
Detecção de notícias falsas no aprendizado de máquina [explicado com exemplo de codificação]
Publicados: 2021-02-08As notícias falsas são um dos maiores problemas da era atual da internet e das mídias sociais. Embora seja uma bênção que as notícias fluam de um canto do mundo para outro em questão de algumas horas, também é doloroso ver muitas pessoas e grupos espalhando notícias falsas.
Técnicas de aprendizado de máquina usando processamento de linguagem natural e aprendizado profundo podem ser usadas para resolver esse problema até certo ponto. Estaremos construindo um modelo de detecção de notícias falsas usando aprendizado de máquina neste tutorial.
Ao final deste artigo, você saberá o seguinte:
- Manipulando dados de texto
- Técnicas de processamento de PNL
- Contagem de vetorização e TF-IDF
- Fazendo previsões e classificando o texto das notícias
Participe do curso de IA e ML on-line das melhores universidades do mundo - mestrados, programas de pós-graduação executiva e programa de certificação avançada em ML e IA para acelerar sua carreira.
Índice
Dados e problema
Usaremos os dados do desafio Kaggle Fake News para fazer um classificador. O conjunto de dados consiste em 4 recursos e 1 destino binário. As 4 características são as seguintes:
- id : id exclusivo para um artigo de notícias
- title : o título de uma notícia
- autor : autor da notícia
- texto : o texto do artigo; pode estar incompleto
E o alvo é “label” que contém valores binários 0s e 1s. Onde 0 significa que é uma fonte confiável de notícias, ou em outras palavras, Not Fake. 1 significa que é uma notícia potencialmente falsa e não confiável. O conjunto de dados que temos consistiu em 20.800 instâncias. Vamos mergulhar direto.

Pré-processamento e limpeza de dados
| importar pandas como pd df=pd.read_csv( 'fake-news/train.csv' ) df.head() |
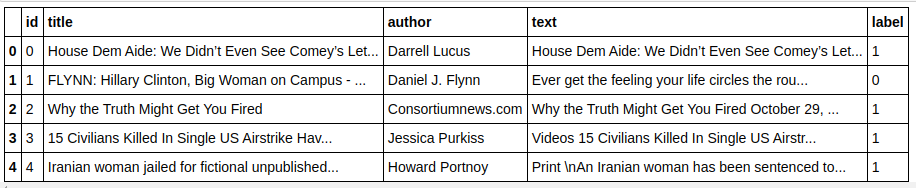
| X=df.drop( 'label' ,axis= 1 ) # Recursos y=df[ 'label' ] # Destino |
Precisamos descartar instâncias com dados ausentes agora.
| df=df.dropna() |
![]()
Como podemos ver, todas as instâncias com dados ausentes foram descartadas.
| mensagens=df.copy() messages.reset_index(inplace= True ) mensagens.head( 10 ) |
Vamos dar uma olhada nos dados uma vez.
| mensagens['texto'][6] |

Como podemos ver, é necessário seguir os seguintes passos:
- Remoção de palavras irrelevantes: Existem muitas palavras que não agregam valor a nenhum texto, independentemente dos dados. Por exemplo, "eu", "um", "sou", etc. Essas palavras não têm valor informativo e, portanto, podem ser removidas para reduzir o tamanho do nosso corpus para que possamos nos concentrar apenas nas palavras/tokens que são de valor real .
- Stemming as palavras: Stemming e Lematization são as técnicas para reduzir as palavras a seus radicais ou raízes. A principal vantagem desta etapa é reduzir o tamanho do vocabulário. Por exemplo, palavras como Play, Playing, Played serão reduzidas para “Play”. Stemming apenas trunca as palavras para a palavra mais curta e não leva em consideração o aspecto gramatical do texto. A lematização, por outro lado, também leva em consideração gramatical e, portanto, produz resultados muito melhores. No entanto, a Lematização geralmente é mais lenta do que a derivação, pois precisa consultar o dicionário e levar em consideração o aspecto gramatical.
- Removendo tudo além de valores alfabéticos: Os valores não alfabéticos não são muito úteis aqui, então eles podem ser removidos. No entanto, você pode explorar mais para ver se a presença de dados numéricos ou outros tipos de dados tem algum impacto no destino.
- Minúsculas as palavras: Minúsculas as palavras para reduzir o vocabulário.
- Tokenize as sentenças: Gerando tokens a partir de sentenças.
| de sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer, HashingVectorizer de palavras irrelevantes de importação nltk.corpus de nltk.stem.porter importar PorterStemmer importar re ps = Porter Stemmer() corpus = [] for i in range(0, len(messages)): revisão = re.sub('[^a-zA-Z]', ' ', mensagens['text'][i]) review = review.lower() revisão = revisão.split() review = [ps.stem(word) para palavra em review se não for palavra em stopwords.words('english')] review = ' '.join(review) corpus.append(revisão) |
Vamos dar uma olhada no nosso corpus agora.
| corpus [ 3 ] |
![]()
Como podemos ver, as palavras agora são derivadas de palavras-raiz.
Vetorizador TF-IDF
Agora precisamos vetorizar as palavras para dados numéricos, o que também é chamado de vetorização. A maneira mais fácil de vetorizar é usar o Saco de Palavras. Mas Bag of Words cria uma matriz esparsa e, portanto, é necessária muita memória de processamento. Além disso, o BoW não leva em consideração a frequência das palavras, o que o torna um algoritmo ruim.
TF-IDF (Term Frequency – Inverse Document Frequency) é outra forma de vetorizar palavras que leva em consideração as frequências das palavras. Por exemplo, palavras comuns como “nós”, “nosso”, “o” estão em todos os documentos/instâncias, portanto, o valor de BoW será muito alto e, portanto, enganoso. Isso levará a um modelo ruim. TF-IDF é a multiplicação da Frequência do Termo e da Frequência Inversa do Documento.
Term Frequency leva em conta a frequência de palavras em um documento e Inverse Document Frequency leva em conta as palavras que estão presentes em todo o corpus. As palavras que estão presentes em todo o corpus têm importância reduzida, pois o valor do IDF é muito menor. As palavras que estão presentes especificamente em um documento têm um valor IDF alto, o que torna o valor total de TF-IDF alto.
| ## Vetorizador TFi df de sklearn.feature_extraction.text import TfidfVectorizer tfidf_v = TfidfVectorizer(max_features= 5000 ,ngram_range=( 1 , 3 )) X=tfidf_v.fit_transform(corpus).toarray() y=messages[ 'label' ] |
No código acima, importamos o TF-IDF Vectorizer do módulo de extração de recursos do Sklearn. Fazemos seu objeto passando max_features como 5000 e ngram_range como (1,3). O parâmetro max_features define o número máximo de vetores de recursos que queremos criar e o parâmetro ngram_range define as combinações de ngram que queremos incluir. No nosso caso, teremos 3 combinações de 1 palavra, 2 palavras e 3 palavras. Vamos dar uma olhada em alguns dos recursos criados.

| tfidf_v.get_feature_names()[: 20 ] |

Como podemos ver, existem vários tipos de combinações formadas. Existem nomes de recursos com 1 token, 2 tokens e também com 3 tokens.
Fazendo um Dataframe
| ## Divida o conjunto de dados em Treinar e Testar de sklearn.model_selection importar train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size= 0.33 , random_state= 0 ) count_df = pd.DataFrame(X_train, columns=tfidf_v.get_feature_names()) count_df.head() |
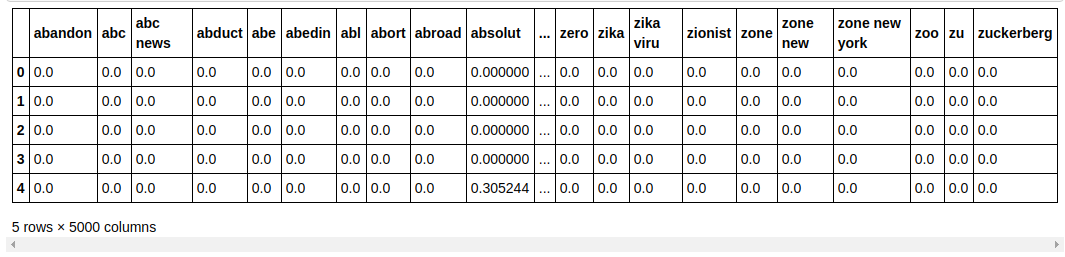
Dividimos o conjunto de dados em treinar e testar para que possamos testar o desempenho do modelo em dados não vistos. Em seguida, criamos um novo Dataframe que contém os novos vetores de recursos.
Modelagem e Ajuste
Algoritmo MultinomialNB
Primeiro, usamos o teorema Multinomial Naive Bayes que é o algoritmo mais comum e mais fácil preferido para classificação de dados de texto. Nós nos encaixamos nos dados de treinamento e prevemos nos dados de teste. Mais tarde, calculamos e plotamos a matriz de confusão e obtemos uma precisão de 88,1%.
| de sklearn.naive_bayes import MultinomialNB das métricas de importação do sklearn importar numpy como np importar itertools de sklearn.metrics importar plot_confusion_matrix classificador=MultinomialNB() classificador.fit(X_train, y_train) pred = classificador.predict(X_test) pontuação = métrica.accuracy_score(y_test, pred) print( “precisão: %0.3f” % pontuação) cm = métrica.confusão_matrix(y_test, pred) plot_confusion_matrix(cm, classes=[ 'FAKE' , 'REAL' ]) |
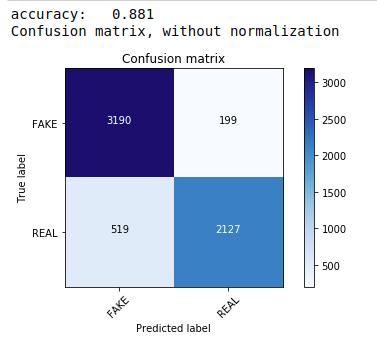
Classificador multinomial com ajuste de hiperparâmetro
MultinomialNB tem um parâmetro alfa que pode ser ajustado ainda mais. Portanto, executamos um loop para experimentar vários classificadores MultinomialNB com diferentes valores de alfa e verificar suas pontuações de precisão. E verificamos se a pontuação atual é maior que a pontuação anterior. Se for, então definimos o classificador como o atual.
| pontuação_anterior= 0 para alfa em np.arange( 0 , 1 , 0.1 ): sub_classifier=MultinomialNB(alfa=alfa) sub_classifier.fit(X_train,y_train) y_pred=sub_classifier.predict(X_test) pontuação = métrica.accuracy_score(y_test, y_pred) se pontuação>pontuação_anterior: classificador=sub_classificador print( “Alpha: {}, Score : {}” .format(alpha,score)) |
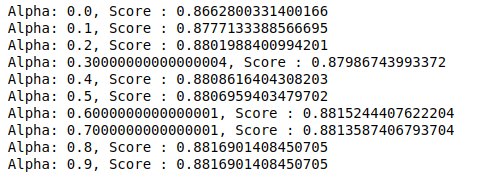
Portanto, podemos ver que um valor alfa de 0,9 ou 0,8 deu a maior pontuação de precisão.
Interpretando os Resultados
Agora vamos ver o que esses valores de coeficiente do classificador significam. Primeiro, salvaremos todos os nomes de recursos em outra variável.
| ## Obter nomes de recursos feature_names = cv.get_feature_names() |
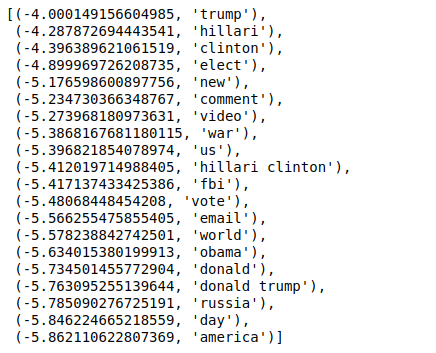
Agora, quando ordenamos os valores na ordem inversa, obtemos valores com um valor mínimo de -4. Estas denotam as palavras que são mais reais ou menos falsas.
| ### Mais real sorted(zip(classifier.coef_[ 0 ], feature_names), reverse= True )[: 20 ] |
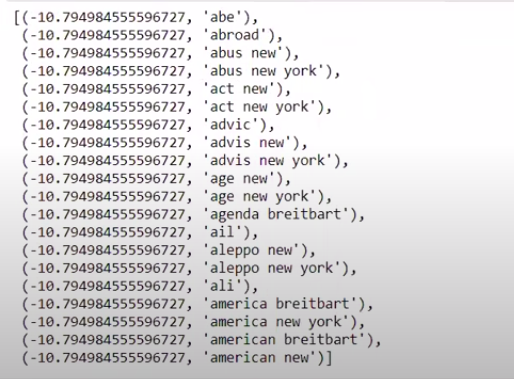
Quando ordenamos os valores em ordem não inversa, obtemos valores com valor mínimo de -10. Estas denotam as palavras que são menos reais ou mais falsas.
| ### Mais real sorted(zip(classifier.coef_[ 0 ], feature_names))[: 20 ] |
Conclusão
Neste tutorial, usamos apenas algoritmos de ML, mas você também usa outros métodos de redes neurais. Além disso, para vetorizar os dados de texto, utilizou-se o vetorizador TF-IDF. Existem mais vetorizadores como Count Vectorizer, Hashing Vectorizer, etc., que podem ser melhores em fazer o trabalho. Experimente e experimente outros algoritmos e técnicas para ver se você pode produzir melhores resultados ou não.
Se você estiver interessado em aprender mais sobre aprendizado de máquina, confira o Programa PG Executivo do IIIT-B e do upGrad em Machine Learning e IA , projetado para profissionais que trabalham e oferece mais de 450 horas de treinamento rigoroso, mais de 30 estudos de caso e atribuições, IIIT -B Alumni status, mais de 5 projetos práticos práticos e assistência de trabalho com as principais empresas.
Por que é necessário detectar notícias falsas?
Em sua condição atual, as plataformas de mídia social são altamente poderosas e valiosas, pois permitem aos usuários discutir e trocar ideias, bem como debater assuntos como democracia, educação e saúde. No entanto, certas entidades utilizam mal essas plataformas, para ganho monetário em algumas circunstâncias e para produzir pontos de vista preconceituosos, alterar mentalidades e disseminar sátira ou ridículo em outras. Fake news é o termo para esse fenômeno. A proliferação de postagens online que não aderem à realidade resultou em uma série de problemas na política, esportes, saúde, ciência e outros campos.
Quais empresas usam principalmente a detecção de notícias falsas?
A detecção de notícias falsas é usada em plataformas como redes sociais e sites de notícias. Gigantes de mídia social como Facebook, Instagram e Twitter são vulneráveis a notícias falsas, já que a maioria de seus usuários confia neles como fontes de notícias diárias para obter as informações mais atualizadas. Técnicas de detecção falsas também são usadas por empresas de mídia para determinar a autenticidade das informações que possuem. O e-mail é outro meio pelo qual os indivíduos podem receber notícias, o que dificulta a identificação e a verificação de sua veracidade. Hoaxes, spam e lixo eletrônico são bem conhecidos por serem transmitidos por e-mail. Como resultado, a maioria das plataformas de e-mail emprega detecção de notícias falsas para identificar spam e lixo eletrônico.