
Como implementar a classificação no aprendizado de máquina?
Publicados: 2021-03-12A aplicação do Machine Learning em vários campos aumentou aos trancos e barrancos nos últimos anos e continua a fazê-lo. Uma das tarefas mais populares do modelo de Machine Learning é reconhecer objetos e separá-los em suas classes designadas.
Este é o método de Classificação que é uma das aplicações mais populares de Machine Learning. A classificação é usada para separar uma grande quantidade de dados em um conjunto de valores discretos que podem ser binários, como 0/1, Sim/Não, ou multiclasse, como animais, carros, pássaros, etc.
No artigo a seguir, vamos entender o conceito de Classificação em Machine Learning, os tipos de Dados envolvidos, e ver alguns dos algoritmos de Classificação mais populares usados em Machine Learning para classificar diversos dados.
Índice
O que é Aprendizagem Supervisionada?
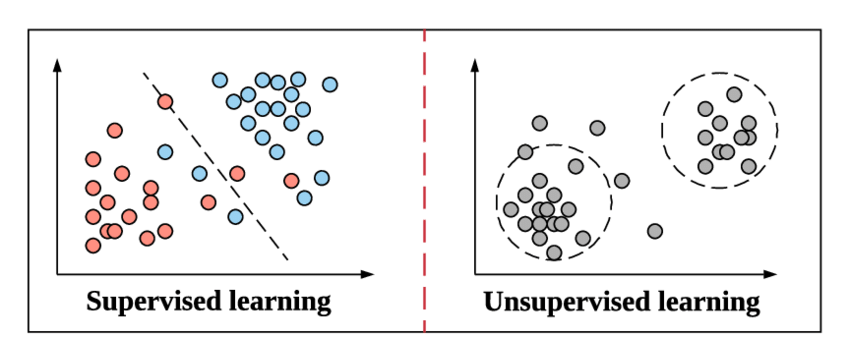
Enquanto nos preparamos para mergulhar no conceito de Classificação e seus tipos, vamos nos atualizar rapidamente com o que se entende por Aprendizado Supervisionado e como ele difere do outro método de Aprendizado Não Supervisionado em Aprendizado de Máquina.
Vamos entender isso tomando um exemplo simples de nossa aula de Física no Ensino Médio. Suponha que haja um problema simples envolvendo um novo método. Se nos for apresentada uma questão em que temos que resolver usando o mesmo método, não nos referiríamos a um problema de exemplo com o mesmo método e tentaríamos resolvê-lo. Uma vez que estamos confiantes com esse método, não precisamos consultá-lo novamente e continuar a resolvê-lo.
Fonte

Essa é a mesma maneira pela qual o Aprendizado Supervisionado funciona no Aprendizado de Máquina. Ele aprende pelo exemplo. Para mantê-lo ainda mais simples, no Aprendizado Supervisionado, todos os dados são alimentados com seus rótulos correspondentes e, portanto, durante o processo de treinamento, o modelo de Aprendizado de Máquina compara sua saída para um dado específico com a saída real desses mesmos dados e tenta minimizar o erro entre o valor de rótulo previsto e real.
Os Algoritmos de Classificação que veremos neste artigo seguem este método de Aprendizado Supervisionado – por exemplo, Detecção de Spam e Reconhecimento de Objetos.
O Aprendizado Não Supervisionado é uma etapa acima na qual os dados não são alimentados com seus rótulos. Cabe à responsabilidade e eficiência do modelo de Machine Learning derivar padrões dos dados e fornecer a saída. Os algoritmos de agrupamento seguem este método não supervisionado de aprendizado.
O que é Classificação?
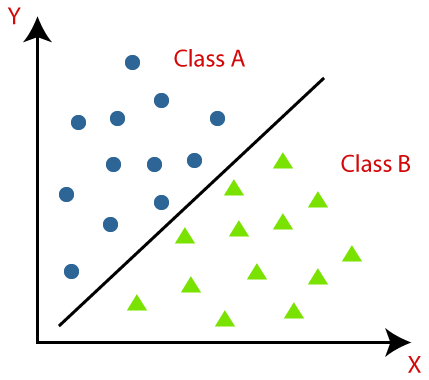
A classificação é definida como reconhecer, compreender e agrupar os objetos ou dados em classes predefinidas. Ao categorizar os dados antes do processo de treinamento do modelo de Machine Learning, podemos usar vários algoritmos de classificação para classificar os dados em várias classes. Ao contrário da Regressão, um problema de classificação ocorre quando a variável de saída é uma categoria, como “Sim” ou “Não” ou “Doença” ou “Sem Doença”.
Na maioria dos problemas de Machine Learning, uma vez que o conjunto de dados é carregado no programa, antes do treinamento, divide-se o conjunto de dados em um conjunto de treinamento e o conjunto de teste com uma proporção fixa (geralmente 70% do conjunto de treinamento e 30% do conjunto de teste). Esse processo de divisão permite que o modelo realize retropropagação na qual ele tenta corrigir seu erro do valor previsto em relação ao valor verdadeiro por várias aproximações matemáticas.
Da mesma forma, antes de começarmos a Classificação, o conjunto de dados de treinamento é criado. O algoritmo de classificação passa por treinamento nele enquanto testa no conjunto de dados de teste a cada iteração, conhecido como época.
Fonte
Um dos aplicativos de algoritmos de classificação mais comuns é filtrar os e-mails para saber se eles são “spam” ou “não spam”. Em suma, podemos definir a Classificação em Aprendizado de Máquina como uma forma de “Reconhecimento de Padrões” em que esses algoritmos que são aplicados aos dados de treinamento são usados para extrair vários padrões dos dados (como palavras ou sequências numéricas semelhantes, sentimentos, etc.). .).
A classificação é um processo de categorizar um determinado conjunto de dados em classes; ele pode ser executado em dados estruturados ou não estruturados. Ele começa prevendo a classe dos pontos de dados fornecidos. Essas classes também são chamadas de variáveis de saída, rótulos de destino, etc. Vários algoritmos têm funções matemáticas embutidas para aproximar a função de mapeamento das variáveis de ponto de dados de entrada para a classe de destino de saída. O objetivo principal da classificação é identificar em qual classe/categoria os novos dados se enquadrarão.
Tipos de algoritmos de classificação em aprendizado de máquina
Dependendo do tipo de dados em que os Algoritmos de Classificação são aplicados, existem duas grandes categorias de algoritmos, os modelos Linear e Não-linear.
Modelos lineares
- Regressão Logística
- Máquinas de vetor de suporte (SVM)
Modelos não lineares
- Classificação K-Vizinhos Mais Próximos (KNN)
- Kernel SVM
- Classificação Naive Bayes
- Classificação da Árvore de Decisão
- Classificação Florestal Aleatória
Neste artigo, abordaremos brevemente o conceito por trás de cada um dos algoritmos mencionados acima.
Avaliação de um Modelo de Classificação em Machine Learning
Antes de entrarmos nos conceitos desses algoritmos mencionados acima, devemos entender como podemos avaliar nosso modelo de Machine Learning construído sobre esses algoritmos. É essencial avaliar nosso modelo quanto à precisão tanto no conjunto de treinamento quanto no conjunto de teste.
Perda de Entropia Cruzada ou Perda de Log
Este é o primeiro tipo de função de perda que usaremos na avaliação do desempenho de um classificador cuja saída está entre 0 e 1. Isso é usado principalmente para modelos de Classificação Binária. A fórmula de Log Loss é dada por,
Perda de Log = -((1 – y) * log(1 – yhat) + y * log(yhat))
Onde esse é o valor previsto e y é o valor real.
Matriz de confusão
Uma matriz de confusão é uma matriz NXN, onde N é o número de classes que estão sendo previstas. A matriz de confusão nos fornece uma matriz/tabela como saída e descreve o desempenho do modelo. Consiste no resultado das previsões na forma de uma matriz a partir da qual podemos derivar várias métricas de desempenho para avaliar o modelo de Classificação. É da forma,
| Positivo real | Negativo real | |
| Positivo previsto | Verdadeiro Positivo | Falso positivo |
| Negativo previsto | Falso negativo | Verdadeiro Negativo |
Algumas das métricas de desempenho que podem ser derivadas da tabela acima são fornecidas abaixo.
1.Precisão – a proporção do número total de previsões corretas.
2. Valor Preditivo Positivo ou Precisão – a proporção de casos positivos que foram identificados corretamente.
3. Valor Preditivo Negativo – a proporção de casos negativos que foram identificados corretamente.
4. Sensibilidade ou Recall – a proporção de casos positivos reais que são corretamente identificados.
5. Especificidade – a proporção de casos negativos reais que são corretamente identificados.
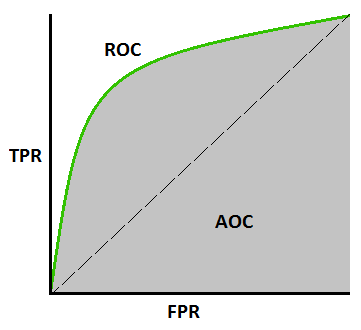
Curva AUC-ROC -
Essa é outra métrica de curva importante que avalia qualquer modelo de Machine Learning. A curva ROC significa Curva de Características de Operação do Receptor e AUC significa Área Sob a Curva. A curva ROC é plotada com TPR e FPR, onde TPR (True Positive Rate) no eixo Y e FPR (False Positive Rate) no eixo X. Ele mostra o desempenho do modelo de classificação em diferentes limites.
Fonte
1. Regressão Logística
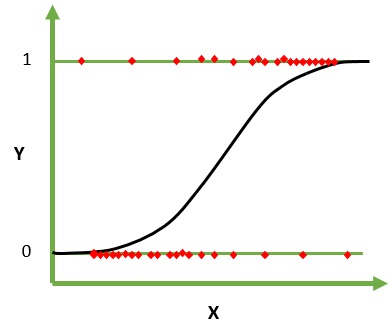
A regressão logística é um algoritmo de aprendizado de máquina para classificação. Neste algoritmo, as probabilidades que descrevem os resultados possíveis de um único ensaio são modeladas usando uma função logística. Ele assume que as variáveis de entrada são numéricas e têm uma distribuição Gaussiana (curva de sino).
A função logística, também chamada de função sigmóide, foi inicialmente usada por estatísticos para descrever o crescimento populacional em ecologia. A função sigmóide é uma função matemática usada para mapear os valores previstos para probabilidades. A Regressão Logística tem uma curva em forma de S e pode assumir valores entre 0 e 1, mas nunca exatamente nesses limites.

Fonte
A regressão logística é usada principalmente para prever um resultado binário, como Sim/Não e Aprovado/Reprovado. As variáveis independentes podem ser categóricas ou numéricas, mas a variável dependente é sempre categórica. A fórmula da regressão logística é dada por,
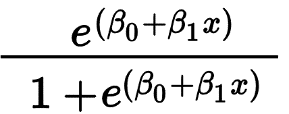
Onde e representa a curva em forma de S que tem valores entre 0 e 1.
2. Máquinas de vetor de suporte
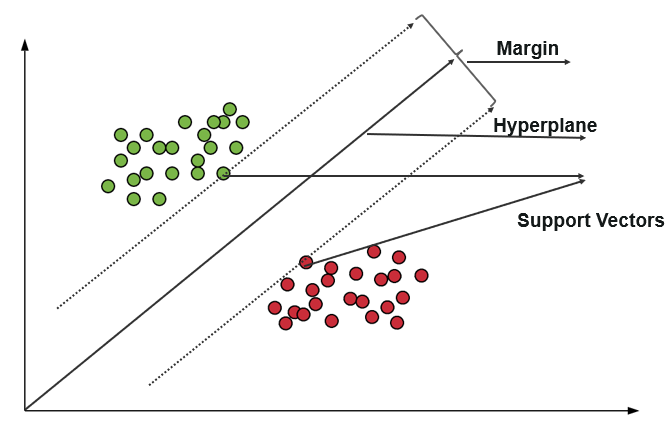
Uma máquina de vetores de suporte (SVM) usa algoritmos para treinar e classificar dados em graus de polaridade, levando-os a um grau além da previsão X/Y. No SVM, a linha que é usada para separar as classes é chamada de Hyperplane. Os pontos de dados em ambos os lados do hiperplano mais próximos do hiperplano são chamados de vetores de suporte usados para traçar a linha de limite.
Esta máquina de vetores de suporte na classificação representa os dados de treinamento como pontos de dados em um espaço no qual muitas categorias são separadas nas categorias de hiperplano. Quando um novo ponto entra, ele é classificado prevendo em qual categoria eles se enquadram e pertencem a um determinado espaço.
Fonte
O principal objetivo da máquina de vetores de suporte é maximizar a margem entre os dois vetores de suporte.
Participe do curso de ML online das melhores universidades do mundo - mestrados, programas de pós-graduação executiva e programa de certificação avançada em ML e IA para acelerar sua carreira.
3. Classificação K-Vizinhos Mais Próximos (KNN)
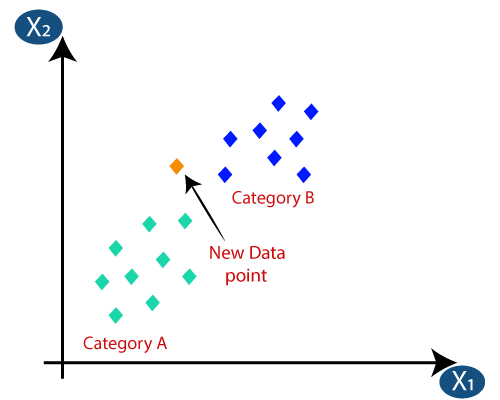
A Classificação KNN é um dos algoritmos mais simples de Classificação, mas é altamente utilizado devido à sua alta eficiência e facilidade de uso. Nesse método, todo o conjunto de dados é armazenado inicialmente na máquina. Então, um valor – k é escolhido, que representa o número de vizinhos. Dessa forma, quando um novo ponto de dados é adicionado ao conjunto de dados, ele leva a maioria dos votos do rótulo de classe dos k vizinhos mais próximos para esse novo ponto de dados. Com essa votação, o novo ponto de dados é adicionado a essa classe específica com a votação mais alta.
Fonte
4. Kernel SVM
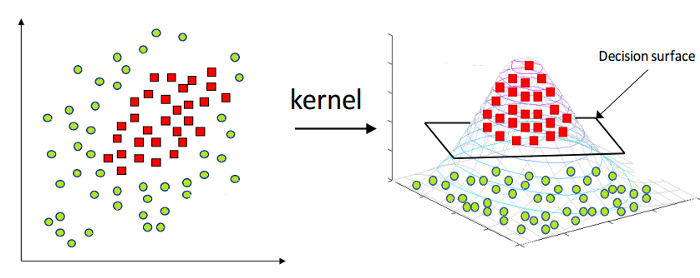
Como mencionado acima, o Linear Support Vector Machine só pode ser aplicado a dados lineares por natureza. No entanto, todos os dados do mundo não são linearmente separáveis. Portanto, precisamos desenvolver uma máquina de vetores de suporte para levar em conta os dados que também são separáveis não linearmente. Aí vem o truque do Kernel, também conhecido como Kernel Support Vector Machine ou Kernel SVM.
No Kernel SVM, selecionamos um kernel como o RBF ou o Kernel Gaussiano. Todos os pontos de dados são mapeados para uma dimensão superior, onde se tornam linearmente separáveis. Dessa forma, podemos criar um limite de decisão entre as diferentes classes do conjunto de dados.
Fonte
Assim, desta forma, utilizando os conceitos básicos de Support Vector Machines, podemos projetar um Kernel SVM para não linear.
5. Classificação Naive Bayes
A Classificação Naive Bayes tem suas raízes pertencentes ao Teorema de Bayes, assumindo que todas as variáveis independentes (características) do conjunto de dados são independentes. Eles têm igual importância na previsão do resultado. Esta suposição do Teorema de Bayes dá o nome de 'Naive'. Ele é usado para várias tarefas, como filtragem de spam e outras áreas de classificação de texto. Naive Bayes calcula a possibilidade de um ponto de dados pertencer a uma determinada categoria ou não.
A fórmula da Classificação Naive Bayes é dada por,
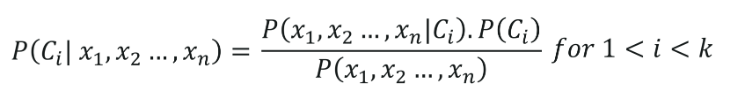
6. Classificação da Árvore de Decisão
Uma árvore de decisão é um algoritmo de aprendizado supervisionado perfeito para problemas de classificação, pois pode ordenar classes em um nível preciso. Ele opera na forma de um fluxograma onde separa os pontos de dados em cada nível. A estrutura final parece uma árvore com nós e folhas.

Fonte
Um nó de decisão terá duas ou mais ramificações e uma folha representa uma classificação ou decisão. No exemplo acima de uma Árvore de Decisão, ao fazer várias perguntas, cria-se um fluxograma, que nos ajuda a resolver o simples problema de prever se vamos ou não ao mercado.
7. Classificação Florestal Aleatória
Chegando ao último Algoritmo de Classificação desta lista, a Floresta Aleatória é apenas uma extensão do Algoritmo da Árvore de Decisão. Uma Floresta Aleatória é um método de aprendizado conjunto com várias Árvores de Decisão. Funciona da mesma maneira que as Árvores de Decisão.
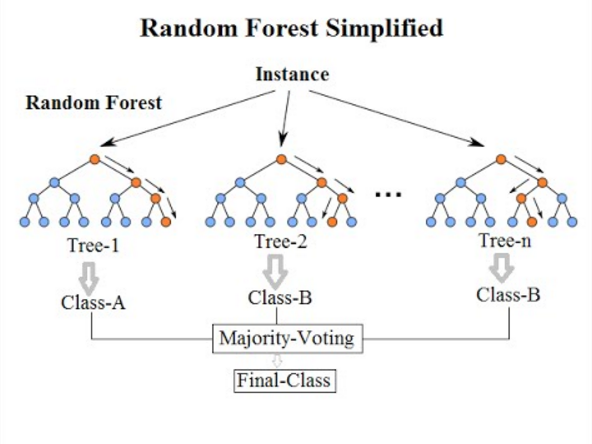
Fonte
O Random Forest Algorithm é um avanço para o algoritmo de árvore de decisão existente, que sofre de um grande problema de “ overfitting ”. Também é considerado mais rápido e preciso em comparação com o Algoritmo da Árvore de Decisão.
Leia também: Ideias e tópicos de projetos de aprendizado de máquina
Conclusão
Assim, neste artigo sobre Métodos de Aprendizado de Máquina para Classificação, entendemos os conceitos básicos de Classificação e Aprendizado Supervisionado, Tipos e Métricas de Avaliação de modelos de Classificação e, por fim, um resumo de todos os modelos de Classificação de Aprendizado de Máquina mais usados.
Se você estiver interessado em aprender mais sobre aprendizado de máquina, confira o Programa PG Executivo do IIIT-B e do upGrad em Machine Learning e IA , projetado para profissionais que trabalham e oferece mais de 450 horas de treinamento rigoroso, mais de 30 estudos de caso e atribuições, IIIT -B Alumni status, mais de 5 projetos práticos práticos e assistência de trabalho com as principais empresas.
Q1. Quais algoritmos são mais usados em aprendizado de máquina?
O aprendizado de máquina emprega muitos algoritmos diferentes, que podem ser amplamente classificados em três tipos principais – algoritmos de aprendizado supervisionado, algoritmos de aprendizado não supervisionado e algoritmos de aprendizado por reforço. Agora, para restringir e nomear alguns dos algoritmos mais usados, os que devem ser mencionados são regressão linear, regressão logística, SVM, árvores de decisão, algoritmo de floresta aleatória, kNN, teoria Naive Bayes, K-Means, redução de dimensionalidade, e algoritmos de aumento de gradiente. Os algoritmos XGBoost, GBM, LightGBM e CatBoost merecem menção especial em algoritmos de aumento de gradiente. Esses algoritmos podem ser aplicados para resolver quase qualquer tipo de problema de dados.
Q2. O que é classificação e regressão no aprendizado de máquina?
Os algoritmos de classificação e regressão são amplamente usados em aprendizado de máquina. No entanto, existem muitas diferenças entre eles, que acabam por determinar seu uso ou finalidade. A principal diferença é que, enquanto os algoritmos de classificação são usados para classificar ou prever valores discretos como masculino-feminino ou verdadeiro-falso, os algoritmos de regressão são usados para prever valores contínuos não discretos, como salário, idade, preço, etc. Árvores de decisão, floresta aleatória, Kernel SVM e regressão logística são alguns dos algoritmos de classificação mais comuns, enquanto regressão linear simples e múltipla, regressão vetorial de suporte, regressão polinomial e regressão em árvore de decisão são alguns dos algoritmos de regressão mais populares usados em aprendizado de máquina.
Q3. Quais são os pré-requisitos para aprender machine learning?
Para começar com o aprendizado de máquina, você não precisa ser um matemático proficiente ou um programador especialista. No entanto, dada a vastidão do campo, pode parecer intimidador quando você está prestes a começar sua jornada de aprendizado de máquina. Nesses casos, conhecer os pré-requisitos pode ajudá-lo a ter um início tranquilo. Os pré-requisitos são essencialmente as principais habilidades que você precisa adquirir para entender os conceitos de aprendizado de máquina. Então, antes de tudo, certifique-se de aprender a codificar usando Python. Em seguida, uma compreensão básica de estatística e matemática, especialmente álgebra linear e cálculo multivariável, será uma vantagem adicional.