
Carregamento de imagem mais rápido com visualizações de imagem incorporadas
Publicados: 2022-03-10A visualização de imagem de baixa qualidade (LQIP) e a variante SQIP baseada em SVG são as duas técnicas predominantes para carregamento lento de imagem. O que ambos têm em comum é que você primeiro gera uma imagem de visualização de baixa qualidade. Isso será exibido desfocado e posteriormente substituído pela imagem original. E se você pudesse apresentar uma imagem de visualização ao visitante do site sem precisar carregar dados adicionais?
Os arquivos JPEG, para os quais o carregamento lento é mais utilizado, têm a possibilidade, de acordo com a especificação, de armazenar os dados contidos neles de forma que primeiro o conteúdo da imagem grosseira e depois o detalhado seja exibido. Em vez de ter a imagem construída de cima para baixo durante o carregamento (modo de linha de base), uma imagem borrada pode ser exibida muito rapidamente, que gradualmente se torna cada vez mais nítida (modo progressivo).


Além da melhor experiência do usuário proporcionada pela aparência exibida mais rapidamente, os JPEGs progressivos geralmente também são menores do que seus equivalentes codificados na linha de base. Para arquivos maiores que 10 kB, há uma probabilidade de 94% de uma imagem menor ao usar o modo progressivo, de acordo com Stoyan Stefanov, da equipe de desenvolvimento do Yahoo.
Se o seu site consiste em muitos JPEGs, você notará que mesmo os JPEGs progressivos carregam um após o outro. Isso ocorre porque os navegadores modernos permitem apenas seis conexões simultâneas a um domínio. JPEGs progressivos por si só não são, portanto, a solução para dar ao usuário a impressão mais rápida possível da página. Na pior das hipóteses, o navegador carregará uma imagem completamente antes de começar a carregar a próxima.
A ideia apresentada aqui agora é carregar apenas tantos bytes de um JPEG progressivo do servidor que você possa obter rapidamente uma impressão do conteúdo da imagem. Posteriormente, em um momento definido por nós (por exemplo, quando todas as imagens de visualização na viewport atual tiverem sido carregadas), o restante da imagem deverá ser carregado sem solicitar novamente a parte já solicitada para visualização.

Infelizmente, você não pode dizer a uma tag img em um atributo quanto da imagem deve ser carregada em que momento. Com Ajax, no entanto, isso é possível, desde que o servidor que entrega a imagem suporte HTTP Range Requests.
Usando solicitações de intervalo HTTP, um cliente pode informar ao servidor em um cabeçalho de solicitação HTTP quais bytes do arquivo solicitado devem estar contidos na resposta HTTP. Esse recurso, suportado por cada um dos servidores maiores (Apache, IIS, nginx), é usado principalmente para reprodução de vídeo. Se um usuário pular para o final de um vídeo, não será muito eficiente carregar o vídeo completo antes que o usuário possa finalmente ver a parte desejada. Portanto, apenas os dados de vídeo no horário solicitado pelo usuário são solicitados pelo servidor, para que o usuário possa assistir ao vídeo o mais rápido possível.
Agora, enfrentamos os três desafios a seguir:
- Criando o JPEG progressivo
- Determinar o deslocamento de bytes até o qual a primeira solicitação de intervalo HTTP deve carregar a imagem de visualização
- Criando o código JavaScript de front-end
1. Criando o JPEG Progressivo
Um JPEG progressivo consiste em vários segmentos de varredura, cada um dos quais contém uma parte da imagem final. A primeira varredura mostra a imagem apenas grosseiramente, enquanto as que seguem posteriormente no arquivo adicionam informações cada vez mais detalhadas aos dados já carregados e, finalmente, formam a aparência final.
A aparência exata das digitalizações individuais é determinada pelo programa que gera os JPEGs. Em programas de linha de comando como o cjpeg do projeto mozjpeg, você pode até definir quais dados essas varreduras contêm. No entanto, isso requer um conhecimento mais aprofundado, o que ultrapassaria o escopo deste artigo. Para isso, gostaria de consultar meu artigo "Finalmente Entendendo o JPG", que ensina os fundamentos da compactação JPEG. Os parâmetros exatos que devem ser passados ao programa em um script de varredura são explicados no wizard.txt do projeto mozjpeg. Na minha opinião, os parâmetros do script de varredura (sete varreduras) usados pelo mozjpeg por padrão são um bom compromisso entre a estrutura progressiva rápida e o tamanho do arquivo e podem, portanto, ser adotados.
Para transformar nosso JPEG inicial em um JPEG progressivo, usamos jpegtran do projeto mozjpeg. Esta é uma ferramenta para fazer alterações sem perdas em um JPEG existente. As compilações pré-compiladas para Windows e Linux estão disponíveis aqui: https://mozjpeg.codelove.de/binaries.html. Se você preferir jogar pelo seguro por motivos de segurança, é melhor construí-los você mesmo.
A partir da linha de comando, agora criamos nosso JPEG progressivo:
$ jpegtran input.jpg > progressive.jpgO fato de querermos construir um JPEG progressivo é assumido pelo jpegtran e não precisa ser especificado explicitamente. Os dados da imagem não serão alterados de forma alguma. Apenas a disposição dos dados de imagem dentro do arquivo é alterada.
Metadados irrelevantes para a aparência da imagem (como dados Exif, IPTC ou XMP), idealmente devem ser removidos do JPEG, uma vez que os segmentos correspondentes só podem ser lidos por decodificadores de metadados se precederem o conteúdo da imagem. Como não podemos movê-los para trás dos dados da imagem no arquivo por esse motivo, eles já seriam entregues com a imagem de visualização e aumentariam a primeira solicitação de acordo. Com o programa de linha de comando exiftool , você pode remover facilmente esses metadados:
$ exiftool -all= progressive.jpgSe você não quiser usar uma ferramenta de linha de comando, também poderá usar o serviço de compactação online compress-or-die.com para gerar um JPEG progressivo sem metadados.
2. Determine o deslocamento de bytes até o qual a primeira solicitação de intervalo HTTP deve carregar a imagem de visualização
Um arquivo JPEG é dividido em diferentes segmentos, cada um contendo diferentes componentes (dados de imagem, metadados como IPTC, Exif e XMP, perfis de cores incorporados, tabelas de quantização, etc.). Cada um desses segmentos começa com um marcador introduzido por um byte FF hexadecimal. Isto é seguido por um byte que indica o tipo de segmento. Por exemplo, D8 completa o marcador para o marcador SOI FF D8 (Start Of Image), com o qual cada arquivo JPEG começa.
Cada início de uma varredura é marcado pelo marcador SOS (Start Of Scan, hexadecimal FF DA ). Como os dados por trás do marcador SOS são codificados por entropia (JPEGs usam a codificação Huffman), há outro segmento com as tabelas Huffman (DHT, hexadecimal FF C4 ) necessárias para decodificação antes do segmento SOS. A área de interesse para nós dentro de um arquivo JPEG progressivo, portanto, consiste em alternar tabelas Huffman/segmentos de dados de varredura. Assim, se quisermos exibir a primeira varredura muito grosseira de uma imagem, temos que solicitar todos os bytes até a segunda ocorrência de um segmento DHT (hexadecimal FF C4 ) do servidor.
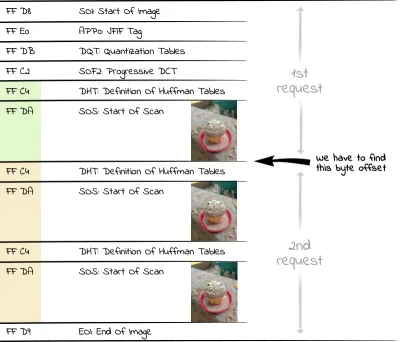
Em PHP, podemos usar o seguinte código para ler o número de bytes necessários para todas as varreduras em um array:
<?php $img = "progressive.jpg"; $jpgdata = file_get_contents($img); $positions = []; $offset = 0; while ($pos = strpos($jpgdata, "\xFF\xC4", $offset)) { $positions[] = $pos+2; $offset = $pos+2; }Temos que adicionar o valor de dois à posição encontrada porque o navegador só renderiza a última linha da imagem de visualização quando encontra um novo marcador (que consiste em dois bytes, conforme mencionado).
Como estamos interessados na primeira imagem de visualização neste exemplo, encontramos a posição correta em $positions[1] até a qual temos que solicitar o arquivo via HTTP Range Request. Para solicitar uma imagem com melhor resolução, poderíamos usar uma posição posterior no array, por exemplo $positions[3] .

3. Criando o código JavaScript de front-end
Em primeiro lugar, definimos uma tag img , à qual damos a posição do byte avaliada:
<img data-src="progressive.jpg" data-bytes="<?= $positions[1] ?>"> Como costuma acontecer com bibliotecas de carregamento lento, não definimos o atributo src diretamente para que o navegador não comece imediatamente a solicitar a imagem do servidor ao analisar o código HTML.
Com o seguinte código JavaScript, agora carregamos a imagem de visualização:
var $img = document.querySelector("img[data-src]"); var URL = window.URL || window.webkitURL; var xhr = new XMLHttpRequest(); xhr.onload = function(){ if (this.status === 206){ $img.src_part = this.response; $img.src = URL.createObjectURL(this.response); } } xhr.open('GET', $img.getAttribute('data-src')); xhr.setRequestHeader("Range", "bytes=0-" + $img.getAttribute('data-bytes')); xhr.responseType = 'blob'; xhr.send(); Esse código cria uma solicitação Ajax que informa ao servidor em um cabeçalho de intervalo HTTP para retornar o arquivo do início para a posição especificada em data-bytes ... e nada mais. Se o servidor entender HTTP Range Requests, ele retornará os dados da imagem binária em uma resposta HTTP-206 (HTTP 206 = Partial Content) na forma de um blob, a partir do qual podemos gerar uma URL interna do navegador usando createObjectURL . Usamos essa URL como src para nossa tag img . Assim, carregamos nossa imagem de visualização.
Armazenamos o blob adicionalmente no objeto DOM na propriedade src_part , pois precisaremos desses dados imediatamente.
Na guia de rede do console do desenvolvedor, você pode verificar se não carregamos a imagem completa, mas apenas uma pequena parte. Além disso, o carregamento da URL do blob deve ser exibido com um tamanho de 0 bytes.
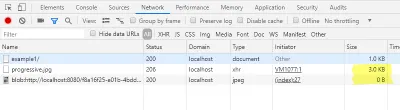
Como já carregamos o cabeçalho JPEG do arquivo original, a imagem de visualização tem o tamanho correto. Assim, dependendo da aplicação, podemos omitir a altura e a largura da tag img .
Alternativa: Carregar a imagem de visualização inline
Por motivos de desempenho, também é possível transferir os dados da imagem de visualização como URI de dados diretamente no código-fonte HTML. Isso nos poupa a sobrecarga de transferir os cabeçalhos HTTP, mas a codificação base64 torna os dados da imagem um terço maiores. Isso é relativizado se você entregar o código HTML com uma codificação de conteúdo como gzip ou brotli , mas você ainda deve usar URIs de dados para pequenas imagens de visualização.
Muito mais importante é o fato de que as imagens de visualização estão disponíveis imediatamente e não há atraso perceptível para o usuário ao construir a página.
Antes de tudo, temos que criar o URI de dados, que usamos na tag img como src . Para isso, criamos o URI de dados via PHP, onde este código é baseado no código recém-criado, que determina os deslocamentos de bytes dos marcadores SOS:
<?php … $fp = fopen($img, 'r'); $data_uri = 'data:image/jpeg;base64,'. base64_encode(fread($fp, $positions[1])); fclose($fp); O URI de dados criado agora é inserido diretamente na tag `img` como src :
<img src="<?= $data_uri ?>" data-src="progressive.jpg" alt="">Claro, o código JavaScript também deve ser adaptado:
<script> var $img = document.querySelector("img[data-src]"); var binary = atob($img.src.slice(23)); var n = binary.length; var view = new Uint8Array(n); while(n--) { view[n] = binary.charCodeAt(n); } $img.src_part = new Blob([view], { type: 'image/jpeg' }); $img.setAttribute('data-bytes', $img.src_part.size - 1); </script> Em vez de solicitar os dados via solicitação Ajax, onde receberíamos imediatamente um blob, neste caso temos que criar o blob nós mesmos a partir do URI de dados. Para fazer isso, liberamos o data-URI da parte que não contém dados de imagem: data:image/jpeg;base64 . Decodificamos os dados codificados em base64 restantes com o comando atob . Para criar um blob a partir dos dados de string agora binários, precisamos transferir os dados para uma matriz Uint8, que garante que os dados não sejam tratados como um texto codificado em UTF-8. A partir dessa matriz, agora podemos criar um blob binário com os dados de imagem da imagem de visualização.
Para que não tenhamos que adaptar o código a seguir para esta versão inline, adicionamos o atributo data-bytes na tag img , que no exemplo anterior contém o deslocamento de byte a partir do qual a segunda parte da imagem deve ser carregada .
Na guia de rede do console do desenvolvedor, você também pode verificar aqui que o carregamento da imagem de visualização não gera uma solicitação adicional, enquanto o tamanho do arquivo da página HTML aumentou.
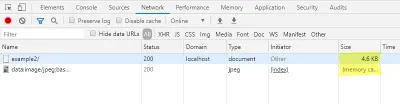
Carregando a imagem final
Em uma segunda etapa carregamos o restante do arquivo de imagem após dois segundos como exemplo:
setTimeout(function(){ var xhr = new XMLHttpRequest(); xhr.onload = function(){ if (this.status === 206){ var blob = new Blob([$img.src_part, this.response], { type: 'image/jpeg'} ); $img.src = URL.createObjectURL(blob); } } xhr.open('GET', $img.getAttribute('data-src')); xhr.setRequestHeader("Range", "bytes="+ (parseInt($img.getAttribute('data-bytes'), 10)+1) +'-'); xhr.responseType = 'blob'; xhr.send(); }, 2000); Desta vez, no cabeçalho Range, especificamos que queremos solicitar a imagem da posição final da imagem de visualização até o final do arquivo. A resposta à primeira solicitação é armazenada na propriedade src_part do objeto DOM. Usamos as respostas de ambas as solicitações para criar um novo blob por new Blob() , que contém os dados de toda a imagem. A URL do blob gerada a partir disso é usada novamente como src do objeto DOM. Agora a imagem está completamente carregada.
Além disso, agora podemos verificar os tamanhos carregados na guia de rede do console do desenvolvedor novamente.
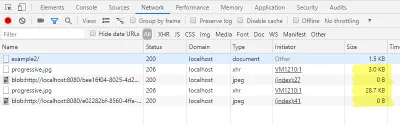
Protótipo
No URL a seguir, forneci um protótipo onde você pode experimentar diferentes parâmetros: https://embedded-image-preview.cerdmann.com/prototype/
O repositório GitHub para o protótipo pode ser encontrado aqui: https://github.com/McSodbrenner/embedded-image-preview
Considerações no final
Usando a tecnologia Embedded Image Preview (EIP) apresentada aqui, podemos carregar imagens de visualização qualitativamente diferentes de JPEGs progressivos com a ajuda de Ajax e HTTP Range Requests. Os dados dessas imagens de visualização não são descartados, mas reutilizados para exibir a imagem inteira.
Além disso, nenhuma imagem de visualização precisa ser criada. No lado do servidor, apenas o deslocamento de byte no qual a imagem de visualização termina deve ser determinado e salvo. Em um sistema CMS, deve ser possível salvar esse número como um atributo em uma imagem e levá-lo em consideração ao enviá-lo na tag img . Mesmo um fluxo de trabalho seria concebível, que complementa o nome do arquivo da imagem pelo deslocamento, por exemplo, progressive-8343.jpg , para não ter que salvar o deslocamento separado do arquivo de imagem. Esse deslocamento pode ser extraído pelo código JavaScript.
Como os dados da imagem de visualização são reutilizados, essa técnica pode ser uma alternativa melhor à abordagem usual de carregar uma imagem de visualização e, em seguida, um WebP (e fornecer um fallback JPEG para navegadores não compatíveis com WebP). A imagem de visualização geralmente destrói as vantagens de armazenamento do WebP, que não oferece suporte ao modo progressivo.
Atualmente, as imagens de visualização em LQIP normal são de qualidade inferior, pois supõe-se que carregar os dados de visualização requer largura de banda adicional. Como Robin Osborne já deixou claro em um post de blog em 2018, não faz muito sentido mostrar espaços reservados que não dão uma ideia da imagem final. Usando a técnica sugerida aqui, podemos mostrar um pouco mais da imagem final como uma imagem de visualização sem hesitação, apresentando ao usuário uma digitalização posterior do JPEG progressivo.
No caso de uma conexão de rede fraca do usuário, pode fazer sentido, dependendo do aplicativo, não carregar todo o JPEG, mas, por exemplo, omitir as duas últimas varreduras. Isso produz um JPEG muito menor com uma qualidade apenas ligeiramente reduzida. O usuário nos agradecerá por isso e não precisamos armazenar um arquivo adicional no servidor.
Agora, desejo-lhe muita diversão experimentando o protótipo e aguardo seus comentários.