
Uma cartilha do GraphQL: a evolução do design de API (parte 2)
Publicados: 2022-03-10Na Parte 1, vimos como as APIs evoluíram nas últimas décadas e como cada uma deu lugar à seguinte. Também falamos sobre algumas das desvantagens específicas do uso de REST para desenvolvimento de clientes móveis. Neste artigo, quero ver para onde o design da API do cliente móvel parece estar indo – com ênfase particular no GraphQL.
Existem, é claro, muitas pessoas, empresas e projetos que tentaram resolver as deficiências do REST ao longo dos anos: HAL, Swagger/OpenAPI, OData JSON API e dezenas de outros projetos menores ou internos procuraram trazer ordem ao mundo de REST sem especificações. Em vez de pegar o mundo como ele é e propor melhorias incrementais, ou tentar juntar peças díspares suficientes para transformar o REST no que eu preciso, eu gostaria de tentar um experimento mental. Dada a compreensão das técnicas que funcionaram e não funcionaram no passado, gostaria de usar as restrições de hoje e nossas linguagens imensamente mais expressivas para tentar esboçar a API que queremos. Vamos trabalhar a partir da experiência do desenvolvedor para trás, em vez da implementação para a frente (estou olhando para você SQL).
Tráfego HTTP mínimo
Sabemos que o custo de cada solicitação de rede (HTTP/1) é alto em algumas medidas, desde a latência até a duração da bateria. Idealmente, os clientes de nossa nova API precisarão de uma maneira de solicitar todos os dados de que precisam no menor número possível de viagens de ida e volta.
Cargas Mínimas
Também sabemos que o cliente médio tem recursos limitados, em largura de banda, CPU e memória, portanto, nosso objetivo deve ser enviar apenas as informações de que nosso cliente precisa. Para fazer isso, provavelmente precisaremos de uma maneira para o cliente solicitar dados específicos.
Legível para humanos
Aprendemos com os dias do SOAP que uma API não é fácil de interagir, as pessoas vão fazer caretas com sua menção. As equipes de engenharia querem usar as mesmas ferramentas nas quais confiamos há anos, como curl , wget e Charles e a guia de rede de nossos navegadores.
Rico em ferramentas
Outra coisa que aprendemos com XML-RPC e SOAP é que os contratos cliente/servidor e os sistemas de tipos, em particular, são incrivelmente úteis. Se possível, qualquer nova API teria a leveza de um formato como JSON ou YAML com a capacidade de introspecção de contratos mais estruturados e de tipo seguro.
Preservação do Raciocínio Local
Ao longo dos anos, chegamos a um acordo sobre alguns princípios orientadores sobre como organizar grandes bases de código - o principal deles é a "separação de interesses". Infelizmente para a maioria dos projetos, isso tende a quebrar na forma de uma camada centralizada de acesso a dados. Se possível, diferentes partes de um aplicativo devem ter a opção de gerenciar suas próprias necessidades de dados junto com outras funcionalidades.
Como estamos projetando uma API centrada no cliente, vamos começar com a aparência de buscar dados em uma API como esta. Se sabemos que precisamos fazer viagens de ida e volta mínimas e que precisamos filtrar os campos que não queremos, precisamos de uma maneira de percorrer grandes conjuntos de dados e solicitar apenas as partes que são útil para nós. Uma linguagem de consulta parece se encaixar bem aqui.
Não precisamos fazer perguntas sobre nossos dados da mesma forma que você faz com um banco de dados, então uma linguagem imperativa como SQL parece ser a ferramenta errada. Na verdade, nossos principais objetivos são atravessar relacionamentos pré-existentes e limitar campos que devemos ser capazes de fazer com algo relativamente simples e declarativo. A indústria estabeleceu muito bem o JSON para dados não binários, então vamos começar com uma linguagem de consulta declarativa semelhante a JSON. Devemos ser capazes de descrever os dados de que precisamos e o servidor deve retornar JSON contendo esses campos.

Uma linguagem de consulta declarativa atende ao requisito para cargas mínimas e tráfego HTTP mínimo, mas há outro benefício que nos ajudará com outro de nossos objetivos de design. Muitas linguagens declarativas, de consulta e outras, podem ser manipuladas de forma eficiente como se fossem dados. Se projetarmos com cuidado, nossa linguagem de consulta permitirá que os desenvolvedores separem grandes solicitações e as recombinem de qualquer maneira que faça sentido para seu projeto. Usar uma linguagem de consulta como essa nos ajudaria a avançar em direção ao nosso objetivo final de Preservação do Raciocínio Local.
Há muitas coisas interessantes que você pode fazer quando suas consultas se tornarem “dados”. Por exemplo, você pode interceptar todas as solicitações e agrupá-las de maneira semelhante à forma como um DOM virtual agrupa as atualizações do DOM, você também pode usar um compilador para extrair as pequenas consultas em tempo de compilação para pré-armazenar os dados ou criar um sistema de cache sofisticado como Apollo Cache.
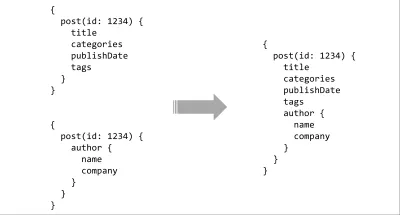
O item final da lista de desejos da API é o ferramental. Já obtemos um pouco disso usando uma linguagem de consulta, mas o verdadeiro poder vem quando você o emparelha com um sistema de tipos. Com um esquema digitado simples no servidor, há possibilidades quase infinitas de ferramentas ricas. As consultas podem ser analisadas estaticamente e validadas em relação ao contrato, as integrações de IDE podem fornecer dicas ou preenchimento automático, os compiladores podem fazer otimizações de tempo de construção para consultas ou vários esquemas podem ser unidos para formar uma superfície de API contígua.

Projetar uma API que combine uma linguagem de consulta e um sistema de tipos pode parecer uma proposta dramática, mas as pessoas vêm experimentando isso, de várias formas, há anos. O XML-RPC pressionou por respostas digitadas em meados dos anos 90 e seu sucessor, SOAP, dominou por anos! Mais recentemente, há coisas como a abstração do MongoDB do Meteor, o Horizon do RethinkDB (RIP), o incrível Falcor do Netflix que eles usam para o Netflix.com há anos e, por último, o GraphQL do Facebook. Para o resto deste ensaio, estarei focado no GraphQL, pois, enquanto outros projetos como o Falcor estão fazendo coisas semelhantes, o mindshare da comunidade parece favorecê-lo esmagadoramente.
O que é GraphQL?
Primeiro, devo dizer que menti um pouco. A API que construímos acima foi o GraphQL. O GraphQL é apenas um sistema de tipos para seus dados, uma linguagem de consulta para percorrê-los - o resto é apenas detalhes. No GraphQL, você descreve seus dados como um gráfico de interconexões e seu cliente solicita especificamente o subconjunto de dados de que precisa. Há muito para falar e escrever sobre todas as coisas incríveis que o GraphQL permite, mas os conceitos principais são muito gerenciáveis e descomplicados.
Para tornar esses conceitos mais concretos e ajudar a ilustrar como o GraphQL tenta resolver alguns dos problemas da Parte 1, o restante desta postagem criará uma API do GraphQL que pode impulsionar o blog na Parte 1 desta série. Antes de entrar no código, há algumas coisas sobre o GraphQL a serem lembradas.
GraphQL é uma especificação (não uma implementação)
GraphQL é apenas uma especificação. Ele define um sistema de tipos junto com uma linguagem de consulta simples, e é isso. A primeira coisa que sai disso é que o GraphQL não está, de forma alguma, vinculado a uma linguagem específica. Existem mais de duas dúzias de implementações em tudo, de Haskell a C++, das quais JavaScript é apenas uma. Logo após o anúncio da especificação, o Facebook lançou uma implementação de referência em JavaScript mas, como não a utiliza internamente, implementações em linguagens como Go e Clojure podem ser ainda melhores ou mais rápidas.
A especificação do GraphQL não menciona clientes ou dados
Se você ler a especificação, notará que duas coisas estão visivelmente ausentes. Primeiro, além da linguagem de consulta, não há menção a integrações de clientes. Ferramentas como Apollo, Relay, Loka e similares são possíveis devido ao design do GraphQL, mas de forma alguma fazem parte ou são necessárias para usá-lo. Em segundo lugar, não há menção a nenhuma camada de dados específica. O mesmo servidor GraphQL pode, e frequentemente o faz, buscar dados de um conjunto heterogêneo de fontes. Ele pode solicitar dados em cache do Redis, fazer uma pesquisa de endereço da API do USPS e chamar microsserviços baseados em protobuff e o cliente nunca saberia a diferença.
Divulgação progressiva da complexidade
O GraphQL, para muitas pessoas, atingiu uma rara interseção de poder e simplicidade. Ele faz um trabalho fantástico de tornar as coisas simples simples e as coisas difíceis possíveis. Obter um servidor executando e servindo dados digitados por HTTP pode ser apenas algumas linhas de código em praticamente qualquer linguagem que você possa imaginar.
Por exemplo, um servidor GraphQL pode encapsular uma API REST existente e seus clientes podem obter dados com solicitações GET regulares, assim como você interagiria com outros serviços. Você pode ver uma demonstração aqui. Ou, se o projeto precisar de um conjunto de ferramentas mais sofisticado, é possível usar o GraphQL para fazer coisas como autenticação em nível de campo, assinaturas pub/sub ou consultas pré-compiladas/em cache.
Um aplicativo de exemplo
O objetivo deste exemplo é demonstrar o poder e a simplicidade do GraphQL em ~70 linhas de JavaScript, não escrever um tutorial extenso. Não vou entrar em muitos detalhes sobre a sintaxe e semântica, mas todo o código aqui é executável, e há um link para uma versão para download do projeto no final do artigo. Se depois de passar por isso, você quiser se aprofundar um pouco mais, tenho uma coleção de recursos no meu blog que ajudarão você a criar serviços maiores e mais robustos.
Para a demonstração, usarei JavaScript, mas as etapas são muito semelhantes em qualquer idioma. Vamos começar com alguns dados de exemplo usando o incrível Mocky.io.
Autores
{ 9: { id: 9, name: "Eric Baer", company: "Formidable" }, ... }Postagens
[ { id: 17, author: "author/7", categories: [ "software engineering" ], publishdate: "2016/03/27 14:00", summary: "...", tags: [ "http/2", "interlock" ], title: "http/2 server push" }, ... ] O primeiro passo é criar um novo projeto com o middleware express e express-graphql .

bash npm init -y && npm install --save graphql express express-graphql E para criar um arquivo index.js com um servidor expresso.
const app = require("express")(); const PORT = 5000; app.listen(PORT, () => { console.log(`Server running at https://localhost:${PORT}`); }); Para começar a trabalhar com o GraphQL, podemos começar modelando os dados na API REST. Em um novo arquivo chamado schema.js adicione o seguinte:
const { GraphQLInt, GraphQLList, GraphQLObjectType, GraphQLSchema, GraphQLString } = require("graphql"); const Author = new GraphQLObjectType({ name: "Author", fields: { id: { type: GraphQLInt }, name: { type: GraphQLString }, company: { type: GraphQLString }, } }); const Post = new GraphQLObjectType({ name: "Post", fields: { id: { type: GraphQLInt }, author: { type: Author }, categories: { type: new GraphQLList(GraphQLString) }, publishDate: { type: GraphQLString }, summary: { type: GraphQLString }, tags: { type: new GraphQLList(GraphQLString) }, title: { type: GraphQLString } } }); const Blog = new GraphQLObjectType({ name: "Blog", fields: { posts: { type: new GraphQLList(Post) } } }); module.exports = new GraphQLSchema({ query: Blog }); O código acima mapeia os tipos nas respostas JSON da nossa API para os tipos do GraphQL. Um GraphQLObjectType corresponde a um JavaScript Object , um GraphQLString corresponde a um JavaScript String e assim por diante. O único tipo especial para prestar atenção é o GraphQLSchema nas últimas linhas. O GraphQLSchema é a exportação no nível da raiz de um GraphQL — o ponto de partida para as consultas percorrerem o gráfico. Neste exemplo básico, estamos apenas definindo a query ; é aqui que você definiria mutações (gravações) e assinaturas.
Em seguida, adicionaremos o esquema ao nosso servidor expresso no arquivo index.js . Para fazer isso, adicionaremos o middleware express-graphql e passaremos o esquema.
const graphqlHttp = require("express-graphql"); const schema = require("./schema.js"); const app = require("express")(); const PORT = 5000; app.use(graphqlHttp({ schema, // Pretty Print the JSON response pretty: true, // Enable the GraphiQL dev tool graphiql: true })); app.listen(PORT, () => { console.log(`Server running at https://localhost:${PORT}`); }); Neste ponto, embora não estejamos retornando nenhum dado, temos um servidor GraphQL em funcionamento que fornece seu esquema aos clientes. Para facilitar o início do aplicativo, também adicionaremos um script de início ao package.json .
"scripts": { "start": "nodemon index.js" }, Executar o projeto e acessar https://localhost:5000/ deve mostrar um explorador de dados chamado GraphiQL. O GraphiQL será carregado por padrão, desde que o cabeçalho HTTP Accept não esteja definido como application/json . Chamar esse mesmo URL com fetch ou cURL usando application/json retornará um resultado JSON. Sinta-se à vontade para brincar com a documentação interna e escrever uma consulta.

A única coisa que falta fazer para completar o servidor é conectar os dados subjacentes ao esquema. Para fazer isso, precisamos definir funções de resolve . No GraphQL, uma consulta é executada de cima para baixo chamando uma função de resolve à medida que percorre a árvore. Por exemplo, para a seguinte consulta:
query homepage { posts { title } } O GraphQL chamará primeiro posts.resolve(parentData) e depois posts.title.resolve(parentData) . Vamos começar definindo o resolvedor em nossa lista de postagens do blog.
const Blog = new GraphQLObjectType({ name: "Blog", fields: { posts: { type: new GraphQLList(Post), resolve: () => { return fetch('https://www.mocky.io/v2/594a3ac810000053021aa3a7') .then((response) => response.json()) } } } }); Estou usando o pacote isomorphic-fetch aqui para fazer uma solicitação HTTP, pois demonstra muito bem como retornar uma promessa de um resolvedor, mas você pode usar o que quiser. Esta função retornará um array de Posts para o tipo Blog. A função de resolução padrão para a implementação JavaScript do GraphQL é parentData.<fieldName> . Por exemplo, o resolvedor padrão para o campo de nome do autor seria:
rawAuthorObject => rawAuthorObject.nameEsse resolvedor de substituição única deve fornecer os dados para todo o objeto de postagem. Ainda precisamos definir o resolvedor para Autor, mas se você executar uma consulta para buscar os dados necessários para a página inicial, verá que está funcionando.
Como o atributo author em nossa API de postagens é apenas o ID do autor, quando o GraphQL procura um Object que define nome e empresa e encontra uma String, ele retornará apenas null . Para conectar o autor, precisamos alterar nosso esquema de postagem para se parecer com o seguinte:
const Post = new GraphQLObjectType({ name: "Post", fields: { id: { type: GraphQLInt }, author: { type: Author, resolve: (subTree) => { // Get the AuthorId from the post data const authorId = subTree.author.split("/")[1]; return fetch('https://www.mocky.io/v2/594a3bd21000006d021aa3ac') .then((response) => response.json()) .then(authors => authors[authorId]); } }, ... } });Agora, temos um servidor GraphQL totalmente funcional que envolve uma API REST. A fonte completa pode ser baixada neste link do Github ou executada neste launchpad do GraphQL.
Você pode estar se perguntando sobre as ferramentas que precisará usar para consumir um endpoint GraphQL como este. Existem muitas opções como Relay e Apollo, mas para começar, acho que a abordagem simples é a melhor. Se você brincou muito com o GraphiQL, deve ter notado que ele tem uma URL longa. Este URL é apenas uma versão codificada de URI de sua consulta. Para construir uma consulta GraphQL em JavaScript, você pode fazer algo assim:
const homepageQuery = ` posts { title author { name } } `; const uriEncodedQuery = encodeURIComponent(homepageQuery); fetch(`https://localhost:5000/?query=${uriEncodedQuery}`);Ou, se desejar, você pode copiar e colar a URL diretamente do GraphiQL assim:
https://localhost:5000/?query=query%20homepage%20%7B%0A%20%20posts%20%7B%0A%20%20%20%20title%0A%20%20%20%20author%20%7B%0A%20%20%20%20%20%20name%0A%20%20%20%20%7D%0A%20%20%7D%0A%7D&operationName=homepageComo temos um endpoint GraphQL e uma maneira de usá-lo, podemos compará-lo com nossa API RESTish. O código que precisávamos escrever para buscar nossos dados usando uma API RESTish ficou assim:
Usando uma API RESTish
const getPosts = () => fetch(`${API_ROOT}/posts`); const getPost = postId => fetch(`${API_ROOT}/post/${postId}`); const getAuthor = authorId => fetch(`${API_ROOT}/author/${postId}`); const getPostWithAuthor = post => { return getAuthor(post.author) .then(author => { return Object.assign({}, post, { author }) }) }; const getHomePageData = () => { return getPosts() .then(posts => { const postDetails = posts.map(getPostWithAuthor); return Promise.all(postDetails); }) };Usando uma API GraphQL
const homepageQuery = ` posts { title author { name } } `; const uriEncodedQuery = encodeURIComponent(homepageQuery); fetch(`https://localhost:5000/?query=${uriEncodedQuery}`);Em resumo, usamos o GraphQL para:
- Reduza nove solicitações (lista de postagens, quatro postagens do blog e o autor de cada postagem).
- Reduza a quantidade de dados enviados em uma porcentagem significativa.
- Use ferramentas de desenvolvedor incríveis para criar nossas consultas.
- Escreva um código muito mais limpo em nosso cliente.
Falhas no GraphQL
Embora eu acredite que o hype seja justificado, não há bala de prata e, por melhor que o GraphQL seja, não é isento de falhas.
Integridade de dados
O GraphQL às vezes parece uma ferramenta criada especificamente para bons dados. Geralmente funciona melhor como uma espécie de gateway, unindo serviços díspares ou tabelas altamente normalizadas. Se os dados que retornam dos serviços que você consome são confusos e não estruturados, adicionar um pipeline de transformação de dados no GraphQL pode ser um verdadeiro desafio. O escopo de uma função de resolução do GraphQL é apenas seus próprios dados e os de seus filhos. Se uma tarefa de orquestração precisar de acesso a dados em um irmão ou pai na árvore, isso pode ser especialmente desafiador.
Tratamento de erros complexos
Uma solicitação do GraphQL pode executar um número arbitrário de consultas e cada consulta pode atingir um número arbitrário de serviços. Se qualquer parte da solicitação falhar, em vez de falhar em toda a solicitação, o GraphQL, por padrão, retornará dados parciais. Os dados parciais são provavelmente a escolha certa tecnicamente e podem ser incrivelmente úteis e eficientes. A desvantagem é que o tratamento de erros não é mais tão simples quanto verificar o código de status HTTP. Esse comportamento pode ser desativado, mas, na maioria das vezes, os clientes acabam com casos de erro mais sofisticados.
Cache
Embora muitas vezes seja uma boa ideia usar consultas estáticas do GraphQL, para organizações como o Github que permitem consultas arbitrárias, o cache de rede com ferramentas padrão como Varnish ou Fastly não será mais possível.
Alto custo de CPU
Analisar, validar e verificar o tipo de uma consulta é um processo vinculado à CPU que pode levar a problemas de desempenho em linguagens de thread único, como JavaScript.
Este é apenas um problema para avaliação de consulta em tempo de execução.
Considerações finais
Os recursos do GraphQL não são uma revolução - alguns deles existem há quase 30 anos. O que torna o GraphQL poderoso é que o nível de polimento, integração e facilidade de uso o tornam mais do que a soma de suas partes.
Muitas das coisas que o GraphQL realiza podem, com esforço e disciplina, ser alcançadas usando REST ou RPC, mas o GraphQL traz APIs de última geração para o enorme número de projetos que podem não ter tempo, recursos ou ferramentas para fazer isso sozinhos. Também é verdade que o GraphQL não é uma bala de prata, mas suas falhas tendem a ser menores e bem compreendidas. Como alguém que construiu um servidor GraphQL razoavelmente complicado, posso dizer facilmente que os benefícios superam facilmente o custo.
Este ensaio se concentra quase inteiramente no motivo pelo qual o GraphQL existe e nos problemas que ele resolve. Se isso despertou seu interesse em aprender mais sobre sua semântica e como usá-lo, encorajo você a aprender da maneira que funcionar melhor para você, seja em blogs, youtube ou apenas lendo a fonte (How To GraphQL é particularmente bom).
Se você gostou deste artigo (ou se você odiou) e gostaria de me dar feedback, por favor me encontre no Twitter como @ebaerbaerbaer ou LinkedIn em ericjbaer.