
Apresentando a API baseada em componentes
Publicados: 2022-03-10Este artigo foi atualizado em 31 de janeiro de 2019 para reagir aos comentários dos leitores. O autor adicionou recursos de consulta personalizada à API baseada em componentes e descreve como ela funciona .
Uma API é o canal de comunicação para um aplicativo carregar dados do servidor. No mundo das APIs, REST tem sido a metodologia mais estabelecida, mas ultimamente tem sido ofuscada pelo GraphQL, que oferece vantagens importantes sobre REST. Enquanto o REST requer várias solicitações HTTP para buscar um conjunto de dados para renderizar um componente, o GraphQL pode consultar e recuperar esses dados em uma única solicitação, e a resposta será exatamente o que é necessário, sem excesso ou falta de dados, como normalmente acontece em DESCANSO.
Neste artigo, descreverei outra maneira de buscar dados que projetei e chamei de “PoP” (e de código aberto aqui), que expande a ideia de buscar dados para várias entidades em uma única solicitação introduzida pelo GraphQL e leva um passo adiante, ou seja, enquanto o REST busca os dados de um recurso e o GraphQL busca os dados de todos os recursos em um componente, a API baseada em componentes pode buscar os dados de todos os recursos de todos os componentes em uma página.
Usar uma API baseada em componentes faz mais sentido quando o próprio site é construído usando componentes, ou seja, quando a página da Web é composta iterativamente por componentes que envolvem outros componentes até que, no topo, obtenhamos um único componente que representa a página. Por exemplo, a página da Web mostrada na imagem abaixo é construída com componentes, que são descritos com quadrados:
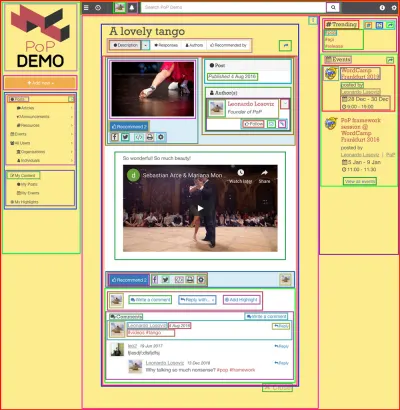
Uma API baseada em componentes é capaz de fazer uma única solicitação ao servidor solicitando os dados de todos os recursos de cada componente (assim como de todos os componentes da página), o que é feito mantendo os relacionamentos entre os componentes em a própria estrutura da API.
Entre outros, esta estrutura oferece os seguintes benefícios:
- Uma página com muitos componentes acionará apenas uma solicitação em vez de muitas;
- Os dados compartilhados entre os componentes podem ser obtidos apenas uma vez do banco de dados e impressos apenas uma vez na resposta;
- Ele pode reduzir bastante — até mesmo remover completamente — a necessidade de um armazenamento de dados.
Vamos explorar isso em detalhes ao longo do artigo, mas primeiro, vamos explorar quais componentes realmente são e como podemos construir um site com base nesses componentes e, finalmente, explorar como funciona uma API baseada em componentes.
Leitura recomendada : A GraphQL Primer: Por que precisamos de um novo tipo de API
Construindo um site por meio de componentes
Um componente é simplesmente um conjunto de pedaços de código HTML, JavaScript e CSS juntos para criar uma entidade autônoma. Isso pode então envolver outros componentes para criar estruturas mais complexas e também ser encapsulado por outros componentes. Um componente tem uma finalidade, que pode variar de algo muito básico (como um link ou um botão) a algo muito elaborado (como um carrossel ou um uploader de imagens de arrastar e soltar). Os componentes são mais úteis quando são genéricos e permitem a personalização por meio de propriedades injetadas (ou “props”), para que possam atender a uma ampla variedade de casos de uso. No caso extremo, o próprio site torna-se um componente.
O termo “componente” é frequentemente usado para se referir tanto à funcionalidade quanto ao design. Por exemplo, em relação à funcionalidade, frameworks JavaScript como React ou Vue permitem criar componentes do lado do cliente, que são capazes de auto-renderização (por exemplo, após a API buscar seus dados necessários) e usar props para definir valores de configuração em seus componentes encapsulados, permitindo a reutilização do código. No que diz respeito ao design, o Bootstrap padronizou a aparência dos sites através de sua biblioteca de componentes front-end, e tornou-se uma tendência saudável para as equipes criar sistemas de design para manter seus sites, o que permite que os diferentes membros da equipe (designers e desenvolvedores, mas também comerciantes e vendedores) para falar uma linguagem unificada e expressar uma identidade consistente.
Componentizar um site, então, é uma maneira muito sensata de tornar o site mais sustentável. Sites que usam estruturas JavaScript, como React e Vue, já são baseados em componentes (pelo menos no lado do cliente). Usar uma biblioteca de componentes como o Bootstrap não necessariamente torna o site baseado em componentes (pode ser um grande pedaço de HTML), no entanto, incorpora o conceito de elementos reutilizáveis para a interface do usuário.
Se o site é um grande pedaço de HTML, para nós o componentizemos devemos quebrar o layout em uma série de padrões recorrentes, para os quais devemos identificar e catalogar seções na página com base em sua similaridade de funcionalidade e estilos, e quebrar esses seções em camadas, o mais granular possível, tentando fazer com que cada camada se concentre em um único objetivo ou ação e também tentando combinar camadas comuns em diferentes seções.
Nota : O “Atomic Design” de Brad Frost é uma ótima metodologia para identificar esses padrões comuns e construir um sistema de design reutilizável.
Portanto, construir um site por meio de componentes é semelhante a brincar com LEGO. Cada componente é uma funcionalidade atômica, uma composição de outros componentes ou uma combinação dos dois.
Conforme mostrado abaixo, um componente básico (um avatar) é composto iterativamente por outros componentes até obter a página da web no topo:

A especificação da API baseada em componentes
Para a API baseada em componentes que eu projetei, um componente é chamado de “módulo”, então a partir de agora os termos “componente” e “módulo” são usados alternadamente.
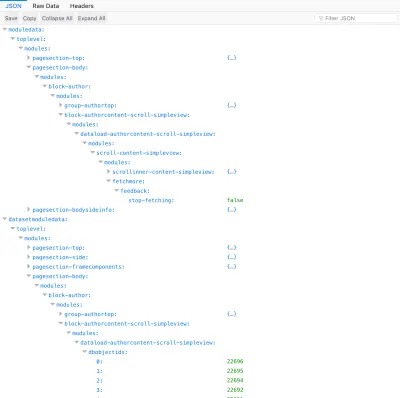
O relacionamento de todos os módulos que se envolvem, desde o módulo mais alto até o último nível, é chamado de “hierarquia de componentes”. Esse relacionamento pode ser expresso por meio de um array associativo (um array de key => property) no lado do servidor, no qual cada módulo declara seu nome como o atributo key e seus módulos internos sob a propriedade modules . A API então simplesmente codifica essa matriz como um objeto JSON para consumo:
// Component hierarchy on server-side, eg through PHP: [ "top-module" => [ "modules" => [ "module-level1" => [ "modules" => [ "module-level11" => [ "modules" => [...] ], "module-level12" => [ "modules" => [ "module-level121" => [ "modules" => [...] ] ] ] ] ], "module-level2" => [ "modules" => [ "module-level21" => [ "modules" => [...] ] ] ] ] ] ] // Component hierarchy encoded as JSON: { "top-module": { modules: { "module-level1": { modules: { "module-level11": { ... }, "module-level12": { modules: { "module-level121": { ... } } } } }, "module-level2": { modules: { "module-level21": { ... } } } } } }A relação entre os módulos é definida estritamente de cima para baixo: um módulo envolve outros módulos e sabe quem eles são, mas não sabe – e não se importa – quais módulos o estão envolvendo.
Por exemplo, no código JSON acima, o módulo module-level1 sabe que envolve os módulos module-level11 e module-level12 e, transitivamente, também sabe que envolve o module-level121 ; mas o module module-level11 não se importa com quem o está envolvendo, consequentemente não tem conhecimento do module-level1 .
Tendo a estrutura baseada em componentes, agora podemos adicionar as informações reais exigidas por cada módulo, que são categorizadas em configurações (como valores de configuração e outras propriedades) e dados (como os IDs dos objetos de banco de dados consultados e outras propriedades) , e colocado de acordo com as entradas modulesettings e moduledata :
{ modulesettings: { "top-module": { configuration: {...}, ..., modules: { "module-level1": { configuration: {...}, ..., modules: { "module-level11": { repeat... }, "module-level12": { configuration: {...}, ..., modules: { "module-level121": { repeat... } } } } }, "module-level2": { configuration: {...}, ..., modules: { "module-level21": { repeat... } } } } } }, moduledata: { "top-module": { dbobjectids: [...], ..., modules: { "module-level1": { dbobjectids: [...], ..., modules: { "module-level11": { repeat... }, "module-level12": { dbobjectids: [...], ..., modules: { "module-level121": { repeat... } } } } }, "module-level2": { dbobjectids: [...], ..., modules: { "module-level21": { repeat... } } } } } } } A seguir, a API adicionará os dados do objeto do banco de dados. Essas informações não são colocadas em cada módulo, mas em uma seção compartilhada chamada databases , para evitar a duplicação de informações quando dois ou mais módulos diferentes buscam os mesmos objetos do banco de dados.
Além disso, a API representa os dados do objeto de banco de dados de maneira relacional, para evitar a duplicação de informações quando dois ou mais objetos de banco de dados diferentes estão relacionados a um objeto comum (como duas postagens com o mesmo autor). Em outras palavras, os dados do objeto de banco de dados são normalizados.
Leitura recomendada : Construindo um formulário de contato sem servidor para seu site estático
A estrutura é um dicionário, organizado em cada tipo de objeto primeiro e segundo o ID do objeto, a partir do qual podemos obter as propriedades do objeto:
{ databases: { primary: { dbobject_type: { dbobject_id: { property: ..., ... }, ... }, ... } } }Este objeto JSON já é a resposta da API baseada em componentes. Seu formato é uma especificação por si só: desde que o servidor retorne a resposta JSON em seu formato necessário, o cliente pode consumir a API independentemente de como ela é implementada. Assim, a API pode ser implementada em qualquer linguagem (o que é uma das belezas do GraphQL: ser uma especificação e não uma implementação real permitiu que ela se tornasse disponível em uma infinidade de linguagens).
Nota : Em um próximo artigo, descreverei minha implementação da API baseada em componentes em PHP (que é a disponível no repositório).
Exemplo de resposta da API
Por exemplo, a resposta da API abaixo contém uma hierarquia de componentes com dois módulos, page => post-feed , onde o módulo post-feed busca postagens do blog. Observe o seguinte:
- Cada módulo sabe quais são seus objetos consultados da propriedade
dbobjectids(IDs4e9para as postagens do blog) - Cada módulo conhece o tipo de objeto para seus objetos consultados da propriedade
dbkeys(os dados de cada postagem são encontrados emposts, e os dados de autor da postagem, correspondentes ao autor com o ID fornecido na propriedadeauthorda postagem , são encontrados emusers) - Como os dados do objeto de banco de dados são relacionais, a propriedade
authorcontém o ID para o objeto author em vez de imprimir os dados do autor diretamente.
{ moduledata: { "page": { modules: { "post-feed": { dbobjectids: [4, 9] } } } }, modulesettings: { "page": { modules: { "post-feed": { dbkeys: { id: "posts", author: "users" } } } } }, databases: { primary: { posts: { 4: { title: "Hello World!", author: 7 }, 9: { title: "Everything fine?", author: 7 } }, users: { 7: { name: "Leo" } } } } }Diferenças na busca de dados de APIs baseadas em recursos, baseadas em esquemas e baseadas em componentes
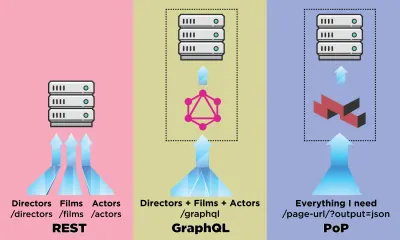
Vamos ver como uma API baseada em componentes, como PoP, se compara, ao buscar dados, a uma API baseada em recursos, como REST, e a uma API baseada em esquema, como GraphQL.
Digamos que o IMDB tenha uma página com dois componentes que precisam buscar dados: “Diretor em destaque” (mostrando uma descrição de George Lucas e uma lista de seus filmes) e “Filmes recomendados para você” (mostrando filmes como Star Wars: Episódio I — A Ameaça Fantasma e O Exterminador do Futuro ). Poderia ficar assim:
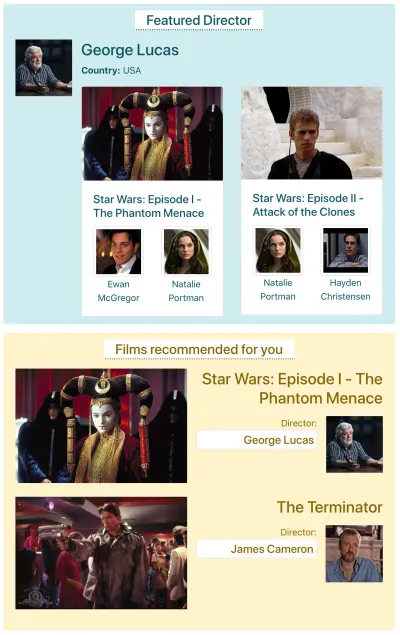
Vamos ver quantas solicitações são necessárias para buscar os dados por meio de cada método de API. Para este exemplo, o componente “Diretor em destaque” traz um resultado (“George Lucas”), do qual recupera dois filmes ( Star Wars: Episódio I — A Ameaça Fantasma e Star Wars: Episódio II — Ataque dos Clones ), e para cada filme dois atores (“Ewan McGregor” e “Natalie Portman” para o primeiro filme, e “Natalie Portman” e “Hayden Christensen” para o segundo filme). O componente “Filmes recomendados para você” traz dois resultados ( Star Wars: Episódio I — A Ameaça Fantasma e O Exterminador do Futuro ), e depois busca seus diretores (“George Lucas” e “James Cameron”, respectivamente).
Usando REST para renderizar o componente featured-director , podemos precisar das 7 requisições a seguir (esse número pode variar dependendo de quantos dados são fornecidos por cada endpoint, ou seja, quanto over-fetching foi implementado):
GET - /featured-director GET - /directors/george-lucas GET - /films/the-phantom-menace GET - /films/attack-of-the-clones GET - /actors/ewan-mcgregor GET - /actors/natalie-portman GET - /actors/hayden-christensen O GraphQL permite, por meio de esquemas fortemente tipados, buscar todos os dados necessários em uma única solicitação por componente. A consulta para buscar dados por meio do GraphQL para o componente featuredDirector se parece com isso (depois de implementarmos o esquema correspondente):
query { featuredDirector { name country avatar films { title thumbnail actors { name avatar } } } }E produz a seguinte resposta:
{ data: { featuredDirector: { name: "George Lucas", country: "USA", avatar: "...", films: [ { title: "Star Wars: Episode I - The Phantom Menace", thumbnail: "...", actors: [ { name: "Ewan McGregor", avatar: "...", }, { name: "Natalie Portman", avatar: "...", } ] }, { title: "Star Wars: Episode II - Attack of the Clones", thumbnail: "...", actors: [ { name: "Natalie Portman", avatar: "...", }, { name: "Hayden Christensen", avatar: "...", } ] } ] } } }E consultar o componente “Filmes recomendados para você” produz a seguinte resposta:
{ data: { films: [ { title: "Star Wars: Episode I - The Phantom Menace", thumbnail: "...", director: { name: "George Lucas", avatar: "...", } }, { title: "The Terminator", thumbnail: "...", director: { name: "James Cameron", avatar: "...", } } ] } } O PoP emitirá apenas uma solicitação para buscar todos os dados de todos os componentes da página e normalizar os resultados. O endpoint a ser chamado é simplesmente o mesmo que a URL para a qual precisamos obter os dados, apenas adicionando um parâmetro adicional output=json para indicar trazer os dados no formato JSON em vez de imprimi-los como HTML:
GET - /url-of-the-page/?output=json Supondo que a estrutura do módulo tenha um módulo superior chamado page contendo módulos featured-director e films-recommended-for-you , e estes também tenham submódulos, como este:
"page" modules "featured-director" modules "director-films" modules "film-actors" "films-recommended-for-you" modules "film-director"A única resposta JSON retornada terá esta aparência:
{ modulesettings: { "page": { modules: { "featured-director": { dbkeys: { id: "people", }, modules: { "director-films": { dbkeys: { films: "films" }, modules: { "film-actors": { dbkeys: { actors: "people" }, } } } } }, "films-recommended-for-you": { dbkeys: { id: "films", }, modules: { "film-director": { dbkeys: { director: "people" }, } } } } } }, moduledata: { "page": { modules: { "featured-director": { dbobjectids: [1] }, "films-recommended-for-you": { dbobjectids: [1, 3] } } } }, databases: { primary: { people { 1: { name: "George Lucas", country: "USA", avatar: "..." films: [1, 2] }, 2: { name: "Ewan McGregor", avatar: "..." }, 3: { name: "Natalie Portman", avatar: "..." }, 4: { name: "Hayden Christensen", avatar: "..." }, 5: { name: "James Cameron", avatar: "..." }, }, films: { 1: { title: "Star Wars: Episode I - The Phantom Menace", actors: [2, 3], director: 1, thumbnail: "..." }, 2: { title: "Star Wars: Episode II - Attack of the Clones", actors: [3, 4], thumbnail: "..." }, 3: { title: "The Terminator", director: 5, thumbnail: "..." }, } } } }Vamos analisar como esses três métodos se comparam, em termos de velocidade e quantidade de dados recuperados.
Velocidade
Por meio do REST, ter que buscar 7 solicitações apenas para renderizar um componente pode ser muito lento, principalmente em conexões de dados móveis e instáveis. Portanto, o salto do REST para o GraphQL representa muito para a velocidade, pois podemos renderizar um componente com apenas uma solicitação.
O PoP, porque pode buscar todos os dados de muitos componentes em uma solicitação, será mais rápido para renderizar muitos componentes de uma só vez; no entanto, provavelmente não há necessidade para isso. Ter os componentes renderizados em ordem (como aparecem na página), já é uma boa prática, e para aqueles componentes que aparecem sob a dobra certamente não há pressa em renderizá-los. Portanto, tanto as APIs baseadas em esquema quanto as baseadas em componentes já são muito boas e claramente superiores a uma API baseada em recursos.
Quantidade de dados
Em cada solicitação, os dados na resposta do GraphQL podem ser duplicados: a atriz “Natalie Portman” é buscada duas vezes na resposta do primeiro componente e, ao considerar a saída conjunta dos dois componentes, também podemos encontrar dados compartilhados, como filme Star Wars: Episódio I — A Ameaça Fantasma .
O PoP, por outro lado, normaliza os dados do banco de dados e os imprime apenas uma vez, porém, carrega a sobrecarga de imprimir a estrutura do módulo. Portanto, dependendo da solicitação específica com dados duplicados ou não, a API baseada em esquema ou a API baseada em componentes terão um tamanho menor.
Em conclusão, uma API baseada em esquema, como GraphQL, e uma API baseada em componentes, como PoP, são igualmente boas em relação ao desempenho e superiores a uma API baseada em recursos, como REST.
Leitura recomendada : Entendendo e usando APIs REST
Propriedades particulares de uma API baseada em componentes
Se uma API baseada em componentes não for necessariamente melhor em termos de desempenho do que uma API baseada em esquema, você pode estar se perguntando, então o que estou tentando alcançar com este artigo?
Nesta seção, tentarei convencê-lo de que tal API tem um potencial incrível, fornecendo vários recursos que são muito desejáveis, tornando-se um concorrente sério no mundo das APIs. Eu descrevo e demonstro cada um de seus grandes recursos exclusivos abaixo.
Os dados a serem recuperados do banco de dados podem ser inferidos da hierarquia de componentes
Quando um módulo exibe uma propriedade de um objeto de banco de dados, o módulo pode não saber, ou se importar, que objeto é; tudo o que importa é definir quais propriedades do objeto carregado são necessárias.
Por exemplo, considere a imagem abaixo. Um módulo carrega um objeto do banco de dados (neste caso, um único post), e então seus módulos descendentes mostrarão certas propriedades do objeto, como title e content :
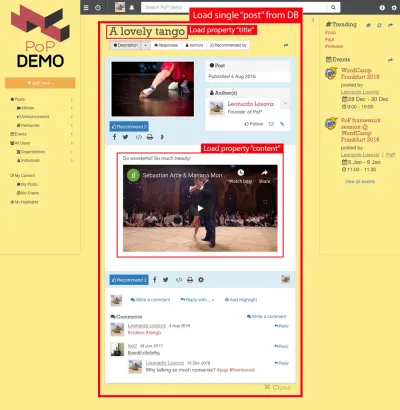
Assim, ao longo da hierarquia de componentes, os módulos “dataloading” serão responsáveis por carregar os objetos consultados (o módulo que carrega o post único, neste caso), e seus módulos descendentes definirão quais propriedades do objeto DB são necessárias ( title e content , neste caso).
A busca de todas as propriedades necessárias para o objeto DB pode ser feita automaticamente percorrendo a hierarquia de componentes: a partir do módulo de carregamento de dados, iteramos todos os seus módulos descendentes até chegar a um novo módulo de carregamento de dados, ou até o final da árvore; em cada nível, obtemos todas as propriedades necessárias e, em seguida, mesclamos todas as propriedades e as consultamos no banco de dados, todas elas apenas uma vez.
Na estrutura abaixo, o módulo single-post busca os resultados do BD (o post com ID 37), e os submódulos post-title e post-content definem as propriedades a serem carregadas para o objeto do BD consultado ( title e content respectivamente); submódulos post-layout e fetch-next-post-button não requerem nenhum campo de dados.
"single-post" => Load objects with object type "post" and ID 37 modules "post-layout" modules "post-title" => Load property "title" "post-content" => Load property "content" "fetch-next-post-button"A consulta a ser executada é calculada automaticamente a partir da hierarquia de componentes e seus campos de dados obrigatórios, contendo todas as propriedades necessárias para todos os módulos e seus submódulos:
SELECT title, content FROM posts WHERE id = 37 Ao buscar as propriedades para recuperar diretamente dos módulos, a consulta será atualizada automaticamente sempre que a hierarquia do componente for alterada. Se, por exemplo, adicionarmos o submódulo post-thumbnail , que requer a thumbnail do campo de dados :
"single-post" => Load objects with object type "post" and ID 37 modules "post-layout" modules "post-title" => Load property "title" "post-content" => Load property "content" "post-thumbnail" => Load property "thumbnail" "fetch-next-post-button"Em seguida, a consulta é atualizada automaticamente para buscar a propriedade adicional:
SELECT title, content, thumbnail FROM posts WHERE id = 37Como estabelecemos os dados do objeto de banco de dados a serem recuperados de maneira relacional, também podemos aplicar essa estratégia entre os relacionamentos entre os próprios objetos de banco de dados.
Considere a imagem abaixo: Começando pelo tipo de objeto post e descendo a hierarquia de componentes, precisaremos mudar o tipo de objeto DB para user e comment , correspondendo ao autor do post e a cada um dos comentários do post respectivamente, e então, para cada comentário, deve alterar novamente o tipo de objeto para user correspondente ao autor do comentário.
Passar de um objeto de banco de dados para um objeto relacional (possivelmente mudando o tipo de objeto, como em post => author passando de post para user , ou não, como em author => seguidores passando de user para user ) é o que chamo de “trocar domínios ”.
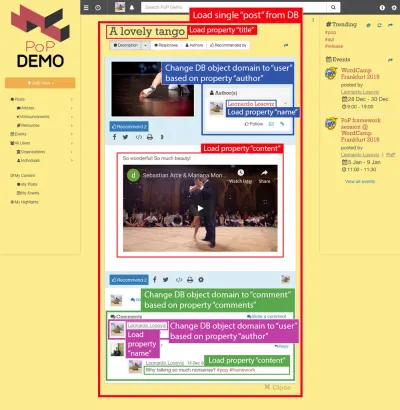
Depois de mudar para um novo domínio, desse nível na hierarquia de componentes para baixo, todas as propriedades necessárias serão submetidas ao novo domínio:
-
nameé obtido do objeto deuser(representando o autor da postagem), - o
contenté obtido do objeto decomment(representando cada um dos comentários da postagem), -
nameé obtido do objetouser(representando o autor de cada comentário).
Percorrendo a hierarquia de componentes, a API sabe quando está mudando para um novo domínio e, apropriadamente, atualiza a consulta para buscar o objeto relacional.
Por exemplo, se precisarmos mostrar dados do autor do post, empilhar o submódulo post-author mudará o domínio naquele nível de post para o user correspondente e, deste nível para baixo, o objeto DB carregado no contexto passado para o módulo é o usuário. Em seguida, os submódulos user-name e user-avatar em post-author carregarão as propriedades name e avatar no objeto user :
"single-post" => Load objects with object type "post" and ID 37 modules "post-layout" modules "post-title" => Load property "title" "post-content" => Load property "content" "post-author" => Switch domain from "post" to "user", based on property "author" modules "user-layout" modules "user-name" => Load property "name" "user-avatar" => Load property "avatar" "fetch-next-post-button"Resultando na seguinte consulta:
SELECT p.title, p.content, p.author, u.name, u.avatar FROM posts p INNER JOIN users u WHERE p.id = 37 AND p.author = u.idEm resumo, configurando cada módulo adequadamente, não há necessidade de escrever a consulta para buscar dados para uma API baseada em componentes. A consulta é produzida automaticamente a partir da própria estrutura da hierarquia de componentes, obtendo quais objetos devem ser carregados pelos módulos de carregamento de dados, os campos a serem recuperados para cada objeto carregado definido em cada módulo descendente e a comutação de domínio definida em cada módulo descendente.
Adicionar, remover, substituir ou alterar qualquer módulo atualizará automaticamente a consulta. Depois de executar a consulta, os dados recuperados serão exatamente o que é necessário - nada mais ou menos.
Observando Dados e Calculando Propriedades Adicionais
A partir do módulo de carregamento de dados na hierarquia de componentes, qualquer módulo pode observar os resultados retornados e calcular itens de dados extras com base neles, ou valores de feedback , que são colocados na entrada moduledata .
Por exemplo, o módulo fetch-next-post-button pode adicionar uma propriedade indicando se há mais resultados para buscar ou não (com base neste valor de feedback, se não houver mais resultados, o botão ficará desabilitado ou oculto):
{ moduledata: { "page": { modules: { "single-post": { modules: { "fetch-next-post-button": { feedback: { hasMoreResults: true } } } } } } } }O conhecimento implícito dos dados necessários diminui a complexidade e torna obsoleto o conceito de um “endpoint”
Conforme mostrado acima, a API baseada em componentes pode buscar exatamente os dados necessários, pois possui o modelo de todos os componentes no servidor e quais campos de dados são exigidos por cada componente. Em seguida, pode tornar implícito o conhecimento dos campos de dados necessários.

A vantagem é que definir quais dados são exigidos pelo componente pode ser atualizado apenas no lado do servidor, sem ter que reimplantar arquivos JavaScript, e o cliente pode ficar burro, apenas pedindo ao servidor para fornecer os dados que ele precisa , diminuindo assim a complexidade do aplicativo do lado do cliente.
Além disso, chamar a API para recuperar os dados de todos os componentes de uma URL específica pode ser realizada simplesmente consultando essa URL e adicionando o parâmetro extra output=json para indicar o retorno de dados da API em vez de imprimir a página. Assim, a URL torna-se seu próprio endpoint ou, considerado de outra forma, o conceito de “endpoint” torna-se obsoleto.
Recuperando subconjuntos de dados: os dados podem ser buscados para módulos específicos, encontrados em qualquer nível da hierarquia de componentes
O que acontece se não precisarmos buscar os dados de todos os módulos em uma página, mas simplesmente os dados de um módulo específico começando em qualquer nível da hierarquia de componentes? Por exemplo, se um módulo implementa uma rolagem infinita, ao rolar para baixo devemos buscar apenas novos dados para este módulo, e não para os outros módulos da página.
Isso pode ser feito filtrando as ramificações da hierarquia de componentes que serão incluídas na resposta, para incluir propriedades apenas a partir do módulo especificado e ignorar tudo acima desse nível. Na minha implementação (que descreverei em um próximo artigo), a filtragem é habilitada adicionando o parâmetro modulefilter=modulepaths à URL, e o módulo (ou módulos) selecionado é indicado através de um parâmetro modulepaths[] , onde um “module path ” é a lista de módulos começando do módulo mais alto para o módulo específico (por exemplo module1 => module2 => module3 tem caminho de módulo [ module1 , module2 , module3 ] e é passado como um parâmetro de URL como module1.module2.module3 ) .
Por exemplo, na hierarquia de componentes abaixo de cada módulo tem uma entrada dbobjectids :
"module1" dbobjectids: [...] modules "module2" dbobjectids: [...] modules "module3" dbobjectids: [...] "module4" dbobjectids: [...] "module5" dbobjectids: [...] modules "module6" dbobjectids: [...] Em seguida, solicitar o URL da página da Web adicionando os parâmetros modulefilter=modulepaths e modulepaths[]=module1.module2.module5 produzirá a seguinte resposta:
"module1" modules "module2" modules "module5" dbobjectids: [...] modules "module6" dbobjectids: [...] Em essência, a API começa a carregar dados a partir de module1 => module2 => module5 . É por isso que module6 , que vem sob module5 , também traz seus dados enquanto module3 e module4 não.
Além disso, podemos criar filtros de módulo personalizados para incluir um conjunto pré-organizado de módulos. Por exemplo, chamar uma página com modulefilter=userstate pode imprimir apenas os módulos que exigem o estado do usuário para renderizá-los no cliente, como os módulos module3 e module6 :
"module1" modules "module2" modules "module3" dbobjectids: [...] "module5" modules "module6" dbobjectids: [...] A informação de quais são os módulos iniciais vem na seção filteredmodules , em entry requestmeta , como uma matriz de caminhos de módulo:
requestmeta: { filteredmodules: [ ["module1", "module2", "module3"], ["module1", "module2", "module5", "module6"] ] }Este recurso permite implementar uma aplicação de página única descomplicada, na qual o frame do site é carregado na solicitação inicial:
"page" modules "navigation-top" dbobjectids: [...] "navigation-side" dbobjectids: [...] "page-content" dbobjectids: [...] Mas, a partir deles, podemos anexar o parâmetro modulefilter=page a todas as URLs solicitadas, filtrando o frame e trazendo apenas o conteúdo da página:
"page" modules "navigation-top" "navigation-side" "page-content" dbobjectids: [...] Semelhante aos filtros de módulo userstate e page descritos acima, podemos implementar qualquer filtro de módulo personalizado e criar experiências de usuário ricas.
O módulo é sua própria API
Conforme mostrado acima, podemos filtrar a resposta da API para recuperar dados a partir de qualquer módulo. Como consequência, cada módulo pode interagir consigo mesmo do cliente para o servidor apenas adicionando o caminho do módulo à URL da página da Web na qual foi incluído.
Espero que você desculpe minha excitação excessiva, mas eu realmente não posso enfatizar o suficiente como esse recurso é maravilhoso. Ao criar um componente, não precisamos criar uma API para acompanhá-lo para recuperar dados (REST, GraphQL ou qualquer coisa), porque o componente já pode se comunicar no servidor e carregar seu próprio dados — é completamente autônomo e de autoatendimento .
Cada módulo de carregamento de dados exporta a URL para interagir com ela na entrada dataloadsource da seção datasetmodulemeta :
{ datasetmodulemeta: { "module1": { modules: { "module2": { modules: { "module5": { meta: { dataloadsource: "https://page-url/?modulefilter=modulepaths&modulepaths[]=module1.module2.module5" }, modules: { "module6": { meta: { dataloadsource: "https://page-url/?modulefilter=modulepaths&modulepaths[]=module1.module2.module5.module6" } } } } } } } } } }A busca de dados é desacoplada entre módulos e seca
Para mostrar que a busca de dados em uma API baseada em componentes é altamente desacoplada e DRY ( D on't R epeat Yourself), primeiro precisarei mostrar como em uma API baseada em esquema, como GraphQL, ela é menos desacoplada e não seco.
No GraphQL, a consulta para buscar dados deve indicar os campos de dados do componente, que podem incluir subcomponentes, e estes também podem incluir subcomponentes e assim por diante. Em seguida, o componente superior precisa saber quais dados são exigidos por cada um de seus subcomponentes também, para buscar esses dados.
Por exemplo, renderizar o componente <FeaturedDirector> pode exigir os seguintes subcomponentes:
Render <FeaturedDirector>: <div> Country: {country} {foreach films as film} <Film film={film} /> {/foreach} </div> Render <Film>: <div> Title: {title} Pic: {thumbnail} {foreach actors as actor} <Actor actor={actor} /> {/foreach} </div> Render <Actor>: <div> Name: {name} Photo: {avatar} </div> Nesse cenário, a consulta GraphQL é implementada no nível <FeaturedDirector> . Então, se o subcomponente <Film> for atualizado, solicitando o título por meio da propriedade filmTitle em vez de title , a consulta do componente <FeaturedDirector> também precisará ser atualizada para espelhar essas novas informações (o GraphQL possui um mecanismo de versionamento que pode lidar com com este problema, mas mais cedo ou mais tarde ainda devemos atualizar as informações). Isso produz complexidade de manutenção, que pode ser difícil de lidar quando os componentes internos mudam frequentemente ou são produzidos por desenvolvedores de terceiros. Assim, os componentes não são completamente desacoplados uns dos outros.
Da mesma forma, podemos querer renderizar diretamente o componente <Film> para algum filme específico, para o qual também devemos implementar uma consulta GraphQL nesse nível, para buscar os dados do filme e seus atores, o que adiciona código redundante: partes de a mesma consulta viverá em diferentes níveis da estrutura do componente. Portanto, o GraphQL não é DRY .
Como uma API baseada em componentes já sabe como seus componentes se agrupam em sua própria estrutura, esses problemas são completamente evitados. Por um lado, o cliente pode simplesmente solicitar os dados necessários de que precisa, quaisquer que sejam esses dados; if a subcomponent data field changes, the overall model already knows and adapts immediately, without having to modify the query for the parent component in the client. Therefore, the modules are highly decoupled from each other.
For another, we can fetch data starting from any module path, and it will always return the exact required data starting from that level; there are no duplicated queries whatsoever, or even queries to start with. Hence, a component-based API is fully DRY . (This is another feature that really excites me and makes me get wet.)
(Yes, pun fully intended. Sorry about that.)
Retrieving Configuration Values In Addition To Database Data
Let's revisit the example of the featured-director component for the IMDB site described above, which was created — you guessed it! — with Bootstrap. Instead of hardcoding the Bootstrap classnames or other properties such as the title's HTML tag or the avatar max width inside of JavaScript files (whether they are fixed inside the component, or set through props by parent components), each module can set these as configuration values through the API, so that then these can be directly updated on the server and without the need to redeploy JavaScript files. Similarly, we can pass strings (such as the title Featured director ) which can be already translated/internationalized on the server-side, avoiding the need to deploy locale configuration files to the front-end.
Similar to fetching data, by traversing the component hierarchy, the API is able to deliver the required configuration values for each module and nothing more or less.
The configuration values for the featured-director component might look like this:
{ modulesettings: { "page": { modules: { "featured-director": { configuration: { class: "alert alert-info", title: "Featured director", titletag: "h3" }, modules: { "director-films": { configuration: { classes: { wrapper: "media", avatar: "mr-3", body: "media-body", films: "row", film: "col-sm-6" }, avatarmaxsize: "100px" }, modules: { "film-actors": { configuration: { classes: { wrapper: "card", image: "card-img-top", body: "card-body", title: "card-title", avatar: "img-thumbnail" } } } } } } } } } } } Please notice how — because the configuration properties for different modules are nested under each module's level — these will never collide with each other if having the same name (eg property classes from one module will not override property classes from another module), avoiding having to add namespaces for modules.
Higher Degree Of Modularity Achieved In The Application
According to Wikipedia, modularity means:
The degree to which a system's components may be separated and recombined, often with the benefit of flexibility and variety in use. The concept of modularity is used primarily to reduce complexity by breaking a system into varying degrees of interdependence and independence across and 'hide the complexity of each part behind an abstraction and interface'.
Being able to update a component just from the server-side, without the need to redeploy JavaScript files, has the consequence of better reusability and maintenance of components. I will demonstrate this by re-imagining how this example coded for React would fare in a component-based API.
Let's say that we have a <ShareOnSocialMedia> component, currently with two items: <FacebookShare> and <TwitterShare> , like this:
Render <ShareOnSocialMedia>: <ul> <li>Share on Facebook: <FacebookShare url={window.location.href} /></li> <li>Share on Twitter: <TwitterShare url={window.location.href} /></li> </ul> But then Instagram got kind of cool, so we need to add an item <InstagramShare> to our <ShareOnSocialMedia> component, too:
Render <ShareOnSocialMedia>: <ul> <li>Share on Facebook: <FacebookShare url={window.location.href} /></li> <li>Share on Twitter: <TwitterShare url={window.location.href} /></li> <li>Share on Instagram: <InstagramShare url={window.location.href} /></li> </ul> In the React implementation, as it can be seen in the linked code, adding a new component <InstagramShare> under component <ShareOnSocialMedia> forces to redeploy the JavaScript file for the latter one, so then these two modules are not as decoupled as they could be.
Na API baseada em componentes, porém, podemos usar prontamente os relacionamentos entre os módulos já descritos na API para acoplar os módulos. Enquanto originalmente teremos esta resposta:
{ modulesettings: { "share-on-social-media": { modules: { "facebook-share": { configuration: {...} }, "twitter-share": { configuration: {...} } } } } }Depois de adicionar o Instagram, teremos a resposta atualizada:
{ modulesettings: { "share-on-social-media": { modules: { "facebook-share": { configuration: {...} }, "twitter-share": { configuration: {...} }, "instagram-share": { configuration: {...} } } } } } E apenas iterando todos os valores em modulesettings["share-on-social-media"].modules , o componente <ShareOnSocialMedia> pode ser atualizado para mostrar o componente <InstagramShare> sem a necessidade de reimplantar qualquer arquivo JavaScript. Assim, a API suporta a adição e remoção de módulos sem comprometer o código de outros módulos, alcançando um maior grau de modularidade.
Cache/armazenamento de dados do lado do cliente nativo
Os dados do banco de dados recuperados são normalizados em uma estrutura de dicionário e padronizados para que, a partir do valor em dbobjectids , qualquer parte dos dados nos bancos de databases possa ser alcançado apenas seguindo o caminho para ele conforme indicado nas entradas dbkeys , independentemente da forma como foi estruturado . Portanto, a lógica de organização dos dados já é nativa da própria API.
Podemos nos beneficiar dessa situação de várias maneiras. Por exemplo, os dados retornados para cada solicitação podem ser adicionados a um cache do lado do cliente contendo todos os dados solicitados pelo usuário durante a sessão. Assim, é possível evitar a adição de um armazenamento de dados externo como o Redux à aplicação (refiro-me ao tratamento de dados, não a outros recursos como o Undo/Redo, o ambiente colaborativo ou a depuração de viagem no tempo).
Além disso, a estrutura baseada em componentes promove o armazenamento em cache: a hierarquia de componentes não depende da URL, mas de quais componentes são necessários nessa URL. Dessa forma, dois eventos em /events/1/ e /events/2/ compartilharão a mesma hierarquia de componentes, e as informações de quais módulos são necessários podem ser reutilizadas entre eles. Como consequência, todas as propriedades (exceto dados do banco de dados) podem ser armazenadas em cache no cliente após buscar o primeiro evento e reutilizadas a partir de então, de modo que apenas os dados do banco de dados para cada evento subsequente devem ser buscados e nada mais.
Extensibilidade e reaproveitamento
A seção de databases de dados da API pode ser estendida, permitindo categorizar suas informações em subseções personalizadas. Por padrão, todos os dados do objeto de banco de dados são colocados na entrada primary , no entanto, também podemos criar entradas personalizadas onde colocar propriedades específicas do objeto de banco de dados.
Por exemplo, se o componente “Filmes recomendados para você” descrito anteriormente em mostra uma lista dos amigos do usuário logado que assistiram a este filme na propriedade friendsWhoWatchedFilm no objeto de banco de dados do film , porque esse valor mudará dependendo do usuário logado user, salvamos essa propriedade em uma entrada userstate , portanto, quando o usuário faz logout, excluímos apenas essa ramificação do banco de dados em cache no cliente, mas todos os dados primary ainda permanecem:
{ databases: { userstate: { films: { 5: { friendsWhoWatchedFilm: [22, 45] }, } }, primary: { films: { 5: { title: "The Terminator" }, } "people": { 22: { name: "Peter", }, 45: { name: "John", }, }, } } }Além disso, até certo ponto, a estrutura da resposta da API pode ser redefinida. Em particular, os resultados do banco de dados podem ser impressos em uma estrutura de dados diferente, como uma matriz em vez do dicionário padrão.
Por exemplo, se o tipo de objeto for apenas um (por exemplo, films ), ele pode ser formatado como um array para ser alimentado diretamente em um componente typeahead:
[ { title: "Star Wars: Episode I - The Phantom Menace", thumbnail: "..." }, { title: "Star Wars: Episode II - Attack of the Clones", thumbnail: "..." }, { title: "The Terminator", thumbnail: "..." }, ]Suporte para programação orientada a aspectos
Além de buscar dados, a API baseada em componentes também pode postar dados, como para criar uma postagem ou adicionar um comentário, e executar qualquer tipo de operação, como fazer login ou logout do usuário, enviar e-mails, log, análises, e assim por diante. Não há restrições: qualquer funcionalidade fornecida pelo CMS subjacente pode ser invocada por meio de um módulo — em qualquer nível.
Ao longo da hierarquia de componentes, podemos adicionar qualquer número de módulos e cada módulo pode executar sua própria operação. Portanto, nem todas as operações devem necessariamente estar relacionadas à ação esperada da requisição, como ao fazer uma operação POST, PUT ou DELETE em REST ou enviar uma mutação no GraphQL, mas podem ser adicionadas para fornecer funcionalidades extras, como enviar um email para o administrador quando um usuário cria uma nova postagem.
Assim, ao definir a hierarquia de componentes por meio de injeção de dependência ou arquivos de configuração, a API pode ser considerada compatível com programação orientada a aspectos, “um paradigma de programação que visa aumentar a modularidade, permitindo a separação de interesses transversais”.
Leitura recomendada : Protegendo seu site com política de recursos
Segurança melhorada
Os nomes dos módulos não são necessariamente fixos quando impressos na saída, mas podem ser encurtados, desconfigurados, alterados aleatoriamente ou (em resumo) tornados variáveis de qualquer maneira pretendida. Embora originalmente pensado para encurtar a saída da API (para que os nomes dos módulos carousel-featured-posts ou drag-and-drop-user-images pudessem ser encurtados para uma notação de base 64, como a1 , a2 e assim por diante, para o ambiente de produção ), esse recurso permite alterar frequentemente os nomes dos módulos na resposta da API por motivos de segurança.
Por exemplo, os nomes de entrada são, por padrão, nomeados como seu módulo correspondente; em seguida, módulos chamados username e password , que devem ser renderizados no cliente como <input type="text" name="{input_name}"> e <input type="password" name="{input_name}"> respectivamente, podem ser definidos valores aleatórios variados para seus nomes de entrada (como zwH8DSeG e QBG7m6EF hoje e c3oMLBjo e c46oVgN6 amanhã), tornando mais difícil para spammers e bots direcionarem o site.
Versatilidade por meio de modelos alternativos
O aninhamento de módulos permite ramificar para outro módulo para adicionar compatibilidade para uma mídia ou tecnologia específica, ou alterar algum estilo ou funcionalidade e, em seguida, retornar à ramificação original.
Por exemplo, digamos que a página da Web tenha a seguinte estrutura:
"module1" modules "module2" modules "module3" "module4" modules "module5" modules "module6" Nesse caso, gostaríamos de fazer o site funcionar também para AMP, no entanto, os módulos module2 , module4 e module5 não são compatíveis com AMP. Podemos ramificar esses módulos em módulos semelhantes, compatíveis com AMP, module2AMP , module4AMP e module5AMP , após o qual continuamos carregando a hierarquia de componentes original, para que apenas esses três módulos sejam substituídos (e nada mais):
"module1" modules "module2AMP" modules "module3" "module4AMP" modules "module5AMP" modules "module6"Isso torna bastante fácil gerar diferentes saídas a partir de uma única base de código, adicionando bifurcações apenas aqui e ali, conforme necessário, e sempre com escopo e restrito a módulos individuais.
Tempo de demonstração
O código que implementa a API conforme explicado neste artigo está disponível neste repositório de código aberto.
Eu implantei a API PoP em https://nextapi.getpop.org para fins de demonstração. O site é executado no WordPress, portanto, os links permanentes de URL são os típicos do WordPress. Conforme observado anteriormente, ao adicionar o parâmetro output=json a eles, esses URLs se tornam seus próprios endpoints de API.
O site é suportado pelo mesmo banco de dados do site PoP Demo, portanto, uma visualização da hierarquia de componentes e dados recuperados pode ser feita consultando a mesma URL neste outro site (por exemplo, visitando o https://demo.getpop.org/u/leo/ explica os dados de https://nextapi.getpop.org/u/leo/?output=json ).
Os links abaixo demonstram a API para casos descritos anteriormente:
- A página inicial, uma única postagem, um autor, uma lista de postagens e uma lista de usuários.
- Um evento, filtrando de um módulo específico.
- Uma tag, módulos de filtragem que exigem estado do usuário e filtragem para trazer apenas uma página de um aplicativo de página única.
- Uma matriz de locais, para alimentar um typeahead.
- Modelos alternativos para a página “Quem somos”: Normal, Imprimível, Incorporável.
- Alterando os nomes dos módulos: original vs mutilado.
- Filtrando informações: somente configurações do módulo, dados do módulo mais dados do banco de dados.
Conclusão
Uma boa API é um trampolim para a criação de aplicativos confiáveis, de fácil manutenção e poderosos. Neste artigo, descrevi os conceitos que alimentam uma API baseada em componentes que, acredito, é uma API muito boa, e espero ter convencido você também.
Até agora, o design e a implementação da API envolveram várias iterações e levaram mais de cinco anos — e ainda não está completamente pronto. No entanto, está em um estado bastante decente, não pronto para produção, mas como um alfa estável. Atualmente, ainda estou trabalhando nisso; trabalhando na definição da especificação aberta, implementando as camadas adicionais (como renderização) e escrevendo a documentação.
Em um próximo artigo, descreverei como funciona minha implementação da API. Até lá, se você tiver alguma opinião sobre isso – independentemente de ser positiva ou negativa – eu adoraria ler seus comentários abaixo.
Atualização (31 de janeiro): recursos de consulta personalizada
Alain Schlesser comentou que uma API que não pode ser consultada de forma personalizada do cliente é inútil, levando-nos de volta ao SOAP, como tal, não pode competir com REST ou GraphQL. Depois de dar seu comentário alguns dias de reflexão, tive que admitir que ele está certo. No entanto, em vez de descartar a API baseada em componentes como um empreendimento bem-intencionado, mas ainda não muito bom, fiz algo muito melhor: implementei o recurso de consulta personalizada para ela. E funciona como um encanto!
Nos links a seguir, os dados de um recurso ou coleção de recursos são buscados normalmente por meio de REST. No entanto, por meio de fields de parâmetros, também podemos especificar quais dados específicos recuperar para cada recurso, evitando dados excessivos ou insuficientes:
- Uma única postagem e uma coleção de postagens adicionando
fields=title,content,datetime - Um usuário e uma coleção de usuários adicionando
fields=name,username,description
Os links acima demonstram a busca de dados apenas para os recursos consultados. E os relacionamentos deles? Por exemplo, digamos que queremos recuperar uma lista de postagens com os campos "title" e "content" , os comentários de cada postagem com os campos "content" e "date" e o autor de cada comentário com os campos "name" e "url" . Para conseguir isso no GraphQL, implementaríamos a seguinte consulta:
query { post { title content comments { content date author { name url } } } } Para a implementação da API baseada em componentes, traduzi a consulta em sua expressão de “sintaxe de ponto” correspondente, que pode ser fornecida por meio de fields de parâmetro . Consultando em um recurso “post”, este valor é:
fields=title,content,comments.content,comments.date,comments.author.name,comments.author.url Ou pode ser simplificado, usando | para agrupar todos os campos aplicados ao mesmo recurso:
fields=title|content,comments.content|date,comments.author.name|urlAo executar esta consulta em um único post obtemos exatamente os dados necessários para todos os recursos envolvidos:
{ "datasetmodulesettings": { "dataload-dataquery-singlepost-fields": { "dbkeys": { "id": "posts", "comments": "comments", "comments.author": "users" } } }, "datasetmoduledata": { "dataload-dataquery-singlepost-fields": { "dbobjectids": [ 23691 ] } }, "databases": { "posts": { "23691": { "id": 23691, "title": "A lovely tango", "content": "<div class=\"responsiveembed-container\"><iframe loading="lazy" width=\"480\" height=\"270\" src=\"https:\\/\\/www.youtube.com\\/embed\\/sxm3Xyutc1s?feature=oembed\" frameborder=\"0\" allowfullscreen><\\/iframe><\\/div>\n", "comments": [ "25094", "25164" ] } }, "comments": { "25094": { "id": "25094", "content": "<p><a class=\"hashtagger-tag\" href=\"https:\\/\\/newapi.getpop.org\\/tags\\/videos\\/\">#videos<\\/a>\\u00a0<a class=\"hashtagger-tag\" href=\"https:\\/\\/newapi.getpop.org\\/tags\\/tango\\/\">#tango<\\/a><\\/p>\n", "date": "4 Aug 2016", "author": "851" }, "25164": { "id": "25164", "content": "<p>fjlasdjf;dlsfjdfsj<\\/p>\n", "date": "19 Jun 2017", "author": "1924" } }, "users": { "851": { "id": 851, "name": "Leonardo Losoviz", "url": "https:\\/\\/newapi.getpop.org\\/u\\/leo\\/" }, "1924": { "id": 1924, "name": "leo2", "url": "https:\\/\\/newapi.getpop.org\\/u\\/leo2\\/" } } } } Portanto, podemos consultar recursos de maneira REST e especificar consultas baseadas em esquema de maneira GraphQL, e obteremos exatamente o que é necessário, sem excesso ou falta de dados, e normalizando dados no banco de dados para que nenhum dado seja duplicado. Favoravelmente, a consulta pode incluir qualquer número de relacionamentos, aninhados profundamente, e estes são resolvidos com tempo de complexidade linear: pior caso de O(n+m), onde n é o número de nós que trocam de domínio (neste caso 2: comments e comments.author ) e m é o número de resultados recuperados (neste caso 5: 1 post + 2 comentários + 2 usuários), e o caso médio de O(n). (Isso é mais eficiente que o GraphQL, que possui tempo de complexidade polinomial O(n^c) e sofre com o aumento do tempo de execução à medida que a profundidade do nível aumenta).
Por fim, essa API também pode aplicar modificadores ao consultar dados, por exemplo, para filtrar quais recursos são recuperados, como pode ser feito por meio do GraphQL. Para conseguir isso, a API simplesmente fica em cima do aplicativo e pode usar convenientemente sua funcionalidade, portanto, não há necessidade de reinventar a roda. Por exemplo, adicionar parâmetros filter=posts&searchfor=internet filtrará todas as postagens que contêm "internet" de uma coleção de postagens.
A implementação deste novo recurso será descrita em um próximo artigo.