
Conversão de imagem para texto com React e Tesseract.js (OCR)
Publicados: 2022-03-10Os dados são a espinha dorsal de todos os aplicativos de software porque o principal objetivo de um aplicativo é resolver problemas humanos. Para resolver os problemas humanos, é necessário ter algumas informações sobre eles.
Tais informações são representadas como dados, principalmente por meio de computação. Na web, os dados são coletados principalmente na forma de textos, imagens, vídeos e muito mais. Às vezes, as imagens contêm textos essenciais que devem ser processados para atingir um determinado propósito. Essas imagens foram processadas principalmente manualmente porque não havia como processá-las programaticamente.
A incapacidade de extrair texto de imagens foi uma limitação de processamento de dados que experimentei em primeira mão na minha última empresa. Precisávamos processar cartões-presente digitalizados e tínhamos que fazer isso manualmente, pois não conseguíamos extrair texto das imagens.
Havia um departamento chamado “Operações” dentro da empresa que era responsável pela confirmação manual dos cartões-presente e crédito nas contas dos usuários. Embora tivéssemos um site através do qual os usuários se conectavam conosco, o processamento dos cartões-presente era realizado manualmente nos bastidores.
Na época, nosso site era construído principalmente com PHP (Laravel) para o backend e JavaScript (jQuery e Vue) para o frontend. Nossa pilha técnica era boa o suficiente para trabalhar com o Tesseract.js, desde que o problema fosse considerado importante pela administração.
Eu estava disposto a resolver o problema, mas não era necessário resolver o problema pelo ponto de vista do negócio ou da gestão. Depois de sair da empresa, decidi fazer algumas pesquisas e tentar encontrar possíveis soluções. Eventualmente, eu descobri OCR.
O que é OCR?
OCR significa “Optical Character Recognition” ou “Optical Character Reader”. É usado para extrair textos de imagens.
A evolução do OCR pode ser atribuída a várias invenções, mas Optophone, “Gismo”, scanner de mesa CCD, Newton MessagePad e Tesseract são as principais invenções que levam o reconhecimento de caracteres a outro nível de utilidade.
Então, por que usar OCR? Bem, o reconhecimento óptico de caracteres resolve muitos problemas, um dos quais me levou a escrever este artigo. Percebi que a capacidade de extrair textos de uma imagem garante muitas possibilidades, como:
- Regulamento
Toda organização precisa regular as atividades dos usuários por alguns motivos. O regulamento pode ser usado para proteger os direitos dos usuários e protegê-los contra ameaças ou golpes.
Extrair textos de uma imagem permite que uma organização processe informações textuais em uma imagem para regulamentação, especialmente quando as imagens são fornecidas por alguns dos usuários.
Por exemplo, a regulação semelhante ao Facebook do número de textos em imagens usadas para anúncios pode ser alcançada com OCR. Além disso, ocultar conteúdo sensível no Twitter também é possível pelo OCR. - Capacidade de pesquisa
A pesquisa é uma das atividades mais comuns, principalmente na internet. Os algoritmos de pesquisa baseiam-se principalmente na manipulação de textos. Com o Reconhecimento Óptico de Caracteres, é possível reconhecer caracteres em imagens e usá-los para fornecer resultados de imagem relevantes aos usuários. Em suma, imagens e vídeos agora são pesquisáveis com o auxílio do OCR. - Acessibilidade
Ter textos em imagens sempre foi um desafio para acessibilidade e é regra geral ter poucos textos em uma imagem. Com o OCR, os leitores de tela podem ter acesso a textos em imagens para fornecer alguma experiência necessária aos seus usuários. - Automação de processamento de dados O processamento de dados é principalmente automatizado para escala. Ter textos em imagens é uma limitação ao processamento de dados porque os textos não podem ser processados exceto manualmente. O Reconhecimento Óptico de Caracteres (OCR) possibilita a extração de textos em imagens de forma programática, garantindo a automação do processamento de dados, especialmente quando se trata do processamento de textos em imagens.
- Digitalização de Materiais Impressos
Tudo está se tornando digital e ainda há muitos documentos a serem digitalizados. Cheques, certificados e outros documentos físicos agora podem ser digitalizados com o uso do Reconhecimento Óptico de Caracteres.
Descobrir todos os usos acima aprofundou meus interesses, então decidi ir mais longe fazendo uma pergunta:
“Como posso usar OCR na web, especialmente em um aplicativo React?”
Essa pergunta me levou ao Tesseract.js.
O que é o Tesseract.js?
Tesseract.js é uma biblioteca JavaScript que compila o Tesseract original de C para JavaScript WebAssembly, tornando o OCR acessível no navegador. O mecanismo Tesseract.js foi originalmente escrito em ASM.js e posteriormente foi portado para WebAssembly, mas o ASM.js ainda serve como backup em alguns casos quando o WebAssembly não é suportado.
Conforme declarado no site do Tesseract.js, ele suporta mais de 100 idiomas , orientação automática de texto e detecção de script, uma interface simples para leitura de parágrafos, palavras e caixas delimitadoras de caracteres.
Tesseract é um mecanismo de reconhecimento óptico de caracteres para vários sistemas operacionais. É um software livre, lançado sob a licença Apache. A Hewlett-Packard desenvolveu o Tesseract como software proprietário na década de 1980. Foi lançado como código aberto em 2005 e seu desenvolvimento é patrocinado pelo Google desde 2006.
A versão mais recente, a versão 4, do Tesseract foi lançada em outubro de 2018 e contém um novo mecanismo de OCR que usa um sistema de rede neural baseado em Long Short-Term Memory (LSTM) e destina-se a produzir resultados mais precisos.
Entendendo as APIs do Tesseract
Para realmente entender como o Tesseract funciona, precisamos detalhar algumas de suas APIs e seus componentes. De acordo com a documentação do Tesseract.js, existem duas maneiras de abordar o uso dele. Abaixo está a primeira abordagem e seu detalhamento:
Tesseract.recognize( image,language, { logger: m => console.log(m) } ) .catch (err => { console.error(err); }) .then(result => { console.log(result); }) } O método de recognize toma imagem como seu primeiro argumento, idioma (que pode ser múltiplo) como seu segundo argumento e { logger: m => console.log(me) } como seu último argumento. Os formatos de imagem suportados pelo Tesseract são jpg, png, bmp e pbm que só podem ser fornecidos como elementos (img, video ou canvas), objeto de arquivo ( <input> ), objeto blob, caminho ou URL para uma imagem e imagem codificada em base64 . (Leia aqui para obter mais informações sobre todos os formatos de imagem que o Tesseract pode manipular.)
O idioma é fornecido como uma string, como eng . O sinal + pode ser usado para concatenar vários idiomas como em eng+chi_tra . O argumento language é usado para determinar os dados de idioma treinados a serem usados no processamento de imagens.
Nota : Você encontrará todos os idiomas disponíveis e seus códigos aqui.
{ logger: m => console.log(m) } é muito útil para obter informações sobre o andamento de uma imagem sendo processada. A propriedade logger usa uma função que será chamada várias vezes à medida que o Tesseract processa uma imagem. O parâmetro para a função logger deve ser um objeto com workerId , jobId , status e progress como suas propriedades:
{ workerId: 'worker-200030', jobId: 'job-734747', status: 'recognizing text', progress: '0.9' } progress é um número entre 0 e 1, e é em porcentagem para mostrar o progresso de um processo de reconhecimento de imagem.
O Tesseract gera automaticamente o objeto como um parâmetro para a função do registrador, mas também pode ser fornecido manualmente. À medida que um processo de reconhecimento está ocorrendo, as propriedades do objeto logger são atualizadas toda vez que a função é chamada . Portanto, ele pode ser usado para mostrar uma barra de progresso de conversão, alterar alguma parte de um aplicativo ou usado para obter qualquer resultado desejado.
O result no código acima é o resultado do processo de reconhecimento de imagem. Cada uma das propriedades de result tem a propriedade bbox como as coordenadas x/y de sua caixa delimitadora.
Aqui estão as propriedades do objeto de result , seus significados ou usos:
{ text: "I am codingnninja from Nigeria..." hocr: "<div class='ocr_page' id= ..." tsv: "1 1 0 0 0 0 0 0 1486 ..." box: null unlv: null osd: null confidence: 90 blocks: [{...}] psm: "SINGLE_BLOCK" oem: "DEFAULT" version: "4.0.0-825-g887c" paragraphs: [{...}] lines: (5) [{...}, ...] words: (47) [{...}, {...}, ...] symbols: (240) [{...}, {...}, ...] }-
text: Todo o texto reconhecido como uma string. -
lines: Uma matriz de cada linha reconhecida por linha de texto. -
words: uma matriz de cada palavra reconhecida. -
symbols: Uma matriz de cada um dos caracteres reconhecidos. -
paragraphs: uma matriz de todos os parágrafos reconhecidos. Vamos discutir “confiança” mais adiante neste artigo.
O Tesseract também pode ser usado de forma mais imperativa como em:
import { createWorker } from 'tesseract.js'; const worker = createWorker({ logger: m => console.log(m) }); (async () => { await worker.load(); await worker.loadLanguage('eng'); await worker.initialize('eng'); const { data: { text } } = await worker.recognize('https://tesseract.projectnaptha.com/img/eng_bw.png'); console.log(text); await worker.terminate(); })();Esta abordagem está relacionada com a primeira abordagem, mas com diferentes implementações.
createWorker(options) cria um trabalhador da web ou processo filho do nó que cria um trabalhador do Tesseract. O trabalhador ajuda a configurar o mecanismo Tesseract OCR. O método load() carrega os scripts principais do Tesseract, loadLanguage() carrega qualquer idioma fornecido a ele como uma string, initialize() garante que o Tesseract esteja totalmente pronto para uso e, em seguida, o método de reconhecimento é usado para processar a imagem fornecida. O método terminate() para o trabalhador e limpa tudo.
Observação : verifique a documentação das APIs do Tesseract para obter mais informações.
Agora, temos que construir algo para realmente ver o quão eficaz é o Tesseract.js.
O que vamos construir?
Vamos construir um extrator de PIN de cartão-presente porque extrair o PIN de um cartão-presente foi o problema que levou a essa aventura de escrita em primeiro lugar.
Construiremos um aplicativo simples que extrai o PIN de um cartão-presente digitalizado . À medida que me propus a construir um extrator de alfinetes de cartão-presente simples, mostrarei alguns dos desafios que enfrentei ao longo da linha, as soluções que forneci e minha conclusão com base na minha experiência.
- Ir para o código-fonte →
Abaixo está a imagem que vamos usar para teste porque tem algumas propriedades realistas que são possíveis no mundo real.

Vamos extrair AQUX-QWMB6L-R6JAU do cartão. Então vamos começar.
Instalação do React e Tesseract
Há uma pergunta a ser respondida antes de instalar o React e o Tesseract.js e a pergunta é: por que usar o React com o Tesseract? Praticamente, podemos usar o Tesseract com Vanilla JavaScript, qualquer biblioteca ou framework JavaScript como React, Vue e Angular.
Usar o React neste caso é uma preferência pessoal. Inicialmente, eu queria usar o Vue, mas decidi usar o React porque estou mais familiarizado com o React do que com o Vue.
Agora, vamos continuar com as instalações.
Para instalar o React com create-react-app, você deve executar o código abaixo:
npx create-react-app image-to-text cd image-to-text yarn add Tesseract.jsou
npm install tesseract.jsDecidi usar o yarn para instalar o Tesseract.js porque não consegui instalar o Tesseract com o npm, mas o yarn fez o trabalho sem estresse. Você pode usar o npm, mas eu recomendo instalar o Tesseract com yarn a julgar pela minha experiência.
Agora, vamos iniciar nosso servidor de desenvolvimento executando o código abaixo:
yarn startou
npm startDepois de executar yarn start ou npm start, seu navegador padrão deve abrir uma página da Web parecida com a abaixo:

Você também pode navegar para localhost:3000 no navegador, desde que a página não seja iniciada automaticamente.
Depois de instalar o React e o Tesseract.js, o que vem depois?
Configurando um formulário de upload
Neste caso, vamos ajustar a página inicial (App.js) que acabamos de visualizar no navegador para conter o formulário que precisamos:
import { useState, useRef } from 'react'; import Tesseract from 'tesseract.js'; import './App.css'; function App() { const [imagePath, setImagePath] = useState(""); const [text, setText] = useState(""); const handleChange = (event) => { setImage(URL.createObjectURL(event.target.files[0])); } return ( <div className="App"> <main className="App-main"> <h3>Actual image uploaded</h3> <img src={imagePath} className="App-logo" alt="logo"/> <h3>Extracted text</h3> <div className="text-box"> <p> {text} </p> </div> <input type="file" onChange={handleChange} /> </main> </div> ); } export default App A parte do código acima que precisa de nossa atenção neste momento é a função handleChange .
const handleChange = (event) => { setImage(URL.createObjectURL(event.target.files[0])); } Na função, URL.createObjectURL pega um arquivo selecionado por meio de event.target.files[0] e cria uma URL de referência que pode ser usada com tags HTML como img, audio e video. Usamos setImagePath para adicionar a URL ao estado. Agora, a URL agora pode ser acessada com imagePath .
<img src={imagePath} className="App-logo" alt="image"/> Definimos o atributo src da imagem como {imagePath} para visualizá-la no navegador antes de processá-la.
Convertendo Imagens Selecionadas em Textos
Como pegamos o caminho para a imagem selecionada, podemos passar o caminho da imagem para Tesseract.js para extrair textos dela.
import { useState} from 'react'; import Tesseract from 'tesseract.js'; import './App.css'; function App() { const [imagePath, setImagePath] = useState(""); const [text, setText] = useState(""); const handleChange = (event) => { setImagePath(URL.createObjectURL(event.target.files[0])); } const handleClick = () => { Tesseract.recognize( imagePath,'eng', { logger: m => console.log(m) } ) .catch (err => { console.error(err); }) .then(result => { // Get Confidence score let confidence = result.confidence let text = result.text setText(text); }) } return ( <div className="App"> <main className="App-main"> <h3>Actual imagePath uploaded</h3> <img src={imagePath} className="App-image" alt="logo"/> <h3>Extracted text</h3> <div className="text-box"> <p> {text} </p> </div> <input type="file" onChange={handleChange} /> <button onClick={handleClick} style={{height:50}}> convert to text</button> </main> </div> ); } export default AppAdicionamos a função “handleClick” ao “App.js e contém a API Tesseract.js que leva o caminho para a imagem selecionada. Tesseract.js leva “imagePath”, “idioma”, “um objeto de configuração”.
O botão abaixo é adicionado ao formulário para chamar “handClick” que aciona a conversão de imagem para texto sempre que o botão é clicado.
<button onClick={handleClick} style={{height:50}}> convert to text</button>Quando o processamento é bem-sucedido, acessamos “confiança” e “texto” do resultado. Em seguida, adicionamos “texto” ao estado com “setText(texto)”.
Ao adicionar a <p> {text} </p> , exibimos o texto extraído.
É óbvio que o “texto” é extraído da imagem, mas o que é confiança?
A confiança mostra a precisão da conversão. O nível de confiança está entre 1 e 100. 1 representa o pior, enquanto 100 representa o melhor em termos de precisão. Também pode ser usado para determinar se um texto extraído deve ser aceito como preciso ou não.
Então a questão é quais fatores podem afetar a pontuação de confiança ou a precisão de toda a conversão? Ele é afetado principalmente por três fatores principais — a qualidade e a natureza do documento usado, a qualidade da digitalização criada a partir do documento e as capacidades de processamento do mecanismo Tesseract.
Agora, vamos adicionar o código abaixo ao “App.css” para estilizar um pouco o aplicativo.
.App { text-align: center; } .App-image { width: 60vmin; pointer-events: none; } .App-main { background-color: #282c34; min-height: 100vh; display: flex; flex-direction: column; align-items: center; justify-content: center; font-size: calc(7px + 2vmin); color: white; } .text-box { background: #fff; color: #333; border-radius: 5px; text-align: center; }Aqui está o resultado do meu primeiro teste :
Resultado no Firefox
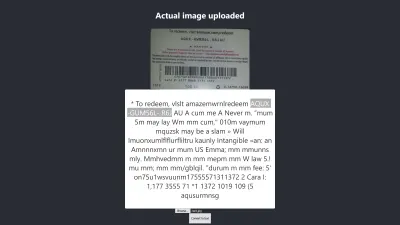
O nível de confiança do resultado acima é 64. Vale a pena notar que a imagem do cartão-presente é de cor escura e isso definitivamente afeta o resultado que obtemos.

Se você olhar mais de perto a imagem acima, verá que o pin do cartão está quase preciso no texto extraído. Não é preciso porque o cartão-presente não é muito claro.
Oh espere! Como será no Chrome?
Resultado no Chrome
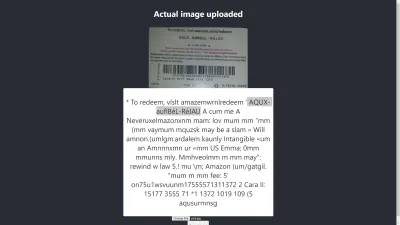
Ah! O resultado é ainda pior no Chrome. Mas por que o resultado no Chrome é diferente do Mozilla Firefox? Diferentes navegadores lidam com imagens e seus perfis de cores de maneira diferente. Isso significa que uma imagem pode ser renderizada de forma diferente dependendo do navegador . Ao fornecer image.data pré-renderizado ao Tesseract, é provável que produza um resultado diferente em diferentes navegadores porque image.data diferente é fornecido ao Tesseract dependendo do navegador em uso. O pré-processamento de uma imagem, como veremos mais adiante neste artigo, ajudará a obter um resultado consistente.
Precisamos ser mais precisos para que possamos ter certeza de que estamos recebendo ou fornecendo as informações corretas. Então temos que ir um pouco mais longe.
Vamos tentar mais para ver se conseguimos atingir o objetivo no final.
Teste de precisão
Existem muitos fatores que afetam uma conversão de imagem para texto com o Tesseract.js. A maioria desses fatores gira em torno da natureza da imagem que queremos processar e o restante depende de como o mecanismo do Tesseract lida com a conversão.
Internamente, o Tesseract pré-processa as imagens antes da conversão real do OCR, mas nem sempre fornece resultados precisos.
Como solução, podemos pré-processar imagens para obter conversões precisas. Podemos binarizar, inverter, dilatar, desinclinar ou redimensionar uma imagem para pré-processá-la para Tesseract.js.
O pré-processamento de imagens é muito trabalhoso ou um campo extenso por conta própria. Felizmente, o P5.js forneceu todas as técnicas de pré-processamento de imagem que queremos usar. Em vez de reinventar a roda ou usar toda a biblioteca só porque queremos usar uma pequena parte dela, copiei as que precisamos. Todas as técnicas de pré-processamento de imagem estão incluídas no preprocess.js.
O que é Binarização?
Binarização é a conversão dos pixels de uma imagem para preto ou branco. Queremos binarizar o cartão-presente anterior para verificar se a precisão será melhor ou não.
Anteriormente, extraímos alguns textos de um cartão-presente, mas o PIN de destino não era tão preciso quanto desejávamos. Portanto, há uma necessidade de encontrar outra maneira de obter um resultado preciso.
Agora, queremos binarizar o cartão-presente , ou seja, queremos converter seus pixels em preto e branco para que possamos ver se um melhor nível de precisão pode ser alcançado ou não.
As funções abaixo serão usadas para binarização e estão incluídas em um arquivo separado chamado preprocess.js.
function preprocessImage(canvas) { const ctx = canvas.getContext('2d'); const image = ctx.getImageData(0,0,canvas.width, canvas.height); thresholdFilter(image.data, 0.5); return image; } Export default preprocessImageO que o código acima faz?
Introduzimos o canvas para armazenar os dados de uma imagem para aplicar alguns filtros, para pré-processar a imagem, antes de passá-la para o Tesseract para conversão.
A primeira função preprocessImage está localizada em preprocess.js e prepara a tela para uso obtendo seus pixels. A função thresholdFilter binariza a imagem convertendo seus pixels em preto ou branco .
Vamos chamar preprocessImage para ver se o texto extraído do cartão-presente anterior pode ser mais preciso.
No momento em que atualizarmos o App.js, ele deverá ter a seguinte aparência no código:
import { useState, useRef } from 'react'; import preprocessImage from './preprocess'; import Tesseract from 'tesseract.js'; import './App.css'; function App() { const [image, setImage] = useState(""); const [text, setText] = useState(""); const canvasRef = useRef(null); const imageRef = useRef(null); const handleChange = (event) => { setImage(URL.createObjectURL(event.target.files[0])) } const handleClick = () => { const canvas = canvasRef.current; const ctx = canvas.getContext('2d'); ctx.drawImage(imageRef.current, 0, 0); ctx.putImageData(preprocessImage(canvas),0,0); const dataUrl = canvas.toDataURL("image/jpeg"); Tesseract.recognize( dataUrl,'eng', { logger: m => console.log(m) } ) .catch (err => { console.error(err); }) .then(result => { // Get Confidence score let confidence = result.confidence console.log(confidence) // Get full output let text = result.text setText(text); }) } return ( <div className="App"> <main className="App-main"> <h3>Actual image uploaded</h3> <img src={image} className="App-logo" alt="logo" ref={imageRef} /> <h3>Canvas</h3> <canvas ref={canvasRef} width={700} height={250}></canvas> <h3>Extracted text</h3> <div className="pin-box"> <p> {text} </p> </div> <input type="file" onChange={handleChange} /> <button onClick={handleClick} style={{height:50}}>Convert to text</button> </main> </div> ); } export default AppPrimeiro, temos que importar “preprocessImage” de “preprocess.js” com o código abaixo:
import preprocessImage from './preprocess'; Em seguida, adicionamos uma tag canvas ao formulário. Definimos o atributo ref das tags canvas e img para { canvasRef } e { imageRef } respectivamente. As refs são usadas para acessar a tela e a imagem do componente App. Pegamos tanto a tela quanto a imagem com “useRef” como em:
const canvasRef = useRef(null); const imageRef = useRef(null);Nesta parte do código, mesclamos a imagem com a tela, pois só podemos pré-processar uma tela em JavaScript. Em seguida, convertemos em um URL de dados com “jpeg” como formato de imagem.
const canvas = canvasRef.current; const ctx = canvas.getContext('2d'); ctx.drawImage(imageRef.current, 0, 0); ctx.putImageData(preprocessImage(canvas),0,0); const dataUrl = canvas.toDataURL("image/jpeg");“dataUrl” é passado para o Tesseract como a imagem a ser processada.
Agora, vamos verificar se o texto extraído será mais preciso.
Teste nº 2

A imagem acima mostra o resultado no Firefox. É óbvio que a parte escura da imagem foi alterada para branca, mas o pré-processamento da imagem não leva a um resultado mais preciso. É ainda pior.
A primeira conversão tem apenas dois caracteres incorretos, mas esta tem quatro caracteres incorretos. Eu até tentei alterar o nível de limite, mas sem sucesso. Não obtemos um resultado melhor não porque a binarização seja ruim, mas porque a binarização da imagem não corrige a natureza da imagem de uma maneira adequada para o mecanismo do Tesseract.
Vamos verificar como também é no Chrome:

Obtemos o mesmo resultado.
Após obter um resultado pior ao binarizar a imagem, há a necessidade de verificar outras técnicas de pré-processamento de imagem para ver se conseguimos resolver o problema ou não. Então, vamos tentar dilatação, inversão e desfoque em seguida.
Vamos apenas obter o código para cada uma das técnicas do P5.js, conforme usado neste artigo. Adicionaremos as técnicas de processamento de imagem ao preprocess.js e as usaremos uma a uma. É necessário entender cada uma das técnicas de pré-processamento de imagem que queremos usar antes de usá-las, então vamos discuti-las primeiro.
O que é dilatação?
A dilatação é adicionar pixels aos limites dos objetos em uma imagem para torná-la mais ampla, maior ou mais aberta. A técnica “dilatar” é usada para pré-processar nossas imagens para aumentar o brilho dos objetos nas imagens. Precisamos de uma função para dilatar imagens usando JavaScript, então o snippet de código para dilatar uma imagem é adicionado ao preprocess.js.
O que é desfoque?
O desfoque é a suavização das cores de uma imagem, reduzindo sua nitidez. Às vezes, as imagens têm pequenos pontos/manchas. Para remover esses patches, podemos desfocar as imagens. O snippet de código para desfocar uma imagem está incluído em preprocess.js.
O que é inversão?
A inversão está mudando as áreas claras de uma imagem para uma cor escura e as áreas escuras para uma cor clara. Por exemplo, se uma imagem tiver um fundo preto e um primeiro plano branco, podemos invertê-la para que seu plano de fundo seja branco e seu primeiro plano seja preto. Também adicionamos o snippet de código para inverter uma imagem para preprocess.js.
Depois de adicionar dilate , invertColors e blurARGB ao “preprocess.js”, agora podemos usá-los para pré-processar imagens. Para usá-los, precisamos atualizar a função inicial “preprocessImage” em preprocess.js:
preprocessImage(...) agora se parece com isso:
function preprocessImage(canvas) { const level = 0.4; const radius = 1; const ctx = canvas.getContext('2d'); const image = ctx.getImageData(0,0,canvas.width, canvas.height); blurARGB(image.data, canvas, radius); dilate(image.data, canvas); invertColors(image.data); thresholdFilter(image.data, level); return image; } Em preprocessImage acima, aplicamos quatro técnicas de pré-processamento a uma imagem: blurARGB() para remover os pontos na imagem, dilate() para aumentar o brilho da imagem, invertColors() para alternar a cor de primeiro e segundo plano da imagem e thresholdFilter() para converter a imagem em preto e branco, o que é mais adequado para a conversão do Tesseract.
O thresholdFilter() recebe image.data e level como seus parâmetros. level é usado para definir quão branca ou preta a imagem deve ser. Determinamos o nível thresholdFilter e o raio blurRGB por tentativa e erro, pois não temos certeza de quão branca, escura ou suave a imagem deve ser para que o Tesseract produza um ótimo resultado.
Teste nº 3
Aqui está o novo resultado após a aplicação de quatro técnicas:

A imagem acima representa o resultado que obtemos no Chrome e no Firefox.
Ops! O resultado é terrível.
Em vez de usar todas as quatro técnicas, por que não usamos apenas duas de cada vez?
Isso! Podemos simplesmente usar as técnicas invertColors e thresholdFilter para converter a imagem em preto e branco e alternar o primeiro plano e o plano de fundo da imagem. Mas como sabemos o que e quais técnicas combinar? Sabemos o que combinar com base na natureza da imagem que queremos pré-processar.
Por exemplo, uma imagem digital precisa ser convertida em preto e branco e uma imagem com manchas precisa ser desfocada para remover os pontos/manchas. O que importa mesmo é entender para que serve cada uma das técnicas.
Para usar invertColors e thresholdFilter , precisamos comentar blurARGB e dilate em preprocessImage :
function preprocessImage(canvas) { const ctx = canvas.getContext('2d'); const image = ctx.getImageData(0,0,canvas.width, canvas.height); // blurARGB(image.data, canvas, 1); // dilate(image.data, canvas); invertColors(image.data); thresholdFilter(image.data, 0.5); return image; }Teste #4
Agora, aqui está o novo resultado:

O resultado ainda é pior do que aquele sem nenhum pré-processamento. Após ajustar cada uma das técnicas para esta imagem em particular e algumas outras imagens, cheguei à conclusão de que imagens de natureza diferente requerem técnicas de pré-processamento diferentes.
Resumindo, usar Tesseract.js sem pré-processamento de imagem produziu o melhor resultado para o cartão-presente acima. Todos os outros experimentos com pré-processamento de imagem produziram resultados menos precisos.
Questão
Inicialmente, eu queria extrair o PIN de qualquer cartão-presente da Amazon, mas não consegui porque não faz sentido corresponder um PIN inconsistente para obter um resultado consistente. Embora seja possível processar uma imagem para obter um PIN preciso, esse pré-processamento será inconsistente no momento em que outra imagem de natureza diferente for usada.
O melhor resultado produzido
A imagem abaixo mostra o melhor resultado produzido pelos experimentos.
Teste nº 5

Os textos da imagem e os extraídos são totalmente os mesmos. A conversão tem 100% de precisão. Tentei reproduzir o resultado mas só consegui reproduzi-lo ao utilizar imagens de natureza semelhante.
Observação e lições
- Algumas imagens que não são pré-processadas podem apresentar resultados diferentes em diferentes navegadores . Esta afirmação é evidente no primeiro teste. O resultado no Firefox é diferente do Chrome. No entanto, o pré-processamento de imagens ajuda a obter um resultado consistente em outros testes.
- A cor preta em um fundo branco tende a dar resultados gerenciáveis. A imagem abaixo é um exemplo de um resultado preciso sem nenhum pré-processamento . Também consegui obter o mesmo nível de precisão pré-processando a imagem, mas precisei de muitos ajustes desnecessários.
A conversão é 100% precisa.
- Um texto com um tamanho de fonte grande tende a ser mais preciso.
- Fontes com bordas curvas tendem a confundir o Tesseract. O melhor resultado que obtive foi alcançado quando usei Arial (fonte).
- Atualmente, o OCR não é bom o suficiente para automatizar a conversão de imagem para texto, especialmente quando é necessário um nível de precisão superior a 80%. No entanto, ele pode ser usado para tornar o processamento manual de textos em imagens menos estressante , extraindo textos para correção manual.
- Atualmente, o OCR não é bom o suficiente para passar informações úteis aos leitores de tela para acessibilidade . Fornecer informações imprecisas a um leitor de tela pode facilmente enganar ou distrair os usuários.
- OCR é muito promissor, pois as redes neurais possibilitam aprender e melhorar. O aprendizado profundo fará do OCR um divisor de águas em um futuro próximo .
- Tomar decisões com confiança. Uma pontuação de confiança pode ser usada para tomar decisões que podem afetar muito nossos aplicativos. A pontuação de confiança pode ser usada para determinar se um resultado deve ser aceito ou rejeitado. Da minha experiência e experimento, percebi que qualquer pontuação de confiança abaixo de 90 não é realmente útil. Se eu precisar apenas extrair alguns pinos de um texto, esperarei uma pontuação de confiança entre 75 e 100, e qualquer coisa abaixo de 75 será rejeitada .
Caso eu esteja lidando com textos sem a necessidade de extrair qualquer parte dele, definitivamente aceitarei uma pontuação de confiança entre 90 e 100, mas rejeito qualquer pontuação abaixo disso. Por exemplo, uma precisão de 90 e acima será esperada se eu quiser digitalizar documentos como cheques, um rascunho histórico ou sempre que uma cópia exata for necessária. Mas uma pontuação entre 75 e 90 é aceitável quando uma cópia exata não é importante, como obter o PIN de um cartão-presente. Em suma, uma pontuação de confiança ajuda na tomada de decisões que afetam nossos aplicativos.
Conclusão
Dada a limitação de processamento de dados causada por textos em imagens e as desvantagens associadas a isso, o Reconhecimento Óptico de Caracteres (OCR) é uma tecnologia útil a ser adotada. Embora o OCR tenha suas limitações, é muito promissor devido ao uso de redes neurais.
Com o tempo, o OCR superará a maioria de suas limitações com a ajuda do aprendizado profundo, mas antes disso, as abordagens destacadas neste artigo podem ser utilizadas para lidar com a extração de texto de imagens, pelo menos, para reduzir as dificuldades e perdas associadas ao manual. processamento — especialmente do ponto de vista comercial.
Agora é sua vez de experimentar o OCR para extrair textos de imagens. Boa sorte!
Leitura adicional
- P5.js
- Pré-processamento em OCR
- Melhorando a qualidade da saída
- Usando JavaScript para pré-processar imagens para OCR
- OCR no navegador com Tesseract.js
- Uma rápida história do reconhecimento óptico de caracteres
- O futuro do OCR é Deep Learning
- Linha do tempo do reconhecimento óptico de caracteres