
Classificador KNN para aprendizado de máquina: tudo o que você precisa saber
Publicados: 2021-09-28Lembre-se da época em que a inteligência artificial (IA) era apenas um conceito limitado a romances e filmes de ficção científica? Bem, graças ao avanço tecnológico, a IA é algo com o qual vivemos todos os dias. De Alexa e Siri estarem à nossa disposição para plataformas OTT “escolhendo” os filmes que gostaríamos de assistir, a IA quase se tornou a ordem do dia e está aqui para dizer no futuro próximo.
Tudo isso é possível graças aos algoritmos avançados de ML. Hoje, vamos falar sobre um algoritmo de ML tão útil, o classificador K-NN.
Um ramo da IA e da ciência da computação, o aprendizado de máquina usa dados e algoritmos para imitar a compreensão humana, melhorando gradualmente a precisão dos algoritmos. O aprendizado de máquina envolve algoritmos de treinamento para fazer previsões ou classificações e descobrir insights importantes que impulsionam a tomada de decisões estratégicas em negócios e aplicativos.
O algoritmo KNN (k-neest neighbor) é um algoritmo de aprendizado de máquina supervisionado fundamental usado para resolver declarações de problemas de regressão e classificação. Então, vamos mergulhar para saber mais sobre o Classificador K-NN.
Índice
Aprendizado de máquina supervisionado x não supervisionado
O aprendizado supervisionado e não supervisionado são duas abordagens básicas da ciência de dados, e é pertinente saber a diferença antes de entrarmos nos detalhes do KNN.
O aprendizado supervisionado é uma abordagem de aprendizado de máquina que usa conjuntos de dados rotulados para ajudar a prever resultados. Esses conjuntos de dados são projetados para “supervisionar” ou treinar algoritmos para prever resultados ou classificar dados com precisão. Assim, entradas e saídas rotuladas permitem que o modelo aprenda ao longo do tempo, melhorando sua precisão.

A aprendizagem supervisionada envolve dois tipos de problemas – classificação e regressão. Em problemas de classificação , algoritmos alocam dados de teste em categorias discretas, como separar gatos de cães.
Um exemplo significativo da vida real seria classificar e-mails de spam em uma pasta separada da sua caixa de entrada. Por outro lado, o método de regressão do aprendizado supervisionado treina algoritmos para entender a relação entre variáveis independentes e dependentes. Ele usa diferentes pontos de dados para prever valores numéricos, como projetar a receita de vendas de um negócio.
O aprendizado não supervisionado , pelo contrário, usa algoritmos de aprendizado de máquina para a análise e agrupamento de conjuntos de dados não rotulados. Assim, não há necessidade de intervenção humana (“não supervisionada”) para que os algoritmos identifiquem padrões ocultos nos dados.
Os modelos de aprendizado não supervisionado têm três aplicações principais – associação, agrupamento e redução de dimensionalidade. No entanto, não entraremos em detalhes, pois está além do nosso escopo de discussão.
K-vizinho mais próximo (KNN)
O algoritmo K-Nearest Neighbor ou KNN é um algoritmo de aprendizado de máquina baseado no modelo de aprendizado supervisionado. O algoritmo K-NN funciona assumindo que coisas semelhantes existem próximas umas das outras. Assim, o algoritmo K-NN utiliza similaridade de recursos entre os novos pontos de dados e os pontos no conjunto de treinamento (casos disponíveis) para prever os valores dos novos pontos de dados. Em essência, o algoritmo K-NN atribui um valor ao ponto de dados mais recente com base na semelhança com os pontos no conjunto de treinamento. O algoritmo K-NN encontra aplicação em problemas de classificação e regressão, mas é usado principalmente para problemas de classificação.
Aqui está um exemplo para entender o Classificador K-NN.

Fonte
Na imagem acima, o valor de entrada é uma criatura com semelhanças com um gato e um cachorro. No entanto, queremos classificá-lo em um gato ou um cachorro. Assim, podemos usar o algoritmo K-NN para esta classificação. O modelo K-NN encontrará semelhanças entre o novo conjunto de dados (entrada) e as imagens de cães e gatos disponíveis (conjunto de dados de treinamento). Posteriormente, o modelo colocará o novo ponto de dados na categoria gato ou cachorro com base nos recursos mais semelhantes.
Da mesma forma, a categoria A (pontos verdes) e a categoria B (pontos laranja) possuem o exemplo gráfico acima. Também temos um novo ponto de dados (ponto azul) que se enquadra em qualquer uma das categorias. Podemos resolver esse problema de classificação usando um algoritmo K-NN e identificar a nova categoria de ponto de dados.
Definindo Propriedades do Algoritmo K-NN
As duas propriedades a seguir definem melhor o algoritmo K-NN:
- É um algoritmo de aprendizado lento porque, em vez de aprender com o conjunto de treinamento imediatamente, o algoritmo K-NN armazena o conjunto de dados e treina a partir do conjunto de dados no momento da classificação.
- O K-NN também é um algoritmo não paramétrico , o que significa que não faz suposições sobre os dados subjacentes.
Funcionamento do Algoritmo K-NN
Agora, vamos dar uma olhada nas etapas a seguir para entender como o algoritmo K-NN funciona.
Etapa 1: Carregar os dados de treinamento e teste.
Passo 2: Escolha os pontos de dados mais próximos, ou seja, o valor de K.
Etapa 3: Calcule a distância do número K de vizinhos (a distância entre cada linha de dados de treinamento e dados de teste). O método euclidiano é mais comumente usado para calcular a distância.
Passo 4: Pegue os K vizinhos mais próximos com base na distância euclidiana calculada.
Passo 5: Entre os K vizinhos mais próximos, conte o número de pontos de dados em cada categoria.
Etapa 6: Distribuir os novos pontos de dados para aquela categoria para a qual o número de vizinhos é máximo.
Passo 7: Fim. O modelo já está pronto.
Participe de cursos de Inteligência Artificial on-line das principais universidades do mundo - Mestrados, Programas de Pós-Graduação Executiva e Programa de Certificado Avançado em ML e IA para acelerar sua carreira.
Escolhendo o valor de K
K é um parâmetro crítico no algoritmo K-NN. Portanto, precisamos ter em mente alguns pontos antes de decidir sobre um valor de K.
O uso de curvas de erro é um método comum para determinar o valor de K. A imagem abaixo mostra curvas de erro para diferentes valores de K para dados de teste e treinamento.


Fonte
No exemplo gráfico acima, o erro de trem é zero em K=1 nos dados de treinamento porque o vizinho mais próximo do ponto é o próprio ponto. No entanto, o erro de teste é alto mesmo em valores baixos de K. Isso é chamado de alta variância ou overfitting de dados. O erro do teste diminui à medida que aumentamos o valor de K., mas após um certo valor de K, vemos que o erro do teste aumenta novamente, chamado de bias ou underfitting. Assim, o erro de dados de teste é inicialmente alto devido à variância, posteriormente diminui e estabiliza, e com um aumento adicional no valor de K, o erro de teste novamente dispara devido ao viés.
Portanto, o valor de K no qual o erro de teste se estabiliza e é baixo é considerado o valor ótimo de K. Considerando a curva de erro acima, K=8 é o valor ótimo.
Um exemplo para entender o funcionamento do algoritmo K-NN
Considere um conjunto de dados que foi plotado da seguinte forma:

Fonte
Digamos que haja um novo ponto de dados (ponto preto) em (60,60) que temos que classificar na classe roxa ou vermelha. Usaremos K=3, o que significa que o novo ponto de dados encontrará três pontos de dados mais próximos, dois na classe vermelha e um na classe roxa.
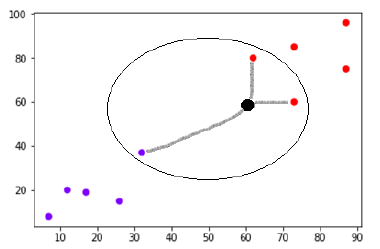
Fonte
Os vizinhos mais próximos são determinados calculando a distância euclidiana entre dois pontos. Aqui está uma ilustração para mostrar como o cálculo é feito.

Fonte
Agora, como dois (dos três) dos vizinhos mais próximos do novo ponto de dados (ponto preto) estão na classe vermelha, o novo ponto de dados também será atribuído à classe vermelha.
Participe do Curso de Aprendizado de Máquina on-line das principais universidades do mundo - Mestrados, Programas de Pós-Graduação Executiva e Programa de Certificado Avançado em ML e IA para acelerar sua carreira.
K-NN como classificador (implementação em Python)
Agora que temos uma explicação simplificada do algoritmo K-NN, vamos implementar o algoritmo K-NN em Python. Vamos nos concentrar apenas no Classificador K-NN.
Etapa 1: importe os pacotes Python necessários.

Fonte
Etapa 2: baixe o conjunto de dados da íris do repositório de aprendizado de máquina UCI. Seu weblink é “https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data”
Etapa 3: atribua nomes de coluna ao conjunto de dados.

Fonte
Etapa 4: leia o conjunto de dados para o Pandas DataFrame.

Fonte
Etapa 5: O pré-processamento de dados é feito usando as seguintes linhas de script.

Fonte
Etapa 6: divida o conjunto de dados em divisão de teste e treinamento. O código abaixo dividirá o conjunto de dados em 40% de dados de teste e 60% de dados de treinamento.

Fonte
Etapa 7: O dimensionamento de dados é feito da seguinte forma:

Fonte
Etapa 8: Treine o modelo usando a classe KNeighborsClassifier do sklearn.

Fonte
Etapa 9: faça uma previsão usando o seguinte script:

Fonte
Passo 10: Imprima os resultados.

Fonte
Saída:

Fonte
Qual o proximo? Inscreva-se no Advanced Certificate Program in Machine Learning do IIT Madras e upGrad
Suponha que você esteja aspirando a se tornar um Cientista de Dados ou profissional de Aprendizado de Máquina qualificado. Nesse caso, o Curso de Certificação Avançada em Machine Learning e Cloud do IIT Madras e upGrad é só para você!
O programa online de 12 meses é especialmente projetado para profissionais que buscam dominar conceitos em Machine Learning, Big Data Processing, Data Management, Data Warehousing, Cloud e implantação de modelos de Machine Learning.
Aqui estão alguns destaques do curso para que você tenha uma ideia melhor do que o programa oferece:
- Certificação de prestígio globalmente aceita do IIT Madras
- Mais de 500 horas de aprendizado, mais de 20 estudos de caso e projetos, mais de 25 sessões de orientação do setor, mais de 8 tarefas de codificação
- Cobertura abrangente de 7 linguagens e ferramentas de programação
- 4 semanas de projeto capstone da indústria
- Workshops práticos
- Rede ponto a ponto offline
Inscreva-se hoje para saber mais sobre o programa!
Conclusão
Com o tempo, o Big Data continua a crescer e a inteligência artificial se torna cada vez mais entrelaçada com nossas vidas. Como resultado, há um aumento agudo na demanda por profissionais de ciência de dados que podem aproveitar o poder dos modelos de aprendizado de máquina para coletar insights de dados e melhorar processos críticos de negócios e, em geral, nosso mundo. Sem dúvida, o campo da inteligência artificial e aprendizado de máquina parece realmente promissor. Com o upGrad , você pode ter certeza de que sua carreira em aprendizado de máquina e nuvem é recompensadora!
Por que o K-NN é um bom classificador?
A principal vantagem do K-NN sobre outros algoritmos de aprendizado de máquina é que podemos usar convenientemente o K-NN para classificação multiclasse. Assim, K-NN é o melhor algoritmo se precisarmos classificar os dados em mais de duas categorias ou se os dados compreenderem mais de dois rótulos. Além disso, é ideal para dados não lineares e tem uma precisão relativamente alta.
Qual é a limitação do algoritmo K-NN?
O algoritmo K-NN funciona calculando a distância entre os pontos de dados. Portanto, é bastante óbvio que é um algoritmo relativamente mais demorado e levará mais tempo para classificar em alguns casos. Portanto, é melhor não usar muitos pontos de dados ao usar K-NN para classificação multiclasse. Outras limitações incluem alto armazenamento de memória e sensibilidade a recursos irrelevantes.
Quais são as aplicações reais do K-NN?
A K-NN tem vários casos de uso da vida real em aprendizado de máquina, como detecção de manuscrito, reconhecimento de fala, reconhecimento de vídeo e reconhecimento de imagem. No setor bancário, K-NN é usado para prever se um indivíduo é elegível para um empréstimo com base em características semelhantes aos inadimplentes. Na política, K-NN pode ser usado para classificar potenciais eleitores em diferentes classes, como “votar no partido X” ou “votar no partido Y”, etc.