
7 algoritmos de aprendizado de máquina mais usados em Python que você deve conhecer
Publicados: 2021-03-04Machine Learning é um ramo da Inteligência Artificial (IA) que lida com os algoritmos de computador que estão sendo usados em qualquer dado. Ele se concentra em aprender automaticamente com os dados que estão sendo inseridos nele e nos fornece resultados melhorando sempre as previsões anteriores.
Índice
Principais algoritmos de aprendizado de máquina usados em Python
Abaixo estão alguns dos principais algoritmos de aprendizado de máquina usados em Python, juntamente com trechos de código que mostram sua implementação e visualizações dos limites de classificação.
1. Regressão Linear
A regressão linear é uma das técnicas de aprendizado de máquina supervisionado mais comumente usadas. Como o próprio nome sugere, essa regressão tenta modelar a relação entre duas variáveis usando uma equação linear e ajustando essa linha aos dados observados. Essa técnica é usada para estimar valores contínuos reais, como vendas totais realizadas ou custo de casas.
A linha de melhor ajuste também é chamada de linha de regressão. É dado pela seguinte equação:
Y = a*X + b
onde Y é a variável dependente, a é a inclinação, X é a variável independente e b é o valor do intercepto. Os coeficientes aeb são derivados minimizando o quadrado da diferença dessa distância entre os vários pontos de dados e a equação da linha de regressão.

# conjunto de dados sintéticos para regressão simples
de sklearn.datasets importar make_regression
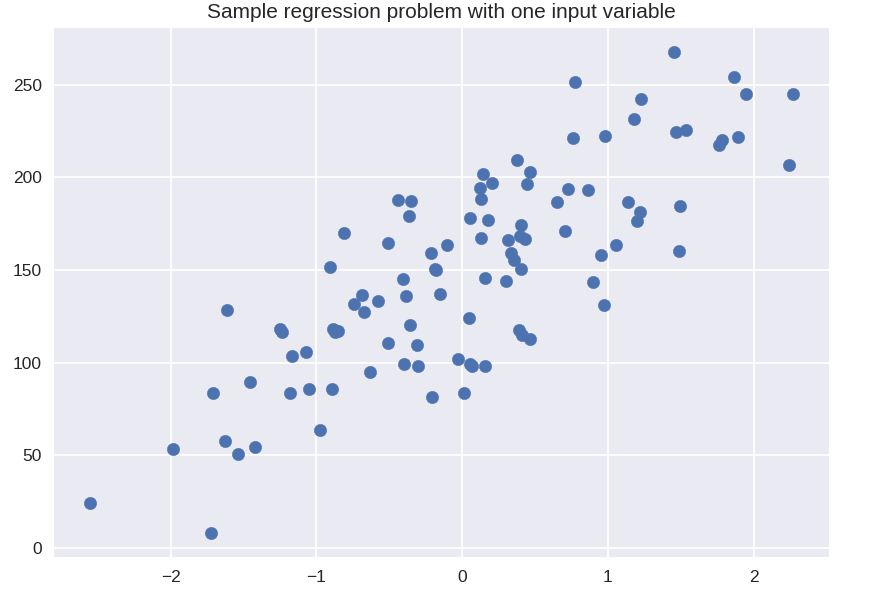
plt.figura()
plt.title('Problema de regressão de amostra com uma variável de entrada')
X_R1, y_R1 = make_regression(n_samples = 100, n_features = 1, n_informative = 1, bias = 150.0, noise = 30, random_state = 0 )
plt.scatter( X_R1, y_R1, marcador = 'o', s = 50 )
plt.show()
de sklearn.linear_model importar LinearRegression
X_train, X_test, y_train, y_test = train_test_split( X_R1, y_R1,
random_state = 0)
linreg = LinearRegression().fit( X_train, y_train )
print( 'coef do modelo linear (w): {}'.format( linreg.coef_ ) )
print('intercepto de modelo linear (b): {:.3f}'z.format(linreg.intercept_))
print( 'R-squared score (treinamento): {:.3f}'.format( linreg.score( X_train, y_train ) ) )
print( 'R-squad score (teste): {:.3f}'.format( linreg.score( X_test, y_test ) ) )
Saída
coeficiente de modelo linear (w): [ 45,71]
interceptação do modelo linear (b): 148,446
Pontuação R-quadrado (treinamento): 0,679
Pontuação R-quadrado (teste): 0,492
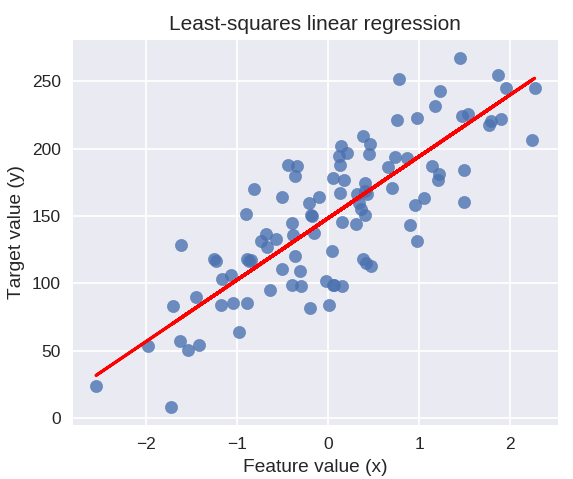
O código a seguir desenhará a linha de regressão ajustada no gráfico de nossos pontos de dados.
plt.figure( figsize = ( 5, 4 ) )
plt.scatter( X_R1, y_R1, marcador = 'o', s = 50, alfa = 0,8 )
plt.plot( X_R1, linreg.coef_ * X_R1 + linreg.intercept_, 'r-' )
plt.title('Regressão linear de mínimos quadrados')
plt.xlabel('Valor do recurso (x)')
plt.ylabel('Valor alvo (y)')
plt.show()
Preparando um conjunto de dados comum para explorar técnicas de classificação
Os dados a seguir serão usados para mostrar os vários algoritmos de classificação que são mais comumente usados em aprendizado de máquina em Python.
O conjunto de dados de cogumelos UCI é armazenado em cogumelos.csv.
bloco de notas %matplotlib
importar pandas como pd
importar numpy como np
importar matplotlib.pyplot como plt
de sklearn.decomposition importar PCA
de sklearn.model_selection importar train_test_split
df = pd.read_csv('readonly/mushrooms.csv')
df2 = pd.get_dummies( df )
df3 = df2.sample( frac = 0,08 )
X = df3.iloc[:, 2:]
y = df3.iloc[:, 1]
pca = PCA( n_componentes = 2 ).fit_transform( X )
X_train, X_test, y_train, y_test = train_test_split( pca, y, random_state = 0 )
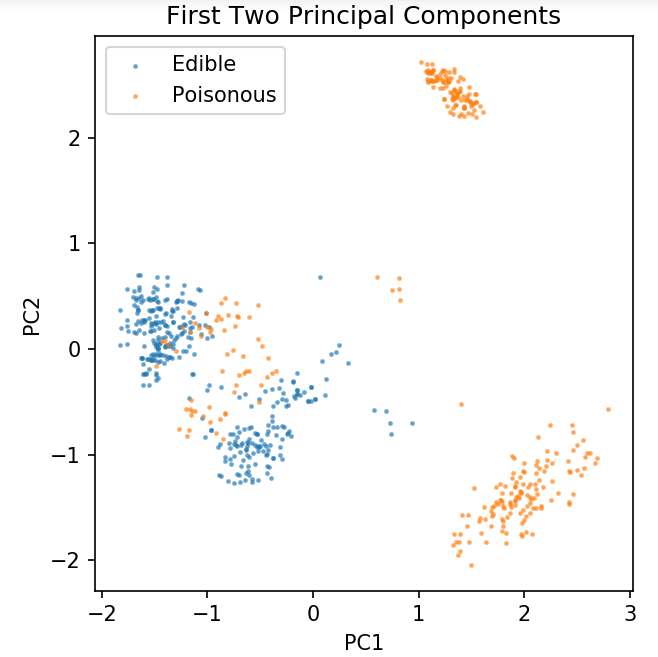
plt.figura( dpi = 120 )
plt.scatter( pca[y.values == 0, 0], pca[y.values == 0, 1], alpha = 0,5, label = 'Comestível', s = 2 )
plt.scatter( pca[y.values == 1, 0], pca[y.values == 1, 1], alpha = 0.5, label = 'Veneno', s = 2 )
plt.legend()
plt.title('Conjunto de dados de cogumelo\nPrimeiros dois componentes principais')
plt.xlabel('PC1')
plt.ylabel('PC2')
plt.gca().set_aspect( 'igual' )
Usaremos a função definida abaixo para obter os limites de decisão dos diferentes classificadores que usaremos no conjunto de dados do cogumelo.
def plot_mushroom_boundary( X, y, modelo_ajustado ):
plt.figure( figsize = (9,8, 5), dpi = 100 )
for i, plot_type in enumerate( ['Decision Boundary', 'Decision Probabilities'] ):
plt.subtrama( 1, 2, i + 1 )
mesh_step_size = 0.01 # tamanho do passo na malha
x_min, x_max = X[:, 0].min() – .1, X[:, 0].max() + .1
y_min, y_max = X[:, 1].min() – .1, X[:, 1].max() + .1
xx, yy = np.meshgrid( np.arange( x_min, x_max, mesh_step_size ), np.arange( y_min, y_max, mesh_step_size ) )
se eu == 0:
Z = modelo_ajustado.predict(np.c_[xx.ravel(), aa.ravel()])
outro:
experimentar:
Z = modelo_ajustado.predict_proba( np.c_[xx.ravel(), aa.ravel()] )[:, 1]
exceto:
plt.text( 0.4, 0.5, 'Probabilidades indisponíveis', horizontalalignment = 'center', verticalalignment = 'center', transform = plt.gca().transAxes, fontsize = 12 )
plt.axis( 'desligado' )
pausa
Z = Z.reforma ( xx.forma )
plt.scatter( X[y.values == 0, 0], X[y.values == 0, 1], alpha = 0,4, label = 'Comestível', s = 5 )
plt.scatter( X[y.values == 1, 0], X[y.values == 1, 1], alpha = 0.4, label = 'Posionous', s = 5 )
plt.imshow( Z, interpolação = 'mais próximo', cmap = 'RdYlBu_r', alfa = 0,15, extensão = ( x_min, x_max, y_min, y_max ), origin = 'inferior')
plt.title( plot_type + '\n' + str(sized_model ).split( '(' )[0] + ' Test Accuracy: ' + str( np.round( ajustado_model.score( X, y ), 5 ) ) )
plt.gca().set_aspect( 'igual' );
plt.tight_layout()
plt.subplots_adjust(top = 0,9, bottom = 0,08, wspace = 0,02 )
2. Regressão Logística
Ao contrário da regressão linear, a regressão logística trata da estimativa de valores discretos (valores binários 0/1, verdadeiro/falso, sim/não). Essa técnica também é chamada de regressão logit. Isso ocorre porque ele prevê a probabilidade de um evento usando uma função logit para treinar os dados fornecidos. Seu valor sempre fica entre 0 e 1 (já que está calculando uma probabilidade).
As probabilidades logarítmicas dos resultados são construídas como uma combinação linear da variável preditora da seguinte forma:
odds = p / (1 – p) = probabilidade do evento ocorrer ou probabilidade do evento não ocorrer
ln( odds ) = ln( p / (1 – p) )
logit(p) = ln(p / (1 – p)) = b0 + b1X1 + b2X2 + b3X3 + … + bkXk
onde p é a probabilidade de presença de uma característica.
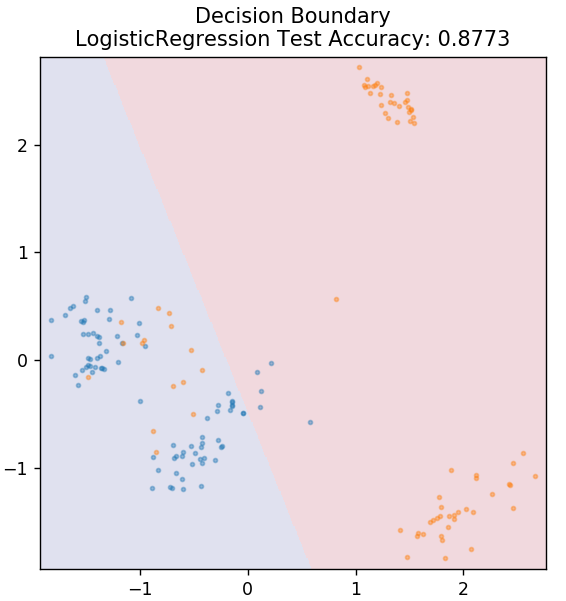
de sklearn.linear_model importar LogisticRegression
model = LogisticRegression()
model.fit( X_train, y_train )
plot_mushroom_boundary( X_test, y_test, modelo )
Obtenha a certificação de inteligência artificial online das melhores universidades do mundo - mestrados, programas de pós-graduação executiva e programa de certificação avançada em ML e IA para acelerar sua carreira.
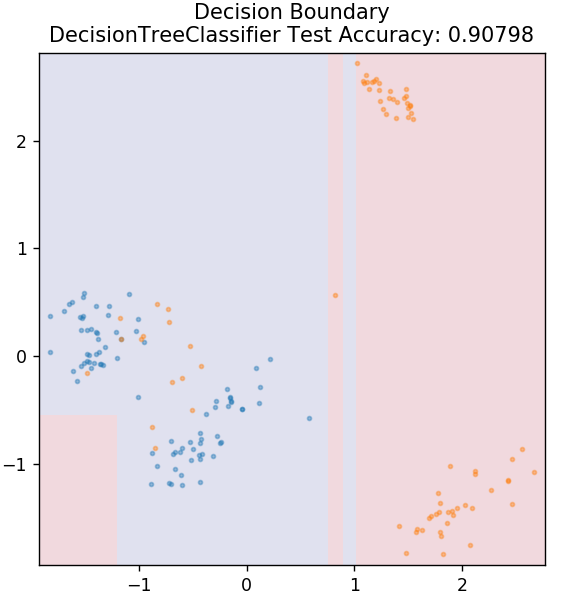
3. Árvore de Decisão
Este é um algoritmo muito popular que pode ser usado para classificar variáveis contínuas e discretas de dados. A cada etapa, os dados são divididos em mais de um conjunto homogêneo com base em alguns atributos/condições de divisão.

de sklearn.tree importação DecisionTreeClassifier
model = DecisionTreeClassifier( max_depth = 3 )
model.fit( X_train, y_train )
plot_mushroom_boundary( X_test, y_test, modelo )
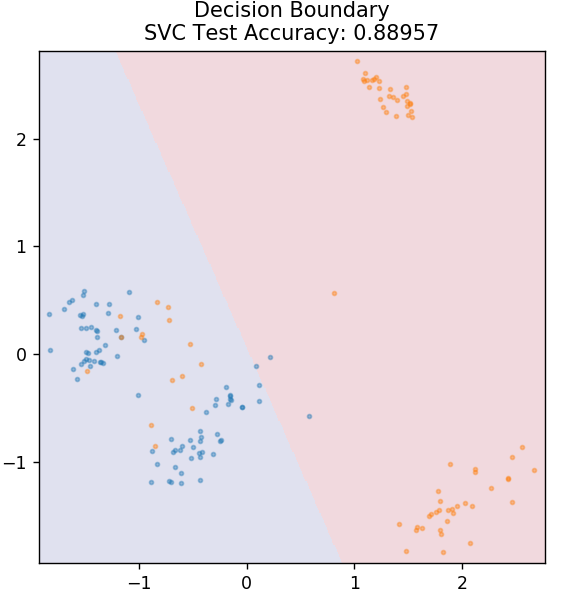
4. SVM
SVM é a abreviação de Support Vector Machines. Aqui a ideia básica é classificar os pontos de dados usando hiperplanos para separação. O objetivo é descobrir um hiperplano que tenha a distância máxima (ou margem) entre os pontos de dados de ambas as classes ou categorias.
Escolhemos o plano de forma a cuidar de classificar pontos desconhecidos no futuro com a maior confiança. Os SVMs são famosos porque fornecem alta precisão enquanto ocupam muito menos poder computacional. SVMs também podem ser usados para problemas de regressão.
de sklearn.svm importar SVC
modelo = SVC( kernel = 'linear' )
model.fit( X_train, y_train )
plot_mushroom_boundary( X_test, y_test, modelo )
Checkout: Projetos Python no GitHub
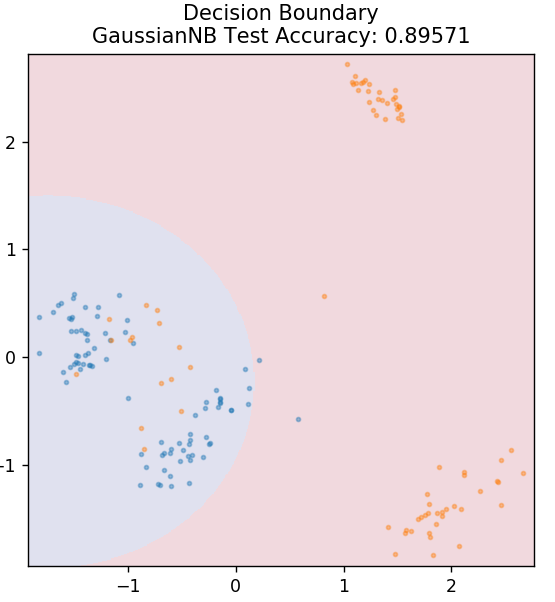
5. Naive Bayes
Como o nome sugere, o algoritmo Naive Bayes é um algoritmo de aprendizado supervisionado baseado no Teorema de Bayes . O Teorema de Bayes usa probabilidades condicionais para fornecer a probabilidade de um evento com base em algum conhecimento fornecido.
Onde, 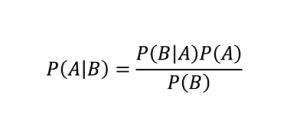
P (A | B): A probabilidade condicional de que o evento A ocorra, dado que o evento B já ocorreu. (Também chamado de probabilidade posterior)
P(A): Probabilidade do evento A.
P(B): Probabilidade do evento B.
P (B | A): A probabilidade condicional de que o evento B ocorra, dado que o evento A já ocorreu.
Por que esse algoritmo é chamado Naive, você pergunta? Isso ocorre porque assume que todas as ocorrências de eventos são independentes umas das outras. Portanto, cada recurso define separadamente a classe à qual um ponto de dados pertence, sem ter nenhuma dependência entre eles. Naive Bayes é a melhor escolha para categorizações de texto. Ele funcionará suficientemente bem mesmo com pequenas quantidades de dados de treinamento.
de sklearn.naive_bayes importar GaussianNB
model = GaussianNB()
model.fit( X_train, y_train )
plot_mushroom_boundary( X_test, y_test, modelo )
5. KNN
KNN significa K-Nearest Neighbours. É um algoritmo de aprendizado supervisionado muito utilizado que classifica os dados de teste de acordo com suas semelhanças com os dados de treinamento previamente classificados. O KNN não classifica todos os pontos de dados durante o treinamento. Em vez disso, ele apenas armazena o conjunto de dados e, quando obtém novos dados, classifica esses pontos de dados com base em suas semelhanças. Ele faz isso calculando a distância euclidiana do número K de vizinhos mais próximos (aqui, n_neighbors ) desse ponto de dados.
de sklearn.neighbors importar KNeighborsClassifier
model = KNeighborsClassifier( n_vizinhos = 20 )
model.fit( X_train, y_train )
plot_mushroom_boundary( X_test, y_test, modelo )
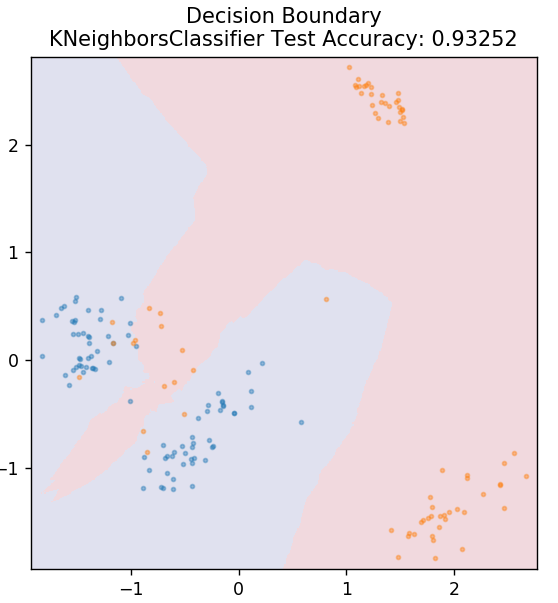
6. Floresta Aleatória
A floresta aleatória é um algoritmo de aprendizado de máquina muito simples e diversificado que usa uma técnica de aprendizado supervisionado. Como você pode adivinhar pelo nome, a floresta aleatória consiste em um grande número de árvores de decisão, atuando como um conjunto. Cada árvore de decisão descobrirá a classe de saída dos pontos de dados e a classe majoritária será escolhida como saída final do modelo. A ideia aqui é que mais árvores trabalhando nos mesmos dados tenderão a ter resultados mais precisos do que árvores individuais.
de sklearn.ensemble importar RandomForestClassifier
model = RandomForestClassifier()
model.fit( X_train, y_train )
plot_mushroom_boundary( X_test, y_test, modelo )
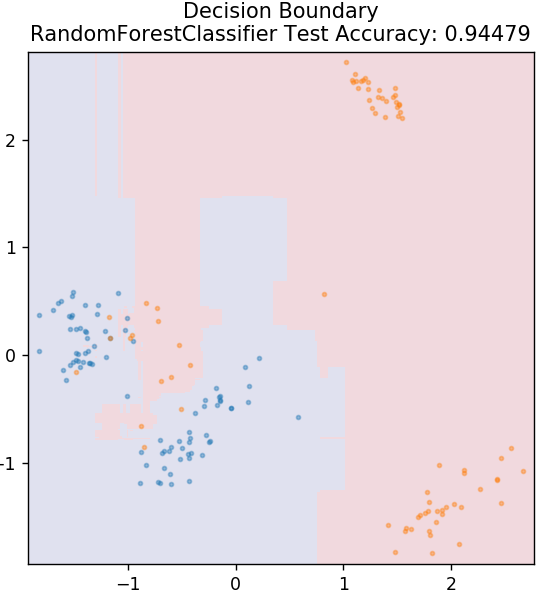
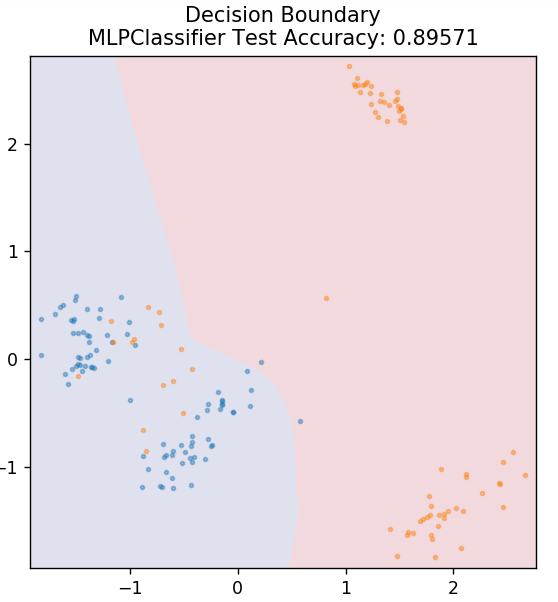
7. Perceptron de várias camadas
O Multi-Layer Perceptron (ou MLP) é um algoritmo muito fascinante que se enquadra no ramo de aprendizado profundo. Mais especificamente, pertence à classe de redes neurais artificiais (RNA) feed-forward. O MLP forma uma rede de múltiplos perceptrons com pelo menos três camadas: uma camada de entrada, uma camada de saída e uma(s) camada(s) oculta(s). Os MLPs são capazes de distinguir entre dados que não são separáveis linearmente.
Cada neurônio nas camadas ocultas usa uma função de ativação para prosseguir para a próxima camada. Aqui, o algoritmo de retropropagação é usado para ajustar os parâmetros e, portanto, treinar a rede neural. Ele pode ser usado principalmente para problemas de regressão simples.
de sklearn.neural_network importar MLPClassifier
model = MLPClassifier()
model.fit( X_train, y_train )
plot_mushroom_boundary( X_test, y_test, modelo )
Leia também: Ideias e tópicos do projeto Python
Conclusão
Podemos concluir que diferentes algoritmos de aprendizado de máquina produzem diferentes limites de decisão e, portanto, resultados de precisão diferentes na classificação do mesmo conjunto de dados.
Não há como declarar qualquer algoritmo como o melhor algoritmo para todos os tipos de dados em geral. O aprendizado de máquina requer testes e erros rigorosos para vários algoritmos para determinar o que funciona melhor para cada conjunto de dados separadamente. A lista de algoritmos de ML obviamente não termina aqui. Há um vasto mar de outras técnicas que estão esperando para serem exploradas na biblioteca Scikit-Learn do Python. Vá em frente e treine seus conjuntos de dados usando tudo isso e divirta-se!
Se você estiver interessado em saber mais sobre árvores de decisão, aprendizado de máquina, confira o Programa PG Executivo do IIIT-B e do upGrad em Machine Learning e IA , projetado para profissionais que trabalham e oferece mais de 450 horas de treinamento rigoroso, mais de 30 estudos de caso e atribuições, status de ex-alunos do IIIT-B, mais de 5 projetos práticos práticos e assistência de trabalho com as principais empresas.
Quais são os principais pressupostos da regressão linear?
Existem 4 pressupostos essenciais para a regressão linear: linearidade, homocedasticidade, independência e normalidade. Linearidade significa que a relação entre a variável independente (X) e a média da variável dependente (Y) é considerada linear quando usamos regressão linear. A homocedasticidade significa que a variância nos erros dos pontos residuais do gráfico é presumida como constante. Independência refere-se a todas as observações dos dados de entrada a serem consideradas independentes umas das outras. Normalidade significa que a distribuição dos dados de entrada pode ser uniforme ou não uniforme, mas presume-se que seja uniformemente distribuída no caso de regressão linear.
Quais são as diferenças entre uma árvore de decisão e Random Forest?
A árvore de decisão implementa seu processo de tomada de decisão, usando uma estrutura em forma de árvore que representa os resultados possíveis para ações específicas. A floresta aleatória usa um pacote dessas árvores de decisão para analisar os dados. Por esse processo, mais dados serão usados pela Random Forest, mas isso ajuda a evitar overfitting e fornece resultados precisos. Existe um escopo de overfitting em um algoritmo de árvore de decisão e pode fornecer resultados menos precisos. Uma árvore de decisão é fácil de interpretar, pois requer menos cálculos, enquanto uma floresta aleatória é difícil de interpretar devido às suas análises complexas.
Quais são algumas bibliotecas padrão usadas para algoritmos de aprendizado de máquina em Python?
O Python substituiu quase todas as outras linguagens no aprendizado de máquina devido à disponibilidade de um grande número de bibliotecas e regras de sintaxe fáceis. Existem muitas bibliotecas Python para aprendizado de máquina, como Numpy, Scipy, Scikit-learn, Theono, TensorFlow, PyTorch, Matplotlib, Keras, Pandas, etc. Usar as funções dessas bibliotecas economiza muito tempo escrevendo algoritmos para cada tarefa; os processos são menos demorados e fornecem resultados eficientes. Essas bibliotecas têm aplicações como processamento de matrizes, problemas de otimização, mineração de dados, análise estatística, cálculos envolvendo tensores, detecção de objetos, redes neurais e muito mais.