
Mantendo o Node.js rápido: ferramentas, técnicas e dicas para criar servidores Node.js de alto desempenho
Publicados: 2022-03-10Se você está construindo algo com Node.js há tempo suficiente, sem dúvida já experimentou a dor de problemas inesperados de velocidade. JavaScript é uma linguagem com eventos e assíncrona. Isso pode dificultar o raciocínio sobre o desempenho, como ficará evidente. A crescente popularidade do Node.js expôs a necessidade de ferramentas, técnicas e pensamento adequados às restrições do JavaScript do lado do servidor.
Quando se trata de desempenho, o que funciona no navegador não é necessariamente adequado ao Node.js. Então, como podemos garantir que uma implementação do Node.js seja rápida e adequada à finalidade? Vamos percorrer um exemplo prático.
Ferramentas
Node é uma plataforma muito versátil, mas uma das aplicações predominantes é a criação de processos em rede. Vamos nos concentrar na criação de perfil dos mais comuns: servidores web HTTP.
Precisaremos de uma ferramenta que possa explodir um servidor com muitas solicitações enquanto mede o desempenho. Por exemplo, podemos usar AutoCannon:
npm install -g autocannonOutras boas ferramentas de benchmark de HTTP incluem Apache Bench (ab) e wrk2, mas o AutoCannon é escrito em Node, fornece pressão de carga semelhante (ou às vezes maior) e é muito fácil de instalar no Windows, Linux e Mac OS X.
Depois de estabelecermos uma medição de desempenho de linha de base, se decidirmos que nosso processo pode ser mais rápido, precisaremos de alguma maneira de diagnosticar problemas com o processo. Uma ótima ferramenta para diagnosticar vários problemas de desempenho é o Node Clinic, que também pode ser instalado com o npm:
npm install -g clinicIsso realmente instala um conjunto de ferramentas. Estaremos usando Clinic Doctor e Clinic Flame (um wrapper em torno de 0x) à medida que avançamos.
Observação : para este exemplo prático, precisaremos do Node 8.11.2 ou superior.
O código
Nosso caso de exemplo é um servidor REST simples com um único recurso: uma grande carga JSON exposta como uma rota GET em /seed/v1 . O servidor é uma pasta de app que consiste em um arquivo package.json (dependendo do restify 7.1.0 ), um arquivo index.js e um arquivo util.js.
O arquivo index.js do nosso servidor tem a seguinte aparência:
'use strict' const restify = require('restify') const { etagger, timestamp, fetchContent } = require('./util')() const server = restify.createServer() server.use(etagger().bind(server)) server.get('/seed/v1', function (req, res, next) { fetchContent(req.url, (err, content) => { if (err) return next(err) res.send({data: content, url: req.url, ts: timestamp()}) next() }) }) server.listen(3000) Este servidor é representativo do caso comum de servir conteúdo dinâmico armazenado em cache do cliente. Isso é obtido com o middleware etagger , que calcula um cabeçalho ETag para o estado mais recente do conteúdo.
O arquivo util.js fornece peças de implementação que normalmente seriam usadas em tal cenário, uma função para buscar o conteúdo relevante de um back-end, o middleware etag e uma função timestamp que fornece timestamps minuto a minuto:
'use strict' require('events').defaultMaxListeners = Infinity const crypto = require('crypto') module.exports = () => { const content = crypto.rng(5000).toString('hex') const ONE_MINUTE = 60000 var last = Date.now() function timestamp () { var now = Date.now() if (now — last >= ONE_MINUTE) last = now return last } function etagger () { var cache = {} var afterEventAttached = false function attachAfterEvent (server) { if (attachAfterEvent === true) return afterEventAttached = true server.on('after', (req, res) => { if (res.statusCode !== 200) return if (!res._body) return const key = crypto.createHash('sha512') .update(req.url) .digest() .toString('hex') const etag = crypto.createHash('sha512') .update(JSON.stringify(res._body)) .digest() .toString('hex') if (cache[key] !== etag) cache[key] = etag }) } return function (req, res, next) { attachAfterEvent(this) const key = crypto.createHash('sha512') .update(req.url) .digest() .toString('hex') if (key in cache) res.set('Etag', cache[key]) res.set('Cache-Control', 'public, max-age=120') next() } } function fetchContent (url, cb) { setImmediate(() => { if (url !== '/seed/v1') cb(Object.assign(Error('Not Found'), {statusCode: 404})) else cb(null, content) }) } return { timestamp, etagger, fetchContent } }De forma alguma tome este código como um exemplo de boas práticas! Existem vários cheiros de código neste arquivo, mas vamos localizá-los à medida que medimos e criamos o perfil do aplicativo.
Para obter a fonte completa do nosso ponto de partida, o servidor lento pode ser encontrado aqui.
Perfil
Para fazer o perfil, precisamos de dois terminais, um para iniciar o aplicativo e outro para teste de carga.
Em um terminal, dentro da pasta app , podemos executar:
node index.jsEm outro terminal, podemos perfilá-lo assim:
autocannon -c100 localhost:3000/seed/v1Isso abrirá 100 conexões simultâneas e bombardeará o servidor com solicitações por dez segundos.
Os resultados devem ser algo semelhante ao seguinte (Executando 10s test @ https://localhost:3000/seed/v1 — 100 conexões):
| Estado | Média | StdevGenericName | Máx. |
|---|---|---|---|
| Latência (ms) | 3086,81 | 1725,2 | 5554 |
| Req/s | 23.1 | 19.18 | 65 |
| Bytes/s | 237,98kB | 197,7 KB | 688,13 kB |
Os resultados variam de acordo com a máquina. No entanto, considerando que um servidor Node.js “Hello World” é facilmente capaz de trinta mil solicitações por segundo na máquina que produziu esses resultados, 23 solicitações por segundo com uma latência média superior a 3 segundos é desanimador.
Diagnosticando
Descobrindo a área do problema
Podemos diagnosticar a aplicação com um único comando, graças ao comando –on-port do Clinic Doctor. Dentro da pasta do app executamos:
clinic doctor --on-port='autocannon -c100 localhost:$PORT/seed/v1' -- node index.jsIsso criará um arquivo HTML que será aberto automaticamente em nosso navegador quando a criação de perfil estiver concluída.
Os resultados devem ser algo como o seguinte:
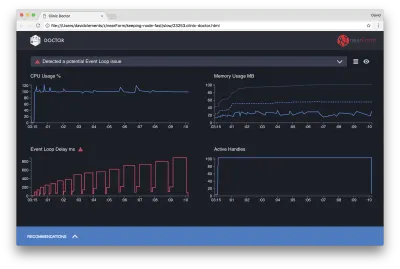
O Doutor está nos dizendo que provavelmente tivemos um problema no Event Loop.
Junto com a mensagem na parte superior da interface do usuário, também podemos ver que o gráfico Event Loop está vermelho e mostra um atraso cada vez maior. Antes de nos aprofundarmos no que isso significa, vamos primeiro entender o efeito que o problema diagnosticado está tendo nas outras métricas.
Podemos ver que a CPU está consistentemente em ou acima de 100%, pois o processo trabalha duro para processar solicitações enfileiradas. O mecanismo JavaScript do Node (V8) na verdade usa dois núcleos de CPU neste caso porque a máquina é multi-core e o V8 usa dois threads. Um para o Event Loop e outro para a Coleta de Lixo. Quando vemos a CPU aumentando em até 120% em alguns casos, o processo está coletando objetos relacionados a solicitações tratadas.
Vemos isso correlacionado no gráfico de Memória. A linha sólida no gráfico Memória é a métrica Heap Usado. Sempre que há um pico na CPU, vemos uma queda na linha Heap Used, mostrando que a memória está sendo desalocada.
Os identificadores ativos não são afetados pelo atraso do loop de eventos. Um identificador ativo é um objeto que representa E/S (como um soquete ou identificador de arquivo) ou um temporizador (como um setInterval ). Instruímos o AutoCannon a abrir 100 conexões ( -c100 ). Os identificadores ativos mantêm uma contagem consistente de 103. Os outros três são identificadores para STDOUT, STDERR e o identificador para o próprio servidor.
Se clicarmos no painel Recomendações na parte inferior da tela, devemos ver algo como o seguinte:
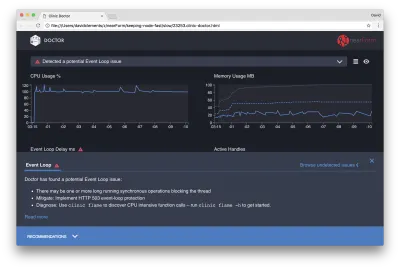
Mitigação de Curto Prazo
A análise da causa raiz de problemas sérios de desempenho pode levar tempo. No caso de um projeto implantado ao vivo, vale a pena adicionar proteção contra sobrecarga a servidores ou serviços. A ideia da proteção contra sobrecarga é monitorar o atraso do loop de eventos (entre outras coisas) e responder com “503 Serviço indisponível” se um limite for ultrapassado. Isso permite que um balanceador de carga faça failover para outras instâncias ou, na pior das hipóteses, significa que os usuários terão que atualizar. O módulo de proteção contra sobrecarga pode fornecer isso com sobrecarga mínima para Express, Koa e Restify. A estrutura Hapi tem uma configuração de carga que fornece a mesma proteção.
Entendendo a área do problema
Como a breve explicação em Clinic Doctor explica, se o Event Loop estiver atrasado para o nível que estamos observando, é muito provável que uma ou mais funções estejam “bloqueando” o Event Loop.
É especialmente importante com o Node.js reconhecer essa característica primária do JavaScript: eventos assíncronos não podem ocorrer até que o código em execução seja concluído.
É por isso que um setTimeout não pode ser preciso.
Por exemplo, tente executar o seguinte no DevTools de um navegador ou no Node REPL:
console.time('timeout') setTimeout(console.timeEnd, 100, 'timeout') let n = 1e7 while (n--) Math.random() A medição de tempo resultante nunca será de 100ms. Provavelmente estará na faixa de 150ms a 250ms. O setTimeout agendou uma operação assíncrona ( console.timeEnd ), mas o código atualmente em execução ainda não foi concluído; há mais duas linhas. O código atualmente em execução é conhecido como o “tick” atual. Para completar o tick, Math.random tem que ser chamado dez milhões de vezes. Se isso demorar 100ms, o tempo total antes que o tempo limite seja resolvido será de 200ms (mais o tempo que a função setTimeout leva para enfileirar o tempo limite antes, geralmente alguns milissegundos).
Em um contexto do lado do servidor, se uma operação no tick atual estiver demorando muito para concluir, as solicitações não poderão ser tratadas e a busca de dados não poderá ocorrer porque o código assíncrono não será executado até que o tick atual seja concluído. Isso significa que o código computacionalmente caro diminuirá a velocidade de todas as interações com o servidor. Portanto, é recomendável dividir o trabalho intenso de recursos em processos separados e chamá-los do servidor principal, isso evitará casos em que uma rota raramente usada, mas cara, diminui o desempenho de outras rotas frequentemente usadas, mas baratas.
O servidor de exemplo tem algum código que está bloqueando o Event Loop, portanto, a próxima etapa é localizar esse código.
Analisando
Uma maneira de identificar rapidamente o código com baixo desempenho é criar e analisar um gráfico em chamas. Um gráfico de chama representa chamadas de função como blocos sobrepostos - não ao longo do tempo, mas de forma agregada. A razão pela qual é chamado de 'gráfico de chama' é porque normalmente usa um esquema de cores laranja para vermelho, onde quanto mais vermelho um bloco é mais "quente" é uma função, ou seja, mais provável é que ela esteja bloqueando o loop de eventos. A captura de dados para um gráfico em chamas é realizada por meio de amostragem da CPU - o que significa que um instantâneo da função que está sendo executada no momento e sua pilha são obtidos. O calor é determinado pela porcentagem de tempo durante a criação de perfil em que uma determinada função está no topo da pilha (por exemplo, a função que está sendo executada no momento) para cada amostra. Se não for a última função a ser chamada dentro dessa pilha, é provável que esteja bloqueando o loop de eventos.
Vamos usar a clinic flame para gerar um gráfico de chama do aplicativo de exemplo:
clinic flame --on-port='autocannon -c100 localhost:$PORT/seed/v1' -- node index.jsO resultado deve abrir em nosso navegador com algo como o seguinte:
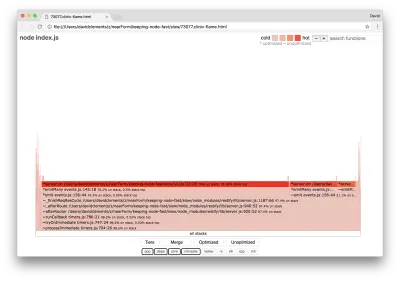
A largura de um bloco representa quanto tempo gastou na CPU em geral. Três pilhas principais podem ser observadas ocupando a maior parte do tempo, todas destacando server.on como a função mais quente. Na verdade, todas as três pilhas são iguais. Eles divergem porque, durante a criação de perfil, funções otimizadas e não otimizadas são tratadas como quadros de chamada separados. As funções prefixadas com * são otimizadas pelo mecanismo JavaScript e aquelas prefixadas com ~ não são otimizadas. Se o estado otimizado não for importante para nós, podemos simplificar ainda mais o gráfico pressionando o botão Merge. Isso deve levar a uma visualização semelhante à seguinte:
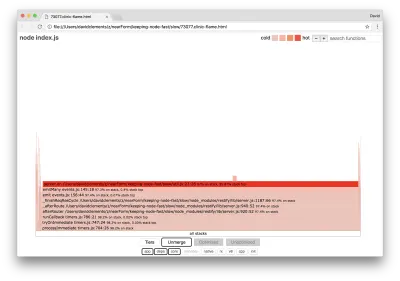
Desde o início, podemos inferir que o código incorreto está no arquivo util.js do código do aplicativo.
A função slow também é um manipulador de eventos: as funções que levam à função fazem parte do módulo de events principais e server.on é um nome de fallback para uma função anônima fornecida como uma função de manipulação de eventos. Também podemos ver que esse código não está no mesmo tick que o código que realmente trata a solicitação. Se fosse, as funções dos módulos principais http , net e stream estariam na pilha.
Essas funções centrais podem ser encontradas expandindo outras partes muito menores do gráfico em chamas. Por exemplo, tente usar a entrada de pesquisa no canto superior direito da interface do usuário para pesquisar send (o nome dos métodos internos restify e http ). Deve estar à direita do gráfico (as funções são ordenadas alfabeticamente):
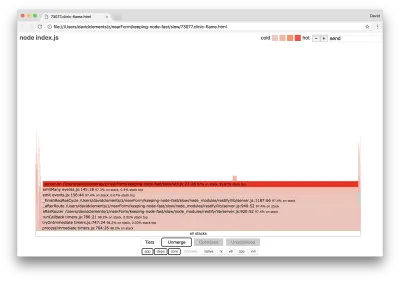
Observe como todos os blocos de manipulação HTTP reais são comparativamente pequenos.

Podemos clicar em um dos blocos destacados em ciano que se expandirá para mostrar funções como writeHead e write no arquivo http_outgoing.js (parte da biblioteca http do núcleo do Node):
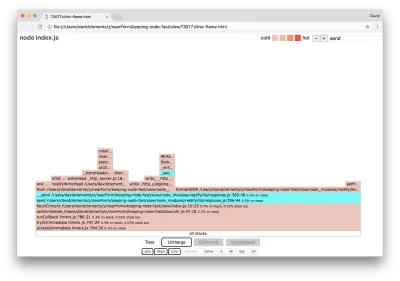
Podemos clicar em todas as pilhas para retornar à visualização principal.
O ponto-chave aqui é que, embora a função server.on não esteja no mesmo nível que o código de manipulação de solicitação real, ela ainda está afetando o desempenho geral do servidor, atrasando a execução do código de outro modo performático.
Depuração
Sabemos pelo gráfico de chamas que a função problemática é o manipulador de eventos passado para server.on no arquivo util.js.
Vamos dar uma olhada:
server.on('after', (req, res) => { if (res.statusCode !== 200) return if (!res._body) return const key = crypto.createHash('sha512') .update(req.url) .digest() .toString('hex') const etag = crypto.createHash('sha512') .update(JSON.stringify(res._body)) .digest() .toString('hex') if (cache[key] !== etag) cache[key] = etag }) É bem conhecido que a criptografia tende a ser cara, assim como a serialização ( JSON.stringify ), mas por que eles não aparecem no gráfico de chama? Essas operações estão nas amostras capturadas, mas estão ocultas atrás do filtro cpp . Se pressionarmos o botão cpp , devemos ver algo como o seguinte:
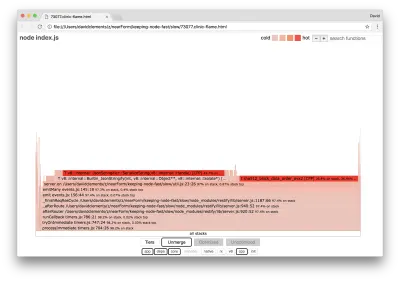
As instruções internas do V8 relacionadas à serialização e criptografia agora são mostradas como as pilhas mais quentes e ocupando a maior parte do tempo. O método JSON.stringify chama diretamente o código C++; é por isso que não vemos uma função JavaScript. No caso da criptografia, funções como createHash e update estão nos dados, mas são embutidas (o que significa que desaparecem na exibição mesclada) ou muito pequenas para serem renderizadas.
Uma vez que começamos a raciocinar sobre o código na função etagger , pode rapidamente se tornar aparente que ele foi mal projetado. Por que estamos pegando a instância do server do contexto da função? Há muito hash acontecendo, tudo isso é necessário? Também não há suporte ao cabeçalho If-None-Match na implementação, o que reduziria parte da carga em alguns cenários do mundo real, porque os clientes fariam apenas uma solicitação principal para determinar a atualização.
Vamos ignorar todos esses pontos por enquanto e validar a descoberta de que o trabalho real que está sendo executado no server.on é de fato o gargalo. Isso pode ser feito configurando o código server.on para uma função vazia e gerando um novo flamegraph.
Altere a função etagger para o seguinte:
function etagger () { var cache = {} var afterEventAttached = false function attachAfterEvent (server) { if (attachAfterEvent === true) return afterEventAttached = true server.on('after', (req, res) => {}) } return function (req, res, next) { attachAfterEvent(this) const key = crypto.createHash('sha512') .update(req.url) .digest() .toString('hex') if (key in cache) res.set('Etag', cache[key]) res.set('Cache-Control', 'public, max-age=120') next() } } A função de ouvinte de eventos passada para server.on agora não é operacional.
Vamos executar o clinic flame novamente:
clinic flame --on-port='autocannon -c100 localhost:$PORT/seed/v1' -- node index.jsIsso deve produzir um gráfico de chama semelhante ao seguinte:
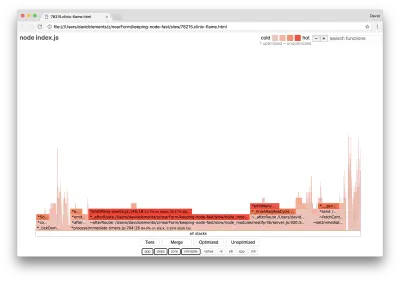
Isso parece melhor e deveríamos ter notado um aumento na solicitação por segundo. Mas por que o evento está emitindo código tão quente? Esperaríamos que, neste ponto, o código de processamento HTTP ocupasse a maior parte do tempo da CPU, não há nada sendo executado no evento server.on .
Esse tipo de gargalo é causado por uma função sendo executada mais do que deveria.
O seguinte código suspeito na parte superior do util.js pode ser uma pista:
require('events').defaultMaxListeners = Infinity Vamos remover esta linha e iniciar nosso processo com o --trace-warnings :
node --trace-warnings index.jsSe perfilarmos com o AutoCannon em outro terminal, assim:
autocannon -c100 localhost:3000/seed/v1Nosso processo produzirá algo semelhante a:
(node:96371) MaxListenersExceededWarning: Possible EventEmitter memory leak detected. 11 after listeners added. Use emitter.setMaxListeners() to increase limit at _addListener (events.js:280:19) at Server.addListener (events.js:297:10) at attachAfterEvent (/Users/davidclements/z/nearForm/keeping-node-fast/slow/util.js:22:14) at Server. (/Users/davidclements/z/nearForm/keeping-node-fast/slow/util.js:25:7) at call (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/chain.js:164:9) at next (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/chain.js:120:9) at Chain.run (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/chain.js:123:5) at Server._runUse (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/server.js:976:19) at Server._runRoute (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/server.js:918:10) at Server._afterPre (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/server.js:888:10)(node:96371) MaxListenersExceededWarning: Possible EventEmitter memory leak detected. 11 after listeners added. Use emitter.setMaxListeners() to increase limit at _addListener (events.js:280:19) at Server.addListener (events.js:297:10) at attachAfterEvent (/Users/davidclements/z/nearForm/keeping-node-fast/slow/util.js:22:14) at Server. (/Users/davidclements/z/nearForm/keeping-node-fast/slow/util.js:25:7) at call (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/chain.js:164:9) at next (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/chain.js:120:9) at Chain.run (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/chain.js:123:5) at Server._runUse (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/server.js:976:19) at Server._runRoute (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/server.js:918:10) at Server._afterPre (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/server.js:888:10)
Node está nos dizendo que muitos eventos estão sendo anexados ao objeto do servidor . Isso é estranho porque há um booleano que verifica se o evento foi anexado e, em seguida, retorna mais cedo, essencialmente tornando attachAfterEvent um no-op após o primeiro evento ser anexado.
Vamos dar uma olhada na função attachAfterEvent :
var afterEventAttached = false function attachAfterEvent (server) { if (attachAfterEvent === true) return afterEventAttached = true server.on('after', (req, res) => {}) } A verificação condicional está errada! Ele verifica se attachAfterEvent é true em vez de afterEventAttached . Isso significa que um novo evento está sendo anexado à instância do server em cada solicitação e, em seguida, todos os eventos anexados anteriores estão sendo acionados após cada solicitação. Opa!
Otimização
Agora que descobrimos as áreas problemáticas, vamos ver se podemos tornar o servidor mais rápido.
Frutos mais baixos
Vamos colocar o código do ouvinte server.on de volta (em vez de uma função vazia) e usar o nome booleano correto na verificação condicional. Nossa função etagger tem a seguinte aparência:
function etagger () { var cache = {} var afterEventAttached = false function attachAfterEvent (server) { if (afterEventAttached === true) return afterEventAttached = true server.on('after', (req, res) => { if (res.statusCode !== 200) return if (!res._body) return const key = crypto.createHash('sha512') .update(req.url) .digest() .toString('hex') const etag = crypto.createHash('sha512') .update(JSON.stringify(res._body)) .digest() .toString('hex') if (cache[key] !== etag) cache[key] = etag }) } return function (req, res, next) { attachAfterEvent(this) const key = crypto.createHash('sha512') .update(req.url) .digest() .toString('hex') if (key in cache) res.set('Etag', cache[key]) res.set('Cache-Control', 'public, max-age=120') next() } }Agora verificamos nossa correção criando o perfil novamente. Inicie o servidor em um terminal:
node index.jsEm seguida, crie um perfil com o AutoCannon:
autocannon -c100 localhost:3000/seed/v1 Devemos ver resultados em algum lugar na faixa de uma melhoria de 200 vezes (Executando 10s test @ https://localhost:3000/seed/v1 — 100 conexões):
| Estado | Média | StdevGenericName | Máx. |
|---|---|---|---|
| Latência (ms) | 19,47 | 4,29 | 103 |
| Req/s | 5011.11 | 506.2 | 5487 |
| Bytes/s | 51,8 MB | 5,45 MB | 58,72 MB |
É importante equilibrar as potenciais reduções de custo do servidor com os custos de desenvolvimento. Precisamos definir, em nossos próprios contextos situacionais, até onde precisamos ir para otimizar um projeto. Caso contrário, pode ser muito fácil colocar 80% do esforço em 20% dos aprimoramentos de velocidade. As restrições do projeto justificam isso?
Em alguns cenários, pode ser apropriado alcançar uma melhoria de 200 vezes com uma fruta fácil e encerrar o dia. Em outros, podemos querer tornar nossa implementação o mais rápida possível. Depende muito das prioridades do projeto.
Uma maneira de controlar o gasto de recursos é definir uma meta. Por exemplo, melhoria de 10 vezes ou 4.000 solicitações por segundo. Basear isso nas necessidades do negócio faz mais sentido. Por exemplo, se os custos do servidor estiverem 100% acima do orçamento, podemos definir uma meta de melhoria de 2x.
Levando mais longe
Se produzirmos um novo gráfico de chama do nosso servidor, devemos ver algo semelhante ao seguinte:
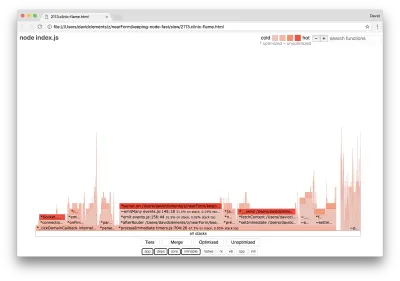
O ouvinte de eventos ainda é o gargalo, ainda está ocupando um terço do tempo de CPU durante a criação de perfil (a largura é cerca de um terço de todo o gráfico).
Que ganhos adicionais podem ser obtidos e as mudanças (junto com a interrupção associada) valem a pena?
Com uma implementação otimizada, mas um pouco mais restrita, as seguintes características de desempenho podem ser alcançadas (Executando 10s test @ https://localhost:3000/seed/v1 — 10 conexões):
| Estado | Média | StdevGenericName | Máx. |
|---|---|---|---|
| Latência (ms) | 0,64 | 0,86 | 17 |
| Req/s | 8330,91 | 757,63 | 8991 |
| Bytes/s | 84,17 MB | 7,64 MB | 92,27 MB |
Embora uma melhoria de 1,6x seja significativa, pode-se argumentar que depende da situação se o esforço, as alterações e a interrupção do código necessários para criar essa melhoria são justificados. Especialmente quando comparado à melhoria de 200x na implementação original com uma única correção de bug.
Para alcançar essa melhoria, a mesma técnica iterativa de perfil, gerar flamegraph, analisar, depurar e otimizar foi usada para chegar ao servidor final otimizado, cujo código pode ser encontrado aqui.
As mudanças finais para atingir 8000 req/s foram:
- Não construa objetos e então serialize, construa uma string de JSON diretamente;
- Use algo único sobre o conteúdo para definir sua Etag, em vez de criar um hash;
- Não faça hash da URL, use-a diretamente como a chave.
Essas mudanças são um pouco mais complicadas, um pouco mais disruptivas para a base de código, e deixam o middleware etagger um pouco menos flexível porque sobrecarrega a rota para fornecer o valor Etag . Mas atinge 3.000 solicitações extras por segundo na máquina de criação de perfil.
Vamos dar uma olhada em um gráfico de chama para essas melhorias finais:
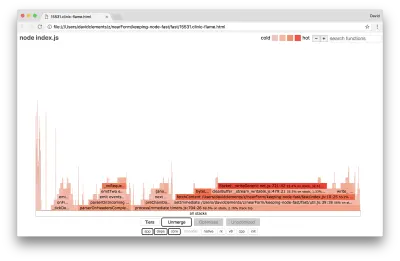
A parte mais quente do flame graph é parte do Node core, no módulo net . Isso é o ideal.
Prevenção de problemas de desempenho
Para finalizar, aqui estão algumas sugestões sobre como evitar problemas de desempenho antes de serem implantados.
O uso de ferramentas de desempenho como pontos de verificação informais durante o desenvolvimento pode filtrar bugs de desempenho antes que eles entrem em produção. Recomenda-se tornar o AutoCannon e o Clinic (ou equivalentes) parte das ferramentas de desenvolvimento diárias.
Ao comprar em uma estrutura, descubra qual é sua política de desempenho. Se a estrutura não priorizar o desempenho, é importante verificar se isso está alinhado com as práticas de infraestrutura e os objetivos de negócios. Por exemplo, Restify claramente (desde o lançamento da versão 7) investiu em melhorar o desempenho da biblioteca. No entanto, se o baixo custo e a alta velocidade forem uma prioridade absoluta, considere o Fastify, que foi medido como 17% mais rápido por um colaborador do Restify.
Fique atento a outras opções de biblioteca de grande impacto — considere especialmente o registro em log. À medida que os desenvolvedores corrigem problemas, eles podem decidir adicionar saída de log adicional para ajudar a depurar problemas relacionados no futuro. Se um registrador de baixo desempenho for usado, isso pode estrangular o desempenho ao longo do tempo, à moda da fábula do sapo em ebulição. O registrador pino é o registrador JSON delimitado por nova linha mais rápido disponível para Node.js.
Por fim, lembre-se sempre de que o Event Loop é um recurso compartilhado. Um servidor Node.js é limitado pela lógica mais lenta no caminho mais quente.