Como fazer uma rede neural: arquitetura, parâmetros e código
Publicados: 2021-02-12Redes Neurais como o nome sugere são circuitos de Neurônios. Existem diferentes tipos de Redes Neurais. As redes neurais biológicas são feitas de neurônios biológicos reais. Já as Redes Neurais Artificiais (RNA) são um sistema que se baseia na Rede Neural biológica, como presente no cérebro. O número estimado de neurônios no cérebro é de cerca de 100 bilhões, que se comunicam por meio de sinais eletroquímicos.
A RNA tenta recriar a complexidade computacional presente nos Neurônios biológicos, mas não é tão comparável a isso e são versões muito mais simples e não complexas das redes neurais biológicas. Neste artigo, vamos entender a estrutura de uma RNA e aprender a criar uma Rede Neural usando Python.
Índice
Arquitetura de rede neural
A rede neural artificial é composta por neurônios artificiais que também são chamados de “nós”. Esses nós são conectados uns aos outros de modo que uma rede ou malha seja criada. A força dessas conexões entre si recebe um valor. Este valor está entre -1 e 1.
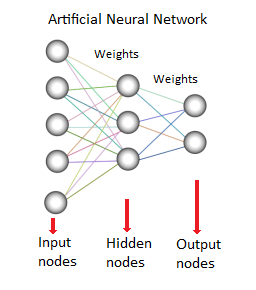
Se o valor da conexão for alto, indica uma forte conexão entre esses nós. Cada nó tem uma função característica para ele. Alterar essa função mudará o comportamento e a natureza da complexidade da rede neural. Existem três tipos de neurônios em uma RNA, nós de entrada, nós ocultos e nós de saída, conforme mostrado abaixo:
Fonte
O nó de entrada é responsável por receber as informações que geralmente estão na forma de valores numéricos ou expressões. As informações são apresentadas como valores de ativação, onde cada nó recebe um número, quanto maior o número, maior a ativação.
As informações são repassadas pela rede. Com base nos pesos de conexão do Node e na função de ativação pertencente a determinados neurônios de camadas específicas, a informação é passada de neurônio para neurônio. Cada um dos nós adiciona os valores de ativação no recebimento, os valores são modificados com base na função de transferência.
A informação flui por toda a rede, através de camadas ocultas, até chegar aos nós de saída. Os nós de saída são muito importantes, pois refletem a entrada de maneira significativa para o mundo exterior. Aqui pode ser visto um aspecto surpreendente das redes neurais que leva ao ajuste de pesos para cada camada e nós.

A diferença entre o valor previsto e o valor real (erro) será propagada para trás. A Rede Neural, portanto, aprenderá com os erros cometidos e tentará ajustar os pesos com base na abordagem de taxa de aprendizado designada.
Assim, ajustando os parâmetros como número de camadas ocultas, número de neurônios por camada, estratégia de atualização de peso e função de ativação, podemos criar uma Rede Neural.
Defina os parâmetros
Função de ativação
Existem várias funções de ativação para escolher que podem ser usadas na Rede Neural com base no problema em questão.
As funções de ativação são equações matemáticas que todo neurônio possui. Determina a saída de uma Rede Neural.
Essa função de ativação é anexada a cada neurônio da rede e determina se ele deve ser ativado ou não, o que se baseia se a ativação desse neurônio em particular ajuda a derivar previsões relevantes na camada de saída. Diferentes camadas podem ter diferentes funções de ativação anexadas a ela. As funções de ativação também ajudam a normalizar a saída de cada neurônio para um intervalo entre 1 e 0 ou entre -1 e 1.
As redes neurais modernas usam uma técnica importante chamada retropropagação para treinar o modelo ajustando os pesos, o que aumenta a pressão computacional sobre a função de ativação e sua função derivada.
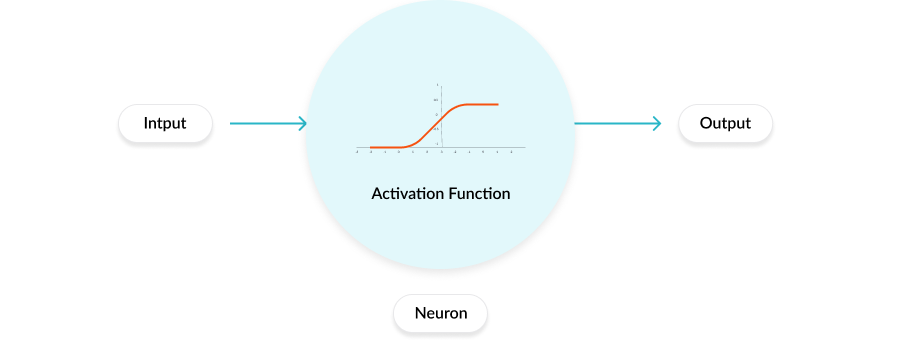
Funcionamento de uma função de ativação
Link perdido
Existem 3 tipos de funções de ativação:
Binário- x<0 y=0 , x>0 y=1
Linear- x=y
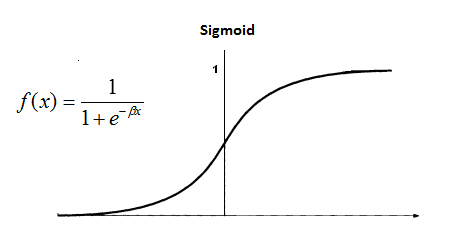
Não Linear – Vários tipos: Sigmoid, TanH, Logistic, ReLU, Softmax etc.
Fonte: Blogue
Tipo: ReLU
Link perdido
Algoritmo
Existem muitos tipos de redes neurais, mas elas são frequentemente divididas em redes feed-forward e feed-back (backpropagation).
1) A rede de alimentação direta é uma rede não repetitiva que contém entradas, saídas e camadas ocultas; pois os sinais só podem se mover em uma direção. Os dados de entrada são transferidos para a camada do equipamento de processamento onde realiza os cálculos. Cada fator de processamento faz seu cálculo com base no peso da entrada. Novos valores são calculados e então novos valores de entrada alimentam a próxima camada.

Esse processo continua até passar por todas as camadas e determinar o resultado. Uma função de transferência de limite às vezes é usada para medir a saída do neurônio na camada de saída. As redes Feed Forward são conhecidas e incluem redes Perceptron (diretas e indiretas). As redes feed-forward são frequentemente usadas para mineração de dados.
2) A rede Feed-Back (por exemplo, uma rede neural recorrente ou RNN) possui mecanismos retrospectivos, o que significa que eles podem ter sinais se movendo em ambas as direções usando armadilhas/loops. Todas as comunicações possíveis entre os neurônios são permitidas.
Uma vez que os laços estão presentes neste tipo de rede, torna-se um sistema não linear que está em constante mudança até atingir um estado de estabilidade. As redes de feedback são frequentemente usadas para memórias associadas a problemas de desempenho quando a rede está procurando um bom conjunto de objetos conectados.
Treinamento
o feed-forward pass significa dada uma entrada e pondera como a saída é calculada. Após a conclusão do treinamento, executamos apenas o passe para frente para formar as previsões.
Mas primeiro temos que treinar nosso modelo para realmente aprender os pesos e, portanto, o procedimento de treinamento funciona da seguinte forma:
- Selecione e inicialize aleatoriamente os pesos para todos os nós. Existem métodos de inicialização inteligentes integrados ao TensorFlow e Keras (Python).
- Para cada exemplo de treinamento, execute uma passagem para frente usando os pesos atuais e calcule a saída de cada nó indo da esquerda para a direita. A saída final é o valor do último nó.
- Compare a saída final com o alvo real dentro dos dados de treinamento e meça o erro empregando uma função de perda.
- Execute uma passagem para trás da direita para a esquerda e propague o erro calculado na última etapa para cada nó individual usando retropropagação.
- Calcule a contribuição do peso de cada neurônio para o erro e ajuste os pesos da conexão de acordo com o gradiente descendente. Propague os gradientes de erro de volta desde a última camada.
Código Python para Rede Neural
Agora que entendemos como a Rede Neural é feita Teoricamente, vamos implementar a mesma usando Python.
Rede neural em Python
Usaremos a API Keras com backends Tensorflow ou Theano para criar nossa rede neural.
Instalando bibliotecas
Theano
>>> pip install –upgrade –no-deps git+git://github.com/Theano/Theano.git
Tensorflow e Keras
>>> pip3 instala tensorflow
>>> pip install –upgrade Keras
Importar as bibliotecas
importar keras
de keras.models import Sequencial
de keras.layers importação Dense
Inicializando a Rede Neural Artificial
modelo = Sequencial()
Cria camadas de entrada e ocultas-
model.add(Dense(input_dim = 2, unidades = 10, ativação='relu', kernel_initializer='uniform'))
Este código adiciona a camada de entrada e uma camada oculta à rede sequencial
Dense(): permite criar uma rede neural densamente conectada
input_dim: forma ou número de nós na camada de entrada
unidades: o número de neurônios ou nós na camada atual (camada oculta)
ativação: a função de ativação aplicada a cada nó.”relu” significa Unidade Linear Retificada
kernel_initializer: pesos aleatórios iniciais da camada
Segunda camada oculta
model.add(Dense(unidades = 20, ativação='relu', kernel_initializer='uniform'))
O código cria e adiciona outra camada oculta ao modelo com 20 nós e função de ativação 'linear retificada'. Mais camadas podem ser adicionadas de maneira semelhante, dependendo do problema e da complexidade.
Camada de saída
model.add(Dense(unidades = 1, ativação='sigmoid', kernel_initializer='uniform'))
Uma única camada de saída com Sigmoid ou softmax são as funções de ativação comumente usadas para uma camada de saída.
Compilação ANN:
model.compile(optimizer='adam', perda='binary_crossentropy', métrica=['precisão'])
A RNA é compilada com uma função de otimização e uma função de perda antes de ser treinada.
Otimizador: uma função de otimizador para a rede. Existem vários tipos de otimizadores e o adam é o mais utilizado.
Perda: usado para calcular as perdas e erros. Existem vários tipos e a escolha depende da natureza do problema a ser tratado.
Métricas: a métrica usada para medir o desempenho do modelo.
Ajustando o modelo com os dados de treinamento:
model.fit(X_train,Y_train,batch_size=64, epochs=30)
Este código criará o modelo
Conclusão
Agora podemos criar uma Rede Neural Artificial (em Python) do zero, pois entendemos os diferentes parâmetros que podem ser alterados de acordo com o problema em questão.
Se você estiver interessado em aprender mais sobre técnicas de aprendizado profundo , aprendizado de máquina, confira o Diploma PG do IIIT-B e do upGrad em aprendizado de máquina e IA, projetado para profissionais que trabalham e oferece mais de 450 horas de treinamento rigoroso, mais de 30 estudos de caso e atribuições, status de ex-alunos do IIIT-B, mais de 5 projetos práticos práticos e assistência de trabalho com as principais empresas.
Aprenda ML Course das melhores universidades do mundo. Ganhe Masters, Executive PGP ou Advanced Certificate Programs para acelerar sua carreira.