
Classificação de imagens na CNN: tudo o que você precisa saber
Publicados: 2021-02-25Índice
Introdução
Ao passar pelo feed do Facebook, você já se perguntou como as pessoas em uma foto de grupo são rotuladas automaticamente pelo software do Facebook? Por trás de cada interface de usuário interativa do Facebook que você vê, há um algoritmo complexo e forte que é usado para reconhecer e rotular cada imagem que é enviada por nós para a plataforma de mídia social. Com cada foto nossa, apenas ajudamos a melhorar a eficiência do algoritmo. Sim, a Classificação de Imagens é um dos algoritmos mais utilizados onde vemos a aplicação da Inteligência Artificial.
Nos últimos tempos, as Redes Neurais Convolucionais (CNN) se tornaram um dos mais fortes defensores do Deep Learning. Uma aplicação popular dessas Redes Convolucionais é a Classificação de Imagens. Neste tutorial, veremos o básico das Redes Neurais Convolucionais, veremos as várias camadas envolvidas na construção de um modelo CNN e, finalmente, visualizaremos um exemplo da tarefa de Classificação de Imagens.
Classificação de imagem
Antes de entrarmos nos detalhes de Deep Learning e Redes Neurais Convolucionais, vamos entender o básico da Classificação de Imagens. Em geral, a Classificação de Imagens é definida como a tarefa em que damos uma imagem como entrada para um modelo construído usando um algoritmo específico que gera a classe ou a probabilidade da classe à qual a imagem pertence. Esse processo no qual rotulamos uma imagem para uma determinada classe é chamado de Aprendizagem Supervisionada.
Há uma enorme diferença entre como vemos uma imagem e como a máquina (computador) vê a mesma imagem. Para nós, somos capazes de visualizar a imagem e caracterizá-la com base na cor e no tamanho. Por outro lado, para a máquina, tudo o que ela consegue ver são números. Os números que são vistos são chamados de pixels.
Cada pixel tem um valor entre 0 e 255. Assim, com esses dados numéricos, a máquina requer algumas etapas de pré-processamento para derivar alguns padrões ou características específicas que distinguem uma imagem da outra. As Redes Neurais Convolucionais nos ajudam a construir algoritmos capazes de derivar o padrão específico de imagens.
O que vemos versus o que o computador vê
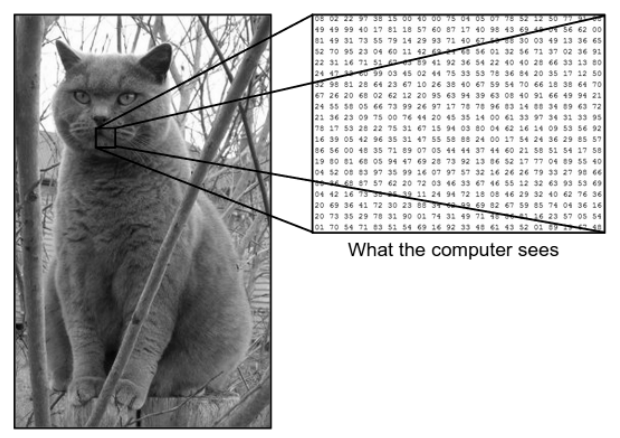 Fonte - Diferença entre Computador e Olho Humano
Fonte - Diferença entre Computador e Olho Humano

Aprendizado profundo para classificação de imagens
Agora que já entendemos o que é Classificação de Imagens, vamos agora ver como podemos implementá-la usando Inteligência Artificial. Para isso, usamos os métodos populares de Deep Learning. Deep Learning é um subconjunto de Inteligência Artificial que faz uso de grandes conjuntos de dados de imagem para reconhecer e derivar padrões de várias imagens para diferenciar entre várias classes presentes no conjunto de dados de imagem.
O grande desafio que o Deep Learning enfrenta é que, para um banco de dados enorme, leva muito tempo e tem um alto custo computacional. No entanto, as Redes Neurais Convolucionais, que é um tipo de algoritmo de Deep Learning, aborda bem esse problema.
Redes Neurais Convolucionais
No Deep Learning, as Redes Neurais Convolucionais são uma classe de Redes Neurais Profundas que são usadas principalmente em imagens visuais. Eles são uma arquitetura especial das Redes Neurais Artificiais (RNA) que foi proposta em 1998 por Yann LeCunn. As Redes Neurais Convolucionais consistem em duas partes.
A primeira parte consiste nas camadas Convolutional e nas camadas Pooling nas quais ocorre o processo principal de extração de recursos. Na segunda parte, as camadas Totalmente Conectada e Densa realizam várias transformações não lineares nas feições extraídas e atuam como a parte classificadora. Aprenda CNN para classificação de imagens.
Considere o exemplo de imagem mostrado acima do que o humano e a máquina veem. Como vemos, o computador vê uma matriz de pixels. Por exemplo, se o tamanho da imagem for 500×500, o tamanho da matriz será 500x500x3. Aqui, 500 representa cada altura e largura, 3 representa o canal RGB onde cada canal de cor é representado por uma matriz separada. A intensidade do pixel varia de 0 a 255.
Agora, para Classificação de imagem, o computador procurará os recursos no nível básico. De acordo com nós, como humanos, essas características básicas do gato são suas orelhas, nariz e bigodes. Enquanto para o computador, esses recursos de nível básico são as curvaturas e os limites. Dessa forma, usando várias camadas diferentes, como as camadas Convolutional e as camadas Pooling, o computador extrai os recursos de nível básico das imagens.
No modelo de Rede Neural Convolucional, existem vários tipos de camadas como a –
- Camada de entrada
- Camada Convolucional
- Camada de pool
- Camada totalmente conectada
- Camada de saída
- Funções de ativação
Vamos passar brevemente por cada uma das camadas antes de entrarmos em sua aplicação na Classificação de Imagens.
Camada de entrada
Pelo nome, entendemos que esta é a camada na qual a imagem de entrada será alimentada no modelo CNN. Dependendo do nosso requisito, podemos remodelar a imagem para diferentes tamanhos, como (28,28,3)
Camada Convolucional
Em seguida, vem a camada mais importante que consiste em um filtro (também conhecido como kernel) com tamanho fixo. A operação matemática de Convolução é realizada entre a imagem de entrada e o filtro. Este é o estágio em que a maioria dos recursos básicos, como bordas afiadas e curvas, são extraídas da imagem e, portanto, essa camada também é conhecida como camada extratora de recursos.
Camada de pool
Após realizar a operação de convolução, realizamos a operação de Pooling. Isso também é conhecido como downsampling, onde o volume espacial da imagem é reduzido. Por exemplo, se realizarmos uma operação de Pooling com um passo de 2 em uma imagem com dimensões 28×28, então o tamanho da imagem reduzido para 14×14, fica reduzido à metade de seu tamanho original.
Camada totalmente conectada
A Camada Totalmente Conectada (FC) é colocada imediatamente antes da saída de classificação final do modelo CNN. Essas camadas são usadas para achatar os resultados antes da classificação. Envolve vários vieses, pesos e neurônios. Anexar uma camada FC antes da classificação resulta em um vetor N-dimensional onde N é um número de classes das quais o modelo deve escolher uma classe.
Camada de saída
Finalmente, a camada de saída consiste no rótulo que é codificado principalmente usando o método de codificação one-hot.
Função de ativação
Essas Funções de Ativação são o núcleo de qualquer modelo de Rede Neural Convolucional. Essas funções são usadas para determinar a saída de uma rede neural. Em suma, determina se um determinado neurônio deve ser ativado (“disparado”) ou não. Estas são geralmente funções não lineares que são executadas nos sinais de entrada. Essa saída transformada é então enviada como entrada para a próxima camada de neurônios. Existem várias funções de ativação, como o Sigmoid, ReLU, Leaky ReLU, TanH e Softmax.
Arquitetura básica da CNN
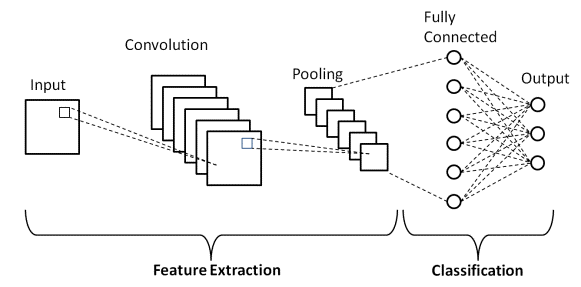
Fonte : Arquitetura básica da CNN
Conforme definido anteriormente, o diagrama mostrado acima é a arquitetura básica de um modelo de Rede Neural Convolucional. Agora que estamos prontos com o básico de Classificação de Imagens e CNN, vamos agora mergulhar em sua aplicação com um problema em tempo real. Saiba mais sobre a arquitetura básica da CNN.
Implementação de Redes Neurais Convolucionais
Agora que entendemos o básico da classificação de imagens e das redes neurais convolucionais, vamos visualizar sua implementação no TensorFlow/Keras com codificação Python. Neste, vamos construir um modelo de rede neural convolucional simples com uma arquitetura LeNet básica, treinar o modelo em um conjunto de treinamento e conjunto de teste e, finalmente, obter a precisão do modelo nos dados do conjunto de teste.
Conjunto de problemas
Neste artigo para construção e treinamento do Modelo de Rede Neural Convolucional, usaremos o famoso conjunto de dados Fashion MNIST. MNIST significa Instituto Nacional de Padrões e Tecnologia Modificado. Fashion-MNIST é um conjunto de dados de imagens de artigos de Zalando—consistindo em um conjunto de treinamento de 60.000 exemplos e um conjunto de teste de 10.000 exemplos. Cada exemplo é uma imagem em tons de cinza 28×28, associada a um rótulo de 10 classes.

Cada exemplo de treinamento e teste é atribuído a um dos seguintes rótulos:
0 – camiseta/topo
1 – Calça
2 – Pulôver
3 – Vestido
4 – Casaco
5 – Sandália
6 – Camisa
7 – Tênis
8 – Bolsa
9 – Botins
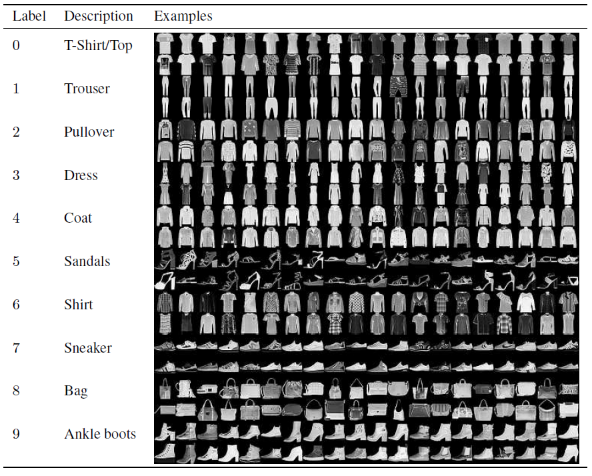
Fonte : Imagens do conjunto de dados MNIST de moda
Código do programa
Passo 1 – Importando as Bibliotecas
O primeiro passo para construir qualquer modelo de Deep Learning é importar as bibliotecas necessárias para o programa. Em nosso exemplo, como estamos usando o framework TensorFlow, importaremos a biblioteca Keras e também outras bibliotecas importantes, como o número para cálculo e o matplotlib para plotagem dos gráficos.
#TensorFlow – Importando as bibliotecas
importar numpy como np
importar matplotlib.pyplot como plt
%matplotlib em linha
importe tensorflow como tf
do tensorflow import Keras
Etapa 2 – Obtendo e dividindo o conjunto de dados
Depois de importar as bibliotecas, a próxima etapa é baixar o conjunto de dados e dividir o conjunto de dados Fashion MNIST nos respectivos 60.000 dados de treinamento e 10.000 dados de teste. Felizmente, keras nos fornece uma função predefinida para importar o conjunto de dados Fashion MNIST e podemos dividi-los na próxima linha usando uma linha de código simples que é auto-compreendida.
#TensorFlow – Obtendo e dividindo o conjunto de dados
fashion_mnist = keras.datasets.fashion_mnist
(train_images_tf, train_labels_tf), (test_images_tf, test_labels_tf) = fashion_mnist.load_data()
Passo 3 – Visualizando os Dados
Como o conjunto de dados é baixado junto com as imagens e seus respectivos rótulos, para deixar mais claro para o usuário, é sempre aconselhável visualizar os dados para que possamos entender o tipo de dados com os quais estamos lidando para construir o Neural Convolucional Modelo de rede em conformidade. Aqui, com este simples bloco de código dado abaixo, vamos visualizar as 3 primeiras imagens do conjunto de dados de treinamento que é embaralhado aleatoriamente.
#TensorFlow – Visualizando os dados
def imshowTensorFlow(img):
plt.imshow(img, cmap='cinza')
print(“Etiqueta:”, img[0])
imshowTensorFlow(train_images_tf[0])
Etiqueta: 9 Etiqueta: 0 Etiqueta: 3


A imagem fornecida acima e seus rótulos podem ser verificados com os rótulos fornecidos nos detalhes do conjunto de dados Fashion MNIST acima. A partir disso, inferimos que nossa imagem de dados é uma imagem em tons de cinza com altura de 28 pixels e largura de 28 pixels.
Assim, o modelo pode ser construído com um tamanho de entrada de (28,28,1), onde 1 representa a imagem em tons de cinza.
Passo 4 – Construindo o Modelo
Como mencionado acima, neste artigo estaremos construindo uma Rede Neural Convolucional simples com a arquitetura LeNet. LeNet é uma estrutura de rede neural convolucional proposta por Yann LeCun et al. em 1989. Em geral, LeNet refere-se a LeNet-5 e é uma rede neural convolucional simples.
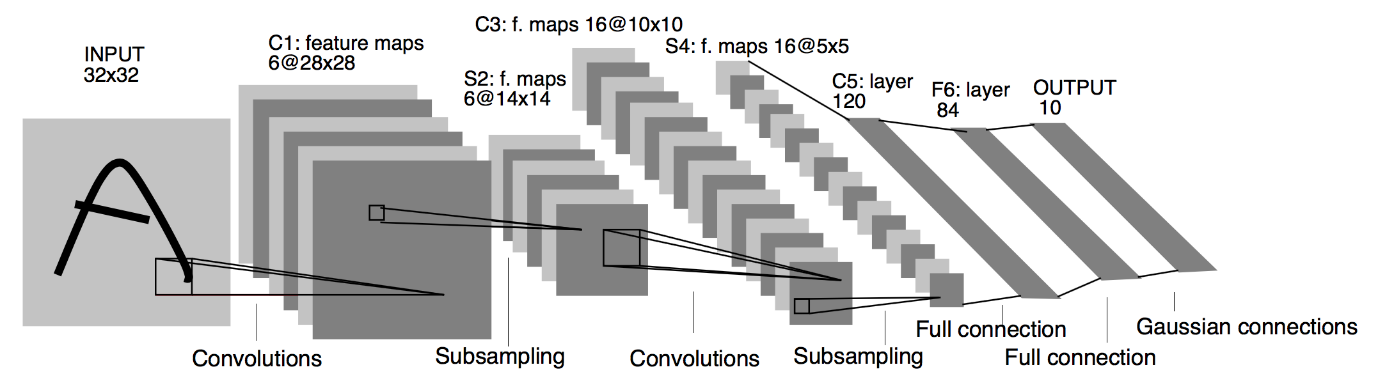
Fonte : A Arquitetura LeNet
A partir do diagrama de arquitetura dado acima do modelo LeNet CNN, vemos que existem 5+2 camadas. A primeira e a segunda camadas são uma camada Convolucional seguida por uma camada de Pooling. Novamente, a terceira e a quarta camadas consistem em uma camada convolucional e uma camada de pooling. Como resultado dessas operações, o tamanho da imagem de entrada de 28×28 é reduzido para 7×7.
A quinta camada do Modelo LeNet é a Camada Totalmente Conectada que nivela a saída da camada anterior. Seguida por duas camadas Dense, a camada de saída final do modelo CNN consiste em uma função de ativação Softmax com 10 unidades. A função Softmax prevê uma probabilidade de classe para cada uma das 10 classes do conjunto de dados Fashion MNIST.
#TensorFlow – Construindo o modelo
modelo = keras.Sequencial([
keras.layers.Conv2D(input_shape=(28,28,1), filter=6, kernel_size=5, strides=1, padding=”mesmo”, ativação=tf.nn.relu),
keras.layers.AveragePooling2D(pool_size=2, strides=2),
keras.layers.Conv2D(16, kernel_size=5, strides=1, padding=”mesmo”, ativação=tf.nn.relu),
keras.layers.AveragePooling2D(pool_size=2, strides=2),
keras.layers.Flatten(),
keras.layers.Dense(120, ativação=tf.nn.relu),
keras.layers.Dense(84, ativação=tf.nn.relu),
keras.layers.Dense(10, ativação=tf.nn.softmax)
])
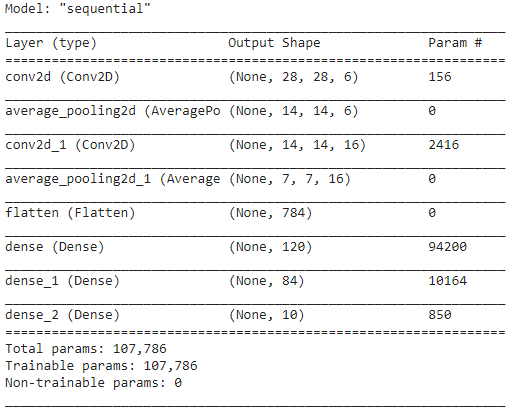
Etapa 5 - Resumo do modelo
Uma vez finalizadas as camadas do modelo LeNet, podemos proceder à compilação do modelo e visualizar uma versão resumida do modelo CNN projetado.
#TensorFlow – Resumo do modelo
model.compile(loss=keras.losses.categorical_crossentropy,
otimizador='adam',
métricas=['acc'])
model.summary()
Neste, como a saída final possui mais de 2 classes (10 classes), utilizamos a entropia categórica como função de perda e o Adam Optimizer para nosso modelo construído. O resumo do modelo é apresentado a seguir.
Passo 6 – Treinando o Modelo
Por fim, chegamos à parte em que iniciamos o processo de treinamento do modelo LeNet CNN. Em primeiro lugar, remodelamos o conjunto de dados de treinamento e o normalizamos para valores menores dividindo por 255,0 para reduzir o custo computacional. Em seguida, os rótulos de treinamento são convertidos de um vetor de classe inteiro para uma matriz de classe binária. Por exemplo, o rótulo 3 é convertido em [0, 0, 0, 1, 0, 0, 0, 0, 0]
#TensorFlow – Treinando o modelo
train_images_tensorflow = (train_images_tf / 255.0).reshape(train_images_tf.shape[0], 28, 28, 1)
test_images_tensorflow = (test_images_tf / 255.0).reshape(test_images_tf.shape[0], 28, 28 ,1)
train_labels_tensorflow=keras.utils.to_categorical(train_labels_tf)
test_labels_tensorflow=keras.utils.to_categorical(test_labels_tf)
H = model.fit(train_images_tensorflow, train_labels_tensorflow, epochs=30, batch_size=32)
Ao final do treinamento após 30 épocas, obtemos a precisão e perda final do treinamento como,
Época 30/30
1875/1875 [==============================] – 4s 2ms/passo – perda: 0,0421 – acc: 0,9850
Precisão do treinamento: 98.294997215271%
Perda de treinamento: 0,04584110900759697
Passo 7 – Prevendo os Resultados
Finalmente, uma vez que terminamos nosso processo de treinamento do modelo CNN, devemos ajustar o mesmo modelo no conjunto de dados de teste e prever a precisão de 10.000 imagens de teste.
#TensorFlow – Comparando os resultados
previsões = model.predict(test_images_tensorflow)
correto = 0
for i, pred in enumerate(predictions):
if np.argmax(pred) == test_labels_tf[i]:
correto += 1
print('Teste a precisão do modelo nas {} imagens de teste: {}% com TensorFlow'.format(test_images_tf.shape[0],100 * correct/test_images_tf.shape[0])))
A saída que obtemos é,
Teste de precisão do modelo nas 10.000 imagens de teste: 90,67% com TensorFlow
Com isso, encerramos o programa de construção de um Modelo de Classificação de Imagens com Redes Neurais Convolucionais.
Leia também: Ideias de projetos de aprendizado de máquina
Conclusão
Assim, neste tutorial sobre a implementação da Classificação de Imagens na CNN, entendemos os conceitos básicos por trás da Classificação de Imagens, Redes Neurais Convolucionais e sua implementação na linguagem de programação Python com o framework TensorFlow.
Se você estiver interessado em aprender mais sobre aprendizado de máquina, confira o PG Diploma in Machine Learning & AI do IIIT-B e upGrad, projetado para profissionais que trabalham e oferece mais de 450 horas de treinamento rigoroso, mais de 30 estudos de caso e atribuições, IIIT- B Status de ex-aluno, mais de 5 projetos práticos práticos e assistência de trabalho com as principais empresas.
Qual modelo CNN é considerado o melhor para classificação de imagens?
O melhor modelo CNN para classificação de imagens é o VGG-16, que significa Very Deep Convolutional Networks for Large-Scale Image Recognition. O VGG, que foi projetado como uma CNN profunda, supera as linhas de base em uma ampla variedade de tarefas e conjuntos de dados fora do ImageNet. A característica distintiva do modelo é que, quando foi criado, foi dada mais atenção à incorporação de excelentes camadas de convolução, em vez de focar na adição de um grande número de hiperparâmetros. Tem um total de 16 camadas, 5 blocos, e cada bloco tem uma camada máxima de pooling, tornando-se uma rede bastante grande.
Quais são as desvantagens de usar modelos CNN para classificação de imagens?
Quando se trata de classificação de imagens, os modelos CNN são altamente bem-sucedidos. No entanto, existem várias desvantagens em empregar CNNs. Se a imagem a ser identificada estiver inclinada ou girada, o modelo CNN tem problemas para identificar com precisão a imagem. Quando a CNN visualiza as imagens, não há representações internas dos componentes e suas conexões parte-todo. Além disso, se o modelo CNN a ser empregado incluir várias camadas convolucionais, o processo de classificação levará muito tempo.
Por que o uso do modelo CNN é preferido em relação ao ANN para dados de imagem como entrada?
Ao combinar filtros ou transformações, a CNN pode aprender muitas camadas de representações de recursos para cada imagem fornecida como entrada. O overfitting é reduzido, pois o número de parâmetros para a rede aprender na CNN é substancialmente menor do que nas redes neurais multicamadas. Ao usar ANN, as redes neurais podem aprender uma única representação de recurso da imagem, mas, no caso de imagens complexas, a ANN não fornecerá visualizações ou classificações aprimoradas, pois não pode aprender as dependências de pixels existentes nas imagens de entrada.