AWS.
Outro requisito essencial era a capacidade de transmitir todos os tipos de dados (Bytes, texto, dados de mídia estranhos, etc.). Com tudo considerado, não fazia sentido confiar em uma solução de terceiros para oferecer suporte aos nossos produtos. Por sua vez, decidimos reviver nosso espírito de startup, arregaçando as mangas para codificar nossa própria solução.

Construindo nossa solução
Pub/Sub por design significa que haverá um editor, gerando e enviando dados, e um Assinante aceitando e processando-os. Isso é semelhante a um rádio: um canal de rádio transmite (publica) conteúdo em todos os lugares dentro de um alcance. Como assinante, você pode decidir se deseja sintonizar esse canal e ouvir (ou desligar completamente o rádio).
Ao contrário da analogia do rádio em que os dados são gratuitos para todos e qualquer um pode decidir sintonizar, em nosso cenário digital precisamos de autenticação, o que significa que os dados gerados pelo editor só podem ser para um único cliente ou assinante em particular.
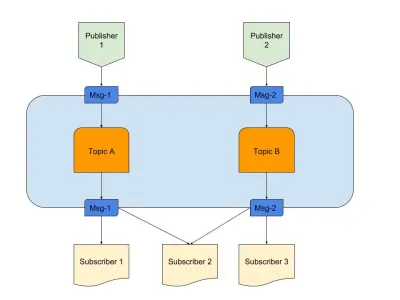
Acima está um diagrama que fornece um exemplo de um bom Pub/Sub com:
- Editores
Aqui temos dois editores gerando mensagens com base em lógica pré-definida. Em nossa analogia de rádio, esses são nossos jockeys de rádio criando o conteúdo. - Tópicos
Existem dois aqui, o que significa que existem dois tipos de dados. Podemos dizer que estes são os nossos canais de rádio 1 e 2. - Assinantes
Temos três que cada um lê dados sobre um determinado tópico. Uma coisa a notar é que o Assinante 2 está lendo vários tópicos. Em nossa analogia de rádio, essas são as pessoas que estão sintonizadas em um canal de rádio.
Vamos começar a entender os requisitos necessários para o serviço.
- Um componente com evento
Isso só entra em ação quando há algo para chutar. - Armazenamento temporário
Isso mantém os dados persistidos por um curto período, portanto, se o assinante estiver lento, ele ainda terá uma janela para consumi-los. - Reduzindo a latência
Conectando duas entidades em uma rede com o mínimo de saltos e distância.
Escolhemos uma pilha de tecnologia que atendeu aos requisitos acima:
- Node.js
Porque por que não? Com eventos, não precisaríamos de processamento pesado de dados, além de ser fácil de integrar. - Redis
Suporta perfeitamente dados de curta duração. Ele tem todos os recursos para iniciar, atualizar e expirar automaticamente. Ele também coloca menos carga no aplicativo.
Node.js para conectividade de lógica de negócios
Node.js é uma linguagem quase perfeita quando se trata de escrever código incorporando E/S e eventos. Nosso problema específico tinha ambos, tornando esta opção a mais prática para nossas necessidades.
Certamente outras linguagens como Java poderiam ser mais otimizadas, ou uma linguagem como Python oferece escalabilidade. No entanto, o custo de começar com essas linguagens é tão alto que um desenvolvedor pode terminar de escrever código no Node na mesma duração.
Para ser honesto, se o serviço tivesse a chance de adicionar recursos mais complicados, poderíamos ter analisado outras linguagens ou uma pilha completa. Mas aqui é um casamento feito no céu. Aqui está nosso package.json :
{ "name": "Pusher", "version": "1.0.0", "dependencies": { "bstack-analytics": "*****", // Hidden for BrowserStack reasons. :) "ioredis": "^2.5.0", "socket.io": "^1.4.4" }, "devDependencies": {}, "scripts": { "start": "node server.js" } }Simplificando, acreditamos no minimalismo, especialmente quando se trata de escrever código. Por outro lado, poderíamos ter usado bibliotecas como Express para escrever código extensível para este projeto. No entanto, nossos instintos de startup decidiram passar isso e guardá-lo para o próximo projeto. Ferramentas adicionais que usamos:
- ioredis
Esta é uma das bibliotecas mais suportadas para conectividade Redis com Node.js usada por empresas como Alibaba. - socket.io
A melhor biblioteca para conectividade graciosa e fallback com WebSocket e HTTP.
Redis para armazenamento temporário
O Redis como escala de serviço é altamente confiável e configurável. Além disso, existem muitos provedores de serviços gerenciados confiáveis para Redis, incluindo a AWS. Mesmo que você não queira usar um provedor, é fácil começar a usar o Redis.
Vamos detalhar a parte configurável. Começamos com a configuração usual de mestre-escravo, mas o Redis também vem com modos de cluster ou sentinela. Cada modo tem suas próprias vantagens.
Se pudéssemos compartilhar os dados de alguma forma, um cluster Redis seria a melhor escolha. Mas se compartilharmos os dados por qualquer heurística, teremos menos flexibilidade, pois a heurística deve ser seguida em . Menos regras, mais controle é bom para a vida!
O Redis Sentinel funciona melhor para nós, pois a pesquisa de dados é feita em apenas um nó, conectando-se em um determinado momento enquanto os dados não são fragmentados. Isso também significa que, mesmo que vários nós sejam perdidos, os dados ainda serão distribuídos e presentes em outros nós. Assim você tem mais HA e menos chances de perda. Claro, isso removeu os profissionais de ter um cluster, mas nosso caso de uso é diferente.
Arquitetura a 30.000 pés
O diagrama abaixo fornece uma imagem de alto nível de como nossos painéis Automate e App Automate funcionam. Você se lembra do sistema em tempo real que tínhamos na seção anterior?
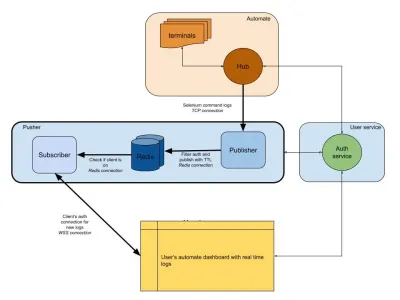
Em nosso diagrama, nosso fluxo de trabalho principal é destacado com bordas mais grossas. A seção “automatizar” consiste em:
- Terminais
Composto pelas versões originais do Windows, OSX, Android ou iOS que você obtém ao testar no BrowserStack. - Eixo
O ponto de contato para todos os seus testes de Selenium e Appium com o BrowserStack.
A seção “serviço ao usuário” aqui é nosso gatekeeper, garantindo que os dados sejam enviados e salvos para o indivíduo certo. É também o nosso guardião de segurança. A seção “empurrador” incorpora o cerne do que discutimos neste artigo. Consiste nos suspeitos usuais, incluindo:
- Redis
Nosso armazenamento transitório para mensagens, onde no nosso caso os logs automatizados são armazenados temporariamente. - Editor
Esta é basicamente a entidade que obtém os dados do hub. Todas as suas respostas de solicitação são capturadas por este componente que grava no Redis comsession_idcomo o canal. - Assinante
Isso lê os dados do Redis gerados para osession_id. Também é o servidor web para os clientes se conectarem via WebSocket (ou HTTP) para obter dados e enviá-los para clientes autenticados.
Por fim, temos a seção do navegador do usuário, representando uma conexão WebSocket autenticada para garantir que os logs session_id sejam enviados. Isso permite que o JS front-end analise e embeleze para os usuários.
Semelhante ao serviço de logs, temos um pusher aqui que está sendo usado para outras integrações de produtos. Em vez de session_id , usamos outra forma de ID para representar esse canal. Isso tudo funciona fora do empurrador!
Conclusão (TLDR)
Tivemos um sucesso considerável na criação do Pub/Sub. Para resumir por que construímos internamente:
- Escala melhor para nossas necessidades;
- Mais barato que serviços terceirizados;
- Controle total sobre a arquitetura geral.
Sem contar que o JS é o ajuste perfeito para esse tipo de cenário. Loop de eventos e grande quantidade de IO é o que o problema precisa! JavaScript é mágica de um único pseudo thread.
Eventos e Redis como um sistema simplificam as coisas para os desenvolvedores, pois você pode obter dados de uma fonte e enviá-los para outra via Redis. Então nós construímos.
Se o uso se encaixa no seu sistema, recomendo fazer o mesmo!