
Testes esquisitos: Livrando-se de um pesadelo vivo em testes
Publicados: 2022-03-10Há uma fábula que penso muito nestes dias. A fábula me foi contada quando criança. Chama-se "O menino que gritou lobo" por Esopo. É sobre um menino que cuida das ovelhas de sua aldeia. Ele fica entediado e finge que um lobo está atacando o rebanho, pedindo ajuda aos aldeões - apenas para eles perceberem, desapontados, que é um alarme falso e deixarem o menino em paz. Então, quando um lobo realmente aparece e o menino pede ajuda, os moradores acreditam que é mais um alarme falso e não vêm em socorro, e as ovelhas acabam sendo comidas pelo lobo.
A moral da história é melhor resumida pelo próprio autor:
“Um mentiroso não será acreditado, mesmo quando ele fala a verdade.”
Um lobo ataca a ovelha, e o menino grita por socorro, mas depois de inúmeras mentiras, ninguém mais acredita nele. Essa moral pode ser aplicada aos testes: a história de Esopo é uma bela alegoria para um padrão de correspondência que encontrei: testes esquisitos que não fornecem qualquer valor.
Testes front-end: por que se preocupar?
A maior parte dos meus dias são gastos em testes front-end. Portanto, não deve surpreendê-lo que os exemplos de código neste artigo sejam principalmente dos testes de front-end que encontrei em meu trabalho. No entanto, na maioria dos casos, eles podem ser facilmente traduzidos para outros idiomas e aplicados a outros frameworks. Então, espero que o artigo seja útil para você – qualquer que seja o conhecimento que você possa ter.
Vale a pena lembrar o que significa teste de front-end. Em sua essência, o teste de front-end é um conjunto de práticas para testar a interface do usuário de um aplicativo da Web, incluindo sua funcionalidade.
Começando como engenheiro de garantia de qualidade, conheço a dor de testes manuais intermináveis a partir de uma lista de verificação logo antes de um lançamento. Portanto, além do objetivo de garantir que um aplicativo permaneça livre de erros durante sucessivas atualizações, eu me esforcei para aliviar a carga de trabalho de testes causada por aquelas tarefas rotineiras para as quais você não precisa de um humano. Agora, como desenvolvedor, acho o tópico ainda relevante, especialmente porque tento ajudar diretamente usuários e colegas de trabalho. E há um problema com os testes em particular que nos deu pesadelos.
A ciência dos testes escamosos
Um teste escamoso é aquele que não produz o mesmo resultado toda vez que a mesma análise é executada. A compilação falhará apenas ocasionalmente: uma vez passará, outra falhará, a próxima vez passará novamente, sem que nenhuma alteração na compilação tenha sido feita.
Quando me lembro dos meus pesadelos de teste, um caso em particular me vem à mente. Foi em um teste de interface do usuário. Construímos uma caixa de combinação de estilo personalizado (ou seja, uma lista selecionável com campo de entrada):
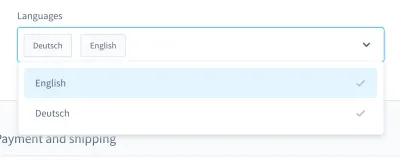
Com esta caixa de combinação, você pode pesquisar um produto e selecionar um ou mais resultados. Muitos dias, este teste correu bem, mas em algum momento, as coisas mudaram. Em uma das aproximadamente dez compilações em nosso sistema de integração contínua (CI), o teste para pesquisar e selecionar um produto nesta caixa de combinação falhou.
A captura de tela da falha mostra que a lista de resultados não está sendo filtrada, apesar da pesquisa ter sido bem-sucedida:
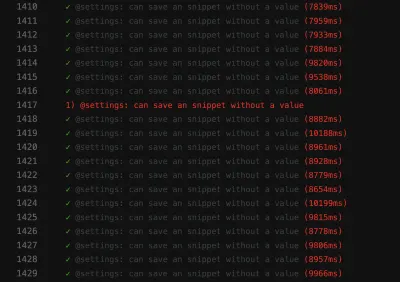
Um teste irregular como esse pode bloquear o pipeline de implantação contínua , tornando a entrega de recursos mais lenta do que o necessário. Além disso, um teste esquisito é problemático porque não é mais determinista – tornando-o inútil. Afinal, você não confiaria em um mais do que confiaria em um mentiroso.
Além disso, os testes flaky são caros para reparar , geralmente exigindo horas ou até dias para depurar. Embora os testes de ponta a ponta sejam mais propensos a serem esquisitos, eu os experimentei em todos os tipos de testes: testes de unidade, testes funcionais, testes de ponta a ponta e tudo mais.
Outro problema significativo com testes esquisitos é a atitude que eles imbuem em nós, desenvolvedores. Quando comecei a trabalhar na automação de testes, muitas vezes ouvia os desenvolvedores dizerem isso em resposta a um teste com falha:
“Ah, essa construção. Não importa, apenas comece novamente. Isso eventualmente passará, em algum momento.”
Esta é uma grande bandeira vermelha para mim . Isso me mostra que o erro na compilação não será levado a sério. Há uma suposição de que um teste flaky não é um bug real, mas é “apenas” flaky, sem precisar ser cuidado ou mesmo depurado. O teste vai passar novamente mais tarde de qualquer maneira, certo? Não! Se tal commit for mesclado, na pior das hipóteses teremos um novo flaky test no produto.
As causas
Portanto, testes escamosos são problemáticos. O que devemos fazer com eles? Bem, se conhecemos o problema, podemos desenhar uma contra-estratégia.
Muitas vezes encontro causas na vida cotidiana. Eles podem ser encontrados nos próprios testes . Os testes podem ser escritos de forma inadequada, conter suposições erradas ou conter práticas ruins. No entanto, não só isso. Testes irregulares podem ser uma indicação de algo muito pior.
Nas seções a seguir, veremos os mais comuns que encontrei.
1. Causas do lado do teste
Em um mundo ideal, o estado inicial de seu aplicativo deve ser impecável e 100% previsível. Na realidade, você nunca sabe se o ID usado em seu teste será sempre o mesmo.
Vamos inspecionar dois exemplos de uma única falha de minha parte. O erro número um foi usar um ID nos meus equipamentos de teste:
{ "id": "f1d2554b0ce847cd82f3ac9bd1c0dfca", "name": "Variant product", }O erro número dois foi procurar um seletor exclusivo para usar em um teste de interface do usuário e pensar: “Ok, esse ID parece único. Eu vou usar.”
<!-- This is a text field I took from a project I worked on --> <input type="text" />No entanto, se eu executasse o teste em outra instalação ou, posteriormente, em várias compilações no CI, esses testes poderiam falhar. Nosso aplicativo geraria os IDs novamente, alterando-os entre as compilações. Portanto, a primeira causa possível deve ser encontrada em IDs codificados .
A segunda causa pode surgir de dados de demonstração gerados aleatoriamente (ou não). Claro, você pode estar pensando que essa “falha” é justificada – afinal, a geração de dados é aleatória – mas pense em depurar esses dados. Pode ser muito difícil ver se um bug está nos próprios testes ou nos dados de demonstração.
Em seguida, é uma causa do lado do teste com a qual lutei várias vezes: testes com dependências cruzadas . Alguns testes podem não ser executados de forma independente ou em ordem aleatória, o que é problemático. Além disso, testes anteriores podem interferir nos subsequentes. Esses cenários podem causar testes irregulares ao introduzir efeitos colaterais.
No entanto, não se esqueça de que os testes são sobre suposições desafiadoras. O que acontece se suas suposições são falhas para começar? Eu experimentei isso com frequência, sendo meu favorito suposições falhas sobre o tempo.
Um exemplo é o uso de tempos de espera imprecisos, especialmente em testes de IU — por exemplo, usando tempos de espera fixos . A linha a seguir foi retirada de um teste Nightwatch.js.
// Please never do that unless you have a very good reason! // Waits for 1 second browser.pause(1000);Outra suposição errada diz respeito ao próprio tempo. Certa vez, descobri que um teste PHPUnit esquisito estava falhando apenas em nossas compilações noturnas. Após alguma depuração, descobri que a mudança de horário entre ontem e hoje era a culpada. Outro bom exemplo são as falhas devido aos fusos horários .
As falsas suposições não param por aí. Também podemos ter suposições erradas sobre a ordem dos dados . Imagine uma grade ou lista contendo várias entradas com informações, como uma lista de moedas:
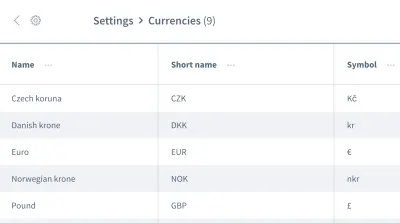
Queremos trabalhar com as informações da primeira entrada, a moeda “coroa tcheca”. Você pode ter certeza de que seu aplicativo sempre colocará esse dado como a primeira entrada toda vez que seu teste for executado? Será que o “Euro” ou outra moeda será a primeira entrada em algumas ocasiões?
Não assuma que seus dados virão na ordem em que você precisa. Semelhante a IDs codificados, um pedido pode mudar entre compilações, dependendo do design do aplicativo.
2. Causas do lado do meio ambiente
A próxima categoria de causas está relacionada a tudo fora de seus testes. Especificamente, estamos falando sobre o ambiente em que os testes são executados, as dependências relacionadas ao CI e ao docker fora de seus testes — todas essas coisas que você mal pode influenciar, pelo menos em sua função de testador.
Uma causa comum do lado do ambiente são vazamentos de recursos : muitas vezes, isso seria um aplicativo sob carga, causando tempos de carregamento variados ou comportamento inesperado. Testes grandes podem facilmente causar vazamentos, consumindo muita memória. Outro problema comum é a falta de limpeza .
A incompatibilidade entre dependências me dá pesadelos em particular. Um pesadelo ocorreu quando eu estava trabalhando com Nightwatch.js para testes de interface do usuário. Nightwatch.js usa WebDriver, que obviamente depende do Chrome. Quando o Chrome acelerou com uma atualização, houve um problema de compatibilidade: Chrome, WebDriver e Nightwatch.js não funcionavam mais juntos, o que fazia com que nossas compilações falhassem de tempos em tempos.
Falando em dependências : Uma menção honrosa vai para qualquer problema do npm, como permissões ausentes ou npm inativo. Eu experimentei tudo isso ao observar CI.
Quando se trata de erros em testes de interface do usuário devido a problemas ambientais, lembre-se de que você precisa de toda a pilha de aplicativos para que eles sejam executados. Quanto mais coisas estiverem envolvidas, maior o potencial de erro . Os testes JavaScript são, portanto, os testes mais difíceis de estabilizar no desenvolvimento web, pois cobrem uma grande quantidade de código.
3. Causas do lado do produto
Por último, mas não menos importante, temos que ter muito cuidado com essa terceira área – uma área com bugs reais. Estou falando sobre as causas de descamação do lado do produto. Um dos exemplos mais conhecidos são as condições de corrida em uma aplicação. Quando isso acontece, o bug precisa ser corrigido no produto, não no teste! Tentar consertar o teste ou o ambiente não terá utilidade neste caso.
Maneiras de combater a flacidez
Identificamos três causas de descamação. Podemos construir nossa contra-estratégia sobre isso! Claro, você já terá ganho muito mantendo as três causas em mente quando encontrar testes esquisitos. Você já saberá o que procurar e como melhorar os testes. No entanto, além disso, existem algumas estratégias que nos ajudarão a projetar, escrever e depurar testes, e vamos analisá-las juntas nas seções a seguir.
Concentre-se em sua equipe
Sua equipe é sem dúvida o fator mais importante . Como primeiro passo, admita que você tem um problema com testes esquisitos. Conseguir o comprometimento de toda a equipe é fundamental! Então, como equipe, você precisa decidir como lidar com testes esquisitos.
Durante os anos em que trabalhei em tecnologia, me deparei com quatro estratégias usadas pelas equipes para combater a flakiness:

- Não faça nada e aceite o resultado do teste escamoso.
É claro que essa estratégia não é uma solução. O teste não produzirá nenhum valor porque você não pode mais confiar nele – mesmo que aceite a falsidade. Assim, podemos pular este rapidamente. - Repita o teste até passar.
Essa estratégia era comum no início da minha carreira, resultando na resposta que mencionei anteriormente. Houve alguma aceitação com a repetição dos testes até que eles passassem. Essa estratégia não requer depuração, mas é preguiçosa. Além de esconder os sintomas do problema, vai deixar ainda mais lenta a sua suíte de testes, o que inviabiliza a solução. No entanto, pode haver algumas exceções a essa regra, que explicarei mais tarde. - Apague e esqueça o teste.
Este é auto-explicativo: simplesmente exclua o teste flaky, para que ele não atrapalhe mais seu conjunto de testes. Claro, você economizará dinheiro porque você não precisará mais depurar e corrigir o teste. Mas isso vem à custa de perder um pouco de cobertura de teste e perder possíveis correções de bugs. O teste existe por uma razão! Não atire no mensageiro excluindo o teste. - Quarentena e correção.
Eu tive o maior sucesso com esta estratégia. Nesse caso, pularíamos o teste temporariamente e faríamos com que o conjunto de testes nos lembrasse constantemente que um teste foi ignorado. Para garantir que a correção não seja esquecida, agendamos um ticket para o próximo sprint. Os lembretes de bot também funcionam bem. Assim que o problema que causa a falha for corrigido, vamos integrar (ou seja, desfazer pulo) o teste novamente. Infelizmente, perderemos a cobertura temporariamente, mas ela voltará com uma correção, portanto, isso não demorará muito.
Essas estratégias nos ajudam a lidar com problemas de teste no nível do fluxo de trabalho, e não sou o único que os encontrou. Em seu artigo, Sam Saffron chega a uma conclusão semelhante. Mas em nosso trabalho diário, eles nos ajudam de forma limitada. Então, como proceder quando tal tarefa vem em nosso caminho?
Mantenha os testes isolados
Ao planejar seus casos de teste e estrutura, sempre mantenha seus testes isolados de outros testes, para que possam ser executados em uma ordem independente ou aleatória. A etapa mais importante é restaurar uma instalação limpa entre os testes . Além disso, teste apenas o fluxo de trabalho que você deseja testar e crie dados simulados apenas para o teste em si. Outra vantagem desse atalho é que ele melhorará o desempenho do teste . Se você seguir esses pontos, nenhum efeito colateral de outros testes ou dados restantes ficarão no caminho.
O exemplo abaixo é retirado dos testes de UI de uma plataforma de e-commerce, e trata do login do cliente na vitrine da loja. (O teste é escrito em JavaScript, usando o framework Cypress.)
// File: customer-login.spec.js let customer = {}; beforeEach(() => { // Set application to clean state cy.setInitialState() .then(() => { // Create test data for the test specifically return cy.setFixture('customer'); }) }): A primeira etapa é redefinir o aplicativo para uma instalação limpa. Isso é feito como a primeira etapa no gancho do ciclo de vida beforeEach para garantir que a redefinição seja executada em todas as ocasiões. Depois, os dados de teste são criados especificamente para o teste — para este caso de teste, um cliente seria criado por meio de um comando personalizado. Posteriormente, podemos começar com o fluxo de trabalho que queremos testar: o login do cliente.
Otimize ainda mais a estrutura de teste
Podemos fazer alguns outros pequenos ajustes para tornar nossa estrutura de teste mais estável. A primeira é bem simples: comece com testes menores. Como dito antes, quanto mais você faz em um teste, mais pode dar errado. Mantenha os testes o mais simples possível e evite muita lógica em cada um.
Quando se trata de não assumir uma ordem de dados (por exemplo, ao lidar com a ordem das entradas em uma lista em testes de interface do usuário), podemos projetar um teste para funcionar independentemente de qualquer ordem. Para trazer de volta o exemplo da grade com informações, não usaríamos pseudo-seletores ou outro CSS que tenha uma forte dependência da ordem. Em vez do seletor nth-child(3) , poderíamos usar texto ou outras coisas para as quais a ordem não importa. Por exemplo, poderíamos usar uma afirmação como “Encontre-me o elemento com esta string de texto nesta tabela”.
Esperar! As tentativas de teste às vezes são boas?
Repetir testes é um tema controverso, e com razão. Ainda penso nisso como um antipadrão se o teste for repetido cegamente até ser bem-sucedido. No entanto, há uma exceção importante: quando você não pode controlar erros, tentar novamente pode ser o último recurso (por exemplo, para excluir erros de dependências externas). Nesse caso, não podemos influenciar a origem do erro. No entanto, seja extremamente cuidadoso ao fazer isso: não fique cego para falhas ao tentar novamente um teste e use notificações para lembrá-lo quando um teste estiver sendo ignorado.
O exemplo a seguir é um que usei em nosso CI com o GitLab. Outros ambientes podem ter sintaxe diferente para obter novas tentativas, mas isso deve lhe dar um gostinho:
test: script: rspec retry: max: 2 when: runner_system_failureNeste exemplo, estamos configurando quantas tentativas devem ser feitas se o trabalho falhar. O interessante é a possibilidade de tentar novamente se houver um erro no sistema runner (por exemplo, a configuração do trabalho falhou). Estamos optando por repetir nosso trabalho somente se algo na configuração do docker falhar.
Observe que isso tentará novamente todo o trabalho quando acionado. Se você deseja repetir apenas o teste defeituoso, precisará procurar um recurso em sua estrutura de teste para oferecer suporte a isso. Abaixo está um exemplo do Cypress, que suporta a repetição de um único teste desde a versão 5:
{ "retries": { // Configure retry attempts for 'cypress run` "runMode": 2, // Configure retry attempts for 'cypress open` "openMode": 2, } } Você pode ativar novas tentativas de teste no arquivo de configuração do Cypress, cypress.json . Lá, você pode definir as tentativas de repetição no executor de teste e no modo headless.
Usando tempos de espera dinâmicos
Este ponto é importante para todos os tipos de testes, mas especialmente para testes de interface do usuário. Eu não posso enfatizar isso o suficiente: nunca use tempos de espera fixos – pelo menos não sem uma razão muito boa. Se você fizer isso, considere os resultados possíveis. Na melhor das hipóteses, você escolherá tempos de espera muito longos, tornando o conjunto de testes mais lento do que o necessário. Na pior das hipóteses, você não esperará o suficiente, então o teste não prosseguirá porque o aplicativo ainda não está pronto, fazendo com que o teste falhe de maneira irregular. Na minha experiência, esta é a causa mais comum de testes escamosos.
Em vez disso, use tempos de espera dinâmicos. Existem muitas maneiras de fazer isso, mas o Cypress lida com elas particularmente bem.
Todos os comandos do Cypress possuem um método de espera implícito: eles já verificam se o elemento ao qual o comando está sendo aplicado existe no DOM pelo tempo especificado - apontando para a capacidade de repetição do Cypress. No entanto, ele apenas verifica a existência e nada mais. Portanto, recomendo dar um passo adiante — aguardar qualquer alteração na interface do usuário do seu site ou aplicativo que um usuário real também veja, como alterações na própria interface do usuário ou na animação.
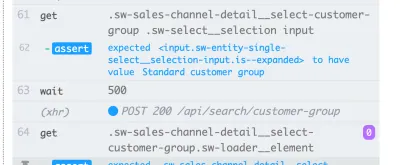
Este exemplo usa um tempo de espera explícito no elemento com o seletor .offcanvas . O teste só prosseguirá se o elemento estiver visível até o tempo limite especificado, que você pode configurar:
// Wait for changes in UI (until element is visible) cy.get(#element).should('be.visible'); Outra possibilidade interessante no Cypress para espera dinâmica são seus recursos de rede. Sim, podemos aguardar a ocorrência de solicitações e os resultados de suas respostas. Eu uso esse tipo de espera especialmente com frequência. No exemplo abaixo, definimos a solicitação a ser aguardada, usamos um comando wait para aguardar a resposta e declaramos seu código de status:
// File: checkout-info.spec.js // Define request to wait for cy.intercept({ url: '/widgets/customer/info', method: 'GET' }).as('checkoutAvailable'); // Imagine other test steps here... // Assert the response's status code of the request cy.wait('@checkoutAvailable').its('response.statusCode') .should('equal', 200);Dessa forma, podemos esperar exatamente o tempo que nosso aplicativo precisar, tornando os testes mais estáveis e menos propensos a falhas devido a vazamentos de recursos ou outros problemas ambientais.
Depurando testes instáveis
Agora sabemos como evitar testes esquisitos por design. Mas e se você já estiver lidando com um teste esquisito? Como você pode se livrar dele?
Quando eu estava depurando, colocar o teste falho em um loop me ajudou muito a descobrir falhas. Por exemplo, se você executar um teste 50 vezes e ele passar todas as vezes, poderá ter mais certeza de que o teste é estável - talvez sua correção tenha funcionado. Se não, você pode pelo menos obter mais informações sobre o teste esquisito.
// Use in build Lodash to repeat the test 100 times Cypress._.times(100, (k) => { it(`typing hello ${k + 1} / 100`, () => { // Write your test steps in here }) }) Obter mais informações sobre esse teste esquisito é especialmente difícil em CI. Para obter ajuda, veja se sua estrutura de teste é capaz de obter mais informações sobre sua compilação. Quando se trata de testes de front-end, geralmente você pode usar um console.log em seus testes:
it('should be a Vue.JS component', () => { // Mock component by a method defined before const wrapper = createWrapper(); // Print out the component's html console.log(wrapper.html()); expect(wrapper.isVueInstance()).toBe(true); }) Este exemplo é retirado de um teste de unidade Jest no qual uso um console.log para obter a saída do HTML do componente que está sendo testado. Se você usar essa possibilidade de registro no executor de testes do Cypress, poderá até inspecionar a saída nas ferramentas de desenvolvedor de sua escolha. Além disso, quando se trata de Cypress no CI, você pode inspecionar essa saída no log do seu CI usando um plug-in.
Sempre observe os recursos de sua estrutura de teste para obter suporte com log. No teste de interface do usuário, a maioria dos frameworks fornece recursos de captura de tela — pelo menos em caso de falha, uma captura de tela será feita automaticamente. Alguns frameworks até fornecem gravação de vídeo , o que pode ser uma grande ajuda para obter informações sobre o que está acontecendo em seu teste.
Combata Pesadelos de Flakiness!
É importante procurar continuamente por testes instáveis, seja prevenindo-os em primeiro lugar ou depurando-os e corrigindo-os assim que ocorrerem. Precisamos levá-los a sério, porque eles podem sugerir problemas em sua aplicação.
Identificando as bandeiras vermelhas
Prevenir testes escamosos em primeiro lugar é o melhor, é claro. Para recapitular rapidamente, aqui estão algumas bandeiras vermelhas:
- O teste é grande e contém muita lógica.
- O teste abrange muito código (por exemplo, em testes de interface do usuário).
- O teste faz uso de tempos de espera fixos.
- O teste depende de testes anteriores.
- O teste afirma dados que não são 100% previsíveis, como o uso de IDs, horários ou dados de demonstração, especialmente os gerados aleatoriamente.
Se você mantiver as dicas e estratégias deste artigo em mente, poderá evitar testes esquisitos antes que eles aconteçam. E se eles vierem, você saberá como depurá-los e corrigi-los.
Essas etapas realmente me ajudaram a recuperar a confiança em nosso conjunto de testes. Nosso conjunto de testes parece estável no momento. Pode haver problemas no futuro - nada é 100% perfeito. Esse conhecimento e essas estratégias me ajudarão a lidar com eles. Assim, vou crescer confiante na minha capacidade de lutar contra esses pesadelos de teste esquisito .
Espero ter conseguido aliviar pelo menos um pouco da sua dor e preocupação com a descamação!
Leitura adicional
Se você quiser aprender mais sobre esse tópico, aqui estão alguns recursos e artigos interessantes, que me ajudaram muito:
- Artigos sobre “flake”, Cypress.io
- “Repetir seus testes é realmente uma coisa boa (se sua abordagem estiver correta)”, Filip Hric, Cypress.io
- “Teste Flakiness: Métodos para Identificar e Lidar com Testes Flaky”, Jason Palmer, Spotify R&D Engineering
- “Testes irregulares no Google e como os mitigamos”, John Micco, blog de testes do Google