
Os 10 principais comandos do Hadoop [com usos]
Publicados: 2021-01-29Nesta era, com enormes blocos de dados, torna-se essencial lidar com eles. Os dados provenientes de organizações com clientes em crescimento são muito maiores do que qualquer ferramenta tradicional de gerenciamento de dados pode armazenar. Isso nos deixa com a questão de gerenciar conjuntos maiores de dados, que podem variar de gigabytes a petabytes, sem usar um único computador grande ou ferramenta tradicional de gerenciamento de dados.
É aqui que o framework Apache Hadoop chama a atenção. Antes de mergulhar na implementação do comando do Hadoop, vamos compreender brevemente a estrutura do Hadoop e sua importância.
Índice
O que é Hadoop?
O Hadoop é comumente usado por grandes organizações empresariais para resolver vários problemas, desde o armazenamento de grandes GBs (Gigabytes) de dados todos os dias até operações de computação nos dados.
Tradicionalmente definido como uma estrutura de software de código aberto usada para armazenar dados e aplicativos de processamento, o Hadoop se destaca bastante da maioria das ferramentas tradicionais de gerenciamento de dados. Ele melhora o poder de computação e estende o limite de armazenamento de dados adicionando alguns nós na estrutura, tornando-a altamente escalável. Além disso, seus dados e processos de aplicativos são protegidos contra várias falhas de hardware.
O Hadoop segue uma arquitetura mestre-escravo para distribuir e armazenar dados usando MapReduce e HDFS. Conforme ilustrado na figura abaixo, a arquitetura é adaptada de uma maneira definida para realizar operações de gerenciamento de dados usando quatro nós primários, a saber, Nome, Dados, Mestre e Escravo. Os componentes principais do Hadoop são construídos diretamente sobre a estrutura. Outros componentes integram-se diretamente com os segmentos.
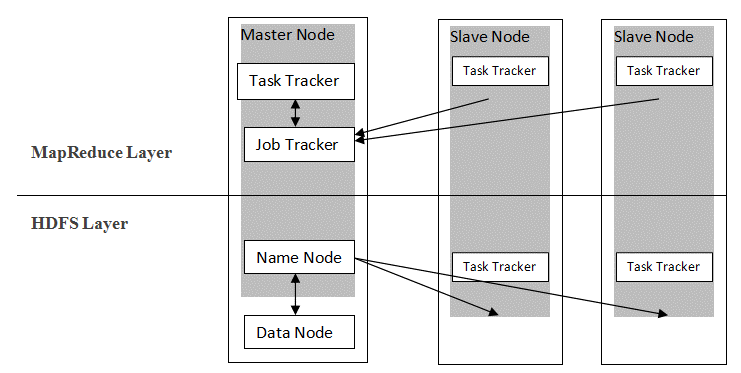 Fonte
Fonte

Comandos do Hadoop
Os principais recursos da estrutura do Hadoop mostram uma natureza coerente e se tornam mais fáceis de usar quando se trata de gerenciar big data com o aprendizado de comandos do Hadoop. Abaixo estão alguns comandos Hadoop convenientes que permitem realizar várias operações, como gerenciamento e processamento de arquivos de clusters HDFS. Essa lista de comandos é frequentemente necessária para alcançar determinados resultados do processo.
1. Hadoop Touchz
hadoop fs -touchz /diretório/nome do arquivo
Este comando permite que o usuário crie um novo arquivo no cluster HDFS. O “diretório” no comando refere-se ao nome do diretório onde o usuário deseja criar o novo arquivo, e o “nome do arquivo” significa o nome do novo arquivo que será criado após a conclusão do comando.
2. Comando de teste do Hadoop
hadoop fs -test -[defsz] <caminho>
Esse comando específico atende ao propósito de testar a existência de um arquivo no cluster HDFS. Os caracteres de “[defsz]” no comando devem ser modificados conforme necessário. Aqui está uma breve descrição desses personagens:
- d -> Verifica se é um diretório ou não
- e -> Verifica se é um caminho ou não
- f -> Verifica se é um arquivo ou não
- s -> Verifica se é um caminho vazio ou não
- r -> Verifica a existência do caminho e a permissão de leitura
- w -> Verifica a existência do caminho e permissão de gravação
- z -> Verifica o tamanho do arquivo
3. Comando de texto do Hadoop
hadoop fs -texto <src>
O comando text é particularmente útil para exibir o arquivo zip alocado em formato de texto. Ele opera processando arquivos de origem e fornecendo seu conteúdo em um formato de texto decodificado simples.

4. Comando Localizar Hadoop
hadoop fs -find <caminho> … <expressão>
Esse comando geralmente é usado para pesquisar arquivos no cluster HDFS. Ele verifica a expressão fornecida no comando com todos os arquivos no cluster e exibe os arquivos que correspondem à expressão definida.
Leia: Principais ferramentas do Hadoop
5. Comando Getmerge do Hadoop
hadoop fs -getmerge <src> <localdest>
O comando Getmerge permite mesclar um ou vários arquivos em um diretório designado no cluster do sistema de arquivos HDFS. Ele acumula os arquivos em um único arquivo localizado no sistema de arquivos local. O “src” e “localdest” representam o significado de origem-destino e destino local.
6. Comando de contagem de Hadoop
hadoop fs -count [opções] <caminho>
Tão óbvio quanto seu nome, o comando Hadoop count conta o número de arquivos e bytes em um determinado diretório. Existem várias opções disponíveis que modificam a saída de acordo com o requisito. Estes são os seguintes:
- q -> quota mostra o limite do número total de nomes e uso de espaço
- u -> exibe apenas cota e uso
- h -> dá o tamanho de um arquivo
- v -> exibe o cabeçalho
7. Comando AppendToFile do Hadoop
hadoop fs -appendToFile <localsrc> <dest>
Ele permite que o usuário anexe o conteúdo de um ou vários arquivos em um único arquivo no arquivo de destino especificado no cluster do sistema de arquivos HDFS. Na execução deste comando, os arquivos de origem fornecidos são anexados à origem de destino de acordo com o nome de arquivo fornecido no comando.
8. Comando Hadoop ls
hadoop fs -ls /caminho
O comando ls no Hadoop mostra a lista de arquivos/conteúdos em um diretório especificado, ou seja, caminho. Ao adicionar “R” antes de /path, a saída mostrará detalhes do conteúdo, como nomes, tamanho, proprietário e assim por diante para cada arquivo especificado no diretório fornecido.
9. Comando Hadoop mkdir
hadoop fs -mkdir /path/directory_name
O recurso exclusivo desse comando é a criação de um diretório no cluster do sistema de arquivos HDFS se o diretório não existir. Além disso, se o diretório especificado estiver presente, a mensagem de saída mostrará um erro indicando a existência do diretório.
10. Comando chmod do Hadoop
hadoop fs -chmod [-R] <modo> <caminho>
Este comando é utilizado quando há necessidade de alterar as permissões de acesso a um determinado arquivo. Ao dar o comando chmod, a permissão do arquivo especificado é alterada. No entanto, é importante lembrar que a permissão será modificada quando o proprietário do arquivo executar este comando.
Leia também: Tutorial do Impala Hadoop
Conclusão
Começando com a importante questão de armazenamento de dados enfrentada pelas principais organizações no mundo de hoje, este artigo discutiu a solução para armazenamento de dados limitado apresentando o Hadoop e seu impacto na realização de operações de gerenciamento de dados usando comandos do Hadoop. Para iniciantes no Hadoop, uma visão geral da estrutura é descrita juntamente com seus componentes e arquitetura.

Depois de ler este artigo, pode-se facilmente se sentir confiante sobre seu conhecimento no aspecto da estrutura do Hadoop e seus comandos aplicados. Certificação PG exclusiva do upGrad em Big Data: upGrad oferece um programa de 7,5 meses específico do setor para Certificação PG em Big Data, onde você organizará, analisará e interpretará Big Data com o IIIT-Bangalore.
Projetado cuidadosamente para profissionais que trabalham, ajudará os alunos a obter conhecimento prático e promover sua entrada em funções de Big Data.
Destaques do programa:
- Aprender linguagens e ferramentas relevantes
- Aprendendo conceitos avançados de Programação Distribuída, Plataformas de Big Data, Banco de Dados, Algoritmos e Web Mining
- Um certificado acreditado do ITT Bangalore
- Assistência de colocação para ser absorvido pelas principais multinacionais
- Mentoria 1:1 para acompanhar seu progresso e ajudá-lo em todos os pontos
- Trabalhando em projetos e tarefas ao vivo
Elegibilidade : Conhecimento em matemática/engenharia de software/estatística/análise
Confira nossos outros Cursos de Engenharia de Software no upGrad.