
Como meu site baseado em API me ajuda a viajar pelo mundo
Publicados: 2022-03-10(Este é um post patrocinado.) Recentemente, decidi reconstruir meu site pessoal, porque tinha seis anos e parecia – educadamente falando – um pouco “desatualizado”. O objetivo era incluir algumas informações sobre mim, uma área de blog, uma lista dos meus projetos paralelos recentes e eventos futuros.
Como eu trabalho com clientes de tempos em tempos, havia uma coisa com a qual eu não queria lidar – bancos de dados ! Anteriormente, eu construía sites WordPress para todos que queriam. A parte de programação geralmente era divertida para mim, mas os lançamentos, a mudança de bancos de dados para diferentes ambientes e a publicação real sempre eram irritantes. Provedores de hospedagem baratos só oferecem interfaces web ruins para configurar bancos de dados MySQL e um acesso FTP para fazer upload de arquivos sempre foi a pior parte. Eu não queria lidar com isso para o meu site pessoal.
Então, os requisitos que eu tinha para o redesenho eram:
- Uma pilha de tecnologia atualizada baseada em JavaScript e tecnologias front-end.
- Uma solução de gerenciamento de conteúdo para editar conteúdo de qualquer lugar.
- Um site de bom desempenho com resultados rápidos.
Neste artigo, quero mostrar o que construí e como meu site surpreendentemente acabou se tornando meu companheiro diário.
Definindo um modelo de conteúdo
Publicar coisas na web parece ser fácil. Escolha um sistema de gerenciamento de conteúdo (CMS) que forneça um editor WYSIWYG ( O que você vê ) para cada página necessária e todos os editores podem gerenciar o conteúdo facilmente. É isso, certo?
Depois de construir vários sites de clientes, desde pequenos cafés até startups em crescimento, descobri que o santo editor WYSIWYG nem sempre é a bala de prata que todos procuramos. Essas interfaces visam facilitar a construção de sites, mas aqui vem o ponto:
Construir sites não é fácil
Para construir e editar o conteúdo de um site sem quebrá-lo constantemente, você precisa ter um conhecimento profundo de HTML e pelo menos entender um pouco de CSS. Isso não é algo que você pode esperar de seus editores.
Já vi layouts complexos horríveis construídos com editores WYSIWYG e não posso começar a nomear todas as situações em que tudo desmorona porque o sistema é muito frágil. Essas situações levam a brigas e desconfortos onde todas as partes se culpam por algo que era inevitável. Sempre tentei evitar essas situações e criar ambientes confortáveis e estáveis para os editores evitarem e-mails irritados gritando “Socorro! Tudo está quebrado."
O conteúdo estruturado evita alguns problemas
Aprendi rapidamente que as pessoas raramente quebram as coisas quando divido todo o conteúdo do site necessário em vários pedaços, cada um relacionado entre si sem pensar em nenhuma representação. No WordPress, isso pode ser feito usando tipos de postagem personalizados. Cada tipo de postagem personalizado pode incluir várias propriedades com seu próprio campo de texto fácil de entender. Enterrei completamente o conceito de pensar em páginas .
Meu trabalho era conectar as partes de conteúdo e construir páginas da web a partir desses blocos de conteúdo. Isso significava que os editores só podiam fazer poucas, ou nenhuma, mudanças visuais em seus sites. Eles eram responsáveis pelo conteúdo e apenas pelo conteúdo. As mudanças visuais tiveram que ser feitas por mim - nem todos podiam estilizar o site e poderíamos evitar um ambiente frágil. Esse conceito parecia uma grande troca e geralmente era bem recebido.
Mais tarde, descobri que o que eu estava fazendo era definir um modelo de conteúdo. Rachel Lovinger define, em seu excelente artigo “Content Modelling: A Master Skill”, um modelo de conteúdo da seguinte forma:
“Um modelo de conteúdo documenta todos os diferentes tipos de conteúdo que você terá para um determinado projeto. Ele contém definições detalhadas dos elementos de cada tipo de conteúdo e seus relacionamentos entre si.”
Começar com a modelagem de conteúdo funcionou bem para a maioria dos clientes, exceto para um.
“Stefan, não estou definindo seu esquema de banco de dados!”
A ideia deste projeto era construir um site enorme que deveria criar muito tráfego orgânico, fornecendo toneladas de conteúdo – em todas as variações exibidas em várias páginas e locais diferentes. Marquei uma reunião para discutir nossa estratégia para abordar esse projeto.
Eu queria definir todas as páginas e modelos de conteúdo que deveriam ser incluídos. Não importava o pequeno widget ou a barra lateral que o cliente tinha em mente, eu queria que fosse claramente definido. Meu objetivo era criar uma estrutura de conteúdo sólida que tornasse possível fornecer uma interface fácil de usar para os editores e fornecer dados reutilizáveis para exibi-los em qualquer formato imaginável.
Acontece que a ideia deste projeto não era muito clara e eu não conseguia obter respostas para todas as minhas perguntas. O líder do projeto não entendeu que deveríamos começar com a modelagem de conteúdo adequada (não design e desenvolvimento). Para ele, isso era apenas uma tonelada de páginas. Conteúdo duplicado e grandes áreas de texto para adicionar uma enorme quantidade de texto, não parecem ser um problema. Em sua mente, as perguntas que eu tinha sobre estrutura eram técnicas, e eles não deveriam se preocupar com elas. Para encurtar a história, eu não fiz o projeto.
O importante é que a modelagem de conteúdo não é sobre bancos de dados.
Trata-se de tornar seu conteúdo acessível e à prova de futuro. Se você não conseguir definir as necessidades do seu conteúdo no início do projeto, será muito difícil, se não impossível, reutilizá-lo mais tarde.
A modelagem de conteúdo adequada é a chave para sites atuais e futuros.
Contentful: Um CMS Headless
Ficou claro que eu queria seguir uma boa modelagem de conteúdo para o meu site também. No entanto, havia mais uma coisa. Eu não queria lidar com a camada de armazenamento para construir meu novo site, então decidi usar o Contentful, um CMS headless, no qual estou trabalhando atualmente. “Headless” significa que este serviço oferece uma interface web para gerenciar o conteúdo na nuvem e fornece uma API que me devolverá meus dados no formato JSON. Escolher este CMS me ajudou a ser produtivo imediatamente, pois eu tinha uma API disponível em minutos e não precisei lidar com nenhuma configuração de infraestrutura. Contentful também fornece um plano gratuito que é perfeito para pequenos projetos, como meu site pessoal.
Um exemplo de consulta para obter todas as postagens do blog é assim:
<a href="https://cdn.contentful.com/spaces/space_id/entries?access_token=access_token&content_type=post">https://cdn.contentful.com/spaces/space_id/entries?access_token=access_token&content_type=post</a>E a resposta, em uma versão abreviada, fica assim:
{ "sys": { "type": "Array" }, "total": 7, "skip": 0, "limit": 100, "items": [ { "sys": { "space": {...}, "id": "455OEfg1KUskygWUiKwmkc", "type": "Entry", "createdAt": "2016-07-29T11:53:52.596Z", "updatedAt": "2016-11-09T21:07:19.118Z", "revision": 12, "contentType": {...}, "locale": "en-US" }, "fields": { "title": "How to React to Changing Environments Using matchMedia", "excerpt": "...", "slug": "how-to-react-to-changing-environments-using-match-media", "author": [...], "body": "...", "date": "2014-12-26T00:00+02:00", "comments": true, "externalUrl": "https://4waisenkinder.de/blog/2014/12/26/handle-environment-changes-via-window-dot-matchmedia/" }, {...}, {...}, {...}, {...}, {...}, {...} ] } }A grande parte do Contentful é que ele é ótimo em modelagem de conteúdo, o que eu precisava. Usando a interface da web fornecida, posso definir rapidamente todas as partes de conteúdo necessárias. A definição de um modelo de conteúdo específico no Contentful é chamada de tipo de conteúdo. Uma grande coisa a destacar aqui é a capacidade de modelar relacionamentos entre itens de conteúdo. Por exemplo, posso conectar facilmente um autor a uma postagem de blog. Isso pode resultar em árvores de dados estruturadas, perfeitas para serem reutilizadas em vários casos de uso.
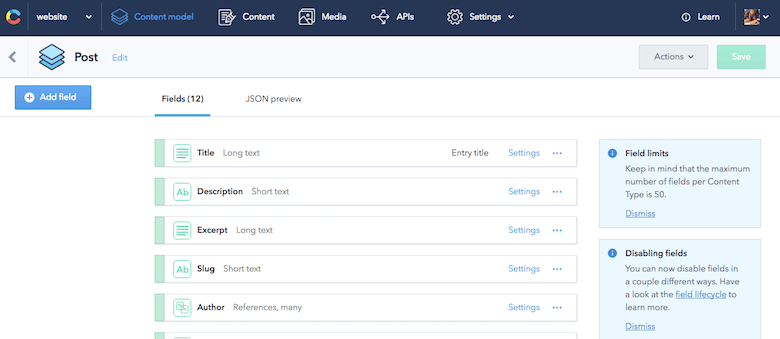
Então, eu configuro meu modelo de conteúdo sem pensar em nenhuma página que eu queira construir no futuro.
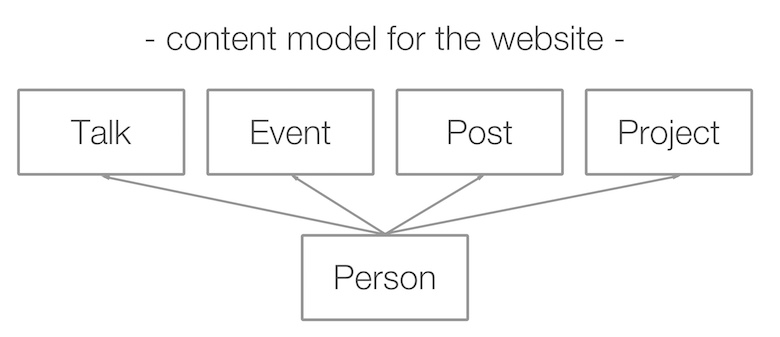
O próximo passo foi descobrir o que eu queria fazer com esses dados. Perguntei a um designer que eu conhecia, e ele veio com uma página de índice do site com a seguinte estrutura.
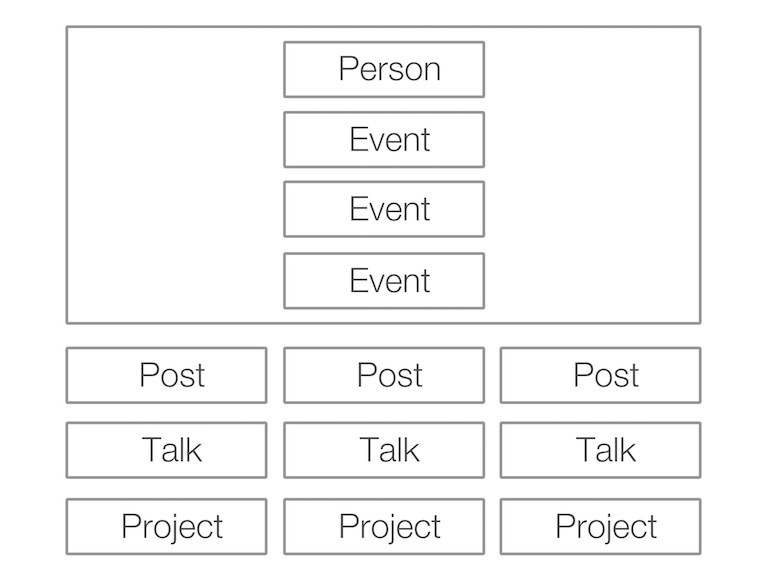
Renderizando páginas HTML usando Node.js
Agora veio a parte complicada. Até agora, não precisei lidar com armazenamento e bancos de dados, o que foi uma grande conquista para mim. Então, como posso construir meu site quando tenho apenas uma API disponível?
Minha primeira abordagem foi a abordagem do-it-yourself. Comecei a escrever um script Node.js simples que recuperava os dados e renderizava um pouco de HTML a partir deles.
A renderização inicial de todos os arquivos HTML atendeu a um dos meus principais requisitos. HTML estático pode ser servido muito rápido.
Então, vamos dar uma olhada no script que usei.
'use strict'; const contentful = require('contentful'); const template = require('lodash.template'); const fs = require('fs'); // create contentful client with particular credentials const client = contentful.createClient({ space: 'your_space_id', accessToken: 'your_token' }); // cache templates to not read // them over and over again const TEMPLATES = { index : template(fs.readFileSync(`${__dirname}/templates/index.html`)) }; // fetch all the data Promise.all([ // get posts client.getEntries({content_type: 'content_type_post_id'}), // get events client.getEntries({content_type: 'content_type_event_id'}), // get projects client.getEntries({content_type: 'content_type_project_id'}), // get talk client.getEntries({content_type: 'content_type_talk_id'}), // get specific person client.getEntries({'sys.id': 'person_id'}) ]) .then(([posts, events, projects, talks, persons]) => { const renderedHTML = TEMPLATES.index({ posts, events, projects, talks, person : persons.items[0] }) fs.writeFileSync(`${__dirname}/build/index.html`, renderedHTML); console.log('Rendered HTML'); }) .catch(console.error); <!doctype html> <html lang="en"> <head> <!-- ... --> </head> <body> <!-- ... --> <h2>Posts</h2> <ul> <% posts.items.forEach( function( talk ) { %> <li><%- talk.fields.title %> <% }) %> </ul> <!-- ... --> </body> </html>Isso funcionou bem. Eu poderia construir meu site desejado de uma maneira completamente flexível, tomando todas as decisões sobre a estrutura e funcionalidade do arquivo. Renderizar diferentes tipos de página com conjuntos de dados completamente diferentes não foi problema algum. Todo mundo que lutou contra as regras e a estrutura de um CMS existente que vem com renderização HTML sabe que liberdade total pode ser uma coisa excelente. Especialmente, quando o modelo de dados se torna mais complexo ao longo do tempo, incluindo muitas relações, a flexibilidade compensa.
Neste script Node.js, um cliente Contentful SDK é criado e todos os dados são buscados usando o método cliente getEntries . Todos os métodos fornecidos do cliente são orientados a promessas, o que facilita evitar retornos de chamada profundamente aninhados. Para modelagem, decidi usar o mecanismo de modelagem do lodash. Por fim, para leitura e gravação de arquivos, o Node.js oferece o módulo fs nativo, que é usado para ler os modelos e gravar o HTML renderizado.
No entanto, havia uma desvantagem nessa abordagem; era muito básico. Mesmo quando esse método era completamente flexível, parecia reinventar a roda. O que eu estava construindo era basicamente um gerador de site estático, e já existem muitos deles por aí. Era hora de começar tudo de novo.
Indo para um gerador de site estático real
Geradores de sites estáticos famosos, por exemplo, Jekyll ou Middleman, geralmente lidam com arquivos Markdown que serão renderizados para HTML. Os editores trabalham com isso e o site é construído usando um comando CLI. Essa abordagem estava falhando em um dos meus requisitos iniciais, no entanto. Eu queria poder editar o site onde quer que estivesse, sem depender de arquivos armazenados em meu computador particular.

Minha primeira ideia foi renderizar esses arquivos Markdown usando a API. Embora isso tivesse funcionado, não parecia certo. Renderizar arquivos Markdown para transformar em HTML mais tarde ainda eram duas etapas que não ofereciam um grande benefício em comparação com minha solução inicial.
Felizmente, existem integrações Contentful, por exemplo, Metalsmith e Middleman. Eu decidi pelo Metalsmith para este projeto, já que está escrito em Node.js e eu não queria trazer uma dependência Ruby.
O Metalsmith transforma arquivos de uma pasta de origem e os renderiza em uma pasta de destino. Esses arquivos não precisam necessariamente ser arquivos Markdown. Você também pode usá-lo para transpilar Sass ou otimizar suas imagens. Não há limites, e é realmente flexível.
Usando a integração Contentful, consegui definir alguns arquivos de origem que foram tomados como arquivos de configuração e, então, pude buscar tudo o que precisava da API.
--- title: Blog contentful: content_type: content_type_id entry_filename_pattern: ${ fields.slug } entry_template: article.html order: '-fields.date' filter: include: 5 layout: blog.html description: >- Recent articles by Stefan Judis. --- Esta configuração de exemplo renderiza a área de postagem do blog com um arquivo blog.html pai, incluindo a resposta da solicitação da API, mas também renderiza várias páginas filhas usando o modelo article.html . Os nomes dos arquivos para as páginas filhas são definidos por meio entry_filename_pattern .
Como você vê, com algo assim, posso construir minhas páginas facilmente. Essa configuração funcionou perfeitamente para garantir que todas as páginas dependessem da API.
Conecte o serviço ao seu projeto
A única parte que faltava era conectar o site com o serviço CMS e torná-lo renderizado novamente quando qualquer conteúdo fosse editado. A solução para esse problema — webhooks, com os quais você já deve estar familiarizado se estiver usando serviços como o GitHub.
Webhooks são solicitações feitas por software como serviço para um endpoint previamente definido que o notifica de que algo aconteceu. O GitHub, por exemplo, pode enviar um ping para você quando alguém abre uma pull request em um de seus repositórios. Em relação ao gerenciamento de conteúdo, podemos aplicar o mesmo princípio aqui. Sempre que algo acontecer com o conteúdo, faça ping em um endpoint e faça um ambiente específico reagir a ele. No nosso caso, isso significaria renderizar novamente o HTML usando o metalsmith.
Para aceitar webhooks eu também fui com uma solução JavaScript. Meu provedor de hospedagem de escolha (Uberspace) torna possível instalar o Node.js e usar JavaScript no lado do servidor.
const http = require('http'); const exec = require('child_process').exec; const server = http.createServer((req, res) => { res.setHeader('Content-Type', 'text/plain'); // check for secret header // to not open up this endpoint for everybody if (req.headers.secret === 'YOUR_SECRET') { res.end('ok'); // wait for the CDN to // invalidate the data setTimeout(() => { // execute command exec('npm start', { cwd: __dirname }, (error) => { if (error) { return console.log(error); } console.log('Rebuilt success'); }); }, 1000 * 120 ); } else { res.end('Not allowed'); } }); console.log('Started server at 8000'); server.listen(8000); Esses scripts iniciam um servidor HTTP simples na porta 8000. Ele verifica as solicitações recebidas por um cabeçalho adequado para garantir que seja o webhook do Contentful. Se a solicitação for confirmada como o webhook, o comando predefinido npm start será executado para renderizar novamente todas as páginas HTML. Você pode se perguntar por que há um tempo limite no local. Isso é necessário para pausar as ações por um momento até que os dados na nuvem sejam invalidados porque os dados armazenados são fornecidos a partir de um CDN.
Dependendo do seu ambiente, este servidor HTTP pode não estar acessível à Internet. Meu site é servido usando um servidor apache, então eu precisava adicionar uma regra de reescrita interna para tornar o servidor do nó em execução acessível à Internet.
# add node endpoint to enable webhooks RewriteRule ^rerender/(.*) https://localhost:8000/$1 [P]Dados estruturados e em primeiro lugar na API: melhores amigos para sempre
Nesse ponto, consegui gerenciar todos os meus dados na nuvem e meu site reagiria adequadamente após as alterações.
Repetição em todo o lugar
Estar na estrada é uma parte importante da minha vida, então era necessário ter informações, como a localização de um determinado local ou qual hotel eu reservei, na ponta dos dedos – geralmente armazenadas em uma planilha do Google. Agora, as informações estavam espalhadas por uma planilha, vários e-mails, minha agenda, além do meu site.
Eu tive que admitir, criei muita duplicação de dados no meu fluxo diário.
O momento dos dados estruturados
Sonhei com uma única fonte de verdade (de preferência no meu telefone) para ver rapidamente quais eventos estavam chegando, mas também obter informações adicionais sobre hotéis e locais. Os eventos listados no meu site não tinham todas as informações neste momento, mas é muito fácil adicionar novos campos a um tipo de conteúdo no Contentful. Então, adicionei os campos necessários ao tipo de conteúdo “Evento”.
Colocar essas informações no CMS do meu site nunca foi minha intenção, pois não deveria ser exibida online, mas tê-las acessível por meio de uma API me fez perceber que agora eu poderia fazer coisas completamente diferentes com esses dados.
Construindo um aplicativo nativo com JavaScript
A criação de aplicativos para dispositivos móveis é um tópico há anos e há várias abordagens para isso. Progressive Web Apps (PWA) são um tópico especialmente quente nos dias de hoje. Usando Service Workers e um Web App Manifest, é possível criar experiências completas semelhantes a aplicativos, desde um ícone da tela inicial até o comportamento offline gerenciado usando tecnologias da Web.
Há uma desvantagem a mencionar. Os Progressive Web Apps estão em ascensão, mas ainda não estão completamente lá. Service Workers, por exemplo, não são suportados no Safari hoje e apenas “sob consideração” do lado da Apple até agora. Isso foi um fator decisivo para mim, pois eu também queria ter um aplicativo compatível com offline nos iPhones.
Então procurei alternativas. Um amigo meu gostava muito de NativeScript e ficava me contando sobre essa tecnologia relativamente nova. NativeScript é uma estrutura de código aberto para criar aplicativos móveis realmente nativos com JavaScript, então decidi experimentá-lo.
Conhecendo o NativeScript
A configuração do NativeScript demora um pouco porque você precisa instalar muitas coisas para desenvolver para ambientes móveis nativos. Você será guiado pelo processo de instalação ao instalar a ferramenta de linha de comando NativeScript pela primeira vez usando npm install nativescript -g .
Em seguida, você pode usar comandos de andaimes para configurar novos projetos: tns create MyNewApp
No entanto, não foi isso que eu fiz. Eu estava examinando a documentação e me deparei com um aplicativo de gerenciamento de compras de amostra construído em NativeScript. Então peguei este aplicativo, mergulhei no código e o modifiquei passo a passo, ajustando-o às minhas necessidades.
Eu não quero mergulhar muito fundo no processo, mas para construir uma lista com todas as informações que eu queria, não demorou muito.
O NativeScript funciona muito bem junto com o Angular 2, que eu não queria tentar desta vez, pois descobrir o próprio NativeScript parecia grande o suficiente. No NativeScript, você deve escrever "Visualizações". Cada visualização consiste em um arquivo XML que define o layout base e JavaScript e CSS opcionais. Todos estes são definidos em uma pasta por visualização.
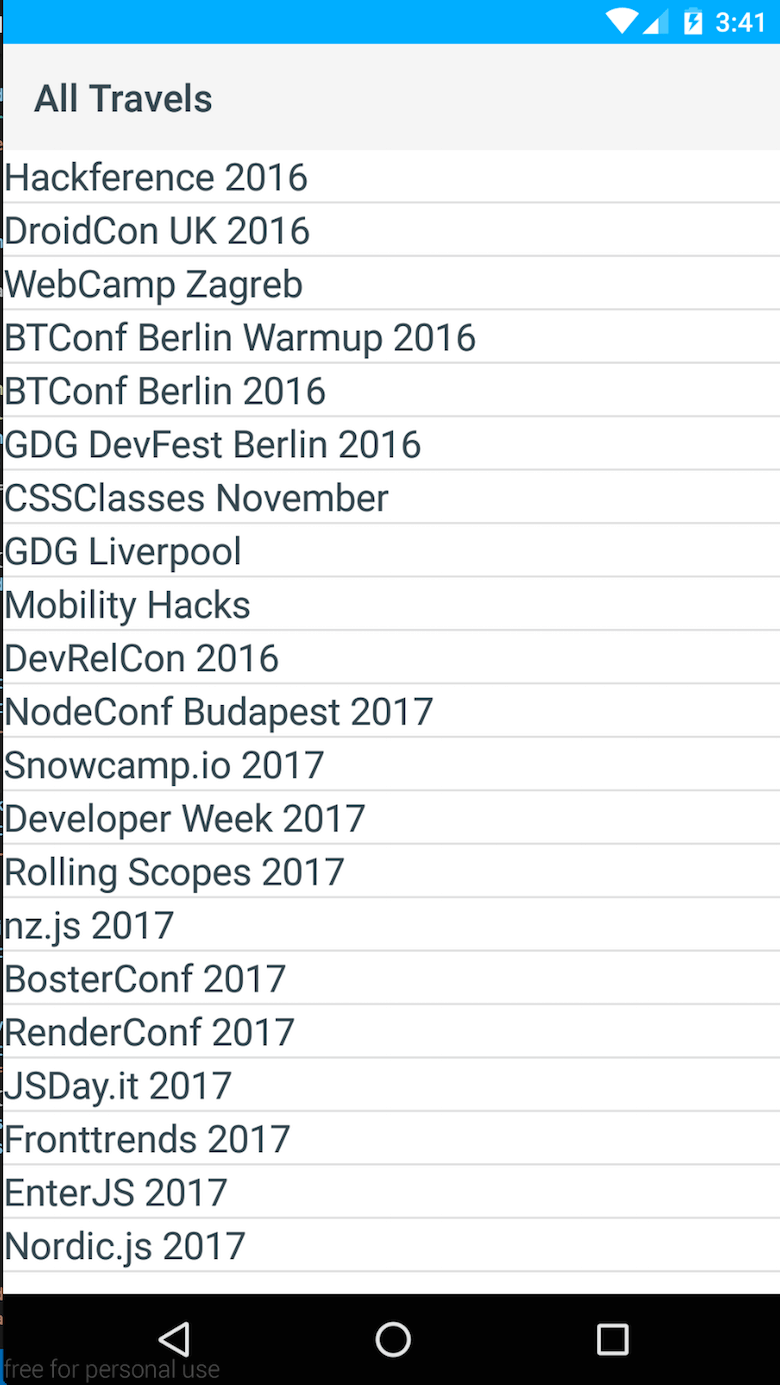
A renderização de uma lista simples pode ser obtida com um modelo XML como este:
<!-- call JavaScript function when ready --> <Page loaded="loaded"> <ActionBar title="All Travels" /> <!-- make it scrollable when going too big --> <ScrollView> <!-- iterate over the entries in context --> <ListView items="{{ entries }}"> <ListView.itemTemplate> <Label text="{{ fields.name }}" textWrap="true" class="headline"/> </ListView.itemTemplate> </ListView> </ScrollView> </Page> A primeira coisa que acontece aqui é definir um elemento de página. Dentro desta página, defini uma ActionBar para dar a aparência clássica do Android, bem como um título adequado. Construir coisas para ambientes nativos pode ser um pouco complicado às vezes. Por exemplo, para obter o comportamento de rolagem de trabalho, você deve usar um 'ScrollView.' A última coisa é, então, simplesmente iterar sobre meus eventos usando um ListView . No geral, parecia bastante simples!
Mas de onde vêm essas entradas que são usadas na exibição? Acontece que existe um objeto de contexto compartilhado que pode ser usado para isso. Ao ler o XML para a visualização, você já deve ter notado que a página possui um conjunto de atributos loaded . Ao definir esse atributo, digo à exibição para chamar uma função JavaScript específica quando a página for carregada.
Essa função JavaScript é definida no arquivo JS dependente. Ele pode ser acessado simplesmente exportando-o usando exports.something . Para adicionar a vinculação de dados, tudo o que precisamos fazer é definir um novo Observable para a propriedade de página bindingContext . Observables em NativeScript emitem eventos propertyChange que são necessários para reagir a mudanças de dados dentro das 'exibições, mas você não precisa se preocupar com isso, pois funciona fora da caixa.
const context = new Observable({ entries: null}); const fetchModule = require('fetch'); // export loaded to be called from // List.xml when everything is loaded exports.loaded = (args) => { const page = args.object; page.bindingContext = context; fetchModule.fetch( `https://cdn.contentful.com/spaces/${config.space}/entries?access_token=${config.cda.token}&content_type=event&order=fields.start`, { method: "GET", headers: { 'Content-Type': 'application/json' } } ) .then(response => response.json()) .then(response => context.set('entries', response.items)); } A última coisa é buscar os dados e configurá-los no contexto. Isso pode ser feito usando o módulo de fetch NativeScript. Aqui, você pode ver o resultado.
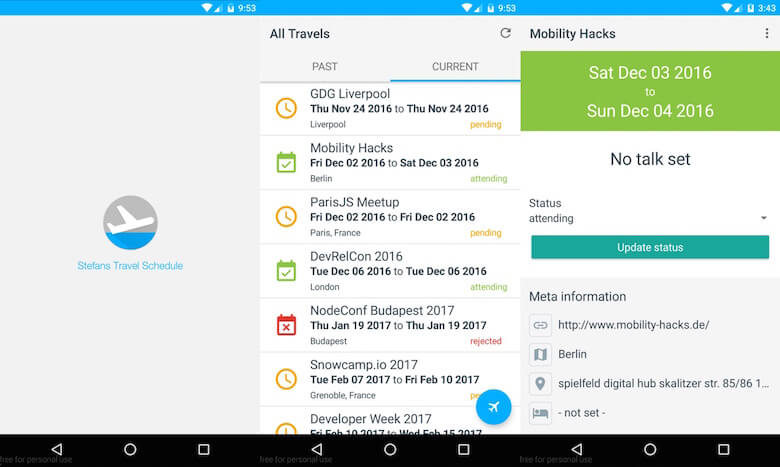
Então, como você pode ver, construir uma lista simples usando NativeScript não é muito difícil. Mais tarde, estendi o aplicativo com outra visualização, bem como funcionalidades adicionais para abrir determinados endereços no Google Maps e visualizações da Web para visualizar os sites do evento.
Uma coisa a destacar aqui é que o NativeScript ainda é bem novo, o que significa que os plugins encontrados no npm geralmente não possuem muitos downloads ou estrelas no GitHub. Isso me irritou no começo, mas eu usei vários componentes nativos (nativescript-floatingactionbutton, nativescript-advanced-webview e nativescript-pulltorefresh) que me ajudaram a obter uma experiência nativa e tudo funcionou perfeitamente bem.
Você pode ver o resultado melhorado aqui:
Quanto mais funcionalidades eu colocava neste aplicativo, mais eu gostava dele e mais eu o usava. A melhor parte é que eu poderia me livrar da duplicação de dados, gerenciando todos os dados em um só lugar, sendo flexível o suficiente para exibi-los para vários casos de uso.
As páginas são ontem: Viva o conteúdo estruturado!
Construir este aplicativo me mostrou mais uma vez que o princípio de ter dados em formato de página é coisa do passado. Não sabemos para onde nossos dados irão — precisamos estar prontos para um número ilimitado de casos de uso.
Olhando para trás, o que eu consegui é:
- Ter um sistema de gerenciamento de conteúdo na nuvem
- Não ter que lidar com a manutenção do banco de dados
- Uma pilha de tecnologia JavaScript completa
- Ter um site estático eficiente
- Ter um aplicativo Android para acessar meu conteúdo sempre e em qualquer lugar
E a parte mais importante:
Ter meu conteúdo estruturado e acessível me ajudou a melhorar meu dia a dia.
Esse caso de uso pode parecer trivial para você agora, mas quando você pensa nos produtos que cria todos os dias, sempre há mais casos de uso para seu conteúdo em diferentes plataformas. Hoje, aceitamos que os dispositivos móveis estão finalmente ultrapassando os ambientes de desktop da velha escola, mas plataformas como carros, relógios e até geladeiras já estão esperando por seus holofotes. Não consigo nem pensar nos casos de uso que virão.
Então, vamos tentar estar prontos e colocar conteúdo estruturado no meio, porque no final não se trata de esquemas de banco de dados – trata-se de construir para o futuro.
Leitura adicional no SmashingMag:
- Raspagem da Web com Node.js
- Navegando com Sails.js: uma estrutura de estilo MVC para Node.js
- 40 ícones de viagem para enfeitar seus designs
- Uma introdução detalhada ao Webpack