
Como escolher um método de seleção de recursos para aprendizado de máquina
Publicados: 2021-06-22Índice
Introdução à seleção de recursos
Muitos recursos são usados por um modelo de aprendizado de máquina, dos quais apenas alguns deles são importantes. Há uma precisão reduzida do modelo se recursos desnecessários forem usados para treinar um modelo de dados. Além disso, há um aumento na complexidade do modelo e uma diminuição na capacidade de generalização resultando em um modelo tendencioso. O ditado “às vezes menos é melhor” combina bem com o conceito de aprendizado de máquina. O problema foi enfrentado por muitos usuários onde eles acham difícil identificar o conjunto de recursos relevantes de seus dados e ignorar todos os conjuntos de recursos irrelevantes. Os recursos menos importantes são denominados de modo que não contribuam para a variável de destino.
Portanto, um dos processos importantes é a seleção de recursos no aprendizado de máquina . O objetivo é selecionar o melhor conjunto possível de recursos para o desenvolvimento de um modelo de aprendizado de máquina. Há um enorme impacto no desempenho do modelo pela seleção de recursos. Juntamente com a limpeza de dados, a seleção de recursos deve ser a primeira etapa no design de um modelo.
A seleção de recursos no Machine Learning pode ser resumida como
- Seleção automática ou manual dos recursos que mais contribuem para a variável de previsão ou a saída.
- A presença de recursos irrelevantes pode levar a uma menor precisão do modelo, pois ele aprenderá com recursos irrelevantes.
Benefícios da seleção de recursos
- Reduz o overfitting de dados: um número menor de dados leva a uma redundância menor. Portanto, há menos chances de tomar decisões sobre o ruído.
- Melhora a precisão do modelo: com menor chance de dados enganosos, a precisão do modelo é aumentada.
- O tempo de treinamento é reduzido: a remoção de recursos irrelevantes reduz a complexidade do algoritmo, pois apenas menos pontos de dados estão presentes. Portanto, os algoritmos treinam mais rápido.
- A complexidade do modelo é reduzida com uma melhor interpretação dos dados.
Métodos supervisionados e não supervisionados de seleção de recursos
O principal objetivo dos algoritmos de seleção de características é selecionar um conjunto de melhores características para o desenvolvimento do modelo. Os métodos de seleção de recursos no aprendizado de máquina podem ser classificados em métodos supervisionados e não supervisionados.
- Método supervisionado: o método supervisionado é usado para a seleção de características a partir de dados rotulados e também para a classificação das características relevantes. Assim, há um aumento da eficiência dos modelos que são construídos.
- Método não supervisionado : este método de seleção de características é usado para dados não rotulados.
Lista de métodos sob métodos supervisionados
Os métodos supervisionados de seleção de recursos em aprendizado de máquina podem ser classificados em

1. Métodos de embalagem
Esse tipo de algoritmo de seleção de recursos avalia o processo de desempenho dos recursos com base nos resultados do algoritmo. Também conhecido como algoritmo guloso, ele treina o algoritmo usando um subconjunto de recursos de forma iterativa. Os critérios de parada geralmente são definidos pela pessoa que treina o algoritmo. A adição e remoção de features no modelo ocorrem com base no treinamento prévio do modelo. Qualquer tipo de algoritmo de aprendizado pode ser aplicado nesta estratégia de busca. Os modelos são mais precisos em comparação com os métodos de filtro.
As técnicas usadas nos métodos Wrapper são:
- Seleção direta: O processo de seleção direta é um processo iterativo onde novos recursos que melhoram o modelo são adicionados após cada iteração. Ele começa com um conjunto vazio de recursos. A iteração continua e para até que um recurso seja adicionado que não melhore ainda mais o desempenho do modelo.
- Seleção/eliminação para trás: O processo é um processo iterativo que começa com todos os recursos. Após cada iteração, os recursos com menor significância são removidos do conjunto de recursos iniciais. O critério de parada para a iteração é quando o desempenho do modelo não melhora ainda mais com a remoção do recurso. Esses algoritmos são implementados no pacote mlxtend.
- Eliminação bidirecional : Ambos os métodos de seleção direta e a técnica de eliminação inversa são aplicados simultaneamente no método de eliminação bidirecional para alcançar uma solução única.
- Seleção exaustiva de recursos: também é conhecida como abordagem de força bruta para a avaliação de subconjuntos de recursos. Um conjunto de possíveis subconjuntos é criado e um algoritmo de aprendizado é construído para cada subconjunto. Esse subconjunto é escolhido cujo modelo oferece o melhor desempenho.
- Eliminação de recursos recursivos (RFE): O método é denominado ganancioso, pois seleciona recursos considerando recursivamente o conjunto cada vez menor de recursos. Um conjunto inicial de características é usado para treinar o estimador e sua importância é obtida usando feature_importance_attribute. Em seguida, é seguido pela remoção dos recursos menos importantes, deixando para trás apenas o número necessário de recursos. Os algoritmos são implementados no pacote scikit-learn.
Figura 4: Um exemplo de código mostrando a técnica de eliminação de recursos recursivos
2. Métodos incorporados
Os métodos de seleção de recursos incorporados no aprendizado de máquina têm uma certa vantagem sobre os métodos de filtro e wrapper, incluindo a interação de recursos e também mantendo um custo computacional razoável. As técnicas usadas em métodos embarcados são:
- Regularização: O ajuste excessivo de dados é evitado pelo modelo adicionando uma penalidade aos parâmetros do modelo. Os coeficientes são adicionados com a penalidade resultando em alguns coeficientes serem zero. Portanto, os recursos que têm um coeficiente zero são removidos do conjunto de recursos. A abordagem de seleção de atributos utiliza Lasso (regularização L1) e redes elásticas (regularização L1 e L2).
- SMLR (Regressão Logística Multinomial Esparsa): O algoritmo implementa uma regularização esparsa por ARD prior (determinação automática de relevância) para a regressão logística multinacional clássica. Essa regularização estima a importância de cada recurso e elimina as dimensões que não são úteis para a previsão. A implementação do algoritmo é feita em SMLR.
- ARD (Regressão Automática de Determinação de Relevância): O algoritmo deslocará os pesos dos coeficientes para zero e é baseado em uma regressão Bayesiana. O algoritmo pode ser implementado em scikit-learn.
- Importância da Floresta Aleatória: Este algoritmo de seleção de recursos é uma agregação de um número especificado de árvores. As estratégias baseadas em árvore neste algoritmo classificam com base no aumento da impureza de um nó ou na diminuição da impureza (impureza Gini). O final das árvores consiste nos nós com a menor diminuição na impureza e o início das árvores consiste nos nós com a maior diminuição na impureza. Portanto, recursos importantes podem ser selecionados por meio da poda da árvore abaixo de um nó específico.
3. Métodos de filtro
Os métodos são aplicados durante as etapas de pré-processamento. Os métodos são bastante rápidos e baratos e funcionam melhor na remoção de recursos duplicados, correlacionados e redundantes. Em vez de aplicar qualquer método de aprendizado supervisionado, a importância dos recursos é avaliada com base em suas características inerentes. O custo computacional do algoritmo é menor em comparação com os métodos wrapper de seleção de recursos. No entanto, se dados suficientes não estiverem presentes para derivar a correlação estatística entre os recursos, os resultados poderão ser piores do que os métodos do wrapper. Portanto, os algoritmos são usados sobre dados de alta dimensão, o que levaria a um maior custo computacional se métodos wrapper fossem aplicados.

As técnicas usadas nos métodos de filtro são :
- Ganho de informação : O ganho de informação refere-se a quanta informação é obtida das características para identificar o valor alvo. Em seguida, mede a redução nos valores de entropia. O ganho de informação de cada atributo é calculado considerando os valores alvo para seleção de atributos.
- Teste do qui-quadrado : O método do qui-quadrado (X 2 ) é geralmente usado para testar a relação entre duas variáveis categóricas. O teste é utilizado para identificar se existe uma diferença significativa entre os valores observados de diferentes atributos do conjunto de dados em relação ao seu valor esperado. Uma hipótese nula afirma que não há associação entre duas variáveis.
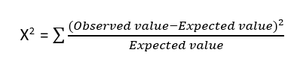
Fonte
A fórmula do teste Qui-quadrado
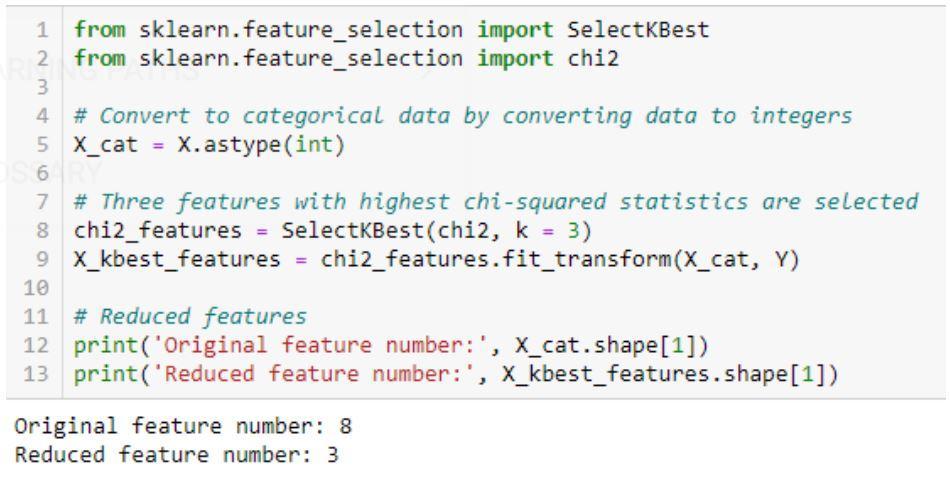
Implementação do algoritmo Qui-Quadrado: sklearn, scipy
Um exemplo de código para teste Qui-quadrado
Fonte
- CFS (Seleção de recursos baseados em correlação): O método segue “Os Implementação do CFS (seleção de recursos baseada em correlação): scikit-feature
Participe dos cursos de IA e ML on-line das melhores universidades do mundo - mestrados, programas de pós-graduação executiva e programa de certificação avançada em ML e IA para acelerar sua carreira.
- FCBF (Filtro rápido baseado em correlação): Comparado aos métodos de Relief e CFS mencionados acima, o método FCBF é mais rápido e eficiente. Inicialmente, o cálculo da Incerteza Simétrica é realizado para todas as características. Usando esses critérios, os recursos são classificados e os recursos redundantes são removidos.
Incerteza Simétrica= o ganho de informação de x | y dividido pela soma de suas entropias. Implementação do FCBF: skfeature
- Escore de Fischer: A razão de Fischer (FIR) é definida como a distância entre as médias amostrais para cada classe por característica dividida por suas variâncias. Cada recurso é selecionado independentemente de acordo com suas pontuações no critério de Fisher. Isso leva a um conjunto de recursos abaixo do ideal. Uma pontuação de Fisher maior denota uma característica melhor selecionada.
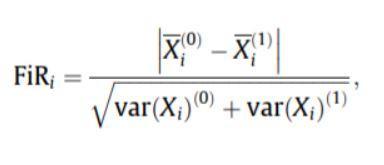
Fonte
A fórmula para a pontuação de Fischer
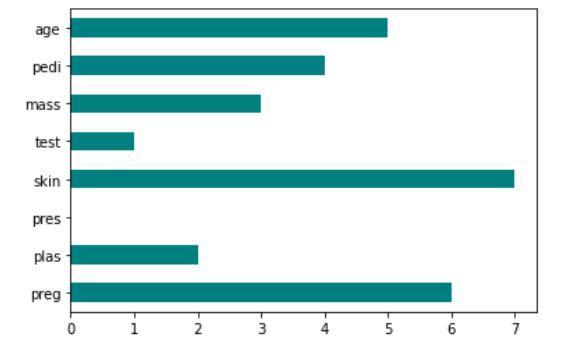
Implementação da pontuação de Fisher: recurso scikit
A saída do código mostrando a técnica de pontuação de Fisher
Fonte
Coeficiente de Correlação de Pearson: É uma medida de quantificação da associação entre as duas variáveis contínuas. Os valores do coeficiente de correlação variam de -1 a 1 que define a direção do relacionamento entre as variáveis.
- Limite de variação: os recursos cuja variação não atende ao limite específico são removidos. Os recursos com variação zero são removidos por esse método. A suposição considerada é que características de maior variância provavelmente contêm mais informações.
Figura 15: Um exemplo de código mostrando a implementação do limite de variação
- Diferença Média Absoluta (MAD): O método calcula a média absoluta
diferença do valor médio.
Um exemplo de código e sua saída mostrando a implementação da Diferença Absoluta Média (MAD)
Fonte
- Taxa de dispersão: A taxa de dispersão é definida como a razão entre a média aritmética (AM) e a média geométrica (GM) para um determinado recurso. Seu valor varia de +1 a ∞ como AM ≥ GM para um determinado recurso.
Uma razão de dispersão mais alta implica um valor mais alto de Ri e, portanto, uma característica mais relevante. Por outro lado, quando Ri está próximo de 1, indica um recurso de baixa relevância.
- Dependência Mútua: O método é usado para medir a dependência mútua entre duas variáveis. As informações obtidas de uma variável podem ser usadas para obter informações da outra variável.
- Escore Laplaciano: Os dados da mesma classe costumam estar próximos uns dos outros. A importância de uma feição pode ser avaliada pelo seu poder de preservação da localidade. A Pontuação Laplaciana para cada recurso é calculada. Os menores valores determinam dimensões importantes. Implementação da partitura Laplaciana: scikit-feature.
Conclusão
A seleção de recursos no processo de aprendizado de máquina pode ser resumida como uma das etapas importantes para o desenvolvimento de qualquer modelo de aprendizado de máquina. O processo do algoritmo de seleção de características leva à redução da dimensionalidade dos dados com a remoção de características que não são relevantes ou importantes para o modelo em consideração. Recursos relevantes podem acelerar o tempo de treinamento dos modelos resultando em alto desempenho.
Se você estiver interessado em aprender mais sobre aprendizado de máquina, confira o Programa PG Executivo do IIIT-B e do upGrad em Machine Learning e IA, projetado para profissionais que trabalham e oferece mais de 450 horas de treinamento rigoroso, mais de 30 estudos de caso e atribuições, IIIT -B Alumni status, mais de 5 projetos práticos práticos e assistência de trabalho com as principais empresas.
Como o método de filtro é diferente do método wrapper?
O método wrapper ajuda a medir a utilidade dos recursos com base no desempenho do classificador. O método de filtro, por outro lado, avalia as qualidades intrínsecas dos recursos usando estatísticas univariadas em vez de desempenho de validação cruzada, o que implica que eles julgam a relevância dos recursos. Como resultado, o método wrapper é mais eficaz, pois otimiza o desempenho do classificador. No entanto, devido aos repetidos processos de aprendizado e validação cruzada, a técnica de wrapper é computacionalmente mais cara que o método de filtro.
O que é seleção direta sequencial no aprendizado de máquina?
É um tipo de seleção sequencial de recursos, embora seja muito mais caro do que a seleção de filtros. É uma técnica de busca gananciosa que seleciona recursos de forma iterativa com base no desempenho do classificador para descobrir o subconjunto de recursos ideal. Ele começa com um subconjunto de recursos vazio e continua a adicionar um recurso em cada rodada. Esse recurso é escolhido de um conjunto de todos os recursos que não estão em nosso subconjunto de recursos e é aquele que resulta no melhor desempenho do classificador quando combinado com os outros.
Quais são as limitações de usar o método de filtro para seleção de recursos?
A abordagem de filtro é computacionalmente mais barata do que os métodos de seleção de recursos incorporados e wrapper, mas tem algumas desvantagens. No caso de abordagens univariadas, essa estratégia frequentemente ignora a interdependência de recursos ao selecionar recursos e avalia cada recurso de forma independente. Quando comparado com os outros dois métodos de seleção de recursos, isso às vezes pode resultar em desempenho de computação ruim.