
Descida Gradiente na Regressão Logística [Explicado para Iniciantes]
Publicados: 2021-01-08Neste artigo, discutiremos o muito popular algoritmo de descida de gradiente em regressão logística. Veremos o que é Regressão Logística e, gradualmente, avançaremos para a Equação para Regressão Logística, sua Função de Custo e, finalmente, o Algoritmo de Descida Gradiente.
Índice
O que é regressão logística?
A regressão logística é simplesmente um algoritmo de classificação usado para prever categorias discretas, como prever se um e-mail é 'spam' ou 'não é spam'; prevendo se um determinado dígito é '9' ou 'não 9' etc. Agora, olhando para o nome, você deve pensar, por que ele se chama Regressão?
A razão é que a ideia de Regressão Logística foi desenvolvida ajustando alguns elementos do Algoritmo de Regressão Linear básico usado em problemas de regressão.
A Regressão Logística também pode ser aplicada a problemas de classificação Multi-Class (mais de duas classes). No entanto, é recomendável usar este algoritmo apenas para problemas de classificação binária.
Função sigmóide
Problemas de classificação não são problemas de função linear. A saída é limitada a certos valores discretos, por exemplo, 0 e 1 para um problema de classificação binária. Não faz sentido para uma função linear prever nossos valores de saída como maiores que 1 ou menores que 0. Portanto, precisamos de uma função adequada para representar nossos valores de saída.
A função sigmóide resolve nosso problema. Também conhecida como Função Logística, é uma função em forma de S que mapeia qualquer número de valor real para o intervalo (0,1), tornando-a muito útil para transformar qualquer função aleatória em uma função baseada em classificação. Uma função sigmóide se parece com isso:

Função sigmóide
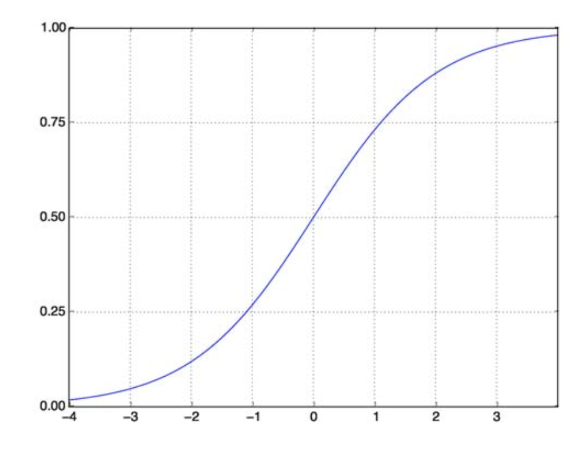
fonte
Agora, a forma matemática da função sigmóide para vetor parametrizado e vetor de entrada X é:
(z) = 11+exp(-z) onde z = TX
(z) nos dará a probabilidade de que a saída seja 1. Como todos sabemos, o valor de probabilidade varia de 0 a 1. Agora, esta não é a saída que queremos para nosso problema de classificação baseado em discreto (0 e 1 apenas) . Então agora podemos comparar a probabilidade prevista com 0,5. Se probabilidade > 0,5, temos y=1. Da mesma forma, se a probabilidade for < 0,5, temos y=0.
Função de custo
Agora que temos nossas previsões discretas, é hora de verificar se nossas previsões estão realmente corretas ou não. Para isso, temos uma função de custo. A Função de Custo é meramente a soma de todos os erros cometidos nas previsões em todo o conjunto de dados. Obviamente, não podemos usar a Função de Custo usada na Regressão Linear. Assim, a nova Função de Custo para Regressão Logística é:
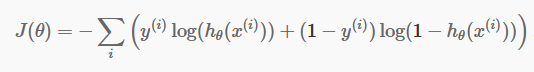 fonte
fonte
Não tenha medo da equação. É muito simples. Para cada iteração i , ele calcula o erro que cometemos em nossa previsão e, em seguida, soma todos os erros para definir nossa função de custo J().
Os dois termos dentro do colchete são, na verdade, para os dois casos: y=0 e y=1. Quando y = 0, o primeiro termo desaparece e ficamos com apenas o segundo termo. Da mesma forma, quando y = 1, o segundo termo desaparece e ficamos com apenas o primeiro termo.
Algoritmo de descida de gradiente
Calculamos com sucesso nossa Função de Custo. Mas precisamos minimizar a perda para fazer um bom algoritmo de previsão. Para isso, temos o Algoritmo Gradient Descent.
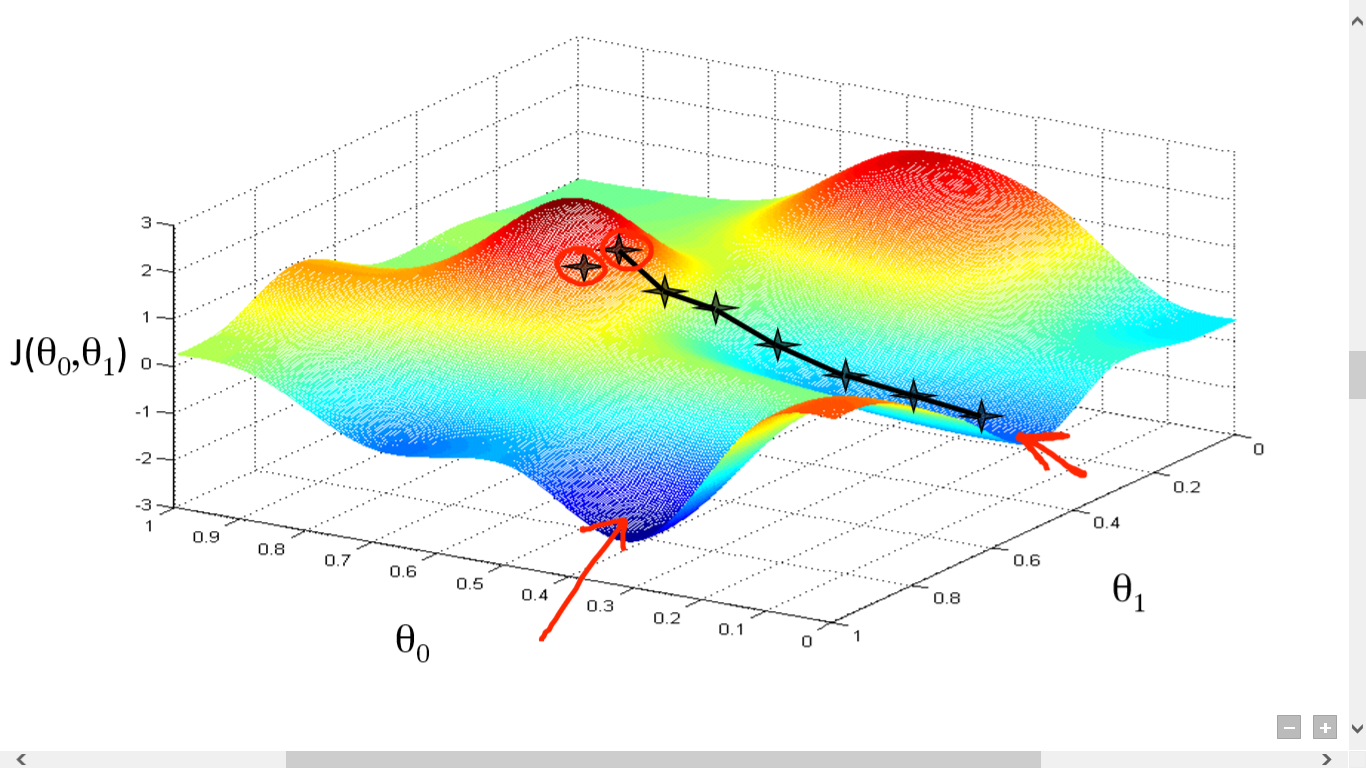 fonte
fonte
Aqui traçamos um gráfico entre J() e . Nosso objetivo é encontrar o ponto mais profundo (mínimo global) dessa função. Agora, o ponto mais profundo é onde o J() é mínimo.
Duas coisas são necessárias para encontrar o ponto mais profundo:
- Derivativo – para encontrar a direção do próximo passo.
- (Taxa de Aprendizagem) – magnitude do próximo passo
A ideia é que você primeiro selecione qualquer ponto aleatório da função. Então você precisa calcular a derivada de J()wrt . Isso apontará para a direção do mínimo local. Agora multiplique esse gradiente resultante pela Taxa de Aprendizagem. A Taxa de Aprendizagem não tem valor fixo e deve ser decidida com base em problemas.
Agora, você precisa subtrair o resultado para obter o novo .
Esta atualização de deve ser feita simultaneamente para cada (i) .
Execute essas etapas repetidamente até atingir o mínimo local ou global. Ao atingir o mínimo global, você alcançou a menor perda possível em sua previsão.
A derivação é simples. Apenas o cálculo básico que você deve ter feito em sua escola é suficiente. O principal problema é com a Taxa de Aprendizagem ( ). Ter uma boa taxa de aprendizado é importante e muitas vezes difícil.
Se você adotar uma taxa de aprendizado muito pequena, cada etapa será muito pequena e, portanto, levará muito tempo para atingir o mínimo local.

Agora, se você tende a ter um valor de taxa de aprendizado enorme, você ultrapassará o mínimo e nunca convergirá novamente. Não existe uma regra específica para a taxa de aprendizagem perfeita.
Você precisa ajustá-lo para preparar o melhor modelo.
A equação para a descida do gradiente é:
Repita até a convergência:
Assim, podemos resumir o Algoritmo Gradient Descent como:
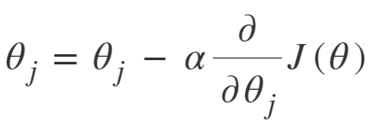
- Comece com aleatório
- Loop até a convergência:
- Calcular gradiente
- Atualizar
- Retornar
Algoritmo de Descida de Gradiente Estocástico
Agora, o Gradient Descent Algorithm é um bom algoritmo para minimizar a Função de Custo, especialmente para dados pequenos e médios. Mas quando precisamos lidar com conjuntos de dados maiores, o Gradient Descent Algorithm acaba sendo lento na computação. A razão é simples: ele precisa calcular o gradiente e atualizar os valores simultaneamente para cada parâmetro, e isso também para cada exemplo de treinamento.
Então pense em todos esses cálculos! É enorme e, portanto, havia a necessidade de um algoritmo de descida de gradiente ligeiramente modificado, a saber - Algoritmo de descida de gradiente estocástico (SGD).
A única diferença que o SGD tem com o Normal Gradient Descent é que, no SGD, não lidamos com toda a instância de treinamento de uma só vez. Em SGD, calculamos o gradiente da função de custo para apenas um único exemplo aleatório em cada iteração.
Agora, isso reduz o tempo necessário para cálculos em uma margem enorme, especialmente para grandes conjuntos de dados. O caminho tomado pelo SGD é muito aleatório e barulhento (embora um caminho barulhento possa nos dar a chance de alcançar mínimos globais).
Mas tudo bem, já que não precisamos nos preocupar com o caminho percorrido.
Nós só precisamos atingir a perda mínima em um tempo mais rápido.
Assim, podemos resumir o Algoritmo Gradient Descent como:
- Loop até a convergência:
- Escolha um único ponto de dados ' i'
- Calcular gradiente sobre esse único ponto
- Atualizar
- Retornar
Algoritmo de descida de gradiente de mini-lote
Mini-Batch Gradient Descent é outra pequena modificação do algoritmo Gradient Descent. É um pouco entre a descida do gradiente normal e a descida do gradiente estocástico.
Mini-Batch Gradient Descent é apenas pegar um lote menor de todo o conjunto de dados e, em seguida, minimizar a perda nele.
Este processo é mais eficiente do que os dois algoritmos de descida de gradiente acima. Agora, o tamanho do lote pode ser o que você quiser.
Mas os pesquisadores mostraram que é melhor mantê-lo entre 1 e 100, sendo 32 o melhor tamanho de lote.
Portanto, o tamanho do lote = 32 é mantido como padrão na maioria das estruturas.
- Loop até a convergência:
- Escolha um lote de pontos de dados ' b '
- Calcular gradiente sobre esse lote
- Atualizar
- Retornar
Conclusão
Agora você tem o entendimento teórico da Regressão Logística. Você aprendeu a representar matematicamente a função logística. Você sabe como medir o erro previsto usando a Função de Custo.
Você também sabe como minimizar essa perda usando o algoritmo Gradient Descent.
Finalmente, você sabe qual variação do algoritmo de descida de gradiente você deve escolher para o seu problema. O upGrad fornece um PG Diploma em Machine Learning e IA e um Master of Science em Machine Learning e IA que podem orientá-lo na construção de uma carreira. Esses cursos explicarão a necessidade de Aprendizado de Máquina e outras etapas para reunir conhecimento neste domínio, abrangendo conceitos variados, desde algoritmos de descida de gradiente até Redes Neurais.
O que é um algoritmo de gradiente descendente?
Descida de gradiente é um algoritmo de otimização para encontrar o mínimo de uma função. Suponha que você queira encontrar o mínimo de uma função f(x) entre dois pontos (a, b) e (c, d) no gráfico de y = f(x). Então a descida do gradiente envolve três etapas: (1) escolha um ponto no meio entre dois pontos finais, (2) calcule o gradiente ∇f(x) (3) mova-se na direção oposta ao gradiente, ou seja, de (c, d) para (a, b). A maneira de pensar sobre isso é que o algoritmo descobre a inclinação da função em um ponto e depois se move na direção oposta à inclinação.
O que é função sigmóide?
A função sigmóide, ou curva sigmóide, é um tipo de função matemática não linear e muito semelhante em forma à letra S (daí o nome). É usado em pesquisa operacional, estatística e outras disciplinas para modelar certas formas de crescimento de valor real. Também é usado em uma ampla gama de aplicações em ciência da computação e engenharia, especialmente em áreas relacionadas a redes neurais e inteligência artificial. As funções sigmóides são usadas como parte das entradas para algoritmos de aprendizado de reforço, que são baseados em redes neurais artificiais.
O que é algoritmo de descida de gradiente estocástico?
Stochastic Gradient Descent é uma das variações populares do algoritmo clássico Gradient Descent para encontrar os mínimos locais da função. O algoritmo escolhe aleatoriamente a direção na qual a função seguirá para minimizar o valor e a direção é repetida até que um mínimo local seja alcançado. O objetivo é que, repetindo continuamente esse processo, o algoritmo convirja para o mínimo global ou local da função.