
Introdução ao Node: uma introdução às APIs, HTTP e JavaScript ES6+
Publicados: 2022-03-10Você provavelmente já ouviu falar do Node.js como sendo um “tempo de execução JavaScript assíncrono construído no mecanismo JavaScript V8 do Chrome” e que “usa um modelo de E/S sem bloqueio e orientado a eventos que o torna leve e eficiente”. Mas para alguns, essa não é a maior das explicações.
O que é o Node em primeiro lugar? O que exatamente significa para o Node ser “assíncrono” e como isso difere de “síncrono”? Qual é o significado de “orientado a eventos” e “sem bloqueio”, e como o Node se encaixa no cenário maior de aplicativos, redes de Internet e servidores?
Tentaremos responder a todas essas perguntas e muito mais ao longo desta série à medida que analisamos detalhadamente o funcionamento interno do Node, aprendemos sobre o HyperText Transfer Protocol, APIs e JSON e criamos nossa própria API Bookshelf utilizando MongoDB, Express, Lodash, Mocha e Handlebars.
O que é Node.js
Node é apenas um ambiente, ou tempo de execução, no qual se pode executar JavaScript normal (com pequenas diferenças) fora do navegador. Podemos usá-lo para criar aplicativos de desktop (com estruturas como o Electron), escrever servidores web ou de aplicativos e muito mais.
Bloqueio/Não Bloqueio e Síncrono/Assíncrono
Suponha que estamos fazendo uma chamada de banco de dados para recuperar propriedades sobre um usuário. Essa chamada vai demorar, e se a requisição estiver “bloqueando”, isso significa que ela irá bloquear a execução do nosso programa até que a chamada seja completada. Nesse caso, fizemos uma requisição “síncrona”, pois acabou bloqueando a thread.
Assim, uma operação síncrona bloqueia um processo ou encadeamento até que essa operação seja concluída, deixando o encadeamento em um “estado de espera”. Uma operação assíncrona , por outro lado, não é bloqueante . Ele permite que a execução do encadeamento prossiga independentemente do tempo que leva para a operação ser concluída ou do resultado com o qual ela é concluída, e nenhuma parte do encadeamento cai em um estado de espera em nenhum ponto.
Vejamos outro exemplo de uma chamada síncrona que bloqueia um thread. Suponha que estamos construindo um aplicativo que compara os resultados de duas APIs de clima para encontrar sua diferença percentual de temperatura. De forma bloqueante, fazemos uma chamada para Weather API One e aguardamos o resultado. Assim que obtivermos um resultado, chamamos a Weather API Two e aguardamos seu resultado. Não se preocupe neste momento se você não estiver familiarizado com APIs. Nós vamos cobri-los em uma próxima seção. Por enquanto, pense apenas em uma API como o meio pelo qual dois computadores podem se comunicar um com o outro.
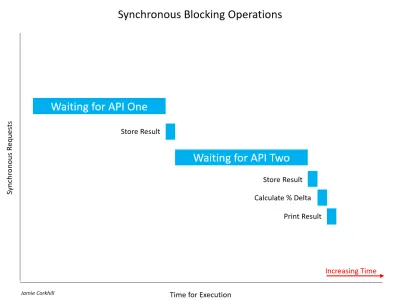
Permita-me observar que é importante reconhecer que nem todas as chamadas síncronas são necessariamente bloqueantes. Se uma operação síncrona puder ser concluída sem bloquear o encadeamento ou causar um estado de espera, ela não foi bloqueante. Na maioria das vezes, as chamadas síncronas estarão bloqueando e o tempo que elas levam para serem concluídas dependerá de vários fatores, como a velocidade dos servidores da API, a velocidade de download da conexão de Internet do usuário final etc.
No caso da imagem acima, tivemos que esperar bastante para recuperar os primeiros resultados da API One. Depois disso, tivemos que esperar o mesmo tempo para obter uma resposta da API Dois. Enquanto espera por ambas as respostas, o usuário notaria que nosso aplicativo travava – a interface do usuário literalmente travava – e isso seria ruim para a experiência do usuário.
No caso de uma chamada sem bloqueio, teríamos algo assim:

Você pode ver claramente o quão mais rápido concluímos a execução. Em vez de esperar na API One e depois esperar na API Two, poderíamos esperar que ambas fossem concluídas ao mesmo tempo e atingissem nossos resultados quase 50% mais rápido. Observe que, uma vez que chamamos a API One e começamos a esperar por sua resposta, também chamamos a API Two e começamos a esperar por sua resposta ao mesmo tempo que One.
Neste ponto, antes de passar para exemplos mais concretos e tangíveis, é importante mencionar que, para facilitar, o termo “Síncrono” geralmente é abreviado para “Síncrono”, e o termo “Assíncrono” geralmente é abreviado para “Assíncrono”. Você verá esta notação usada em nomes de métodos/funções.
Funções de retorno de chamada
Você pode estar se perguntando: “se pudermos lidar com uma chamada de forma assíncrona, como saberemos quando essa chamada terminará e teremos uma resposta?” Geralmente, passamos como um argumento para nosso método assíncrono uma função de retorno de chamada, e esse método “chamará de volta” essa função posteriormente com uma resposta. Estou usando funções ES5 aqui, mas atualizaremos para os padrões ES6 posteriormente.
function asyncAddFunction(a, b, callback) { callback(a + b); //This callback is the one passed in to the function call below. } asyncAddFunction(2, 4, function(sum) { //Here we have the sum, 2 + 4 = 6. }); Essa função é chamada de “Função de ordem superior”, pois recebe uma função (nosso retorno de chamada) como argumento. Como alternativa, uma função de retorno de chamada pode receber um objeto de erro e um objeto de resposta como argumentos e apresentá-los quando a função assíncrona for concluída. Veremos isso mais tarde com o Express. Quando chamamos asyncAddFunction(...) , você notará que fornecemos uma função de retorno de chamada para o parâmetro de retorno de chamada da definição do método. Esta função é uma função anônima (não tem nome) e é escrita usando a Sintaxe de Expressão . A definição do método, por outro lado, é uma instrução de função. Não é anônimo porque na verdade tem um nome (sendo “asyncAddFunction”).
Alguns podem notar confusão, pois, na definição do método, fornecemos um nome, que é “callback”. No entanto, a função anônima passada como o terceiro parâmetro para asyncAddFunction(...) não sabe sobre o nome e, portanto, permanece anônima. Também não podemos executar essa função posteriormente pelo nome, teríamos que passar pela função de chamada assíncrona novamente para ativá-la.
Como exemplo de uma chamada síncrona, podemos usar o método readFileSync(...) do Node.js. Novamente, estaremos migrando para o ES6+ mais tarde.
var fs = require('fs'); var data = fs.readFileSync('/example.txt'); // The thread will be blocked here until complete.Se estivéssemos fazendo isso de forma assíncrona, passaríamos uma função de retorno de chamada que seria acionada quando a operação assíncrona fosse concluída.
var fs = require('fs'); var data = fs.readFile('/example.txt', function(err, data) { //Move on, this will fire when ready. if(err) return console.log('Error: ', err); console.log('Data: ', data); // Assume var data is defined above. }); // Keep executing below, don't wait on the data. Se você nunca viu return usado dessa maneira antes, estamos apenas dizendo para parar a execução da função para não imprimir o objeto de dados se o objeto de erro estiver definido. Poderíamos também ter apenas envolvido a instrução log em uma cláusula else .
Assim como nosso asyncAddFunction(...) , o código por trás da fs.readFile(...) seria algo como:
function readFile(path, callback) { // Behind the scenes code to read a file stream. // The data variable is defined up here. callback(undefined, data); //Or, callback(err, undefined); }Permita-nos examinar uma última implementação de uma chamada de função assíncrona. Isso ajudará a solidificar a ideia de funções de retorno de chamada serem acionadas posteriormente e nos ajudará a entender a execução de um programa típico do Node.js.
setTimeout(function() { // ... }, 1000); O método setTimeout(...) recebe uma função de retorno de chamada para o primeiro parâmetro que será acionado após o número de milissegundos especificado como o segundo argumento.
Vejamos um exemplo mais complexo:
console.log('Initiated program.'); setTimeout(function() { console.log('3000 ms (3 sec) have passed.'); }, 3000); setTimeout(function() { console.log('0 ms (0 sec) have passed.'); }, 0); setTimeout(function() { console.log('1000 ms (1 sec) has passed.'); }, 1000); console.log('Terminated program');A saída que recebemos é:
Initiated program. Terminated program. 0 ms (0 sec) have passed. 1000 ms (1 sec) has passed. 3000 ms (3 sec) have passed. Você pode ver que a primeira instrução de log é executada conforme o esperado. Instantaneamente, a última declaração de log é impressa na tela, pois isso acontece antes que 0 segundos tenham ultrapassado após o segundo setTimeout(...) . Imediatamente depois, o segundo, terceiro e primeiro métodos setTimeout(...) são executados.
Se o Node.js não fosse não bloqueante, veríamos a primeira instrução de log, esperaríamos 3 segundos para ver a próxima, veríamos instantaneamente a terceira (o setTimeout(...) de 0 segundos e então teríamos que esperar mais uma segundo para ver as duas últimas instruções de log. A natureza não bloqueante do Node faz com que todos os cronômetros comecem a contagem regressiva a partir do momento em que o programa é executado, em vez da ordem em que são digitados. Você pode querer examinar as APIs do Node, as Callstack e o Event Loop para obter mais informações sobre como o Node funciona nos bastidores.
É importante observar que só porque você vê uma função de retorno de chamada não significa necessariamente que há uma chamada assíncrona no código. Chamamos o método asyncAddFunction(…) acima de “async” porque estamos assumindo que a operação leva tempo para ser concluída — como fazer uma chamada para um servidor. Na realidade, o processo de adição de dois números não é assíncrono e, portanto, esse seria um exemplo de uso de uma função de retorno de chamada de uma maneira que não bloqueie o encadeamento.
Promessas sobre retornos de chamada
Os retornos de chamada podem rapidamente se tornar confusos em JavaScript, especialmente vários retornos de chamada aninhados. Estamos familiarizados com a passagem de um callback como argumento para uma função, mas as Promises nos permitem adicionar ou anexar um callback a um objeto retornado de uma função. Isso nos permitiria lidar com várias chamadas assíncronas de uma maneira mais elegante.
Como exemplo, suponha que estamos fazendo uma chamada de API e nossa função, não tão exclusivamente chamada ' makeAPICall(...) ', recebe uma URL e um retorno de chamada.
Nossa função, makeAPICall(...) , seria definida como
function makeAPICall(path, callback) { // Attempt to make API call to path argument. // ... callback(undefined, res); // Or, callback(err, undefined); depending upon the API's response. }e chamaríamos com:
makeAPICall('/example', function(err1, res1) { if(err1) return console.log('Error: ', err1); // ... }); Se quiséssemos fazer outra chamada de API usando a resposta da primeira, teríamos que aninhar os dois callbacks. Suponha que eu precise injetar a propriedade userName do objeto res1 no caminho da segunda chamada de API. Nós teríamos:
makeAPICall('/example', function(err1, res1) { if(err1) return console.log('Error: ', err1); makeAPICall('/newExample/' + res1.userName, function(err2, res2) { if(err2) return console.log('Error: ', err2); console.log(res2); }); }); Nota : O método ES6+ para injetar a propriedade res1.userName em vez da concatenação de strings seria usar "Strings de modelo". Dessa forma, em vez de encapsular nossa string entre aspas ( ' , ou " ), usaríamos acentos graves ${} ` ). No final, nosso caminho anterior seria: /newExample/${res.UserName} , envolto em acentos graves.
É claro que esse método de aninhamento de retornos de chamada pode rapidamente se tornar bastante deselegante, o chamado “JavaScript Pyramid of Doom”. Avançando, se estivéssemos usando promessas em vez de retornos de chamada, poderíamos refatorar nosso código do primeiro exemplo como tal:
makeAPICall('/example').then(function(res) { // Success callback. // ... }, function(err) { // Failure callback. console.log('Error:', err); }); O primeiro argumento para a função then() é nosso retorno de chamada de sucesso e o segundo argumento é nosso retorno de chamada de falha. Alternativamente, poderíamos perder o segundo argumento para .then() e chamar .catch() em vez disso. Argumentos para .then() são opcionais, e chamar .catch() seria equivalente a .then(successCallback, null) .
Usando .catch() , temos:
makeAPICall('/example').then(function(res) { // Success callback. // ... }).catch(function(err) { // Failure Callback console.log('Error: ', err); });Também podemos reestruturar isso para facilitar a leitura:
makeAPICall('/example') .then(function(res) { // ... }) .catch(function(err) { console.log('Error: ', err); }); É importante notar que não podemos simplesmente incluir uma chamada .then() em qualquer função e esperar que ela funcione. A função que estamos chamando tem que retornar uma promessa, uma promessa que acionará o .then() quando a operação assíncrona for concluída. Neste caso, makeAPICall(...) fará isso, disparando o bloco then() ou o bloco catch() quando concluído.
Para fazer makeAPICall(...) retornar uma Promise, atribuímos uma função a uma variável, onde essa função é o construtor Promise. As promessas podem ser cumpridas ou rejeitadas , onde cumprida significa que a ação relacionada à promessa foi concluída com êxito e rejeitada significando o contrário. Uma vez que a promessa é cumprida ou rejeitada, dizemos que ela foi resolvida e, enquanto esperamos que ela seja resolvida, talvez durante uma chamada assíncrona, dizemos que a promessa está pendente .
O construtor Promise recebe uma função de retorno de chamada como argumento, que recebe dois parâmetros — resolve e reject , que chamaremos em um momento posterior para disparar o retorno de chamada de sucesso em .then() , ou a falha .then() callback, ou .catch() , se fornecido.
Aqui está um exemplo de como isso se parece:
var examplePromise = new Promise(function(resolve, reject) { // Do whatever we are going to do and then make the appropiate call below: resolve('Happy!'); // — Everything worked. reject('Sad!'); // — We noticed that something went wrong. }):Então, podemos usar:
examplePromise.then(/* Both callback functions in here */); // Or, the success callback in .then() and the failure callback in .catch(). Observe, no entanto, que examplePromise não pode receber argumentos. Isso meio que anula o propósito, então podemos retornar uma promessa.
function makeAPICall(path) { return new Promise(function(resolve, reject) { // Make our async API call here. if (/* All is good */) return resolve(res); //res is the response, would be defined above. else return reject(err); //err is error, would be defined above. }); } As promessas realmente brilham para melhorar a estrutura e, posteriormente, a elegância do nosso código com o conceito de “Promise Chaining”. Isso nos permitiria retornar uma nova Promise dentro de uma cláusula .then() , para que pudéssemos anexar um segundo .then() depois disso, que dispararia o retorno de chamada apropriado da segunda promessa.
Refatorando nossa chamada de URL de várias APIs acima com Promises, obtemos:
makeAPICall('/example').then(function(res) { // First response callback. Fires on success to '/example' call. return makeAPICall(`/newExample/${res.UserName}`); // Returning new call allows for Promise Chaining. }, function(err) { // First failure callback. Fires if there is a failure calling with '/example'. console.log('Error:', err); }).then(function(res) { // Second response callback. Fires on success to returned '/newExample/...' call. console.log(res); }, function(err) { // Second failure callback. Fire if there is a failure calling with '/newExample/...' console.log('Error:', err); }); Observe que primeiro chamamos makeAPICall('/example') . Isso retorna uma promessa e, portanto, anexamos um .then() . Dentro desse then() , retornamos uma nova chamada para makeAPICall(...) , que, por si só, como visto anteriormente, retorna uma promessa, permitindo-nos encadear um novo .then() após o primeiro.
Como acima, podemos reestruturar isso para facilitar a leitura e remover os retornos de chamada de falha para uma cláusula genérica catch() all. Então, podemos seguir o Princípio DRY (Don't Repeat Yourself), e só temos que implementar o tratamento de erros uma vez.
makeAPICall('/example') .then(function(res) { // Like earlier, fires with success and response from '/example'. return makeAPICall(`/newExample/${res.UserName}`); // Returning here lets us chain on a new .then(). }) .then(function(res) { // Like earlier, fires with success and response from '/newExample'. console.log(res); }) .catch(function(err) { // Generic catch all method. Fires if there is an err with either earlier call. console.log('Error: ', err); }); Observe que os retornos de chamada de sucesso e falha em .then() apenas para o status do Promise individual ao qual .then() corresponde. O bloco catch , entretanto, capturará quaisquer erros que sejam disparados em qualquer um dos .then() s.
ES6 Const vs. Let
Em todos os nossos exemplos, empregamos funções ES5 e a antiga palavra-chave var . Embora milhões de linhas de código ainda sejam executadas hoje empregando esses métodos ES5, é útil atualizar para os padrões ES6+ atuais e refatoramos alguns de nossos códigos acima. Vamos começar com const e let .
Você pode estar acostumado a declarar uma variável com a palavra-chave var :
var pi = 3.14;Com os padrões ES6+, poderíamos fazer isso
let pi = 3.14;ou
const pi = 3.14; onde const significa “constante” — um valor que não pode ser reatribuído posteriormente. (Exceto para propriedades de objetos — abordaremos isso em breve. Além disso, variáveis declaradas const não são imutáveis, apenas a referência à variável é.)
No JavaScript antigo, escopos de bloco, como os de if , while , {} . for , etc. não afetou var de forma alguma, e isso é bem diferente de linguagens mais tipadas estaticamente como Java ou C++. Ou seja, o escopo de var é toda a função delimitadora — e isso pode ser global (se colocado fora de uma função) ou local (se colocado dentro de uma função). Para demonstrar isso, veja o exemplo a seguir:
function myFunction() { var num = 5; console.log(num); // 5 console.log('--'); for(var i = 0; i < 10; i++) { var num = i; console.log(num); //num becomes 0 — 9 } console.log('--'); console.log(num); // 9 console.log(i); // 10 } myFunction();Saída:
5 --- 0 1 2 3 ... 7 8 9 --- 9 10 O importante a notar aqui é que definir um novo var num dentro do escopo for afetou diretamente o var num fora e acima do for . Isso ocorre porque o escopo de var é sempre o da função delimitadora, e não um bloco.
Novamente, por padrão, var i dentro for() é padronizado para o escopo de myFunction , e assim podemos acessar i fora do loop e obter 10.
Em termos de atribuição de valores para variáveis, let é equivalente a var , é apenas que let tem escopo de bloco, e assim as anomalias que ocorreram com var acima não acontecerão.
function myFunction() { let num = 5; console.log(num); // 5 for(let i = 0; i < 10; i++) { let num = i; console.log('--'); console.log(num); // num becomes 0 — 9 } console.log('--'); console.log(num); // 5 console.log(i); // undefined, ReferenceError } Observando a palavra-chave const , você pode ver que atingimos um erro se tentarmos reatribuir a ela:
const c = 299792458; // Fact: The constant "c" is the speed of light in a vacuum in meters per second. c = 10; // TypeError: Assignment to constant variable. As coisas se tornam interessantes quando atribuímos uma variável const a um objeto:
const myObject = { name: 'Jane Doe' }; // This is illegal: TypeError: Assignment to constant variable. myObject = { name: 'John Doe' }; // This is legal. console.log(myObject.name) -> John Doe myObject.name = 'John Doe'; Como você pode ver, apenas a referência na memória ao objeto atribuído a um objeto const é imutável, não o valor em si.
Funções de seta ES6
Você pode estar acostumado a criar uma função como esta:
function printHelloWorld() { console.log('Hello, World!'); }Com funções de seta, isso se tornaria:
const printHelloWorld = () => { console.log('Hello, World!'); };Suponha que temos uma função simples que retorna o quadrado de um número:
const squareNumber = (x) => { return x * x; } squareNumber(5); // We can call an arrow function like an ES5 functions. Returns 25.Você pode ver que, assim como nas funções do ES5, podemos receber argumentos entre parênteses, podemos usar declarações de retorno normais e podemos chamar a função como qualquer outra.
É importante observar que, embora os parênteses sejam necessários se nossa função não receber argumentos (como printHelloWorld() acima), podemos descartar os parênteses se for necessário apenas um, portanto, nossa definição anterior do método squareNumber() pode ser reescrita como:
const squareNumber = x => { // Notice we have dropped the parentheses for we only take in one argument. return x * x; }Se você optar por encapsular um único argumento entre parênteses ou não, é uma questão de gosto pessoal, e você provavelmente verá os desenvolvedores usarem os dois métodos.
Finalmente, se quisermos retornar apenas uma expressão implicitamente, como com squareNumber(...) acima, podemos colocar a instrução return de acordo com a assinatura do método:
const squareNumber = x => x * x;Isso é,
const test = (a, b, c) => expressioné o mesmo que
const test = (a, b, c) => { return expression }Observe que, ao usar a abreviação acima para retornar um objeto implicitamente, as coisas ficam obscuras. O que impede o JavaScript de acreditar que os colchetes dentro dos quais somos obrigados a encapsular nosso objeto não são o corpo da nossa função? Para contornar isso, colocamos os colchetes do objeto entre parênteses. Isso permite explicitamente que o JavaScript saiba que estamos realmente retornando um objeto e não estamos apenas definindo um corpo.
const test = () => ({ pi: 3.14 }); // Spaces between brackets are a formality to make the code look cleaner.Para ajudar a solidificar o conceito de funções ES6, refatoramos alguns de nossos códigos anteriores, permitindo comparar as diferenças entre as duas notações.
asyncAddFunction(...) , acima, pode ser refatorado de:
function asyncAddFunction(a, b, callback){ callback(a + b); }para:
const aysncAddFunction = (a, b, callback) => { callback(a + b); };ou mesmo para:
const aysncAddFunction = (a, b, callback) => callback(a + b); // This will return callback(a + b).Ao chamar a função, podemos passar uma função de seta para o retorno de chamada:
asyncAddFunction(10, 12, sum => { // No parentheses because we only take one argument. console.log(sum); }É claro ver como esse método melhora a legibilidade do código. Para mostrar apenas um caso, podemos pegar nosso antigo exemplo baseado em ES5 Promise acima e refatorá-lo para usar funções de seta.
makeAPICall('/example') .then(res => makeAPICall(`/newExample/${res.UserName}`)) .then(res => console.log(res)) .catch(err => console.log('Error: ', err)); Agora, existem algumas advertências com as funções de seta. Por um lado, eles não vinculam uma palavra-chave this . Suponha que eu tenha o seguinte objeto:
const Person = { name: 'John Doe', greeting: () => { console.log(`Hi. My name is ${this.name}.`); } } Você pode esperar que uma chamada para Person.greeting() retornará “Oi. Meu nome é John Doe.” Em vez disso, recebemos: “Oi. Meu nome é indefinido.” Isso ocorre porque as funções de seta não têm um this e, portanto, tentar usar this dentro de uma função de seta padroniza para o this do escopo delimitador, e o escopo delimitador do objeto Person é window , no navegador, ou module.exports em Nó.
Para provar isso, se usarmos o mesmo objeto novamente, mas definirmos a propriedade name do global this para algo como 'Jane Doe', então this.name na função de seta retornará 'Jane Doe', porque o global this está dentro do escopo delimitador ou é o pai do objeto Person .
this.name = 'Jane Doe'; const Person = { name: 'John Doe', greeting: () => { console.log(`Hi. My name is ${this.name}.`); } } Person.greeting(); // Hi. My name is Jane DoeIsso é conhecido como 'Lexical Scoping', e podemos contornar isso usando a chamada 'Short Syntax', que é onde perdemos os dois pontos e a seta para refatorar nosso objeto como tal:
const Person = { name: 'John Doe', greeting() { console.log(`Hi. My name is ${this.name}.`); } } Person.greeting() //Hi. My name is John Doe.Classes ES6
Embora o JavaScript nunca tenha suportado classes, você sempre pode emulá-las com objetos como o acima. O EcmaScript 6 fornece suporte para classes usando a class e new palavras-chave:
class Person { constructor(name) { this.name = name; } greeting() { console.log(`Hi. My name is ${this.name}.`); } } const person = new Person('John'); person.greeting(); // Hi. My name is John. A função construtora é chamada automaticamente ao usar a palavra-chave new , na qual podemos passar argumentos para configurar inicialmente o objeto. Isso deve ser familiar para qualquer leitor que tenha experiência com linguagens de programação orientadas a objetos de tipo mais estático, como Java, C++ e C#.
Sem entrar em muitos detalhes sobre os conceitos de POO, outro paradigma desse tipo é a “herança”, que é permitir que uma classe herde de outra. Uma classe chamada Car , por exemplo, será muito geral — contendo métodos como “stop”, “start” etc., que todos os carros precisam. Um subconjunto da classe chamado SportsCar , então, pode herdar operações fundamentais de Car e substituir qualquer coisa que precise ser personalizada. Podemos denotar tal classe da seguinte forma:
class Car { constructor(licensePlateNumber) { this.licensePlateNumber = licensePlateNumber; } start() {} stop() {} getLicensePlate() { return this.licensePlateNumber; } // … } class SportsCar extends Car { constructor(engineRevCount, licensePlateNumber) { super(licensePlateNumber); // Pass licensePlateNumber up to the parent class. this.engineRevCount = engineRevCount; } start() { super.start(); } stop() { super.stop(); } getLicensePlate() { return super.getLicensePlate(); } getEngineRevCount() { return this.engineRevCount; } } Você pode ver claramente que a palavra-chave super nos permite acessar propriedades e métodos da classe pai, ou super.
Eventos JavaScript
Um Evento é uma ação que ocorre à qual você tem a capacidade de responder. Suponha que você esteja criando um formulário de login para seu aplicativo. Quando o usuário pressiona o botão “enviar”, você pode reagir a esse evento por meio de um “manipulador de eventos” em seu código – normalmente uma função. Quando esta função é definida como o manipulador de eventos, dizemos que estamos “registrando um manipulador de eventos”. O manipulador de eventos para o clique do botão enviar provavelmente verificará a formatação da entrada fornecida pelo usuário, sanitá-la para evitar ataques como SQL Injections ou Cross Site Scripting (por favor, esteja ciente de que nenhum código no lado do cliente pode ser considerado Sempre limpe os dados no servidor - nunca confie em nada do navegador) e, em seguida, verifique se essa combinação de nome de usuário e senha existe em um banco de dados para autenticar um usuário e fornecer a ele um token.
Como este é um artigo sobre Node, vamos nos concentrar no Node Event Model.
Podemos usar o módulo de events do Node para emitir e reagir a eventos específicos. Qualquer objeto que emita um evento é uma instância da classe EventEmitter .
Podemos emitir um evento chamando o método emit() e escutamos esse evento através do método on() , ambos expostos através da classe EventEmitter .
const EventEmitter = require('events'); const myEmitter = new EventEmitter(); Com myEmitter agora uma instância da classe EventEmitter , podemos acessar emit() e on() :
const EventEmitter = require('events'); const myEmitter = new EventEmitter(); myEmitter.on('someEvent', () => { console.log('The "someEvent" event was fired (emitted)'); }); myEmitter.emit('someEvent'); // This will call the callback function above. O segundo parâmetro para myEmitter.on() é a função de retorno de chamada que será acionada quando o evento for emitido — este é o manipulador de eventos. O primeiro parâmetro é o nome do evento, que pode ser o que quisermos, embora a convenção de nomenclatura camelCase seja recomendada.
Além disso, o manipulador de eventos pode receber qualquer número de argumentos, que são transmitidos quando o evento é emitido:
const EventEmitter = require('events'); const myEmitter = new EventEmitter(); myEmitter.on('someEvent', (data) => { console.log(`The "someEvent" event was fired (emitted) with data: ${data}`); }); myEmitter.emit('someEvent', 'This is the data payload'); Usando herança, podemos expor os métodos emit() e on() de 'EventEmitter' para qualquer classe. Isso é feito criando uma classe Node.js e usando a palavra-chave reservada extends para herdar as propriedades disponíveis em EventEmitter :
const EventEmitter = require('events'); class MyEmitter extends EventEmitter { // This is my class. I can emit events from a MyEmitter object. } Suponha que estamos construindo um programa de notificação de colisão de veículo que recebe dados de giroscópios, acelerômetros e medidores de pressão no casco do carro. Quando um veículo colide com um objeto, esses sensores externos detectarão a colisão, executando a função collide(...) e passando para ela os dados agregados do sensor como um belo objeto JavaScript. Esta função emitirá um evento de collision , notificando o fornecedor da falha.

const EventEmitter = require('events'); class Vehicle extends EventEmitter { collide(collisionStatistics) { this.emit('collision', collisionStatistics) } } const myVehicle = new Vehicle(); myVehicle.on('collision', collisionStatistics => { console.log('WARNING! Vehicle Impact Detected: ', collisionStatistics); notifyVendor(collisionStatistics); }); myVehicle.collide({ ... }); Este é um exemplo complicado, pois poderíamos simplesmente colocar o código dentro do manipulador de eventos dentro da função de colisão da classe, mas demonstra como o Node Event Model funciona mesmo assim. Observe que alguns tutoriais mostrarão o método util.inherits() para permitir que um objeto emita eventos. Isso foi preterido em favor das classes ES6 e extends .
O gerenciador de pacotes de nós
Ao programar com Node e JavaScript, será bastante comum ouvir sobre npm . O Npm é um gerenciador de pacotes que faz exatamente isso — permite o download de pacotes de terceiros que resolvem problemas comuns em JavaScript. Outras soluções, como Yarn, Npx, Grunt e Bower também existem, mas nesta seção, focaremos apenas no npm e em como você pode instalar dependências para seu aplicativo por meio de uma simples interface de linha de comando (CLI) usando-o.
Vamos começar simples, com apenas npm . Visite a página inicial do NpmJS para ver todos os pacotes disponíveis no NPM. Ao iniciar um novo projeto que dependerá de Pacotes NPM, você terá que executar npm init pelo terminal no diretório raiz do seu projeto. Você receberá uma série de perguntas que serão usadas para criar um arquivo package.json . Este arquivo armazena todas as suas dependências — módulos dos quais seu aplicativo depende para funcionar, scripts — comandos de terminal predefinidos para executar testes, construir o projeto, iniciar o servidor de desenvolvimento, etc., e muito mais.
Para instalar um pacote, basta executar npm install [package-name] --save . O sinalizador de save garantirá que o pacote e sua versão sejam registrados no arquivo package.json . Desde a versão 5 do npm , as dependências são salvas por padrão, então --save pode ser omitido. Você também notará uma nova pasta node_modules , contendo o código para aquele pacote que você acabou de instalar. Isso também pode ser reduzido para apenas npm i [package-name] . Como uma observação útil, a pasta node_modules nunca deve ser incluída em um repositório GitHub devido ao seu tamanho. Sempre que você clonar um repositório do GitHub (ou qualquer outro sistema de gerenciamento de versão), certifique-se de executar o comando npm install para sair e buscar todos os pacotes definidos no arquivo package.json , criando o diretório node_modules automaticamente. Você também pode instalar um pacote em uma versão específica: npm i [package-name]@1.10.1 --save , por exemplo.
A remoção de um pacote é semelhante à instalação de um: npm remove [package-name] .
Você também pode instalar um pacote globalmente. Este pacote estará disponível em todos os projetos, não apenas naquele em que você está trabalhando. Você faz isso com o sinalizador -g após npm i [package-name] . Isso é comumente usado para CLIs, como Google Firebase e Heroku. Apesar da facilidade que esse método apresenta, geralmente é considerado uma má prática instalar pacotes globalmente, pois eles não são salvos no arquivo package.json e, se outro desenvolvedor tentar usar seu projeto, ele não obterá todas as dependências necessárias de npm install .
APIs e JSON
APIs são um paradigma muito comum na programação, e mesmo se você está apenas começando em sua carreira como desenvolvedor, APIs e seu uso, especialmente no desenvolvimento web e móvel, provavelmente surgirão com mais frequência.
Uma API é uma Interface de Programação de Aplicativos e é basicamente um método pelo qual dois sistemas desacoplados podem se comunicar entre si. Em termos mais técnicos, uma API permite que um sistema ou programa de computador (geralmente um servidor) receba solicitações e envie respostas apropriadas (para um cliente, também conhecido como host).
Suponha que você esteja construindo um aplicativo meteorológico. Você precisa de uma maneira de geocodificar o endereço de um usuário em uma latitude e longitude e, em seguida, uma maneira de obter o clima atual ou previsto nesse local específico.
As a developer, you want to focus on building your app and monetizing it, not putting the infrastructure in place to geocode addresses or placing weather stations in every city.
Luckily for you, companies like Google and OpenWeatherMap have already put that infrastructure in place, you just need a way to talk to it — that is where the API comes in. While, as of now, we have developed a very abstract and ambiguous definition of the API, bear with me. We'll be getting to tangible examples soon.
Now, it costs money for companies to develop, maintain, and secure that aforementioned infrastructure, and so it is common for corporations to sell you access to their API. This is done with that is known as an API key, a unique alphanumeric identifier associating you, the developer, with the API. Every time you ask the API to send you data, you pass along your API key. The server can then authenticate you and keep track of how many API calls you are making, and you will be charged appropriately. The API key also permits Rate-Limiting or API Call Throttling (a method of throttling the number of API calls in a certain timeframe as to not overwhelm the server, preventing DOS attacks — Denial of Service). Most companies, however, will provide a free quota, giving you, as an example, 25,000 free API calls a day before charging you.
Up to this point, we have established that an API is a method by which two computer programs can communicate with each other. If a server is storing data, such as a website, and your browser makes a request to download the code for that site, that was the API in action.
Let us look at a more tangible example, and then we'll look at a more real-world, technical one. Suppose you are eating out at a restaurant for dinner. You are equivalent to the client, sitting at the table, and the chef in the back is equivalent to the server.
Since you will never directly talk to the chef, there is no way for him/her to receive your request (for what order you would like to make) or for him/her to provide you with your meal once you order it. We need someone in the middle. In this case, it's the waiter, analogous to the API. The API provides a medium with which you (the client) may talk to the server (the chef), as well as a set of rules for how that communication should be made (the menu — one meal is allowed two sides, etc.)
Now, how do you actually talk to the API (the waiter)? You might speak English, but the chef might speak Spanish. Is the waiter expected to know both languages to translate? What if a third person comes in who only speaks Mandarin? What then? Well, all clients and servers have to agree to speak a common language, and in computer programming, that language is JSON, pronounced JAY-sun, and it stands for JavaScript Object Notation.
At this point, we don't quite know what JSON looks like. It's not a computer programming language, it's just, well, a language, like English or Spanish, that everyone (everyone being computers) understands on a guaranteed basis. It's guaranteed because it's a standard, notably RFC 8259 , the JavaScript Object Notation (JSON) Data Interchange Format by the Internet Engineering Task Force (IETF).
Even without formal knowledge of what JSON actually is and what it looks like (we'll see in an upcoming article in this series), we can go ahead introduce a technical example operating on the Internet today that employs APIs and JSON. APIs and JSON are not just something you can choose to use, it's not equivalent to one out of a thousand JavaScript frameworks you can pick to do the same thing. It is THE standard for data exchange on the web.
Suppose you are building a travel website that compares prices for aircraft, rental car, and hotel ticket prices. Let us walk through, step-by-step, on a high level, how we would build such an application. Of course, we need our User Interface, the front-end, but that is out of scope for this article.
We want to provide our users with the lowest price booking method. Well, that means we need to somehow attain all possible booking prices, and then compare all of the elements in that set (perhaps we store them in an array) to find the smallest element (known as the infimum in mathematics.)
How will we get this data? Well, suppose all of the booking sites have a database full of prices. Those sites will provide an API, which exposes the data in those databases for use by you. You will call each API for each site to attain all possible booking prices, store them in your own array, find the lowest or minimum element of that array, and then provide the price and booking link to your user. We'll ask the API to query its database for the price in JSON, and it will respond with said price in JSON to us. We can then use, or parse, that accordingly. We have to parse it because APIs will return JSON as a string, not the actual JavaScript data type of JSON. This might not make sense now, and that's okay. We'll be covering it more in a future article.
Also, note that just because something is called an API does not necessarily mean it operates on the web and sends and receives JSON. The Java API, for example, is just the list of classes, packages, and interfaces that are part of the Java Development Kit (JDK), providing programming functionality to the programmer.
OK. We know we can talk to a program running on a server by way of an Application Programming Interface, and we know that the common language with which we do this is known as JSON. But in the web development and networking world, everything has a protocol. What do we actually do to make an API call, and what does that look like code-wise? That's where HTTP Requests enter the picture, the HyperText Transfer Protocol, defining how messages are formatted and transmitted across the Internet. Once we have an understanding of HTTP (and HTTP verbs, you'll see that in the next section), we can look into actual JavaScript frameworks and methods (like fetch() ) offered by the JavaScript API (similar to the Java API), that actually allow us to make API calls.
HTTP And HTTP Requests
HTTP is the HyperText Transfer Protocol. It is the underlying protocol that determines how messages are formatted as they are transmitted and received across the web. Let's think about what happens when, for example, you attempt to load the home page of Smashing Magazine in your web browser.
You type the website URL (Uniform Resource Locator) in the URL bar, where the DNS server (Domain Name Server, out of scope for this article) resolves the URL into the appropriate IP Address. The browser makes a request, called a GET Request, to the Web Server to, well, GET the underlying HTML behind the site. The Web Server will respond with a message such as “OK”, and then will go ahead and send the HTML down to the browser where it will be parsed and rendered accordingly.
There are a few things to note here. First, the GET Request, and then the “OK” response. Suppose you have a specific database, and you want to write an API to expose that database to your users. Suppose the database contains books the user wants to read (as it will in a future article in this series). Then there are four fundamental operations your user may want to perform on this database, that is, Create a record, Read a record, Update a record, or Delete a record, known collectively as CRUD operations.
Let's look at the Read operation for a moment. Without incorrectly assimilating or conflating the notion of a web server and a database, that Read operation is very similar to your web browser attempting to get the site from the server, just as to read a record is to get the record from the database.
Isso é conhecido como uma solicitação HTTP. Você está fazendo uma solicitação para algum servidor em algum lugar para obter alguns dados e, como tal, a solicitação é apropriadamente chamada de “GET”, sendo a capitalização uma maneira padrão de denotar tais solicitações.
E a parte Criar do CRUD? Bem, quando se fala em solicitações HTTP, isso é conhecido como solicitação POST. Assim como você pode postar uma mensagem em uma plataforma de mídia social, você também pode postar um novo registro em um banco de dados.
A atualização do CRUD nos permite usar uma solicitação PUT ou PATCH para atualizar um recurso. O PUT do HTTP criará um novo registro ou atualizará/substituirá o antigo.
Vamos ver isso um pouco mais detalhadamente, e então chegaremos ao PATCH.
Uma API geralmente funciona fazendo solicitações HTTP para rotas específicas em uma URL. Suponha que estamos fazendo uma API para conversar com um banco de dados contendo a lista de livros de um usuário. Então poderemos visualizar esses livros na URL .../books . Uma solicitação POST para .../books criará um novo livro com quaisquer propriedades que você definir (pense em id, título, ISBN, autor, dados de publicação, etc.) na rota .../books . Não importa qual seja a estrutura de dados subjacente que armazena todos os livros em .../books agora. Nós apenas nos importamos que a API exponha esse endpoint (acessado pela rota) para manipular dados. A frase anterior era chave: Uma requisição POST cria um novo livro na rota ...books/ . A diferença entre PUT e POST, então, é que PUT criará um novo livro (como com POST) se tal livro não existir, ou substituirá um livro existente se o livro já existir dentro dessa estrutura de dados mencionada.
Suponha que cada livro tenha as seguintes propriedades: id, title, ISBN, author, hasRead (boolean).
Em seguida, para adicionar um novo livro, como visto anteriormente, faríamos uma solicitação POST para .../books . Se quiséssemos atualizar ou substituir completamente um livro, faríamos uma solicitação PUT para .../books/id onde id é o ID do livro que queremos substituir.
Enquanto PUT substitui completamente um livro existente, PATCH atualiza algo relacionado a um livro específico, talvez modificando a propriedade booleana hasRead que definimos acima — então faríamos uma solicitação PATCH para …/books/id enviando os novos dados.
Pode ser difícil ver o significado disso agora, pois até agora estabelecemos tudo em teoria, mas não vimos nenhum código tangível que realmente faça uma solicitação HTTP. No entanto, chegaremos a isso em breve, cobrindo GET neste artigo e o restante em um artigo futuro.
Há uma última operação CRUD fundamental e é chamada Excluir. Como seria de esperar, o nome de tal solicitação HTTP é “DELETE” e funciona da mesma forma que PATCH, exigindo que o ID do livro seja fornecido em uma rota.
Aprendemos até agora, então, que as rotas são URLs específicos para os quais você faz uma solicitação HTTP e que os endpoints são funções que a API fornece, fazendo algo com os dados que ela expõe. Ou seja, o endpoint é uma função de linguagem de programação localizada na outra extremidade da rota e executa qualquer solicitação HTTP que você especificou. Também aprendemos que existem termos como POST, GET, PUT, PATCH, DELETE e outros (conhecidos como verbos HTTP) que realmente especificam quais solicitações você está fazendo à API. Assim como o JSON, esses métodos de solicitação HTTP são padrões da Internet definidos pela Internet Engineering Task Force (IETF), mais notavelmente, RFC 7231, seção quatro: métodos de solicitação e RFC 5789, seção dois: método de patch, onde RFC é um acrônimo para Pedido de comentários.
Então, podemos fazer uma solicitação GET para a URL .../books/id onde o ID passado é conhecido como parâmetro. Poderíamos fazer uma solicitação POST, PUT ou PATCH para .../books para criar um recurso ou para .../books/id para modificar/substituir/atualizar um recurso. E também podemos fazer uma solicitação DELETE para .../books/id para excluir um livro específico.
Uma lista completa de métodos de solicitação HTTP pode ser encontrada aqui.
Também é importante observar que, após fazer uma solicitação HTTP, receberemos uma resposta. A resposta específica é determinada pela forma como construímos a API, mas você sempre deve receber um código de status. Anteriormente, dissemos que quando seu navegador da Web solicita o HTML do servidor da Web, ele responde com "OK". Isso é conhecido como um código de status HTTP, mais especificamente, HTTP 200 OK. O código de status apenas especifica como a operação ou ação especificada no endpoint (lembre-se, essa é a nossa função que faz todo o trabalho) concluída. Os códigos de status HTTP são enviados de volta pelo servidor, e provavelmente há muitos com os quais você está familiarizado, como 404 Not Found (o recurso ou arquivo não pôde ser encontrado, isso seria como fazer uma solicitação GET para .../books/id onde não existe tal ID.)
Uma lista completa de códigos de status HTTP pode ser encontrada aqui.
MongoDB
O MongoDB é um banco de dados NoSQL não relacional semelhante ao Firebase Real-time Database. Você conversará com o banco de dados por meio de um pacote Node, como o MongoDB Native Driver ou Mongoose.
No MongoDB, os dados são armazenados em JSON, que é bem diferente de bancos de dados relacionais como MySQL, PostgreSQL ou SQLite. Ambos são chamados de bancos de dados, com Tabelas SQL chamadas Coleções, Linhas da Tabela SQL chamadas Documentos e Colunas da Tabela SQL chamadas Campos.
Usaremos o banco de dados MongoDB em um próximo artigo desta série quando criarmos nossa primeira API Bookshelf. As operações CRUD fundamentais listadas acima podem ser executadas em um banco de dados MongoDB.
É recomendável que você leia os Documentos do MongoDB para aprender como criar um banco de dados ativo em um cluster Atlas e fazer operações CRUD nele com o driver nativo do MongoDB. No próximo artigo desta série, aprenderemos como configurar um banco de dados local e um banco de dados de produção em nuvem.
Criando um aplicativo de nó de linha de comando
Ao construir um aplicativo, você verá muitos autores despejarem toda a sua base de código no início do artigo e tentarão explicar cada linha a partir de então. Neste texto, vou adotar uma abordagem diferente. Vou explicar meu código linha por linha, construindo o aplicativo à medida que avançamos. Não vou me preocupar com modularidade ou desempenho, não vou dividir a base de código em arquivos separados e não vou seguir o Princípio DRY ou tentar tornar o código reutilizável. Quando estamos apenas aprendendo, é útil tornar as coisas o mais simples possível, e essa é a abordagem que adotarei aqui.
Sejamos claros sobre o que estamos construindo. Não estaremos preocupados com a entrada do usuário e, portanto, não faremos uso de pacotes como Yargs. Também não construiremos nossa própria API. Isso virá em um artigo posterior desta série, quando usarmos o Express Web Application Framework. Eu adoto essa abordagem para não confundir o Node.js com o poder do Express e das APIs, já que a maioria dos tutoriais o faz. Em vez disso, fornecerei um método (de muitos) para chamar e receber dados de uma API externa que utiliza uma biblioteca JavaScript de terceiros. A API que chamaremos é uma API Weather, que acessaremos do Node e despejaremos sua saída no terminal, talvez com alguma formatação, conhecida como “pretty-printing”. Abordarei todo o processo, incluindo como configurar a API e obter a chave da API, cujas etapas fornecem os resultados corretos a partir de janeiro de 2019.
Usaremos a API OpenWeatherMap para este projeto, então, para começar, navegue até a página de inscrição do OpenWeatherMap e crie uma conta com o formulário. Uma vez logado, encontre o item de menu API Keys na página do painel (localizado aqui). Se você acabou de criar uma conta, terá que escolher um nome para sua chave de API e clicar em “Gerar”. Pode levar pelo menos 2 horas para que sua nova chave de API esteja funcional e associada à sua conta.
Antes de começarmos a criar o aplicativo, visitaremos a documentação da API para aprender como formatar nossa chave de API. Neste projeto, especificaremos um CEP e um código de país para obter as informações meteorológicas naquele local.
Nos documentos, podemos ver que o método pelo qual fazemos isso é fornecer o seguinte URL:
api.openweathermap.org/data/2.5/weather?zip={zip code},{country code}No qual poderíamos inserir dados:
api.openweathermap.org/data/2.5/weather?zip=94040,usAgora, antes que possamos realmente obter dados relevantes dessa API, precisaremos fornecer nossa nova chave de API como um parâmetro de consulta:
api.openweathermap.org/data/2.5/weather?zip=94040,us&appid={YOUR_API_KEY} Por enquanto, copie esse URL em uma nova guia em seu navegador da Web, substituindo o espaço reservado {YOUR_API_KEY} pela chave de API que você obteve anteriormente quando se registrou em uma conta.
O texto que você pode ver é, na verdade, JSON — o idioma acordado da web, conforme discutido anteriormente.
Para inspecionar isso ainda mais, pressione Ctrl + Shift + I no Google Chrome para abrir as ferramentas do desenvolvedor do Chrome e navegue até a guia Rede. No momento, não deve haver dados aqui.
Para realmente monitorar os dados da rede, recarregue a página e observe a guia ser preenchida com informações úteis. Clique no primeiro link conforme mostrado na imagem abaixo.
Depois de clicar nesse link, podemos visualizar informações específicas de HTTP, como os cabeçalhos. Os cabeçalhos são enviados na resposta da API (você também pode, em alguns casos, enviar seus próprios cabeçalhos para a API ou até mesmo criar seus próprios cabeçalhos personalizados (geralmente prefixados com x- ) para enviar de volta ao criar sua própria API ), e apenas contêm informações extras que o cliente ou o servidor podem precisar.
Nesse caso, você pode ver que fizemos uma solicitação HTTP GET para a API e ela respondeu com um status HTTP 200 OK. Você também pode ver que os dados enviados de volta estavam em JSON, conforme listado na seção "Cabeçalhos de resposta".
Se você clicar na guia de visualização, poderá visualizar o JSON como um objeto JavaScript. A versão de texto que você pode ver em seu navegador é uma string, pois o JSON é sempre transmitido e recebido pela web como uma string. É por isso que temos que analisar o JSON em nosso código, para colocá-lo em um formato mais legível - neste caso (e em praticamente todos os casos) - um objeto JavaScript.
Você também pode usar a extensão do Google Chrome “JSON View” para fazer isso automaticamente.
Para começar a construir nosso aplicativo, vou abrir um terminal e criar um novo diretório raiz e depois cd nele. Uma vez dentro, criarei um novo arquivo app.js , executarei npm init para gerar um arquivo package.json com as configurações padrão e, em seguida, abrirei o Visual Studio Code.
mkdir command-line-weather-app && cd command-line-weather-app touch app.js npm init code . Em seguida, vou baixar o Axios, verificar se ele foi adicionado ao meu arquivo package.json e observar se a pasta node_modules foi criada com sucesso.
No navegador, você pode ver que fizemos uma solicitação GET manualmente, digitando manualmente o URL adequado na barra de URL. Axios é o que me permitirá fazer isso dentro do Node.
A partir de agora, todos os códigos a seguir estarão localizados dentro do arquivo app.js , cada snippet colocado um após o outro.
A primeira coisa que farei é exigir o pacote Axios que instalamos anteriormente com
const axios = require('axios'); Agora temos acesso ao Axios e podemos fazer solicitações HTTP relevantes, por meio da constante axios .
Geralmente, nossas chamadas de API serão dinâmicas — nesse caso, podemos querer injetar diferentes CEPs e códigos de país em nossa URL. Então, estarei criando variáveis constantes para cada parte da URL e, em seguida, reunindo-as com ES6 Template Strings. Primeiro, temos a parte da nossa URL que nunca mudará, assim como nossa chave de API:
const API_URL = 'https://api.openweathermap.org/data/2.5/weather?zip='; const API_KEY = 'Your API Key Here'; Também atribuirei nosso CEP e código do país. Como não estamos esperando a entrada do usuário e estamos codificando os dados, vou torná-los constantes também, embora, em muitos casos, seja mais útil usar let .
const LOCATION_ZIP_CODE = '90001'; const COUNTRY_CODE = 'us';Agora precisamos colocar essas variáveis juntas em uma URL na qual podemos usar o Axios para fazer solicitações GET para:
const ENTIRE_API_URL = `${API_URL}${LOCATION_ZIP_CODE},${COUNTRY_CODE}&appid=${API_KEY}`; Aqui está o conteúdo do nosso arquivo app.js até este ponto:
const axios = require('axios'); // API specific settings. const API_URL = 'https://api.openweathermap.org/data/2.5/weather?zip='; const API_KEY = 'Your API Key Here'; const LOCATION_ZIP_CODE = '90001'; const COUNTRY_CODE = 'us'; const ENTIRE_API_URL = `${API_URL}${LOCATION_ZIP_CODE},${COUNTRY_CODE}&appid=${API_KEY}`; Tudo o que resta a fazer é usar o axios para fazer uma solicitação GET para essa URL. Para isso, usaremos o método get(url) fornecido por axios .
axios.get(ENTIRE_API_URL) axios.get(...) na verdade retorna uma Promise, e a função de retorno de chamada de sucesso receberá um argumento de resposta que nos permitirá acessar a resposta da API — a mesma coisa que você viu no navegador. Também adicionarei uma cláusula .catch() para detectar quaisquer erros.
axios.get(ENTIRE_API_URL) .then(response => console.log(response)) .catch(error => console.log('Error', error)); Se agora executarmos esse código com o node app.js no terminal, você poderá ver a resposta completa que recebemos. No entanto, suponha que você queira apenas ver a temperatura desse CEP - então a maioria desses dados na resposta não é útil para você. Na verdade, o Axios retorna a resposta da API no objeto de dados, que é uma propriedade da resposta. Isso significa que a resposta do servidor está localizada em response.data , então vamos imprimir isso na função de retorno de chamada: console.log(response.data) .
Agora, dissemos que os servidores da Web sempre lidam com JSON como uma string, e isso é verdade. Você pode notar, no entanto, que response.data já é um objeto (evidente executando console.log(typeof response.data) ) — não precisamos analisá-lo com JSON.parse() . Isso porque a Axios já cuida disso para nós nos bastidores.
A saída no terminal da execução de console.log(response.data) pode ser formatada — “pretty-printed” — executando console.log(JSON.stringify(response.data, undefined, 2)) . JSON.stringify() converte um objeto JSON em uma string e recebe o objeto, um filtro e o número de caracteres pelos quais recuar ao imprimir. Você pode ver a resposta que isso fornece:
{ "coord": { "lon": -118.24, "lat": 33.97 }, "weather": [ { "id": 800, "main": "Clear", "description": "clear sky", "icon": "01d" } ], "base": "stations", "main": { "temp": 288.21, "pressure": 1022, "humidity": 15, "temp_min": 286.15, "temp_max": 289.75 }, "visibility": 16093, "wind": { "speed": 2.1, "deg": 110 }, "clouds": { "all": 1 }, "dt": 1546459080, "sys": { "type": 1, "id": 4361, "message": 0.0072, "country": "US", "sunrise": 1546441120, "sunset": 1546476978 }, "id": 420003677, "name": "Lynwood", "cod": 200 } Agora, fica claro que a temperatura que estamos procurando está localizada na propriedade main do objeto response.data , então podemos acessá-la chamando response.data.main.temp . Vejamos o código da aplicação até agora:
const axios = require('axios'); // API specific settings. const API_URL = 'https://api.openweathermap.org/data/2.5/weather?zip='; const API_KEY = 'Your API Key Here'; const LOCATION_ZIP_CODE = '90001'; const COUNTRY_CODE = 'us'; const ENTIRE_API_URL = `${API_URL}${LOCATION_ZIP_CODE},${COUNTRY_CODE}&appid=${API_KEY}`; axios.get(ENTIRE_API_URL) .then(response => console.log(response.data.main.temp)) .catch(error => console.log('Error', error));A temperatura que recebemos de volta é na verdade em Kelvin, que é uma escala de temperatura geralmente usada em Física, Química e Termodinâmica devido ao fato de fornecer um ponto de “zero absoluto”, que é a temperatura na qual todo movimento térmico de todas as partes internas partículas cessam. Só precisamos converter isso para Fahrenheit ou Celsius com as fórmulas abaixo:
F = K * 9/5 - 459,67
C = K - 273,15
Vamos atualizar nosso retorno de chamada de sucesso para imprimir os novos dados com essa conversão. Também adicionaremos uma frase adequada para fins de experiência do usuário:
axios.get(ENTIRE_API_URL) .then(response => { // Getting the current temperature and the city from the response object. const kelvinTemperature = response.data.main.temp; const cityName = response.data.name; const countryName = response.data.sys.country; // Making K to F and K to C conversions. const fahrenheitTemperature = (kelvinTemperature * 9/5) — 459.67; const celciusTemperature = kelvinTemperature — 273.15; // Building the final message. const message = ( `Right now, in \ ${cityName}, ${countryName} the current temperature is \ ${fahrenheitTemperature.toFixed(2)} deg F or \ ${celciusTemperature.toFixed(2)} deg C.`.replace(/\s+/g, ' ') ); console.log(message); }) .catch(error => console.log('Error', error)); Os parênteses em torno da variável de message não são obrigatórios, eles apenas parecem bons - semelhante a quando se trabalha com JSX no React. As barras invertidas impedem que a string do modelo formate uma nova linha, e o método de protótipo replace() String se livra do espaço em branco usando Expressões Regulares (RegEx). Os métodos de protótipo de número toFixed() arredondam um ponto flutuante para um número específico de casas decimais — neste caso, duas.
Com isso, nosso app.js final fica assim:
const axios = require('axios'); // API specific settings. const API_URL = 'https://api.openweathermap.org/data/2.5/weather?zip='; const API_KEY = 'Your API Key Here'; const LOCATION_ZIP_CODE = '90001'; const COUNTRY_CODE = 'us'; const ENTIRE_API_URL = `${API_URL}${LOCATION_ZIP_CODE},${COUNTRY_CODE}&appid=${API_KEY}`; axios.get(ENTIRE_API_URL) .then(response => { // Getting the current temperature and the city from the response object. const kelvinTemperature = response.data.main.temp; const cityName = response.data.name; const countryName = response.data.sys.country; // Making K to F and K to C conversions. const fahrenheitTemperature = (kelvinTemperature * 9/5) — 459.67; const celciusTemperature = kelvinTemperature — 273.15; // Building the final message. const message = ( `Right now, in \ ${cityName}, ${countryName} the current temperature is \ ${fahrenheitTemperature.toFixed(2)} deg F or \ ${celciusTemperature.toFixed(2)} deg C.`.replace(/\s+/g, ' ') ); console.log(message); }) .catch(error => console.log('Error', error));Conclusão
Aprendemos muito sobre como o Node funciona neste artigo, desde as diferenças entre solicitações síncronas e assíncronas, funções de retorno de chamada, novos recursos do ES6, eventos, gerenciadores de pacotes, APIs, JSON e o protocolo de transferência de hipertexto, bancos de dados não relacionais , e até construímos nosso próprio aplicativo de linha de comando utilizando a maior parte desse novo conhecimento encontrado.
Em artigos futuros desta série, analisaremos detalhadamente o Call Stack, o Event Loop e as APIs Node, falaremos sobre o Cross-Origin Resource Sharing (CORS) e criaremos um Stack Bookshelf API utilizando bancos de dados, endpoints, autenticação de usuário, tokens, renderização de modelo do lado do servidor e muito mais.
A partir daqui, comece a construir seus próprios aplicativos Node, leia a documentação do Node, saia e encontre APIs ou Módulos Node interessantes e implemente-os você mesmo. O mundo é sua ostra e você tem na ponta dos dedos acesso à maior rede de conhecimento do planeta — a Internet. Use-o a seu favor.
Leitura adicional no SmashingMag:
- Entendendo e usando APIs REST
- Novos recursos de JavaScript que mudarão a forma como você escreve Regex
- Mantendo o Node.js rápido: ferramentas, técnicas e dicas para criar servidores Node.js de alto desempenho
- Criando um chatbot de IA simples com API de fala na Web e Node.js