
Desempenho de front-end 2021: planejamento e métricas
Publicados: 2022-03-10Este guia foi gentilmente apoiado por nossos amigos da LogRocket, um serviço que combina monitoramento de desempenho de front-end , repetição de sessão e análise de produto para ajudá-lo a criar melhores experiências para o cliente. LogRocket rastreia as principais métricas, incl. DOM completo, tempo para o primeiro byte, atraso da primeira entrada, CPU do cliente e uso de memória. Obtenha uma avaliação gratuita do LogRocket hoje.

Índice
- Preparação: planejamento e métricas
Cultura de desempenho, Core Web Vitals, perfis de desempenho, CrUX, Lighthouse, FID, TTI, CLS, dispositivos. - Definir metas realistas
Orçamentos de desempenho, metas de desempenho, estrutura RAIL, orçamentos de 170 KB/30 KB. - Definindo o Ambiente
Escolhendo uma estrutura, custo de desempenho de linha de base, Webpack, dependências, CDN, arquitetura front-end, CSR, SSR, CSR + SSR, renderização estática, pré-renderização, padrão PRPL. - Otimizações de recursos
Brotli, AVIF, WebP, imagens responsivas, AV1, carregamento de mídia adaptável, compactação de vídeo, fontes da web, fontes do Google. - Otimizações de compilação
Módulos JavaScript, padrão de módulo/nomódulo, trepidação de árvore, divisão de código, elevação de escopo, Webpack, serviço diferencial, web worker, WebAssembly, pacotes JavaScript, React, SPA, hidratação parcial, importação na interação, terceiros, cache. - Otimizações de entrega
Carregamento lento, observador de interseção, renderização e decodificação de adiamento, CSS crítico, streaming, dicas de recursos, mudanças de layout, service worker. - Rede, HTTP/2, HTTP/3
Grampeamento OCSP, certificados EV/DV, embalagem, IPv6, QUIC, HTTP/3. - Teste e monitoramento
Fluxo de trabalho de auditoria, navegadores proxy, página 404, prompts de consentimento de cookies GDPR, CSS de diagnóstico de desempenho, acessibilidade. - Vitórias rápidas
- Tudo em uma página
- Baixe a lista de verificação (PDF, Apple Pages, MS Word)
- Assine nossa newsletter por e-mail para não perder os próximos guias.
Preparação: planejamento e métricas
As micro-otimizações são ótimas para manter o desempenho sob controle, mas é fundamental ter em mente metas claramente definidas — metas mensuráveis que influenciariam quaisquer decisões tomadas ao longo do processo. Existem alguns modelos diferentes, e os discutidos abaixo são bastante opinativos – apenas certifique-se de definir suas próprias prioridades desde o início.
- Estabeleça uma cultura de desempenho.
Em muitas organizações, os desenvolvedores front-end sabem exatamente quais são os problemas subjacentes comuns e quais estratégias devem ser usadas para corrigi-los. No entanto, enquanto não houver um endosso estabelecido da cultura de desempenho, cada decisão se transformará em um campo de batalha de departamentos, dividindo a organização em silos. Você precisa da adesão de uma parte interessada nos negócios e, para obtê-la, precisa estabelecer um estudo de caso ou uma prova de conceito sobre como a velocidade - especialmente os principais aspectos vitais da Web , que abordaremos em detalhes mais adiante - beneficia as métricas e os indicadores-chave de desempenho ( KPIs ) com os quais eles se importam.Por exemplo, para tornar o desempenho mais tangível, você pode expor o impacto no desempenho da receita mostrando a correlação entre a taxa de conversão e o tempo de carregamento do aplicativo, bem como o desempenho de renderização. Ou a taxa de rastreamento do bot de pesquisa (PDF, páginas 27–50).
Sem um forte alinhamento entre as equipes de desenvolvimento/design e de negócios/marketing, o desempenho não se sustentará a longo prazo. Estude reclamações comuns que chegam ao atendimento ao cliente e à equipe de vendas, estude análises para altas taxas de rejeição e quedas de conversão. Explore como melhorar o desempenho pode ajudar a aliviar alguns desses problemas comuns. Ajuste o argumento dependendo do grupo de stakeholders com quem você está falando.
Execute experimentos de desempenho e meça os resultados — tanto em dispositivos móveis quanto em computadores (por exemplo, com o Google Analytics). Ele irá ajudá-lo a construir um estudo de caso sob medida para a empresa com dados reais. Além disso, o uso de dados de estudos de caso e experimentos publicados no WPO Stats ajudará a aumentar a sensibilidade dos negócios sobre por que o desempenho é importante e qual o impacto que ele tem na experiência do usuário e nas métricas de negócios. Afirmar que o desempenho importa por si só não é suficiente - você também precisa estabelecer algumas metas mensuráveis e rastreáveis e observá-las ao longo do tempo.
Como chegar lá? Em sua palestra sobre Construindo Desempenho a Longo Prazo, Allison McKnight compartilha um estudo de caso abrangente de como ela ajudou a estabelecer uma cultura de desempenho no Etsy (slides). Mais recentemente, Tammy Everts falou sobre hábitos de equipes de desempenho altamente eficazes em organizações pequenas e grandes.
Ao ter essas conversas nas organizações, é importante ter em mente que, assim como o UX é um espectro de experiências, o desempenho na web é uma distribuição. Como Karolina Szczur observou, "esperar que um único número seja capaz de fornecer uma classificação a que aspirar é uma suposição falha". Portanto, as metas de desempenho precisam ser granulares, rastreáveis e tangíveis.
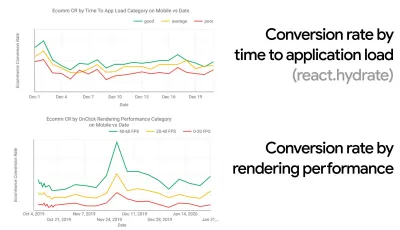
- Objetivo: Ser pelo menos 20% mais rápido que seu concorrente mais rápido.
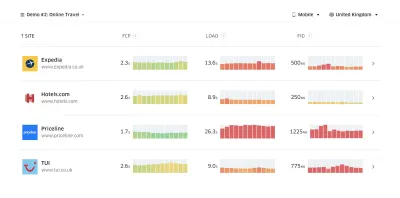
De acordo com pesquisas psicológicas, se você quer que os usuários sintam que seu site é mais rápido que o site do seu concorrente, você precisa ser pelo menos 20% mais rápido. Estude seus principais concorrentes, colete métricas sobre o desempenho deles em dispositivos móveis e desktops e defina limites que o ajudariam a superá-los. No entanto, para obter resultados e metas precisos, certifique-se de obter primeiro uma imagem completa da experiência de seus usuários estudando suas análises. Você pode então imitar a experiência do 90º percentil para teste.Para obter uma boa primeira impressão do desempenho de seus concorrentes, você pode usar o Chrome UX Report ( CrUX , um conjunto de dados RUM pronto, introdução em vídeo de Ilya Grigorik e guia detalhado de Rick Viscomi) ou Treo, uma ferramenta de monitoramento de RUM que é desenvolvido pelo Chrome UX Report. Os dados são coletados dos usuários do navegador Chrome, portanto, os relatórios serão específicos do Chrome, mas fornecerão uma distribuição bastante completa do desempenho, principalmente as pontuações do Core Web Vitals, em uma ampla variedade de visitantes. Observe que novos conjuntos de dados CrUX são lançados na segunda terça-feira de cada mês .
Alternativamente, você também pode usar:
- Ferramenta de comparação de relatórios de UX do Chrome de Addy Osmani,
- Speed Scorecard (também fornece um estimador de impacto de receita),
- Comparação real do teste de experiência do usuário ou
- SiteSpeed CI (baseado em testes sintéticos).
Observação : se você usar o Page Speed Insights ou a API do Page Speed Insights (não, ele não está obsoleto!), poderá obter dados de desempenho do CrUX para páginas específicas em vez de apenas os agregados. Esses dados podem ser muito mais úteis para definir metas de desempenho para recursos como "página de destino" ou "lista de produtos". E se você estiver usando CI para testar os orçamentos, você precisa ter certeza de que seu ambiente testado corresponde ao CrUX se você usou o CrUX para definir o destino ( obrigado Patrick Meenan! ).
Se você precisar de ajuda para mostrar o raciocínio por trás da priorização da velocidade, ou quiser visualizar o declínio da taxa de conversão ou o aumento da taxa de rejeição com desempenho mais lento, ou talvez precise defender uma solução RUM em sua organização, Sergey Chernyshev construiu uma UX Speed Calculator, uma ferramenta de código aberto que ajuda você a simular dados e visualizá-los para direcionar seu ponto de vista.
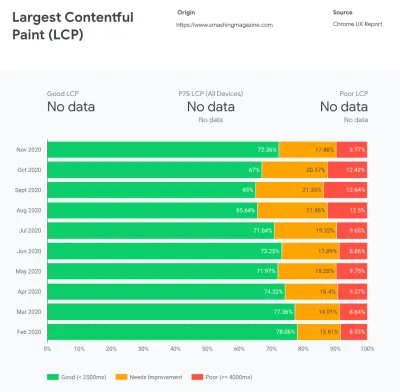
O CrUX gera uma visão geral das distribuições de desempenho ao longo do tempo, com o tráfego coletado dos usuários do Google Chrome. Você pode criar o seu próprio no Chrome UX Dashboard. (Visualização grande) 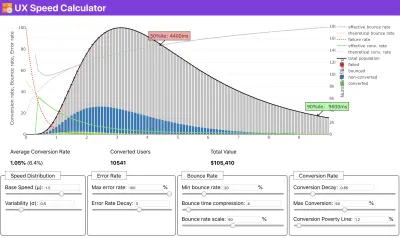
Exatamente quando você precisa defender o desempenho para impulsionar seu ponto de vista: o UX Speed Calculator visualiza um impacto do desempenho nas taxas de rejeição, conversão e receita total - com base em dados reais. (Visualização grande) Às vezes, você pode querer ir um pouco mais fundo, combinando os dados provenientes do CrUX com quaisquer outros dados que você já tenha para descobrir rapidamente onde estão as lentidão, pontos cegos e ineficiências - para seus concorrentes ou para seu projeto. Em seu trabalho, Harry Roberts tem usado uma Planilha de Topografia de Velocidade de Site que ele usa para dividir o desempenho por tipos de página principais e rastrear como as métricas principais são diferentes entre elas. Você pode baixar a planilha como Planilhas Google, Excel, documento OpenOffice ou CSV.
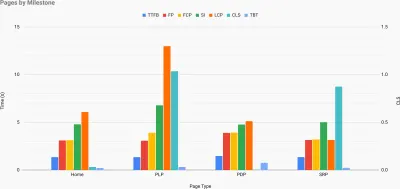
Topografia de velocidade do site, com as principais métricas representadas para as principais páginas do site. (Visualização grande) E se você quiser ir até o fim, pode executar uma auditoria de desempenho do Lighthouse em todas as páginas de um site (via Lightouse Parade), com uma saída salva como CSV. Isso ajudará você a identificar quais páginas específicas (ou tipos de páginas) de seus concorrentes têm um desempenho pior ou melhor e em que você pode concentrar seus esforços. (Para seu próprio site, provavelmente é melhor enviar dados para um endpoint de análise!).

Com o Lighthouse Parade, você pode executar uma auditoria de desempenho do Lighthouse em todas as páginas de um site, com uma saída salva como CSV. (Visualização grande) Colete dados, monte uma planilha, reduza 20% e defina suas metas ( orçamentos de desempenho ) dessa maneira. Agora você tem algo mensurável para testar. Se você está mantendo o orçamento em mente e tentando enviar apenas a carga útil mínima para obter um tempo rápido de interação, então você está no caminho razoável.
Precisa de recursos para começar?
- Addy Osmani escreveu um artigo muito detalhado sobre como iniciar o orçamento de desempenho, como quantificar o impacto de novos recursos e por onde começar quando estiver acima do orçamento.
- O guia de Lara Hogan sobre como abordar projetos com um orçamento de desempenho pode fornecer dicas úteis para designers.
- Harry Roberts publicou um guia sobre como configurar uma planilha do Google para exibir o impacto de scripts de terceiros no desempenho, usando o Request Map,
- A calculadora de orçamento de desempenho de Jonathan Fielding, a calculadora de orçamento de desempenho de Katie Hempenius e as calorias do navegador podem ajudar na criação de orçamentos (graças a Karolina Szczur pelo aviso).
- Em muitas empresas, os orçamentos de desempenho não devem ser aspiracionais, mas sim pragmáticos, servindo como um sinal de espera para evitar passar de um certo ponto. Nesse caso, você pode escolher seu pior ponto de dados nas últimas duas semanas como um limite e a partir daí. Orçamentos de desempenho, pragmaticamente mostra uma estratégia para conseguir isso.
- Além disso, torne o orçamento de desempenho e o desempenho atual visíveis configurando painéis com tamanhos de compilação de relatórios de gráficos. Existem muitas ferramentas que permitem que você faça isso: o painel SiteSpeed.io (código aberto), SpeedCurve e Caliber são apenas algumas delas, e você pode encontrar mais ferramentas em perf.rocks.

As calorias do navegador ajudam você a definir um orçamento de desempenho e medir se uma página está excedendo esses números ou não. (Visualização grande) Depois de ter um orçamento definido, incorpore-os em seu processo de criação com Webpack Performance Hints and Bundlesize, Lighthouse CI, PWMetrics ou Sitespeed CI para impor orçamentos em pull requests e fornecer um histórico de pontuação nos comentários de PR.
Para expor orçamentos de desempenho para toda a equipe, integre orçamentos de desempenho no Lighthouse por meio do Lightwallet ou use o LHCI Action para integração rápida do Github Actions. E se precisar de algo personalizado, você pode usar webpagetest-charts-api, uma API de endpoints para construir gráficos a partir dos resultados do WebPagetest.
No entanto, a conscientização sobre o desempenho não deve vir apenas dos orçamentos de desempenho. Assim como o Pinterest, você pode criar uma regra eslint personalizada que não permita a importação de arquivos e diretórios que são conhecidos por serem muito dependentes e sobrecarregariam o pacote. Configure uma lista de pacotes “seguros” que podem ser compartilhados com toda a equipe.
Além disso, pense nas tarefas críticas do cliente que são mais benéficas para o seu negócio. Estude, discuta e defina limites de tempo aceitáveis para ações críticas e estabeleça marcas de tempo de usuário "UX ready" que toda a organização aprovou. Em muitos casos, as jornadas do usuário afetarão o trabalho de muitos departamentos diferentes, portanto, o alinhamento em termos de tempos aceitáveis ajudará a apoiar ou evitar discussões de desempenho no futuro. Certifique-se de que os custos adicionais de recursos e recursos adicionados sejam visíveis e compreendidos.
Alinhe os esforços de desempenho com outras iniciativas de tecnologia, desde novos recursos do produto que está sendo criado até a refatoração para alcançar novos públicos globais. Então, toda vez que uma conversa sobre desenvolvimento adicional acontece, o desempenho também faz parte dessa conversa. É muito mais fácil atingir metas de desempenho quando a base de código é nova ou está apenas sendo refatorada.
Além disso, como sugeriu Patrick Meenan, vale a pena planejar uma sequência de carregamento e compensações durante o processo de design. Se você priorizar antecipadamente quais partes são mais críticas e definir a ordem em que elas devem aparecer, também saberá o que pode ser atrasado. Idealmente, essa ordem também refletirá a sequência de suas importações de CSS e JavaScript, portanto, será mais fácil manuseá-las durante o processo de compilação. Além disso, considere qual deve ser a experiência visual nos estados "intermediários", enquanto a página está sendo carregada (por exemplo, quando as fontes da Web ainda não foram carregadas).
Depois de estabelecer uma forte cultura de desempenho em sua organização, tente ser 20% mais rápido do que seu antigo eu para manter as prioridades intactas com o passar do tempo ( obrigado, Guy Podjarny! ). Mas considere os diferentes tipos e comportamentos de uso de seus clientes (que Tobias Baldauf chamou de cadência e coortes), juntamente com o tráfego de bots e efeitos de sazonalidade.
Planejamento, planejamento, planejamento. Pode ser tentador entrar em algumas otimizações rápidas de "frutos fáceis" no início - e pode ser uma boa estratégia para ganhos rápidos - mas será muito difícil manter o desempenho como prioridade sem planejamento e definição de empresas realistas. - metas de desempenho personalizadas.
- Escolha as métricas certas.
Nem todas as métricas são igualmente importantes. Estude quais métricas são mais importantes para seu aplicativo: geralmente, elas serão definidas pela rapidez com que você pode começar a renderizar os pixels mais importantes da sua interface e com que rapidez você pode fornecer resposta de entrada para esses pixels renderizados. Esse conhecimento lhe dará a melhor meta de otimização para esforços contínuos. No final, não são os eventos de carregamento ou os tempos de resposta do servidor que definem a experiência, mas a percepção de quão ágil a interface parece .O que isto significa? Em vez de se concentrar no tempo de carregamento da página inteira (por meio de horários onLoad e DOMContentLoaded , por exemplo), priorize o carregamento da página conforme percebido por seus clientes. Isso significa focar em um conjunto ligeiramente diferente de métricas. Na verdade, escolher a métrica certa é um processo sem vencedores óbvios.
Com base na pesquisa de Tim Kadlec e nas notas de Marcos Iglesias em sua palestra, as métricas tradicionais podem ser agrupadas em alguns conjuntos. Normalmente, precisaremos de todos eles para obter uma visão completa do desempenho e, no seu caso particular, alguns deles serão mais importantes do que outros.
- Métricas baseadas em quantidade medem o número de solicitações, peso e pontuação de desempenho. Bom para disparar alarmes e monitorar mudanças ao longo do tempo, não tão bom para entender a experiência do usuário.
- As métricas de marco usam estados no tempo de vida do processo de carregamento, por exemplo, Tempo até o primeiro byte e Tempo até a interação . Bom para descrever a experiência do usuário e monitoramento, não tão bom para saber o que acontece entre os marcos.
- As métricas de renderização fornecem uma estimativa de quão rápido o conteúdo é renderizado (por exemplo, tempo de renderização inicial , índice de velocidade ). Bom para medir e ajustar o desempenho de renderização, mas não tão bom para medir quando um conteúdo importante aparece e pode interagir.
- Métricas personalizadas medem um evento específico e personalizado para o usuário, por exemplo, Time To First Tweet do Twitter e PinnerWaitTime do Pinterest. Bom para descrever a experiência do usuário com precisão, não tão bom para dimensionar as métricas e comparar com os concorrentes.
Para completar o quadro, normalmente procuramos métricas úteis entre todos esses grupos. Normalmente, os mais específicos e relevantes são:
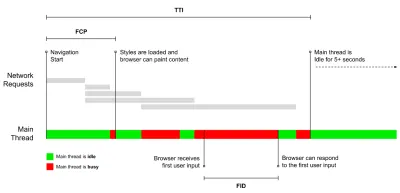
- Tempo para Interação (TTI)
O ponto em que o layout se estabilizou , as principais fontes da web ficam visíveis e o encadeamento principal está disponível o suficiente para lidar com a entrada do usuário - basicamente a marca de tempo em que um usuário pode interagir com a interface do usuário. As principais métricas para entender quanto tempo um usuário precisa esperar para usar o site sem atrasos. Boris Schapira escreveu um post detalhado sobre como medir o ITT de forma confiável. - Atraso da primeira entrada (FID) ou responsividade de entrada
O tempo desde quando um usuário interage pela primeira vez com seu site até o momento em que o navegador é realmente capaz de responder a essa interação. Complementa muito bem o TTI, pois descreve a parte que falta na imagem: o que acontece quando um usuário realmente interage com o site. Destinado apenas como uma métrica RUM. Existe uma biblioteca JavaScript para medir o FID no navegador. - Maior pintura de conteúdo (LCP)
Marca o ponto na linha do tempo de carregamento da página quando o conteúdo importante da página provavelmente foi carregado. A suposição é que o elemento mais importante da página seja o maior visível na janela de visualização do usuário. Se os elementos forem renderizados acima e abaixo da dobra, apenas a parte visível será considerada relevante. - Tempo Total de Bloqueio ( TBT )
Uma métrica que ajuda a quantificar a gravidade de quão não interativa é uma página antes de se tornar confiavelmente interativa (ou seja, o encadeamento principal está livre de quaisquer tarefas executando mais de 50ms ( tarefas longas ) por pelo menos 5s). A métrica mede a quantidade total de tempo entre a primeira pintura e o Tempo para Interação (TTI) em que o encadeamento principal foi bloqueado por tempo suficiente para impedir a resposta de entrada. Não é de admirar, então, que um TBT baixo seja um bom indicador de bom desempenho. (obrigado, Artem, Phil) - Mudança de layout cumulativa ( CLS )
A métrica destaca a frequência com que os usuários experimentam mudanças inesperadas de layout ( refluxos ) ao acessar o site. Ele examina elementos instáveis e seu impacto na experiência geral. Quanto menor a pontuação, melhor. - Índice de velocidade
Mede a rapidez com que o conteúdo da página é preenchido visualmente; quanto menor a pontuação, melhor. A pontuação do Índice de Velocidade é calculada com base na velocidade do progresso visual , mas é apenas um valor calculado. Também é sensível ao tamanho da janela de visualização, portanto, você precisa definir uma variedade de configurações de teste que correspondam ao seu público-alvo. Observe que está se tornando menos importante com o LCP se tornando uma métrica mais relevante ( obrigado, Boris, Artem! ). - Tempo de CPU gasto
Uma métrica que mostra com que frequência e por quanto tempo o thread principal está bloqueado, trabalhando na pintura, renderização, script e carregamento. O alto tempo de CPU é um indicador claro de uma experiência ruim , ou seja, quando o usuário experimenta um atraso perceptível entre sua ação e uma resposta. Com o WebPageTest, você pode selecionar "Capture Dev Tools Timeline" na guia "Chrome" para expor o detalhamento do thread principal conforme ele é executado em qualquer dispositivo usando o WebPageTest. - Custos de CPU em nível de componente
Assim como o tempo gasto na CPU , essa métrica, proposta por Stoyan Stefanov, explora o impacto do JavaScript na CPU . A ideia é usar a contagem de instruções da CPU por componente para entender seu impacto na experiência geral, isoladamente. Pode ser implementado usando Puppeteer e Chrome. - Índice de frustração
Embora muitas métricas apresentadas acima expliquem quando um determinado evento acontece, o FrustrationIndex de Tim Vereecke analisa as lacunas entre as métricas em vez de analisá-las individualmente. Ele analisa os principais marcos percebidos pelo usuário final, como o título é visível, o primeiro conteúdo é visível, visualmente pronto e a página parece pronta e calcula uma pontuação indicando o nível de frustração ao carregar uma página. Quanto maior a lacuna, maior a chance de um usuário ficar frustrado. Potencialmente um bom KPI para a experiência do usuário. Tim publicou um post detalhado sobre FrustrationIndex e como ele funciona. - Impacto da ponderação do anúncio
Se o seu site depende da receita gerada pela publicidade, é útil acompanhar o peso do código relacionado ao anúncio. O script de Paddy Ganti constrói duas URLs (uma normal e outra bloqueando os anúncios), solicita a geração de uma comparação de vídeo via WebPageTest e informa um delta. - Métricas de desvio
Conforme observado pelos engenheiros da Wikipedia, os dados de quanta variação existe em seus resultados podem informar o quão confiáveis são seus instrumentos e quanta atenção você deve prestar a desvios e outlers. Grande variação é um indicador de ajustes necessários na configuração. Também ajuda a entender se certas páginas são mais difíceis de medir de forma confiável, por exemplo, devido a scripts de terceiros que causam variação significativa. Também pode ser uma boa ideia rastrear a versão do navegador para entender os impactos no desempenho quando uma nova versão do navegador é lançada. - Métricas personalizadas
As métricas personalizadas são definidas pelas necessidades do seu negócio e pela experiência do cliente. Ele exige que você identifique pixels importantes , scripts críticos , CSS necessário e ativos relevantes e meça a rapidez com que eles são entregues ao usuário. Para isso, você pode monitorar os tempos de renderização de heróis ou usar a API Performance, marcando timestamps específicos para eventos importantes para sua empresa. Além disso, você pode coletar métricas personalizadas com WebPagetest executando JavaScript arbitrário no final de um teste.
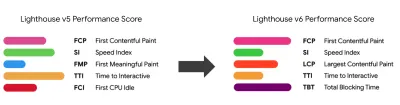
Observe que a primeira pintura significativa (FMP) não aparece na visão geral acima. Ele costumava fornecer uma visão sobre a rapidez com que o servidor gera qualquer dado. O FMP longo geralmente indicava JavaScript bloqueando o thread principal, mas também pode estar relacionado a problemas de back-end/servidor. No entanto, a métrica foi preterida recentemente, pois parece não ser precisa em cerca de 20% dos casos. Ele foi efetivamente substituído pelo LCP, que é mais confiável e mais fácil de raciocinar. Não é mais suportado no Lighthouse. Verifique novamente as métricas e recomendações de desempenho centradas no usuário mais recentes apenas para garantir que você esteja na página segura ( obrigado, Patrick Meenan ).

Steve Souders tem uma explicação detalhada de muitas dessas métricas. É importante observar que, embora o tempo para interação seja medido pela execução de auditorias automatizadas no chamado ambiente de laboratório , o atraso da primeira entrada representa a experiência real do usuário, com os usuários reais experimentando um atraso perceptível. Em geral, provavelmente é uma boa ideia sempre medir e acompanhar os dois.
Dependendo do contexto do seu aplicativo, as métricas preferidas podem diferir: por exemplo, para a interface do usuário da TV Netflix, a capacidade de resposta de entrada de teclas, o uso de memória e o TTI são mais críticos e, para a Wikipedia, as primeiras/últimas alterações visuais e as métricas de tempo de CPU são mais importantes.
Observação : tanto o FID quanto o TTI não levam em conta o comportamento de rolagem; a rolagem pode acontecer de forma independente, pois é fora do thread principal, portanto, para muitos sites de consumo de conteúdo, essas métricas podem ser muito menos importantes ( obrigado, Patrick! ).
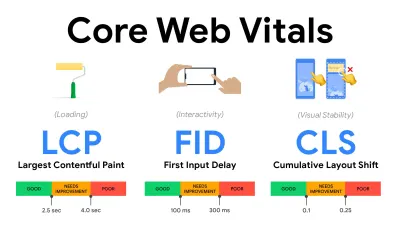
- Meça e otimize os Core Web Vitals .
Por muito tempo, as métricas de desempenho eram bastante técnicas, focando na visão de engenharia de quão rápido os servidores estão respondendo e quão rápidos os navegadores estão carregando. As métricas mudaram ao longo dos anos – tentando encontrar uma maneira de capturar a experiência real do usuário, em vez dos horários do servidor. Em maio de 2020, o Google anunciou o Core Web Vitals, um conjunto de novas métricas de desempenho focadas no usuário, cada uma representando uma faceta distinta da experiência do usuário.Para cada um deles, o Google recomenda uma série de metas de velocidade aceitáveis. Pelo menos 75% de todas as visualizações de página devem exceder o intervalo Bom para passar nessa avaliação. Essas métricas ganharam força rapidamente e, com o Core Web Vitals se tornando sinais de classificação para a Pesquisa do Google em maio de 2021 ( atualização do algoritmo de classificação da experiência da página ), muitas empresas voltaram sua atenção para suas pontuações de desempenho.
Vamos detalhar cada um dos Core Web Vitals, um por um, juntamente com técnicas e ferramentas úteis para otimizar suas experiências com essas métricas em mente. (Vale a pena notar que você terminará com melhores pontuações no Core Web Vitals seguindo um conselho geral neste artigo.)
- Maior pintura de conteúdo ( LCP ) < 2,5 seg.
Mede o carregamento de uma página e informa o tempo de renderização da maior imagem ou bloco de texto visível na janela de visualização. Portanto, o LCP é afetado por tudo o que está adiando a renderização de informações importantes - sejam tempos de resposta lentos do servidor, CSS bloqueando, JavaScript em andamento (primário ou de terceiros), carregamento de fonte da Web, renderização cara ou operações de pintura, -carregadas de imagens, telas de esqueleto ou renderização do lado do cliente.
Para uma boa experiência, o LCP deve ocorrer dentro de 2,5 segundos após o início do carregamento da página. Isso significa que precisamos renderizar a primeira parte visível da página o mais cedo possível. Isso exigirá CSS crítico personalizado para cada modelo, orquestrando o<head>-order e pré-buscando ativos críticos (vamos cobri-los mais tarde).A principal razão para uma baixa pontuação no LCP geralmente são as imagens. Para entregar um LCP em <2,5s em Fast 3G — hospedado em um servidor bem otimizado, todo estático sem renderização do lado do cliente e com uma imagem proveniente de um CDN de imagem dedicado — significa que o tamanho máximo teórico da imagem é de apenas 144 KB . É por isso que imagens responsivas são importantes, além de pré-carregar imagens críticas antecipadamente (com
preload).Dica rápida : para descobrir o que é considerado LCP em uma página, no DevTools você pode passar o mouse sobre o selo LCP em "Tempos" no Painel de Desempenho ( obrigado, Tim Kadlec !).
- Atraso da primeira entrada ( FID ) < 100ms.
Mede a capacidade de resposta da interface do usuário, ou seja, quanto tempo o navegador estava ocupado com outras tarefas antes que pudesse reagir a um evento discreto de entrada do usuário, como um toque ou um clique. Ele foi projetado para capturar atrasos resultantes do encadeamento principal estar ocupado, especialmente durante o carregamento da página.
O objetivo é ficar entre 50 e 100 ms para cada interação. Para chegar lá, precisamos identificar tarefas longas (bloqueia o encadeamento principal por > 50ms) e dividi-las, dividir um pacote em vários pedaços, reduzir o tempo de execução do JavaScript, otimizar a busca de dados, adiar a execução de scripts de terceiros , mova o JavaScript para o thread em segundo plano com Web workers e use hidratação progressiva para reduzir os custos de reidratação em SPAs.Dica rápida : em geral, uma estratégia confiável para obter uma pontuação FID melhor é minimizar o trabalho no encadeamento principal , dividindo pacotes maiores em menores e atendendo o que o usuário precisa quando precisar, para que as interações do usuário não sejam atrasadas . Cobriremos mais sobre isso em detalhes abaixo.
- Deslocamento cumulativo de layout ( CLS ) < 0,1.
Mede a estabilidade visual da interface do usuário para garantir interações suaves e naturais, ou seja, a soma total de todas as pontuações de mudança de layout individual para cada mudança de layout inesperada que ocorre durante a vida útil da página. Uma mudança de layout individual ocorre sempre que um elemento que já estava visível muda sua posição na página. É pontuado com base no tamanho do conteúdo e na distância que ele moveu.
Assim, toda vez que uma mudança aparece - por exemplo, quando fontes de fallback e fontes da Web têm métricas de fonte diferentes, ou anúncios, incorporações ou iframes chegando atrasados, ou dimensões de imagem/vídeo não são reservadas, ou CSS atrasado força repinturas ou alterações são injetadas por JavaScript atrasado — tem um impacto na pontuação do CLS. O valor recomendado para uma boa experiência é um CLS < 0,1.
Vale a pena notar que os Core Web Vitals devem evoluir ao longo do tempo, com um ciclo anual previsível . Para a atualização do primeiro ano, podemos esperar que o First Contentful Paint seja promovido a Core Web Vitals, um limite FID reduzido e melhor suporte para aplicativos de página única. Também podemos ver a resposta às entradas do usuário após a carga ganhando mais peso, juntamente com considerações de segurança, privacidade e acessibilidade (!).
Relacionados aos Core Web Vitals, há muitos recursos e artigos úteis que valem a pena serem analisados:
- O Web Vitals Leaderboard permite que você compare suas pontuações com a concorrência em dispositivos móveis, tablets, desktops e em 3G e 4G.
- Core SERP Vitals, uma extensão do Chrome que mostra os Core Web Vitals do CrUX nos resultados de pesquisa do Google.
- Layout Shift GIF Generator que visualiza o CLS com um GIF simples (também disponível na linha de comando).
- A biblioteca web-vitals pode coletar e enviar Core Web Vitals para o Google Analytics, Google Tag Manager ou qualquer outro endpoint de análise.
- Analisando Web Vitals com WebPageTest, em que Patrick Meenan explora como WebPageTest expõe dados sobre Core Web Vitals.
- Otimizando com o Core Web Vitals, um vídeo de 50 minutos com Addy Osmani, no qual ele destaca como melhorar o Core Web Vitals em um estudo de caso de comércio eletrônico.
- Mudança de layout cumulativa na prática e Mudança de layout cumulativa no mundo real são artigos abrangentes de Nic Jansma, que cobrem praticamente tudo sobre o CLS e como ele se correlaciona com as principais métricas, como taxa de rejeição, tempo de sessão ou cliques de raiva.
- O que força o Reflow, com uma visão geral das propriedades ou métodos, quando solicitados/chamados em JavaScript, que acionarão o navegador para calcular de forma síncrona o estilo e o layout.
- CSS Triggers mostra quais propriedades CSS acionam Layout, Paint e Composite.
- Corrigindo a instabilidade de layout é um passo a passo do uso do WebPageTest para identificar e corrigir problemas de instabilidade de layout.
- Mudança de layout cumulativa, a métrica de instabilidade de layout, outro guia muito detalhado de Boris Schapira sobre CLS, como é calculado, como medir e como otimizar para isso.
- How To Improve Core Web Vitals, um guia detalhado de Simon Hearne sobre cada uma das métricas (incluindo outros Web Vitals, como FCP, TTI, TBT), quando ocorrem e como são medidos.
Então, os Core Web Vitals são as métricas finais a serem seguidas ? Não exatamente. Eles já estão expostos na maioria das soluções e plataformas RUM, incluindo Cloudflare, Treo, SpeedCurve, Calibre, WebPageTest (já na visualização da tira de filme), Newrelic, Shopify, Next.js, todas as ferramentas do Google (PageSpeed Insights, Lighthouse + CI, Search Console etc.) e muitos outros.
No entanto, como explica Katie Sylor-Miller, alguns dos principais problemas com o Core Web Vitals são a falta de suporte entre navegadores, não medimos realmente o ciclo de vida completo da experiência de um usuário, além de ser difícil correlacionar alterações no FID e CLS com resultados de negócios.
Como devemos esperar que os Core Web Vitals evoluam, parece razoável sempre combinar os Web Vitals com suas métricas personalizadas para obter uma melhor compreensão de onde você está em termos de desempenho.
- Maior pintura de conteúdo ( LCP ) < 2,5 seg.
- Reúna dados em um dispositivo representativo do seu público.
Para coletar dados precisos, precisamos escolher cuidadosamente os dispositivos para testar. Na maioria das empresas, isso significa analisar análises e criar perfis de usuários com base nos tipos de dispositivos mais comuns. No entanto, muitas vezes, a análise por si só não fornece uma imagem completa. Uma parte significativa do público-alvo pode estar abandonando o site (e não retornando) apenas porque sua experiência é muito lenta e é improvável que seus dispositivos apareçam como os dispositivos mais populares em análises por esse motivo. Portanto, realizar pesquisas adicionais em dispositivos comuns em seu grupo-alvo pode ser uma boa ideia.Globalmente, em 2020, de acordo com o IDC, 84,8% de todos os telefones celulares enviados são dispositivos Android. Um consumidor médio atualiza seu telefone a cada 2 anos e, nos EUA, o ciclo de substituição do telefone é de 33 meses. A média de telefones mais vendidos em todo o mundo custará menos de US $ 200.
Um dispositivo representativo, então, é um dispositivo Android com pelo menos 24 meses , custando US$ 200 ou menos, rodando em 3G lento, 400ms RTT e transferência de 400kbps, só para ser um pouco mais pessimista. Isso pode ser muito diferente para sua empresa, é claro, mas é uma aproximação bastante próxima da maioria dos clientes por aí. Na verdade, pode ser uma boa ideia pesquisar os best-sellers atuais da Amazon para o seu mercado-alvo. ( Obrigado a Tim Kadlec, Henri Helvetica e Alex Russell pelas dicas! ).
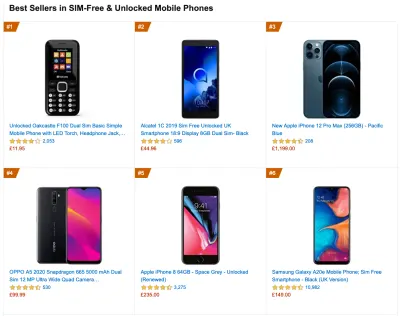
Ao criar um novo site ou aplicativo, sempre verifique primeiro os Amazon Best Sellers atuais para seu mercado-alvo. (Visualização grande) Que dispositivos de teste escolher então? Aqueles que se encaixam bem com o perfil descrito acima. É uma boa opção escolher um Moto G4/G5 Plus um pouco mais antigo, um dispositivo Samsung de gama média (Galaxy A50, S8), um bom dispositivo intermediário como um Nexus 5X, Xiaomi Mi A3 ou Xiaomi Redmi Note 7 e um dispositivo lento como Alcatel 1X ou Cubot X19, talvez em um laboratório de dispositivos aberto. Para testar em dispositivos térmicos mais lentos, você também pode obter um Nexus 4, que custa cerca de US$ 100.
Além disso, verifique os chipsets usados em cada dispositivo e não represente demais um chipset : algumas gerações de Snapdragon e Apple, bem como Rockchip de baixo custo, Mediatek seriam suficientes (obrigado, Patrick!) .
Se você não tiver um dispositivo em mãos, emule a experiência móvel no desktop testando em uma rede 3G limitada (por exemplo, 300ms RTT, 1,6 Mbps para baixo, 0,8 Mbps para cima) com uma CPU limitada (5× desaceleração). Eventualmente, mude para 3G normal, 4G lento (por exemplo, 170ms RTT, 9 Mbps para baixo, 9 Mbps para cima) e Wi-Fi. Para tornar o impacto no desempenho mais visível, você pode até mesmo introduzir o 2G às terças-feiras ou configurar uma rede 3G/4G limitada em seu escritório para testes mais rápidos.
Tenha em mente que em um dispositivo móvel, devemos esperar uma desaceleração de 4×–5× em comparação com computadores desktop. Os dispositivos móveis têm diferentes GPUs, CPU, memória e características de bateria diferentes. Por isso é importante ter um bom perfil de um aparelho mediano e sempre testar nesse aparelho.
- As ferramentas de teste sintético coletam dados de laboratório em um ambiente reproduzível com configurações predefinidas de dispositivo e rede (por exemplo, Lighthouse , Caliber , WebPageTest ) e
- As ferramentas Real User Monitoring ( RUM ) avaliam as interações do usuário continuamente e coletam dados de campo (por exemplo, SpeedCurve , New Relic — as ferramentas também fornecem testes sintéticos).
- use o Lighthouse CI para rastrear as pontuações do Lighthouse ao longo do tempo (é bastante impressionante),
- execute o Lighthouse no GitHub Actions para obter um relatório do Lighthouse junto com cada PR,
- execute uma auditoria de desempenho do Lighthouse em cada página de um site (via Lightouse Parade), com uma saída salva como CSV,
- use a Calculadora de Pontuações do Lighthouse e os pesos das métricas do Lighthouse se precisar se aprofundar em mais detalhes.
- O Lighthouse também está disponível para o Firefox, mas sob o capô ele usa a API PageSpeed Insights e gera um relatório com base em um Chrome 79 User-Agent headless.

Felizmente, existem muitas opções excelentes que ajudam você a automatizar a coleta de dados e medir o desempenho do seu site ao longo do tempo de acordo com essas métricas. Tenha em mente que uma boa imagem de desempenho abrange um conjunto de métricas de desempenho, dados de laboratório e dados de campo:
O primeiro é particularmente útil durante o desenvolvimento , pois ajudará você a identificar, isolar e corrigir problemas de desempenho enquanto trabalha no produto. O último é útil para manutenção de longo prazo, pois ajudará você a entender seus gargalos de desempenho à medida que eles acontecem ao vivo — quando os usuários realmente acessam o site.
Ao tocar em APIs RUM integradas, como Navigation Timing, Resource Timing, Paint Timing, Long Tasks, etc., as ferramentas de teste sintético e o RUM juntos fornecem uma imagem completa do desempenho em seu aplicativo. Você pode usar Calibre, Treo, SpeedCurve, mPulse e Boomerang, Sitespeed.io, que são ótimas opções para monitoramento de desempenho. Além disso, com o cabeçalho Server Timing, você pode até monitorar o desempenho de back-end e front-end em um só lugar.
Nota : É sempre uma aposta mais segura escolher aceleradores de nível de rede, externos ao navegador, pois, por exemplo, o DevTools tem problemas ao interagir com o push HTTP/2, devido à forma como ele é implementado ( obrigado, Yoav, Patrick !). Para Mac OS, podemos usar o Network Link Conditioner, para Windows Windows Traffic Shaper, para Linux netem e para FreeBSD dummynet.
Como é provável que você esteja testando no Lighthouse, lembre-se de que você pode:
- Configure perfis "limpo" e "cliente" para teste.
Ao executar testes em ferramentas de monitoramento passivo, é uma estratégia comum desativar tarefas antivírus e de CPU em segundo plano, remover transferências de largura de banda em segundo plano e testar com um perfil de usuário limpo sem extensões de navegador para evitar resultados distorcidos (no Firefox e no Chrome).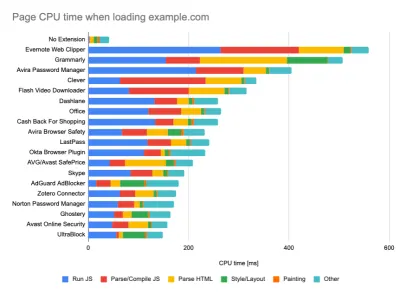
O relatório do DebugBear destaca as 20 extensões mais lentas, incluindo gerenciadores de senhas, bloqueadores de anúncios e aplicativos populares como Evernote e Grammarly. (Visualização grande) No entanto, também é uma boa ideia estudar quais extensões de navegador seus clientes usam com frequência e testar também com perfis de "cliente" dedicados. Na verdade, algumas extensões podem ter um impacto profundo no desempenho (Relatório de desempenho de extensões do Chrome 2020) em seu aplicativo e, se seus usuários as usarem muito, convém considerar isso antecipadamente. Portanto, os resultados de perfil "limpos" por si só são excessivamente otimistas e podem ser esmagados em cenários da vida real.
- Compartilhe as metas de desempenho com seus colegas.
Certifique-se de que as metas de desempenho sejam familiares a todos os membros de sua equipe para evitar mal-entendidos no futuro. Cada decisão – seja design, marketing ou qualquer coisa intermediária – tem implicações de desempenho , e a distribuição de responsabilidade e propriedade por toda a equipe simplificaria as decisões focadas no desempenho posteriormente. Mapeie as decisões de design em relação ao orçamento de desempenho e às prioridades definidas desde o início.
Índice
- Preparação: planejamento e métricas
- Definir metas realistas
- Definindo o Ambiente
- Otimizações de recursos
- Otimizações de compilação
- Otimizações de entrega
- Rede, HTTP/2, HTTP/3
- Teste e monitoramento
- Vitórias rápidas
- Tudo em uma página
- Baixe a lista de verificação (PDF, Apple Pages, MS Word)
- Assine nossa newsletter por e-mail para não perder os próximos guias.