
A GraphQL Primer: Por que precisamos de um novo tipo de API (Parte 1)
Publicados: 2022-03-10Nesta série, quero apresentá-lo ao GraphQL. No final, você deve entender não apenas o que é, mas também suas origens, suas desvantagens e o básico de como trabalhar com ele. Neste primeiro artigo, em vez de pular para a implementação, quero explicar como e por que chegamos ao GraphQL (e ferramentas semelhantes) analisando as lições aprendidas nos últimos 60 anos de desenvolvimento de API, do RPC até agora. Afinal, como Mark Twain descreveu de forma colorida, não há novas ideias.
"Não existe uma ideia nova. É impossível. Simplesmente pegamos muitas ideias antigas e as colocamos em uma espécie de caleidoscópio mental."
— Mark Twain em "A Autobiografia de Mark Twain: os capítulos da revisão norte-americana"
Mas primeiro, tenho que me dirigir ao elefante na sala. Coisas novas são sempre emocionantes, mas também podem parecer exaustivas. Você pode ter ouvido falar sobre o GraphQL e apenas pensado: “Por que…” Alternativamente, talvez você tenha pensado algo mais como “Por que eu me importo com uma nova tendência de design de API? REST é... bom.” Essas são perguntas legítimas, então deixe-me ajudar a explicar por que você deve prestar atenção a esta.
Introdução
Os benefícios de trazer novas ferramentas para sua equipe devem ser ponderados em relação aos seus custos. Há muitas coisas para medir. Há o tempo que leva para aprender, o tempo de conversão tira o desenvolvimento de recursos, a sobrecarga de manter dois sistemas. Com custos tão altos, qualquer nova tecnologia precisa ser muito melhor, mais rápida ou mais produtiva . Melhorias incrementais, embora empolgantes, simplesmente não valem o investimento. Os tipos de APIs sobre os quais quero falar, GraphQL em particular, são, na minha opinião, um grande passo à frente e oferecem benefícios mais do que suficientes para justificar o custo.
Em vez de explorar os recursos primeiro, é útil colocá-los em contexto e entender como eles surgiram. Para fazer isso, vou começar com uma pequena recapitulação da história das APIs.
RPC
O RPC foi, sem dúvida, o primeiro grande padrão de API e suas origens remontam ao início da computação em meados dos anos 60. Na época, os computadores ainda eram tão grandes e caros que a noção de desenvolvimento de aplicativos orientado por API, como pensamos, era principalmente apenas teórica. Restrições como largura de banda/latência, poder de computação, tempo de computação compartilhado e proximidade física forçaram os engenheiros a pensar em termos de sistemas distribuídos em vez de serviços que expõem dados. Da ARPANET nos anos 60, até meados dos anos 90, com coisas como CORBA e RMI de Java, a maioria dos computadores interagia entre si usando Remote Procedure Calls (RPC), que é um modelo de interação cliente-servidor em que um cliente causa um procedimento (ou método) para executar em um servidor remoto.
Há um monte de coisas boas sobre RPC. Seu princípio principal é permitir que um desenvolvedor trate o código em um ambiente remoto como se estivesse em um local, embora muito mais lento e menos confiável, o que cria continuidade em sistemas distintos e díspares. Como muitas coisas que surgiram na ARPANET, ela estava à frente de seu tempo, pois esse tipo de continuidade é algo que ainda buscamos ao trabalhar com ações não confiáveis e assíncronas, como acesso ao banco de dados e chamadas de serviço externas.
Ao longo das décadas, tem havido uma enorme quantidade de pesquisas sobre como permitir que os desenvolvedores incorporem um comportamento assíncrono como esse no fluxo típico de um programa; se houvesse coisas como Promises, Futures e ScheduledTasks disponíveis no momento, é possível que nosso cenário de API parecesse diferente.
Outra grande vantagem do RPC é que, como ele não é limitado pela estrutura dos dados, métodos altamente especializados podem ser escritos para clientes que solicitam e recuperam exatamente as informações necessárias, o que pode resultar em sobrecarga de rede mínima e cargas úteis menores.
Há, no entanto, coisas que tornam o RPC difícil. Primeiro, a continuidade requer contexto . O RPC, por design, cria bastante acoplamento entre sistemas locais e remotos – você perde os limites entre seu código local e remoto. Para alguns domínios, isso é bom ou até mesmo preferido como em SDKs de cliente, mas para APIs em que o código do cliente não é bem compreendido, pode ser consideravelmente menos flexível do que algo mais orientado a dados.
Mais importante, porém, é o potencial de proliferação de métodos de API . Em teoria, um serviço RPC expõe uma pequena API pensada que pode lidar com qualquer tarefa. Na prática, um grande número de endpoints externos pode agregar sem muita estrutura. É preciso muita disciplina para evitar a sobreposição de APIs e a duplicação ao longo do tempo, à medida que os membros da equipe vão e vêm e os projetos mudam.
É verdade que com ferramentas adequadas e mudanças de documentação, como as que mencionei, podem ser gerenciadas, mas no meu tempo escrevendo software, encontrei poucos serviços de documentação automática e disciplinados, então, para mim, isso é um pouco difícil arenque vermelho.
SABÃO
O próximo grande tipo de API a aparecer foi o SOAP, que nasceu no final dos anos 90 na Microsoft Research. SOAP ( P rotocolo de acesso a objetos simples ) é uma especificação de protocolo ambiciosa para comunicação baseada em XML entre aplicativos. A ambição declarada do SOAP era abordar algumas das desvantagens práticas do RPC, XML-RPC em particular, criando uma base bem estruturada para serviços web complexos. Na verdade, isso significava apenas adicionar um sistema de tipo comportamental ao XML. Infelizmente, ele criou mais impedimentos do que resolveu, como evidenciado pelo fato de que muito poucos novos terminais SOAP são escritos hoje.
"SOAP é o que a maioria das pessoas consideraria um sucesso moderado."
- Dom Caixa
SOAP tinha algumas coisas boas, apesar de sua verbosidade insuportável e nomes terríveis. Os contratos executáveis no WSDL e WADL (pronuncia-se “wizdle” e “waddle”) entre o cliente e o servidor garantiam resultados previsíveis e de tipagem segura, e o WSDL poderia ser usado para gerar documentação ou para criar integrações com IDEs e outras ferramentas.
A grande revelação do SOAP em relação à evolução da API foi sua introdução gradual e possivelmente não intencional de chamadas mais orientadas a recursos. Os terminais SOAP permitem solicitar dados com uma estrutura predeterminada, em vez de pensar nos métodos necessários para gerar os dados (supondo que sejam escritos dessa maneira).
A desvantagem mais significativa do SOAP é ser tão detalhado; é quase impossível de usar sem muitas ferramentas . Você precisa de ferramentas para escrever testes, ferramentas para inspecionar respostas de um servidor e ferramentas para analisar todos os dados. Muitos sistemas mais antigos ainda usam SOAP, mas o requisito de ferramentas o torna muito complicado para a maioria dos novos projetos, e o número de bytes necessários para a estrutura XML o torna uma escolha ruim para atender a dispositivos móveis ou sistemas distribuídos chatos.
Para mais informações, vale a pena ler as especificações do SOAP, bem como a história surpreendentemente interessante do SOAP de Don Box, um dos membros originais da equipe.
DESCANSO
Finalmente, chegamos ao padrão de design da API do dia: REST. O REST, apresentado em uma tese de doutorado de Roy Fielding em 2000, fez o pêndulo girar em uma direção totalmente diferente. REST é, de muitas maneiras, a antítese do SOAP e olhar para eles lado a lado faz você sentir que sua dissertação foi um pouco desanimada.
O SOAP usa HTTP como um transporte burro e constrói sua estrutura no corpo da solicitação e da resposta. O REST, por outro lado, descarta os contratos cliente-servidor, ferramentas, XML e cabeçalhos personalizados, substituindo-os pela semântica HTTPs, pois é uma estrutura que opta por usar verbos HTTP interagindo com dados e URIs que fazem referência a um recurso em alguma hierarquia de dados.
| SABÃO | DESCANSO | |
|---|---|---|
| Verbos HTTP | OBTER, COLOCAR, POSTAR, PATCH, EXCLUIR | |
| Formato de dados | XML | O que você quiser |
| Contratos Cliente/Servidor | Todo o dia 'todo dia! | Quem precisa daqueles |
| Tipo de sistema | JavaScript tem unsigned curto certo? | |
| URLs | Descrever as operações | Recursos nomeados |
REST altera completa e explicitamente o design da API de interações de modelagem para simplesmente modelar os dados de um domínio. Sendo totalmente orientado a recursos ao trabalhar com uma API REST, você não precisa mais saber ou se importar com o que é necessário para recuperar um determinado dado; nem é obrigado a saber nada sobre a implementação dos serviços de back-end.

Não só a simplicidade foi um benefício para os desenvolvedores, mas como os URLs representam informações estáveis, são facilmente armazenados em cache, sua ausência de estado facilita o dimensionamento horizontal e, como modela os dados em vez de antecipar as necessidades dos consumidores, pode reduzir drasticamente a área de superfície das APIs .
O REST é ótimo, e sua onipresença é um sucesso surpreendente, mas, como todas as soluções que vieram antes dele, o REST tem suas falhas. Para falar concretamente sobre algumas de suas deficiências, vamos a um exemplo básico. Vamos fingir que temos que construir a página de destino de um blog que exibe uma lista de postagens do blog e o nome do autor.
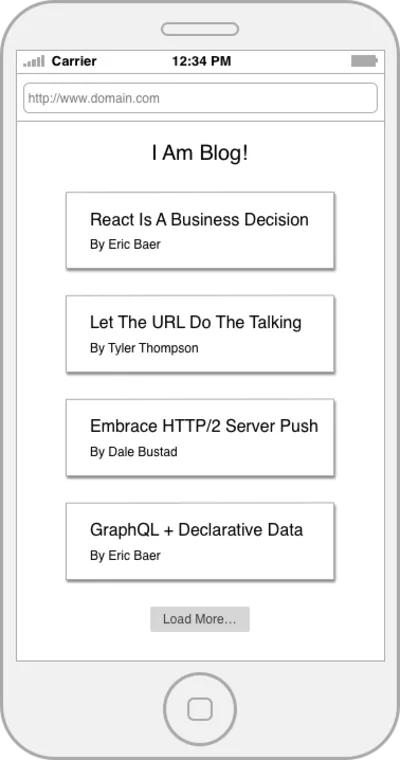
Vamos escrever o código que pode recuperar os dados da página inicial de uma API REST simples. Começaremos com algumas funções que envolvem nossos recursos.
const getPosts = () => fetch(`${API_ROOT}/posts`); const getPost = postId => fetch(`${API_ROOT}/posts/${postId}`); const getAuthor = authorId => fetch(`${API_ROOT}/authors/${authorId}`);Agora, vamos orquestrar!
const getPostWithAuthor = postId => { return getPost(postId) .then(post => getAuthor(post.author)) .then(author => { return Object.assign({}, post, { author }) }) }; const getHomePageData = () => { return getPosts() .then(postIds => { const postDetails = postIds.map(getPostWithAuthor); return Promise.all(postDetails); }) };Então nosso código fará o seguinte:
- Buscar todos os Posts;
- Busque os detalhes sobre cada Post;
- Recurso de busca do autor para cada postagem.
O bom é que isso é muito fácil de raciocinar, bem organizado e os limites conceituais de cada recurso são bem desenhados. A chatice aqui é que acabamos de fazer oito solicitações de rede, muitas das quais acontecem em série.
GET /posts GET /posts/234 GET /posts/456 GET /posts/17 GET /posts/156 GET /author/9 GET /author/4 GET /author/7 GET /author/2 Sim, você pode criticar este exemplo sugerindo que a API poderia ter um ponto final paginado /posts mas isso está dividindo os cabelos. O fato é que muitas vezes você tem uma coleção de chamadas de API para fazer depender umas das outras para renderizar um aplicativo ou uma página completa.
Desenvolver clientes e servidores REST é certamente melhor do que o que veio antes dele, ou pelo menos mais à prova de idiotas, mas muita coisa mudou nas duas décadas desde o artigo de Fielding. Na época, todos os computadores eram de plástico bege; agora são de alumínio! Mas falando sério, 2000 estava perto do pico da explosão da computação pessoal. Todos os anos, os processadores dobravam de velocidade e as redes estavam ficando mais rápidas a uma velocidade incrível. A penetração de mercado da internet foi de cerca de 45%, sem ter para onde ir, mas para cima.
Então, por volta de 2008, a computação móvel se popularizou. Com os dispositivos móveis, regredimos efetivamente uma década em termos de velocidade/desempenho da noite para o dia. Em 2017, temos quase 80% de penetração doméstica e mais de 50% de penetração global de smartphones, e é hora de repensar algumas de nossas suposições sobre o design da API.
Pontos fracos do REST
A seguir, uma visão crítica do REST da perspectiva de um desenvolvedor de aplicativo cliente, particularmente um que trabalha em dispositivos móveis. As APIs de estilo GraphQL e GraphQL não são novas e não resolvem problemas que estão fora do alcance dos desenvolvedores REST. A contribuição mais significativa do GraphQL é sua capacidade de resolver esses problemas sistematicamente e com um nível de integração que não está prontamente disponível em outros lugares. Em outras palavras, é uma solução “pilhas incluídas”.
Os principais autores do REST, incluindo Fielding, publicaram um artigo no final de 2017 (Reflections on the REST Architectural Style and “Principled Design of the Modern Web Architecture”) refletindo sobre duas décadas de REST e os muitos padrões que ele inspirou. É curto e absolutamente vale a leitura para qualquer pessoa interessada em design de API.
Com algum contexto histórico e um aplicativo de referência, vejamos os três principais pontos fracos do REST.
REST é chato
Os serviços REST tendem a ser pelo menos um pouco “conversadores”, pois são necessárias várias viagens de ida e volta entre o cliente e o servidor para obter dados suficientes para renderizar um aplicativo. Essa cascata de solicitações tem impactos devastadores no desempenho, especialmente em dispositivos móveis. Voltando ao exemplo do blog, mesmo no melhor cenário possível com um novo telefone e uma rede confiável com uma conexão 4G, você gastou quase 0,5s apenas em sobrecarga de latência antes que o primeiro byte de dados fosse baixado.
55ms de latência 4G * 8 solicitações = 440ms de sobrecarga
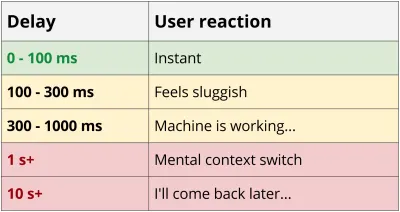
Outro problema com os serviços chatty é que, em muitos casos, leva menos tempo para baixar uma solicitação grande do que muitas pequenas. O desempenho reduzido de pequenas solicitações é verdade por muitos motivos, incluindo TCP Slow Start, falta de compactação de cabeçalho e eficiência de gzip e, se você estiver curioso, recomendo a leitura de High-Performance Browser Networking de Ilya Grigorik. O blog MaxCDN também tem uma ótima visão geral.
Esse problema não é tecnicamente com REST, mas com HTTP, especificamente HTTP/1. O HTTP/2 praticamente resolve o problema da conversa, independentemente do estilo da API, e tem amplo suporte em clientes como navegadores e SDKs nativos. Infelizmente, o lançamento foi lento no lado da API. Entre os 10.000 principais sites, a adoção está em torno de 20% (e subindo) no final de 2017. Até o Node.js, para minha surpresa, recebeu suporte HTTP/2 em sua versão 8.x. Se você tiver capacidade, atualize sua infraestrutura! Enquanto isso, não vamos nos alongar, pois esta é apenas uma parte da equação.
Deixando de lado o HTTP, a parte final da importância da tagarelice tem a ver com a forma como os dispositivos móveis e, especificamente, seus rádios funcionam. O resumo disso é que operar o rádio é uma das partes mais intensivas da bateria de um telefone, então o sistema operacional o desliga em todas as oportunidades. A partida do rádio não apenas consome a bateria, mas adiciona ainda mais sobrecarga a cada solicitação.
TMI (Sobrebusca)
O próximo problema com os serviços no estilo REST é que eles enviam muito mais informações do que o necessário. Em nosso exemplo de blog, tudo o que precisamos é o título de cada postagem e o nome do autor, que é apenas cerca de 17% do que foi retornado. Isso é uma perda de 6x para uma carga muito simples. Em uma API do mundo real, esse tipo de sobrecarga pode ser enorme. Sites de comércio eletrônico, por exemplo, geralmente representam um único produto como milhares de linhas de JSON. Assim como o problema da conversa, os serviços REST podem lidar com esse cenário hoje usando “conjuntos de campos esparsos” para incluir ou excluir condicionalmente partes dos dados. Infelizmente, o suporte para isso é irregular, incompleto ou problemático para o cache de rede.
Ferramentas e introspecção
A última coisa que falta às APIs REST são mecanismos para introspecção. Sem nenhum contrato com informações sobre os tipos de retorno ou estrutura de um endpoint, não há como gerar documentação de forma confiável, criar ferramentas ou interagir com os dados. É possível trabalhar dentro do REST para resolver esse problema em vários graus. Projetos que implementam totalmente OpenAPI, OData ou JSON API geralmente são limpos, bem especificados e, em vários graus, bem documentados, mas back-ends como esse são raros. Mesmo a Hipermídia, um fruto relativamente barato, apesar de ter sido elogiado em conferências por décadas, ainda não é frequentemente bem feito, se é que o faz.
Conclusão
Cada um dos tipos de API é falho, mas todo padrão é. Esta escrita não é um julgamento da base fenomenal que os gigantes do software estabeleceram, apenas para ser uma avaliação sóbria de cada um desses padrões, aplicados em sua forma “pura” da perspectiva de um desenvolvedor cliente. Espero que, em vez de sair desse pensamento, um padrão como REST ou RPC está quebrado, você possa sair pensando em como cada um deles fez compensações e as áreas em que uma organização de engenharia pode concentrar seus esforços para melhorar suas próprias APIs .
No próximo artigo, explorarei o GraphQL e como ele visa resolver alguns dos problemas que mencionei acima. A inovação no GraphQL e ferramentas similares está em seu nível de integração e não em sua implementação. Por favor, se você ou sua equipe não estiver procurando por uma API com “baterias incluídas”, considere procurar algo como a nova especificação OpenAPI que pode ajudar a construir uma base mais forte hoje!
Se você gostou deste artigo (ou se você odiou) e gostaria de me dar feedback, por favor me encontre no Twitter como @ebaerbaerbaer ou LinkedIn em ericjbaer.