
HTTP/3: melhorias de desempenho (parte 2)
Publicados: 2022-03-10Bem-vindo de volta a esta série sobre o novo protocolo HTTP/3. Na parte 1, analisamos por que exatamente precisamos do HTTP/3 e do protocolo QUIC subjacente e quais são seus principais novos recursos.
Nesta segunda parte, vamos ampliar as melhorias de desempenho que QUIC e HTTP/3 trazem para a mesa para carregamento de páginas da web. No entanto, também seremos um pouco céticos em relação ao impacto que podemos esperar desses novos recursos na prática.
Como veremos, o QUIC e o HTTP/3 realmente têm um grande potencial de desempenho na web, mas principalmente para usuários em redes lentas . Se o visitante médio estiver em uma rede cabeada ou celular rápida, provavelmente não se beneficiará tanto dos novos protocolos. No entanto, observe que, mesmo em países e regiões com uplinks normalmente rápidos, os mais lentos de 1% a 10% do seu público (os chamados percentis 99 ou 90 ) ainda podem ganhar muito. Isso ocorre porque o HTTP/3 e o QUIC ajudam principalmente a lidar com os problemas um tanto incomuns, mas potencialmente de alto impacto, que podem surgir na Internet de hoje.
Esta parte é um pouco mais técnica do que a primeira, embora descarregue a maioria das coisas realmente profundas para fontes externas, concentrando-se em explicar por que essas coisas são importantes para o desenvolvedor web comum.
- Parte 1: Histórico e conceitos básicos do HTTP/3
Este artigo é destinado a pessoas novas em HTTP/3 e protocolos em geral, e discute principalmente o básico. - Parte 2: Recursos de desempenho HTTP/3
Este é mais profundo e técnico. As pessoas que já conhecem o básico podem começar por aqui. - Parte 3: Opções práticas de implantação HTTP/3
Este terceiro artigo da série explica os desafios envolvidos na implantação e teste do HTTP/3 por conta própria. Ele detalha como e se você também deve alterar suas páginas e recursos da Web.
Uma cartilha sobre velocidade
Discutir desempenho e “velocidade” pode se tornar rapidamente complexo, porque muitos aspectos subjacentes contribuem para que uma página da Web seja carregada “lentamente”. Como estamos lidando com protocolos de rede aqui, examinaremos principalmente os aspectos de rede, dos quais dois são os mais importantes: latência e largura de banda.
A latência pode ser definida aproximadamente como o tempo que leva para enviar um pacote do ponto A (digamos, o cliente) para o ponto B (o servidor) . Ele é fisicamente limitado pela velocidade da luz ou, praticamente, pela rapidez com que os sinais podem viajar em fios ou ao ar livre. Isso significa que a latência geralmente depende da distância física do mundo real entre A e B.
Na Terra, isso significa que as latências típicas são conceitualmente pequenas, entre aproximadamente 10 e 200 milissegundos. No entanto, esta é apenas uma maneira: as respostas aos pacotes também precisam retornar. A latência bidirecional é frequentemente chamada de tempo de ida e volta (RTT) .
Devido a recursos como controle de congestionamento (veja abaixo), muitas vezes precisaremos de algumas viagens de ida e volta para carregar até mesmo um único arquivo. Como tal, mesmo baixas latências de menos de 50 milissegundos podem resultar em atrasos consideráveis. Esta é uma das principais razões pelas quais as redes de entrega de conteúdo (CDNs) existem: elas colocam os servidores fisicamente mais próximos do usuário final para reduzir a latência e, portanto, o atraso, tanto quanto possível.
A largura de banda, então, pode ser considerada aproximadamente o número de pacotes que podem ser enviados ao mesmo tempo . Isso é um pouco mais difícil de explicar, pois depende das propriedades físicas do meio (por exemplo, a frequência de ondas de rádio utilizada), do número de usuários na rede e também dos dispositivos que interligam diferentes sub-redes (porque eles normalmente só pode processar um certo número de pacotes por segundo).
Uma metáfora muito usada é a de um cano usado para transportar água. O comprimento do tubo é a latência, enquanto a largura do tubo é a largura de banda. Na Internet, no entanto, normalmente temos uma longa série de tubos conectados , alguns dos quais podem ser mais largos do que outros (levando aos chamados gargalos nos links mais estreitos). Como tal, a largura de banda de ponta a ponta entre os pontos A e B é frequentemente limitada pelas subseções mais lentas.
Embora uma compreensão perfeita desses conceitos não seja necessária para o restante deste post, seria bom ter uma definição comum de alto nível. Para obter mais informações, recomendo verificar o excelente capítulo de Ilya Grigorik sobre latência e largura de banda em seu livro High Performance Browser Networking .
Controle de congestão
Um aspecto do desempenho é sobre a eficiência com que um protocolo de transporte pode usar toda a largura de banda (física) de uma rede (ou seja, quantos pacotes por segundo podem ser enviados ou recebidos). Isso, por sua vez, afeta a rapidez com que os recursos de uma página podem ser baixados. Alguns afirmam que o QUIC de alguma forma faz isso muito melhor que o TCP, mas isso não é verdade.
Você sabia?
Uma conexão TCP, por exemplo, não inicia apenas o envio de dados com largura de banda total, pois isso pode acabar sobrecarregando (ou congestionando) a rede. Isso ocorre porque, como dissemos, cada link de rede possui apenas uma certa quantidade de dados que pode processar (fisicamente) a cada segundo. Dê mais e não há outra opção a não ser descartar os pacotes excessivos, levando à perda de pacotes .
Conforme discutido na parte 1, para um protocolo confiável como o TCP, a única maneira de se recuperar da perda de pacotes é retransmitir uma nova cópia dos dados, o que leva uma viagem de ida e volta. Especialmente em redes de alta latência (digamos, com um RTT de mais de 50 milissegundos), a perda de pacotes pode afetar seriamente o desempenho.
Outro problema é que não sabemos de antemão qual será a largura de banda máxima . Muitas vezes depende de um gargalo em algum lugar na conexão de ponta a ponta, mas não podemos prever ou saber onde isso será. A Internet também não possui mecanismos (ainda) para sinalizar as capacidades do link de volta aos terminais.
Além disso, mesmo que soubéssemos a largura de banda física disponível, isso não significaria que poderíamos usar tudo por conta própria. Vários usuários normalmente estão ativos em uma rede simultaneamente, cada um dos quais precisa de uma parte justa da largura de banda disponível.
Como tal, uma conexão não sabe quanta largura de banda ela pode usar com segurança ou justiça antecipadamente, e essa largura de banda pode mudar à medida que os usuários entram, saem e usam a rede. Para resolver esse problema, o TCP tentará constantemente descobrir a largura de banda disponível ao longo do tempo usando um mecanismo chamado controle de congestionamento .
No início da conexão, ele envia apenas alguns pacotes (na prática, variando entre 10 e 100 pacotes, ou cerca de 14 e 140 KB de dados) e aguarda uma viagem de ida e volta até que o receptor envie de volta os reconhecimentos desses pacotes. Se todos forem reconhecidos, isso significa que a rede pode lidar com essa taxa de envio e podemos tentar repetir o processo, mas com mais dados (na prática, a taxa de envio geralmente dobra a cada iteração).
Dessa forma, a taxa de envio continua a crescer até que alguns pacotes não sejam reconhecidos (o que indica perda de pacotes e congestionamento da rede). Esta primeira fase é normalmente chamada de “início lento”. Ao detectar a perda de pacotes, o TCP reduz a taxa de envio e (depois de um tempo) começa a aumentar a taxa de envio novamente, embora em incrementos (muito) menores. Essa lógica de redução e crescimento é repetida para cada perda de pacote posterior. Eventualmente, isso significa que o TCP tentará constantemente alcançar seu compartilhamento de largura de banda ideal e justo. Este mecanismo é ilustrado na figura 1.
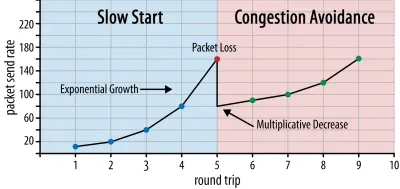
Esta é uma explicação extremamente simplificada de controle de congestionamento. Na prática, muitos outros fatores estão em jogo, como bufferbloat, a flutuação de RTTs devido ao congestionamento e o fato de que vários remetentes simultâneos precisam obter sua parte justa da largura de banda. Como tal, existem muitos algoritmos de controle de congestionamento diferentes, e muitos ainda estão sendo inventados hoje, sem que nenhum tenha desempenho ideal em todas as situações.
Embora o controle de congestionamento do TCP o torne robusto, também significa que demora um pouco para atingir as taxas de envio ideais , dependendo do RTT e da largura de banda disponível real. Para o carregamento de páginas da Web, essa abordagem de início lento também pode afetar métricas como a primeira pintura de conteúdo, porque apenas uma pequena quantidade de dados (dezenas a algumas centenas de KB) pode ser transferida nas primeiras viagens de ida e volta. (Você pode ter ouvido a recomendação de manter seus dados críticos em menos de 14 KB.)
A escolha de uma abordagem mais agressiva pode, portanto, levar a melhores resultados em redes de alta largura de banda e alta latência, especialmente se você não se importar com a perda ocasional de pacotes. É aqui que novamente vi muitas interpretações erradas sobre como o QUIC funciona.
Conforme discutido na parte 1, o QUIC, em teoria, sofre menos com a perda de pacotes (e o bloqueio de cabeçalho de linha (HOL) relacionado) porque trata a perda de pacotes no fluxo de bytes de cada recurso de forma independente. Além disso, o QUIC é executado no User Datagram Protocol (UDP), que, diferentemente do TCP, não possui um recurso de controle de congestionamento integrado; ele permite que você tente enviar em qualquer taxa que desejar e não retransmite dados perdidos.
Isso levou a muitos artigos alegando que o QUIC também não usa controle de congestionamento, que o QUIC pode começar a enviar dados a uma taxa muito mais alta sobre UDP (dependendo da remoção do bloqueio HOL para lidar com a perda de pacotes), é por isso que O QUIC é muito mais rápido que o TCP.
Na realidade, nada poderia estar mais longe da verdade: o QUIC realmente usa técnicas de gerenciamento de largura de banda muito semelhantes às do TCP . Ele também começa com uma taxa de envio mais baixa e aumenta ao longo do tempo, usando reconhecimentos como um mecanismo chave para medir a capacidade da rede. Isso ocorre (entre outras razões) porque o QUIC precisa ser confiável para ser útil para algo como HTTP, porque precisa ser justo com outras conexões QUIC (e TCP!) realmente ajudam muito bem contra a perda de pacotes (como veremos abaixo).
No entanto, isso não significa que o QUIC não possa ser (um pouco) mais inteligente sobre como gerencia a largura de banda do que o TCP. Isso ocorre principalmente porque o QUIC é mais flexível e fácil de evoluir do que o TCP . Como dissemos, os algoritmos de controle de congestionamento ainda estão evoluindo muito hoje e provavelmente precisaremos, por exemplo, ajustar as coisas para aproveitar ao máximo o 5G.
No entanto, o TCP é normalmente implementado no kernel do sistema operacional (SO), um ambiente seguro e mais restrito, que para a maioria dos SOs nem é de código aberto. Como tal, o ajuste da lógica de congestionamento geralmente é feito apenas por alguns desenvolvedores selecionados, e a evolução é lenta.
Em contraste, a maioria das implementações do QUIC está sendo feita atualmente no “espaço do usuário” (onde normalmente executamos aplicativos nativos) e é feita de código aberto, explicitamente para incentivar a experimentação por um grupo muito maior de desenvolvedores (como já mostrado, por exemplo, pelo Facebook ).
Outro exemplo concreto é a proposta de extensão da frequência de confirmação atrasada para o QUIC. Enquanto, por padrão, o QUIC envia uma confirmação para cada 2 pacotes recebidos, essa extensão permite que os terminais reconheçam, por exemplo, a cada 10 pacotes. Demonstrou-se que isso oferece grandes benefícios de velocidade em redes de satélite e de largura de banda muito alta, porque a sobrecarga de transmissão dos pacotes de confirmação é reduzida. Adicionar tal extensão para TCP levaria muito tempo para ser adotado, enquanto para QUIC é muito mais fácil de implantar.
Como tal, podemos esperar que a flexibilidade do QUIC leve a mais experimentação e melhores algoritmos de controle de congestionamento ao longo do tempo, que por sua vez também podem ser portados para TCP para melhorá-lo também.
Você sabia?
A RFC 9002 oficial do QUIC Recovery especifica o uso do algoritmo de controle de congestionamento NewReno. Embora essa abordagem seja robusta, ela também está um pouco desatualizada e não é mais usada extensivamente na prática. Então, por que está no QUIC RFC? A primeira razão é que quando o QUIC foi iniciado, o NewReno era o algoritmo de controle de congestionamento mais recente que foi padronizado. Algoritmos mais avançados, como BBR e CUBIC, ainda não são padronizados ou apenas recentemente se tornaram RFCs.
A segunda razão é que o NewReno é uma configuração relativamente simples. Como os algoritmos precisam de alguns ajustes para lidar com as diferenças do QUIC em relação ao TCP, é mais fácil explicar essas mudanças em um algoritmo mais simples. Como tal, o RFC 9002 deve ser lido mais como “como adaptar um algoritmo de controle de congestionamento ao QUIC”, em vez de “isso é o que você deve usar para o QUIC”. De fato, a maioria das implementações de QUIC em nível de produção fez implementações personalizadas de Cubic e BBR.
Vale a pena repetir que os algoritmos de controle de congestionamento não são específicos de TCP ou QUIC ; eles podem ser usados por qualquer um dos protocolos, e a esperança é que os avanços no QUIC eventualmente encontrem seu caminho para as pilhas TCP também.
Você sabia?
Observe que, próximo ao controle de congestionamento, há um conceito relacionado chamado controle de fluxo. Esses dois recursos são frequentemente confundidos no TCP, porque ambos usam a “janela TCP” , embora na verdade existam duas janelas: a janela de congestionamento e a janela de recepção do TCP. O controle de fluxo, no entanto, é muito menos importante para o caso de uso de carregamento de página da Web no qual estamos interessados, então vamos pular isso aqui. Informações mais detalhadas estão disponíveis.
O que tudo isso significa?
O QUIC ainda está sujeito às leis da física e à necessidade de ser gentil com outros remetentes na Internet. Isso significa que ele não baixará magicamente os recursos do seu site muito mais rapidamente do que o TCP. No entanto, a flexibilidade do QUIC significa que será mais fácil experimentar novos algoritmos de controle de congestionamento, o que deve melhorar as coisas no futuro para TCP e QUIC.
Configuração de conexão 0-RTT
Um segundo aspecto de desempenho é sobre quantas viagens de ida e volta são necessárias antes que você possa enviar dados HTTP úteis (digamos, recursos de página) em uma nova conexão. Alguns afirmam que o QUIC é de duas a três viagens de ida e volta mais rápido que o TCP + TLS, mas veremos que é realmente apenas um.
Você sabia?
Como dissemos na parte 1, uma conexão normalmente executa um (TCP) ou dois (TCP + TLS) handshakes antes que solicitações e respostas HTTP possam ser trocadas. Esses handshakes trocam parâmetros iniciais que o cliente e o servidor precisam saber para, por exemplo, criptografar os dados.
Como você pode ver na figura 2 abaixo, cada handshake individual leva pelo menos uma viagem de ida e volta para ser concluída (TCP + TLS 1.3, (b)) e às vezes duas (TLS 1.2 e anterior (a)). Isso é ineficiente, porque precisamos de pelo menos duas viagens de ida e volta de tempo de espera de handshake (sobrecarga) antes de podermos enviar nossa primeira solicitação HTTP, o que significa esperar pelo menos três viagens de ida e volta para que os primeiros dados de resposta HTTP (a seta vermelha de retorno) cheguem Em redes lentas, isso pode significar uma sobrecarga de 100 a 200 milissegundos.
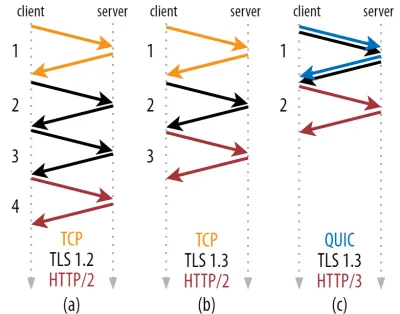
Você pode estar se perguntando por que o handshake TCP + TLS não pode ser simplesmente combinado, feito na mesma viagem de ida e volta. Embora isso seja conceitualmente possível (o QUIC faz exatamente isso), as coisas inicialmente não foram projetadas assim, porque precisamos ser capazes de usar TCP com e sem TLS no topo. Em outras palavras, o TCP simplesmente não suporta o envio de coisas não TCP durante o handshake. Houve esforços para adicionar isso com a extensão TCP Fast Open; no entanto, conforme discutido na parte 1, isso se mostrou difícil de implantar em escala.
Felizmente, o QUIC foi projetado com o TLS em mente desde o início e, como tal, combina os handshakes de transporte e criptografia em um único mecanismo. Isso significa que o handshake QUIC levará apenas uma viagem de ida e volta no total para ser concluída, que é uma viagem de ida e volta a menos que TCP + TLS 1.3 (veja a figura 2c acima).
Você pode estar confuso, porque provavelmente já leu que o QUIC é duas ou até três viagens de ida e volta mais rápida que o TCP, não apenas um. Isso porque a maioria dos artigos considera apenas o pior caso (TCP + TLS 1.2, (a)), sem contar que o TCP + TLS 1.3 moderno também “apenas” faz duas viagens de ida e volta ((b) raramente é mostrado). Embora um aumento de velocidade de uma viagem de ida e volta seja bom, dificilmente é incrível. Especialmente em redes rápidas (digamos, menos de um RTT de 50 milissegundos), isso será quase imperceptível , embora redes lentas e conexões com servidores distantes lucrem um pouco mais.
Em seguida, você pode estar se perguntando por que precisamos esperar pelo(s) aperto(s) de mão. Por que não podemos enviar uma solicitação HTTP na primeira viagem de ida e volta? Isso ocorre principalmente porque, se o fizéssemos, a primeira solicitação seria enviada sem criptografia , legível por qualquer bisbilhoteiro, o que obviamente não é ótimo para privacidade e segurança. Como tal, precisamos aguardar a conclusão do handshake criptográfico antes de enviar a primeira solicitação HTTP. Ou nós?
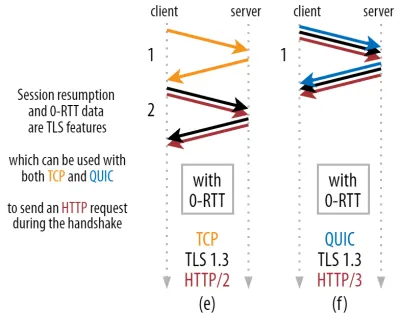
É aqui que um truque inteligente é usado na prática. Sabemos que os usuários frequentemente revisitam as páginas da web pouco tempo depois de sua primeira visita. Como tal, podemos usar a conexão criptografada inicial para inicializar uma segunda conexão no futuro. Simplificando, em algum momento durante sua vida útil, a primeira conexão é usada para comunicar com segurança novos parâmetros criptográficos entre o cliente e o servidor. Esses parâmetros podem ser usados para criptografar a segunda conexão desde o início, sem ter que aguardar a conclusão do handshake TLS completo. Essa abordagem é chamada de “retomada de sessão” .
Ele permite uma otimização poderosa: agora podemos enviar com segurança nossa primeira solicitação HTTP junto com o handshake QUIC/TLS, economizando outra viagem de ida e volta ! Quanto ao TLS 1.3, isso remove efetivamente o tempo de espera do handshake TLS. Esse método geralmente é chamado de 0-RTT (embora, é claro, ainda leve uma viagem de ida e volta para os dados de resposta HTTP começarem a chegar).
Tanto a retomada da sessão quanto o 0-RTT são, novamente, coisas que muitas vezes vi erroneamente explicadas como sendo recursos específicos do QUIC. Na realidade, esses são recursos do TLS que já estavam presentes de alguma forma no TLS 1.2 e agora estão totalmente desenvolvidos no TLS 1.3.
Em outras palavras, como você pode ver na figura 3 abaixo, podemos obter os benefícios de desempenho desses recursos sobre TCP (e, portanto, também HTTP/2 e até HTTP/1.1) também! Vemos que, mesmo com 0-RTT, o QUIC ainda é apenas uma viagem de ida e volta mais rápido do que uma pilha TCP + TLS 1.3 funcionando de maneira ideal. A afirmação de que o QUIC é três viagens de ida e volta mais rápido vem da comparação da figura 2 (a) com a figura 3 (f), o que, como vimos, não é realmente justo.
A pior parte é que, ao usar 0-RTT, o QUIC não pode nem mesmo usar esse ganho de ida e volta tão bem devido à segurança. Para entender isso, precisamos entender uma das razões pelas quais o handshake TCP existe. Primeiro, ele permite que o cliente tenha certeza de que o servidor está realmente disponível no endereço IP fornecido antes de enviar qualquer dado de camada superior.
Em segundo lugar, e crucialmente aqui, ele permite que o servidor certifique-se de que o cliente que está abrindo a conexão é realmente quem e onde ele diz estar antes de enviar os dados. Se você se lembrar de como definimos uma conexão com a tupla de 4 na parte 1, você saberá que o cliente é identificado principalmente por seu endereço IP. E este é o problema: endereços IP podem ser falsificados !
Suponha que um invasor solicite um arquivo muito grande via HTTP sobre QUIC 0-RTT. No entanto, eles falsificam seu endereço IP, fazendo parecer que a solicitação 0-RTT veio do computador da vítima. Isso é mostrado na figura 4 abaixo. O servidor QUIC não tem como detectar se o IP foi falsificado, porque este é o primeiro pacote (s) que está vendo desse cliente.

Se o servidor simplesmente começar a enviar o arquivo grande de volta para o IP falsificado, ele pode acabar sobrecarregando a largura de banda da rede da vítima (especialmente se o invasor fizer muitas dessas solicitações falsas em paralelo). Observe que a resposta do QUIC seria descartada pela vítima, porque ela não espera dados de entrada, mas isso não importa: sua rede ainda precisa processar os pacotes!
Isso é chamado de ataque de reflexão, ou amplificação, e é uma maneira significativa de os hackers executarem ataques de negação de serviço distribuído (DDoS). Observe que isso não acontece quando 0-RTT sobre TCP + TLS está sendo usado, precisamente porque o handshake TCP precisa ser concluído primeiro antes que a solicitação 0-RTT seja enviada junto com o handshake TLS.
Como tal, o QUIC deve ser conservador na resposta a solicitações 0-RTT, limitando a quantidade de dados que envia em resposta até que o cliente seja verificado como um cliente real e não uma vítima. Para o QUIC, essa quantidade de dados foi definida como três vezes a quantidade recebida do cliente.
Em outras palavras, o QUIC tem um “fator de amplificação” máximo de três, que foi determinado como uma compensação aceitável entre utilidade de desempenho e risco de segurança (especialmente em comparação com alguns incidentes que tiveram um fator de amplificação de mais de 51.000 vezes). Como o cliente normalmente envia primeiro apenas um ou dois pacotes, a resposta 0-RTT do servidor QUIC será limitada a apenas 4 a 6 KB (incluindo outras sobrecargas de QUIC e TLS!), o que é um pouco menos que impressionante.
Além disso, outros problemas de segurança podem levar a, por exemplo, “ataques de repetição”, que limitam o tipo de solicitação HTTP que você pode fazer. Por exemplo, a Cloudflare só permite solicitações HTTP GET sem parâmetros de consulta em 0-RTT. Isso limita ainda mais a utilidade do 0-RTT.
Felizmente, o QUIC tem opções para tornar isso um pouco melhor. Por exemplo, o servidor pode verificar se o 0-RTT vem de um IP com o qual teve uma conexão válida antes. No entanto, isso só funciona se o cliente permanecer na mesma rede (limitando um pouco o recurso de migração de conexão do QUIC). E mesmo que funcione, a resposta do QUIC ainda é limitada pela lógica de inicialização lenta do controlador de congestionamento que discutimos acima; portanto, não há aumento de velocidade extra massivo além da viagem de ida e volta salva.
Você sabia?
É interessante notar que o limite de amplificação de três vezes do QUIC também conta para seu processo normal de handshake não-0-RTT na figura 2c. Isso pode ser um problema se, por exemplo, o certificado TLS do servidor for muito grande para caber em 4 a 6 KB. Nesse caso, ele teria que ser dividido, com o segundo pedaço tendo que esperar o envio da segunda viagem de ida e volta (depois de receber as confirmações dos primeiros pacotes, indicando que o IP do cliente não foi falsificado). Nesse caso, o handshake do QUIC ainda pode acabar levando duas viagens de ida e volta , igual a TCP + TLS! É por isso que, para o QUIC, técnicas como compactação de certificados serão extremamente importantes.
Você sabia?
Pode ser que certas configurações avançadas sejam capazes de mitigar esses problemas o suficiente para tornar o 0-RTT mais útil. Por exemplo, o servidor pode lembrar quanta largura de banda um cliente tinha disponível na última vez que foi visto, tornando-o menos limitado pelo início lento do controle de congestionamento para reconectar clientes (não falsificados). Isso tem sido investigado na academia, e existe até uma proposta de extensão no QUIC para fazer isso. Várias empresas já fazem esse tipo de coisa para acelerar o TCP também.
Outra opção seria fazer com que os clientes enviassem mais de um ou dois pacotes (por exemplo, enviando mais 7 pacotes com preenchimento), de modo que o limite de três vezes se traduza em uma resposta mais interessante de 12 a 14 KB, mesmo após a migração da conexão. Eu escrevi sobre isso em um dos meus trabalhos.
Por fim, os servidores QUIC (com mau comportamento) também podem aumentar intencionalmente o limite de três vezes se acharem que é seguro fazê-lo ou se não se importarem com os possíveis problemas de segurança (afinal, não há polícia de protocolo impedindo isso).
O que tudo isso significa?
A configuração de conexão mais rápida do QUIC com 0-RTT é realmente mais uma micro-otimização do que um novo recurso revolucionário. Comparado com uma configuração TCP + TLS 1.3 de última geração, economizaria no máximo uma viagem de ida e volta. A quantidade de dados que pode realmente ser enviada na primeira viagem de ida e volta também é limitada por várias considerações de segurança.
Como tal, esse recurso irá brilhar principalmente se seus usuários estiverem em redes com latência muito alta (digamos, redes de satélite com RTTs de mais de 200 milissegundos) ou se você normalmente não enviar muitos dados. Alguns exemplos deste último são sites com muito cache, bem como aplicativos de página única que buscam periodicamente pequenas atualizações por meio de APIs e outros protocolos, como DNS-over-QUIC. Uma das razões pelas quais o Google viu resultados 0-RTT muito bons para o QUIC foi que ele o testou em sua página de pesquisa já altamente otimizada, onde as respostas às consultas são bastante pequenas.
Em outros casos, você ganhará apenas algumas dezenas de milissegundos na melhor das hipóteses, ainda menos se já estiver usando um CDN (o que você deveria estar fazendo se se preocupa com o desempenho!).
Migração de conexão
Um terceiro recurso de desempenho torna o QUIC mais rápido na transferência entre redes, mantendo as conexões existentes intactas . Embora isso realmente funcione, esse tipo de mudança de rede não acontece com tanta frequência e as conexões ainda precisam redefinir suas taxas de envio.
Conforme discutido na parte 1, os IDs de conexão (CIDs) do QUIC permitem que ele execute a migração de conexão ao alternar redes . Ilustramos isso com um cliente passando de uma rede Wi-Fi para 4G ao fazer um download de arquivos grandes. No TCP, esse download pode ter que ser abortado, enquanto no QUIC ele pode continuar.
Primeiro, no entanto, considere com que frequência esse tipo de cenário realmente acontece. Você pode pensar que isso também ocorre ao se mover entre pontos de acesso Wi-Fi dentro de um prédio ou entre torres de celular enquanto estiver na estrada. Nessas configurações, no entanto (se forem feitas corretamente), seu dispositivo normalmente manterá seu IP intacto, porque a transição entre as estações base sem fio é feita em uma camada de protocolo inferior. Como tal, ocorre apenas quando você se move entre redes completamente diferentes , o que eu diria que não acontece com tanta frequência.
Em segundo lugar, podemos perguntar se isso também funciona para outros casos de uso, além de downloads de arquivos grandes e videoconferência e streaming ao vivo. Se você estiver carregando uma página da Web no momento exato de trocar de rede, talvez seja necessário solicitar novamente alguns dos recursos (posteriores).
No entanto, o carregamento de uma página geralmente leva alguns segundos, de modo que coincidir com um switch de rede também não será muito comum. Além disso, para casos de uso em que essa é uma preocupação urgente, outras mitigações normalmente já estão em vigor . Por exemplo, servidores que oferecem downloads de arquivos grandes podem oferecer suporte a solicitações de intervalo HTTP para permitir downloads retomáveis.
Como normalmente há algum tempo de sobreposição entre a queda da rede 1 e a disponibilização da rede 2, os aplicativos de vídeo podem abrir várias conexões (1 por rede), sincronizando-as antes que a rede antiga desapareça completamente. O usuário ainda notará a mudança, mas não eliminará totalmente o feed de vídeo.
Em terceiro lugar, não há garantia de que a nova rede terá tanta largura de banda disponível quanto a antiga. Assim, mesmo que a conexão conceitual seja mantida intacta, o servidor QUIC não pode continuar enviando dados em alta velocidade. Em vez disso, para evitar sobrecarregar a nova rede, ela precisa redefinir (ou pelo menos diminuir) a taxa de envio e iniciar novamente na fase de início lento do controlador de congestionamento.
Como essa taxa de envio inicial geralmente é muito baixa para realmente suportar coisas como streaming de vídeo, você verá alguma perda de qualidade ou soluços, mesmo no QUIC. De certa forma, a migração de conexão tem mais a ver com evitar a variação e a sobrecarga do contexto de conexão no servidor do que com a melhoria do desempenho.
Você sabia?
Observe que, conforme discutido para 0-RTT acima, podemos desenvolver algumas técnicas avançadas para melhorar a migração de conexão. Por exemplo, podemos, mais uma vez, tentar lembrar quanta largura de banda estava disponível em uma determinada rede da última vez e tentar aumentar mais rapidamente para esse nível para uma nova migração. Além disso, poderíamos imaginar não apenas alternar entre redes, mas usar ambas ao mesmo tempo. Esse conceito é chamado de multipath e o discutiremos com mais detalhes a seguir.
Até agora, falamos principalmente sobre migração de conexão ativa, onde os usuários se movem entre diferentes redes. Há, no entanto, também casos de migração de conexão passiva, em que uma determinada rede altera os parâmetros. Um bom exemplo disso é a religação de tradução de endereço de rede (NAT). Embora uma discussão completa sobre NAT esteja fora do escopo deste artigo, significa principalmente que os números de porta da conexão podem ser alterados a qualquer momento, sem aviso prévio. Isso também acontece com muito mais frequência para UDP do que TCP na maioria dos roteadores.
Se isso ocorrer, o QUIC CID não será alterado e a maioria das implementações assumirá que o usuário ainda está na mesma rede física e, portanto, não redefinirá a janela de congestionamento ou outros parâmetros. O QUIC também inclui alguns recursos como PINGs e indicadores de tempo limite para evitar que isso aconteça, pois isso normalmente ocorre para conexões ociosas longas.
Discutimos na parte 1 que o QUIC não usa apenas um único CID por motivos de segurança. Em vez disso, ele altera os CIDs ao realizar a migração ativa. Na prática, é ainda mais complicado, porque cliente e servidor têm listas separadas de CIDs (chamados CIDs de origem e destino no QUIC RFC). Isso é ilustrado na figura 5 abaixo.
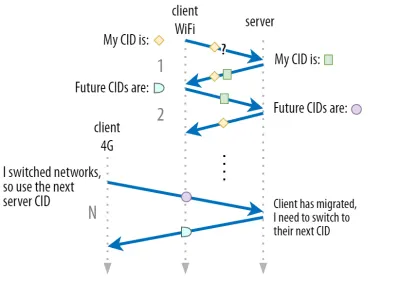
Isso é feito para permitir que cada endpoint escolha seu próprio formato e conteúdo CID , o que, por sua vez, é crucial para permitir roteamento avançado e lógica de balanceamento de carga. Com a migração de conexão, os balanceadores de carga não podem mais apenas examinar a tupla de 4 para identificar uma conexão e enviá-la ao servidor back-end correto. No entanto, se todas as conexões QUIC usarem CIDs aleatórios, isso aumentaria muito os requisitos de memória no balanceador de carga, pois seria necessário armazenar mapeamentos de CIDs para servidores back-end. Além disso, isso ainda não funcionaria com a migração de conexão, pois os CIDs mudam para novos valores aleatórios.
Como tal, é importante que os servidores de back-end QUIC implantados atrás de um balanceador de carga tenham um formato previsível de seus CIDs, para que o balanceador de carga possa derivar o servidor de back-end correto do CID, mesmo após a migração. Algumas opções para fazer isso estão descritas no documento proposto pelo IETF. Para que tudo isso seja possível, os servidores precisam poder escolher seu próprio CID, o que não seria possível se o iniciador da conexão (que, para o QUIC, é sempre o cliente) escolhesse o CID. É por isso que há uma divisão entre os CIDs do cliente e do servidor no QUIC.

O que tudo isso significa?
Assim, a migração de conexão é um recurso situacional. Testes iniciais do Google, por exemplo, mostram melhorias de baixa porcentagem para seus casos de uso. Muitas implementações do QUIC ainda não implementam esse recurso. Mesmo aqueles que o fazem normalmente o limitam a clientes e aplicativos móveis e não a seus equivalentes de desktop. Algumas pessoas até acham que o recurso não é necessário, pois abrir uma nova conexão com 0-RTT deve ter propriedades de desempenho semelhantes na maioria dos casos.
Ainda assim, dependendo do seu caso de uso ou perfil de usuário, isso pode ter um grande impacto. Se o seu site ou aplicativo é usado com mais frequência em movimento (digamos, algo como Uber ou Google Maps), você provavelmente se beneficiaria mais do que se seus usuários normalmente estivessem sentados atrás de uma mesa. Similarly, if you're focusing on constant interaction (be it video chat, collaborative editing, or gaming), then your worst-case scenarios should improve more than if you have a news website.
Head-of-Line Blocking Removal
The fourth performance feature is intended to make QUIC faster on networks with a high amount of packet loss by mitigating the head-of-line (HoL) blocking problem. While this is true in theory, we will see that in practice this will probably only provide minor benefits for web-page loading performance.
To understand this, though, we first need to take a detour and talk about stream prioritization and multiplexing.
Stream Prioritization
As discussed in part 1, a single TCP packet loss can delay data for multiple in-transit resources because TCP's bytestream abstraction considers all data to be part of a single file. QUIC, on the other hand, is intimately aware that there are multiple concurrent bytestreams and can handle loss on a per-stream basis. However, as we've also seen, these streams are not truly transmitting data in parallel: Rather, the stream data is multiplexed onto a single connection. This multiplexing can happen in many different ways.
For example, for streams A, B, and C, we might see a packet sequence of ABCABCABCABCABCABCABCABC , where we change the active stream in each packet (let's call this round-robin). However, we might also see the opposite pattern of AAAAAAAABBBBBBBBCCCCCCCC , where each stream is completed in full before starting the next one (let's call this sequential). Of course, many other options are possible in between these extremes ( AAAABBCAAAAABBC… , AABBCCAABBCC… , ABABABCCCC… , etc.). The multiplexing scheme is dynamic and driven by an HTTP-level feature called stream prioritization (discussed later in this article).
As it turns out, which multiplexing scheme you choose can have a huge impact on website loading performance. You can see this in the video below, courtesy of Cloudflare, as every browser uses a different multiplexer. The reasons why are quite complex, and I've written several academic papers on the topic, as well as talked about it in a conference. Patrick Meenan, of Webpagetest fame, even has a three-hour tutorial on just this topic.
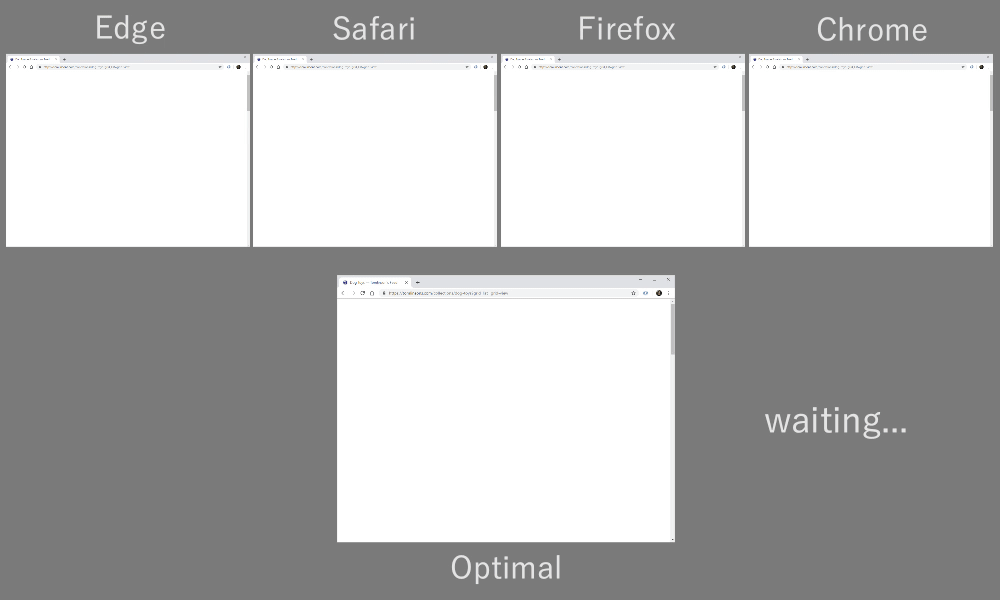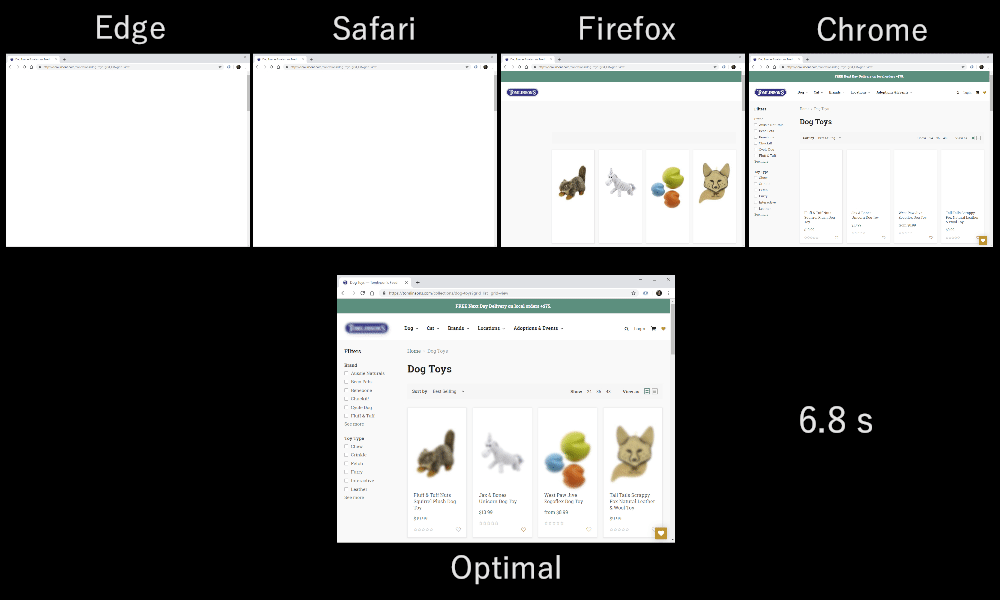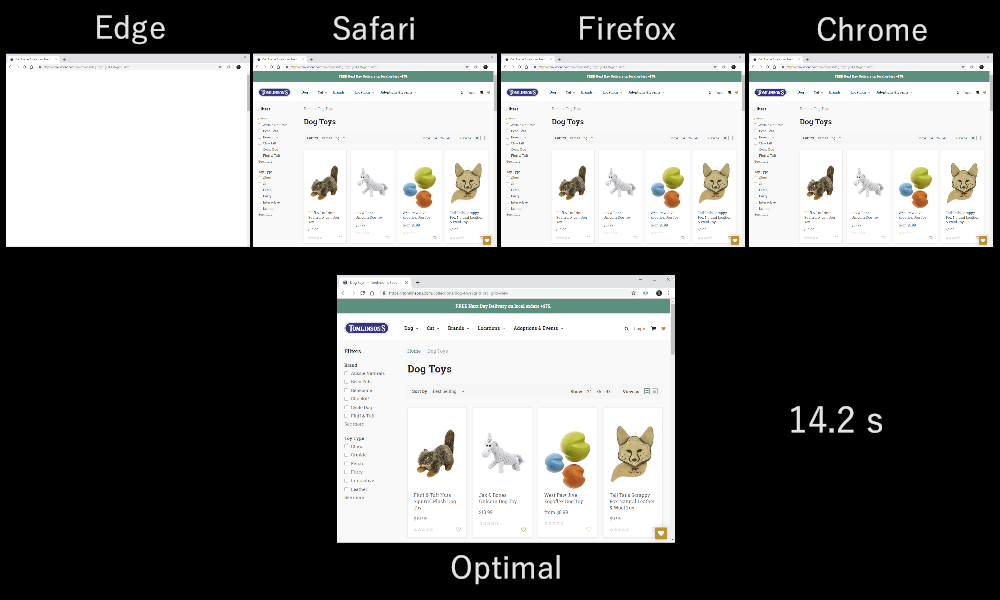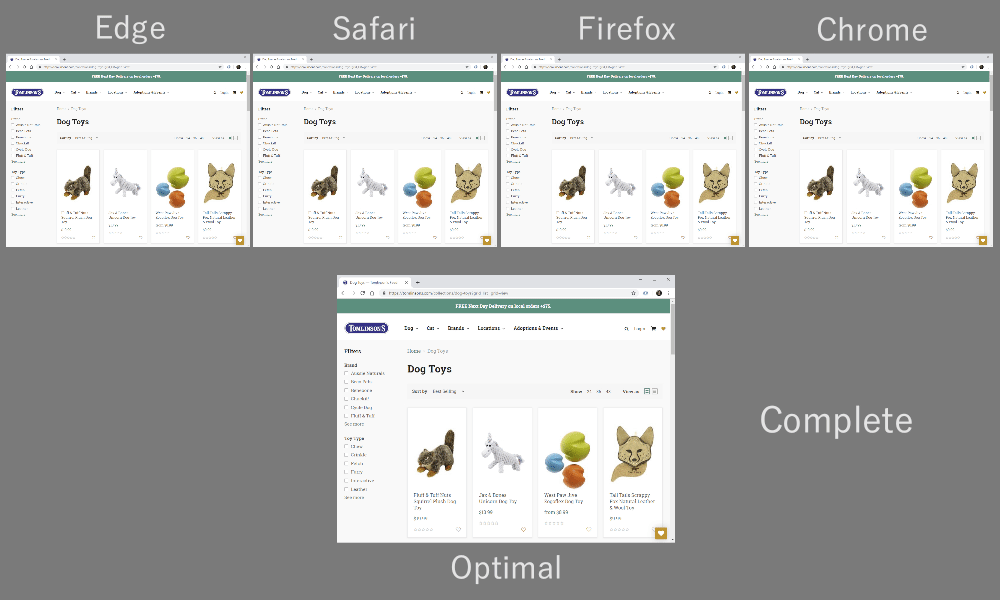
Luckily, we can explain the basics relatively easily. As you may know, some resources can be render blocking. This is the case for CSS files and for some JavaScript in the HTML head element. While these files are loading, the browser cannot paint the page (or, for example, execute new JavaScript).
What's more, CSS and JavaScript files need to be downloaded in full in order to be used (although they can often be incrementally parsed and compiled). As such, these resources need to be loaded as soon as possible, with the highest priority. Let's contemplate what would happen if A, B, and C were all render-blocking resources.
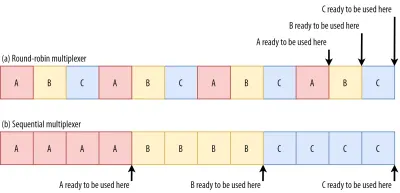
If we use a round-robin multiplexer (the top row in figure 6), we would actually delay each resource's total completion time, because they all need to share bandwidth with the others. Since we can only use them after they are fully loaded, this incurs a significant delay. However, if we multiplex them sequentially (the bottom row in figure 6), we would see that A and B complete much earlier (and can be used by the browser), while not actually delaying C's completion time.
However, that doesn't mean that sequential multiplexing is always the best, because some (mostly non-render-blocking) resources (such as HTML and progressive JPEGs) can actually be processed and used incrementally . In those (and some other) cases, it makes sense to use the first option (or at least something in between).
Still, for most web-page resources, it turns out that sequential multiplexing performs best . This is, for example, what Google Chrome is doing in the video above, while Internet Explorer is using the worst-case round-robin multiplexer.
Packet Loss Resilience
Now that we know that all streams aren't always active at the same time and that they can be multiplexed in different ways, we can consider what happens if we have packet loss. As explained in part 1, if one QUIC stream experiences packet loss, then other active streams can still be used (whereas, in TCP, all would be paused).
However, as we've just seen, having many concurrent active streams is typically not optimal for web performance, because it can delay some critical (render-blocking) resources, even without packet loss! We'd rather have just one or two active at the same time, using a sequential multiplexer. However, this reduces the impact of QUIC's HoL blocking removal.
Imagine, for example, that the sender could transmit 12 packets at a given time (see figure 7 below) — remember that this is limited by the congestion controller). If we fill all 12 of those packets with data for stream A (because it's high priority and render-blocking — think main.js ), then we would have only one active stream in that 12-packet window.
If one of those packets were to be lost, then QUIC would still end up fully HoL blocked because there would simply be no other streams it could process besides A : All of the data is for A , and so everything would still have to wait (we don't have B or C data to process), similar to TCP.

We see that we have a kind of contradiction: Sequential multiplexing ( AAAABBBBCCCC ) is typically better for web performance, but it doesn't allow us to take much advantage of QUIC's HoL blocking removal. Round-robin multiplexing ( ABCABCABCABC ) would be better against HoL blocking, but worse for web performance. As such, one best practice or optimization can end up undoing another .
And it gets worse. Up until now, we've sort of assumed that individual packets get lost one at a time. However, this isn't always true, because packet loss on the Internet is often “bursty”, meaning that multiple packets often get lost at the same time .
As discussed above, an important reason for packet loss is that a network is overloaded with too much data, having to drop excess packets. This is why the congestion controller starts sending slowly. However, it then keeps growing its send rate until… there is packet loss!
Put differently, the mechanism that's intended to prevent overloading the network actually overloads the network (albeit in a controlled fashion). On most networks, that occurs after quite a while, when the send rate has increased to hundreds of packets per round trip. When those reach the limit of the network, several of them are typically dropped together, leading to the bursty loss patterns.
Did You Know?
This is one of the reasons why we wanted to move to using a single (TCP) connection with HTTP/2, rather than the 6 to 30 connections with HTTP/1.1. Because each individual connection ramps up its send rate in pretty much the same way, HTTP/1.1 could get a good speed-up at the start, but the connections could actually start causing massive packet loss for each other as they caused the network to become overloaded.
At the time, Chromium developers speculated that this behaviour caused most of the packet loss seen on the Internet. This is also one of the reasons why BBR has become an often used congestion-control algorithm, because it uses fluctuations in observed RTTs, rather than packet loss, to assess available bandwidth.
Did You Know?
Other causes of packet loss can lead to fewer or individual packets becoming lost (or unusable), especially on wireless networks. There, however, the losses are often detected at lower protocol layers and solved between two local entities (say, the smartphone and the 4G cellular tower), rather than by retransmissions between the client and the server. These usually don't lead to real end-to-end packet loss, but rather show up as variations in packet latency (or “jitter”) and reordered packet arrivals.
So, let's say we are using a per-packet round-robin multiplexer ( ABCABCABCABCABCABCABCABC… ) to get the most out of HoL blocking removal, and we get a bursty loss of just 4 packets. We see that this will always impact all 3 streams (see figure 8, middle row)! In this case, QUIC's HoL blocking removal provides no benefits, because all streams have to wait for their own retransmissions .
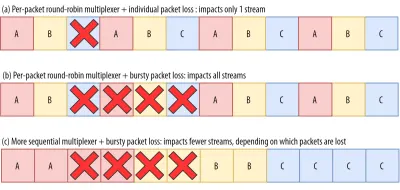
To lower the risk of multiple streams being affected by a lossy burst, we need to concatenate more data for each stream. For example, AABBCCAABBCCAABBCCAABBCC… is a small improvement, and AAAABBBBCCCCAAAABBBBCCCC… (see bottom row in figure 8 above) is even better. You can again see that a more sequential approach is better, even though that reduces the chances that we have multiple concurrent active streams.
In the end, predicting the actual impact of QUIC's HoL blocking removal is difficult, because it depends on the number of streams, the size and frequency of the loss bursts, how the stream data is actually used, etc. However, most results at this time indicate it will not help much for the use case of web-page loading, because there we typically want fewer concurrent streams.
If you want even more detail on this topic or just some concrete examples, please check out my in-depth article on HTTP HoL blocking.
Did You Know?
As with the previous sections, some advanced techniques can help us here. For example, modern congestion controllers use packet pacing. This means that they don't send, for example, 100 packets in a single burst, but rather spread them out over an entire RTT. This conceptually lowers the chances of overloading the network, and the QUIC Recovery RFC strongly recommends using it. Complementarily, some congestion-control algorithms such as BBR don't keep increasing their send rate until they cause packet loss, but rather back off before that (by looking at, for example, RTT fluctuations, because RTTs also rise when a network is becoming overloaded).
While these approaches lower the overall chances of packet loss, they don't necessarily lower its burstiness.
O que tudo isso significa?
While QUIC's HoL blocking removal means, in theory, that it (and HTTP/3) should perform better on lossy networks, in practice this depends on a lot of factors. Because the use case of web-page loading typically favours a more sequential multiplexing set-up, and because packet loss is unpredictable, this feature would, again, likely affect mainly the slowest 1% of users . However, this is still a very active area of research, and only time will tell.
Still, there are situations that might see more improvements. These are mostly outside of the typical use case of the first full page load — for example, when resources are not render blocking, when they can be processed incrementally, when streams are completely independent, or when less data is sent at the same time.
Examples include repeat visits on well-cached pages and background downloads and API calls in single-page apps. For example, Facebook has seen some benefits from HoL blocking removal when using HTTP/3 to load data in its native app.
Desempenho UDP e TLS
Um quinto aspecto de desempenho do QUIC e do HTTP/3 é sobre a eficiência e o desempenho com que eles podem realmente criar e enviar pacotes na rede. Veremos que o uso de UDP e criptografia pesada do QUIC pode torná-lo um pouco mais lento que o TCP (mas as coisas estão melhorando).
Primeiro, já discutimos que o uso do UDP pelo QUIC era mais sobre flexibilidade e capacidade de implantação do que sobre desempenho. Isso é evidenciado ainda mais pelo fato de que, até recentemente, o envio de pacotes QUIC sobre UDP era tipicamente muito mais lento do que o envio de pacotes TCP. Isso ocorre em parte por causa de onde e como esses protocolos são normalmente implementados (veja a figura 9 abaixo).
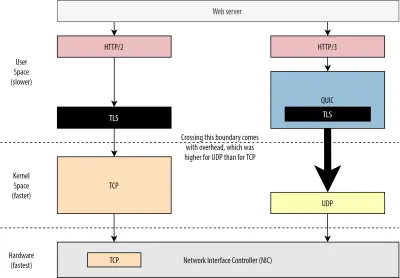
Conforme discutido acima, o TCP e o UDP são normalmente implementados diretamente no kernel rápido do sistema operacional. Em contraste, as implementações de TLS e QUIC estão principalmente no espaço do usuário mais lento (observe que isso não é realmente necessário para o QUIC — é feito principalmente porque é muito mais flexível). Isso torna o QUIC um pouco mais lento que o TCP.
Além disso, ao enviar dados de nosso software de espaço do usuário (digamos, navegadores e servidores da Web), precisamos passar esses dados para o kernel do sistema operacional , que então usa TCP ou UDP para realmente colocá-los na rede. A transmissão desses dados é feita usando APIs do kernel (chamadas de sistema), que envolvem uma certa quantidade de sobrecarga por chamada de API. Para TCP, essas sobrecargas foram muito menores do que para UDP.
Isso ocorre principalmente porque, historicamente, o TCP tem sido muito mais usado do que o UDP. Como tal, ao longo do tempo, muitas otimizações foram adicionadas às implementações de TCP e APIs do kernel para reduzir ao mínimo as sobrecargas de envio e recebimento de pacotes. Muitos controladores de interface de rede (NICs) possuem recursos de descarregamento de hardware integrados para TCP. O UDP, no entanto, não teve a mesma sorte, pois seu uso mais limitado não justificava o investimento em otimizações adicionais. Nos últimos cinco anos, isso mudou, e a maioria dos sistemas operacionais também adicionou opções otimizadas para UDP .
Em segundo lugar, o QUIC tem muita sobrecarga porque criptografa cada pacote individualmente . Isso é mais lento do que usar TLS sobre TCP, porque você pode criptografar pacotes em partes (até cerca de 16 KB ou 11 pacotes por vez), o que é mais eficiente. Essa foi uma troca consciente feita no QUIC, porque a criptografia em massa pode levar a suas próprias formas de bloqueio HoL.
Ao contrário do primeiro ponto, onde poderíamos adicionar APIs extras para tornar o UDP (e, portanto, o QUIC) mais rápido, aqui, o QUIC sempre terá uma desvantagem inerente ao TCP + TLS. No entanto, isso também é bastante gerenciável na prática com, por exemplo, bibliotecas de criptografia otimizadas e métodos inteligentes que permitem que os cabeçalhos dos pacotes QUIC sejam criptografados em massa.
Como resultado, enquanto as primeiras versões do QUIC do Google ainda eram duas vezes mais lentas que o TCP + TLS, as coisas certamente melhoraram desde então. Por exemplo, em testes recentes, a pilha QUIC altamente otimizada da Microsoft conseguiu obter 7,85 Gbps, em comparação com 11,85 Gbps para TCP + TLS no mesmo sistema (então aqui, QUIC é cerca de 66% mais rápido que TCP + TLS).
Isso ocorre com as atualizações recentes do Windows, que tornaram o UDP mais rápido (para uma comparação completa, a taxa de transferência do UDP nesse sistema foi de 19,5 Gbps). A versão mais otimizada da pilha QUIC do Google é atualmente cerca de 20% mais lenta que TCP + TLS. Testes anteriores do Fastly em um sistema menos avançado e com alguns truques até afirmam desempenho igual (cerca de 450 Mbps), mostrando que dependendo do caso de uso, o QUIC pode definitivamente competir com o TCP.
No entanto, mesmo que o QUIC fosse duas vezes mais lento que o TCP + TLS, não é tão ruim assim. Primeiro, o processamento QUIC e TCP + TLS normalmente não é a coisa mais pesada que acontece em um servidor, porque outra lógica (digamos, HTTP, cache, proxy etc.) também precisa ser executada. Como tal, você não precisará do dobro de servidores para executar o QUIC (não está claro quanto impacto isso terá em um data center real, porque nenhuma das grandes empresas divulgou dados sobre isso).
Em segundo lugar, ainda há muitas oportunidades para otimizar as implementações do QUIC no futuro. Por exemplo, ao longo do tempo, algumas implementações QUIC irão (parcialmente) migrar para o kernel do sistema operacional (muito parecido com o TCP) ou ignorá-lo (algumas já o fazem, como MsQuic e Quant). Também podemos esperar que o hardware específico do QUIC esteja disponível.
Ainda assim, provavelmente haverá alguns casos de uso para os quais o TCP + TLS continuará sendo a opção preferida. Por exemplo, a Netflix indicou que provavelmente não mudará para o QUIC tão cedo, tendo investido fortemente em configurações personalizadas do FreeBSD para transmitir seus vídeos por TCP + TLS.
Da mesma forma, o Facebook disse que o QUIC provavelmente será usado principalmente entre usuários finais e a borda da CDN , mas não entre data centers ou entre nós de borda e servidores de origem, devido à sua maior sobrecarga. Em geral, cenários de largura de banda muito alta provavelmente continuarão a favorecer o TCP + TLS, especialmente nos próximos anos.
Você sabia?
A otimização de pilhas de rede é uma toca de coelho profunda e técnica, da qual o acima apenas arranha a superfície (e perde muitas nuances). Se você for corajoso o suficiente ou se quiser saber o que significam termos comoGRO/GSO,SO_TXTIME, kernel bypass esendmmsg()erecvmmsg(), também posso recomendar alguns artigos excelentes sobre como otimizar o QUIC pela Cloudflare e Fastly como um extenso passo a passo de código da Microsoft e uma palestra detalhada da Cisco. Por fim, um engenheiro do Google deu uma palestra muito interessante sobre como otimizar a implementação do QUIC ao longo do tempo.
O que tudo isso significa?
O uso particular do QUIC dos protocolos UDP e TLS historicamente o tornou muito mais lento que o TCP + TLS. No entanto, ao longo do tempo, várias melhorias foram feitas (e continuarão a ser implementadas) que fecharam um pouco a lacuna. Você provavelmente não notará essas discrepâncias em casos de uso típicos de carregamento de páginas da Web, mas elas podem causar dores de cabeça se você mantiver farms de servidores grandes.
Recursos HTTP/3
Até agora, falamos principalmente sobre novos recursos de desempenho no QUIC versus TCP. No entanto, e HTTP/3 versus HTTP/2? Conforme discutido na parte 1, HTTP/3 é realmente HTTP/2-over-QUIC e, como tal, nenhum novo recurso real e grande foi introduzido na nova versão. Isso é diferente da mudança de HTTP/1.1 para HTTP/2, que era muito maior e introduziu novos recursos, como compactação de cabeçalho, priorização de fluxo e envio de servidor. Esses recursos ainda estão em HTTP/3, mas existem algumas diferenças importantes em como eles são implementados nos bastidores.
Isso ocorre principalmente por causa de como funciona a remoção do bloqueio de HoL pelo QUIC. Como discutimos, uma perda no fluxo B não implica mais que os fluxos A e C terão que esperar pelas retransmissões de B, como fizeram no TCP. Como tal, se A, B e C enviassem cada um um pacote QUIC nessa ordem, seus dados poderiam ser entregues (e processados) ao navegador como A, C, B! Em outras palavras, ao contrário do TCP, o QUIC não é mais totalmente ordenado em diferentes fluxos!
Este é um problema para o HTTP/2, que realmente dependia da ordenação estrita do TCP no design de muitos de seus recursos, que usam mensagens de controle especiais intercaladas com blocos de dados. No QUIC, essas mensagens de controle podem chegar (e ser aplicadas) em qualquer ordem, potencialmente até fazendo com que os recursos façam o oposto do que se pretendia! Os detalhes técnicos são, novamente, desnecessários para este artigo, mas a primeira metade deste artigo deve dar uma ideia de quão estupidamente complexo isso pode ficar.
Como tal, a mecânica interna e as implementações dos recursos tiveram que mudar para HTTP/3. Um exemplo concreto é a compressão de cabeçalho HTTP , que reduz a sobrecarga de grandes cabeçalhos HTTP repetidos (por exemplo, cookies e strings de agente de usuário). No HTTP/2, isso foi feito usando a configuração do HPACK, enquanto no HTTP/3 isso foi retrabalhado para o QPACK mais complexo. Ambos os sistemas oferecem o mesmo recurso (ou seja, compressão de cabeçalho), mas de maneiras bem diferentes. Algumas excelentes discussões técnicas e diagramas sobre este tópico podem ser encontrados no blog Litespeed.
Algo semelhante é verdadeiro para o recurso de priorização que impulsiona a lógica de multiplexação de fluxo e que discutimos brevemente acima. No HTTP/2, isso foi implementado usando uma configuração complexa de “árvore de dependência”, que explicitamente tentou modelar todos os recursos da página e suas inter-relações (mais informações estão na palestra “The Ultimate Guide to HTTP Resource Prioritization”). Usar este sistema diretamente sobre o QUIC levaria a alguns layouts de árvore potencialmente muito errados, porque adicionar cada recurso à árvore seria uma mensagem de controle separada.
Além disso, essa abordagem acabou sendo desnecessariamente complexa, levando a muitos bugs de implementação e ineficiências e desempenho abaixo da média em muitos servidores. Ambos os problemas levaram o sistema de priorização a ser redesenhado para HTTP/3 de uma forma muito mais simples. Essa configuração mais direta dificulta ou impossibilita a aplicação de alguns cenários avançados (por exemplo, tráfego de proxy de vários clientes em uma única conexão), mas ainda permite uma ampla variedade de opções para otimização de carregamento de páginas da Web.
Embora, novamente, as duas abordagens forneçam o mesmo recurso básico (guiar a multiplexação de fluxo), a esperança é que a configuração mais fácil do HTTP/3 cause menos erros de implementação.
Por fim, há o push do servidor . Esse recurso permite que o servidor envie respostas HTTP sem esperar primeiro uma solicitação explícita para elas. Em teoria, isso poderia proporcionar excelentes ganhos de desempenho. Na prática, no entanto, revelou-se difícil de usar corretamente e implementado de forma inconsistente. Como resultado, provavelmente será removido do Google Chrome.
Apesar de tudo isso, ele ainda é definido como um recurso no HTTP/3 (embora poucas implementações o suportem). Embora seu funcionamento interno não tenha mudado tanto quanto os dois recursos anteriores, ele também foi adaptado para contornar a ordenação não determinística do QUIC. Infelizmente, porém, isso fará pouco para resolver alguns de seus problemas de longa data.
O que tudo isso significa?
Como dissemos antes, a maior parte do potencial do HTTP/3 vem do QUIC subjacente, não do próprio HTTP/3. Embora a implementação interna do protocolo seja muito diferente do HTTP/2, seus recursos de desempenho de alto nível e como eles podem e devem ser usados permaneceram os mesmos.
Desenvolvimentos futuros a serem observados
Nesta série, destaquei regularmente que evolução mais rápida e maior flexibilidade são aspectos centrais do QUIC (e, por extensão, HTTP/3). Como tal, não deve ser surpresa que as pessoas já estejam trabalhando em novas extensões e aplicações dos protocolos. Listados abaixo estão os principais que você provavelmente encontrará em algum lugar no futuro:
Continue Correção de Erro
O objetivo desta técnica é, novamente, melhorar a resiliência do QUIC à perda de pacotes . Ele faz isso enviando cópias redundantes dos dados (embora codificadas e compactadas de forma inteligente para que não sejam tão grandes). Então, se um pacote for perdido, mas os dados redundantes chegarem, uma retransmissão não será mais necessária.
Isso fazia parte originalmente do Google QUIC (e uma das razões pelas quais as pessoas dizem que o QUIC é bom contra perda de pacotes), mas não está incluído na versão 1 do QUIC padronizado porque seu impacto no desempenho ainda não foi comprovado. Os pesquisadores agora estão realizando experimentos ativos com ele, e você pode ajudá-los usando o aplicativo PQUIC-FEC Download Experiments.QUIC de vários caminhos
Discutimos anteriormente a migração de conexão e como ela pode ajudar ao migrar, digamos, de Wi-Fi para celular. No entanto, isso também não implica que podemos usar Wi-Fi e celular ao mesmo tempo ? O uso simultâneo de ambas as redes nos daria mais largura de banda disponível e maior robustez! Esse é o principal conceito por trás do multipath.
Isso é, novamente, algo que o Google experimentou, mas que não chegou à versão 1 do QUIC devido à sua complexidade inerente. No entanto, os pesquisadores já mostraram seu alto potencial, e pode chegar à versão 2 do QUIC. Observe que o multipath TCP também existe, mas levou quase uma década para se tornar praticamente utilizável.Dados não confiáveis sobre QUIC e HTTP/3
Como vimos, o QUIC é um protocolo totalmente confiável. No entanto, como ele é executado em UDP, que não é confiável, podemos adicionar um recurso ao QUIC para também enviar dados não confiáveis. Isso é descrito na extensão de datagrama proposta. Obviamente, você não gostaria de usar isso para enviar recursos de páginas da Web, mas pode ser útil para coisas como jogos e streaming de vídeo ao vivo. Dessa forma, os usuários obteriam todos os benefícios do UDP, mas com criptografia de nível QUIC e controle de congestionamento (opcional).WebTransport
Os navegadores não expõem TCP ou UDP diretamente ao JavaScript, principalmente devido a questões de segurança. Em vez disso, temos que confiar em APIs de nível HTTP, como Fetch, e os protocolos WebSocket e WebRTC um pouco mais flexíveis. O mais novo nesta série de opções é chamado WebTransport, que permite principalmente usar HTTP/3 (e, por extensão, QUIC) de uma maneira mais de baixo nível (embora também possa retornar para TCP e HTTP/2 se necessário ).
Fundamentalmente, ele incluirá a capacidade de usar dados não confiáveis sobre HTTP/3 (veja o ponto anterior), o que deve tornar coisas como jogos um pouco mais fáceis de implementar no navegador. Para chamadas de API normais (JSON), você, é claro, ainda usará Fetch, que também empregará automaticamente HTTP/3 quando possível. O WebTransport ainda está sob forte discussão no momento, então ainda não está claro como será. Dos navegadores, apenas o Chromium está atualmente trabalhando em uma implementação pública de prova de conceito.Transmissão de vídeo DASH e HLS
Para vídeos não ao vivo (pense no YouTube e Netflix), os navegadores normalmente usam os protocolos Dynamic Adaptive Streaming over HTTP (DASH) ou HTTP Live Streaming (HLS). Ambos basicamente significam que você codifica seus vídeos em pedaços menores (de 2 a 10 segundos) e diferentes níveis de qualidade (720p, 1080p, 4K, etc.).
Em tempo de execução, o navegador estima a qualidade mais alta que sua rede pode suportar (ou a melhor para um determinado caso de uso) e solicita os arquivos relevantes do servidor via HTTP. Como o navegador não tem acesso direto à pilha TCP (como normalmente é implementado no kernel), ocasionalmente comete alguns erros nessas estimativas ou demora um pouco para reagir às mudanças nas condições da rede (levando a travamentos de vídeo) .
Como o QUIC é implementado como parte do navegador, isso pode ser bastante melhorado, dando aos estimadores de streaming acesso a informações de protocolo de baixo nível (como taxas de perda, estimativas de largura de banda etc.). Outros pesquisadores também estão experimentando misturar dados confiáveis e não confiáveis para streaming de vídeo, com alguns resultados promissores.Protocolos diferentes de HTTP/3
Como o QUIC é um protocolo de transporte de uso geral, podemos esperar que muitos protocolos da camada de aplicação que agora são executados sobre TCP também sejam executados em cima do QUIC. Alguns trabalhos em andamento incluem DNS sobre QUIC, SMB sobre QUIC e até SSH sobre QUIC. Como esses protocolos geralmente têm requisitos muito diferentes do HTTP e do carregamento de páginas da Web, as melhorias de desempenho do QUIC que discutimos podem funcionar muito melhor para esses protocolos.
O que tudo isso significa?
A versão 1 do QUIC é apenas o começo . Muitos recursos avançados orientados ao desempenho que o Google havia experimentado anteriormente não chegaram a esta primeira iteração. No entanto, o objetivo é evoluir rapidamente o protocolo, introduzindo novas extensões e recursos em alta frequência. Como tal, com o tempo, o QUIC (e HTTP/3) deve se tornar claramente mais rápido e flexível que o TCP (e HTTP/2).
Conclusão
Nesta segunda parte da série, discutimos os diversos recursos e aspectos de desempenho do HTTP/3 e especialmente do QUIC. Vimos que, embora a maioria desses recursos pareça muito impactante, na prática eles podem não fazer muito para o usuário médio no caso de uso de carregamento de páginas da Web que estamos considerando.
Por exemplo, vimos que o uso do UDP pelo QUIC não significa que ele pode usar repentinamente mais largura de banda do que o TCP, nem significa que ele pode baixar seus recursos mais rapidamente. O recurso 0-RTT frequentemente elogiado é realmente uma micro-otimização que economiza uma viagem de ida e volta, na qual você pode enviar cerca de 5 KB (no pior caso).
A remoção do bloqueio HoL não funciona bem se houver perda intermitente de pacotes ou quando você estiver carregando recursos de bloqueio de renderização. A migração de conexão é altamente situacional e o HTTP/3 não possui nenhum recurso novo importante que possa torná-lo mais rápido que o HTTP/2.
Como tal, você pode esperar que eu recomende que você simplesmente ignore HTTP/3 e QUIC. Por que se incomodar, certo? No entanto, eu definitivamente não vou fazer tal coisa! Embora esses novos protocolos possam não ajudar muito os usuários em redes rápidas (urbanas), os novos recursos certamente têm o potencial de serem altamente impactantes para usuários altamente móveis e pessoas em redes lentas.
Mesmo em mercados ocidentais, como a minha própria Bélgica, onde geralmente temos dispositivos rápidos e acesso a redes celulares de alta velocidade, essas situações podem afetar de 1% a até 10% de sua base de usuários, dependendo do seu produto. Um exemplo é alguém em um trem tentando desesperadamente procurar uma informação crítica em seu site, mas tendo que esperar 45 segundos para carregar. Eu certamente sei que estive nessa situação, desejando que alguém tivesse implantado o QUIC para me tirar dela.
No entanto, existem outros países e regiões onde as coisas são muito piores. Lá, o usuário médio pode se parecer muito mais com os 10% mais lentos da Bélgica, e o 1% mais lento pode nunca ver uma página carregada. Em muitas partes do mundo, o desempenho na web é um problema de acessibilidade e inclusão.
É por isso que nunca devemos apenas testar nossas páginas em nosso próprio hardware (mas também usar um serviço como Webpagetest) e também porque você deve definitivamente implantar QUIC e HTTP/3 . Especialmente se seus usuários estão sempre em movimento ou provavelmente não têm acesso a redes celulares rápidas, esses novos protocolos podem fazer muita diferença, mesmo que você não perceba muito no seu MacBook Pro cabeado. Para mais detalhes, recomendo o post de Fastly sobre o assunto.
Se isso não o convencer totalmente, considere que o QUIC e o HTTP/3 continuarão evoluindo e ficando mais rápidos nos próximos anos. Obter alguma experiência inicial com os protocolos valerá a pena no futuro, permitindo que você aproveite os benefícios dos novos recursos o mais rápido possível. Além disso, o QUIC aplica as melhores práticas de segurança e privacidade em segundo plano, o que beneficia todos os usuários em todos os lugares.
Finalmente convencido? Em seguida, continue na parte 3 da série para ler sobre como você pode usar os novos protocolos na prática.
- Parte 1: Histórico e conceitos básicos do HTTP/3
Este artigo é destinado a pessoas novas em HTTP/3 e protocolos em geral, e discute principalmente o básico. - Parte 2: Recursos de desempenho HTTP/3
Este é mais profundo e técnico. As pessoas que já conhecem o básico podem começar por aqui. - Parte 3: Opções práticas de implantação HTTP/3
Este terceiro artigo da série explica os desafios envolvidos na implantação e teste do HTTP/3 por conta própria. Ele detalha como e se você também deve alterar suas páginas e recursos da Web.