
15 perguntas e respostas da entrevista de aprendizado de máquina para 2022
Publicados: 2021-01-08Você é alguém que deseja fazer uma carreira de sucesso em Machine Learning? Se sim, ótimo para você!
Mas primeiro, você deve se preparar para o quebra-gelo – a entrevista do ML.
Como o processo de preparação para uma entrevista pode ser cansativo, decidimos intervir – aqui está uma lista com curadoria das 15 perguntas mais frequentes em entrevistas de Machine Learning!
- Qual é a diferença entre Deep Learning e Machine Learning?
Enquanto o Machine Learning envolve a aplicação e o uso de algoritmos avançados para analisar dados, descobrir os padrões ocultos nos dados e aprender com eles e, finalmente, aplicar os insights aprendidos para tomar decisões de negócios informadas. Quanto ao Deep Learning, é um subconjunto do Machine Learning que envolve o uso de Redes Neurais Artificiais que se inspiram na estrutura da rede neural do cérebro humano. Deep Learning é amplamente utilizado na detecção de recursos.
- Definir – Precisão e Recall.
Precisão ou Valor Preditivo Positivo mede ou, mais precisamente, prevê o número de verdadeiros positivos reivindicados por um modelo em comparação com o número de positivos que ele realmente reivindica.
Recall ou True Positive Rate refere-se ao número de positivos reivindicados por um modelo em comparação com o número real de positivos presentes em todos os dados.

Participe do Curso de Aprendizado de Máquina on-line das principais universidades do mundo - Mestrados, Programas de Pós-Graduação Executiva e Programa de Certificado Avançado em ML e IA para acelerar sua carreira.
- Explique os termos 'viés' e 'variância'. '
Durante o processo de treinamento, o erro esperado de um algoritmo de aprendizado é geralmente classificado ou decomposto em duas partes – viés e variância. Enquanto 'bias' é uma situação de erro causada devido ao uso de suposições simples no algoritmo de aprendizado, 'variância' denota um erro causado devido à complexidade desse algoritmo de aprendizado na análise de dados. O viés mede a proximidade do classificador médio criado pelo algoritmo de aprendizado para a função de destino e a variância mede quanto a previsão do algoritmo de aprendizado varia para diferentes conjuntos de dados de treinamento.
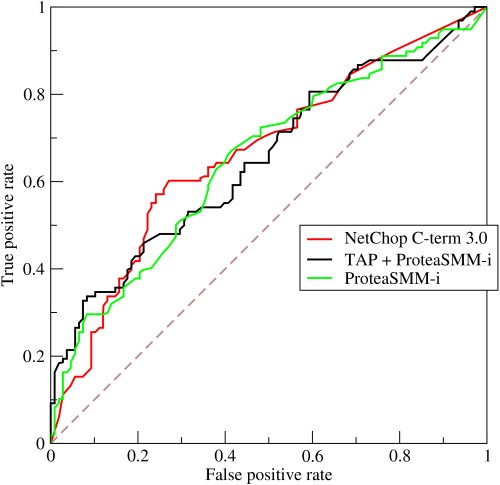
- Como funciona uma curva ROC?
A curva ROC ou Receiver Operating Characteristic é uma representação gráfica da variação entre as taxas de verdadeiros positivos e as taxas de falsos positivos em diferentes limites. É uma ferramenta fundamental para avaliação de testes diagnósticos e é frequentemente usada como uma representação do trade-off entre a sensibilidade do modelo (verdadeiros positivos) versus a probabilidade de acionar falsos alarmes (falsos positivos).
Fonte
- A curva representa o trade-off entre sensibilidade e especificidade – se a sensibilidade aumentar, a especificidade diminuirá.
- Se a curva borda mais para o eixo esquerdo e para o topo do espaço ROC, o teste geralmente é mais preciso. No entanto, se a curva se aproximar da diagonal de 45 graus do espaço ROC, o teste é menos preciso ou confiável.
- A inclinação da linha tangente em um ponto de corte indica a Razão de Verossimilhança (LR) para aquele valor específico do teste.
- A área sob a curva mede a precisão do teste.
- Explique a diferença entre os erros tipo 1 e tipo 2?
O erro tipo 1 é um erro falso positivo que 'afirma' que ocorreu um incidente quando, na verdade, nada ocorreu. O melhor exemplo de um erro falso positivo é um falso alarme de incêndio – o alarme começa a tocar quando não há incêndio. Ao contrário disso, um erro tipo 2 é um erro falso negativo que 'afirma' que nada ocorreu quando algo definitivamente aconteceu. Seria um erro tipo 2 dizer a uma mulher grávida que ela não está carregando um bebê.
- Por que Bayes é chamado de “Naive Bayes?”
Naive Bayes é referido como “ingênuo” porque, embora tenha muitas aplicações práticas, é baseado na suposição de que é impossível encontrar em dados da vida real – todos os recursos em um conjunto de dados são cruciais, independentes e iguais. Na abordagem Naive Bayes, a probabilidade condicional é calculada como o produto puro das probabilidades de componentes individuais, implicando assim a completa independência das características. Infelizmente, essa suposição nunca pode ser cumprida em um cenário do mundo real.
- O que significa o termo 'Overfitting'? Você pode evitá-lo? Se sim, como?
Normalmente, durante o processo de treinamento, um modelo é alimentado com grandes quantidades de dados. No decorrer do processo, os dados começam a aprender mesmo com informações imprecisas e ruídos presentes no conjunto de dados de amostra. Isso cria uma influência negativa no desempenho do modelo em novos dados, ou seja, o modelo não consegue classificar com precisão novas instâncias/dados além daqueles do conjunto de treinamento. Isso é conhecido como Overfitting.
Sim, é possível evitar o Overfitting. Veja como:
- Reúna mais dados (de fontes diferentes) para treinar o modelo com amostras diferentes.
- Aplique métodos de agrupamento (por exemplo, Random Forest) que usam a abordagem de ensacamento para minimizar a variação nas previsões justapondo os resultados de várias árvores de decisão em diferentes unidades do conjunto de dados.
- Certifique-se de usar técnicas de validação cruzada.
- Cite os dois métodos usados para calibração no Aprendizado Supervisionado.
Os dois métodos de calibração no Aprendizado Supervisionado são – Calibração Platt e Regressão Isotônica. Ambos os métodos são projetados especificamente para classificação binária.
- Por que você podar uma árvore de decisão?
Árvores de decisão precisam ser podadas para se livrar dos ramos com habilidades preditivas fracas. Isso ajuda a minimizar o quociente de complexidade do modelo de Árvore de Decisão e otimizar sua precisão preditiva. A poda pode ser feita de cima para baixo ou de baixo para cima. Poda de erro reduzida, poda de complexidade de custo, poda de complexidade de erro e poda de erro mínimo são alguns dos métodos de poda de árvore de decisão mais usados.

- O que se entende por pontuação F1?
Em termos simples, a pontuação F1 é uma medida do desempenho de um modelo – uma média da Precisão e Recall de um modelo, com resultados próximos de 1 sendo os melhores e aqueles próximos de 0 sendo os piores. A pontuação F1 pode ser usada em testes de classificação que não dão importância aos verdadeiros negativos.
- Diferencie entre um algoritmo Generativo e Discriminativo.
Enquanto um algoritmo Generativo aprende as categorias de dados, um algoritmo Discriminativo aprende a distinção entre diferentes categorias de dados. Quando se trata de tarefas de classificação, os modelos discriminativos geralmente superam os modelos generativos.
- O que é Aprendizagem em Conjunto?
O Ensemble Learning usa uma combinação de algoritmos de aprendizado para otimizar o desempenho preditivo dos modelos. Nesse método, vários modelos, como classificadores ou especialistas, são gerados estrategicamente e combinados para evitar o Overfitting nos modelos. É usado principalmente para melhorar a previsão, classificação, aproximação de função, desempenho, etc., de um modelo.
- Defina 'truque do kernel'.
O método Kernel Trick envolve o uso de funções do kernel que podem operar em um espaço de recurso implícito e de dimensão superior sem ter que calcular explicitamente as coordenadas dos pontos dentro dessa dimensão. As funções de kernel calculam os produtos internos entre as imagens de todos os pares de dados presentes em um espaço de recursos. Este procedimento é computacionalmente mais barato comparado ao cálculo explícito das coordenadas e é conhecido como Kernel Trick.
- Como você deve lidar com dados ausentes ou corrompidos em um conjunto de dados?
Para localizar os dados ausentes/corrompidos em um conjunto de dados, você deve eliminar as linhas e colunas ou substituí-las por outros valores. A biblioteca Pandas tem dois ótimos métodos para encontrar dados ausentes/corrompidos – isnull() e dropna(). Ambas as funções são projetadas especificamente para ajudá-lo a encontrar as linhas/colunas de dados com dados ausentes/corrompidos e eliminar esses valores.
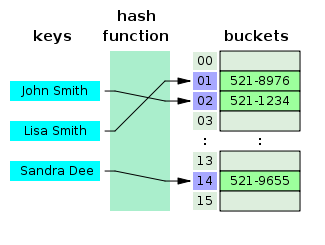
- O que é uma tabela de hash?
Uma tabela de hash é uma estrutura de dados que cria uma matriz associativa, na qual uma chave é mapeada para valores específicos usando uma função de hash. As tabelas de hash são usadas principalmente na indexação de banco de dados.
Fonte
Esta lista de perguntas destina-se apenas a apresentar o básico do Machine Learning e, francamente, essas vinte perguntas são apenas uma gota no mar. O aprendizado de máquina está avançando enquanto falamos e, portanto, com o tempo, novos conceitos surgirão. A chave para acertar suas entrevistas de ML, portanto, está em abrigar um desejo constante de aprender e aprimorar suas habilidades. Então, comece a explorar a Internet, leia jornais, participe de comunidades online, participe de conferências e seminários de ML – há muitas maneiras de aprender.
Para entrar em uma grande organização, um certificado de uma instituição de renome é essencial. Confira o Programa PG Executivo do IIIT-B em Machine Learning e IA e obtenha assistência de trabalho das principais empresas de ML e IA.
Quais são as limitações do Ensemble Learning?
As abordagens ensemble podem ajudar na redução da variância e no desenvolvimento de modelos mais robustos. No entanto, existem algumas desvantagens no uso de técnicas de conjunto, como a falta de explicabilidade e desempenho. Além disso, tenha em mente que a eficácia dos ensembles se origina de sua capacidade de agregar vários modelos que focam em diferentes aspectos da questão. No entanto, eles têm um período de previsão mais longo porque você pode precisar de previsões de centenas de modelos. Mesmo que tenham projeções melhores, o ganho de precisão pode não valer a pena.
Quanto tempo é necessário para aprender Machine Learning?
Quando se trata de Machine Learning, as tecnologias complexas utilizadas para o mesmo podem facilmente assustar as pessoas. No entanto, compreendê-lo pouco a pouco não é difícil. Experiência anterior em estatística, matemática avançada e assim por diante, sem dúvida, o ajudará a compreender rapidamente todos os conceitos. No entanto, como a formação e as habilidades educacionais variam de pessoa para pessoa, um indivíduo pode aprender ML em três semanas, enquanto outro pode precisar de um ano.
Como o Machine Learning está sendo usado no nosso dia a dia?
O Gmail categoriza os e-mails como essenciais, classificando-os como Primário, Promoções, Social e Atualização usando Machine Learning. As empresas estão utilizando redes neurais para detectar transações fraudulentas com base em dados como a frequência mais recente de transações, valor da transação e tipo de comerciante. Os detectores de plágio também fazem uso de aprendizado de máquina. Quando se trata de engenharia de ML, leva cerca de seis meses para terminar.