
Lista de verificação de desempenho de front-end 2021 (PDF, Apple Pages, MS Word)
Publicados: 2022-03-10Este guia foi gentilmente apoiado por nossos amigos da LogRocket, um serviço que combina monitoramento de desempenho de front-end , repetição de sessão e análise de produto para ajudá-lo a criar melhores experiências para o cliente. LogRocket rastreia as principais métricas, incl. DOM completo, tempo para o primeiro byte, atraso da primeira entrada, CPU do cliente e uso de memória. Obtenha uma avaliação gratuita do LogRocket hoje.

O desempenho da Web é uma fera complicada, não é? Como realmente sabemos onde estamos em termos de desempenho e quais são exatamente nossos gargalos de desempenho? É JavaScript caro, entrega lenta de fontes da Web, imagens pesadas ou renderização lenta? Otimizamos o suficiente com trepidação de árvores, elevação de escopo, divisão de código e todos os padrões de carregamento sofisticados com observador de interseção, hidratação progressiva, dicas de clientes, HTTP/3, service workers e — oh meu — edge workers? E, mais importante, por onde começamos a melhorar o desempenho e como estabelecemos uma cultura de desempenho a longo prazo?
Antigamente, o desempenho era muitas vezes uma mera reflexão tardia . Muitas vezes adiado até o final do projeto, se resumiria a minificação, concatenação, otimização de ativos e potencialmente alguns ajustes finos no arquivo de config do servidor. Olhando para trás agora, as coisas parecem ter mudado bastante.
O desempenho não é apenas uma preocupação técnica: afeta tudo, desde a acessibilidade à usabilidade até a otimização do mecanismo de pesquisa e, ao incluí-lo no fluxo de trabalho, as decisões de design precisam ser informadas por suas implicações de desempenho. O desempenho deve ser medido, monitorado e refinado continuamente , e a crescente complexidade da web apresenta novos desafios que dificultam o acompanhamento das métricas, pois os dados variam significativamente dependendo do dispositivo, navegador, protocolo, tipo de rede e latência ( CDNs, ISPs, caches, proxies, firewalls, balanceadores de carga e servidores desempenham um papel no desempenho).
Então, se criássemos uma visão geral de todas as coisas que devemos ter em mente ao melhorar o desempenho – desde o início do projeto até o lançamento final do site – como seria? Abaixo, você encontrará uma lista de verificação de desempenho de front-end (espero que imparcial e objetiva) para 2021 - uma visão geral atualizada dos problemas que você pode precisar considerar para garantir que seus tempos de resposta sejam rápidos, a interação do usuário seja suave e seus sites não drenar a largura de banda do usuário.
Índice
- Tudo em páginas separadas
- Preparação: planejamento e métricas
Cultura de desempenho, Core Web Vitals, perfis de desempenho, CrUX, Lighthouse, FID, TTI, CLS, dispositivos. - Definir metas realistas
Orçamentos de desempenho, metas de desempenho, estrutura RAIL, orçamentos de 170 KB/30 KB. - Definindo o Ambiente
Escolhendo uma estrutura, custo de desempenho de linha de base, Webpack, dependências, CDN, arquitetura front-end, CSR, SSR, CSR + SSR, renderização estática, pré-renderização, padrão PRPL. - Otimizações de recursos
Brotli, AVIF, WebP, imagens responsivas, AV1, carregamento de mídia adaptável, compactação de vídeo, fontes da web, fontes do Google. - Otimizações de compilação
Módulos JavaScript, padrão de módulo/nomódulo, trepidação de árvore, divisão de código, elevação de escopo, Webpack, serviço diferencial, web worker, WebAssembly, pacotes JavaScript, React, SPA, hidratação parcial, importação na interação, terceiros, cache. - Otimizações de entrega
Carregamento lento, observador de interseção, renderização e decodificação de adiamento, CSS crítico, streaming, dicas de recursos, mudanças de layout, service worker. - Rede, HTTP/2, HTTP/3
Grampeamento OCSP, certificados EV/DV, embalagem, IPv6, QUIC, HTTP/3. - Teste e monitoramento
Fluxo de trabalho de auditoria, navegadores proxy, página 404, prompts de consentimento de cookies GDPR, CSS de diagnóstico de desempenho, acessibilidade. - Vitórias rápidas
- Baixe a lista de verificação (PDF, Apple Pages, MS Word)
- Lá vamos nós!
(Você também pode baixar o PDF da lista de verificação (166 KB) ou baixar o arquivo editável do Apple Pages (275 KB) ou o arquivo .docx (151 KB). Boa otimização, pessoal!)
Preparação: planejamento e métricas
As micro-otimizações são ótimas para manter o desempenho sob controle, mas é fundamental ter em mente metas claramente definidas — metas mensuráveis que influenciariam quaisquer decisões tomadas ao longo do processo. Existem alguns modelos diferentes, e os discutidos abaixo são bastante opinativos – apenas certifique-se de definir suas próprias prioridades desde o início.
- Estabeleça uma cultura de desempenho.
Em muitas organizações, os desenvolvedores front-end sabem exatamente quais são os problemas subjacentes comuns e quais estratégias devem ser usadas para corrigi-los. No entanto, enquanto não houver um endosso estabelecido da cultura de desempenho, cada decisão se transformará em um campo de batalha de departamentos, dividindo a organização em silos. Você precisa da adesão de uma parte interessada nos negócios e, para obtê-la, precisa estabelecer um estudo de caso ou uma prova de conceito sobre como a velocidade - especialmente os principais aspectos vitais da Web , que abordaremos em detalhes mais adiante - beneficia as métricas e os indicadores-chave de desempenho ( KPIs ) com os quais eles se importam.Por exemplo, para tornar o desempenho mais tangível, você pode expor o impacto no desempenho da receita mostrando a correlação entre a taxa de conversão e o tempo de carregamento do aplicativo, bem como o desempenho de renderização. Ou a taxa de rastreamento do bot de pesquisa (PDF, páginas 27–50).
Sem um forte alinhamento entre as equipes de desenvolvimento/design e de negócios/marketing, o desempenho não se sustentará a longo prazo. Estude reclamações comuns que chegam ao atendimento ao cliente e à equipe de vendas, estude análises para altas taxas de rejeição e quedas de conversão. Explore como melhorar o desempenho pode ajudar a aliviar alguns desses problemas comuns. Ajuste o argumento dependendo do grupo de stakeholders com quem você está falando.
Execute experimentos de desempenho e meça os resultados — tanto em dispositivos móveis quanto em computadores (por exemplo, com o Google Analytics). Ele irá ajudá-lo a construir um estudo de caso sob medida para a empresa com dados reais. Além disso, o uso de dados de estudos de caso e experimentos publicados no WPO Stats ajudará a aumentar a sensibilidade dos negócios sobre por que o desempenho é importante e qual o impacto que ele tem na experiência do usuário e nas métricas de negócios. Afirmar que o desempenho importa por si só não é suficiente - você também precisa estabelecer algumas metas mensuráveis e rastreáveis e observá-las ao longo do tempo.
Como chegar lá? Em sua palestra sobre Construindo Desempenho a Longo Prazo, Allison McKnight compartilha um estudo de caso abrangente de como ela ajudou a estabelecer uma cultura de desempenho no Etsy (slides). Mais recentemente, Tammy Everts falou sobre hábitos de equipes de desempenho altamente eficazes em organizações pequenas e grandes.
Ao ter essas conversas nas organizações, é importante ter em mente que, assim como o UX é um espectro de experiências, o desempenho na web é uma distribuição. Como Karolina Szczur observou, "esperar que um único número seja capaz de fornecer uma classificação a que aspirar é uma suposição falha". Portanto, as metas de desempenho precisam ser granulares, rastreáveis e tangíveis.
- Objetivo: Ser pelo menos 20% mais rápido que seu concorrente mais rápido.
De acordo com pesquisas psicológicas, se você quer que os usuários sintam que seu site é mais rápido que o site do seu concorrente, você precisa ser pelo menos 20% mais rápido. Estude seus principais concorrentes, colete métricas sobre o desempenho deles em dispositivos móveis e desktops e defina limites que o ajudariam a superá-los. No entanto, para obter resultados e metas precisos, certifique-se de obter primeiro uma imagem completa da experiência de seus usuários estudando suas análises. Você pode então imitar a experiência do 90º percentil para teste.Para obter uma boa primeira impressão do desempenho de seus concorrentes, você pode usar o Chrome UX Report ( CrUX , um conjunto de dados RUM pronto, introdução em vídeo de Ilya Grigorik e guia detalhado de Rick Viscomi) ou Treo, uma ferramenta de monitoramento de RUM que é desenvolvido pelo Chrome UX Report. Os dados são coletados dos usuários do navegador Chrome, portanto, os relatórios serão específicos do Chrome, mas fornecerão uma distribuição bastante completa do desempenho, principalmente as pontuações do Core Web Vitals, em uma ampla variedade de visitantes. Observe que novos conjuntos de dados CrUX são lançados na segunda terça-feira de cada mês .
Alternativamente, você também pode usar:
- Ferramenta de comparação de relatórios de UX do Chrome de Addy Osmani,
- Speed Scorecard (também fornece um estimador de impacto de receita),
- Comparação real do teste de experiência do usuário ou
- SiteSpeed CI (baseado em testes sintéticos).
Observação : se você usar o Page Speed Insights ou a API do Page Speed Insights (não, ele não está obsoleto!), poderá obter dados de desempenho do CrUX para páginas específicas em vez de apenas os agregados. Esses dados podem ser muito mais úteis para definir metas de desempenho para recursos como "página de destino" ou "lista de produtos". E se você estiver usando CI para testar os orçamentos, você precisa ter certeza de que seu ambiente testado corresponde ao CrUX se você usou o CrUX para definir o destino ( obrigado Patrick Meenan! ).
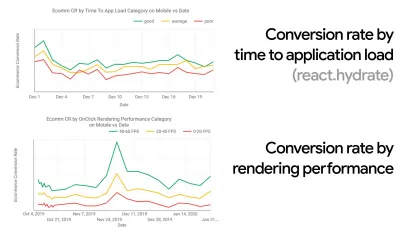
Se você precisar de ajuda para mostrar o raciocínio por trás da priorização da velocidade, ou quiser visualizar o declínio da taxa de conversão ou o aumento da taxa de rejeição com desempenho mais lento, ou talvez precise defender uma solução RUM em sua organização, Sergey Chernyshev construiu uma UX Speed Calculator, uma ferramenta de código aberto que ajuda você a simular dados e visualizá-los para direcionar seu ponto de vista.

O CrUX gera uma visão geral das distribuições de desempenho ao longo do tempo, com o tráfego coletado dos usuários do Google Chrome. Você pode criar o seu próprio no Chrome UX Dashboard. (Visualização grande) 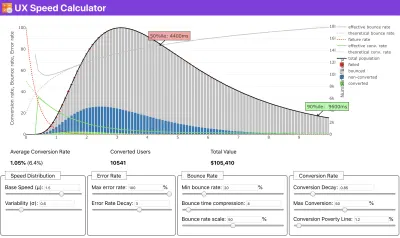
Exatamente quando você precisa defender o desempenho para impulsionar seu ponto de vista: o UX Speed Calculator visualiza um impacto do desempenho nas taxas de rejeição, conversão e receita total - com base em dados reais. (Visualização grande) Às vezes, você pode querer ir um pouco mais fundo, combinando os dados provenientes do CrUX com quaisquer outros dados que você já tenha para descobrir rapidamente onde estão as lentidão, pontos cegos e ineficiências - para seus concorrentes ou para seu projeto. Em seu trabalho, Harry Roberts tem usado uma Planilha de Topografia de Velocidade de Site que ele usa para dividir o desempenho por tipos de página principais e rastrear como as métricas principais são diferentes entre elas. Você pode baixar a planilha como Planilhas Google, Excel, documento OpenOffice ou CSV.
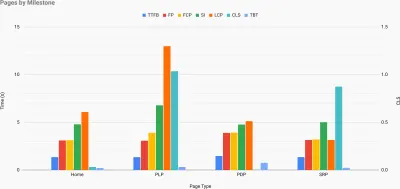
Topografia de velocidade do site, com as principais métricas representadas para as principais páginas do site. (Visualização grande) E se você quiser ir até o fim, pode executar uma auditoria de desempenho do Lighthouse em todas as páginas de um site (via Lightouse Parade), com uma saída salva como CSV. Isso ajudará você a identificar quais páginas específicas (ou tipos de páginas) de seus concorrentes têm um desempenho pior ou melhor e em que você pode concentrar seus esforços. (Para seu próprio site, provavelmente é melhor enviar dados para um endpoint de análise!).

Com o Lighthouse Parade, você pode executar uma auditoria de desempenho do Lighthouse em todas as páginas de um site, com uma saída salva como CSV. (Visualização grande) Colete dados, monte uma planilha, reduza 20% e defina suas metas ( orçamentos de desempenho ) dessa maneira. Agora você tem algo mensurável para testar. Se você está mantendo o orçamento em mente e tentando enviar apenas a carga útil mínima para obter um tempo rápido de interação, então você está no caminho razoável.
Precisa de recursos para começar?
- Addy Osmani escreveu um artigo muito detalhado sobre como iniciar o orçamento de desempenho, como quantificar o impacto de novos recursos e por onde começar quando estiver acima do orçamento.
- O guia de Lara Hogan sobre como abordar projetos com um orçamento de desempenho pode fornecer dicas úteis para designers.
- Harry Roberts publicou um guia sobre como configurar uma planilha do Google para exibir o impacto de scripts de terceiros no desempenho, usando o Request Map,
- A calculadora de orçamento de desempenho de Jonathan Fielding, a calculadora de orçamento de desempenho de Katie Hempenius e as calorias do navegador podem ajudar na criação de orçamentos (graças a Karolina Szczur pelo aviso).
- Em muitas empresas, os orçamentos de desempenho não devem ser aspiracionais, mas sim pragmáticos, servindo como um sinal de espera para evitar passar de um certo ponto. Nesse caso, você pode escolher seu pior ponto de dados nas últimas duas semanas como um limite e a partir daí. Orçamentos de desempenho, pragmaticamente mostra uma estratégia para conseguir isso.
- Além disso, torne o orçamento de desempenho e o desempenho atual visíveis configurando painéis com tamanhos de compilação de relatórios de gráficos. Existem muitas ferramentas que permitem que você faça isso: o painel SiteSpeed.io (código aberto), SpeedCurve e Caliber são apenas algumas delas, e você pode encontrar mais ferramentas em perf.rocks.

As calorias do navegador ajudam você a definir um orçamento de desempenho e medir se uma página está excedendo esses números ou não. (Visualização grande) Depois de ter um orçamento definido, incorpore-os em seu processo de criação com Webpack Performance Hints and Bundlesize, Lighthouse CI, PWMetrics ou Sitespeed CI para impor orçamentos em pull requests e fornecer um histórico de pontuação nos comentários de PR.
Para expor orçamentos de desempenho para toda a equipe, integre orçamentos de desempenho no Lighthouse por meio do Lightwallet ou use o LHCI Action para integração rápida do Github Actions. E se precisar de algo personalizado, você pode usar webpagetest-charts-api, uma API de endpoints para construir gráficos a partir dos resultados do WebPagetest.
No entanto, a conscientização sobre o desempenho não deve vir apenas dos orçamentos de desempenho. Assim como o Pinterest, você pode criar uma regra eslint personalizada que não permita a importação de arquivos e diretórios que são conhecidos por serem muito dependentes e sobrecarregariam o pacote. Configure uma lista de pacotes “seguros” que podem ser compartilhados com toda a equipe.
Além disso, pense nas tarefas críticas do cliente que são mais benéficas para o seu negócio. Estude, discuta e defina limites de tempo aceitáveis para ações críticas e estabeleça marcas de tempo de usuário "UX ready" que toda a organização aprovou. Em muitos casos, as jornadas do usuário afetarão o trabalho de muitos departamentos diferentes, portanto, o alinhamento em termos de tempos aceitáveis ajudará a apoiar ou evitar discussões de desempenho no futuro. Certifique-se de que os custos adicionais de recursos e recursos adicionados sejam visíveis e compreendidos.
Alinhe os esforços de desempenho com outras iniciativas de tecnologia, desde novos recursos do produto que está sendo criado até a refatoração para alcançar novos públicos globais. Então, toda vez que uma conversa sobre desenvolvimento adicional acontece, o desempenho também faz parte dessa conversa. É muito mais fácil atingir metas de desempenho quando a base de código é nova ou está apenas sendo refatorada.
Além disso, como sugeriu Patrick Meenan, vale a pena planejar uma sequência de carregamento e compensações durante o processo de design. Se você priorizar antecipadamente quais partes são mais críticas e definir a ordem em que elas devem aparecer, também saberá o que pode ser atrasado. Idealmente, essa ordem também refletirá a sequência de suas importações de CSS e JavaScript, portanto, será mais fácil manuseá-las durante o processo de compilação. Além disso, considere qual deve ser a experiência visual nos estados "intermediários", enquanto a página está sendo carregada (por exemplo, quando as fontes da Web ainda não foram carregadas).
Depois de estabelecer uma forte cultura de desempenho em sua organização, tente ser 20% mais rápido do que seu antigo eu para manter as prioridades intactas com o passar do tempo ( obrigado, Guy Podjarny! ). Mas considere os diferentes tipos e comportamentos de uso de seus clientes (que Tobias Baldauf chamou de cadência e coortes), juntamente com o tráfego de bots e efeitos de sazonalidade.
Planejamento, planejamento, planejamento. Pode ser tentador entrar em algumas otimizações rápidas de "frutos fáceis" no início - e pode ser uma boa estratégia para ganhos rápidos - mas será muito difícil manter o desempenho como prioridade sem planejamento e definição de empresas realistas. - metas de desempenho personalizadas.
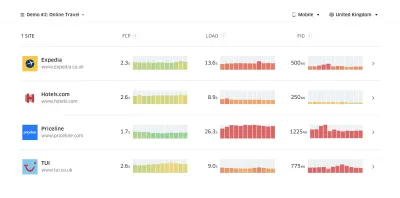
- Escolha as métricas certas.
Nem todas as métricas são igualmente importantes. Estude quais métricas são mais importantes para seu aplicativo: geralmente, elas serão definidas pela rapidez com que você pode começar a renderizar os pixels mais importantes da sua interface e com que rapidez você pode fornecer resposta de entrada para esses pixels renderizados. Esse conhecimento lhe dará a melhor meta de otimização para esforços contínuos. No final, não são os eventos de carregamento ou os tempos de resposta do servidor que definem a experiência, mas a percepção de quão ágil a interface parece .O que isto significa? Em vez de se concentrar no tempo de carregamento da página inteira (por meio de horários onLoad e DOMContentLoaded , por exemplo), priorize o carregamento da página conforme percebido por seus clientes. Isso significa focar em um conjunto ligeiramente diferente de métricas. Na verdade, escolher a métrica certa é um processo sem vencedores óbvios.
Com base na pesquisa de Tim Kadlec e nas notas de Marcos Iglesias em sua palestra, as métricas tradicionais podem ser agrupadas em alguns conjuntos. Normalmente, precisaremos de todos eles para obter uma visão completa do desempenho e, no seu caso particular, alguns deles serão mais importantes do que outros.
- Métricas baseadas em quantidade medem o número de solicitações, peso e pontuação de desempenho. Bom para disparar alarmes e monitorar mudanças ao longo do tempo, não tão bom para entender a experiência do usuário.
- As métricas de marco usam estados no tempo de vida do processo de carregamento, por exemplo, Tempo até o primeiro byte e Tempo até a interação . Bom para descrever a experiência do usuário e monitoramento, não tão bom para saber o que acontece entre os marcos.
- As métricas de renderização fornecem uma estimativa de quão rápido o conteúdo é renderizado (por exemplo, tempo de renderização inicial , índice de velocidade ). Bom para medir e ajustar o desempenho de renderização, mas não tão bom para medir quando um conteúdo importante aparece e pode interagir.
- Métricas personalizadas medem um evento específico e personalizado para o usuário, por exemplo, Time To First Tweet do Twitter e PinnerWaitTime do Pinterest. Bom para descrever a experiência do usuário com precisão, não tão bom para dimensionar as métricas e comparar com os concorrentes.
Para completar o quadro, normalmente procuramos métricas úteis entre todos esses grupos. Normalmente, os mais específicos e relevantes são:
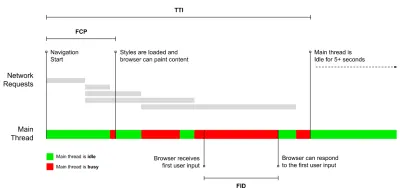
- Tempo para Interação (TTI)
O ponto em que o layout se estabilizou , as principais fontes da web ficam visíveis e o encadeamento principal está disponível o suficiente para lidar com a entrada do usuário - basicamente a marca de tempo em que um usuário pode interagir com a interface do usuário. As principais métricas para entender quanto tempo um usuário precisa esperar para usar o site sem atrasos. Boris Schapira escreveu um post detalhado sobre como medir o ITT de forma confiável. - Atraso da primeira entrada (FID) ou responsividade de entrada
O tempo desde quando um usuário interage pela primeira vez com seu site até o momento em que o navegador é realmente capaz de responder a essa interação. Complementa muito bem o TTI, pois descreve a parte que falta na imagem: o que acontece quando um usuário realmente interage com o site. Destinado apenas como uma métrica RUM. Existe uma biblioteca JavaScript para medir o FID no navegador. - Maior pintura de conteúdo (LCP)
Marca o ponto na linha do tempo de carregamento da página quando o conteúdo importante da página provavelmente foi carregado. A suposição é que o elemento mais importante da página seja o maior visível na janela de visualização do usuário. Se os elementos forem renderizados acima e abaixo da dobra, apenas a parte visível será considerada relevante. - Tempo Total de Bloqueio ( TBT )
Uma métrica que ajuda a quantificar a gravidade de quão não interativa é uma página antes de se tornar confiavelmente interativa (ou seja, o encadeamento principal está livre de quaisquer tarefas executando mais de 50ms ( tarefas longas ) por pelo menos 5s). A métrica mede a quantidade total de tempo entre a primeira pintura e o Tempo para Interação (TTI) em que o encadeamento principal foi bloqueado por tempo suficiente para impedir a resposta de entrada. Não é de admirar, então, que um TBT baixo seja um bom indicador de bom desempenho. (obrigado, Artem, Phil) - Mudança de layout cumulativa ( CLS )
A métrica destaca a frequência com que os usuários experimentam mudanças inesperadas de layout ( refluxos ) ao acessar o site. Ele examina elementos instáveis e seu impacto na experiência geral. Quanto menor a pontuação, melhor. - Índice de velocidade
Mede a rapidez com que o conteúdo da página é preenchido visualmente; quanto menor a pontuação, melhor. A pontuação do Índice de Velocidade é calculada com base na velocidade do progresso visual , mas é apenas um valor calculado. Também é sensível ao tamanho da janela de visualização, portanto, você precisa definir uma variedade de configurações de teste que correspondam ao seu público-alvo. Observe que está se tornando menos importante com o LCP se tornando uma métrica mais relevante ( obrigado, Boris, Artem! ). - Tempo de CPU gasto
Uma métrica que mostra com que frequência e por quanto tempo o thread principal está bloqueado, trabalhando na pintura, renderização, script e carregamento. O alto tempo de CPU é um indicador claro de uma experiência ruim , ou seja, quando o usuário experimenta um atraso perceptível entre sua ação e uma resposta. Com o WebPageTest, você pode selecionar "Capture Dev Tools Timeline" na guia "Chrome" para expor o detalhamento do thread principal conforme ele é executado em qualquer dispositivo usando o WebPageTest. - Custos de CPU em nível de componente
Assim como o tempo gasto na CPU , essa métrica, proposta por Stoyan Stefanov, explora o impacto do JavaScript na CPU . A ideia é usar a contagem de instruções da CPU por componente para entender seu impacto na experiência geral, isoladamente. Pode ser implementado usando Puppeteer e Chrome. - Índice de frustração
Embora muitas métricas apresentadas acima expliquem quando um determinado evento acontece, o FrustrationIndex de Tim Vereecke analisa as lacunas entre as métricas em vez de analisá-las individualmente. Ele analisa os principais marcos percebidos pelo usuário final, como o título é visível, o primeiro conteúdo é visível, visualmente pronto e a página parece pronta e calcula uma pontuação indicando o nível de frustração ao carregar uma página. Quanto maior a lacuna, maior a chance de um usuário ficar frustrado. Potencialmente um bom KPI para a experiência do usuário. Tim publicou um post detalhado sobre FrustrationIndex e como ele funciona. - Impacto da ponderação do anúncio
Se o seu site depende da receita gerada pela publicidade, é útil acompanhar o peso do código relacionado ao anúncio. O script de Paddy Ganti constrói duas URLs (uma normal e outra bloqueando os anúncios), solicita a geração de uma comparação de vídeo via WebPageTest e informa um delta. - Métricas de desvio
Conforme observado pelos engenheiros da Wikipedia, os dados de quanta variação existe em seus resultados podem informar o quão confiáveis são seus instrumentos e quanta atenção você deve prestar a desvios e outlers. Grande variação é um indicador de ajustes necessários na configuração. Também ajuda a entender se certas páginas são mais difíceis de medir de forma confiável, por exemplo, devido a scripts de terceiros que causam variação significativa. Também pode ser uma boa ideia rastrear a versão do navegador para entender os impactos no desempenho quando uma nova versão do navegador é lançada. - Métricas personalizadas
As métricas personalizadas são definidas pelas necessidades do seu negócio e pela experiência do cliente. Ele exige que você identifique pixels importantes , scripts críticos , CSS necessário e ativos relevantes e meça a rapidez com que eles são entregues ao usuário. Para isso, você pode monitorar os tempos de renderização de heróis ou usar a API Performance, marcando timestamps específicos para eventos importantes para sua empresa. Além disso, você pode coletar métricas personalizadas com WebPagetest executando JavaScript arbitrário no final de um teste.
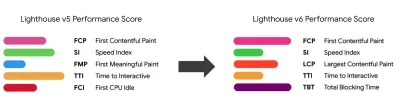
Observe que a primeira pintura significativa (FMP) não aparece na visão geral acima. Ele costumava fornecer uma visão sobre a rapidez com que o servidor gera qualquer dado. O FMP longo geralmente indicava JavaScript bloqueando o thread principal, mas também pode estar relacionado a problemas de back-end/servidor. No entanto, a métrica foi preterida recentemente, pois parece não ser precisa em cerca de 20% dos casos. Ele foi efetivamente substituído pelo LCP, que é mais confiável e mais fácil de raciocinar. Não é mais suportado no Lighthouse. Verifique novamente as métricas e recomendações de desempenho centradas no usuário mais recentes apenas para garantir que você esteja na página segura ( obrigado, Patrick Meenan ).
Steve Souders tem uma explicação detalhada de muitas dessas métricas. É importante observar que, embora o tempo para interação seja medido pela execução de auditorias automatizadas no chamado ambiente de laboratório , o atraso da primeira entrada representa a experiência real do usuário, com os usuários reais experimentando um atraso perceptível. Em geral, provavelmente é uma boa ideia sempre medir e acompanhar os dois.
Dependendo do contexto do seu aplicativo, as métricas preferidas podem diferir: por exemplo, para a interface do usuário da TV Netflix, a capacidade de resposta de entrada de teclas, o uso de memória e o TTI são mais críticos e, para a Wikipedia, as primeiras/últimas alterações visuais e as métricas de tempo de CPU são mais importantes.
Observação : tanto o FID quanto o TTI não levam em conta o comportamento de rolagem; a rolagem pode acontecer de forma independente, pois é fora do thread principal, portanto, para muitos sites de consumo de conteúdo, essas métricas podem ser muito menos importantes ( obrigado, Patrick! ).
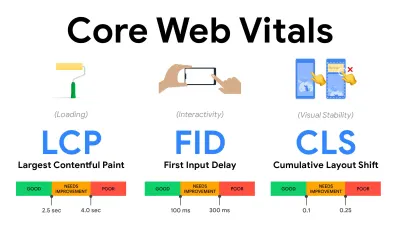
- Meça e otimize os Core Web Vitals .
Por muito tempo, as métricas de desempenho eram bastante técnicas, focando na visão de engenharia de quão rápido os servidores estão respondendo e quão rápidos os navegadores estão carregando. As métricas mudaram ao longo dos anos – tentando encontrar uma maneira de capturar a experiência real do usuário, em vez dos horários do servidor. Em maio de 2020, o Google anunciou o Core Web Vitals, um conjunto de novas métricas de desempenho focadas no usuário, cada uma representando uma faceta distinta da experiência do usuário.Para cada um deles, o Google recomenda uma série de metas de velocidade aceitáveis. Pelo menos 75% de todas as visualizações de página devem exceder o intervalo Bom para passar nessa avaliação. Essas métricas ganharam força rapidamente e, com o Core Web Vitals se tornando sinais de classificação para a Pesquisa do Google em maio de 2021 ( atualização do algoritmo de classificação da experiência da página ), muitas empresas voltaram sua atenção para suas pontuações de desempenho.
Vamos detalhar cada um dos Core Web Vitals, um por um, juntamente com técnicas e ferramentas úteis para otimizar suas experiências com essas métricas em mente. (Vale a pena notar que você terminará com melhores pontuações no Core Web Vitals seguindo um conselho geral neste artigo.)
- Maior pintura de conteúdo ( LCP ) < 2,5 seg.
Mede o carregamento de uma página e informa o tempo de renderização da maior imagem ou bloco de texto visível na janela de visualização. Portanto, o LCP é afetado por tudo o que está adiando a renderização de informações importantes - sejam tempos de resposta lentos do servidor, CSS bloqueando, JavaScript em andamento (primário ou de terceiros), carregamento de fonte da Web, renderização cara ou operações de pintura, -carregadas de imagens, telas de esqueleto ou renderização do lado do cliente.
Para uma boa experiência, o LCP deve ocorrer dentro de 2,5 segundos após o início do carregamento da página. Isso significa que precisamos renderizar a primeira parte visível da página o mais cedo possível. Isso exigirá CSS crítico personalizado para cada modelo, orquestrando o<head>-order e pré-buscando ativos críticos (vamos cobri-los mais tarde).A principal razão para uma baixa pontuação no LCP geralmente são as imagens. Para entregar um LCP em <2,5s em Fast 3G — hospedado em um servidor bem otimizado, todo estático sem renderização do lado do cliente e com uma imagem proveniente de um CDN de imagem dedicado — significa que o tamanho máximo teórico da imagem é de apenas 144 KB . É por isso que imagens responsivas são importantes, além de pré-carregar imagens críticas antecipadamente (com
preload).Dica rápida : para descobrir o que é considerado LCP em uma página, no DevTools você pode passar o mouse sobre o selo LCP em "Tempos" no Painel de Desempenho ( obrigado, Tim Kadlec !).
- Atraso da primeira entrada ( FID ) < 100ms.
Mede a capacidade de resposta da interface do usuário, ou seja, quanto tempo o navegador estava ocupado com outras tarefas antes que pudesse reagir a um evento discreto de entrada do usuário, como um toque ou um clique. Ele foi projetado para capturar atrasos resultantes do encadeamento principal estar ocupado, especialmente durante o carregamento da página.
O objetivo é ficar entre 50 e 100 ms para cada interação. Para chegar lá, precisamos identificar tarefas longas (bloqueia o encadeamento principal por > 50ms) e dividi-las, dividir um pacote em vários pedaços, reduzir o tempo de execução do JavaScript, otimizar a busca de dados, adiar a execução de scripts de terceiros , mova o JavaScript para o thread em segundo plano com Web workers e use hidratação progressiva para reduzir os custos de reidratação em SPAs.Dica rápida : em geral, uma estratégia confiável para obter uma pontuação FID melhor é minimizar o trabalho no encadeamento principal , dividindo pacotes maiores em menores e atendendo o que o usuário precisa quando precisar, para que as interações do usuário não sejam atrasadas . Cobriremos mais sobre isso em detalhes abaixo.
- Deslocamento cumulativo de layout ( CLS ) < 0,1.
Mede a estabilidade visual da interface do usuário para garantir interações suaves e naturais, ou seja, a soma total de todas as pontuações de mudança de layout individual para cada mudança de layout inesperada que ocorre durante a vida útil da página. Uma mudança de layout individual ocorre sempre que um elemento que já estava visível muda sua posição na página. É pontuado com base no tamanho do conteúdo e na distância que ele moveu.
Assim, toda vez que uma mudança aparece - por exemplo, quando fontes de fallback e fontes da Web têm métricas de fonte diferentes, ou anúncios, incorporações ou iframes chegando atrasados, ou dimensões de imagem/vídeo não são reservadas, ou CSS atrasado força repinturas ou alterações são injetadas por JavaScript atrasado — tem um impacto na pontuação do CLS. O valor recomendado para uma boa experiência é um CLS < 0,1.
Vale a pena notar que os Core Web Vitals devem evoluir ao longo do tempo, com um ciclo anual previsível . Para a atualização do primeiro ano, podemos esperar que o First Contentful Paint seja promovido a Core Web Vitals, um limite FID reduzido e melhor suporte para aplicativos de página única. Também podemos ver a resposta às entradas do usuário após a carga ganhando mais peso, juntamente com considerações de segurança, privacidade e acessibilidade (!).
Relacionados aos Core Web Vitals, há muitos recursos e artigos úteis que valem a pena serem analisados:
- O Web Vitals Leaderboard permite que você compare suas pontuações com a concorrência em dispositivos móveis, tablets, desktops e em 3G e 4G.
- Core SERP Vitals, uma extensão do Chrome que mostra os Core Web Vitals do CrUX nos resultados de pesquisa do Google.
- Layout Shift GIF Generator que visualiza o CLS com um GIF simples (também disponível na linha de comando).
- A biblioteca web-vitals pode coletar e enviar Core Web Vitals para o Google Analytics, Google Tag Manager ou qualquer outro endpoint de análise.
- Analisando Web Vitals com WebPageTest, em que Patrick Meenan explora como WebPageTest expõe dados sobre Core Web Vitals.
- Otimizando com o Core Web Vitals, um vídeo de 50 minutos com Addy Osmani, no qual ele destaca como melhorar o Core Web Vitals em um estudo de caso de comércio eletrônico.
- Mudança de layout cumulativa na prática e Mudança de layout cumulativa no mundo real são artigos abrangentes de Nic Jansma, que cobrem praticamente tudo sobre o CLS e como ele se correlaciona com as principais métricas, como taxa de rejeição, tempo de sessão ou cliques de raiva.
- O que força o Reflow, com uma visão geral das propriedades ou métodos, quando solicitados/chamados em JavaScript, que acionarão o navegador para calcular de forma síncrona o estilo e o layout.
- CSS Triggers mostra quais propriedades CSS acionam Layout, Paint e Composite.
- Corrigindo a instabilidade de layout é um passo a passo do uso do WebPageTest para identificar e corrigir problemas de instabilidade de layout.
- Mudança de layout cumulativa, a métrica de instabilidade de layout, outro guia muito detalhado de Boris Schapira sobre CLS, como é calculado, como medir e como otimizar para isso.
- How To Improve Core Web Vitals, um guia detalhado de Simon Hearne sobre cada uma das métricas (incluindo outros Web Vitals, como FCP, TTI, TBT), quando ocorrem e como são medidos.
Então, os Core Web Vitals são as métricas finais a serem seguidas ? Não exatamente. Eles já estão expostos na maioria das soluções e plataformas RUM, incluindo Cloudflare, Treo, SpeedCurve, Calibre, WebPageTest (já na visualização da tira de filme), Newrelic, Shopify, Next.js, todas as ferramentas do Google (PageSpeed Insights, Lighthouse + CI, Search Console etc.) e muitos outros.
No entanto, como explica Katie Sylor-Miller, alguns dos principais problemas com o Core Web Vitals são a falta de suporte entre navegadores, não medimos realmente o ciclo de vida completo da experiência de um usuário, além de ser difícil correlacionar alterações no FID e CLS com resultados de negócios.
Como devemos esperar que os Core Web Vitals evoluam, parece razoável sempre combinar os Web Vitals com suas métricas personalizadas para obter uma melhor compreensão de onde você está em termos de desempenho.
- Maior pintura de conteúdo ( LCP ) < 2,5 seg.
- Reúna dados em um dispositivo representativo do seu público.
Para coletar dados precisos, precisamos escolher cuidadosamente os dispositivos para testar. Na maioria das empresas, isso significa analisar análises e criar perfis de usuários com base nos tipos de dispositivos mais comuns. No entanto, muitas vezes, a análise por si só não fornece uma imagem completa. Uma parte significativa do público-alvo pode estar abandonando o site (e não retornando) apenas porque sua experiência é muito lenta e é improvável que seus dispositivos apareçam como os dispositivos mais populares em análises por esse motivo. Portanto, realizar pesquisas adicionais em dispositivos comuns em seu grupo-alvo pode ser uma boa ideia.Globalmente, em 2020, de acordo com o IDC, 84,8% de todos os telefones celulares enviados são dispositivos Android. Um consumidor médio atualiza seu telefone a cada 2 anos e, nos EUA, o ciclo de substituição do telefone é de 33 meses. A média de telefones mais vendidos em todo o mundo custará menos de US $ 200.
Um dispositivo representativo, então, é um dispositivo Android com pelo menos 24 meses , custando US$ 200 ou menos, rodando em 3G lento, 400ms RTT e transferência de 400kbps, só para ser um pouco mais pessimista. Isso pode ser muito diferente para sua empresa, é claro, mas é uma aproximação bastante próxima da maioria dos clientes por aí. Na verdade, pode ser uma boa ideia pesquisar os best-sellers atuais da Amazon para o seu mercado-alvo. ( Obrigado a Tim Kadlec, Henri Helvetica e Alex Russell pelas dicas! ).
Ao criar um novo site ou aplicativo, sempre verifique primeiro os Amazon Best Sellers atuais para seu mercado-alvo. (Visualização grande) Que dispositivos de teste escolher então? Aqueles que se encaixam bem com o perfil descrito acima. É uma boa opção escolher um Moto G4/G5 Plus um pouco mais antigo, um dispositivo Samsung de gama média (Galaxy A50, S8), um bom dispositivo intermediário como um Nexus 5X, Xiaomi Mi A3 ou Xiaomi Redmi Note 7 e um dispositivo lento como Alcatel 1X ou Cubot X19, talvez em um laboratório de dispositivos aberto. Para testar em dispositivos térmicos mais lentos, você também pode obter um Nexus 4, que custa cerca de US$ 100.
Além disso, verifique os chipsets usados em cada dispositivo e não represente demais um chipset : algumas gerações de Snapdragon e Apple, bem como Rockchip de baixo custo, Mediatek seriam suficientes (obrigado, Patrick!) .
Se você não tiver um dispositivo em mãos, emule a experiência móvel no desktop testando em uma rede 3G limitada (por exemplo, 300ms RTT, 1,6 Mbps para baixo, 0,8 Mbps para cima) com uma CPU limitada (5× desaceleração). Eventualmente, mude para 3G normal, 4G lento (por exemplo, 170ms RTT, 9 Mbps para baixo, 9 Mbps para cima) e Wi-Fi. Para tornar o impacto no desempenho mais visível, você pode até mesmo introduzir o 2G às terças-feiras ou configurar uma rede 3G/4G limitada em seu escritório para testes mais rápidos.
Tenha em mente que em um dispositivo móvel, devemos esperar uma desaceleração de 4×–5× em comparação com computadores desktop. Os dispositivos móveis têm diferentes GPUs, CPU, memória e características de bateria diferentes. Por isso é importante ter um bom perfil de um aparelho mediano e sempre testar nesse aparelho.
- As ferramentas de teste sintético coletam dados de laboratório em um ambiente reproduzível com configurações predefinidas de dispositivo e rede (por exemplo, Lighthouse , Caliber , WebPageTest ) e
- As ferramentas Real User Monitoring ( RUM ) avaliam as interações do usuário continuamente e coletam dados de campo (por exemplo, SpeedCurve , New Relic — as ferramentas também fornecem testes sintéticos).
- use o Lighthouse CI para rastrear as pontuações do Lighthouse ao longo do tempo (é bastante impressionante),
- execute o Lighthouse no GitHub Actions para obter um relatório do Lighthouse junto com cada PR,
- execute uma auditoria de desempenho do Lighthouse em cada página de um site (via Lightouse Parade), com uma saída salva como CSV,
- use a Calculadora de Pontuações do Lighthouse e os pesos das métricas do Lighthouse se precisar se aprofundar em mais detalhes.
- O Lighthouse também está disponível para o Firefox, mas sob o capô ele usa a API PageSpeed Insights e gera um relatório com base em um Chrome 79 User-Agent headless.

Felizmente, existem muitas opções excelentes que ajudam você a automatizar a coleta de dados e medir o desempenho do seu site ao longo do tempo de acordo com essas métricas. Tenha em mente que uma boa imagem de desempenho abrange um conjunto de métricas de desempenho, dados de laboratório e dados de campo:
O primeiro é particularmente útil durante o desenvolvimento , pois ajudará você a identificar, isolar e corrigir problemas de desempenho enquanto trabalha no produto. O último é útil para manutenção de longo prazo, pois ajudará você a entender seus gargalos de desempenho à medida que eles acontecem ao vivo — quando os usuários realmente acessam o site.
Ao tocar em APIs RUM integradas, como Navigation Timing, Resource Timing, Paint Timing, Long Tasks, etc., as ferramentas de teste sintético e o RUM juntos fornecem uma imagem completa do desempenho em seu aplicativo. Você pode usar Calibre, Treo, SpeedCurve, mPulse e Boomerang, Sitespeed.io, que são ótimas opções para monitoramento de desempenho. Além disso, com o cabeçalho Server Timing, você pode até monitorar o desempenho de back-end e front-end em um só lugar.
Nota : É sempre uma aposta mais segura escolher aceleradores de nível de rede, externos ao navegador, pois, por exemplo, o DevTools tem problemas ao interagir com o push HTTP/2, devido à forma como ele é implementado ( obrigado, Yoav, Patrick !). Para Mac OS, podemos usar o Network Link Conditioner, para Windows Windows Traffic Shaper, para Linux netem e para FreeBSD dummynet.
Como é provável que você esteja testando no Lighthouse, lembre-se de que você pode:
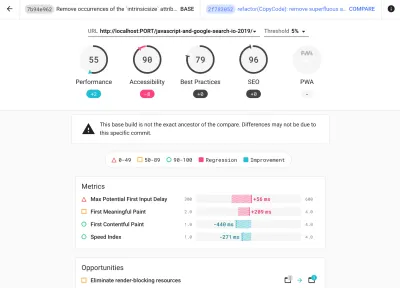
- Configure perfis "limpo" e "cliente" para teste.
Ao executar testes em ferramentas de monitoramento passivo, é uma estratégia comum desativar tarefas antivírus e de CPU em segundo plano, remover transferências de largura de banda em segundo plano e testar com um perfil de usuário limpo sem extensões de navegador para evitar resultados distorcidos (no Firefox e no Chrome).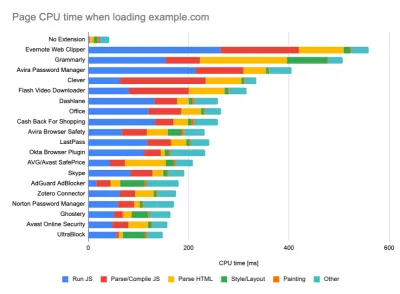
O relatório do DebugBear destaca as 20 extensões mais lentas, incluindo gerenciadores de senhas, bloqueadores de anúncios e aplicativos populares como Evernote e Grammarly. (Visualização grande) No entanto, também é uma boa ideia estudar quais extensões de navegador seus clientes usam com frequência e testar também com perfis de "cliente" dedicados. Na verdade, algumas extensões podem ter um impacto profundo no desempenho (Relatório de desempenho de extensões do Chrome 2020) em seu aplicativo e, se seus usuários as usarem muito, convém considerar isso antecipadamente. Portanto, os resultados de perfil "limpos" por si só são excessivamente otimistas e podem ser esmagados em cenários da vida real.
- Compartilhe as metas de desempenho com seus colegas.
Certifique-se de que as metas de desempenho sejam familiares a todos os membros de sua equipe para evitar mal-entendidos no futuro. Cada decisão – seja design, marketing ou qualquer coisa intermediária – tem implicações de desempenho , e a distribuição de responsabilidade e propriedade por toda a equipe simplificaria as decisões focadas no desempenho posteriormente. Mapeie as decisões de design em relação ao orçamento de desempenho e às prioridades definidas desde o início.
Definir metas realistas
- Tempo de resposta de 100 milissegundos, 60 fps.
Para que uma interação seja suave, a interface tem 100 ms para responder à entrada do usuário. Mais do que isso, e o usuário percebe o aplicativo como lento. O RAIL, um modelo de desempenho centrado no usuário, oferece metas saudáveis : para permitir uma resposta de <100 milissegundos, a página deve devolver o controle ao encadeamento principal no máximo a cada <50 milissegundos. A latência de entrada estimada nos diz se estamos atingindo esse limite e, idealmente, deve estar abaixo de 50ms. Para pontos de alta pressão como animação, é melhor não fazer mais nada onde puder e o mínimo absoluto onde não puder.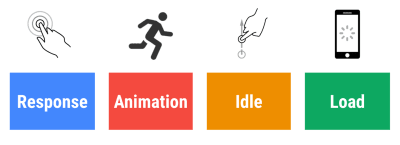
RAIL, um modelo de desempenho centrado no usuário. Além disso, cada quadro de animação deve ser concluído em menos de 16 milissegundos, atingindo assim 60 quadros por segundo (1 segundo ÷ 60 = 16,6 milissegundos) — preferencialmente menos de 10 milissegundos. Como o navegador precisa de tempo para pintar o novo quadro na tela, seu código deve terminar a execução antes de atingir a marca de 16,6 milissegundos. Estamos começando a ter conversas sobre 120fps (por exemplo, as telas do iPad Pro rodam a 120Hz) e a Surma cobriu algumas soluções de desempenho de renderização para 120fps, mas provavelmente não é um alvo que estamos olhando ainda .
Seja pessimista nas expectativas de desempenho, mas seja otimista no design da interface e use o tempo ocioso com sabedoria (verifique idlize, idle-until-urgente e react-idle). Obviamente, esses destinos se aplicam ao desempenho de tempo de execução, em vez de desempenho de carregamento.
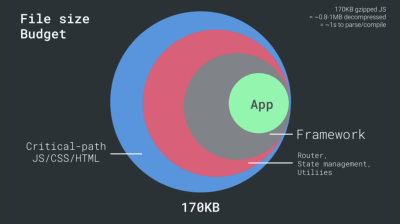
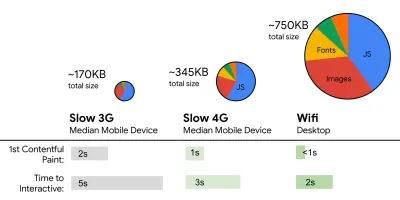
- FID < 100 ms, LCP < 2,5 s, TTI < 5 s em 3G, orçamento de tamanho de arquivo crítico < 170 KB (gzipado).
Embora possa ser muito difícil de alcançar, um bom objetivo final seria o Tempo para Interação abaixo de 5s e, para visitas repetidas, a meta de menos de 2s (alcançável apenas com um service worker). Apontar para a maior pintura de conteúdo de menos de 2,5s e minimizar o tempo total de bloqueio e a mudança de layout cumulativa . Um atraso de primeira entrada aceitável é inferior a 100ms–70ms. Como mencionado acima, estamos considerando que a linha de base seja um telefone Android de US$ 200 (por exemplo, Moto G4) em uma rede 3G lenta, emulado a 400ms RTT e velocidade de transferência de 400kbps.Temos duas restrições principais que moldam efetivamente uma meta razoável para a entrega rápida do conteúdo na web. Por um lado, temos restrições de entrega de rede devido ao TCP Slow Start. Os primeiros 14 KB do HTML — 10 pacotes TCP, cada um com 1.460 bytes, perfazendo cerca de 14,25 KB, embora não devam ser tomados literalmente — é o trecho de carga útil mais crítico e a única parte do orçamento que pode ser entregue na primeira viagem de ida e volta ( que é tudo o que você obtém em 1 segundo a 400ms RTT devido aos horários de ativação do celular).
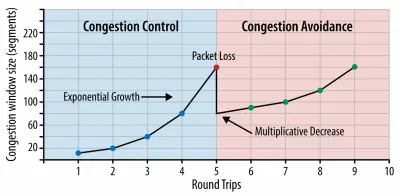
Com conexões TCP, começamos com uma pequena janela de congestionamento e a dobramos para cada viagem de ida e volta. Na primeira viagem de ida e volta, cabem 14 KB. De: Rede de navegadores de alto desempenho por Ilya Grigorik. (Visualização grande) ( Observação : como o TCP geralmente subutiliza a conexão de rede em uma quantidade significativa, o Google desenvolveu a largura de banda do gargalo TCP e o RRT ( BBR ), um algoritmo de controle de fluxo TCP controlado por atraso do TCP. Projetado para a Web moderna, ele responde ao congestionamento real, em vez de perda de pacotes como o TCP faz, é significativamente mais rápido, com maior taxa de transferência e menor latência - e o algoritmo funciona de maneira diferente. ( obrigado, Victor, Barry! )
Por outro lado, temos restrições de hardware na memória e CPU devido aos tempos de análise e execução de JavaScript (falaremos sobre eles em detalhes mais tarde). Para atingir os objetivos declarados no primeiro parágrafo, devemos considerar o orçamento de tamanho de arquivo crítico para JavaScript. As opiniões variam sobre qual deve ser esse orçamento (e depende muito da natureza do seu projeto), mas um orçamento de 170 KB de JavaScript já compactado levaria até 1s para analisar e compilar em um telefone de médio porte. Supondo que 170 KB se expanda para 3 vezes esse tamanho quando descompactado (0,7 MB), isso já pode ser a sentença de morte de uma experiência de usuário "decente" em um Moto G4/G5 Plus.
No caso do site da Wikipedia, em 2020, globalmente, a execução de código ficou 19% mais rápida para os usuários da Wikipedia. Portanto, se suas métricas de desempenho da Web ano a ano permanecerem estáveis, isso geralmente é um sinal de alerta, pois você está realmente regredindo à medida que o ambiente continua melhorando (detalhes em uma postagem no blog de Gilles Dubuc).
Se você deseja atingir mercados em crescimento, como o Sudeste Asiático, África ou Índia, terá que analisar um conjunto muito diferente de restrições. Addy Osmani cobre as principais restrições de recursos de telefonia, como poucos dispositivos de baixo custo e alta qualidade, indisponibilidade de redes de alta qualidade e dados móveis caros - juntamente com orçamento PRPL-30 e diretrizes de desenvolvimento para esses ambientes.
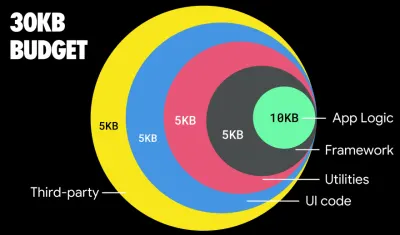
De acordo com Addy Osmani, um tamanho recomendado para rotas de carregamento lento também é inferior a 35 KB. (Visualização grande) 
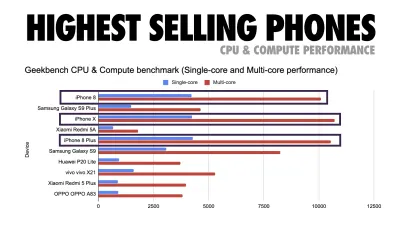
Addy Osmani sugere um orçamento de desempenho PRPL-30 (30 KB compactado + pacote inicial minificado) se tiver como alvo um telefone comum. (Visualização grande) Na verdade, Alex Russell, do Google, recomenda apontar para 130–170 KB compactados como um limite superior razoável. Em cenários do mundo real, a maioria dos produtos não chega nem perto: um tamanho médio de pacote hoje é de cerca de 452 KB, o que representa um aumento de 53,6% em relação ao início de 2015. Em um dispositivo móvel de classe média, isso representa 12 a 20 segundos para o Tempo -Para-Interativo .
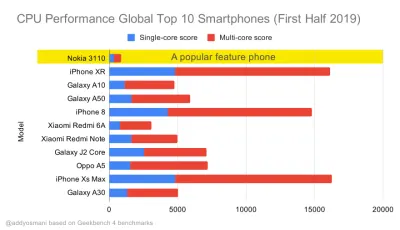
Referências de desempenho de CPU do Geekbench para os smartphones mais vendidos globalmente em 2019. O JavaScript enfatiza o desempenho de núcleo único (lembre-se, é inerentemente mais single-thread do que o restante da plataforma da Web) e é vinculado à CPU. Do artigo de Addy "Carregando páginas da Web rapidamente em um telefone de US $ 20". (Visualização grande) Também poderíamos ir além do orçamento do tamanho do pacote. Por exemplo, podemos definir orçamentos de desempenho com base nas atividades do thread principal do navegador, ou seja, tempo de pintura antes de iniciar a renderização ou rastrear porcos de CPU front-end. Ferramentas como Calibre, SpeedCurve e Bundlesize podem ajudá-lo a manter seus orçamentos sob controle e podem ser integrados ao seu processo de construção.
Por fim, um orçamento de desempenho provavelmente não deve ser um valor fixo . Dependendo da conexão de rede, os orçamentos de desempenho devem se adaptar, mas a carga útil em uma conexão mais lenta é muito mais "caro", independentemente de como eles são usados.
Nota : Pode parecer estranho definir orçamentos tão rígidos em tempos de HTTP/2 generalizado, próximos 5G e HTTP/3, telefones celulares em rápida evolução e SPAs florescentes. No entanto, eles parecem razoáveis quando lidamos com a natureza imprevisível da rede e do hardware, incluindo tudo, desde redes congestionadas até infraestrutura em desenvolvimento lento, limites de dados, navegadores proxy, modo de salvamento de dados e tarifas de roaming sorrateiras.
Definindo o Ambiente
- Escolha e configure suas ferramentas de construção.
Não dê muita atenção ao que é supostamente legal hoje em dia. Atenha-se ao seu ambiente de construção, seja Grunt, Gulp, Webpack, Parcel ou uma combinação de ferramentas. Contanto que você esteja obtendo os resultados de que precisa e não tenha problemas para manter seu processo de compilação, você está indo muito bem.Entre as ferramentas de compilação, o Rollup continua ganhando força, assim como o Snowpack, mas o Webpack parece ser o mais estabelecido, com literalmente centenas de plugins disponíveis para otimizar o tamanho de suas compilações. Fique atento ao Roteiro do Webpack 2021.
Uma das estratégias mais notáveis que apareceram recentemente é o agrupamento granular com Webpack no Next.js e no Gatsby para minimizar o código duplicado. Por padrão, os módulos que não são compartilhados em todos os pontos de entrada podem ser solicitados para rotas que não o utilizam. Isso acaba se tornando uma sobrecarga à medida que mais código é baixado do que o necessário. Com a fragmentação granular no Next.js, podemos usar um arquivo de manifesto de compilação do lado do servidor para determinar quais fragmentos de saída são usados por diferentes pontos de entrada.
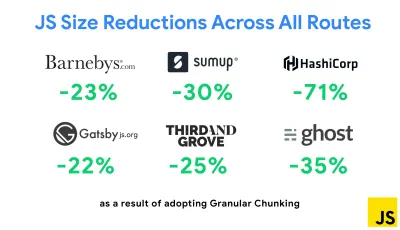
Para reduzir o código duplicado em projetos Webpack, podemos usar fragmentação granular, habilitada em Next.js e Gatsby por padrão. Crédito da imagem: Addy Osmani. (Visualização grande) Com SplitChunksPlugin, vários blocos divididos são criados dependendo de várias condições para evitar a busca de código duplicado em várias rotas. Isso melhora o tempo de carregamento da página e o armazenamento em cache durante as navegações. Enviado no Next.js 9.2 e no Gatsby v2.20.7.
No entanto, começar com o Webpack pode ser difícil. Então, se você quiser mergulhar no Webpack, existem alguns ótimos recursos por aí:
- A documentação do Webpack — obviamente — é um bom ponto de partida, assim como o Webpack — The Confusing Bits de Raja Rao e An Annotated Webpack Config de Andrew Welch.
- Sean Larkin tem um curso gratuito sobre Webpack: The Core Concepts e Jeffrey Way lançou um curso gratuito fantástico sobre Webpack para todos. Ambos são ótimas introduções para mergulhar no Webpack.
- Webpack Fundamentals é um curso de 4h muito abrangente com Sean Larkin, lançado pela FrontendMasters.
- Exemplos de Webpack tem centenas de configurações de Webpack prontas para uso, categorizadas por tópico e finalidade. Bônus: há também um configurador de configuração do Webpack que gera um arquivo de configuração básica.
- awesome-webpack é uma lista com curadoria de recursos, bibliotecas e ferramentas úteis do Webpack, incluindo artigos, vídeos, cursos, livros e exemplos para projetos Angular, React e framework-agnósticos.
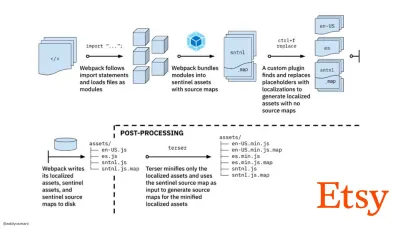
- A jornada para a rápida criação de ativos de produção com o Webpack é o estudo de caso da Etsy sobre como a equipe passou de um sistema de compilação JavaScript baseado em RequireJS para o uso do Webpack e como eles otimizaram suas compilações, gerenciando mais de 13.200 ativos em 4 minutos em média.
- Dicas de desempenho do Webpack é um tópico de mina de ouro de Ivan Akulov, apresentando muitas dicas focadas em desempenho, incluindo aquelas focadas especificamente no Webpack.
- awesome-webpack-perf é um repositório GitHub de mina de ouro com ferramentas e plugins úteis do Webpack para desempenho. Também mantido por Ivan Akulov.
- Use o aprimoramento progressivo como padrão.
Ainda assim, depois de todos esses anos, manter o aprimoramento progressivo como princípio orientador de sua arquitetura e implantação de front-end é uma aposta segura. Projete e construa a experiência principal primeiro e, em seguida, aprimore a experiência com recursos avançados para navegadores capazes, criando experiências resilientes. Se o seu site for executado rápido em uma máquina lenta com uma tela ruim em um navegador ruim em uma rede abaixo do ideal, ele só será executado mais rápido em uma máquina rápida com um bom navegador em uma rede decente.Na verdade, com o serviço de módulo adaptável, parece que estamos levando o aprimoramento progressivo a outro nível, oferecendo experiências básicas "leves" para dispositivos de baixo custo e aprimorando com recursos mais sofisticados para dispositivos de ponta. O aprimoramento progressivo provavelmente não desaparecerá tão cedo.
- Escolha uma linha de base de desempenho forte.
Com tantas incógnitas afetando o carregamento - a rede, limitação térmica, remoção de cache, scripts de terceiros, padrões de bloqueio de analisador, E/S de disco, latência de IPC, extensões instaladas, software antivírus e firewalls, tarefas de CPU em segundo plano, restrições de hardware e memória, diferenças no cache L2/L3, RTTS — JavaScript tem o custo mais alto da experiência, ao lado de fontes da Web que bloqueiam a renderização por padrão e imagens geralmente consumindo muita memória. Com os gargalos de desempenho se afastando do servidor para o cliente, como desenvolvedores, temos que considerar todas essas incógnitas com muito mais detalhes.Com um orçamento de 170 KB que já contém o caminho crítico HTML/CSS/JavaScript, roteador, gerenciamento de estado, utilitários, estrutura e a lógica do aplicativo, temos que examinar minuciosamente o custo de transferência de rede, o tempo de análise/compilação e o custo de tempo de execução do quadro de nossa escolha. Felizmente, vimos uma grande melhoria nos últimos anos na rapidez com que os navegadores podem analisar e compilar scripts. No entanto, a execução do JavaScript ainda é o principal gargalo, portanto, prestar muita atenção ao tempo de execução do script e à rede pode ser impactante.
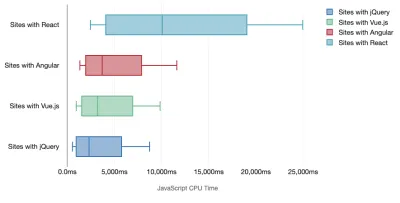
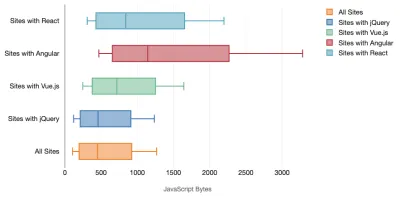
Tim Kadlec conduziu uma pesquisa fantástica sobre o desempenho de frameworks modernos e os resumiu no artigo "Os frameworks JavaScript têm um custo". Costumamos falar sobre o impacto de estruturas independentes, mas, como observa Tim, na prática, não é incomum ter várias estruturas em uso . Talvez uma versão mais antiga do jQuery que está sendo migrada lentamente para uma estrutura moderna, juntamente com alguns aplicativos legados usando uma versão mais antiga do Angular. Portanto, é mais razoável explorar o custo cumulativo de bytes JavaScript e o tempo de execução da CPU que podem facilmente tornar as experiências do usuário quase inúteis, mesmo em dispositivos de última geração.
Em geral, as estruturas modernas não priorizam dispositivos menos poderosos , portanto, as experiências em um telefone e em um desktop geralmente serão drasticamente diferentes em termos de desempenho. De acordo com a pesquisa, sites com React ou Angular gastam mais tempo na CPU do que outros (o que obviamente não quer dizer que React é mais caro na CPU do que Vue.js).
De acordo com Tim, uma coisa é óbvia: "se você estiver usando uma estrutura para construir seu site, estará fazendo uma troca em termos de desempenho inicial - mesmo nos melhores cenários".
- Avalie estruturas e dependências.
Agora, nem todo projeto precisa de uma estrutura e nem toda página de um aplicativo de página única precisa carregar uma estrutura. No caso da Netflix, "remover o React, várias bibliotecas e o código de aplicativo correspondente do lado do cliente reduziu a quantidade total de JavaScript em mais de 200 KB, causando uma redução de mais de 50% no tempo de interatividade da Netflix para a página inicial desconectada ." A equipe então utilizou o tempo gasto pelos usuários na página de destino para pré-buscar o React para as páginas subsequentes que os usuários provavelmente acessariam (leia para obter detalhes).E daí se você remover completamente uma estrutura existente em páginas críticas? Com o Gatsby, você pode verificar o gatsby-plugin-no-javascript que remove todos os arquivos JavaScript criados pelo Gatsby dos arquivos HTML estáticos. No Vercel, você também pode permitir desabilitar o JavaScript em tempo de execução em produção para determinadas páginas (experimental).
Depois que uma estrutura for escolhida, permaneceremos com ela por pelo menos alguns anos, portanto, se precisarmos usar uma, precisamos garantir que nossa escolha seja informada e bem considerada - e isso vale especialmente para as principais métricas de desempenho que se importar.
Os dados mostram que, por padrão, os frameworks são bastante caros: 58,6% das páginas React enviam mais de 1 MB de JavaScript e 36% dos carregamentos de página Vue.js têm uma primeira pintura de conteúdo de <1,5s. De acordo com um estudo da Ankur Sethi, "seu aplicativo React nunca carregará mais rápido do que cerca de 1,1 segundo em um telefone médio na Índia, não importa o quanto você o otimize. Seu aplicativo Angular sempre levará pelo menos 2,7 segundos para inicializar. O os usuários do seu aplicativo Vue precisarão esperar pelo menos 1 segundo antes de poderem começar a usá-lo." Você pode não estar segmentando a Índia como seu mercado principal, mas os usuários que acessam seu site com condições de rede abaixo do ideal terão uma experiência comparável.
É claro que é possível fazer SPAs rápidos, mas eles não são rápidos de fábrica, então precisamos levar em conta o tempo e o esforço necessários para fazê -los e mantê -los rápidos. Provavelmente será mais fácil escolher um custo de desempenho de linha de base leve desde o início.
Então, como escolhemos uma estrutura ? É uma boa ideia considerar pelo menos o custo total em tamanho + tempos de execução iniciais antes de escolher uma opção; opções leves como Preact, Inferno, Vue, Svelte, Alpine ou Polymer podem fazer o trabalho muito bem. O tamanho de sua linha de base definirá as restrições para o código do seu aplicativo.
Conforme observado por Seb Markbage, uma boa maneira de medir os custos iniciais de estruturas é primeiro renderizar uma visualização, excluí-la e renderizar novamente , pois isso pode informar como a estrutura é dimensionada. A primeira renderização tende a aquecer um monte de código compilado preguiçosamente, do qual uma árvore maior pode se beneficiar quando for dimensionada. A segunda renderização é basicamente uma emulação de como a reutilização de código em uma página afeta as características de desempenho à medida que a página cresce em complexidade.
Você pode avaliar seus candidatos (ou qualquer biblioteca JavaScript em geral) no sistema de pontuação de escala de 12 pontos da Sacha Greif explorando recursos, acessibilidade, estabilidade, desempenho, ecossistema de pacotes , comunidade, curva de aprendizado, documentação, ferramentas, histórico , equipe, compatibilidade, segurança por exemplo.
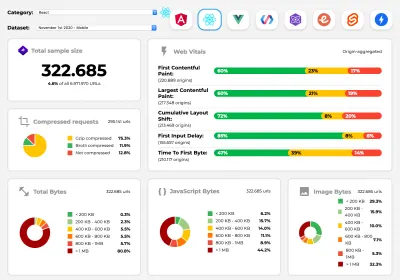
Perf Track rastreia o desempenho da estrutura em escala. (Visualização grande) Você também pode confiar nos dados coletados na web por um longo período de tempo. Por exemplo, o Perf Track rastreia o desempenho da estrutura em escala, mostrando pontuações de Core Web Vitals agregadas de origem para sites criados em Angular, React, Vue, Polymer, Preact, Ember, Svelte e AMP. Você pode até especificar e comparar sites criados com Gatsby, Next.js ou Create React App, bem como sites criados com Nuxt.js (Vue) ou Sapper (Svelte).
Um bom ponto de partida é escolher uma boa pilha padrão para seu aplicativo. Gatsby (React), Next.js (React), Vuepress (Vue), Preact CLI e PWA Starter Kit fornecem padrões razoáveis para carregamento rápido pronto para uso em hardware móvel médio. Além disso, dê uma olhada na orientação de desempenho específica do framework web.dev para React e Angular ( obrigado, Phillip! ).
E talvez você possa adotar uma abordagem um pouco mais atualizada para criar aplicativos de página única – Turbolinks, uma biblioteca JavaScript de 15 KB que usa HTML em vez de JSON para renderizar visualizações. Portanto, quando você segue um link, o Turbolinks busca automaticamente a página, troca seu
<body>e mescla seu<head>, tudo sem incorrer no custo de um carregamento completo da página. Você pode verificar detalhes rápidos e documentação completa sobre a pilha (Hotwire).
- Renderização do lado do cliente ou renderização do lado do servidor? Ambos!
Essa é uma conversa bastante acalorada para se ter. A abordagem final seria configurar algum tipo de inicialização progressiva: use a renderização do lado do servidor para obter uma primeira exibição de conteúdo rápida, mas também inclua algum JavaScript mínimo necessário para manter o tempo de interação próximo ao da primeira exibição de conteúdo. Se o JavaScript chegar muito tarde após o FCP, o navegador bloqueará o thread principal ao analisar, compilar e executar o JavaScript descoberto tardiamente, prejudicando a interatividade do site ou aplicativo.Para evitá-lo, sempre divida a execução de funções em tarefas assíncronas separadas e, sempre que possível, use
requestIdleCallback. Considere o carregamento lento de partes da interface do usuário usando o suporte dynamicimport()do WebPack, evitando o custo de carregamento, análise e compilação até que os usuários realmente precisem deles ( obrigado Addy! ).Como mencionado acima, o Time to Interactive (TTI) nos informa o tempo entre a navegação e a interatividade. Em detalhes, a métrica é definida observando a primeira janela de cinco segundos após a renderização do conteúdo inicial, na qual nenhuma tarefa JavaScript leva mais de 50 ms ( Long Tasks ). Se ocorrer uma tarefa com mais de 50ms, a busca por uma janela de cinco segundos recomeça. Como resultado, o navegador primeiro assumirá que atingiu Interactive , apenas para mudar para Frozen , apenas para eventualmente voltar para Interactive .
Assim que chegarmos ao Interactive , podemos - sob demanda ou conforme o tempo permitir - inicializar partes não essenciais do aplicativo. Infelizmente, como Paul Lewis notou, os frameworks normalmente não têm um conceito simples de prioridade que possa ser apresentado aos desenvolvedores e, portanto, a inicialização progressiva não é fácil de implementar com a maioria das bibliotecas e frameworks.
Ainda assim, estamos chegando lá. Atualmente, existem algumas opções que podemos explorar, e Houssein Djirdeh e Jason Miller fornecem uma excelente visão geral dessas opções em sua palestra sobre Rendering on the Web e no artigo de Jason e Addy sobre Modern Front-End Architectures. A visão geral abaixo é baseada em seu trabalho estelar.
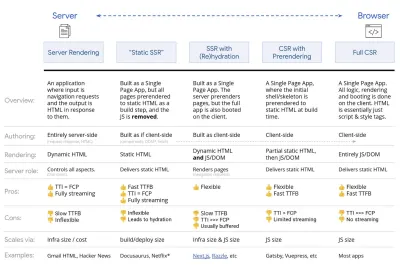
- Renderização completa do lado do servidor (SSR)
No SSR clássico, como o WordPress, todas as solicitações são tratadas inteiramente no servidor. O conteúdo solicitado é retornado como uma página HTML finalizada e os navegadores podem renderizá-lo imediatamente. Portanto, os aplicativos SSR não podem realmente usar as APIs DOM, por exemplo. A diferença entre a primeira pintura de conteúdo e o tempo de interação geralmente é pequena, e a página pode ser renderizada imediatamente à medida que o HTML está sendo transmitido para o navegador.Isso evita viagens de ida e volta adicionais para busca e modelagem de dados no cliente, pois isso é tratado antes que o navegador obtenha uma resposta. No entanto, acabamos com um tempo de raciocínio do servidor mais longo e, consequentemente, com o tempo até o primeiro byte e não usamos recursos responsivos e ricos de aplicativos modernos.
- Renderização estática
Construímos o produto como um aplicativo de página única, mas todas as páginas são pré-renderizadas para HTML estático com JavaScript mínimo como uma etapa de construção. Isso significa que, com renderização estática, produzimos arquivos HTML individuais para cada URL possível com antecedência, algo que poucos aplicativos podem pagar. Mas como o HTML de uma página não precisa ser gerado instantaneamente, podemos obter um tempo até o primeiro byte consistentemente rápido. Assim, podemos exibir uma página de destino rapidamente e, em seguida, pré-buscar uma estrutura SPA para as páginas subsequentes. A Netflix adotou essa abordagem, reduzindo o carregamento e o tempo para interação em 50%. - Renderização do lado do servidor com (Re)hidratação (Renderização universal, SSR + CSR)
Podemos tentar usar o melhor dos dois mundos – as abordagens SSR e CSR. Com hidratação na mistura, a página HTML retornada do servidor também contém um script que carrega um aplicativo completo do lado do cliente. Idealmente, que obtenha uma primeira pintura de conteúdo rápida (como SSR) e continue a renderização com (re)hidratação. Infelizmente, isso raramente acontece. Mais frequentemente, a página parece pronta, mas não pode responder à entrada do usuário, produzindo cliques de raiva e abandonos.Com o React, podemos usar o módulo
ReactDOMServerem um servidor Node como o Express, e então chamar o métodorenderToStringpara renderizar os componentes de nível superior como uma string HTML estática.Com o Vue.js, podemos usar o vue-server-renderer para renderizar uma instância do Vue em HTML usando
renderToString. Em Angular, podemos usar@nguniversalpara transformar solicitações de clientes em páginas HTML totalmente renderizadas pelo servidor. Uma experiência totalmente renderizada pelo servidor também pode ser obtida imediatamente com Next.js (React) ou Nuxt.js (Vue).A abordagem tem suas desvantagens. Como resultado, ganhamos total flexibilidade de aplicativos do lado do cliente ao mesmo tempo em que fornecemos renderização mais rápida do lado do servidor, mas também acabamos com uma lacuna maior entre a primeira pintura de conteúdo e o tempo de interação e um atraso maior na primeira entrada. A reidratação é muito cara e, geralmente, essa estratégia sozinha não será boa o suficiente, pois atrasa muito o Time To Interactive.
- Streaming de renderização do lado do servidor com hidratação progressiva (SSR + CSR)
Para minimizar a lacuna entre o tempo de interação e a primeira pintura de conteúdo, renderizamos várias solicitações de uma só vez e enviamos o conteúdo em partes à medida que são gerados. Portanto, não precisamos esperar pela sequência completa de HTML antes de enviar o conteúdo para o navegador e, portanto, melhorar o tempo até o primeiro byte.Em React, em vez de
renderToString(), podemos usar renderToNodeStream() para canalizar a resposta e enviar o HTML em partes. No Vue, podemos usar renderToStream() que pode ser canalizado e transmitido. Com o React Suspense, podemos usar renderização assíncrona para esse propósito também.No lado do cliente, em vez de inicializar todo o aplicativo de uma vez, inicializamos os componentes progressivamente . As seções dos aplicativos são primeiro divididas em scripts autônomos com divisão de código e, em seguida, hidratadas gradualmente (na ordem de nossas prioridades). Na verdade, podemos hidratar os componentes críticos primeiro, enquanto o resto pode ser hidratado mais tarde. A função de renderização do lado do cliente e do lado do servidor pode ser definida de forma diferente por componente. Também podemos adiar a hidratação de alguns componentes até que eles apareçam ou sejam necessários para a interação do usuário ou quando o navegador estiver ocioso.
Para o Vue, Markus Oberlehner publicou um guia sobre como reduzir o tempo de interação de aplicativos SSR usando hidratação na interação do usuário, bem como vue-lazy-hydration, um plug-in em estágio inicial que permite a hidratação do componente na visibilidade ou interação específica do usuário. A equipe Angular trabalha na hidratação progressiva com Ivy Universal. Você também pode implementar a hidratação parcial com Preact e Next.js.
- Renderização Trisomórfica
Com os service workers em vigor, podemos usar a renderização do servidor de streaming para navegações iniciais/não JS e, em seguida, fazer com que o service worker assuma a renderização do HTML para navegações após a instalação. Nesse caso, o service worker pré-renderiza o conteúdo e habilita as navegações no estilo SPA para renderizar novas exibições na mesma sessão. Funciona bem quando você pode compartilhar o mesmo código de modelagem e roteamento entre o servidor, a página do cliente e o service worker.
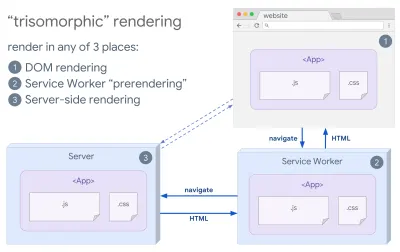
Renderização trisomórfica, com a mesma renderização de código em 3 lugares: no servidor, no DOM ou em um service worker. (Fonte da imagem: Google Developers) (Visualização grande) - CSR com pré-renderização
A pré-renderização é semelhante à renderização do lado do servidor, mas em vez de renderizar páginas no servidor dinamicamente, renderizamos o aplicativo para HTML estático no momento da compilação. Embora as páginas estáticas sejam totalmente interativas sem muito JavaScript do lado do cliente, a pré- renderização funciona de maneira diferente . Basicamente, ele captura o estado inicial de um aplicativo do lado do cliente como HTML estático em tempo de compilação, enquanto com a pré-renderização o aplicativo deve ser inicializado no cliente para que as páginas sejam interativas.Com o Next.js, podemos usar a exportação de HTML estático pré-renderizando um aplicativo para HTML estático. No Gatsby, um gerador de site estático de código aberto que usa React, usa o método
renderToStaticMarkupem vez do métodorenderToStringdurante as compilações, com o bloco JS principal sendo pré-carregado e as rotas futuras são pré-buscadas, sem atributos DOM que não são necessários para páginas estáticas simples.Para o Vue, podemos usar o Vuepress para atingir o mesmo objetivo. Você também pode usar o prerender-loader com o Webpack. O Navi também fornece renderização estática.
O resultado é um melhor tempo até o primeiro byte e primeira pintura de conteúdo, e reduzimos a lacuna entre o tempo de interação e a primeira pintura de conteúdo. Não podemos usar a abordagem se espera-se que o conteúdo mude muito. Além disso, todos os URLs precisam ser conhecidos com antecedência para gerar todas as páginas. Portanto, alguns componentes podem ser renderizados usando pré-renderização, mas se precisarmos de algo dinâmico, teremos que confiar no aplicativo para buscar o conteúdo.
- Renderização completa do lado do cliente (CSR)
Toda a lógica, renderização e inicialização são feitas no cliente. O resultado geralmente é uma enorme lacuna entre o tempo para interação e a primeira pintura de conteúdo. Como resultado, os aplicativos geralmente parecem lentos , pois o aplicativo inteiro precisa ser inicializado no cliente para renderizar qualquer coisa.Como o JavaScript tem um custo de desempenho, à medida que a quantidade de JavaScript cresce com um aplicativo, a divisão agressiva de código e o adiamento do JavaScript serão absolutamente necessários para domar o impacto do JavaScript. Para esses casos, uma renderização do lado do servidor geralmente será uma abordagem melhor, caso não seja necessária muita interatividade. Se não for uma opção, considere usar o App Shell Model.
Em geral, o SSR é mais rápido que o CSR. Ainda assim, é uma implementação bastante frequente para muitos aplicativos por aí.
Então, do lado do cliente ou do lado do servidor? Em geral, é uma boa ideia limitar o uso de estruturas totalmente do lado do cliente a páginas que as exigem absolutamente. Para aplicativos avançados, também não é uma boa ideia confiar apenas na renderização do lado do servidor. Tanto a renderização do servidor quanto a renderização do cliente são um desastre se forem mal feitas.
Se você está inclinado para CSR ou SSR, certifique-se de renderizar pixels importantes o mais rápido possível e minimizar a lacuna entre essa renderização e o tempo de interação. Considere a pré-renderização se suas páginas não mudarem muito e adie a inicialização dos frameworks se puder. Transmita HTML em partes com renderização do lado do servidor e implemente hidratação progressiva para renderização do lado do cliente — e hidrate-se na visibilidade, interação ou durante o tempo ocioso para obter o melhor dos dois mundos.
- Renderização completa do lado do servidor (SSR)

- Quanto podemos servir estaticamente?
Esteja você trabalhando em um aplicativo grande ou em um site pequeno, vale a pena considerar qual conteúdo pode ser servido estaticamente a partir de um CDN (ou seja, JAM Stack), em vez de ser gerado dinamicamente em tempo real. Mesmo se você tiver milhares de produtos e centenas de filtros com muitas opções de personalização, ainda poderá servir suas páginas de destino críticas estaticamente e desacoplar essas páginas da estrutura de sua escolha.Existem muitos geradores de sites estáticos e as páginas que eles geram geralmente são muito rápidas. Quanto mais conteúdo pudermos pré-construir antecipadamente em vez de gerar visualizações de página em um servidor ou cliente no momento da solicitação, melhor desempenho alcançaremos.
Em Construindo Sites Estáticos Parcialmente Hidratados e Progressivamente Aprimorados, Markus Oberlehner mostra como construir sites com um gerador de sites estáticos e um SPA, enquanto obtém aprimoramento progressivo e um tamanho mínimo de pacote JavaScript. Markus usa Eleventy e Preact como suas ferramentas e mostra como configurar as ferramentas, adicionar hidratação parcial, hidratação preguiçosa, arquivo de entrada de cliente, configurar Babel para Preact e agrupar Preact com Rollup — do início ao fim.
Com o JAMStack usado em grandes sites atualmente, uma nova consideração de desempenho apareceu: o tempo de construção . Na verdade, criar até milhares de páginas a cada nova implantação pode levar minutos, por isso é promissor ver compilações incrementais no Gatsby que melhoram os tempos de compilação em 60 vezes , com integração em soluções CMS populares como WordPress, Contentful, Drupal, Netlify CMS e outros.
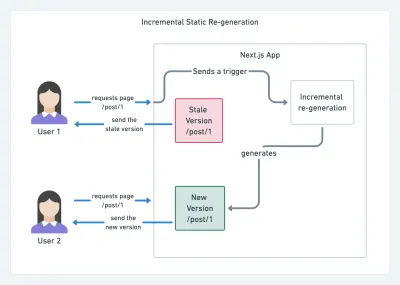
Regeneração estática incremental com Next.js. (Crédito da imagem: Prisma.io) (Visualização grande) Além disso, o Next.js anunciou a geração estática incremental e antecipada, que nos permite adicionar novas páginas estáticas em tempo de execução e atualizar as páginas existentes depois que elas já foram criadas, renderizando-as novamente em segundo plano à medida que o tráfego chega .
Precisa de uma abordagem ainda mais leve? Em sua palestra sobre Eleventy, Alpine e Tailwind: rumo a um Jamstack leve, Nicola Gutay explica as diferenças entre CSR, SSR e tudo no meio, e mostra como usar uma abordagem mais leve - junto com um repositório do GitHub que mostra a abordagem na prática.
- Considere usar o padrão PRPL e a arquitetura do shell do aplicativo.
Estruturas diferentes terão efeitos diferentes no desempenho e exigirão diferentes estratégias de otimização, portanto, você precisa entender claramente todos os detalhes da estrutura em que estará confiando. Ao criar um aplicativo da Web, observe o padrão PRPL e a arquitetura do shell do aplicativo. A ideia é bem direta: envie o código mínimo necessário para ser interativo para que a rota inicial seja renderizada rapidamente, depois use o service worker para recursos de armazenamento em cache e pré-cache e, em seguida, carregue lentamente as rotas de que você precisa, de forma assíncrona.
- Você otimizou o desempenho de suas APIs?
APIs são canais de comunicação para um aplicativo expor dados a aplicativos internos e de terceiros por meio de endpoints . Ao projetar e construir uma API, precisamos de um protocolo razoável para permitir a comunicação entre o servidor e as solicitações de terceiros. Representational State Transfer ( REST ) é uma escolha lógica e bem estabelecida: ela define um conjunto de restrições que os desenvolvedores seguem para tornar o conteúdo acessível de maneira eficiente, confiável e escalável. Os serviços da Web que estão em conformidade com as restrições REST são chamados de serviços da Web RESTful .Assim como acontece com as boas e velhas solicitações HTTP, quando os dados são recuperados de uma API, qualquer atraso na resposta do servidor será propagado para o usuário final, atrasando a renderização . Quando um recurso deseja recuperar alguns dados de uma API, ele precisará solicitar os dados do endpoint correspondente. Um componente que renderiza dados de vários recursos, como um artigo com comentários e fotos do autor em cada comentário, pode precisar de várias viagens de ida e volta ao servidor para buscar todos os dados antes que possam ser renderizados. Além disso, a quantidade de dados retornados por meio do REST geralmente é maior do que o necessário para renderizar esse componente.
Se muitos recursos exigirem dados de uma API, a API poderá se tornar um gargalo de desempenho. O GraphQL fornece uma solução de alto desempenho para esses problemas. Por si só, o GraphQL é uma linguagem de consulta para sua API e um tempo de execução do lado do servidor para executar consultas usando um sistema de tipos que você define para seus dados. Ao contrário do REST, o GraphQL pode recuperar todos os dados em uma única solicitação e a resposta será exatamente o que é necessário, sem excesso ou falta de dados, como normalmente acontece com o REST.
Além disso, como o GraphQL está usando o esquema (metadados que informam como os dados estão estruturados), ele já pode organizar os dados na estrutura preferida, então, por exemplo, com o GraphQL, poderíamos remover o código JavaScript usado para lidar com o gerenciamento de estados, produzindo um código de aplicativo mais limpo que é executado mais rapidamente no cliente.
Se você quiser começar a usar o GraphQL ou encontrar problemas de desempenho, estes artigos podem ser bastante úteis:
- A GraphQL Primer: Por que precisamos de um novo tipo de API por Eric Baer,
- A GraphQL Primer: A evolução do design de API por Eric Baer,
- Projetando um servidor GraphQL para desempenho ideal por Leonardo Losoviz,
- Desempenho do GraphQL explicado por Wojciech Trocki.
- Você usará AMP ou Instant Articles?
Dependendo das prioridades e da estratégia da sua organização, você pode considerar usar o AMP do Google ou os Instant Articles do Facebook ou o Apple News da Apple. Você pode obter um bom desempenho sem eles, mas o AMP fornece uma estrutura de desempenho sólida com uma rede de entrega de conteúdo gratuita (CDN), enquanto os Instant Articles aumentarão sua visibilidade e desempenho no Facebook.O benefício aparentemente óbvio dessas tecnologias para os usuários é o desempenho garantido , portanto, às vezes, eles podem até preferir links AMP/Apple News/Instant Pages a páginas "regulares" e potencialmente inchadas. Para sites com conteúdo pesado que lidam com muito conteúdo de terceiros, essas opções podem ajudar a acelerar drasticamente os tempos de renderização.
A menos que não. De acordo com Tim Kadlec, por exemplo, "documentos AMP tendem a ser mais rápidos do que seus equivalentes, mas não significam necessariamente que uma página tem desempenho. AMP não é o que faz a maior diferença do ponto de vista do desempenho".
Um benefício para o proprietário do site é óbvio: descoberta desses formatos em suas respectivas plataformas e maior visibilidade nos mecanismos de pesquisa.
Bem, pelo menos era assim que costumava ser. Como o AMP não é mais um requisito para o Top Stories , os editores podem estar migrando do AMP para uma pilha tradicional ( obrigado, Barry! ).
Ainda assim, você também pode criar AMPs progressivos da Web, reutilizando AMPs como fonte de dados para seu PWA. Desvantagem? Obviamente, uma presença em um jardim murado coloca os desenvolvedores em posição de produzir e manter uma versão separada de seu conteúdo, e no caso de Instant Articles e Apple News sem URLs reais (obrigado Addy, Jeremy!) .
- Escolha sua CDN com sabedoria.
Conforme mencionado acima, dependendo da quantidade de dados dinâmicos que você possui, você pode "terceirizar" parte do conteúdo para um gerador de site estático, enviando-o para um CDN e servindo uma versão estática dele, evitando assim solicitações ao servidor. Na verdade, alguns desses geradores são compiladores de sites com muitas otimizações automatizadas fornecidas prontas para uso. À medida que os compiladores adicionam otimizações ao longo do tempo, a saída compilada fica menor e mais rápida ao longo do tempo.Observe que as CDNs também podem servir (e descarregar) conteúdo dinâmico. Portanto, não é necessário restringir sua CDN a ativos estáticos. Verifique se o seu CDN realiza compactação e conversão (por exemplo, otimização de imagem e redimensionamento na borda), se eles fornecem suporte para trabalhadores de servidores, testes A/B, bem como inclusões de borda, que montam partes estáticas e dinâmicas de páginas na borda do CDN (ou seja, o servidor mais próximo do usuário) e outras tarefas. Além disso, verifique se o seu CDN suporta HTTP sobre QUIC (HTTP/3).
Katie Hempenius escreveu um guia fantástico para CDNs que fornece informações sobre como escolher um bom CDN , como ajustá-lo e todas as pequenas coisas a serem lembradas ao avaliar um. Em geral, é uma boa ideia armazenar em cache o conteúdo da forma mais agressiva possível e habilitar recursos de desempenho de CDN como Brotli, TLS 1.3, HTTP/2 e HTTP/3.
Nota : com base na pesquisa de Patrick Meenan e Andy Davies, a priorização HTTP/2 é efetivamente quebrada em muitas CDNs, portanto, tenha cuidado ao escolher uma CDN. Patrick tem mais detalhes em sua palestra sobre priorização HTTP/2 ( obrigado, Barry! ).
O CDNPerf mede a velocidade de consulta para CDNs reunindo e analisando 300 milhões de testes todos os dias. (Visualização grande) Ao escolher uma CDN, você pode usar esses sites de comparação com uma visão detalhada de seus recursos:
- Comparação de CDN, uma matriz de comparação de CDN para Cloudfront, Aazure, KeyCDN, Fastly, Verizon, Stackpach, Akamai e muitos outros.
- O CDN Perf mede a velocidade de consulta para CDNs reunindo e analisando 300 milhões de testes todos os dias, com todos os resultados baseados em dados RUM de usuários de todo o mundo. Verifique também a comparação de desempenho de DNS e a comparação de desempenho de nuvem.
- O CDN Planet Guides fornece uma visão geral das CDNs para tópicos específicos, como Servir obsoleto, Purge, Origin Shield, Prefetch e Compression.
- Web Almanac: CDN Adoption and Usage fornece informações sobre os principais provedores de CDN, seu gerenciamento de RTT e TLS, tempo de negociação de TLS, adoção de HTTP/2 e outros. (Infelizmente, os dados são apenas de 2019).
Otimizações de recursos
- Use Brotli para compactação de texto simples.
Em 2015, o Google lançou o Brotli, um novo formato de dados sem perdas de código aberto, que agora é compatível com todos os navegadores modernos. A biblioteca de código aberto Brotli, que implementa um codificador e decodificador para Brotli, possui 11 níveis de qualidade predefinidos para o codificador, com um nível de qualidade mais alto exigindo mais CPU em troca de uma melhor taxa de compactação. A compactação mais lenta levará a taxas de compactação mais altas, mas ainda assim, o Brotli descompacta rapidamente. Vale a pena notar que o Brotli com o nível de compactação 4 é menor e compacta mais rápido que o Gzip.Na prática, o Brotli parece ser muito mais eficaz que o Gzip. As opiniões e experiências diferem, mas se o seu site já estiver otimizado com Gzip, você pode esperar pelo menos melhorias de um dígito e, na melhor das hipóteses, melhorias de dois dígitos na redução de tamanho e nos tempos de FCP. Você também pode estimar a economia de compactação do Brotli para o seu site.
Os navegadores aceitarão o Brotli somente se o usuário estiver visitando um site por HTTPS. O Brotli é amplamente suportado e muitos CDNs o suportam (Akamai, Netlify Edge, AWS, KeyCDN, Fastly (atualmente apenas como pass-through), Cloudflare, CDN77) e você pode habilitar o Brotli mesmo em CDNs que ainda não o suportam (com um trabalhador de serviço).
O problema é que, como a compactação de todos os ativos com o Brotli em um alto nível de compactação é caro, muitos provedores de hospedagem não podem usá-lo em escala total apenas devido à enorme sobrecarga de custos que ele produz. Na verdade, no nível mais alto de compactação, o Brotli é tão lento que qualquer ganho potencial no tamanho do arquivo pode ser anulado pelo tempo que leva para o servidor começar a enviar a resposta enquanto espera para compactar dinamicamente o ativo. (Mas se você tiver tempo durante o tempo de compilação com compactação estática, é claro que as configurações de compactação mais altas são preferidas.)
Comparação de tempos de back-end de vários métodos de compactação. Sem surpresa, o Brotli é mais lento que o gzip (por enquanto). (Visualização grande) Isso pode estar mudando embora. O formato de arquivo Brotli inclui um dicionário estático integrado e, além de conter várias strings em vários idiomas, também suporta a opção de aplicar várias transformações a essas palavras, aumentando sua versatilidade. Em sua pesquisa, Felix Hanau descobriu uma maneira de melhorar a compactação nos níveis 5 a 9 usando "um subconjunto mais especializado do dicionário do que o padrão" e contando com o cabeçalho
Content-Typepara informar ao compressor se ele deve usar um dicionário para HTML, JavaScript ou CSS. O resultado foi um "impacto de desempenho insignificante (1% a 3% a mais de CPU em comparação com 12% normalmente) ao compactar conteúdo da Web em altos níveis de compactação, usando uma abordagem de uso limitado de dicionário".
Com a abordagem de dicionário aprimorada, podemos compactar ativos mais rapidamente em níveis de compactação mais altos, usando apenas 1% a 3% a mais de CPU. Normalmente, o nível de compactação 6 sobre 5 aumentaria o uso da CPU em até 12%. (Visualização grande) Além disso, com a pesquisa de Elena Kirilenko, podemos obter uma recompressão Brotli rápida e eficiente usando artefatos de compressão anteriores. De acordo com Elena, "uma vez que temos um ativo compactado via Brotli, e estamos tentando compactar conteúdo dinâmico dinamicamente, onde o conteúdo se assemelha ao conteúdo disponível para nós antes do tempo, podemos obter melhorias significativas nos tempos de compactação. "
Quantas vezes é o caso? Por exemplo, com entrega de subconjuntos de bundles JavaScript (por exemplo, quando partes do código já estão armazenadas em cache no cliente ou com bundle dinâmico servindo com WebBundles). Ou com HTML dinâmico baseado em modelos conhecidos antecipadamente ou fontes WOFF2 subconjuntos dinamicamente . De acordo com Elena, podemos obter 5,3% de melhoria na compactação e 39% na velocidade de compactação ao remover 10% do conteúdo e 3,2% melhores taxas de compactação e compactação 26% mais rápida, ao remover 50% do conteúdo.
A compactação Brotli está melhorando, portanto, se você puder contornar o custo de compactar dinamicamente ativos estáticos, definitivamente vale a pena o esforço. Escusado será dizer que o Brotli pode ser usado para qualquer carga útil de texto simples — HTML, CSS, SVG, JavaScript, JSON e assim por diante.
Observação : no início de 2021, aproximadamente 60% das respostas HTTP são entregues sem compactação baseada em texto, com 30,82% compactando com Gzip e 9,1% compactando com Brotli (tanto em dispositivos móveis quanto em desktops). Por exemplo, 23,4% das páginas Angular não são compactadas (via gzip ou Brotli). No entanto, muitas vezes, ativar a compactação é uma das vitórias mais fáceis para melhorar o desempenho com um simples toque de um botão.
A estratégia? Pré-compacte ativos estáticos com Brotli+Gzip no nível mais alto e compactar HTML (dinâmico) dinamicamente com Brotli no nível 4–6. Certifique-se de que o servidor lide com a negociação de conteúdo para Brotli ou Gzip corretamente.
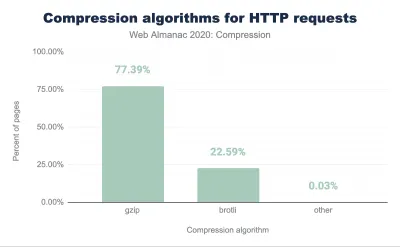
- Usamos carregamento de mídia adaptável e dicas do cliente?
Está vindo da terra das notícias antigas, mas é sempre um bom lembrete usar imagens responsivas comsrcset,sizese o elemento<picture>. Especialmente para sites com uma pegada de mídia pesada, podemos dar um passo adiante com carregamento de mídia adaptável (neste exemplo React + Next.js), oferecendo experiência leve para redes lentas e dispositivos com pouca memória e experiência completa para rede rápida e alta -dispositivos de memória. No contexto do React, podemos alcançá-lo com dicas do cliente no servidor e ganchos adaptáveis de reação no cliente.O futuro das imagens responsivas pode mudar drasticamente com a adoção mais ampla das dicas do cliente. As dicas do cliente são campos de cabeçalho de solicitação HTTP, por exemplo,
DPR,Viewport-Width,Width,Save-Data,Accept(para especificar preferências de formato de imagem) e outros. Eles devem informar o servidor sobre as especificidades do navegador do usuário, tela, conexão etc.Como resultado, o servidor pode decidir como preencher o layout com imagens de tamanho apropriado e servir apenas essas imagens nos formatos desejados. Com as dicas do cliente, movemos a seleção de recursos da marcação HTML para a negociação de solicitação-resposta entre o cliente e o servidor.
Mídia adaptável servindo em uso. Enviamos um placeholder com texto para usuários que estão offline, uma imagem de baixa resolução para usuários de 2G, uma imagem de alta resolução para usuários de 3G e um vídeo HD para usuários de 4G. Via Carregando páginas da web rapidamente em um telefone comum de US$ 20. (Visualização grande) Como Ilya Grigorik observou há algum tempo, as dicas do cliente completam o quadro – elas não são uma alternativa para imagens responsivas. "O elemento
<picture>fornece o controle de direção de arte necessário na marcação HTML. As dicas do cliente fornecem anotações nas solicitações de imagem resultantes que permitem a automação da seleção de recursos. O Service Worker fornece recursos completos de gerenciamento de solicitação e resposta no cliente."Um service worker pode, por exemplo, anexar novos valores de cabeçalhos de dicas do cliente à solicitação, reescrever a URL e apontar a solicitação de imagem para um CDN, adaptar a resposta com base na conectividade e nas preferências do usuário etc. Isso vale não apenas para ativos de imagem, mas para praticamente todos os outros pedidos também.
Para clientes que suportam dicas de clientes, pode-se medir 42% de economia de bytes em imagens e 1 MB+ menos bytes para 70º percentil. Na Smashing Magazine, também pudemos medir uma melhora de 19 a 32%. As dicas do cliente são suportadas em navegadores baseados no Chromium, mas ainda estão sendo consideradas no Firefox.
No entanto, se você fornecer a marcação normal de imagens responsivas e a tag
<meta>para Client Hints, um navegador de suporte avaliará a marcação de imagens responsivas e solicitará a fonte de imagem apropriada usando os cabeçalhos HTTP Client Hints. - Usamos imagens responsivas para imagens de fundo?
Certamente devemos! Comimage-set, agora suportado no Safari 14 e na maioria dos navegadores modernos, exceto Firefox, também podemos fornecer imagens de plano de fundo responsivas:background-image: url("fallback.jpg"); background-image: image-set( "photo-small.jpg" 1x, "photo-large.jpg" 2x, "photo-print.jpg" 600dpi);Basicamente, podemos fornecer condicionalmente imagens de fundo de baixa resolução com um descritor de
1xe imagens de alta resolução com um descritor de2xe até mesmo uma imagem com qualidade de impressão com um descritor de600dpi. Mas cuidado: os navegadores não fornecem nenhuma informação especial sobre imagens de fundo para tecnologia assistiva, então o ideal é que essas fotos sejam meramente decorativas. - Usamos WebP?
A compactação de imagem é frequentemente considerada uma vitória rápida, mas ainda é muito subutilizada na prática. É claro que as imagens não bloqueiam a renderização, mas contribuem fortemente para pontuações ruins de LCP e, muitas vezes, são muito pesadas e grandes para o dispositivo em que estão sendo consumidas.Então, no mínimo, poderíamos explorar o uso do formato WebP para nossas imagens. Na verdade, a saga WebP está chegando ao fim no ano passado com a Apple adicionando suporte para WebP no Safari 14. Então, após muitos anos de discussões e debates, a partir de hoje, o WebP é suportado em todos os navegadores modernos. Assim, podemos servir imagens WebP com o elemento
<picture>e um fallback JPEG, se necessário (consulte o trecho de código de Andreas Bovens) ou usando negociação de conteúdo (usando cabeçalhosAccept).O WebP também tem suas desvantagens . Embora os tamanhos de arquivo de imagem WebP sejam comparados aos equivalentes Guetzli e Zopfli, o formato não suporta renderização progressiva como JPEG, e é por isso que os usuários podem ver a imagem finalizada mais rapidamente com um bom e velho JPEG, embora as imagens WebP possam estar ficando mais rápidas pela rede. Com o JPEG, podemos fornecer uma experiência de usuário "decente" com metade ou até um quarto dos dados e carregar o restante mais tarde, em vez de ter uma imagem meio vazia como no caso do WebP.
Sua decisão dependerá do que você busca: com WebP, você reduzirá a carga útil e, com JPEG, melhorará o desempenho percebido. Você pode aprender mais sobre WebP na palestra WebP Rewind de Pascal Massimino, do Google.
Para conversão para WebP, você pode usar o WebP Converter, cwebp ou libwebp. Ire Aderinokun também tem um tutorial muito detalhado sobre como converter imagens para WebP – e Josh Comeau também em seu artigo sobre como adotar formatos de imagem modernos.

Uma palestra completa sobre WebP: WebP Rewind de Pascal Massimino. (Visualização grande) O Sketch oferece suporte nativo ao WebP e as imagens do WebP podem ser exportadas do Photoshop usando um plug-in WebP para o Photoshop. Mas outras opções também estão disponíveis.
Se você estiver usando WordPress ou Joomla, existem extensões para ajudá-lo a implementar facilmente o suporte para WebP, como Optimus e Cache Enabler para WordPress e a própria extensão suportada do Joomla (via Cody Arsenault). Você também pode abstrair o elemento
<picture>com React, styled components ou gatsby-image.Ah – plug sem vergonha! — Jeremy Wagner até publicou um livro sensacional sobre WebP que você pode querer verificar se estiver interessado em tudo sobre WebP.
- Usamos AVIF?
Você já deve ter ouvido a grande notícia: o AVIF chegou. É um novo formato de imagem derivado dos quadros-chave do vídeo AV1. É um formato aberto e livre de royalties que suporta compactação com e sem perdas, animação, canal alfa com perdas e pode lidar com linhas nítidas e cores sólidas (o que era um problema com o JPEG), proporcionando melhores resultados em ambos.Na verdade, em comparação com WebP e JPEG, o AVIF tem um desempenho significativamente melhor , gerando economias de tamanho médio de arquivo de até 50% no mesmo DSSIM ((dis)similaridade entre duas ou mais imagens usando um algoritmo que aproxima a visão humana). De fato, em seu post completo sobre como otimizar o carregamento de imagens, Malte Ubl observa que o AVIF "supera consistentemente o JPEG de uma maneira muito significativa. Isso é diferente do WebP, que nem sempre produz imagens menores que o JPEG e pode realmente ser uma rede perda por falta de suporte para carregamento progressivo."

Podemos usar o AVIF como um aprimoramento progressivo, fornecendo WebP ou JPEG ou PNG para navegadores mais antigos. (Grande visualização). Veja a visualização de texto simples abaixo. Ironicamente, o AVIF pode ter um desempenho ainda melhor do que os SVGs grandes, embora, é claro, não deva ser visto como um substituto para os SVGs. É também um dos primeiros formatos de imagem a oferecer suporte a cores HDR; oferecendo maior brilho, profundidade de bits de cor e gamas de cores. A única desvantagem é que atualmente o AVIF não suporta decodificação de imagem progressiva (ainda?)
O AVIF é atualmente suportado no Chrome, Firefox e Opera, e o suporte no Safari deve chegar em breve (já que a Apple é membro do grupo que criou o AV1).
Qual é a melhor maneira de veicular imagens hoje em dia ? Para ilustrações e imagens vetoriais, o SVG (comprimido) é sem dúvida a melhor escolha. Para fotos, usamos métodos de negociação de conteúdo com o elemento
picture. Se houver suporte para AVIF, enviamos uma imagem AVIF; se não for o caso, voltamos primeiro ao WebP e, se o WebP também não for suportado, alternamos para JPEG ou PNG como fallback (aplicando condições@mediase necessário):<picture> <source type="image/avif"> <source type="image/webp"> <img src="image.jpg" alt="Photo" width="450" height="350"> </picture>Francamente, é mais provável que usemos algumas condições dentro do elemento de
picture:<picture> <source type="image/avif" /> <source type="image/webp" /> <source type="image/jpeg" /> <img src="fallback-image.jpg" alt="Photo" width="450" height="350"> </picture><picture> <source type="image/avif" /> <source type="image/webp" /> <source type="image/jpeg" /> <img src="fallback-image.jpg" alt="Photo" width="450" height="350"> </picture>Você pode ir ainda mais longe trocando imagens animadas por imagens estáticas para clientes que optam por menos movimento com
prefers-reduced-motion:<picture> <source media="(prefers-reduced-motion: reduce)" type="image/avif"></source> <source media="(prefers-reduced-motion: reduce)" type="image/jpeg"></source> <source type="image/avif"></source> <img src="motion.jpg" alt="Animated AVIF"> </picture><picture> <source media="(prefers-reduced-motion: reduce)" type="image/avif"></source> <source media="(prefers-reduced-motion: reduce)" type="image/jpeg"></source> <source type="image/avif"></source> <img src="motion.jpg" alt="Animated AVIF"> </picture>Ao longo dos dois meses, o AVIF ganhou bastante força:
- Podemos testar fallbacks WebP/AVIF no painel Rendering no DevTools.
- Podemos usar Squoosh, AVIF.io e libavif para codificar, decodificar, compactar e converter arquivos AVIF.
- Podemos usar o componente AVIF Preact de Jake Archibald que decodifica um arquivo AVIF em um trabalhador e exibe o resultado em uma tela,
- Para fornecer AVIF apenas para navegadores compatíveis, podemos usar um plug-in PostCSS junto com um script 315B para usar AVIF em suas declarações CSS.
- Podemos entregar progressivamente novos formatos de imagem com CSS e Cloudlare Workers para alterar dinamicamente o documento HTML retornado, inferindo informações do cabeçalho de
accepte, em seguida, adicionar aswebp/avifetc. conforme apropriado. - O AVIF já está disponível no Cloudinary (com limites de uso), o Cloudflare suporta AVIF no redimensionamento de imagem e você pode habilitar o AVIF com cabeçalhos AVIF personalizados no Netlify.
- Quando se trata de animação, o AVIF funciona tão bem quanto o
<img src=mp4>do Safari, superando o GIF e o WebP em geral, mas o MP4 ainda tem um desempenho melhor. - Em geral, para animações, AVC1 (h264) > HVC1 > WebP > AVIF > GIF, assumindo que os navegadores baseados em Chromium sempre suportarão
<img src=mp4>. - Você pode encontrar mais detalhes sobre AVIF na palestra AVIF for Next Generation Image Coding, de Aditya Mavlankar, da Netflix, e The AVIF Image Format, de Kornel Lesinski, da Cloudflare.
- Uma ótima referência para tudo AVIF: o post abrangente de Jake Archibald sobre AVIF chegou.
Então é o futuro AVIF ? Jon Sneyers discorda: o AVIF tem um desempenho 60% pior que o JPEG XL, outro formato gratuito e aberto desenvolvido pelo Google e Cloudinary. Na verdade, o JPEG XL parece ter um desempenho muito melhor em todos os aspectos. No entanto, o JPEG XL ainda está apenas nos estágios finais de padronização, e ainda não funciona em nenhum navegador. (Para não confundir com o JPEG-XR da Microsoft vindo do bom e velho Internet Explorer 9 vezes).
- Os JPEG/PNG/SVGs estão devidamente otimizados?
Quando você estiver trabalhando em uma página de destino na qual é fundamental que uma imagem principal carregue incrivelmente rápido, certifique-se de que os JPEGs sejam progressivos e compactados com mozJPEG (que melhora o tempo de renderização inicial manipulando os níveis de varredura) ou Guetzli, o software de código aberto do Google codificador com foco no desempenho perceptivo e utilizando aprendizados de Zopfli e WebP. A única desvantagem: tempos de processamento lentos (um minuto de CPU por megapixel).Para PNG, podemos usar Pingo, e para SVG, podemos usar SVGO ou SVGOMG. E se você precisar visualizar e copiar ou baixar rapidamente todos os recursos SVG de um site, o svg-grabber também pode fazer isso por você.
Cada artigo de otimização de imagem afirmaria isso, mas sempre vale a pena mencionar manter os ativos vetoriais limpos e firmes. Certifique-se de limpar ativos não utilizados, remover metadados desnecessários e reduzir o número de pontos de caminho no trabalho artístico (e, portanto, no código SVG). ( Obrigado, Jeremias! )
Existem também ferramentas online úteis disponíveis:
- Use o Squoosh para compactar, redimensionar e manipular imagens nos níveis de compactação ideais (com ou sem perdas),
- Use o Guetzli.it para compactar e otimizar imagens JPEG com o Guetzli, que funciona bem para imagens com bordas nítidas e cores sólidas (mas pode ser um pouco mais lento)).
- Use o Gerador de pontos de interrupção de imagem responsiva ou um serviço como Cloudinary ou Imgix para automatizar a otimização de imagem. Além disso, em muitos casos, usar
srcsetesizestrará benefícios significativos. - Para verificar a eficiência de sua marcação responsiva, você pode usar o imaging-heap, uma ferramenta de linha de comando que mede a eficiência entre os tamanhos da janela de visualização e as proporções de pixels do dispositivo.
- Você pode adicionar compactação automática de imagem aos seus fluxos de trabalho do GitHub, para que nenhuma imagem atinja a produção sem compactação. A ação usa mozjpeg e libvips que funcionam com PNGs e JPGs.
- Para otimizar o armazenamento internamente, você pode usar o novo formato Lepton do Dropbox para compactar JPEGs sem perdas em uma média de 22%.
- Use BlurHash se quiser mostrar uma imagem de espaço reservado antecipadamente. BlurHash pega uma imagem e fornece uma string curta (apenas 20 a 30 caracteres!) que representa o espaço reservado para essa imagem. A string é curta o suficiente para que possa ser facilmente adicionada como um campo em um objeto JSON.
BlurHash é uma representação pequena e compacta de um espaço reservado para uma imagem. (Visualização grande) Às vezes, otimizar imagens por si só não resolve. Para melhorar o tempo necessário para iniciar a renderização de uma imagem crítica, carregue lentamente as imagens menos importantes e adie o carregamento de qualquer script após as imagens críticas já terem sido renderizadas. A maneira mais à prova de balas é o carregamento lento híbrido, quando utilizamos o carregamento lento e o carregamento lento nativos, uma biblioteca que detecta quaisquer alterações de visibilidade desencadeadas pela interação do usuário (com IntersectionObserver, que exploraremos mais tarde). Além disso:
- Considere pré-carregar imagens críticas, para que um navegador não as descubra tarde demais. Para imagens de fundo, se você quiser ser ainda mais agressivo do que isso, você pode adicionar a imagem como uma imagem normal com
<img src>e então ocultá-la da tela. - Considere Trocar Imagens com o Atributo Tamanhos especificando diferentes dimensões de exibição de imagem dependendo das consultas de mídia, por exemplo, para manipular
sizespara trocar fontes em um componente de lupa. - Revise as inconsistências de download de imagens para evitar downloads inesperados de imagens de primeiro e segundo plano. Cuidado com as imagens que são carregadas por padrão, mas podem nunca ser exibidas - por exemplo, em carrosséis, acordeões e galerias de imagens.
- Certifique-se de sempre definir
widtheheightnas imagens. Fique atento à propriedadeaspect-rationo CSS e ao atributointrinsicsizeque nos permitirá definir proporções e dimensões para imagens, para que o navegador possa reservar um slot de layout predefinido antecipadamente para evitar saltos de layout durante o carregamento da página.
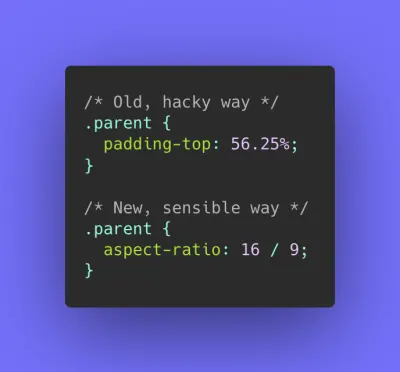
Deve ser apenas uma questão de semanas ou meses agora, com o desembarque da proporção nos navegadores. Já no Safari Technical Preview 118. Atualmente atrás da bandeira no Firefox e Chrome. (Visualização grande) Se você se sentir aventureiro, pode cortar e reorganizar os fluxos HTTP/2 usando Edge workers, basicamente um filtro em tempo real que vive na CDN, para enviar imagens mais rapidamente pela rede. Os trabalhadores de borda usam fluxos de JavaScript que usam partes que você pode controlar (basicamente são JavaScript executados na borda da CDN que podem modificar as respostas de streaming), para que você possa controlar a entrega de imagens.
Com um service worker, é tarde demais, pois você não pode controlar o que está acontecendo, mas funciona com Edge workers. Assim, você pode usá-los em cima de JPEGs estáticos salvos progressivamente para uma página de destino específica.
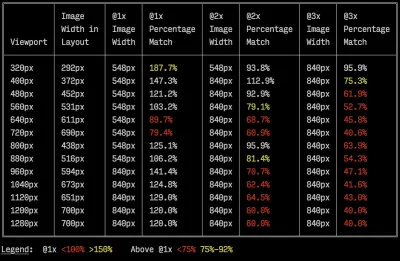
Uma saída de amostra por heap de imagens, uma ferramenta de linha de comando que mede a eficiência entre os tamanhos das portas de visualização e as proporções de pixels do dispositivo. (Fonte da imagem) (Visualização grande) Não esta bom o suficiente? Bem, você também pode melhorar o desempenho percebido para imagens com a técnica de várias imagens de fundo. Lembre-se de que brincar com contraste e desfocar detalhes desnecessários (ou remover cores) também pode reduzir o tamanho do arquivo. Ah, você precisa ampliar uma foto pequena sem perder a qualidade? Considere usar Letsenhance.io.
Essas otimizações até agora cobrem apenas o básico. Addy Osmani publicou um guia muito detalhado sobre Essential Image Optimization, que aprofunda os detalhes de compactação de imagem e gerenciamento de cores. Por exemplo, você pode desfocar partes desnecessárias da imagem (aplicando um filtro de desfoque gaussiano a elas) para reduzir o tamanho do arquivo e, eventualmente, pode até começar a remover cores ou transformar a imagem em preto e branco para reduzir ainda mais o tamanho . Para imagens de fundo, exportar fotos do Photoshop com qualidade de 0 a 10% também pode ser absolutamente aceitável.
Na Smashing Magazine, usamos o postfix
-optpara nomes de imagens — por exemplo,brotli-compression-opt.png; sempre que uma imagem contém esse postfix, todos na equipe sabem que a imagem já foi otimizada.Ah, e não use JPEG-XR na web - "o processamento de decodificação JPEG-XRs no lado do software na CPU anula e até supera o impacto potencialmente positivo da economia de tamanho de byte, especialmente no contexto de SPAs" (não para misturar com o JPEG XL da Cloudinary/Google).

- Os vídeos estão devidamente otimizados?
Cobrimos imagens até agora, mas evitamos uma conversa sobre bons e velhos GIFs. Apesar do nosso amor por GIFs, é realmente a hora de abandoná-los para sempre (pelo menos em nossos sites e aplicativos). Em vez de carregar GIFs animados pesados que afetam tanto o desempenho de renderização quanto a largura de banda, é uma boa ideia alternar para WebP animado (com GIF sendo um substituto) ou substituí-los por vídeos HTML5 em loop.Ao contrário das imagens, os navegadores não pré-carregam o conteúdo
<video>, mas os vídeos HTML5 tendem a ser muito mais leves e menores que os GIFs. Não é uma opção? Bem, pelo menos podemos adicionar compressão com perdas a GIFs com Lossy GIF, gifsicle ou giflossy.Testes de Colin Bendell mostram que vídeos inline dentro de tags
imgno Safari Technology Preview são exibidos pelo menos 20 vezes mais rápido e decodificam 7 vezes mais rápido que o equivalente GIF, além de serem uma fração do tamanho do arquivo. No entanto, não é compatível com outros navegadores.Na terra das boas notícias, os formatos de vídeo vêm avançando massivamente ao longo dos anos. Por muito tempo, esperávamos que o WebM se tornasse o formato para governar todos eles, e o WebP (que é basicamente uma imagem estática dentro do contêiner de vídeo WebM) se tornaria um substituto para formatos de imagem datados. De fato, o Safari agora oferece suporte ao WebP, mas apesar do WebP e do WebM ganharem suporte nos dias de hoje, o avanço realmente não aconteceu.
Ainda assim, poderíamos usar o WebM para a maioria dos navegadores modernos:
<!-- By Houssein Djirdeh. https://web.dev/replace-gifs-with-videos/ --> <!-- A common scenartio: MP4 with a WEBM fallback. --> <video autoplay loop muted playsinline> <source src="my-animation.webm" type="video/webm"> <source src="my-animation.mp4" type="video/mp4"> </video>Mas talvez pudéssemos revisitá-lo completamente. Em 2018, a Alliance of Open Media lançou um novo formato de vídeo promissor chamado AV1 . O AV1 tem compactação semelhante ao codec H.265 (a evolução do H.264), mas ao contrário deste último, o AV1 é gratuito. O preço da licença H.265 levou os fornecedores de navegadores a adotar um AV1 com desempenho comparável: o AV1 (assim como o H.265) compacta duas vezes melhor que o WebM .

O AV1 tem boas chances de se tornar o padrão definitivo para vídeo na web. (Crédito da imagem: Wikimedia.org) (Visualização grande) Na verdade, a Apple atualmente usa o formato HEIF e HEVC (H.265), e todas as fotos e vídeos no iOS mais recente são salvos nesses formatos, não em JPEG. Embora o HEIF e o HEVC (H.265) não estejam devidamente expostos à web (ainda?), o AV1 está – e está ganhando suporte para navegadores. Portanto, adicionar a fonte
AV1em sua tag<video>é razoável, pois todos os fornecedores de navegadores parecem estar de acordo.Por enquanto, a codificação mais usada e suportada é H.264, servida por arquivos MP4, portanto, antes de servir o arquivo, certifique-se de que seus MP4s sejam processados com uma codificação multipass, desfocada com o efeito frei0r iirblur (se aplicável) e Os metadados do moov atom são movidos para o cabeçalho do arquivo, enquanto seu servidor aceita o serviço de byte. Boris Schapira fornece instruções exatas para o FFmpeg otimizar os vídeos ao máximo. É claro que fornecer o formato WebM como alternativa também ajudaria.
Precisa começar a renderizar vídeos mais rapidamente, mas os arquivos de vídeo ainda são muito grandes ? Por exemplo, sempre que você tem um grande vídeo de fundo em uma página de destino? Uma técnica comum a ser usada é mostrar primeiro o primeiro quadro como uma imagem estática ou exibir um segmento de loop curto e altamente otimizado que pode ser interpretado como parte do vídeo e, então, sempre que o vídeo estiver armazenado em buffer o suficiente, comece a reproduzir o vídeo real. Doug Sillars escreveu um guia detalhado para o desempenho do vídeo em segundo plano que pode ser útil nesse caso. ( Obrigado, Guy Podjarny! ).
Para o cenário acima, você pode fornecer imagens de pôster responsivas . Por padrão, os elementos de
videopermitem apenas uma imagem como pôster, o que não é necessariamente o ideal. Podemos usar o Responsive Video Poster, uma biblioteca JavaScript que permite usar diferentes imagens de pôster para diferentes telas, além de adicionar uma sobreposição de transição e controle total de estilo dos espaços reservados de vídeo.A pesquisa mostra que a qualidade do fluxo de vídeo afeta o comportamento do espectador. Na verdade, os espectadores começam a abandonar o vídeo se o atraso na inicialização exceder cerca de 2 segundos. Além desse ponto, um aumento de 1 segundo no atraso resulta em um aumento de aproximadamente 5,8% na taxa de abandono. Portanto, não é surpreendente que o tempo médio de início do vídeo seja de 12,8 segundos, com 40% dos vídeos com pelo menos 1 travamento e 20% pelo menos 2 segundos de reprodução de vídeo travada. Na verdade, as paralisações de vídeo são inevitáveis no 3G, pois os vídeos são reproduzidos mais rapidamente do que a rede pode fornecer conteúdo.
Então, qual é a solução? Normalmente, os dispositivos de tela pequena não conseguem lidar com os 720p e 1080p que estamos atendendo na área de trabalho. De acordo com Doug Sillars, podemos criar versões menores de nossos vídeos e usar Javascript para detectar a origem de telas menores para garantir uma reprodução rápida e suave nesses dispositivos. Alternativamente, podemos usar streaming de vídeo. Os fluxos de vídeo HLS fornecerão um vídeo de tamanho apropriado para o dispositivo - abstraindo a necessidade de criar vídeos diferentes para telas diferentes. Ele também negociará a velocidade da rede e adaptará a taxa de bits do vídeo à velocidade da rede que você está usando.
Para evitar o desperdício de largura de banda, só poderíamos adicionar a fonte de vídeo para dispositivos que realmente reproduzam bem o vídeo. Como alternativa, podemos remover completamente o atributo de
autoplayda tag devideoe usar JavaScript para inserir aautoplayem telas maiores. Além disso, precisamos adicionarpreload="none"novideopara informar ao navegador para não baixar nenhum dos arquivos de vídeo até que ele realmente precise do arquivo:<!-- Based on Doug Sillars's post. https://dougsillars.com/2020/01/06/hiding-videos-on-the-mbile-web/ --> <video preload="none" playsinline muted loop width="1920" height="1080" poster="poster.jpg"> <source src="video.webm" type="video/webm"> <source src="video.mp4" type="video/mp4"> </video>Em seguida, podemos segmentar especificamente navegadores que realmente suportam AV1:
<!-- Based on Doug Sillars's post. https://dougsillars.com/2020/01/06/hiding-videos-on-the-mbile-web/ --> <video preload="none" playsinline muted loop width="1920" height="1080" poster="poster.jpg"> <source src="video.av1.mp4" type="video/mp4; codecs=av01.0.05M.08"> <source src="video.hevc.mp4" type="video/mp4; codecs=hevc"> <source src="video.webm" type="video/webm"> <source src="video.mp4" type="video/mp4"> </video>Em seguida, poderíamos adicionar novamente a
autoplayem um determinado limite (por exemplo, 1000px):/* By Doug Sillars. https://dougsillars.com/2020/01/06/hiding-videos-on-the-mbile-web/ */ <script> window.onload = addAutoplay(); var videoLocation = document.getElementById("hero-video"); function addAutoplay() { if(window.innerWidth > 1000){ videoLocation.setAttribute("autoplay",""); }; } </script>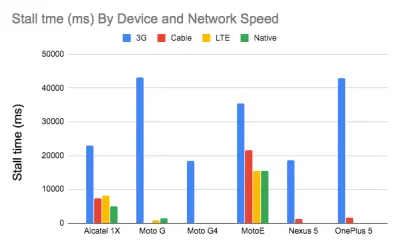
Número de paradas por dispositivo e velocidade da rede. Dispositivos mais rápidos em redes mais rápidas praticamente não têm paradas. De acordo com a pesquisa de Doug Sillars. (Visualização grande) O desempenho de reprodução de vídeo é uma história por si só, e se você quiser mergulhar em detalhes, dê uma olhada em outra série de Doug Sillars sobre o estado atual das práticas recomendadas de entrega de vídeo e vídeo que inclui detalhes sobre métricas de entrega de vídeo , pré-carregamento de vídeo, compressão e streaming. Por fim, você pode verificar o quão lento ou rápido será o seu streaming de vídeo com Stream or Not.
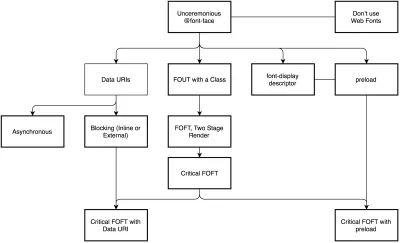
- A entrega de fontes da web é otimizada?
A primeira pergunta que vale a pena fazer é se podemos usar as fontes do sistema de interface do usuário em primeiro lugar - só precisamos nos certificar de que elas aparecem corretamente em várias plataformas. Se não for o caso, as chances são altas de que as fontes da Web que estamos servindo incluem glifos e recursos extras e pesos que não estão sendo usados. Podemos pedir à nossa fundição de tipos para subconjunto de fontes da Web ou, se estivermos usando fontes de código aberto, subconjunto-los por conta própria com Glyphhanger ou Fontsquirrel. Podemos até automatizar todo o nosso fluxo de trabalho com a subfonte de Peter Muller, uma ferramenta de linha de comando que analisa estaticamente sua página para gerar os subconjuntos de fontes da Web mais ideais e depois injetá-los em nossas páginas.O suporte ao WOFF2 é ótimo e podemos usar o WOFF como substituto para navegadores que não o suportam – ou talvez navegadores legados possam ser servidos com fontes do sistema. Existem muitas, muitas, muitas opções para carregamento de fontes da Web, e podemos escolher uma das estratégias do "Guia Completo para Estratégias de Carregamento de Fontes" de Zach Leatherman (trechos de código também disponíveis como receitas de carregamento de fontes da Web).
Provavelmente, as melhores opções a serem consideradas hoje são o FOFT crítico com
preload-carregamento e o método "The Compromise". Ambos usam uma renderização de dois estágios para fornecer fontes da Web em etapas - primeiro um pequeno supersubconjunto necessário para renderizar a página com rapidez e precisão com a fonte da Web e, em seguida, carregar o restante da família assíncrona. A diferença é que a técnica "The Compromise" carrega o polyfill de forma assíncrona apenas se os eventos de carregamento de fonte não forem suportados, portanto, você não precisa carregar o polyfill por padrão. Precisa de uma vitória rápida? Zach Leatherman tem um tutorial rápido de 23 minutos e um estudo de caso para colocar suas fontes em ordem.Em geral, pode ser uma boa ideia usar a dica de recurso de
preload-carregamento para pré-carregar fontes, mas em sua marcação inclua as dicas após o link para CSS e JavaScript críticos. Compreload, há um quebra-cabeça de prioridades, então considere injetar elementosrel="preload"no DOM logo antes dos scripts de bloqueio externos. De acordo com Andy Davies, "os recursos injetados usando um script ficam ocultos do navegador até que o script seja executado, e podemos usar esse comportamento para atrasar quando o navegador descobrir a dica depreload-carregamento". Caso contrário, o carregamento da fonte custará no primeiro tempo de renderização.
Quando tudo é crítico, nada é crítico. pré-carregue apenas uma ou no máximo duas fontes de cada família. (Crédito da imagem: Zach Leatherman – slide 93) (Visualização grande) É uma boa ideia ser seletivo e escolher os arquivos mais importantes, por exemplo, aqueles que são críticos para renderização ou que ajudariam a evitar refluxos de texto visíveis e perturbadores. Em geral, Zach aconselha pré-carregar uma ou duas fontes de cada família - também faz sentido atrasar o carregamento de algumas fontes se elas forem menos críticas.
Tornou-se bastante comum usar o valor
local()(que se refere a uma fonte local pelo nome) ao definir umafont-familyde fontes na regra@font-face:/* Warning! Not a good idea! */ @font-face { font-family: Open Sans; src: local('Open Sans Regular'), local('OpenSans-Regular'), url('opensans.woff2') format ('woff2'), url('opensans.woff') format('woff'); }A ideia é razoável: algumas fontes populares de código aberto, como Open Sans, vêm pré-instaladas com alguns drivers ou aplicativos, portanto, se a fonte estiver disponível localmente, o navegador não precisará baixar a fonte da Web e poderá exibir a fonte local fonte imediatamente. Como Bram Stein observou, "embora uma fonte local corresponda ao nome de uma fonte da Web, provavelmente não é a mesma fonte . Muitas fontes da Web diferem de sua versão "desktop". O texto pode ser renderizado de forma diferente, alguns caracteres podem cair de volta para outras fontes, os recursos OpenType podem estar totalmente ausentes ou a altura da linha pode ser diferente."
Além disso, à medida que os tipos de letra evoluem com o tempo, a versão instalada localmente pode ser muito diferente da fonte da Web, com os caracteres parecendo muito diferentes. Então, de acordo com Bram, é melhor nunca misturar fontes instaladas localmente e fontes da web nas regras
@font-face. O Google Fonts seguiu o exemplo desabilitandolocal()nos resultados de CSS para todos os usuários, exceto as solicitações do Android para Roboto.Ninguém gosta de esperar que o conteúdo seja exibido. Com o descritor CSS
font-display, podemos controlar o comportamento de carregamento da fonte e permitir que o conteúdo seja lido imediatamente (comfont-display: optional) ou quase imediatamente (com um tempo limite de 3s, desde que a fonte seja baixada com sucesso — comfont-display: swap). (Bem, é um pouco mais complicado do que isso.)No entanto, se você quiser minimizar o impacto dos refluxos de texto, podemos usar a API de carregamento de fontes (suportada em todos os navegadores modernos). Especificamente, isso significa que para cada fonte, criamos um objeto
FontFace, depois tentamos buscá-los todos e só então os aplicamos à página. Dessa forma, agrupamos todas as repinturas carregando todas as fontes de forma assíncrona e, em seguida, alternamos das fontes de fallback para a fonte da Web exatamente uma vez. Dê uma olhada na explicação de Zach, a partir de 32:15, e o trecho de código):/* Load two web fonts using JavaScript */ /* Zach Leatherman: https://noti.st/zachleat/KNaZEg/the-five-whys-of-web-font-loading-performance#sWkN4u4 */ // Remove existing @font-face blocks // Create two let font = new FontFace("Noto Serif", /* ... */); let fontBold = new FontFace("Noto Serif, /* ... */); // Load two fonts let fonts = await Promise.all([ font.load(), fontBold.load() ]) // Group repaints and render both fonts at the same time! fonts.forEach(font => documents.fonts.add(font));/* Load two web fonts using JavaScript */ /* Zach Leatherman: https://noti.st/zachleat/KNaZEg/the-five-whys-of-web-font-loading-performance#sWkN4u4 */ // Remove existing @font-face blocks // Create two let font = new FontFace("Noto Serif", /* ... */); let fontBold = new FontFace("Noto Serif, /* ... */); // Load two fonts let fonts = await Promise.all([ font.load(), fontBold.load() ]) // Group repaints and render both fonts at the same time! fonts.forEach(font => documents.fonts.add(font));Para iniciar uma busca muito precoce das fontes com a API de carregamento de fontes em uso, Adrian Bece sugere adicionar um espaço ininterrupto
nbsp;na parte superior dobodye esconda-o visualmente comaria-visibility: hiddene uma classe.hidden:<body class="no-js"> <!-- ... Website content ... --> <div aria-visibility="hidden" class="hidden"> <!-- There is a non-breaking space here --> </div> <script> document.getElementsByTagName("body")[0].classList.remove("no-js"); </script> </body><body class="no-js"> <!-- ... Website content ... --> <div aria-visibility="hidden" class="hidden"> <!-- There is a non-breaking space here --> </div> <script> document.getElementsByTagName("body")[0].classList.remove("no-js"); </script> </body>Isso vai junto com CSS que tem diferentes famílias de fontes declaradas para diferentes estados de carregamento, com a mudança acionada pela API de carregamento de fontes assim que as fontes forem carregadas com sucesso:
body:not(.wf-merriweather--loaded):not(.no-js) { font-family: [fallback-system-font]; /* Fallback font styles */ } .wf-merriweather--loaded, .no-js { font-family: "[web-font-name]"; /* Webfont styles */ } /* Accessible hiding */ .hidden { position: absolute; overflow: hidden; clip: rect(0 0 0 0); height: 1px; width: 1px; margin: -1px; padding: 0; border: 0; }body:not(.wf-merriweather--loaded):not(.no-js) { font-family: [fallback-system-font]; /* Fallback font styles */ } .wf-merriweather--loaded, .no-js { font-family: "[web-font-name]"; /* Webfont styles */ } /* Accessible hiding */ .hidden { position: absolute; overflow: hidden; clip: rect(0 0 0 0); height: 1px; width: 1px; margin: -1px; padding: 0; border: 0; }Se você já se perguntou por que, apesar de todas as suas otimizações, o Lighthouse ainda sugere eliminar recursos de bloqueio de renderização (fontes), no mesmo artigo Adrian Bece fornece algumas técnicas para deixar o Lighthouse feliz, junto com um Gatsby Omni Font Loader, uma fonte assíncrona de alto desempenho carregamento e plugin de manipulação de Flash Of Unstyled Text (FOUT) para Gatsby.

Agora, muitos de nós podem estar usando um CDN ou um host de terceiros para carregar fontes da web. Em geral, é sempre melhor auto-hospedar todos os seus ativos estáticos, se puder, então considere usar o google-webfonts-helper, uma maneira fácil de auto-hospedar o Google Fonts. E se não for possível, talvez você possa fazer proxy dos arquivos do Google Font por meio da origem da página.
Vale a pena notar que o Google está fazendo um pouco de trabalho fora da caixa, então um servidor pode precisar de alguns ajustes para evitar atrasos ( obrigado, Barry! )
Isso é muito importante, especialmente porque desde o Chrome v86 (lançado em outubro de 2020), recursos entre sites, como fontes, não podem mais ser compartilhados no mesmo CDN - devido ao cache do navegador particionado. Esse comportamento foi um padrão no Safari por anos.
Mas se não for possível, existe uma maneira de chegar ao Google Fonts mais rápido possível com o trecho de Harry Roberts:
<!-- By Harry Roberts. https://csswizardry.com/2020/05/the-fastest-google-fonts/ - 1. Preemptively warm up the fonts' origin. - 2. Initiate a high-priority, asynchronous fetch for the CSS file. Works in - most modern browsers. - 3. Initiate a low-priority, asynchronous fetch that gets applied to the page - only after it's arrived. Works in all browsers with JavaScript enabled. - 4. In the unlikely event that a visitor has intentionally disabled - JavaScript, fall back to the original method. The good news is that, - although this is a render-blocking request, it can still make use of the - preconnect which makes it marginally faster than the default. --> <!-- [1] --> <link rel="preconnect" href="https://fonts.gstatic.com" crossorigin /> <!-- [2] --> <link rel="preload" as="style" href="$CSS&display=swap" /> <!-- [3] --> <link rel="stylesheet" href="$CSS&display=swap" media="print" onload="this.media='all'" /> <!-- [4] --> <noscript> <link rel="stylesheet" href="$CSS&display=swap" /> </noscript>A estratégia de Harry é aquecer preventivamente a origem das fontes primeiro. Em seguida, iniciamos uma busca assíncrona de alta prioridade para o arquivo CSS. Depois, iniciamos uma busca assíncrona de baixa prioridade que é aplicada à página somente depois que ela chega (com um truque de folha de estilo de impressão). Por fim, se o JavaScript não for suportado, voltamos ao método original.
Ah, falando do Google Fonts: você pode reduzir até 90% do tamanho das solicitações do Google Fonts declarando apenas os caracteres necessários com
&text. Além disso, o suporte para exibição de fonte também foi adicionado recentemente ao Google Fonts, para que possamos usá-lo imediatamente.Uma palavra rápida de cautela embora. Se você usar
font-display: optional, pode não ser ideal usar também opreload-carregamento, pois ele acionará essa solicitação de fonte da Web antecipadamente (causando congestionamento de rede se você tiver outros recursos de caminho crítico que precisam ser buscados). Use a pré-preconnectpara solicitações de fontes cruzadas mais rápidas, mas tenha cuidado com opreload-carregamento, pois o pré-carregamento de fontes de uma origem diferente incorrerá em contenção de rede. Todas essas técnicas são abordadas nas receitas de carregamento de fontes da Web de Zach.Por outro lado, pode ser uma boa ideia desativar fontes da Web (ou pelo menos renderização de segundo estágio) se o usuário tiver ativado Reduzir movimento nas preferências de acessibilidade ou tiver optado pelo Modo de economia
Save-Data) , ou quando o usuário tem uma conectividade lenta (via API de informações de rede).Também podemos usar a consulta de mídia CSS
prefers-reduced-datapara não definir declarações de fonte se o usuário tiver optado pelo modo de economia de dados (há outros casos de uso também). A consulta de mídia basicamente exporia se o cabeçalho de solicitaçãoSave-Datada extensão HTTP Client Hint estiver ativado/desativado para permitir o uso com CSS. Atualmente suportado apenas no Chrome e Edge por trás de um sinalizador.Métricas? Para medir o desempenho de carregamento da fonte da web, considere a métrica All Text Visible (o momento em que todas as fontes foram carregadas e todo o conteúdo é exibido em fontes da web), Time to Real Italics, bem como Web Font Reflow Count após a primeira renderização. Obviamente, quanto menores forem as duas métricas, melhor será o desempenho.
E quanto a fontes variáveis , você pode perguntar? É importante observar que fontes variáveis podem exigir uma consideração significativa de desempenho. Eles nos dão um espaço de design muito mais amplo para escolhas tipográficas, mas tem o custo de uma única solicitação serial em oposição a várias solicitações de arquivos individuais.
Embora as fontes variáveis reduzam drasticamente o tamanho geral do arquivo combinado dos arquivos de fonte, essa solicitação única pode ser lenta, bloqueando a renderização de todo o conteúdo de uma página. Portanto, subconfigurar e dividir a fonte em conjuntos de caracteres ainda é importante. No lado bom, porém, com uma fonte variável no lugar, obteremos exatamente um refluxo por padrão, portanto, nenhum JavaScript será necessário para agrupar repinturas.
Agora, o que faria uma estratégia de carregamento de fonte da web à prova de balas ? Subconjunto de fontes e prepare-os para a renderização em 2 estágios, declare-os com um descritor
font-display, use a API de carregamento de fontes para agrupar repinturas e armazenar fontes no cache de um service worker persistente. Na primeira visita, injete o pré-carregamento de scripts antes do bloqueio de scripts externos. Você pode recorrer ao Font Face Observer de Bram Stein, se necessário. E se você estiver interessado em medir o desempenho do carregamento de fontes, Andreas Marschke explora o rastreamento de desempenho com a API Font e a API UserTiming.Por fim, não se esqueça de incluir
unicode-rangepara dividir uma fonte grande em fontes menores específicas do idioma e use o combinador de estilo de fonte de Monica Dinculescu para minimizar uma mudança brusca no layout, devido a discrepâncias de tamanho entre o fallback e o fontes da web.Como alternativa, para emular uma fonte da Web para uma fonte de fallback, podemos usar os descritores @font-face para substituir as métricas de fonte (demo, ativado no Chrome 87). (Observe que os ajustes são complicados com pilhas de fontes complicadas.)
O futuro parece brilhante? Com o enriquecimento progressivo da fonte, eventualmente poderemos "baixar apenas a parte necessária da fonte em qualquer página e, para solicitações subsequentes dessa fonte, 'corrigir' dinamicamente o download original com conjuntos adicionais de glifos conforme necessário em páginas sucessivas pontos de vista", como explica Jason Pamental. A demonstração de transferência incremental já está disponível e está em andamento.
Otimizações de compilação
- Definimos nossas prioridades?
É uma boa idéia saber com o que você está lidando primeiro. Faça um inventário de todos os seus ativos (JavaScript, imagens, fontes, scripts de terceiros e módulos "caros" na página, como carrosséis, infográficos complexos e conteúdo multimídia) e divida-os em grupos.Monte uma planilha . Defina a experiência básica básica para navegadores legados (ou seja, conteúdo central totalmente acessível), a experiência aprimorada para navegadores capazes (ou seja, uma experiência completa e enriquecida) e os extras (ativos que não são absolutamente necessários e podem ser carregados lentamente, como fontes da web, estilos desnecessários, scripts de carrossel, players de vídeo, widgets de mídia social, imagens grandes). Anos atrás, publicamos um artigo sobre "Melhorando o desempenho da revista Smashing", que descreve essa abordagem em detalhes.
Ao otimizar o desempenho, precisamos refletir nossas prioridades. Carregue a experiência principal imediatamente, depois os aprimoramentos e os extras .
- Você usa módulos JavaScript nativos em produção?
Lembre-se da boa e velha técnica de cortar a mostarda para enviar a experiência principal para navegadores legados e uma experiência aprimorada para navegadores modernos? Uma variante atualizada da técnica poderia usar ES2017+<script type="module">, também conhecido como padrão de módulo/nomodule (também introduzido por Jeremy Wagner como serviço diferencial ).A ideia é compilar e servir dois bundles JavaScript separados : o build “regular”, aquele com Babel-transforms e polyfills e servi-los apenas para navegadores legados que realmente precisam deles, e outro bundle (mesma funcionalidade) que não tem transformações ou polyfills.
Como resultado, ajudamos a reduzir o bloqueio do encadeamento principal, reduzindo a quantidade de scripts que o navegador precisa processar. Jeremy Wagner publicou um artigo abrangente sobre o serviço diferencial e como configurá-lo em seu pipeline de compilação, desde a configuração do Babel, até quais ajustes você precisará fazer no Webpack, bem como os benefícios de fazer todo esse trabalho.
Os scripts do módulo JavaScript nativo são adiados por padrão, portanto, enquanto a análise de HTML está acontecendo, o navegador baixará o módulo principal.

Os módulos JavaScript nativos são adiados por padrão. Praticamente tudo sobre módulos JavaScript nativos. (Visualização grande) Uma nota de aviso, porém: o padrão de módulo/nomódulo pode sair pela culatra em alguns clientes, então você pode querer considerar uma solução alternativa: o padrão de serviço diferencial menos arriscado de Jeremy que, no entanto, evita o scanner de pré-carregamento, o que pode afetar o desempenho de maneiras que talvez não antecipar. ( obrigado, Jeremias! )
Na verdade, o Rollup oferece suporte a módulos como um formato de saída, para que possamos agrupar código e implantar módulos em produção. Parcel tem suporte a módulo no Parcel 2. Para Webpack, module-nomodule-plugin automatiza a geração de scripts de módulo/nomodule.
Observação : vale a pena afirmar que a detecção de recursos por si só não é suficiente para tomar uma decisão informada sobre a carga útil a ser enviada para esse navegador. Por si só, não podemos deduzir a capacidade do dispositivo da versão do navegador. Por exemplo, telefones Android baratos em países em desenvolvimento executam principalmente o Chrome e cortarão a mostarda, apesar de sua memória limitada e recursos de CPU.
Eventualmente, usando o cabeçalho Device Memory Client Hints, poderemos direcionar dispositivos de baixo custo de forma mais confiável. No momento da escrita, o cabeçalho é suportado apenas em Blink (vale para dicas de clientes em geral). Como a memória do dispositivo também possui uma API JavaScript que está disponível no Chrome, uma opção pode ser detectar recursos com base na API e retornar ao padrão de módulo/nomódulo se não for suportado ( obrigado, Yoav! ).
- Você está usando trepidação de árvores, elevação de escopo e divisão de código?
Tree-shake é uma maneira de limpar seu processo de compilação incluindo apenas o código que é realmente usado na produção e eliminando importações não utilizadas no Webpack. Com Webpack e Rollup, também temos escopo de elevação que permite que ambas as ferramentas detectem onde o encadeamento deimportpode ser nivelado e convertido em uma função embutida sem comprometer o código. Com o Webpack, também podemos usar JSON Tree Shaking.A divisão de código é outro recurso do Webpack que divide sua base de código em "pedaços" que são carregados sob demanda. Nem todo o JavaScript precisa ser baixado, analisado e compilado imediatamente. Depois de definir os pontos de divisão em seu código, o Webpack pode cuidar das dependências e dos arquivos de saída. Ele permite que você mantenha o download inicial pequeno e solicite o código sob demanda quando solicitado pelo aplicativo. Alexander Kondrov tem uma introdução fantástica à divisão de código com Webpack e React.
Considere o uso de preload-webpack-plugin que leva as rotas de divisão de código e, em seguida, solicita ao navegador para pré-carregá-las usando
<link rel="preload">ou<link rel="prefetch">. As diretivas inline do Webpack também dão algum controle sobre opreload-carregamento/prefetch. (Cuidado com os problemas de priorização.)Onde definir pontos de divisão? Ao rastrear quais partes de CSS/JavaScript são usadas e quais não são usadas. Umar Hansa explica como você pode usar o Code Coverage do Devtools para alcançá-lo.
Ao lidar com aplicativos de página única, precisamos de algum tempo para inicializar o aplicativo antes de podermos renderizar a página. Sua configuração exigirá sua solução personalizada, mas você pode ficar atento aos módulos e técnicas para acelerar o tempo de renderização inicial. Por exemplo, veja como depurar o desempenho do React e eliminar problemas comuns de desempenho do React e veja como melhorar o desempenho no Angular. Em geral, a maioria dos problemas de desempenho vem do momento inicial para inicializar o aplicativo.
Então, qual é a melhor maneira de dividir o código de forma agressiva, mas não muito agressiva? De acordo com Phil Walton, "além da divisão de código por meio de importações dinâmicas, [poderíamos] também usar a divisão de código no nível do pacote , onde cada módulo de nó importado é colocado em um pedaço com base no nome do pacote". Phil fornece um tutorial sobre como construí-lo também.
- Podemos melhorar a saída do Webpack?
Como o Webpack é frequentemente considerado misterioso, existem muitos plugins do Webpack que podem ser úteis para reduzir ainda mais a saída do Webpack. Abaixo estão alguns dos mais obscuros que podem precisar de um pouco mais de atenção.Um dos interessantes vem do tópico de Ivan Akulov. Imagine que você tem uma função que chama uma vez, armazena seu resultado em uma variável e não usa essa variável. A agitação da árvore removerá a variável, mas não a função, porque pode ser usada de outra forma. No entanto, se a função não for usada em nenhum lugar, convém removê-la. Para fazer isso, anexe a chamada da função com
/*#__PURE__*/que é suportado pelo Uglify e Terser — pronto!
Para remover tal função quando seu resultado não for usado, anexe a chamada de função com /*#__PURE__*/. Via Ivan Akulov.(Grande visualização)Aqui estão algumas das outras ferramentas que Ivan recomenda:
- purgecss-webpack-plugin remove classes não utilizadas, especialmente quando você está usando Bootstrap ou Tailwind.
- Habilite
optimization.splitChunks: 'all'com split-chunks-plugin. Isso faria com que o webpack dividisse automaticamente seus pacotes de entrada para um melhor armazenamento em cache. - Defina
optimization.runtimeChunk: true. Isso moveria o tempo de execução do webpack para uma parte separada — e também melhoraria o armazenamento em cache. - google-fonts-webpack-plugin baixa arquivos de fonte, para que você possa servi-los de seu servidor.
- workbox-webpack-plugin permite que você gere um service worker com uma configuração de pré-cache para todos os seus ativos de webpack. Além disso, verifique Service Worker Packages, um guia abrangente de módulos que podem ser aplicados imediatamente. Ou use preload-webpack-plugin para gerar
preload-carregamento/prefetch-busca para todos os fragmentos de JavaScript. - speed-measure-webpack-plugin mede a velocidade de compilação do seu webpack, fornecendo informações sobre quais etapas do processo de compilação são mais demoradas.
- duplicado-pacote-verificador-webpack-plugin avisa quando seu pacote contém várias versões do mesmo pacote.
- Use o isolamento de escopo e reduza os nomes das classes CSS dinamicamente no momento da compilação.
- Você pode descarregar JavaScript em um Web Worker?
Para reduzir o impacto negativo no Tempo para Interação, pode ser uma boa ideia procurar descarregar JavaScript pesado em um Web Worker.À medida que a base de código continua crescendo, os gargalos de desempenho da interface do usuário aparecerão, diminuindo a experiência do usuário. Isso ocorre porque as operações do DOM estão sendo executadas junto com seu JavaScript no encadeamento principal. Com os web workers, podemos mover essas operações caras para um processo em segundo plano que está sendo executado em um thread diferente. Casos de uso típicos para web workers são a pré-busca de dados e Progressive Web Apps para carregar e armazenar alguns dados com antecedência para que você possa usá-los mais tarde, quando necessário. E você pode usar o Comlink para agilizar a comunicação entre a página principal e o trabalhador. Ainda há muito trabalho a fazer, mas estamos chegando lá.
Existem alguns estudos de caso interessantes sobre web workers que mostram diferentes abordagens para mover a estrutura e a lógica do aplicativo para web workers. A conclusão: em geral, ainda existem alguns desafios, mas já existem alguns bons casos de uso ( obrigado, Ivan Akulov! ).
A partir do Chrome 80, foi lançado um novo modo para trabalhadores da Web com benefícios de desempenho de módulos JavaScript, chamados de trabalhadores de módulo. Podemos alterar o carregamento e a execução do script para corresponder ao
script type="module", além disso, também podemos usar importações dinâmicas para código de carregamento lento sem bloquear a execução do trabalhador.Como começar? Aqui estão alguns recursos que valem a pena analisar:
- A Surma publicou um excelente guia sobre como executar JavaScript no thread principal do navegador e também Quando você deve usar Web Workers?
- Além disso, confira a palestra de Surma sobre a arquitetura de thread principal.
- A Quest to Guaranteeness por Shubhie Panicker e Jason Miller fornecem uma visão detalhada de como usar os web workers e quando evitá-los.
- Saindo do caminho dos usuários: menos problemas com Web Workers destaca padrões úteis para trabalhar com Web Workers, maneiras eficazes de se comunicar entre workers, lidar com processamento de dados complexos fora do thread principal e testá-los e depurá-los.
- Workerize permite mover um módulo para um Web Worker, refletindo automaticamente as funções exportadas como proxies assíncronos.
- Se você estiver usando o Webpack, poderá usar o workerize-loader. Alternativamente, você também pode usar o plugin do trabalhador.

Use web workers quando o código bloquear por muito tempo, mas evite-os quando você confiar no DOM, lidar com a resposta de entrada e precisar de um atraso mínimo. (via Addy Osmani) (Visualização grande) Observe que os Web Workers não têm acesso ao DOM porque o DOM não é "thread-safe" e o código que eles executam precisa estar contido em um arquivo separado.
- Você pode descarregar "caminhos quentes" para o WebAssembly?
Poderíamos descarregar tarefas computacionalmente pesadas para o WebAssembly ( WASM ), um formato de instrução binária, projetado como um destino portátil para compilação de linguagens de alto nível como C/C++/Rust. Seu suporte ao navegador é notável e recentemente se tornou viável, pois as chamadas de função entre JavaScript e WASM estão ficando mais rápidas. Além disso, ainda é compatível com a nuvem de borda da Fastly.É claro que o WebAssembly não deve substituir o JavaScript, mas pode complementá-lo nos casos em que você percebe problemas de CPU. Para a maioria dos aplicativos da Web, o JavaScript é mais adequado e o WebAssembly é melhor usado para aplicativos da Web computacionalmente intensivos , como jogos.
Se você quiser saber mais sobre o WebAssembly:
- Lin Clark escreveu uma série completa para WebAssembly e Milica Mihajlija fornece uma visão geral de como executar código nativo no navegador, por que você pode querer fazer isso e o que tudo isso significa para JavaScript e o futuro do desenvolvimento web.
- Como usamos o WebAssembly para acelerar nosso aplicativo da Web em 20 vezes (estudo de caso) destaca um estudo de caso de como os cálculos lentos de JavaScript foram substituídos pelo WebAssembly compilado e trouxe melhorias significativas de desempenho.
- Patrick Hamann tem falado sobre o crescente papel do WebAssembly e está desmistificando alguns mitos sobre o WebAssembly, explora seus desafios e podemos usá-lo praticamente em aplicativos hoje.
- O Google Codelabs fornece uma introdução ao WebAssembly, um curso de 60 minutos no qual você aprenderá a pegar código nativo — em C e compilá-lo para o WebAssembly e depois chamá-lo diretamente do JavaScript.
- Alex Danilo explicou o WebAssembly e como ele funciona em sua palestra no Google I/O. Além disso, Benedek Gagyi compartilhou um estudo de caso prático sobre WebAssembly, especificamente como a equipe o usa como formato de saída para sua base de código C++ para iOS, Android e site.
Ainda não tem certeza sobre quando usar Web Workers, Web Assembly, streams ou talvez WebGL JavaScript API para acessar a GPU? Acelerar JavaScript é um guia curto, mas útil, que explica quando usar o quê e por quê - também com um fluxograma útil e muitos recursos úteis.
- Servimos código legado apenas para navegadores legados?
Com o ES2017 sendo incrivelmente bem suportado em navegadores modernos, podemos usar obabelEsmPluginpara apenas transpilar recursos do ES2017+ não suportados pelos navegadores modernos que você está direcionando.Houssein Djirdeh e Jason Miller publicaram recentemente um guia abrangente sobre como transpilar e servir JavaScript moderno e legado, detalhando como fazê-lo funcionar com Webpack e Rollup, e as ferramentas necessárias. Você também pode estimar quanto JavaScript pode eliminar em seu site ou pacotes de aplicativos.
Os módulos JavaScript são suportados em todos os principais navegadores, então use
script type="module"para permitir que navegadores com suporte ao módulo ES carreguem o arquivo, enquanto navegadores mais antigos podem carregar compilações legadas comscript nomodule.Hoje em dia podemos escrever JavaScript baseado em módulo que roda nativamente no navegador, sem transpiladores ou empacotadores. O cabeçalho
<link rel="modulepreload">fornece uma maneira de iniciar o carregamento antecipado (e de alta prioridade) de scripts de módulo. Basicamente, é uma maneira bacana de ajudar a maximizar o uso da largura de banda, informando ao navegador sobre o que ele precisa buscar para que ele não fique preso a nada para fazer durante essas longas viagens de ida e volta. Além disso, Jake Archibald publicou um artigo detalhado com dicas e coisas para se ter em mente com os Módulos ES que vale a pena ler.
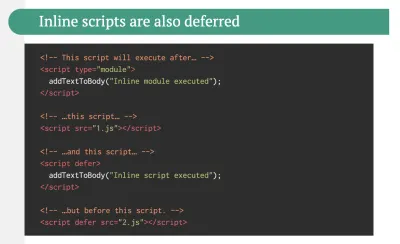
- Identifique e reescreva o código legado com desacoplamento incremental .
Projetos de longa duração tendem a acumular poeira e códigos datados. Revisite suas dependências e avalie quanto tempo seria necessário para refatorar ou reescrever o código legado que está causando problemas ultimamente. Claro, é sempre um grande empreendimento, mas uma vez que você conhece o impacto do código legado, você pode começar com o desacoplamento incremental.Primeiro, configure métricas que rastreiem se a proporção de chamadas de código legado permanece constante ou diminui, não aumenta. Desencoraje publicamente a equipe de usar a biblioteca e certifique-se de que seu CI alerte os desenvolvedores se ela for usada em pull requests. polyfills podem ajudar na transição do código legado para a base de código reescrita que usa recursos padrão do navegador.
- Identifique e remova CSS/JS não utilizado .
A cobertura de código CSS e JavaScript no Chrome permite que você saiba qual código foi executado/aplicado e qual não foi. Você pode começar a gravar a cobertura, executar ações em uma página e explorar os resultados da cobertura do código. Depois de detectar o código não utilizado, encontre esses módulos e carregue lentamente comimport()(veja o tópico inteiro). Em seguida, repita o perfil de cobertura e confirme que agora está enviando menos código no carregamento inicial.Você pode usar o Puppeteer para coletar cobertura de código programaticamente. O Chrome também permite exportar resultados de cobertura de código. Como Andy Davies observou, você pode querer coletar cobertura de código para navegadores modernos e legados.
Existem muitos outros casos de uso e ferramentas para o Puppetter que podem precisar de um pouco mais de exposição:
- Casos de uso para Puppeteer, como, por exemplo, diferenciação visual automática ou monitoramento de CSS não utilizado a cada compilação,
- Receitas de performance na web com o Puppeteer,
- Ferramentas úteis para gravar e gerar scripts de Pupeeteer e Playwright,
- Além disso, você pode até gravar testes diretamente no DevTools,
- Visão geral abrangente do Puppeteer por Nitay Neeman, com exemplos e casos de uso.
Podemos usar o Puppeteer Recorder e o Puppeteer Sandbox para gravar a interação do navegador e gerar scripts do Puppeteer e do Playwright. (Visualização grande) Além disso, purgecss, UnCSS e Helium podem ajudá-lo a remover estilos não utilizados do CSS. E se você não tiver certeza se um pedaço de código suspeito é usado em algum lugar, você pode seguir o conselho de Harry Roberts: crie um GIF transparente de 1×1px para uma classe específica e solte-o em um diretório
dead/, por exemplo,/assets/img/dead/comments.gif.Depois disso, você define essa imagem específica como plano de fundo no seletor correspondente em seu CSS, senta e espera alguns meses se o arquivo aparecer em seus logs. Se não houver entradas, ninguém teve esse componente legado renderizado em sua tela: você provavelmente pode ir em frente e excluir tudo.
Para o departamento I-meel-adventurous , você pode até automatizar a coleta de CSS não utilizado por meio de um conjunto de páginas monitorando o DevTools usando o DevTools.
- Reduza o tamanho de seus pacotes JavaScript.
Como Addy Osmani observou, há uma grande chance de você estar enviando bibliotecas JavaScript completas quando você precisa apenas de uma fração, junto com polyfills datados para navegadores que não precisam deles, ou apenas código duplicado. Para evitar a sobrecarga, considere usar webpack-libs-optimizations que removem métodos não utilizados e polyfills durante o processo de compilação.Verifique e revise os polyfills que você está enviando para navegadores legados e para navegadores modernos e seja mais estratégico sobre eles. Dê uma olhada no polyfill.io, que é um serviço que aceita uma solicitação de um conjunto de recursos do navegador e retorna apenas os polyfills necessários ao navegador solicitante.
Adicione também a auditoria de pacote ao seu fluxo de trabalho regular. Pode haver algumas alternativas leves para bibliotecas pesadas que você adicionou anos atrás, por exemplo, Moment.js (agora descontinuado) pode ser substituído por:
- API de internacionalização nativa,
- Day.js com uma API Moment.js e padrões familiares,
- data-fns ou
- Luxon.
- Você também pode usar o Skypack Discover, que combina recomendações de pacotes revisadas por humanos com uma pesquisa focada na qualidade.
A pesquisa de Benedikt Rotsch mostrou que uma mudança de Moment.js para date-fns poderia reduzir cerca de 300ms para a primeira pintura em 3G e um telefone celular de baixo custo.
Para auditoria de pacote, o Bundlephobia pode ajudar a encontrar o custo de adicionar um pacote npm ao seu pacote. size-limit estende a verificação básica do tamanho do pacote com detalhes sobre o tempo de execução do JavaScript. Você pode até integrar esses custos com uma auditoria personalizada do Lighthouse. Isso vale para frameworks também. Ao remover ou aparar o adaptador Vue MDC (Material Components for Vue), os estilos caem de 194 KB para 10 KB.
Existem muitas outras ferramentas para ajudá-lo a tomar uma decisão informada sobre o impacto de suas dependências e alternativas viáveis:
- webpack-bundle-analyzer
- Explorador do mapa de origem
- Pacote amigo
- Bundlefobia
- A análise do Webpack mostra por que um módulo específico está incluído no pacote.
- bundle-wizard também cria um mapa de dependências para a página inteira.
- Plugin de tamanho do Webpack
- Custo de importação para código visual
Como alternativa ao envio de toda a estrutura, você pode aparar sua estrutura e compilá-la em um pacote JavaScript bruto que não requer código adicional. Svelte faz isso, assim como o plugin Rawact Babel que transpila componentes React.js para operações DOM nativas em tempo de compilação. Por quê? Bem, como os mantenedores explicam, "react-dom inclui código para cada componente/HTMLElement possível que pode ser renderizado, incluindo código para renderização incremental, agendamento, manipulação de eventos, etc. carregamento de página). Para esses aplicativos, pode fazer sentido usar operações DOM nativas para construir a interface de usuário interativa."
- Usamos hidratação parcial?
Com a quantidade de JavaScript usada nos aplicativos, precisamos descobrir maneiras de enviar o mínimo possível para o cliente. Uma maneira de fazer isso – e já abordamos brevemente – é com hidratação parcial. A ideia é bem simples: em vez de fazer SSR e depois enviar o aplicativo inteiro para o cliente, apenas pequenas partes do JavaScript do aplicativo seriam enviadas ao cliente e depois hidratadas. Podemos pensar nisso como vários pequenos aplicativos React com várias raízes de renderização em um site estático.No artigo "O caso da hidratação parcial (com Next e Preact)", Lukas Bombach explica como a equipe por trás do Welt.de, um dos veículos de notícias da Alemanha, obteve melhor desempenho com hidratação parcial. Você também pode verificar o repositório GitHub do próximo super desempenho com explicações e trechos de código.
Você também pode considerar opções alternativas:
- hidratação parcial com Preact e Eleventy,
- hidratação progressiva no repositório React GitHub,
- hidratação preguiçosa no Vue.js (repositório do GitHub),
- Importar no padrão de interação para carregar lentamente recursos não críticos (por exemplo, componentes, incorporações) quando um usuário interage com a interface do usuário que precisa.
Jason Miller publicou demos de trabalho sobre como a hidratação progressiva pode ser implementada com o React, para que você possa usá-los imediatamente: demo 1, demo 2, demo 3 (também disponível no GitHub). Além disso, você pode olhar para a biblioteca de componentes react-prerendered.
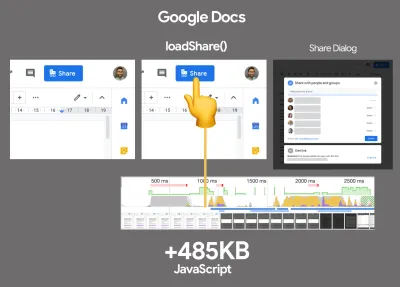
A importação na interação para código primário só deve ser feita se você não conseguir pré-buscar recursos antes da interação. (Visualização grande) - Otimizamos a estratégia para React/SPA?
Lutando com o desempenho em seu aplicativo de página única? Jeremy Wagner explorou o impacto do desempenho da estrutura do lado do cliente em uma variedade de dispositivos, destacando algumas das implicações e diretrizes das quais devemos estar cientes ao usar um.Como resultado, aqui está uma estratégia de SPA que Jeremy sugere usar para o framework React (mas não deve mudar significativamente para outros frameworks):
- Refatore componentes com estado como componentes sem estado sempre que possível.
- Pré-renderize componentes sem estado quando possível para minimizar o tempo de resposta do servidor. Renderize apenas no servidor.
- Para componentes com estado com interatividade simples, considere a pré-renderização ou renderização do servidor desse componente e substitua sua interatividade por ouvintes de eventos independentes de estrutura .
- Se você precisar hidratar componentes com estado no cliente, use hidratação lenta na visibilidade ou na interação.
- Para componentes com hidratação preguiçosa, agende sua hidratação durante o tempo ocioso do encadeamento principal com
requestIdleCallback.
Existem algumas outras estratégias que você pode querer seguir ou revisar:
- Considerações de desempenho para CSS-in-JS em aplicativos React
- Reduza o tamanho do pacote Next.js carregando polyfills somente quando necessário, usando importações dinâmicas e hidratação lenta.
- Segredos do JavaScript: Um conto de React, Performance Optimization e Multi-threading, uma longa série de 7 partes sobre como melhorar os desafios da interface do usuário com React,
- Como medir o desempenho do React e como criar o perfil de aplicativos React.
- Criando animações da web para dispositivos móveis em React, uma palestra fantástica de Alex Holachek, juntamente com slides e repositório do GitHub ( obrigado pela dica, Addy! ).
- webpack-libs-optimizations é um repositório GitHub fantástico com muitas otimizações úteis relacionadas ao desempenho específicas do Webpack. Mantido por Ivan Akulov.
- Melhorias de desempenho do React no Notion, um guia de Ivan Akulov sobre como melhorar o desempenho no React, com muitas dicas úteis para tornar o aplicativo cerca de 30% mais rápido.
- React Refresh Webpack Plugin (experimental) permite o recarregamento a quente que preserva o estado do componente e suporta ganchos e componentes de função.
- Cuidado com os componentes do servidor React Server de tamanho zero, um novo tipo de componente proposto que não terá impacto no tamanho do pacote. O projeto está atualmente em desenvolvimento, mas qualquer feedback da comunidade é muito apreciado (ótimo explicador por Sophie Alpert).
- Você está usando a pré-busca preditiva para fragmentos de JavaScript?
Poderíamos usar heurísticas para decidir quando pré-carregar partes do JavaScript. Guess.js é um conjunto de ferramentas e bibliotecas que usam dados do Google Analytics para determinar qual página um usuário provavelmente visitará em seguida em uma determinada página. Com base nos padrões de navegação do usuário coletados do Google Analytics ou de outras fontes, o Guess.js cria um modelo de aprendizado de máquina para prever e pré-buscar o JavaScript que será necessário em cada página subsequente.Portanto, cada elemento interativo está recebendo uma pontuação de probabilidade de engajamento e, com base nessa pontuação, um script do lado do cliente decide pré-buscar um recurso antecipadamente. Você pode integrar a técnica ao seu aplicativo Next.js, Angular e React, e há um plugin Webpack que automatiza o processo de configuração também.
Obviamente, você pode estar solicitando ao navegador que consuma dados desnecessários e pré-busque páginas indesejáveis, portanto, é uma boa ideia ser bastante conservador no número de solicitações pré-buscadas. Um bom caso de uso seria a pré-busca de scripts de validação necessários no check-out ou a pré-busca especulativa quando uma call-to-action crítica chega à janela de visualização.
Precisa de algo menos sofisticado? DNStradamus faz a pré-busca de DNS para links de saída conforme eles aparecem na janela de visualização. Quicklink, InstantClick e Instant.page são pequenas bibliotecas que pré-buscam automaticamente links na janela de visualização durante o tempo ocioso na tentativa de fazer as navegações da próxima página carregarem mais rapidamente. Quicklink permite pré-buscar rotas do React Router e Javascript; além de considerar os dados, não faz pré-busca em 2G ou se
Data-Saverestiver ativado. O mesmo acontece com o Instant.page se o modo estiver definido para usar a pré- busca da janela de visualização (que é um padrão).Se você quiser examinar a ciência da pré-busca preditiva em todos os detalhes, Divya Tagtachian tem uma ótima palestra sobre A arte da pré-busca preditiva, cobrindo todas as opções do início ao fim.
- Aproveite as otimizações para seu mecanismo JavaScript de destino.
Estude o que os mecanismos JavaScript dominam em sua base de usuários e explore maneiras de otimizar para eles. Por exemplo, ao otimizar para V8, que é usado em navegadores Blink, tempo de execução Node.js e Electron, use o streaming de script para scripts monolíticos.O streaming de script permite que scripts
asyncoudefer scriptssejam analisados em um thread de segundo plano separado assim que o download começa, portanto, em alguns casos, melhorando os tempos de carregamento da página em até 10%. Praticamente, use<script defer>no<head>, para que os navegadores possam descobrir o recurso antecipadamente e depois analisá-lo no thread em segundo plano.Advertência : O Opera Mini não suporta adiamento de script, portanto, se você estiver desenvolvendo para a Índia ou África, o
deferserá ignorado, resultando no bloqueio da renderização até que o script seja avaliado (obrigado Jeremy!) .Você também pode se conectar ao cache de código do V8, dividindo bibliotecas de código usando-as, ou vice-versa, mesclar bibliotecas e seus usos em um único script, agrupar pequenos arquivos e evitar scripts embutidos. Ou talvez até use o cache de compilação v8.
Quando se trata de JavaScript em geral, também existem algumas práticas que vale a pena ter em mente:
- Conceitos de código limpo para JavaScript, uma grande coleção de padrões para escrever código legível, reutilizável e refatorável.
- Você pode compactar dados de JavaScript com a API CompressionStream, por exemplo, para gzip antes de fazer upload de dados (Chrome 80+).
- Vazamentos de memória de janela desanexada e Corrigindo vazamentos de memória em aplicativos da Web são guias detalhados sobre como encontrar e corrigir vazamentos de memória JavaScript complicados. Além disso, você pode usar queryObjects(SomeConstructor) do DevTools Console ( obrigado, Mathias! ).
- As reexportações são ruins para o carregamento e o desempenho do tempo de execução, e evitá-las pode ajudar a reduzir significativamente o tamanho do pacote.
- Podemos melhorar o desempenho de rolagem com ouvintes de eventos passivos definindo um sinalizador no parâmetro
options. Assim, os navegadores podem rolar a página imediatamente, em vez de depois que o ouvinte terminar. (via Kayce Bascos). - Se você tiver ouvintes de
scrolloutouch*, passepassive: truepara addEventListener. Isso informa ao navegador que você não está planejando chamarevent.preventDefault()dentro, para que ele possa otimizar a maneira como lida com esses eventos. (via Ivan Akulov) - Podemos obter um melhor agendamento JavaScript com isInputPending(), uma nova API que tenta preencher a lacuna entre carregamento e capacidade de resposta com os conceitos de interrupções para entradas do usuário na Web e permite que o JavaScript seja capaz de verificar a entrada sem ceder a o navegador.
- Você também pode remover automaticamente um ouvinte de evento após sua execução.
- O recém-lançado Warp do Firefox, uma atualização significativa para o SpiderMonkey (enviado no Firefox 83), o Baseline Interpreter e algumas estratégias de otimização JIT também estão disponíveis.
- Sempre prefira auto-hospedar ativos de terceiros.
Mais uma vez, auto-hospede seus ativos estáticos por padrão. É comum supor que, se muitos sites usarem o mesmo CDN público e a mesma versão de uma biblioteca JavaScript ou uma fonte da web, os visitantes chegarão ao nosso site com os scripts e fontes já armazenados em cache em seu navegador, acelerando consideravelmente sua experiência . No entanto, é muito improvável que isso aconteça.Por motivos de segurança, para evitar impressões digitais, os navegadores estão implementando o cache particionado que foi introduzido no Safari em 2013 e no Chrome no ano passado. Portanto, se dois sites apontarem exatamente para o mesmo URL de recurso de terceiros, o código será baixado uma vez por domínio e o cache será "sandboxed" para esse domínio devido a implicações de privacidade ( obrigado, David Calhoun! ). Portanto, usar uma CDN pública não levará automaticamente a um melhor desempenho.
Além disso, vale a pena notar que os recursos não permanecem no cache do navegador por tanto tempo quanto poderíamos esperar, e os ativos primários são mais propensos a permanecer no cache do que os ativos de terceiros. Portanto, a auto-hospedagem geralmente é mais confiável e segura, e melhor para o desempenho também.
- Restrinja o impacto de scripts de terceiros.
Com todas as otimizações de desempenho implementadas, muitas vezes não podemos controlar scripts de terceiros provenientes de requisitos de negócios. As métricas de scripts de terceiros não são influenciadas pela experiência do usuário final, portanto, muitas vezes, um único script acaba chamando uma longa cauda de scripts de terceiros desagradáveis, arruinando um esforço de desempenho dedicado. Para conter e mitigar as penalidades de desempenho que esses scripts trazem, não é suficiente apenas adiar seu carregamento e execução e aquecer conexões por meio de dicas de recursos, ou seja,dns-prefetchoupreconnect.Atualmente, 57% de todo o tempo de execução de código JavaScript é gasto em código de terceiros. O site móvel mediano acessa 12 domínios de terceiros , com uma mediana de 37 solicitações diferentes (ou cerca de 3 solicitações feitas a cada terceiro).
Além disso, esses terceiros geralmente convidam scripts de terceiros para participar, acabando com um enorme gargalo de desempenho, às vezes chegando aos scripts de oito partes em uma página. Portanto, auditar regularmente suas dependências e gerenciadores de tags pode trazer surpresas caras.
Outro problema, como Yoav Weiss explicou em sua palestra sobre scripts de terceiros, é que em muitos casos esses scripts baixam recursos que são dinâmicos. Os recursos mudam entre os carregamentos de página, portanto, não sabemos necessariamente de quais hosts os recursos serão baixados e de quais recursos eles seriam.
Adiar, como mostrado acima, pode ser apenas o começo, pois scripts de terceiros também roubam largura de banda e tempo de CPU do seu aplicativo. Poderíamos ser um pouco mais agressivos e carregá-los apenas quando nosso aplicativo for inicializado.
/* Before */ const App = () => { return <div> <script> window.dataLayer = window.dataLayer || []; function gtag(){...} gtg('js', new Date()); </script> </div> } /* After */ const App = () => { const[isRendered, setRendered] = useState(false); useEffect(() => setRendered(true)); return <div> {isRendered ? <script> window.dataLayer = window.dataLayer || []; function gtag(){...} gtg('js', new Date()); </script> : null} </div> }Em um post fantástico sobre "Reduzindo o impacto de tags de terceiros na velocidade do site", Andy Davies explora uma estratégia de minimizar a pegada de terceiros - desde a identificação de seus custos até a redução de seu impacto.
De acordo com Andy, há duas maneiras pelas quais as tags afetam a velocidade do site — elas competem pela largura de banda da rede e pelo tempo de processamento nos dispositivos dos visitantes e, dependendo de como são implementadas, elas também podem atrasar a análise de HTML. Assim, o primeiro passo é identificar o impacto que os terceiros têm, testando o site com e sem scripts usando WebPageTest. Com o Request Map de Simon Hearne, também podemos visualizar terceiros em uma página junto com detalhes sobre seu tamanho, tipo e o que acionou sua carga.
De preferência, auto-hospede e use um único nome de host, mas também use um mapa de solicitação para expor chamadas de terceiros e detectar quando os scripts forem alterados. Você pode usar a abordagem de Harry Roberts para auditar terceiros e produzir planilhas como esta (verifique também o fluxo de trabalho de auditoria de Harry).
Depois, podemos explorar alternativas leves para scripts existentes e substituir lentamente duplicatas e principais culpados por opções mais leves. Talvez alguns dos scripts possam ser substituídos pelo pixel de rastreamento de fallback em vez da tag completa.

Carregando o YouTube com fachadas, por exemplo, lite-youtube-embed que é significativamente menor do que um player real do YouTube. (Fonte da imagem) (Visualização grande) Se não for viável, podemos pelo menos carregar recursos de terceiros com fachadas, ou seja, um elemento estático que se parece com o terceiro incorporado real, mas não é funcional e, portanto, muito menos oneroso no carregamento da página. O truque, então, é carregar a incorporação real apenas na interação .
Por exemplo, podemos usar:
- lite-vimeo-embed para o player do Vimeo,
- lite-vimeo para o player do Vimeo,
- lite-youtube-embed para o player do YouTube,
- react-live-chat-loader para um chat ao vivo (estudo de caso e outro estudo de caso),
- lazyframe para iframes.
Uma das razões pelas quais os gerenciadores de tags geralmente são grandes em tamanho é por causa dos muitos experimentos simultâneos que estão sendo executados ao mesmo tempo, juntamente com muitos segmentos de usuários, URLs de página, sites etc., então, de acordo com Andy, reduzi-los pode reduzir tanto o tamanho do download e o tempo que leva para executar o script no navegador.
E depois há trechos anti-cintilação. Terceiros como Google Optimize, Visual Web Optimizer (VWO) e outros são unânimes em usá-los. Esses snippets geralmente são injetados junto com a execução de testes A/B : para evitar oscilações entre os diferentes cenários de teste, eles ocultam o
bodydo documento comopacity: 0e adicionam uma função que é chamada após alguns segundos para trazer aopacityde volta . Isso geralmente resulta em grandes atrasos na renderização devido aos enormes custos de execução do lado do cliente.
Com o teste A/B em uso, os clientes costumam ver oscilações como esta. Os snippets Anti-Flicker evitam isso, mas também custam em desempenho. Via Andy Davies. (Visualização grande) Portanto, acompanhe a frequência com que o tempo limite anti-cintilação é acionado e reduza o tempo limite. O padrão bloqueia a exibição da sua página em até 4s, o que arruinará as taxas de conversão. De acordo com Tim Kadlec, "Amigos não deixam amigos fazerem testes A/B do lado do cliente". O teste A/B do lado do servidor em CDNs (por exemplo, Edge Computing ou Edge Slice Rerendering) é sempre uma opção de melhor desempenho.
Se você tiver que lidar com o todo-poderoso Gerenciador de tags do Google , Barry Pollard fornece algumas diretrizes para conter o impacto do Gerenciador de tags do Google. Além disso, Christian Schaefer explora estratégias para carregar anúncios.
Cuidado: alguns widgets de terceiros se escondem das ferramentas de auditoria, então podem ser mais difíceis de detectar e medir. Para testar terceiros, examine os resumos de baixo para cima na página Perfil de desempenho no DevTools, teste o que acontece se uma solicitação for bloqueada ou tiver expirado - para o último, você pode usar o servidor Blackhole do WebPageTest
blackhole.webpagetest.orgque você pode apontar domínios específicos para o seu arquivohosts.Que opções temos então? Considere o uso de service workers executando o download do recurso com um tempo limite e, se o recurso não tiver respondido dentro de um determinado tempo limite, retorne uma resposta vazia para informar ao navegador para continuar com a análise da página. Você também pode registrar ou bloquear solicitações de terceiros que não são bem-sucedidas ou que não atendem a determinados critérios. Se você puder, carregue o script de terceiros do seu próprio servidor em vez do servidor do fornecedor e carregue-o lentamente.
Outra opção é estabelecer uma Política de Segurança de Conteúdo (CSP) para restringir o impacto de scripts de terceiros, por exemplo, não permitir o download de áudio ou vídeo. A melhor opção é incorporar scripts via
<iframe>para que os scripts sejam executados no contexto do iframe e, portanto, não tenham acesso ao DOM da página e não possam executar código arbitrário em seu domínio. Iframes podem ser ainda mais restritos usando o atributosandbox, para que você possa desabilitar qualquer funcionalidade que o iframe possa fazer, por exemplo, impedir a execução de scripts, evitar alertas, envio de formulários, plugins, acesso à navegação superior e assim por diante.Você também pode manter terceiros sob controle por meio de linting de desempenho no navegador com políticas de recursos, um recurso relativamente novo que permite
ativar ou desativar determinados recursos do navegador em seu site. (Como nota lateral, também pode ser usado para evitar imagens superdimensionadas e não otimizadas, mídia não dimensionada, scripts de sincronização e outros). Atualmente suportado em navegadores baseados em Blink. /* Via Tim Kadlec. https://timkadlec.com/remembers/2020-02-20-in-browser-performance-linting-with-feature-policies/ */ /* Block the use of the Geolocation API with a Feature-Policy header. */ Feature-Policy: geolocation 'none'/* Via Tim Kadlec. https://timkadlec.com/remembers/2020-02-20-in-browser-performance-linting-with-feature-policies/ */ /* Block the use of the Geolocation API with a Feature-Policy header. */ Feature-Policy: geolocation 'none'Como muitos scripts de terceiros estão sendo executados em iframes, você provavelmente precisa restringir suas permissões. Os iframes em sandbox são sempre uma boa ideia, e cada uma das limitações pode ser eliminada por meio de vários valores de
allowno atributosandbox. O sandboxing é suportado em quase todos os lugares, portanto, restrinja os scripts de terceiros ao mínimo do que eles devem ter permissão para fazer.
ThirdPartyWeb.Today agrupa todos os scripts de terceiros por categoria (analítica, social, publicidade, hospedagem, gerenciador de tags etc.) e visualiza quanto tempo os scripts da entidade levam para serem executados (em média). (Visualização grande) Considere usar um Observador de Interseção; que permitiria que os anúncios fossem iframes enquanto ainda enviam eventos ou obtêm as informações de que precisam do DOM (por exemplo, visibilidade do anúncio). Fique atento a novas políticas, como política de recursos, limites de tamanho de recursos e prioridade de CPU/largura de banda para limitar recursos e scripts da Web prejudiciais que tornariam o navegador mais lento, por exemplo, scripts síncronos, solicitações XHR síncronas, document.write e implementações desatualizadas.
Por fim, ao escolher um serviço de terceiros, considere verificar o ThirdPartyWeb.Today de Patrick Hulce, um serviço que agrupa todos os scripts de terceiros por categoria (analítica, social, publicidade, hospedagem, gerenciador de tags etc.) e visualiza quanto tempo os scripts da entidade levar para executar (em média). Obviamente, as maiores entidades têm o pior impacto no desempenho das páginas em que estão. Apenas percorrendo a página, você terá uma ideia da pegada de desempenho que deve esperar.
Ah, e não se esqueça dos suspeitos de sempre: em vez de widgets de terceiros para compartilhamento, podemos usar botões estáticos de compartilhamento social (como por SSBG) e links estáticos para mapas interativos em vez de mapas interativos.
- Defina os cabeçalhos de cache HTTP corretamente.
O armazenamento em cache parece ser uma coisa tão óbvia a fazer, mas pode ser muito difícil acertar. Precisamos verificar novamente seexpires,max-age,cache-controle outros cabeçalhos de cache HTTP foram definidos corretamente. Sem os cabeçalhos de cache HTTP adequados, os navegadores os definirão automaticamente em 10% do tempo decorrido desdelast-modified, terminando com um possível armazenamento em cache insuficiente e excessivo.Em geral, os recursos devem ser armazenados em cache por um período muito curto (se for provável que mudem) ou indefinidamente (se forem estáticos) — você pode apenas alterar sua versão na URL quando necessário. Você pode chamar isso de estratégia Cache-Forever, na qual podemos retransmitir os cabeçalhos
Cache-ControleExpirespara o navegador para permitir que os ativos expirem apenas em um ano. Portanto, o navegador nem faria uma solicitação para o ativo se o tivesse no cache.A exceção são as respostas da API (por exemplo,
/api/user). Para evitar o armazenamento em cache, podemos usarprivate, no storee notmax-age=0, no-store:Cache-Control: private, no-storeUse
Cache-control: immutablepara evitar a revalidação de tempos de vida de cache explícitos longos quando os usuários pressionam o botão de recarregar. Para o caso de recarga,immutablesalva solicitações HTTP e melhora o tempo de carregamento do HTML dinâmico, pois eles não competem mais com a multiplicidade de respostas 304.Um exemplo típico em que queremos usar
immutablesão ativos CSS/JavaScript com um hash em seu nome. Para eles, provavelmente queremos armazenar em cache o maior tempo possível e garantir que nunca sejam revalidados:Cache-Control: max-age: 31556952, immutableDe acordo com a pesquisa de Colin Bendell,
immutablereduz os redirecionamentos 304 em cerca de 50%, pois mesmo commax-ageem uso, os clientes ainda são revalidados e bloqueados na atualização. É suportado no Firefox, Edge e Safari e o Chrome ainda está debatendo o problema.De acordo com o Web Almanac, "seu uso cresceu para 3,5% e é amplamente utilizado nas respostas de terceiros do Facebook e do Google".

Cache-Control: Immutable reduz 304s em cerca de 50%, de acordo com a pesquisa de Colin Bendell na Cloudinary. (Visualização grande) Você se lembra do bom e velho obsoleto-enquanto-revalida? Quando especificamos o tempo de armazenamento em cache com o cabeçalho de resposta
Cache-Control(por exemploCache-Control: max-age=604800), apósmax-ageexpirar, o navegador irá buscar novamente o conteúdo solicitado, fazendo com que a página carregue mais lentamente. Essa desaceleração pode ser evitada comstale-while-revalidate; ele basicamente define uma janela de tempo extra durante a qual um cache pode usar um ativo obsoleto, desde que o revalida assíncrono em segundo plano. Assim, ele "esconde" a latência (tanto na rede quanto no servidor) dos clientes.Em junho-julho de 2019, o Chrome e o Firefox lançaram o suporte de
stale-while-revalidateno cabeçalho HTTP Cache-Control, portanto, ele deve melhorar as latências de carregamento de página subsequentes, pois os ativos obsoletos não estão mais no caminho crítico. Resultado: zero RTT para visualizações repetidas.Tenha cuidado com o cabeçalho de variação, especialmente em relação a CDNs, e atente para as Variantes de Representação HTTP que ajudam a evitar uma viagem de ida e volta adicional para validação sempre que uma nova solicitação difere ligeiramente (mas não significativamente) das solicitações anteriores ( obrigado, Guy e Mark ! ).
Além disso, verifique novamente se você não está enviando cabeçalhos desnecessários (por exemplo
x-powered-by,pragma,x-ua-compatible,expires,X-XSS-Protectione outros) e se inclui cabeçalhos úteis de segurança e desempenho (como comoContent-Security-Policy,X-Content-Type-Optionse outros). Por fim, lembre-se do custo de desempenho das solicitações CORS em aplicativos de página única.Observação : geralmente assumimos que os ativos armazenados em cache são recuperados instantaneamente, mas pesquisas mostram que recuperar um objeto do cache pode levar centenas de milissegundos. Na verdade, de acordo com Simon Hearne, "às vezes a rede pode ser mais rápida que o cache, e recuperar ativos do cache pode ser caro com um grande número de ativos em cache (não o tamanho do arquivo) e os dispositivos do usuário. Por exemplo: recuperação média de cache do Chrome OS dobra de ~50ms com 5 recursos em cache até ~100ms com 25 recursos".
Além disso, geralmente assumimos que o tamanho do pacote não é um grande problema e os usuários farão o download uma vez e depois usarão a versão em cache. Ao mesmo tempo, com CI/CD, enviamos o código para produção várias vezes ao dia, o cache é invalidado todas as vezes, portanto, ser estratégico em relação ao armazenamento em cache.
Quando se trata de cache, há muitos recursos que valem a pena ler:
- Cache-Control for Civilians, um mergulho profundo em tudo que é armazenado em cache com Harry Roberts.
- Cartilha do Heroku sobre cabeçalhos de cache HTTP,
- Práticas recomendadas de armazenamento em cache por Jake Archibald,
- Cartilha de cache HTTP por Ilya Grigorik,
- Mantendo as coisas frescas com stale-while-revalidate por Jeff Posnick.
- CS Visualized: CORS por Lydia Hallie é um ótimo explicador sobre CORS, como ele funciona e como entendê-lo.
- Falando sobre CORS, aqui está uma pequena atualização sobre a Política de mesma origem de Eric Portis.
Otimizações de entrega
-
deferpara carregar JavaScript crítico de forma assíncrona?
Quando o usuário solicita uma página, o navegador busca o HTML e constrói o DOM, então busca o CSS e constrói o CSSOM, e então gera uma árvore de renderização combinando o DOM e o CSSOM. Se algum JavaScript precisar ser resolvido, o navegador não começará a renderizar a página até que ela seja resolvida, atrasando assim a renderização. Como desenvolvedores, temos que dizer explicitamente ao navegador para não esperar e começar a renderizar a página. A maneira de fazer isso para scripts é com os atributosdefereasyncem HTML.Na prática, é melhor usar
deferem vez deasync. Ah, qual é a diferença de novo? De acordo com Steve Souders, assim que os scriptsasyncchegam, eles são executados imediatamente – assim que o script estiver pronto. Se isso acontecer muito rápido, por exemplo, quando o script já estiver no cache, ele pode bloquear o analisador HTML. Comdefer, o navegador não executa scripts até que o HTML seja analisado. Portanto, a menos que você precise que o JavaScript seja executado antes de iniciar a renderização, é melhor usardefer. Além disso, vários arquivos assíncronos serão executados em uma ordem não determinística.Vale a pena notar que existem alguns equívocos sobre
asyncedefer. Mais importante,asyncnão significa que o código será executado sempre que o script estiver pronto; significa que ele será executado sempre que os scripts estiverem prontos e todo o trabalho de sincronização anterior estiver concluído. Nas palavras de Harry Roberts, "Se você colocar um scriptasyncapós os scripts de sincronização, seu scriptasyncserá tão rápido quanto o script de sincronização mais lento".Além disso, não é recomendado usar
asyncedefer. Os navegadores modernos suportam ambos, mas sempre que ambos os atributos são usados, oasyncsempre vence.Se você quiser se aprofundar em mais detalhes, Milica Mihajlija escreveu um guia muito detalhado sobre como construir o DOM mais rapidamente, entrando nos detalhes da análise especulativa, assíncrona e adiada.
- Carregue lentamente componentes caros com IntersectionObserver e dicas de prioridade.
Em geral, é recomendável carregar lentamente todos os componentes caros, como JavaScript pesado, vídeos, iframes, widgets e potencialmente imagens. O carregamento lento nativo já está disponível para imagens e iframes com o atributo deloading(somente Chromium). Sob o capô, esse atributo adia o carregamento do recurso até atingir uma distância calculada da janela de visualização.<!-- Lazy loading for images, iframes, scripts. Probably for images outside of the viewport. --> <img loading="lazy" ... /> <iframe loading="lazy" ... /> <!-- Prompt an early download of an asset. For critical images, eg hero images. --> <img loading="eager" ... /> <iframe loading="eager" ... />Esse limite depende de algumas coisas, desde o tipo de recurso de imagem que está sendo buscado até o tipo de conexão efetiva. Mas experimentos realizados usando o Chrome no Android sugerem que em 4G, 97,5% das imagens abaixo da dobra que são carregadas com preguiça foram totalmente carregadas em 10 ms após se tornarem visíveis, por isso deve ser seguro.
Também podemos usar o atributo de
importance(highoulow) em um elemento<script>,<img>ou<link>(somente Blink). Na verdade, é uma ótima maneira de priorizar imagens em carrosséis, bem como redefinir a prioridade de scripts. No entanto, às vezes podemos precisar de um controle um pouco mais granular.<!-- When the browser assigns "High" priority to an image, but we don't actually want that. --> <img src="less-important-image.svg" importance="low" ... /> <!-- We want to initiate an early fetch for a resource, but also deprioritize it. --> <link rel="preload" importance="low" href="/script.js" as="script" />A maneira mais eficiente de fazer um carregamento lento um pouco mais sofisticado é usando a API Intersection Observer, que fornece uma maneira de observar as alterações de forma assíncrona na interseção de um elemento de destino com um elemento ancestral ou com a janela de visualização de um documento de nível superior. Basicamente, você precisa criar um novo objeto
IntersectionObserver, que recebe uma função de retorno de chamada e um conjunto de opções. Em seguida, adicionamos um alvo para observar.A função de retorno de chamada é executada quando o destino se torna visível ou invisível, portanto, quando ela intercepta a viewport, você pode começar a executar algumas ações antes que o elemento se torne visível. Na verdade, temos um controle granular sobre quando o retorno de chamada do observador deve ser invocado, com
rootMargin(margem ao redor da raiz) ethreshold(um único número ou uma matriz de números que indicam em qual porcentagem da visibilidade do alvo estamos mirando).Alejandro Garcia Anglada publicou um tutorial útil sobre como realmente implementá-lo, Rahul Nanwani escreveu um post detalhado sobre carregamento lento de imagens de primeiro plano e plano de fundo, e o Google Fundamentals fornece um tutorial detalhado sobre carregamento lento de imagens e vídeos com o Intersection Observer também.
Lembra-se de longas leituras de histórias com direção de arte com objetos em movimento e pegajosos? Você também pode implementar o scrollytelling de alto desempenho com o Intersection Observer.
Verifique novamente o que mais você poderia carregar com preguiça. Até mesmo strings de tradução e emojis com carregamento lento podem ajudar. Ao fazer isso, o Mobile Twitter conseguiu alcançar uma execução JavaScript 80% mais rápida a partir do novo pipeline de internacionalização.
Uma palavra rápida de cautela, porém: vale a pena notar que o carregamento lento deve ser uma exceção e não a regra. Provavelmente não é razoável carregar com preguiça qualquer coisa que você realmente queira que as pessoas vejam rapidamente, por exemplo, imagens de páginas de produtos, imagens de heróis ou um script necessário para que a navegação principal se torne interativa.

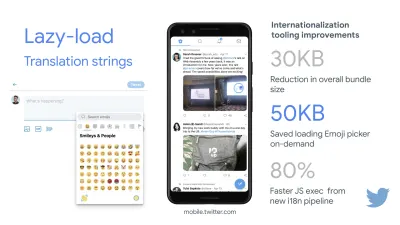
- Carregue imagens progressivamente.
Você pode até levar o carregamento lento para o próximo nível adicionando carregamento progressivo de imagens às suas páginas. Da mesma forma que no Facebook, Pinterest, Medium e Wolt, você pode carregar imagens de baixa qualidade ou até desfocadas primeiro e, à medida que a página continuar a carregar, substitua-as pelas versões de qualidade total usando a técnica BlurHash ou LQIP (Low Quality Image Placeholders) técnica.As opiniões diferem se essas técnicas melhoram ou não a experiência do usuário, mas definitivamente melhora o tempo para a primeira pintura de conteúdo. Podemos até automatizá-lo usando SQIP que cria uma versão de baixa qualidade de uma imagem como um espaço reservado SVG, ou Espaços reservados de imagem de gradiente com gradientes lineares CSS.
Esses espaços reservados podem ser incorporados ao HTML, pois são naturalmente compactados com métodos de compactação de texto. Em seu artigo, Dean Hume descreveu como essa técnica pode ser implementada usando o Intersection Observer.
Cair pra trás? Se o navegador não suportar observador de interseção, ainda podemos carregar um polyfill com preguiça ou carregar as imagens imediatamente. E tem até uma biblioteca para isso.
Quer ficar mais chique? Você pode rastrear suas imagens e usar formas e arestas primitivas para criar um espaço reservado SVG leve, carregá-lo primeiro e, em seguida, fazer a transição da imagem vetorial do espaço reservado para a imagem bitmap (carregada).
- Você adia a renderização com
content-visibility?
Para layouts complexos com muitos blocos de conteúdo, imagens e vídeos, decodificar dados e renderizar pixels pode ser uma operação bastante cara — especialmente em dispositivos de baixo custo. Comcontent-visibility: auto, podemos solicitar que o navegador ignore o layout dos filhos enquanto o contêiner estiver fora da janela de visualização.Por exemplo, você pode pular a renderização do rodapé e das seções finais no carregamento inicial:
footer { content-visibility: auto; contain-intrinsic-size: 1000px; /* 1000px is an estimated height for sections that are not rendered yet. */ }Observe que a visibilidade do conteúdo: auto; se comporta como estouro: oculto; , mas você pode corrigi-lo aplicando
padding-leftepadding-rightem vez domargin-left: auto;,margin-right: auto;e uma largura declarada. O preenchimento basicamente permite que os elementos transbordem a caixa de conteúdo e entrem na caixa de preenchimento sem deixar o modelo de caixa como um todo e ser cortado.Além disso, lembre-se de que você pode introduzir algum CLS quando o novo conteúdo for renderizado, portanto, é uma boa ideia usar
contain-intrinsic-sizecom um espaço reservado de tamanho adequado ( obrigado, Una! ).Thijs Terluin tem muito mais detalhes sobre ambas as propriedades e como
contain-intrinsic-sizeé calculado pelo navegador, Malte Ubl mostra como você pode calculá-lo e um breve vídeo explicativo de Jake e Surma explica como tudo funciona.E se você precisar ficar um pouco mais granular, com CSS Containment, você pode pular manualmente layout, estilo e trabalho de pintura para descendentes de um nó DOM se você precisar apenas de tamanho, alinhamento ou estilos computados em outros elementos - ou o elemento está atualmente fora da tela.


content-visibility: auto a áreas de conteúdo em partes oferece um aumento de 7 vezes no desempenho de renderização no carregamento inicial. (Visualização grande)- Você adia a decodificação com
decoding="async"?
Às vezes, o conteúdo aparece fora da tela, mas queremos garantir que ele esteja disponível quando os clientes precisarem — idealmente, não bloqueando nada no caminho crítico, mas decodificando e renderizando de forma assíncrona. Podemos usardecoding="async"para dar ao navegador permissão para decodificar a imagem do thread principal, evitando o impacto do usuário do tempo de CPU usado para decodificar a imagem (via Malte Ubl):<img decoding="async" … />Alternativamente, para imagens fora da tela, podemos exibir primeiro um espaço reservado e, quando a imagem estiver dentro da janela de visualização, usando IntersectionObserver, acionar uma chamada de rede para que a imagem seja baixada em segundo plano. Além disso, podemos adiar a renderização até a decodificação com img.decode() ou baixar a imagem se a API de decodificação de imagem não estiver disponível.
Ao renderizar a imagem, podemos usar animações de fade-in, por exemplo. Katie Hempenius e Addy Osmani compartilham mais insights em sua palestra Speed at Scale: Web Performance Tips and Tricks from the Trenches.
- Você gera e serve CSS crítico?
Para garantir que os navegadores comecem a renderizar sua página o mais rápido possível, tornou-se uma prática comum coletar todo o CSS necessário para começar a renderizar a primeira parte visível da página (conhecida como "CSS crítico" ou "CSS acima da dobra ") e incluí-lo inline no<head>da página, reduzindo assim as viagens de ida e volta. Devido ao tamanho limitado dos pacotes trocados durante a fase de início lento, seu orçamento para CSS crítico é de cerca de 14 KB.Se você for além disso, o navegador precisará de viagens de ida e volta adicionais para buscar mais estilos. CriticalCSS e Critical permitem que você produza CSS crítico para cada modelo que estiver usando. Em nossa experiência, porém, nenhum sistema automático foi melhor do que a coleta manual de CSS crítico para cada modelo e, de fato, essa é a abordagem para a qual voltamos recentemente.
Você pode então inline CSS crítico e carregar lentamente o resto com o plugin critters Webpack. Se possível, considere usar a abordagem de inlining condicional usada pelo Filament Group ou converta o código inline em ativos estáticos em tempo real.
Se você atualmente carrega seu CSS completo de forma assíncrona com bibliotecas como loadCSS, isso não é realmente necessário. Com
media="print", você pode enganar o navegador para buscar o CSS de forma assíncrona, mas aplicar ao ambiente da tela assim que ele for carregado. ( obrigado, Scott! )<!-- Via Scott Jehl. https://www.filamentgroup.com/lab/load-css-simpler/ --> <!-- Load CSS asynchronously, with low priority --> <link rel="stylesheet" href="full.css" media="print" onload="this.media='all'" />Ao coletar todo o CSS crítico para cada modelo, é comum explorar apenas a área "acima da dobra". No entanto, para layouts complexos, pode ser uma boa ideia incluir a base do layout também para evitar custos massivos de recálculo e repintura, prejudicando sua pontuação no Core Web Vitals como resultado.
E se um usuário obtiver um URL que está direcionando diretamente para o meio da página, mas o CSS ainda não foi baixado? Nesse caso, tornou-se comum ocultar conteúdo não crítico, por exemplo, com
opacity: 0;em CSS embutido eopacity: 1em arquivo CSS completo e exibi-lo quando CSS estiver disponível. No entanto, ele tem uma grande desvantagem , pois os usuários em conexões lentas podem nunca conseguir ler o conteúdo da página. É por isso que é melhor sempre manter o conteúdo visível, mesmo que não esteja estilizado corretamente.Colocar CSS crítico (e outros ativos importantes) em um arquivo separado no domínio raiz traz benefícios, às vezes até mais do que inlining, devido ao cache. O Chrome abre especulativamente uma segunda conexão HTTP com o domínio raiz ao solicitar a página, o que elimina a necessidade de uma conexão TCP para buscar esse CSS. Isso significa que você pode criar um conjunto de arquivos -CSS críticos (por exemplo, critical-homepage.css , critical-product-page.css etc.) e servi-los de sua raiz, sem ter que inline-los. ( obrigado, Felipe! )
Uma palavra de cautela: com HTTP/2, CSS crítico pode ser armazenado em um arquivo CSS separado e entregue por meio de um servidor push sem sobrecarregar o HTML. O problema é que o push do servidor foi problemático com muitas pegadinhas e condições de corrida nos navegadores. Ele nunca foi suportado de forma consistente e teve alguns problemas de cache (veja o slide 114 em diante da apresentação de Hooman Beheshti).
O efeito pode, de fato, ser negativo e sobrecarregar os buffers da rede, impedindo que quadros genuínos no documento sejam entregues. Portanto, não foi muito surpreendente que, por enquanto, o Chrome esteja planejando remover o suporte ao Server Push.
- Experimente reagrupar suas regras CSS.
Estamos acostumados com CSS crítico, mas existem algumas otimizações que podem ir além disso. Harry Roberts conduziu uma pesquisa notável com resultados bastante surpreendentes. Por exemplo, pode ser uma boa ideia dividir o arquivo CSS principal em suas consultas de mídia individuais. Dessa forma, o navegador recuperará CSS crítico com alta prioridade e todo o resto com baixa prioridade - completamente fora do caminho crítico.Além disso, evite colocar
<link rel="stylesheet" />antes de trechosasync. Se os scripts não dependerem de folhas de estilo, considere colocar scripts de bloqueio acima dos estilos de bloqueio. Se o fizerem, divida esse JavaScript em dois e carregue-o em ambos os lados do seu CSS.Scott Jehl resolveu outro problema interessante armazenando em cache um arquivo CSS embutido com um service worker, um problema comum familiar se você estiver usando CSS crítico. Basicamente, adicionamos um atributo de ID ao elemento de
stylepara que seja fácil encontrá-lo usando JavaScript, então um pequeno pedaço de JavaScript encontra esse CSS e usa a API de cache para armazená-lo em um cache de navegador local (com um tipo de conteúdo detext/css) para uso nas páginas subsequentes. Para evitar o inline nas páginas subsequentes e, em vez disso, referenciar os ativos armazenados em cache externamente, definimos um cookie na primeira visita a um site. Voilá!Vale a pena notar que o estilo dinâmico também pode ser caro, mas geralmente apenas nos casos em que você confia em centenas de componentes compostos renderizados simultaneamente. Portanto, se você estiver usando CSS-in-JS, certifique-se de que sua biblioteca CSS-in-JS otimize a execução quando seu CSS não tiver dependências de tema ou adereços e não sobreponha componentes estilizados . Aggelos Arvanitakis compartilha mais insights sobre os custos de desempenho do CSS-in-JS.
- Você transmite respostas?
Frequentemente esquecidos e negligenciados, os fluxos fornecem uma interface para leitura ou gravação de blocos de dados assíncronos, dos quais apenas um subconjunto pode estar disponível na memória a qualquer momento. Basicamente, eles permitem que a página que fez a solicitação original comece a trabalhar com a resposta assim que o primeiro bloco de dados estiver disponível e use analisadores otimizados para streaming para exibir progressivamente o conteúdo.Poderíamos criar um fluxo de várias fontes. Por exemplo, em vez de servir um shell de interface do usuário vazio e permitir que o JavaScript o preencha, você pode permitir que o service worker construa um fluxo em que o shell vem de um cache, mas o corpo vem da rede. Como Jeff Posnick observou, se o seu aplicativo da web é alimentado por um CMS que renderiza HTML pelo servidor juntando modelos parciais, esse modelo se traduz diretamente no uso de respostas de streaming, com a lógica de modelagem replicada no service worker em vez de no servidor. O artigo The Year of Web Streams de Jake Archibald destaca como exatamente você pode construí-lo. O aumento de desempenho é bastante perceptível.
Uma vantagem importante de transmitir toda a resposta HTML é que o HTML renderizado durante a solicitação de navegação inicial pode aproveitar ao máximo o analisador HTML de streaming do navegador. Pedaços de HTML que são inseridos em um documento após o carregamento da página (como é comum com conteúdo preenchido via JavaScript) não podem aproveitar essa otimização.
Suporte ao navegador? Ainda chegando lá com suporte parcial no Chrome, Firefox, Safari e Edge suportando a API e Service Workers sendo suportados em todos os navegadores modernos. E se você se sentir aventureiro novamente, pode verificar uma implementação experimental de solicitações de streaming, que permite começar a enviar a solicitação enquanto ainda gera o corpo. Disponível no Chrome 85.
- Considere tornar seus componentes com reconhecimento de conexão.
Os dados podem ser caros e com carga útil crescente, precisamos respeitar os usuários que optam por optar pela economia de dados ao acessar nossos sites ou aplicativos. O cabeçalho de solicitação de dica do cliente Save-Data nos permite personalizar o aplicativo e a carga útil para usuários com restrições de custo e desempenho.Na verdade, você pode reescrever solicitações de imagens de alto DPI para imagens de baixo DPI, remover fontes da Web, efeitos de paralaxe sofisticados, miniaturas de visualização e rolagem infinita, desativar a reprodução automática de vídeo, envios de servidor, reduzir o número de itens exibidos e diminuir a qualidade da imagem ou até mesmo alterar a forma como você entrega marcação. Tim Vereecke publicou um artigo muito detalhado sobre estratégias de data-s(h)aver apresentando muitas opções para economia de dados.
Quem está usando
save-data, você pode estar se perguntando? 18% dos usuários globais do Android Chrome têm o Modo Lite ativado (comSave-Dataativado) e o número provavelmente será maior. De acordo com a pesquisa de Simon Hearne, a taxa de adesão é mais alta em dispositivos mais baratos, mas há muitos valores discrepantes. Por exemplo: os usuários no Canadá têm uma taxa de adesão de mais de 34% (em comparação com ~7% nos EUA) e os usuários do mais recente carro-chefe da Samsung têm uma taxa de adesão de quase 18% globalmente.Com o modo
Save-Dataativado, o Chrome Mobile fornecerá uma experiência otimizada, ou seja, uma experiência da Web com proxy com scripts adiados ,font-display: swape carregamento lento forçado. É mais sensato construir a experiência por conta própria, em vez de depender do navegador para fazer essas otimizações.Atualmente, o cabeçalho é suportado apenas no Chromium, na versão Android do Chrome ou por meio da extensão Data Saver em um dispositivo desktop. Por fim, você também pode usar a API de informações de rede para fornecer módulos JavaScript caros, imagens e vídeos de alta resolução com base no tipo de rede. A API de informações de rede e especificamente
navigator.connection.effectiveTypeusam valoresRTT,downlink,effectiveType(e alguns outros) para fornecer uma representação da conexão e dos dados que os usuários podem manipular.Nesse contexto, Max Bock fala de componentes com reconhecimento de conexão e Addy Osmani fala de serviço de módulo adaptável. Por exemplo, com o React, poderíamos escrever um componente que renderiza de forma diferente para diferentes tipos de conexão. Como Max sugeriu, um componente
<Media />em um artigo de notícias pode gerar:-
Offline: um espaço reservado com textoalt, -
2G/ modosave-data: uma imagem de baixa resolução, -
3Gem tela não Retina: uma imagem de resolução média, -
3Gem telas Retina: imagem Retina de alta resolução, -
4G: um vídeo HD.
Dean Hume fornece uma implementação prática de uma lógica semelhante usando um service worker. Para um vídeo, podemos exibir um pôster de vídeo por padrão e, em seguida, exibir o ícone "Reproduzir", bem como o shell do player de vídeo, metadados do vídeo etc. em conexões melhores. Como alternativa para navegadores não compatíveis, poderíamos ouvir o evento
canplaythroughe usarPromise.race()para expirar o carregamento da fonte se o eventocanplaythroughnão disparar em 2 segundos.Se você quiser se aprofundar um pouco mais, aqui estão alguns recursos para começar:
- Addy Osmani mostra como implementar a veiculação adaptativa no React.
- React Adaptive Loading Hooks & Utilities fornece trechos de código para React,
- Netanel Basel explora componentes com reconhecimento de conexão em Angular,
- Theodore Vorilas compartilha como funciona Servir Componentes Adaptativos Usando a API de Informações de Rede no Vue.
- Umar Hansa mostra como baixar/executar seletivamente JavaScript caro.
-
- Considere tornar seu dispositivo de componentes com reconhecimento de memória.
A conexão de rede nos dá apenas uma perspectiva no contexto do usuário. Indo além, você também pode ajustar dinamicamente os recursos com base na memória disponível do dispositivo, com a API de memória do dispositivo.navigator.deviceMemoryretorna a quantidade de RAM do dispositivo em gigabytes, arredondado para a potência de dois mais próxima. A API também apresenta um cabeçalho de dicas do cliente,Device-Memory, que informa o mesmo valor.Bônus : Umar Hansa mostra como adiar scripts caros com importações dinâmicas para alterar a experiência com base na memória do dispositivo, conectividade de rede e simultaneidade de hardware.
- Aqueça a conexão para acelerar a entrega.
Use dicas de recursos para economizar tempo nadns-prefetch(que executa uma pesquisa de DNS em segundo plano), pré-preconnect(que solicita ao navegador para iniciar o handshake de conexão (DNS, TCP, TLS) em segundo plano),prefetch-busca (que solicita ao navegador para solicitar um recurso) epreload-carregar (que pré-busca recursos sem executá-los, entre outras coisas). Bem suportado em navegadores modernos, com suporte para Firefox em breve.Lembra
prerender? A dica de recurso usada para solicitar ao navegador que crie a página inteira em segundo plano para a próxima navegação. Os problemas de implementação foram bastante problemáticos, variando de um enorme consumo de memória e uso de largura de banda a vários acessos de análise registrados e impressões de anúncios.Sem surpresa, ele foi preterido, mas a equipe do Chrome o trouxe de volta como mecanismo NoState Prefetch. Na verdade, o Chrome trata a dica de pré-renderização como uma
prerenderPrefetch, então ainda podemos usá-la hoje. Como Katie Hempenius explica nesse artigo, "assim como a pré-renderização, a NoState Prefetch busca recursos antecipadamente ; mas, diferentemente da pré-renderização, ela não executa JavaScript ou renderiza qualquer parte da página antecipadamente".O NoState Prefetch usa apenas ~45MiB de memória e os sub-recursos que são buscados serão buscados com uma prioridade de rede
IDLE. Desde o Chrome 69, o NoState Prefetch adiciona o cabeçalho Objetivo: Pré -busca a todas as solicitações para torná-las distinguíveis da navegação normal.Além disso, fique atento às alternativas e portais de pré-renderização, um novo esforço em direção à pré-renderização consciente da privacidade, que fornecerá a
previewinserida do conteúdo para navegações perfeitas.Usar dicas de recursos é provavelmente a maneira mais fácil de aumentar o desempenho e funciona bem. Quando usar o quê? Como Addy Osmani explicou, é razoável pré-carregar recursos que sabemos que provavelmente serão usados na página atual e para futuras navegações em vários limites de navegação, por exemplo, pacotes Webpack necessários para páginas que o usuário ainda não visitou.
O artigo de Addy sobre "Carregar prioridades no Chrome" mostra exatamente como o Chrome interpreta as dicas de recursos, portanto, depois de decidir quais ativos são críticos para renderização, você pode atribuir alta prioridade a eles. Para ver como suas solicitações são priorizadas, você pode ativar uma coluna "prioridade" na tabela de solicitações de rede do Chrome DevTools (assim como o Safari).
Na maioria das vezes, usaremos pelo menos
preconnectedns-prefetch, e seremos cautelosos ao usarprefetch,preloadeprerender. Observe que, mesmo compreconnectedns-prefetch, o navegador tem um limite no número de hosts que ele procurará/conectará em paralelo, então é uma aposta segura ordená-los com base na prioridade ( obrigado Philip Tellis! ).Como as fontes geralmente são recursos importantes em uma página, às vezes é uma boa ideia solicitar ao navegador que baixe fontes críticas com
preload-carregamento . No entanto, verifique se isso realmente ajuda no desempenho, pois há um quebra-cabeça de prioridades ao pré-carregar fontes: como opreload-carregamento é visto como de alta importância, ele pode ultrapassar recursos ainda mais críticos, como CSS crítico. ( obrigado, Barry! )<!-- Loading two rendering-critical fonts, but not all their weights. --> <!-- crossorigin="anonymous" is required due to CORS. Without it, preloaded fonts will be ignored. https://github.com/w3c/preload/issues/32 via https://twitter.com/iamakulov/status/1275790151642423303 --> <link rel="preload" as="font" href="Elena-Regular.woff2" type="font/woff2" crossorigin="anonymous" media="only screen and (min-width: 48rem)" /> <link rel="preload" as="font" href="Mija-Bold.woff2" type="font/woff2" crossorigin="anonymous" media="only screen and (min-width: 48rem)" /><!-- Loading two rendering-critical fonts, but not all their weights. --> <!-- crossorigin="anonymous" is required due to CORS. Without it, preloaded fonts will be ignored. https://github.com/w3c/preload/issues/32 via https://twitter.com/iamakulov/status/1275790151642423303 --> <link rel="preload" as="font" href="Elena-Regular.woff2" type="font/woff2" crossorigin="anonymous" media="only screen and (min-width: 48rem)" /> <link rel="preload" as="font" href="Mija-Bold.woff2" type="font/woff2" crossorigin="anonymous" media="only screen and (min-width: 48rem)" />Como
<link rel="preload">aceita um atributo demedia, você pode optar por baixar recursos seletivamente com base nas regras de consulta@media, conforme mostrado acima.Além disso, podemos usar os atributos
imagesrcseteimagesizespara pré-carregar imagens de herói descobertas tardiamente mais rapidamente, ou qualquer imagem que seja carregada via JavaScript, por exemplo, pôsteres de filmes:<!-- Addy Osmani. https://addyosmani.com/blog/preload-hero-images/ --> <link rel="preload" as="image" href="poster.jpg" image image><!-- Addy Osmani. https://addyosmani.com/blog/preload-hero-images/ --> <link rel="preload" as="image" href="poster.jpg" image image>Também podemos pré-carregar o JSON como fetch , para que seja descoberto antes que o JavaScript o solicite:
<!-- Addy Osmani. https://addyosmani.com/blog/preload-hero-images/ --> <link rel="preload" as="fetch" href="foo.com/api/movies.json" crossorigin>Também poderíamos carregar JavaScript dinamicamente, efetivamente para execução lenta do script.
/* Adding a preload hint to the head */ var preload = document.createElement("link"); link.href = "myscript.js"; link.rel = "preload"; link.as = "script"; document.head.appendChild(link); /* Injecting a script when we want it to execute */ var script = document.createElement("script"); script.src = "myscript.js"; document.body.appendChild(script);Algumas pegadinhas a serem lembradas: o
preload-carregamento é bom para aproximar o tempo de download de um ativo da solicitação inicial, mas os ativos pré-carregados chegam ao cache de memória que está vinculado à página que faz a solicitação.preloadfunciona bem com o cache HTTP: uma solicitação de rede nunca é enviada se o item já estiver no cache HTTP.Portanto, é útil para recursos descobertos tardiamente, imagens de herói carregadas por meio
background-image, CSS crítico embutido (ou JavaScript) e pré-carregamento do restante do CSS (ou JavaScript).
Pré-carregue imagens importantes antecipadamente; não há necessidade de esperar no JavaScript para descobri-los. (Crédito da imagem: “Preload Late-Discovered Hero Images Faster” por Addy Osmani) (Visualização grande) Uma tag de
preload-carregamento pode iniciar um pré-carregamento somente após o navegador ter recebido o HTML do servidor e o analisador lookahead encontrar a tag depreload-carregamento. O pré-carregamento através do cabeçalho HTTP pode ser um pouco mais rápido, pois não precisamos esperar que o navegador analise o HTML para iniciar a solicitação (embora seja debatido).As dicas iniciais ajudarão ainda mais, permitindo que o pré-carregamento seja ativado antes mesmo que os cabeçalhos de resposta para o HTML sejam enviados (no roteiro no Chromium, Firefox). Além disso, as dicas de prioridade nos ajudarão a indicar as prioridades de carregamento dos scripts.
Cuidado : se você estiver usando
preload,asdeve ser definido ou nada carrega, mais fontes pré-carregadas sem o atributocrossoriginserão buscadas duas vezes. Se você estiver usandoprefetch, cuidado com os problemas do cabeçalhoAgeno Firefox.
- Use service workers para cache e fallbacks de rede.
Nenhuma otimização de desempenho em uma rede pode ser mais rápida do que um cache armazenado localmente na máquina de um usuário (há exceções). Se seu site estiver sendo executado em HTTPS, podemos armazenar em cache ativos estáticos em um cache de service worker e armazenar fallbacks offline (ou mesmo páginas offline) e recuperá-los da máquina do usuário, em vez de ir para a rede.Conforme sugerido por Phil Walton, com os service workers, podemos enviar cargas úteis HTML menores gerando nossas respostas programaticamente. Um service worker pode solicitar apenas o mínimo de dados de que precisa do servidor (por exemplo, uma parcial de conteúdo HTML, um arquivo Markdown, dados JSON etc.) e, em seguida, pode transformar programaticamente esses dados em um documento HTML completo. Assim, quando um usuário visita um site e o service worker é instalado, o usuário nunca mais solicitará uma página HTML completa. O impacto no desempenho pode ser bastante impressionante.
Suporte ao navegador? Os service workers são amplamente suportados e o fallback é a rede de qualquer maneira. Isso ajuda a aumentar o desempenho ? Ah, sim, ele faz. E está ficando melhor, por exemplo, com Background Fetch permitindo uploads/downloads em segundo plano através de um service worker também.
Há vários casos de uso para um service worker. Por exemplo, você pode implementar o recurso "Salvar para offline", lidar com imagens quebradas, introduzir mensagens entre guias ou fornecer diferentes estratégias de armazenamento em cache com base nos tipos de solicitação. Em geral, uma estratégia confiável comum é armazenar o shell do aplicativo no cache do service worker junto com algumas páginas críticas, como página offline, página inicial e qualquer outra coisa que possa ser importante no seu caso.
Existem algumas pegadinhas para manter em mente embora. Com um service worker no local, precisamos tomar cuidado com as solicitações de intervalo no Safari (se você estiver usando o Workbox para um service worker, ele terá um módulo de solicitação de intervalo). Se você já se deparou com
DOMException: Quota exceeded.erro no console do navegador, então veja o artigo de Gerardo Quando 7KB é igual a 7MB.Como Gerardo escreve: “Se você estiver criando um aplicativo da Web progressivo e estiver experimentando armazenamento em cache inchado quando seu service worker armazena em cache ativos estáticos servidos de CDNs, certifique-se de que o cabeçalho de resposta CORS adequado exista para recursos de origem cruzada, você não armazena em cache respostas opacas com seu service worker inadvertidamente, você aceita ativos de imagem de origem cruzada no modo
crossoriginadicionando o atributo de origem cruzada à tag<img>.”Há muitos recursos excelentes para começar a trabalhar com service workers:
- Service Worker Mindset, que ajuda você a entender como os service workers trabalham nos bastidores e o que entender ao construir um.
- Chris Ferdinandi fornece uma grande série de artigos sobre service workers, explicando como criar aplicativos offline e cobrindo uma variedade de cenários, desde salvar páginas visualizadas recentemente offline até definir uma data de expiração para itens em um cache de service worker.
- Armadilhas e práticas recomendadas do Service Worker, com algumas dicas sobre o escopo, atraso no registro de um service worker e no cache do service worker.
- Ótima série de Ire Aderinokun em "Offline First" com Service Worker, com uma estratégia de pré-cache no shell do aplicativo.
- Service Worker: uma introdução com dicas práticas sobre como usar o service worker para experiências offline avançadas, sincronizações periódicas em segundo plano e notificações push.
- Sempre vale a pena consultar o livro de receitas offline do bom e velho Jake Archibald, com várias receitas sobre como preparar seu próprio service worker.
- Workbox é um conjunto de bibliotecas de service worker criadas especificamente para criar aplicativos da Web progressivos.
- Você está executando servidores de trabalho no CDN/Edge, por exemplo, para testes A/B?
Neste ponto, estamos bastante acostumados a executar service workers no cliente, mas com CDNs implementando-os no servidor, podemos usá-los para ajustar o desempenho na borda também.Por exemplo, em testes A/B, quando o HTML precisa variar seu conteúdo para diferentes usuários, podemos usar Service Workers nos servidores CDN para lidar com a lógica. Também podemos transmitir a reescrita de HTML para acelerar sites que usam o Google Fonts.
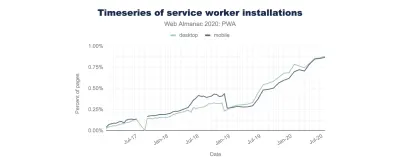
- Otimize o desempenho de renderização.
Sempre que o aplicativo está lento, é perceptível imediatamente. Portanto, precisamos ter certeza de que não há atraso ao rolar a página ou quando um elemento é animado e que você está atingindo consistentemente 60 quadros por segundo. Se isso não for possível, pelo menos tornar os quadros por segundo consistentes é preferível a um intervalo misto de 60 a 15. Use o CSS'will-changepara informar ao navegador quais elementos e propriedades serão alterados.Sempre que estiver enfrentando, depure repinturas desnecessárias no DevTools:
- Meça o desempenho de renderização em tempo de execução. Confira algumas dicas úteis sobre como entender isso.
- Para começar, verifique o curso gratuito Udacity de Paul Lewis sobre otimização de renderização de navegador e o artigo de Georgy Marchuk sobre pintura de navegador e considerações para desempenho na web.
- Ative o Paint Flashing em "Mais ferramentas → Renderização → Paint Flashing" no Firefox DevTools.
- No React DevTools, marque "Destacar atualizações" e ative "Registrar por que cada componente foi renderizado",
- Você também pode usar Why Did You Render, então quando um componente for renderizado novamente, um flash irá notificá-lo sobre a mudança.
Você está usando um layout de alvenaria? Tenha em mente que pode ser possível construir um layout Masonry apenas com grade CSS, muito em breve.
Se você quiser se aprofundar no tópico, Nolan Lawson compartilhou truques para medir com precisão o desempenho do layout em seu artigo, e Jason Miller também sugeriu técnicas alternativas. Também temos um pequeno artigo de Sergey Chikuyonok sobre como obter a animação GPU certa.

Os navegadores podem animar a transformação e a opacidade de forma barata. CSS Triggers é útil para verificar se o CSS aciona re-layouts ou reflows. (Crédito da imagem: Addy Osmani)(Grande visualização) Nota : as alterações nas camadas compostas por GPU são as menos caras, portanto, se você puder se safar acionando apenas a composição via
opacityetransform, estará no caminho certo. Anna Migas também forneceu muitos conselhos práticos em sua palestra sobre Depuração do desempenho de renderização da interface do usuário. E para entender como depurar o desempenho da pintura no DevTools, confira o vídeo de auditoria de desempenho da pintura de Umar. - Você otimizou para o desempenho percebido?
Embora a sequência de como os componentes aparecem na página e a estratégia de como fornecemos recursos para o navegador sejam importantes, também não devemos subestimar o papel do desempenho percebido. O conceito lida com aspectos psicológicos da espera, basicamente mantendo os clientes ocupados ou engajados enquanto outra coisa está acontecendo. É aí que entram em jogo a gestão da percepção, o início preventivo, a conclusão antecipada e a gestão da tolerância.O que tudo isso significa? Ao carregar ativos, podemos tentar estar sempre um passo à frente do cliente, para que a experiência pareça rápida enquanto há muita coisa acontecendo em segundo plano. Para manter o cliente engajado, podemos testar telas de esqueleto (demonstração de implementação) ao invés de indicadores de carregamento, adicionar transições/animações e basicamente enganar o UX quando não há mais nada para otimizar.
Em seu estudo de caso sobre The Art of UI Skeletons, Kumar McMillan compartilha algumas ideias e técnicas sobre como simular listas dinâmicas, texto e a tela final, bem como considerar o pensamento de esqueleto com o React.
Cuidado, porém: as telas de esqueleto devem ser testadas antes da implantação, pois alguns testes mostraram que as telas de esqueleto podem ter o pior desempenho em todas as métricas.
- Você evita mudanças de layout e repinturas?
No domínio do desempenho percebido, provavelmente uma das experiências mais disruptivas é a mudança de layout , ou refluxo , causada por imagens e vídeos redimensionados, fontes da Web, anúncios injetados ou scripts descobertos tardiamente que preenchem componentes com conteúdo real. Como resultado, um cliente pode começar a ler um artigo apenas para ser interrompido por um salto de layout acima da área de leitura. A experiência é muitas vezes abrupta e bastante desorientadora: e esse é provavelmente um caso de prioridades de carregamento que precisam ser reconsideradas.A comunidade desenvolveu algumas técnicas e soluções alternativas para evitar refluxos. Em geral, é uma boa ideia evitar a inserção de novo conteúdo acima do conteúdo existente , a menos que isso aconteça em resposta a uma interação do usuário. Sempre defina os atributos de largura e altura nas imagens, para que os navegadores modernos atribuam a caixa e reservem o espaço por padrão (Firefox, Chrome).
Tanto para imagens quanto para vídeos, podemos usar um espaço reservado SVG para reservar a caixa de exibição na qual a mídia aparecerá. Isso significa que a área será reservada adequadamente quando você precisar manter sua proporção também. Também podemos usar marcadores de posição ou imagens substitutas para anúncios e conteúdo dinâmico, bem como pré-alocar espaços de layout.
Em vez de imagens de carregamento lento com scripts externos, considere usar carregamento lento nativo ou carregamento lento híbrido quando carregarmos um script externo somente se o carregamento lento nativo não for suportado.
Como mencionado acima, sempre agrupe repinturas de fontes da Web e faça a transição de todas as fontes de fallback para todas as fontes da Web de uma só vez - apenas certifique-se de que essa mudança não seja muito abrupta, ajustando a altura da linha e o espaçamento entre as fontes com o font-style-matcher .
Para substituir as métricas de fonte de uma fonte substituta para emular uma fonte da Web, podemos usar os descritores @font-face para substituir as métricas de fonte (demo, ativado no Chrome 87). (Observe que os ajustes são complicados com pilhas de fontes complicadas.)
Para CSS tardio, podemos garantir que o CSS de layout crítico seja embutido no cabeçalho de cada modelo. Além disso: para páginas longas, quando a barra de rolagem vertical é adicionada, ela desloca o conteúdo principal 16px para a esquerda. Para exibir uma barra de rolagem antecipadamente, podemos adicionar
overflow-y: scrollonhtmlpara impor uma barra de rolagem na primeira pintura. O último ajuda porque as barras de rolagem podem causar mudanças de layout não triviais devido ao refluxo do conteúdo acima da dobra quando a largura muda. Deve acontecer principalmente em plataformas com barras de rolagem sem sobreposição, como o Windows. Mas: breakposition: stickyporque esses elementos nunca rolarão para fora do contêiner.Se você lida com cabeçalhos que se tornam fixos ou fixos posicionados no topo da página na rolagem, reserve espaço para o cabeçalho quando ele se tornar pinado, por exemplo, com um elemento de espaço reservado ou
margin-topno conteúdo. Uma exceção deve ser banners de consentimento de cookies que não devem ter impacto no CLS, mas às vezes eles têm: depende da implementação. Existem algumas estratégias e conclusões interessantes neste tópico do Twitter.Para um componente de guia que pode incluir várias quantidades de textos, você pode evitar mudanças de layout com pilhas de grade CSS. Ao colocar o conteúdo de cada guia na mesma área da grade e ocultar uma delas por vez, podemos garantir que o contêiner sempre tenha a altura do elemento maior, para que não ocorram mudanças de layout.
Ah, e claro, rolagem infinita e "Carregar mais" também podem causar mudanças de layout se houver conteúdo abaixo da lista (por exemplo, rodapé). Para melhorar o CLS, reserve espaço suficiente para o conteúdo que seria carregado antes que o usuário role para essa parte da página, remova o rodapé ou qualquer elemento DOM na parte inferior da página que possa ser empurrado para baixo pelo carregamento do conteúdo. Além disso, pré-buscar dados e imagens para conteúdo abaixo da dobra para que, quando um usuário rolar até esse ponto, ele já esteja lá. Você pode usar bibliotecas de virtualização de listas como react-window para otimizar listas longas também ( obrigado, Addy Osmani! ).
Para garantir que o impacto dos refluxos seja contido, meça a estabilidade do layout com a Layout Instability API. Com ele, você pode calcular a pontuação Cumulative Layout Shift ( CLS ) e incluí-la como requisito em seus testes, assim sempre que uma regressão aparecer, você poderá rastreá-la e corrigi-la.
Para calcular a pontuação de mudança de layout, o navegador analisa o tamanho da janela de visualização e o movimento de elementos instáveis na janela de visualização entre dois quadros renderizados. Idealmente, a pontuação seria próxima de
0. Há um ótimo guia de Milica Mihajlija e Philip Walton sobre o que é o CLS e como medi-lo. É um bom ponto de partida para medir e manter o desempenho percebido e evitar interrupções, especialmente para tarefas críticas para os negócios.Dica rápida : para descobrir o que causou uma mudança de layout no DevTools, você pode explorar as mudanças de layout em "Experiência" no Painel de desempenho.
Bônus : se você deseja reduzir refluxos e repinturas, consulte o guia de Charis Theodoulou para Minimizing DOM Reflow/Layout Thrashing e a lista de Paul Irish de O que força layout/reflow, bem como CSSTriggers.com, uma tabela de referência sobre propriedades CSS que acionam layout, pintura e composição.
Rede e HTTP/2
- O grampeamento OCSP está ativado?
Ao habilitar o grampeamento OCSP em seu servidor, você pode acelerar seus handshakes TLS. O Online Certificate Status Protocol (OCSP) foi criado como uma alternativa ao protocolo Certificate Revocation List (CRL). Ambos os protocolos são usados para verificar se um certificado SSL foi revogado.No entanto, o protocolo OCSP não exige que o navegador gaste tempo baixando e pesquisando uma lista de informações de certificado, reduzindo assim o tempo necessário para um handshake.
- Você reduziu o impacto da revogação do certificado SSL?
Em seu artigo sobre "O custo de desempenho dos certificados EV", Simon Hearne fornece uma ótima visão geral dos certificados comuns e o impacto que a escolha de um certificado pode ter no desempenho geral.Como Simon escreve, no mundo do HTTPS, existem alguns tipos de níveis de validação de certificado usados para proteger o tráfego:
- A Validação de Domínio (DV) valida se o solicitante do certificado possui o domínio,
- A Validação da Organização (OV) valida que uma organização possui o domínio,
- A Validação Estendida (EV) valida que uma organização possui o domínio, com validação rigorosa.
É importante observar que todos esses certificados são iguais em termos de tecnologia; eles diferem apenas nas informações e propriedades fornecidas nesses certificados.
Os certificados EV são caros e demorados , pois exigem que um humano revise um certificado e garanta sua validade. Os certificados DV, por outro lado, geralmente são fornecidos gratuitamente — por exemplo, pela Let's Encrypt — uma autoridade de certificação aberta e automatizada que está bem integrada a muitos provedores de hospedagem e CDNs. De fato, no momento da redação deste artigo, ele alimenta mais de 225 milhões de sites (PDF), embora represente apenas 2,69% das páginas (abertas no Firefox).
Então qual é o problema? O problema é que os certificados EV não suportam totalmente o grampeamento OCSP mencionado acima. Enquanto o grampeamento permite que o servidor verifique com a Autoridade de Certificação se o certificado foi revogado e então adicione ("grampeie") essa informação ao certificado, sem grampear o cliente tem que fazer todo o trabalho, resultando em solicitações desnecessárias durante a negociação TLS . Em conexões ruins, isso pode resultar em custos de desempenho perceptíveis (1000ms+).
Os certificados EV não são uma ótima opção para desempenho na Web e podem causar um impacto muito maior no desempenho do que os certificados DV. Para um desempenho ideal na Web, sempre forneça um certificado DV grampeado OCSP. Eles também são muito mais baratos que os certificados EV e menos incômodos para adquirir. Bem, pelo menos até que o CRLite esteja disponível.
A compactação é importante: 40 a 43% das cadeias de certificados não compactadas são muito grandes para caber em um único voo QUIC de 3 datagramas UDP. (Crédito da imagem:) Fastly) (Visualização grande) Nota : Com o QUIC/HTTP/3 sobre nós, vale a pena notar que a cadeia de certificados TLS é o conteúdo de tamanho variável que domina a contagem de bytes no QUIC Handshake. O tamanho varia entre algumas centenas de byes e mais de 10 KB.
Portanto, manter os certificados TLS pequenos é muito importante no QUIC/HTTP/3, pois certificados grandes causarão vários handshakes. Além disso, precisamos garantir que os certificados sejam compactados, caso contrário, as cadeias de certificados seriam muito grandes para caber em um único voo QUIC.
Você pode encontrar muito mais detalhes e indicadores para o problema e as soluções em:
- Certificados EV tornam a Web lenta e não confiável por Aaron Peters,
- O impacto da revogação do certificado SSL no desempenho da Web por Matt Hobbs,
- O custo de desempenho dos certificados EV por Simon Hearne,
- O handshake QUIC exige que a compactação seja rápida? por Patrick McManus.
- Você já adotou o IPv6?
Como estamos ficando sem espaço com o IPv4 e as principais redes móveis estão adotando o IPv6 rapidamente (os EUA quase atingiram um limite de adoção de 50% do IPv6), é uma boa ideia atualizar seu DNS para IPv6 para ficar à prova de balas para o futuro. Apenas certifique-se de que o suporte de pilha dupla seja fornecido em toda a rede - ele permite que o IPv6 e o IPv4 sejam executados simultaneamente um ao lado do outro. Afinal, o IPv6 não é compatível com versões anteriores. Além disso, estudos mostram que o IPv6 tornou esses sites 10 a 15% mais rápidos devido à descoberta de vizinhos (NDP) e à otimização de rotas. - Certifique-se de que todos os ativos sejam executados em HTTP/2 (ou HTTP/3).
Com o Google buscando uma web HTTPS mais segura nos últimos anos, uma mudança para o ambiente HTTP/2 é definitivamente um bom investimento. De fato, de acordo com o Web Almanac, 64% de todas as solicitações já estão sendo executadas em HTTP/2.É importante entender que o HTTP/2 não é perfeito e tem problemas de priorização, mas é muito bem suportado; e, na maioria dos casos, você está melhor com isso.
Uma palavra de cautela: o HTTP/2 Server Push está sendo removido do Chrome, portanto, se sua implementação depender do Server Push, talvez seja necessário revisitá-lo. Em vez disso, podemos estar olhando para as dicas iniciais, que já estão integradas como experimentos no Fastly.
Se você ainda estiver executando em HTTP, a tarefa mais demorada será migrar primeiro para HTTPS e, em seguida, ajustar seu processo de compilação para atender à multiplexação e paralelização HTTP/2. Trazer HTTP/2 para Gov.uk é um estudo de caso fantástico sobre como fazer exatamente isso, encontrando um caminho através de CORS, SRI e WPT ao longo do caminho. Para o restante deste artigo, presumimos que você está mudando ou já mudou para HTTP/2.
- Implante corretamente o HTTP/2.
Novamente, servir ativos por HTTP/2 pode se beneficiar de uma revisão parcial de como você tem servido ativos até agora. Você precisará encontrar um bom equilíbrio entre os módulos de empacotamento e o carregamento de muitos módulos pequenos em paralelo. No final das contas, a melhor solicitação ainda é nenhuma solicitação, no entanto, o objetivo é encontrar um bom equilíbrio entre a primeira entrega rápida de ativos e o armazenamento em cache.Por um lado, você pode querer evitar a concatenação de ativos completamente, em vez de dividir sua interface inteira em vários módulos pequenos, compactando-os como parte do processo de compilação e carregando-os em paralelo. Uma alteração em um arquivo não exigirá que toda a folha de estilo ou JavaScript seja baixado novamente. Também minimiza o tempo de análise e mantém baixas as cargas úteis de páginas individuais.
Por outro lado, a embalagem ainda importa. Ao usar muitos scripts pequenos, a compactação geral sofrerá e o custo de recuperar objetos do cache aumentará. A compactação de um pacote grande se beneficiará da reutilização do dicionário, enquanto pequenos pacotes separados não. Há um trabalho padrão para resolver isso, mas está longe por enquanto. Em segundo lugar, os navegadores ainda não foram otimizados para esses fluxos de trabalho. Por exemplo, o Chrome acionará comunicações entre processos (IPCs) lineares ao número de recursos, portanto, incluir centenas de recursos terá custos de tempo de execução do navegador.
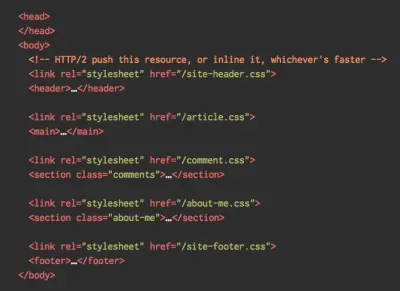
Para obter melhores resultados com HTTP/2, considere carregar CSS progressivamente, conforme sugerido por Jake Archibald do Chrome. Ainda assim, você pode tentar carregar CSS progressivamente. Na verdade, o CSS interno não bloqueia mais a renderização do Chrome. Mas existem alguns problemas de priorização, por isso não é tão simples, mas vale a pena experimentar.
Você pode se safar com a união de conexão HTTP/2, que permite usar fragmentação de domínio enquanto se beneficia do HTTP/2, mas conseguir isso na prática é difícil e, em geral, não é considerado uma boa prática. Além disso, HTTP/2 e integridade de sub-recurso nem sempre funcionam.
O que fazer? Bem, se você estiver executando em HTTP/2, enviar cerca de 6 a 10 pacotes parece um compromisso decente (e não é tão ruim para navegadores legados). Experimente e meça para encontrar o equilíbrio certo para o seu site.
- Enviamos todos os ativos em uma única conexão HTTP/2?
Uma das principais vantagens do HTTP/2 é que ele nos permite enviar ativos pela rede em uma única conexão. No entanto, às vezes podemos ter feito algo errado - por exemplo, ter um problema de CORS ou configurar incorretamente o atributocrossorigin, de modo que o navegador seria forçado a abrir uma nova conexão.Para verificar se todas as requisições usam uma única conexão HTTP/2, ou algo está mal configurado, habilite a coluna "Connection ID" em DevTools → Network. Por exemplo, aqui, todas as solicitações compartilham a mesma conexão (286) — exceto manifest.json, que abre uma conexão separada (451).
- Seus servidores e CDNs suportam HTTP/2?
Diferentes servidores e CDNs (ainda) suportam HTTP/2 de forma diferente. Use a Comparação de CDN para verificar suas opções ou veja rapidamente o desempenho de seus servidores e quais recursos você espera que sejam suportados.Consulte a incrível pesquisa de Pat Meenan sobre prioridades HTTP/2 (vídeo) e teste o suporte do servidor para priorização HTTP/2. De acordo com Pat, é recomendado habilitar o controle de congestionamento BBR e definir
tcp_notsent_lowatpara 16KB para que a priorização HTTP/2 funcione de forma confiável em kernels Linux 4.9 e posteriores ( obrigado, Yoav! ). Andy Davies fez uma pesquisa semelhante para priorização de HTTP/2 em navegadores, CDNs e serviços de hospedagem em nuvem.Enquanto estiver nele, verifique se seu kernel suporta TCP BBR e habilite-o se possível. Atualmente, é usado no Google Cloud Platform, Amazon Cloudfront, Linux (por exemplo, Ubuntu).
- A compactação HPACK está em uso?
Se você estiver usando HTTP/2, verifique novamente se seus servidores implementam a compactação HPACK para cabeçalhos de resposta HTTP para reduzir a sobrecarga desnecessária. Alguns servidores HTTP/2 podem não suportar totalmente a especificação, sendo o HPACK um exemplo. O H2spec é uma ótima ferramenta (embora muito detalhada tecnicamente) para verificar isso. O algoritmo de compressão do HPACK é bastante impressionante e funciona. - Certifique-se de que a segurança do seu servidor seja à prova de balas.
Todas as implementações do HTTP/2 no navegador são executadas em TLS, portanto, você provavelmente desejará evitar avisos de segurança ou alguns elementos em sua página que não funcionem. Verifique novamente se seus cabeçalhos de segurança estão configurados corretamente, elimine vulnerabilidades conhecidas e verifique sua configuração HTTPS.Além disso, certifique-se de que todos os plug-ins externos e scripts de rastreamento sejam carregados via HTTPS, que scripts entre sites não sejam possíveis e que os cabeçalhos HTTP Strict Transport Security e Content Security Policy estejam configurados corretamente.
- Seus servidores e CDNs suportam HTTP/3?
Embora o HTTP/2 tenha trazido uma série de melhorias significativas de desempenho para a web, também deixou bastante área para melhorias - especialmente o bloqueio de cabeçalho de linha no TCP, que era perceptível em uma rede lenta com uma perda significativa de pacotes. O HTTP/3 está resolvendo esses problemas definitivamente (artigo).Para resolver problemas de HTTP/2, o IETF, juntamente com Google, Akamai e outros, estão trabalhando em um novo protocolo que foi recentemente padronizado como HTTP/3.
Robin Marx explicou o HTTP/3 muito bem, e a explicação a seguir é baseada em sua explicação. Em seu núcleo, o HTTP/3 é muito semelhante ao HTTP/2 em termos de recursos, mas nos bastidores funciona de maneira muito diferente. O HTTP/3 oferece várias melhorias: handshakes mais rápidos, melhor criptografia, fluxos independentes mais confiáveis, melhor criptografia e controle de fluxo. Uma diferença notável é que HTTP/3 usa QUIC como camada de transporte, com pacotes QUIC encapsulados em diagramas UDP, em vez de TCP.
O QUIC integra totalmente o TLS 1.3 no protocolo, enquanto no TCP ele está em camadas. Na pilha TCP típica, temos alguns tempos de sobrecarga de ida e volta porque o TCP e o TLS precisam fazer seus próprios handshakes separados, mas com o QUIC ambos podem ser combinados e concluídos em apenas uma única viagem de ida e volta . Como o TLS 1.3 permite configurar chaves de criptografia para uma conexão consequente, a partir da segunda conexão já podemos enviar e receber dados da camada de aplicação na primeira ida e volta, que é chamada de "0-RTT".
Além disso, o algoritmo de compressão de cabeçalho do HTTP/2 foi totalmente reescrito, juntamente com seu sistema de priorização. Além disso, o QUIC suporta migração de conexão de Wi-Fi para rede celular por meio de IDs de conexão no cabeçalho de cada pacote QUIC. A maioria das implementações é feita no espaço do usuário, não no espaço do kernel (como é feito com o TCP), então devemos esperar que o protocolo evolua no futuro.
Tudo faria uma grande diferença? Provavelmente sim, especialmente tendo um impacto nos tempos de carregamento em dispositivos móveis, mas também em como servimos ativos para usuários finais. Enquanto no HTTP/2, várias solicitações compartilham uma conexão, em HTTP/3 as solicitações também compartilham uma conexão, mas transmitem independentemente, portanto, um pacote descartado não afeta mais todas as solicitações, apenas um fluxo.
Isso significa que, embora com um grande pacote JavaScript o processamento de ativos seja desacelerado quando um fluxo pausar, o impacto será menos significativo quando vários arquivos forem transmitidos em paralelo (HTTP/3). Portanto , a embalagem ainda importa .
O HTTP/3 ainda está em andamento. Chrome, Firefox e Safari já têm implementações. Alguns CDNs já suportam QUIC e HTTP/3. No final de 2020, o Chrome começou a implantar HTTP/3 e IETF QUIC e, de fato, todos os serviços do Google (Google Analytics, YouTube etc.) já estão sendo executados em HTTP/3. LiteSpeed Web Server suporta HTTP/3, mas nem Apache, nginx ou IIS suportam ainda, mas é provável que mude rapidamente em 2021.
Conclusão : se você tiver a opção de usar HTTP/3 no servidor e em seu CDN, provavelmente é uma boa ideia fazê-lo. O principal benefício virá da busca de vários objetos simultaneamente, especialmente em conexões de alta latência. Ainda não sabemos ao certo, pois não há muita pesquisa feita nesse espaço, mas os primeiros resultados são muito promissores.
Se você quiser se aprofundar mais nas especificidades e vantagens do protocolo, aqui estão alguns bons pontos de partida a serem verificados:
- HTTP/3 Explained, um esforço colaborativo para documentar os protocolos HTTP/3 e QUIC. Disponível em vários idiomas, também em PDF.
- Nivelando o desempenho da Web com HTTP/3 com Daniel Stenberg.
- Um Guia Acadêmico para QUIC com Robin Marx apresenta conceitos básicos dos protocolos QUIC e HTTP/3, explica como HTTP/3 lida com bloqueio de cabeçalho e migração de conexão e como HTTP/3 é projetado para ser perene (obrigado, Simon !).
- Você pode verificar se seu servidor está rodando em HTTP/3 em HTTP3Check.net.
Teste e monitoramento
- Você otimizou seu fluxo de trabalho de auditoria?
Pode não parecer grande coisa, mas ter as configurações corretas na ponta dos dedos pode economizar bastante tempo nos testes. Considere usar o Alfred Workflow de Tim Kadlec para WebPageTest para enviar um teste para a instância pública de WebPageTest. Na verdade, o WebPageTest tem muitos recursos obscuros, então reserve um tempo para aprender a ler um gráfico WebPageTest Waterfall View e como ler um gráfico WebPageTest Connection View para diagnosticar e resolver problemas de desempenho mais rapidamente.Você também pode conduzir o WebPageTest a partir de uma planilha do Google e incorporar pontuações de acessibilidade, desempenho e SEO em sua configuração do Travis com o Lighthouse CI ou diretamente no Webpack.
Dê uma olhada no recém-lançado AutoWebPerf, uma ferramenta modular que permite a coleta automática de dados de desempenho de várias fontes. Por exemplo, poderíamos definir um teste diário em suas páginas críticas para capturar os dados de campo da API CrUX e dados de laboratório de um relatório do Lighthouse do PageSpeed Insights.
E se você precisar depurar algo rapidamente, mas seu processo de compilação parecer extremamente lento, lembre-se de que "a remoção de espaços em branco e a destruição de símbolos são responsáveis por 95% da redução de tamanho no código minificado para a maioria dos JavaScript - não em transformações de código elaboradas. Você pode simplesmente desative a compactação para acelerar as compilações do Uglify em 3 a 4 vezes."
- Você testou em navegadores proxy e navegadores legados?
Testar no Chrome e Firefox não é suficiente. Veja como seu site funciona em navegadores proxy e navegadores legados. O UC Browser e o Opera Mini, por exemplo, têm uma participação de mercado significativa na Ásia (até 35% na Ásia). Meça a velocidade média da Internet em seus países de interesse para evitar grandes surpresas no futuro. Teste com limitação de rede e emule um dispositivo de alto DPI. O BrowserStack é fantástico para testar em dispositivos reais remotos e complementá-lo com pelo menos alguns dispositivos reais em seu escritório – vale a pena.
- Você testou o desempenho de suas páginas 404?
Normalmente não pensamos duas vezes quando se trata de 404 páginas. Afinal, quando um cliente solicita uma página que não existe no servidor, o servidor responderá com um código de status 404 e a página 404 associada. Não há muito para isso, não é?Um aspecto importante das respostas 404 é o tamanho real do corpo da resposta que está sendo enviada ao navegador. De acordo com a pesquisa de 404 páginas de Matt Hobbs, a grande maioria das 404 respostas são provenientes de favicons ausentes, solicitações de upload do WordPress, solicitações JavaScript quebradas, arquivos de manifesto, bem como arquivos CSS e de fonte. Toda vez que um cliente solicita um ativo que não existe, ele recebe uma resposta 404 – e geralmente essa resposta é enorme.
Certifique-se de examinar e otimizar a estratégia de cache para suas páginas 404. Nosso objetivo é fornecer HTML ao navegador somente quando ele espera uma resposta HTML e retornar uma pequena carga útil de erro para todas as outras respostas. De acordo com Matt, "se colocarmos um CDN na frente de nossa origem, temos a chance de armazenar em cache a resposta de 404 páginas no CDN. Isso é útil porque sem ele, atingir uma página 404 poderia ser usado como um vetor de ataque DoS, por forçando o servidor de origem a responder a cada solicitação 404 em vez de deixar o CDN responder com uma versão em cache."
Os erros 404 não apenas podem prejudicar seu desempenho, mas também podem custar em tráfego, portanto, é uma boa ideia incluir uma página de erro 404 em seu conjunto de testes do Lighthouse e acompanhar sua pontuação ao longo do tempo.
- Você testou o desempenho de suas solicitações de consentimento do GDPR?
Em tempos de GDPR e CCPA, tornou-se comum depender de terceiros para fornecer opções para os clientes da UE optarem ou não pelo rastreamento. No entanto, como acontece com qualquer outro script de terceiros, seu desempenho pode ter um impacto bastante devastador em todo o esforço de desempenho.É claro que o consentimento real provavelmente alterará o impacto dos scripts no desempenho geral, portanto, como Boris Schapira observou, podemos estudar alguns perfis de desempenho da Web diferentes:
- O consentimento foi totalmente recusado,
- O consentimento foi parcialmente recusado,
- O consentimento foi inteiramente dado.
- O usuário não agiu no prompt de consentimento (ou o prompt foi bloqueado por um bloqueador de conteúdo),
Normalmente, os prompts de consentimento de cookies não devem ter impacto no CLS, mas às vezes têm, portanto, considere usar as opções gratuitas e de código aberto Osano ou cookie-consent-box.
Em geral, vale a pena examinar o desempenho do pop-up, pois você precisará determinar o deslocamento horizontal ou vertical do evento do mouse e posicionar corretamente o pop-up em relação à âncora. Noam Rosenthal compartilha os aprendizados da equipe da Wikimedia no artigo Estudo de caso de desempenho na Web: visualizações da página da Wikipedia (também disponível como vídeo e minutos).
- Você mantém um CSS de diagnóstico de desempenho?
Embora possamos incluir todos os tipos de verificações para garantir que o código com baixo desempenho seja implantado, geralmente é útil ter uma ideia rápida de alguns dos frutos mais fáceis que podem ser resolvidos facilmente. Para isso, poderíamos usar o brilhante Performance Diagnostics CSS de Tim Kadlec (inspirado no trecho de Harry Roberts, que destaca imagens de carregamento lento, imagens sem tamanho, imagens de formato herdado e scripts síncronos.Por exemplo, você pode querer garantir que nenhuma imagem acima da dobra seja carregada lentamente. Você pode personalizar o snippet para suas necessidades, por exemplo, para destacar fontes da web que não são usadas ou detectar fontes de ícone. Uma ótima ferramenta para garantir que os erros sejam visíveis durante a depuração ou apenas para auditar o projeto atual muito rapidamente.
/* Performance Diagnostics CSS */ /* via Harry Roberts. https://twitter.com/csswizardry/status/1346477682544951296 */ img[loading=lazy] { outline: 10px solid red; }
- Você testou o impacto na acessibilidade?
Quando o navegador começa a carregar uma página, ele cria um DOM e, se houver uma tecnologia assistiva, como um leitor de tela em execução, também cria uma árvore de acessibilidade. O leitor de tela então precisa consultar a árvore de acessibilidade para recuperar as informações e disponibilizá-las ao usuário – às vezes por padrão e às vezes sob demanda. E às vezes leva tempo.Quando falamos de tempo rápido para interativo, geralmente queremos dizer um indicador de quanto tempo um usuário pode interagir com a página clicando ou tocando em links e botões. O contexto é um pouco diferente com leitores de tela. Nesse caso, Tempo rápido para interativo significa quanto tempo passa até que o leitor de tela possa anunciar a navegação em uma determinada página e um usuário do leitor de tela possa realmente pressionar o teclado para interagir.
Leonie Watson deu uma palestra reveladora sobre o desempenho da acessibilidade e, especificamente, o impacto que o carregamento lento tem nos atrasos dos anúncios do leitor de tela. Os leitores de tela estão acostumados a anúncios em ritmo acelerado e navegação rápida e, portanto, podem ser ainda menos pacientes do que os usuários com visão.
Páginas grandes e manipulações de DOM com JavaScript causarão atrasos nos anúncios do leitor de tela. Uma área bastante inexplorada que poderia precisar de alguma atenção e testes, pois os leitores de tela estão disponíveis em literalmente todas as plataformas (Tubarão, NVDA, Voiceover, Narrator, Orca).
- O monitoramento contínuo está configurado?
Ter uma instância privada do WebPagetest é sempre benéfico para testes rápidos e ilimitados. No entanto, uma ferramenta de monitoramento contínuo - como Sitespeed, Caliber e SpeedCurve - com alertas automáticos fornecerá uma imagem mais detalhada do seu desempenho. Defina suas próprias marcas de tempo do usuário para medir e monitorar métricas específicas de negócios. Além disso, considere adicionar alertas de regressão de desempenho automatizados para monitorar as alterações ao longo do tempo.Procure usar soluções RUM para monitorar mudanças no desempenho ao longo do tempo. Para ferramentas automatizadas de teste de carga semelhantes a testes de unidade, você pode usar o k6 com sua API de script. Além disso, olhe para SpeedTracker, Lighthouse e Calibre.
Vitórias rápidas
Esta lista é bastante abrangente e concluir todas as otimizações pode demorar um pouco. Então, se você tivesse apenas 1 hora para obter melhorias significativas, o que você faria? Vamos resumir tudo em 17 frutas fáceis . Obviamente, antes de começar e depois de terminar, meça os resultados, incluindo a maior pintura com conteúdo e o tempo de interação em uma conexão 3G e a cabo.
- Meça a experiência do mundo real e estabeleça metas apropriadas. Procure ser pelo menos 20% mais rápido que seu concorrente mais rápido. Permaneça dentro do maior índice de conteúdo < 2,5 s, um atraso na primeira entrada < 100 ms, tempo para interação < 5 s em 3G lento, para visitas repetidas, TTI < 2 s. Otimize pelo menos para a primeira pintura de conteúdo e o tempo para interação.
- Otimize imagens com Squoosh, mozjpeg, guetzli, pingo e SVGOMG e sirva AVIF/WebP com um CDN de imagem.
- Prepare o CSS crítico para seus templates principais e insira-os no
<head>de cada template. Para CSS/JS, opere dentro de um orçamento de tamanho de arquivo crítico de máx. 170 KB compactados (0,7 MB descompactados). - Aparar, otimizar, adiar e carregar scripts com preguiça. Invista na configuração do seu bundler para remover redundâncias e verificar alternativas leves.
- Sempre auto-hospede seus ativos estáticos e sempre prefira auto-hospedar ativos de terceiros. Limite o impacto de scripts de terceiros. Use fachadas, carregue widgets na interação e cuidado com os snippets anti-flicker.
- Seja seletivo ao escolher uma estrutura. Para aplicativos de página única, identifique páginas críticas e veicule-as estaticamente, ou pelo menos pré-renderize-as e use hidratação progressiva no nível do componente e módulos de importação na interação.
- A renderização do lado do cliente por si só não é uma boa opção para desempenho. Pré-renderize se suas páginas não mudarem muito e adie a inicialização dos frameworks se puder. Se possível, use a renderização do lado do servidor de streaming.
- Exiba código legado apenas para navegadores legados com
<script type="module">e padrão de módulo/nomodule. - Experimente reagrupar suas regras de CSS e teste o CSS no corpo.
- Adicione dicas de recursos para acelerar a entrega com
dns-lookup,preconnect,prefetch,preloadeprerender. - Subconjunto de fontes da Web e carregue-as de forma assíncrona, e utilize
font-displayem CSS para uma primeira renderização rápida. - Verifique se os cabeçalhos de cache HTTP e os cabeçalhos de segurança estão definidos corretamente.
- Ative a compactação Brotli no servidor. (Se isso não for possível, pelo menos certifique-se de que a compactação Gzip esteja habilitada.)
- Habilite o congestionamento TCP BBR desde que seu servidor esteja rodando no kernel Linux versão 4.9+.
- Habilite o grampeamento OCSP e IPv6, se possível. Sempre forneça um certificado DV grampeado OCSP.
- Habilite a compactação HPACK para HTTP/2 e mova para HTTP/3 se estiver disponível.
- Ativos de cache, como fontes, estilos, JavaScript e imagens em um cache de service worker.
Baixe a lista de verificação (PDF, Páginas da Apple)
Com esta lista de verificação em mente, você deve estar preparado para qualquer tipo de projeto de desempenho de front-end. Sinta-se à vontade para baixar o PDF pronto para impressão da lista de verificação, bem como um documento editável do Apple Pages para personalizar a lista de verificação de acordo com suas necessidades:
- Baixe o PDF da lista de verificação (PDF, 166 KB)
- Baixe a lista de verificação no Apple Pages (.pages, 275 KB)
- Baixe a lista de verificação em MS Word (.docx, 151 KB)
Se você precisar de alternativas, também pode verificar a lista de verificação de front-end de Dan Rublic, a "Lista de verificação de desempenho da Web do designer" de Jon Yablonski e a lista de verificação de frontend.
Lá vamos nós!
Algumas das otimizações podem estar além do escopo do seu trabalho ou orçamento ou podem ser um exagero devido ao código legado com o qual você precisa lidar. Isso é bom! Use esta lista de verificação como um guia geral (e esperançosamente abrangente) e crie sua própria lista de questões que se aplicam ao seu contexto. Mas o mais importante é testar e medir seus próprios projetos para identificar problemas antes de otimizar. Felizes resultados de desempenho em 2021, pessoal!
Um grande obrigado a Guy Podjarny, Yoav Weiss, Addy Osmani, Artem Denysov, Denys Mishunov, Ilya Pukhalski, Jeremy Wagner, Colin Bendell, Mark Zeman, Patrick Meenan, Leonardo Losoviz, Andy Davies, Rachel Andrew, Anselm Hannemann, Barry Pollard, Patrick Hamann, Gideon Pyzer, Andy Davies, Maria Prosvernina, Tim Kadlec, Rey Bango, Matthias Ott, Peter Bowyer, Phil Walton, Mariana Peralta, Pepijn Senders, Mark Nottingham, Jean Pierre Vincent, Philipp Tellis, Ryan Townsend, Ingrid Bergman, Mohamed Hussain SH, Jacob Groß, Tim Swalling, Bob Visser, Kev Adamson, Adir Amsalem, Aleksey Kulikov e Rodney Rehm por revisarem este artigo, bem como nossa fantástica comunidade que compartilhou técnicas e lições aprendidas com seu trabalho de otimização de desempenho para todos usarem . Você está realmente arrasando!