
Melhore seu conhecimento de JavaScript lendo o código-fonte
Publicados: 2022-03-10Você se lembra da primeira vez que mergulhou fundo no código-fonte de uma biblioteca ou framework que você usa com frequência? Para mim, esse momento veio durante meu primeiro trabalho como desenvolvedor frontend há três anos.
Tínhamos acabado de reescrever uma estrutura legada interna que usamos para criar cursos de e-learning. No início da reescrita, passamos um tempo investigando várias soluções diferentes, incluindo Mithril, Inferno, Angular, React, Aurelia, Vue e Polymer. Como eu era muito iniciante (tinha acabado de mudar do jornalismo para o desenvolvimento web), lembro de me sentir intimidado pela complexidade de cada framework e não entender como cada um funcionava.
Minha compreensão cresceu quando comecei a investigar nossa estrutura escolhida, Mithril, em maior profundidade. Desde então, meu conhecimento de JavaScript – e programação em geral – tem sido muito ajudado pelas horas que passei cavando profundamente nas entranhas das bibliotecas que uso diariamente no trabalho ou em meus próprios projetos. Neste post, compartilharei algumas das maneiras pelas quais você pode usar sua biblioteca ou estrutura favorita e usá-la como uma ferramenta educacional.
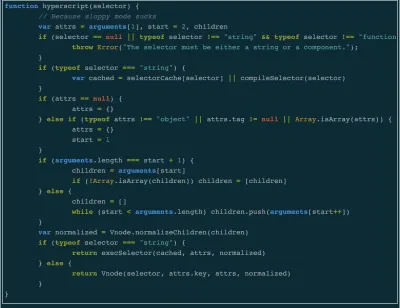
Os benefícios de ler o código-fonte
Um dos principais benefícios de ler o código-fonte é o número de coisas que você pode aprender. Quando examinei a base de código do Mithril pela primeira vez, tive uma vaga ideia do que era o DOM virtual. Quando terminei, fiquei sabendo que o DOM virtual é uma técnica que envolve a criação de uma árvore de objetos que descrevem como deve ser a interface do usuário. Essa árvore é então transformada em elementos DOM usando APIs DOM como document.createElement . As atualizações são realizadas criando uma nova árvore descrevendo o estado futuro da interface do usuário e comparando-a com os objetos da árvore antiga.
Eu tinha lido sobre tudo isso em vários artigos e tutoriais e, embora tenha sido útil, poder observá-lo em funcionamento no contexto de um aplicativo que enviamos foi muito esclarecedor para mim. Também me ensinou quais perguntas fazer ao comparar diferentes estruturas. Em vez de olhar para as estrelas do GitHub, por exemplo, agora eu sabia fazer perguntas como: “Como a maneira como cada estrutura executa atualizações afeta o desempenho e a experiência do usuário?”
Outro benefício é um aumento em sua apreciação e compreensão de uma boa arquitetura de aplicativo. Embora a maioria dos projetos de código aberto geralmente siga a mesma estrutura com seus repositórios, cada um deles contém diferenças. A estrutura do Mithril é bastante simples e, se você estiver familiarizado com sua API, poderá fazer suposições educadas sobre o código em pastas como render , router e request . Por outro lado, a estrutura do React reflete sua nova arquitetura. Os mantenedores separaram o módulo responsável pelas atualizações da interface do usuário ( react-reconciler ) do módulo responsável por renderizar os elementos DOM ( react-dom ).
Um dos benefícios disso é que agora é mais fácil para os desenvolvedores escreverem seus próprios renderizadores personalizados conectando-se ao pacote react-reconciler . Parcel, um empacotador de módulos que tenho estudado recentemente, também tem uma pasta de packages como React. O módulo chave é denominado parcel-bundler e contém o código responsável pela criação de bundles, ativando o servidor de módulo quente e a ferramenta de linha de comando.

Ainda outro benefício - que foi uma surpresa bem-vinda para mim - é que você fica mais confortável lendo a especificação oficial do JavaScript que define como a linguagem funciona. A primeira vez que li a especificação foi quando estava investigando a diferença entre throw Error e throw new Error (alerta de spoiler - não há). Eu olhei para isso porque notei que Mithril usou throw Error na implementação de sua função m e me perguntei se havia algum benefício em usá-lo sobre throw new Error . Desde então, também aprendi que os operadores lógicos && e || não necessariamente retornam booleanos, encontrei as regras que governam como o operador de igualdade == coage valores e a razão Object.prototype.toString.call({}) retorna '[object Object]' .
Técnicas de leitura do código-fonte
Há muitas maneiras de abordar o código-fonte. Descobri que a maneira mais fácil de começar é selecionando um método da biblioteca escolhida e documentando o que acontece quando você o chama. Não documente cada etapa, mas tente identificar seu fluxo e estrutura geral.
Eu fiz isso recentemente com ReactDOM.render e, consequentemente, aprendi muito sobre o React Fiber e algumas das razões por trás de sua implementação. Felizmente, como o React é um framework popular, me deparei com muitos artigos escritos por outros desenvolvedores sobre o mesmo problema e isso acelerou o processo.
Este mergulho profundo também me apresentou os conceitos de agendamento cooperativo, o método window.requestIdleCallback e um exemplo real de listas vinculadas (o React lida com atualizações colocando-as em uma fila que é uma lista vinculada de atualizações priorizadas). Ao fazer isso, é aconselhável criar um aplicativo muito básico usando a biblioteca. Isso facilita a depuração porque você não precisa lidar com os rastreamentos de pilha causados por outras bibliotecas.
Se não estiver fazendo uma revisão detalhada, abrirei a pasta /node_modules em um projeto em que estou trabalhando ou irei para o repositório GitHub. Isso geralmente acontece quando me deparo com um bug ou recurso interessante. Ao ler o código no GitHub, verifique se você está lendo a versão mais recente. Você pode visualizar o código de commits com a tag de versão mais recente clicando no botão usado para alterar as ramificações e selecionar “tags”. Bibliotecas e frameworks estão sempre passando por mudanças, então você não quer aprender sobre algo que pode ser descartado na próxima versão.
Outra maneira menos complicada de ler o código-fonte é o que eu gosto de chamar de método de 'olhar superficial'. Logo no início, quando comecei a ler o código, instalei express.js , abri sua pasta /node_modules e passei por suas dependências. Se o README não me forneceu uma explicação satisfatória, eu leio a fonte. Fazer isso me levou a essas descobertas interessantes:

- O Express depende de dois módulos que mesclam objetos, mas o fazem de maneiras muito diferentes.
merge-descriptorsapenas adiciona propriedades diretamente encontradas diretamente no objeto de origem e também mescla propriedades não enumeráveis, enquantoutils-mergeapenas itera sobre as propriedades enumeráveis de um objeto, bem como aquelas encontradas em sua cadeia de protótipos.merge-descriptorsusaObject.getOwnPropertyNames()eObject.getOwnPropertyDescriptor()enquantoutils-mergeusafor..in; - O módulo
setprototypeoffornece uma maneira multiplataforma de configurar o protótipo de um objeto instanciado; -
escape-htmlé um módulo de 78 linhas para escapar de uma string de conteúdo para que possa ser interpolada no conteúdo HTML.
Embora as descobertas provavelmente não sejam úteis imediatamente, é útil ter uma compreensão geral das dependências usadas por sua biblioteca ou estrutura.
Quando se trata de depurar código front-end, as ferramentas de depuração do seu navegador são suas melhores amigas. Entre outras coisas, eles permitem que você pare o programa a qualquer momento e inspecione seu estado, pule a execução de uma função ou entre ou saia dela. Às vezes, isso não será imediatamente possível porque o código foi minificado. Eu costumo unminificá-lo e copiar o código unminified no arquivo relevante na pasta /node_modules .
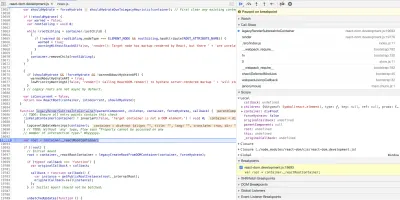
Estudo de caso: Função Connect do Redux
React-Redux é uma biblioteca usada para gerenciar o estado de aplicativos React. Ao lidar com bibliotecas populares como essas, começo pesquisando artigos que foram escritos sobre sua implementação. Ao fazer isso para este estudo de caso, me deparei com este artigo. Esta é outra coisa boa sobre a leitura do código-fonte. A fase de pesquisa geralmente leva você a artigos informativos como este, que apenas melhoram seu próprio pensamento e compreensão.
connect é uma função React-Redux que conecta componentes React ao armazenamento Redux de um aplicativo. Quão? Bem, de acordo com os documentos, ele faz o seguinte:
“...retorna uma nova classe de componente conectada que envolve o componente que você passou.”
Depois de ler isso, eu faria as seguintes perguntas:
- Conheço algum padrão ou conceito em que as funções recebem uma entrada e, em seguida, retornam essa mesma entrada agrupada com funcionalidade adicional?
- Se eu souber de algum desses padrões, como eu implementaria isso com base na explicação dada nos documentos?
Normalmente, o próximo passo seria criar um aplicativo de exemplo muito básico que usa connect . No entanto, nesta ocasião optei por usar o novo aplicativo React que estamos construindo no Limejump porque queria entender a connect dentro do contexto de um aplicativo que acabará entrando em um ambiente de produção.
O componente em que estou focando se parece com isso:
class MarketContainer extends Component { // code omitted for brevity } const mapDispatchToProps = dispatch => { return { updateSummary: (summary, start, today) => dispatch(updateSummary(summary, start, today)) } } export default connect(null, mapDispatchToProps)(MarketContainer); É um componente de contêiner que envolve quatro componentes conectados menores. Uma das primeiras coisas que você encontra no arquivo que exporta o método connect é este comentário: connect é uma fachada sobre connectAdvanced . Sem ir muito longe, temos nosso primeiro momento de aprendizado: uma oportunidade de observar o padrão de projeto da fachada em ação . No final do arquivo vemos que connect exporta uma invocação de uma função chamada createConnect . Seus parâmetros são um monte de valores padrão que foram desestruturados assim:
export function createConnect({ connectHOC = connectAdvanced, mapStateToPropsFactories = defaultMapStateToPropsFactories, mapDispatchToPropsFactories = defaultMapDispatchToPropsFactories, mergePropsFactories = defaultMergePropsFactories, selectorFactory = defaultSelectorFactory } = {})Novamente, nos deparamos com outro momento de aprendizado: exportar funções invocadas e desestruturar argumentos de funções padrão . A parte de desestruturação é um momento de aprendizado porque se o código tivesse sido escrito assim:
export function createConnect({ connectHOC = connectAdvanced, mapStateToPropsFactories = defaultMapStateToPropsFactories, mapDispatchToPropsFactories = defaultMapDispatchToPropsFactories, mergePropsFactories = defaultMergePropsFactories, selectorFactory = defaultSelectorFactory }) Teria resultado neste erro Uncaught TypeError: Cannot destructure property 'connectHOC' of 'undefined' or 'null'. Isso ocorre porque a função não tem argumento padrão para recorrer.
Nota : Para saber mais sobre isso, você pode ler o artigo de David Walsh. Alguns momentos de aprendizado podem parecer triviais, dependendo do seu conhecimento do idioma, e por isso pode ser melhor se concentrar em coisas que você não viu antes ou precisa aprender mais.
O próprio createConnect não faz nada em seu corpo de função. Ele retorna uma função chamada connect , a que usei aqui:
export default connect(null, mapDispatchToProps)(MarketContainer) São necessários quatro argumentos, todos opcionais, e os três primeiros argumentos passam por uma função de match que ajuda a definir seu comportamento de acordo com a presença dos argumentos e seu tipo de valor. Agora, como o segundo argumento fornecido para match é uma das três funções importadas para connect , tenho que decidir qual thread seguir.
Há momentos de aprendizado com a função proxy usada para envolver o primeiro argumento para connect se esses argumentos forem funções, o utilitário isPlainObject usado para verificar objetos simples ou o módulo de warning que revela como você pode configurar seu depurador para interromper todas as exceções. Após as funções match, chegamos ao connectHOC , a função que pega nosso componente React e o conecta ao Redux. É outra invocação de função que retorna wrapWithConnect , a função que realmente lida com a conexão do componente à loja.
Observando a implementação do connectHOC , posso entender por que ele precisa connect para ocultar seus detalhes de implementação. É o coração do React-Redux e contém lógica que não precisa ser exposta via connect . Mesmo que eu termine o mergulho profundo aqui, se eu continuasse, este teria sido o momento perfeito para consultar o material de referência que encontrei anteriormente, pois contém uma explicação incrivelmente detalhada da base de código.
Resumo
Ler o código-fonte é difícil no começo, mas como em qualquer coisa, fica mais fácil com o tempo. O objetivo não é entender tudo, mas sair com uma perspectiva diferente e novos conhecimentos. A chave é ser deliberado sobre todo o processo e intensamente curioso sobre tudo.
Por exemplo, achei a função isPlainObject interessante porque ela usa isso if (typeof obj !== 'object' || obj === null) return false para garantir que o argumento fornecido seja um objeto simples. Quando li sua implementação pela primeira vez, me perguntei por que ele não usava Object.prototype.toString.call(opts) !== '[object Object]' , que é menos código e distingue entre objetos e subtipos de objeto, como Date objeto. No entanto, a leitura da próxima linha revelou que no caso extremamente improvável de um desenvolvedor usando connect retornar um objeto Date, por exemplo, isso será tratado pela verificação de Object.getPrototypeOf(obj) === null .
Outra intriga em isPlainObject é este código:
while (Object.getPrototypeOf(baseProto) !== null) { baseProto = Object.getPrototypeOf(baseProto) }Algumas pesquisas no Google me levaram a esse thread do StackOverflow e ao problema do Redux explicando como esse código lida com casos como a verificação de objetos originados de um iFrame.
Links úteis na leitura do código-fonte
- “Como reverter estruturas de engenharia”, Max Koretskyi, Medium
- “Como ler código”, Aria Stewart, GitHub